YOLOv8 快速入门

前言
本文是 YOLOv8 入门指南(大佬请绕过),将会详细讲解安装,配置,训练,验证,预测等过程
YOLOv8 官网:

注意:如果遇到权重文件,模型文件下载缓慢的问题,可以在自己本机上下载,再上传到服务器。也可以选择代理或是 IDM 这样的下载软件
安装配置
虚拟环境
本文使用 conda 创建虚拟环境,没有配置 conda 也可以使用 python venv 虚拟环境
# 创建环境
conda create -n pytorch python=3.8 -y
# 查看环境
conda env list
# 激活环境
conda activate pytorch安装依赖
请自行到 官网寻找安装命令(需要保证 PyTorch>=1.8)
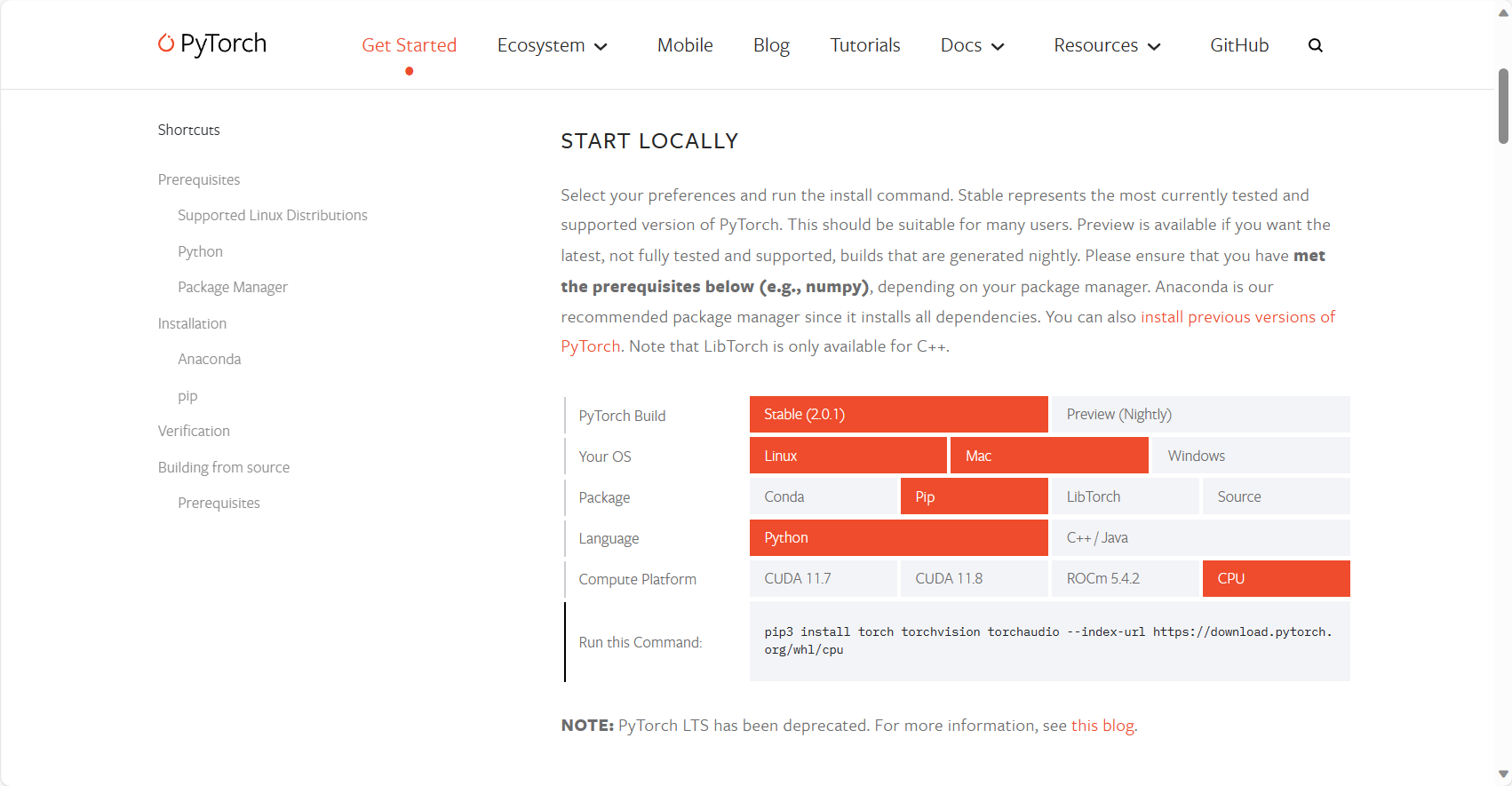
# 请自行替换命令
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cpu拉取仓库
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
# 安装依赖
pip install -e .如果只是想要快速尝试训练自定义数据集并预测结果,可以跳过后面章节教学,直接跳到最后章节的实战演练
两种使用方式
YOLO 命令行
YOLO命令行界面(command line interface, CLI), 方便在各种任务和版本上训练、验证或推断模型。CLI不需要定制或代码,可以使用 yolo 命令从终端运行所有任务。
【YOLO CLI 官方文档】:
语法(Usage)
yolo TASK MODE ARGS
Where TASK (optional) is one of [detect, segment, classify]
MODE (required) is one of [train, val, predict, export, track]
ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.查看所有参数:yolo cfg
训练(Train)
在COCO128上以图像大小 640 训练 YOLOv8n 100 个 epoch
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640恢复中断的训练
yolo detect train resume model=last.pt验证(Val)
在COCO128数据集上验证经过训练的 YOLOv8n 模型准确性。无需传递参数,因为它 model 保留了它的训练 data 和参数作为模型属性。
yolo detect val model=path/to/best.pt预测(Predict)
使用经过训练的 YOLOv8n 模型对图像运行预测。
yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg'导出(Export)
将 YOLOv8n 模型导出为不同的格式,如 ONNX、CoreML 等。
yolo export model=path/to/best.pt format=onnx可用导出形式如下
| Format 格式 | format Argument | format 论点 | Model 型 | Metadata 元数据 | Arguments 参数 |
|---|---|---|---|---|---|
| PyTorch | - | yolov8n.pt | ✅ | - | - |
| TorchScript | torchscript | yolov8n.torchscript | ✅ | imgsz, optimize | - |
| ONNX | onnx | yolov8n.onnx | ✅ | imgsz, half, dynamic, simplify, opset | - |
| OpenVINO | openvino | yolov8n_openvino_model/ | ✅ | imgsz, half | - |
| TensorRT | engine | yolov8n.engine | ✅ | imgsz, half, dynamic, simplify, workspace | - |
| CoreML | coreml | yolov8n.mlpackage | ✅ | imgsz, half, int8, nms | - |
| TF SavedModel | saved_model | yolov8n_saved_model/ | ✅ | imgsz, keras | - |
| TF GraphDef | pb | yolov8n.pb | ❌ | imgsz | - |
| TF Lite | tflite | yolov8n.tflite | ✅ | imgsz, half, int8 | - |
| TF Edge TPU | edgetpu | yolov8n_edgetpu.tflite | ✅ | imgsz | - |
| TF.js | tfjs | yolov8n_web_model/ | ✅ | imgsz | - |
| PaddlePaddle | paddle | yolov8n_paddle_model/ | ✅ | imgsz | - |
| ncnn | ncnn | yolov8n_ncnn_model/ | ✅ | imgsz, half | - |
覆盖默认配置文件
首先使用命令 yolo copy-cfg 在当前工作目录中创建一个 default.yaml 的副本 default_copy.yaml,之后即可指定配置文件来覆盖默认配置文件
yolo cfg=default_copy.yaml imgsz=320Python 脚本
YOLOv8 可以无缝集成到 Python 项目中,以进行对象检测、分割和分类。同时易于使用的 Python 界面是一个宝贵的资源,能够快速实现高级对象检测功能
【YOLO Python 官方文档】:
示例
from ultralytics import YOLO
# 从头开始创建一个新的YOLO模型
model = YOLO('yolov8n.yaml')
# 加载预训练的YOLO模型(推荐用于训练)
model = YOLO('yolov8n.pt')
# 使用'coco128.yaml'数据集对模型进行训练,训练3个epoch
results = model.train(data='coco128.yaml', epochs=3)
# 在验证集上评估模型的性能
results = model.val()
# 使用模型对图像进行目标检测
results = model('https://ultralytics.com/images/bus.jpg')
# 将模型导出为ONNX格式
success = model.export(format='onnx')
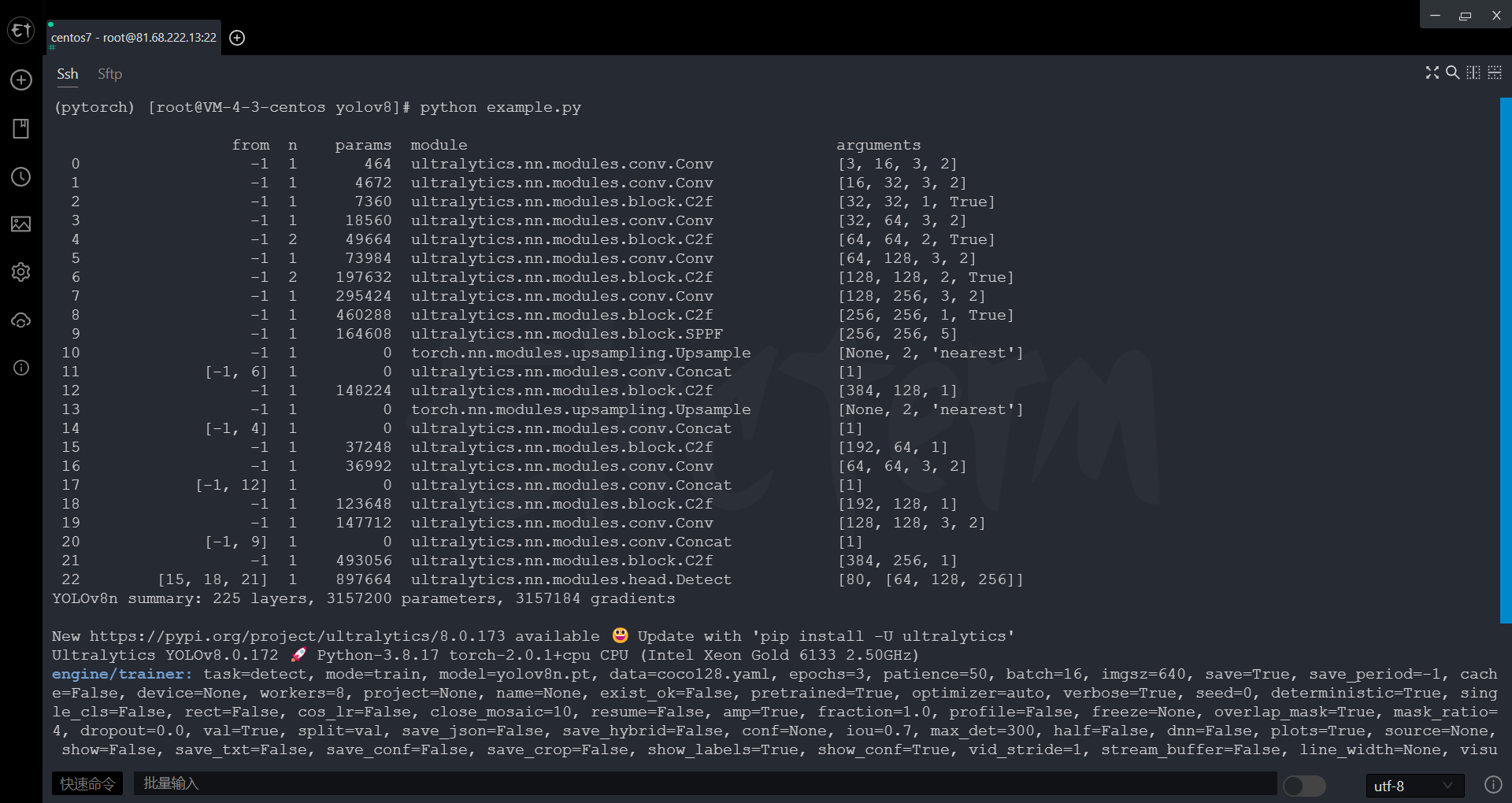

训练
训练模式用于在自定义数据集上训练 YOLOv8 模型。在此模式下,使用指定的数据集和超参数训练模型。训练过程涉及优化模型的参数,以便它可以准确地预测图像中对象的类别和位置。
预训练(From pretrained 推荐使用)
from ultralytics import YOLO
model = YOLO('yolov8n.pt') # pass any model type
results = model.train(epochs=5)初始训练(From scratch)
from ultralytics import YOLO
model = YOLO('yolov8n.yaml')
results = model.train(data='coco128.yaml', epochs=5)恢复训练(Resume)
model = YOLO("last.pt")
results = model.train(resume=True)验证
Val 模式用于在训练 YOLOv8 模型后对其进行验证。在此模式下,在验证集上评估模型,以衡量其准确性和泛化性能。此模式可用于调整模型的超参数以提高其性能。
训练后验证
from ultralytics import YOLO
# 导入YOLO模型
model = YOLO('yolov8n.yaml')
# 使用'coco128.yaml'数据集对模型进行训练,训练5个epoch
model.train(data='coco128.yaml', epochs=5)
# 对训练数据进行自动评估
model.val() # 它会自动评估您训练的数据。单独验证
from ultralytics import YOLO
# 导入YOLO模型
model = YOLO("model.pt")
# 如果您没有设置data参数,它将使用model.pt中的数据YAML文件。
model.val()
# 或者您可以设置要验证的数据
model.val(data='coco128.yaml')预测
预测模式用于使用经过训练的 YOLOv8 模型对新图像或视频进行预测。在此模式下,模型从检查点文件加载,用户可以提供图像或视频来执行推理。该模型预测输入图像或视频中对象的类别和位置。
from ultralytics import YOLO
from PIL import Image
import cv2
model = YOLO("model.pt")
# 接受各种格式 - 图像/目录/路径/URL/视频/PIL/ndarray。0表示网络摄像头
results = model.predict(source="0")
results = model.predict(source="folder", show=True) # 显示预测结果。接受所有YOLO预测参数
# 使用PIL库
im1 = Image.open("bus.jpg")
results = model.predict(source=im1, save=True) # 保存绘制的图像
# 使用ndarray
im2 = cv2.imread("bus.jpg")
results = model.predict(source=im2, save=True, save_txt=True) # 将预测结果保存为标签
# 使用PIL/ndarray列表
results = model.predict(source=[im1, im2])导出
导出模式用于将 YOLOv8 模型导出为可用于部署的格式。在此模式下,模型将转换为可供其他软件应用程序或硬件设备使用的格式。将模型部署到生产环境时,此模式非常有用。
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
model.export(format='onnx', dynamic=True)跟踪
跟踪模式用于使用 YOLOv8 模型实时跟踪对象。在此模式下,模型从检查点文件加载,用户可以提供实时视频流来执行实时对象跟踪。此模式对于监控系统或自动驾驶汽车等应用非常有用。
from ultralytics import YOLO
# 加载模型
model = YOLO('yolov8n.pt') # 加载官方的检测模型
model = YOLO('yolov8n-seg.pt') # 加载官方的分割模型
model = YOLO('path/to/best.pt') # 加载自定义模型
# 使用模型进行目标跟踪
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")训练器
YOLO模型类是Trainer类的高级包装器。每个YOLO任务都有自己的从BaseTrainer继承来的训练器。
from ultralytics.yolo import v8 import DetectionTrainer, DetectionValidator, DetectionPredictor
# trainer
trainer = DetectionTrainer(overrides={})
trainer.train()
trained_model = trainer.best
# Validator
val = DetectionValidator(args=...)
val(model=trained_model)
# predictor
pred = DetectionPredictor(overrides={})
pred(source=SOURCE, model=trained_model)
# resume from last weight
overrides["resume"] = trainer.last
trainer = detect.DetectionTrainer(overrides=overrides)多任务支持
下面示例主要使用 Python 脚本的形式,CLI 形式可以自行到官网找到对应示例代码
官方文档:
目标检测
物体检测是一项涉及识别图像或视频流中物体的位置和类别的任务。
对象检测器的输出是一组包围图像中的对象的包围框,以及每个框的类标签和置信度分数。当你需要识别场景中感兴趣的物体,但不需要知道物体的确切位置或它的确切形状时,物体检测是一个很好的选择。
训练
在图像大小为 640 的 COCO128 数据集上训练 YOLOv8n 100 个 epoch。
设备是自动确定的。如果 GPU 可用,则将使用它,否则将在 CPU 上开始训练。
from ultralytics import YOLO
# 加载一个模型
model = YOLO('yolov8n.yaml') # 从YAML文件构建一个新模型
model = YOLO('yolov8n.pt') # 加载一个预训练模型(推荐用于训练)
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从YAML文件构建模型并加载权重
# 训练模型
results = model.train(data='coco128.yaml', epochs=100, imgsz=640)可以使用 device 参数指定训练设备。如果未传递任何参数,则将使用 GPU device=0 (如果可用),否则 device=cpu 将使用。
from ultralytics import YOLO
# 加载一个模型
model = YOLO('yolov8n.pt') # 加载一个预训练模型(推荐用于训练)
# 使用2个GPU训练模型
results = model.train(data='coco128.yaml', epochs=100, imgsz=640, device=[0, 1])验证
Val 模式用于在训练 YOLOv8 模型后对其进行验证。在此模式下,在验证集上评估模型,以衡量其准确性和泛化性能。此模式可用于调整模型的超参数以提高其性能。
YOLOv8 模型会自动记住其训练设置,因此您只需 yolo val model=yolov8n.pt 使用 or model('yolov8n.pt').val() 即可在原始数据集上轻松验证相同图像大小和原始数据集上的模型
在COCO128数据集上验证经过训练的 YOLOv8n 模型准确性。无需传递参数,因为它 model 保留了它的训练 data 和参数作为模型属性
from ultralytics import YOLO
# 导入模型
model = YOLO('yolov8n.pt') # 加载一个官方模型
model = YOLO('path/to/best.pt') # 加载一个自定义模型
# 验证模型
metrics = model.val() # 不需要参数,数据集和设置会被记住
metrics.box.map # mAP50-95
metrics.box.map50 # mAP50
metrics.box.map75 # mAP75
metrics.box.maps # 包含每个类别的mAP50-95的列表预测
YOLOv8 预测模式可以为各种任务生成预测,在使用流式处理模式时返回对象列表或内存高效的 Results Results 对象生成器。通过传入 stream=True 预测器的调用方法来启用流式处理模式。
YOLOv8 可以处理不同类型的输入源进行推理,如下表所示。源包括静态图像、视频流和各种数据格式。该表还指示每个源是否可以在流模式下与参数 stream=True ✅一起使用。流式传输模式有利于处理视频或实时流,因为它会创建结果生成器,而不是将所有帧加载到内存中
from ultralytics import YOLO
# 导入模型
model = YOLO('yolov8n.pt') # 加载一个预训练的YOLOv8n模型
# 对图像列表进行批量推理
results = model(['im1.jpg', 'im2.jpg']) # 返回一个Results对象列表
# 处理结果列表
for result in results:
boxes = result.boxes # 用于边界框输出的Boxes对象
masks = result.masks # 用于分割掩模输出的Masks对象
keypoints = result.keypoints # 用于姿势输出的Keypoints对象
probs = result.probs # 用于分类输出的Probs对象导出
导出模式用于将 YOLOv8 模型导出为可用于部署的格式。在此模式下,模型将转换为可供其他软件应用程序或硬件设备使用的格式。将模型部署到生产环境时,此模式非常有用。
from ultralytics import YOLO
# 导入模型
model = YOLO('yolov8n.pt') # 加载一个官方模型
model = YOLO('path/to/best.pt') # 加载一个自定义训练的模型
# 导出模型
model.export(format='onnx')实例分割和目标分类此处不再赘述,可以自行查找官方文档
实战演练
下面将会自定义训练目标检测数据集
注意:没有特殊说明,路径均是以项目根目录为准
官方数据集
首先下载权重文件并将放到 ultralytics 项目根目录
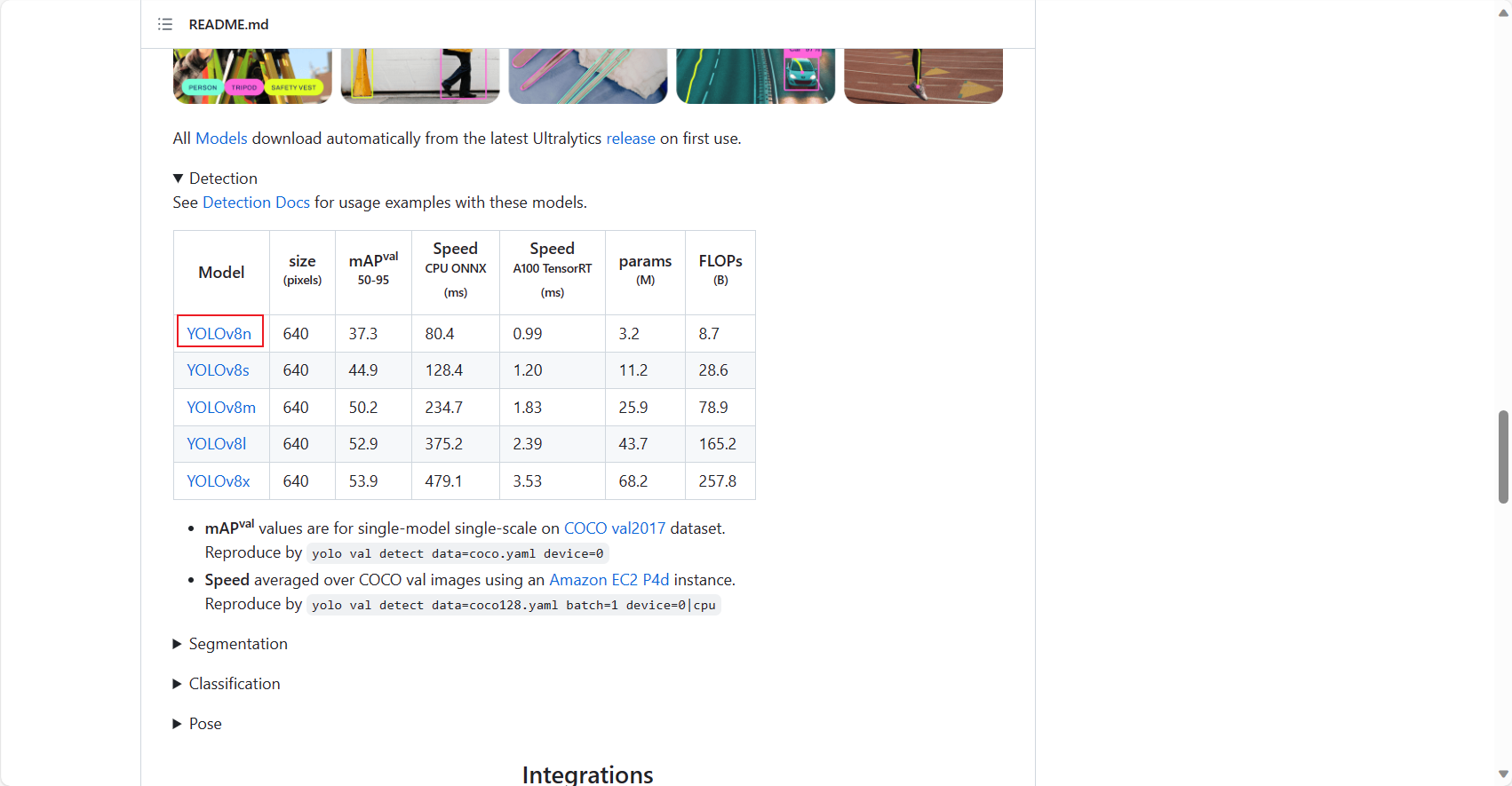
之后测试预训练模型的效果,在根目录执行如下命令
yolo predict model=yolov8n.pt source=ultralytics/assets/bus.jpg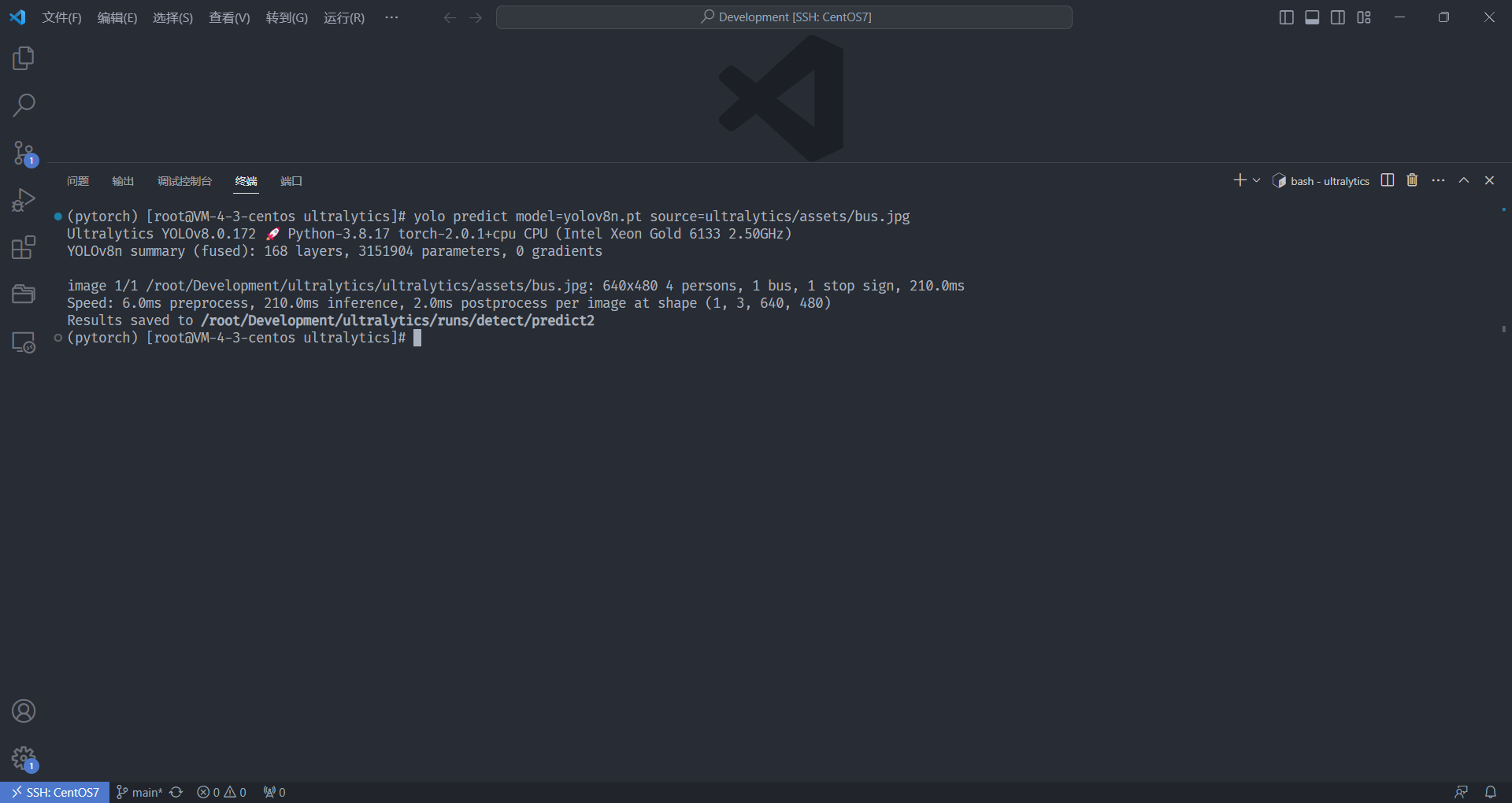
之后我们查看保存的检测好的图片 /root/Development/ultralytics/runs/detect/predict2
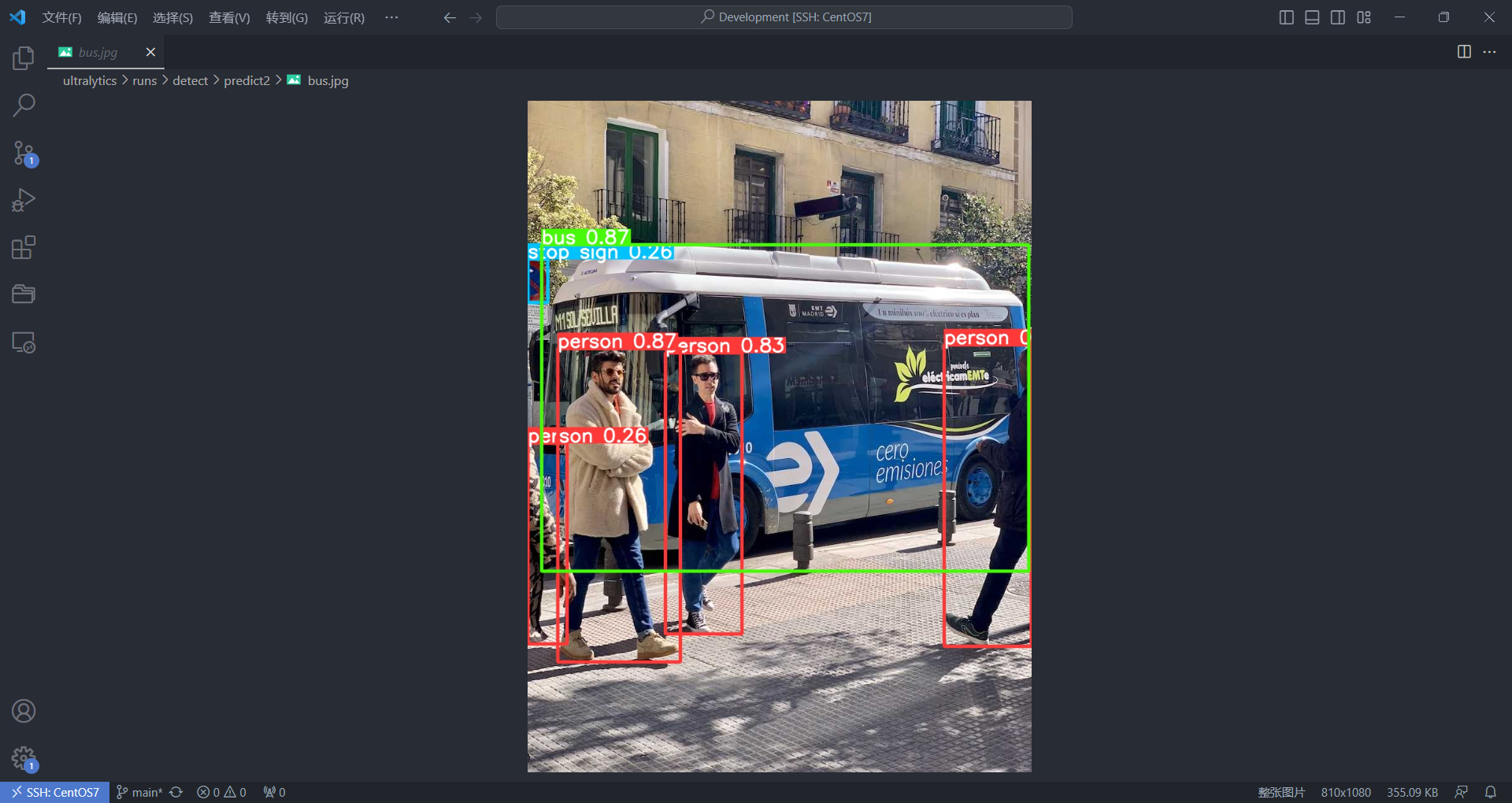
训练 COCO128 数据集(这里可以配置 tensorboard 可视化面板,这里不赘述)
yolo train data=coco128.yaml model=yolov8n.pt epochs=3 lr0=0.01 batch=4与此同时根目录下面生成了一个datasets文件夹,里面有 coco128 的数据集
注意:这里的 datasets 下载目录是在
~/.config/Ultralytics/settings.yaml文件中定义的,可以后续修改
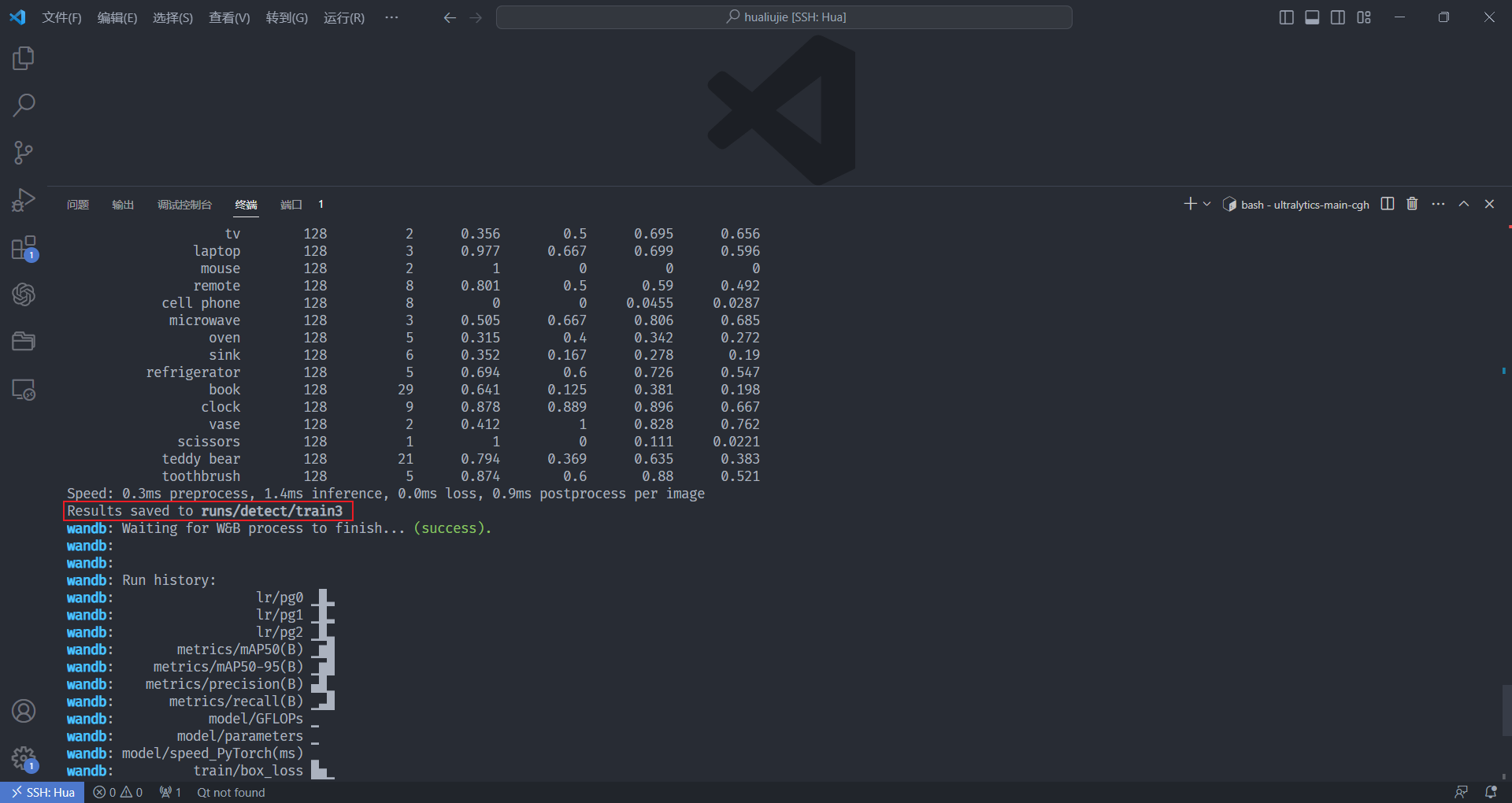
之后查看存储的训练结果的文件夹,weights 文件夹里面装的是效果最好的一次权重文件以及最后一轮训练的权重文件
自定义数据集
下载数据集
【下载地址】:
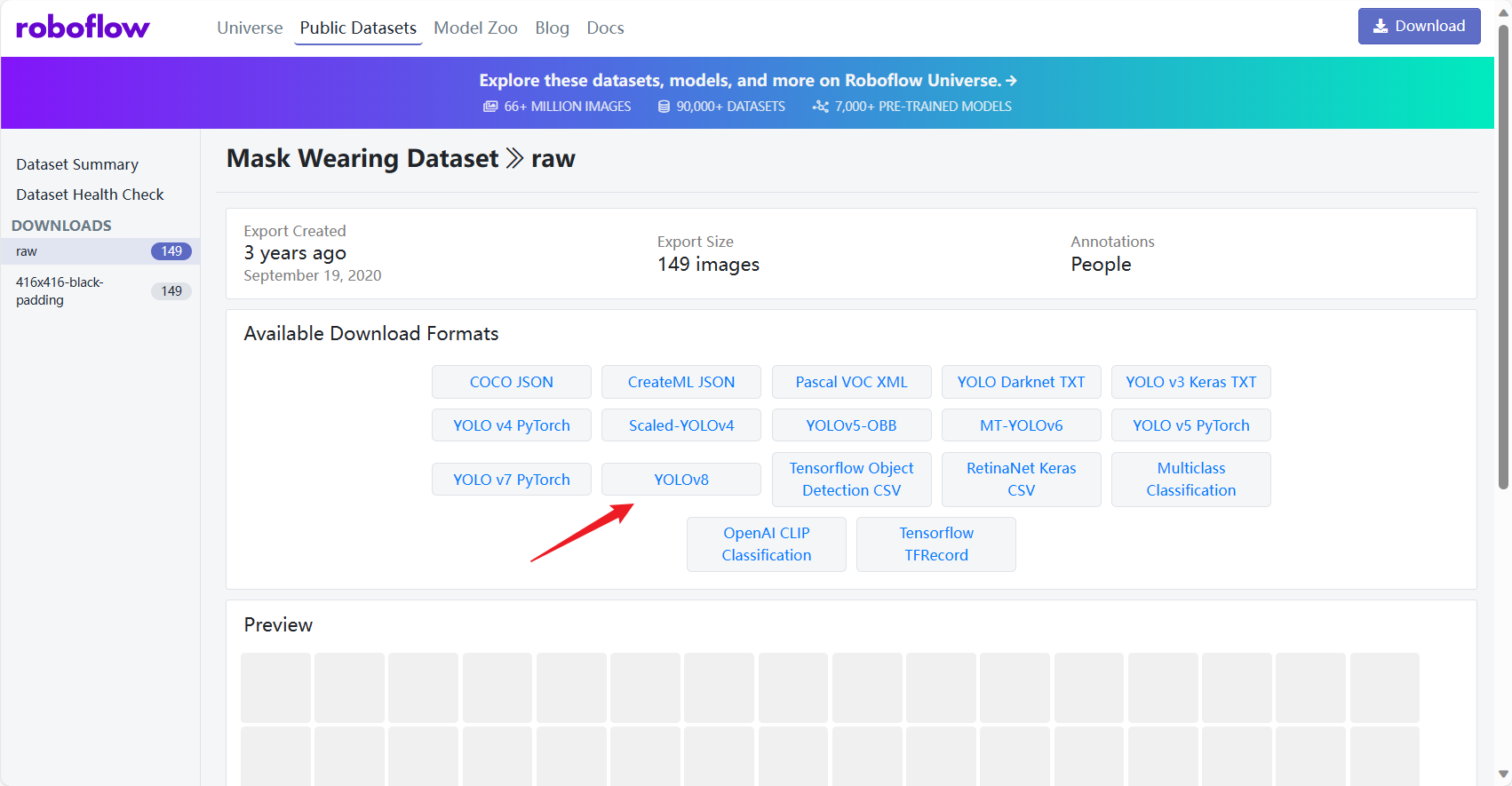
然后下载 zip 压缩包即可
配置数据集
上传到项目根目录的 datasets,并重命名数据集为 MaskDataSet(本次演示直接使用下载的数据集,后面的部分步骤是针对自己制作数据集的要求)
data.yaml修改如下
path: ../datasets/MaskDataSet
train: ./train/images
val: ./valid/images
test: ./test/images
nc: 2
names: ['mask', 'no-mask']
roboflow:
workspace: joseph-nelson
project: mask-wearing
version: 4
license: Public Domain
url: https://universe.roboflow.com/joseph-nelson/mask-wearing/dataset/4划分数据集
我们需要将数据集按照指定比例划分(训练集:验证集:测试集=7:2:1)
【数据集划分脚本】:
标注数据集
安装 lableme,执行 pip install labelme,然后命令行输入 labelme即可进入图形化界面
但是注意:labelme 生成的标签是 json 文件的格式,后续需要转化成 txt 文件才能被 yolov 使用
这里说下两种标注工具 labelImg 和 labelme 的区别
labelimg 是一种矩形标注工具,常用于目标识别和目标检测,其标记数据输出为.xml和.txt
labelme 是一种多边形标注工具,可以准确的将轮廓标注出来,常用于分割,其标记输出格式为json
【数据集标注文件格式转换脚本】:
训练数据集
yolo train data=datasets/MaskDataSet/data.yaml model=yolov8n.pt epochs=10 lr0=0.01 batch=4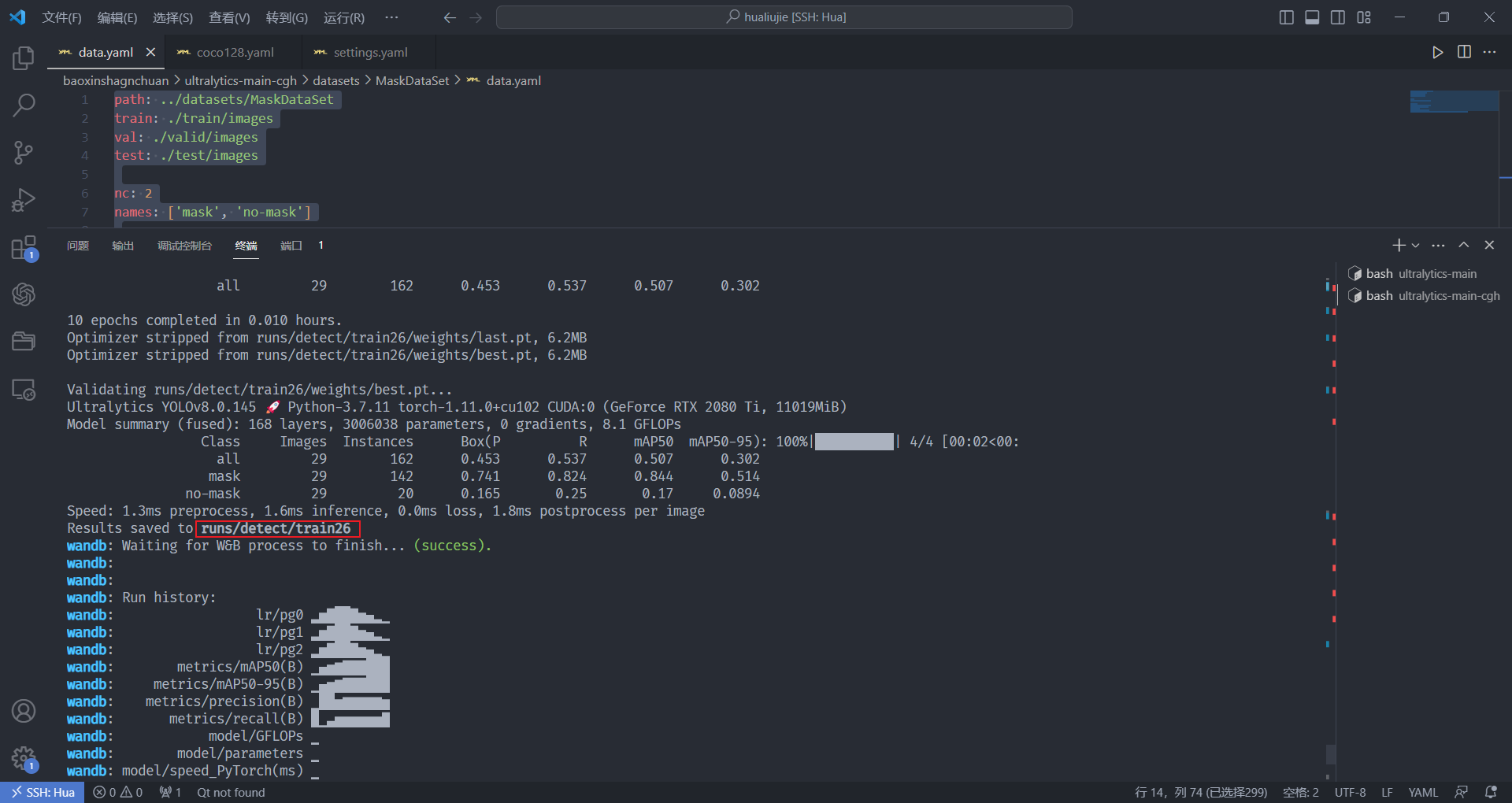
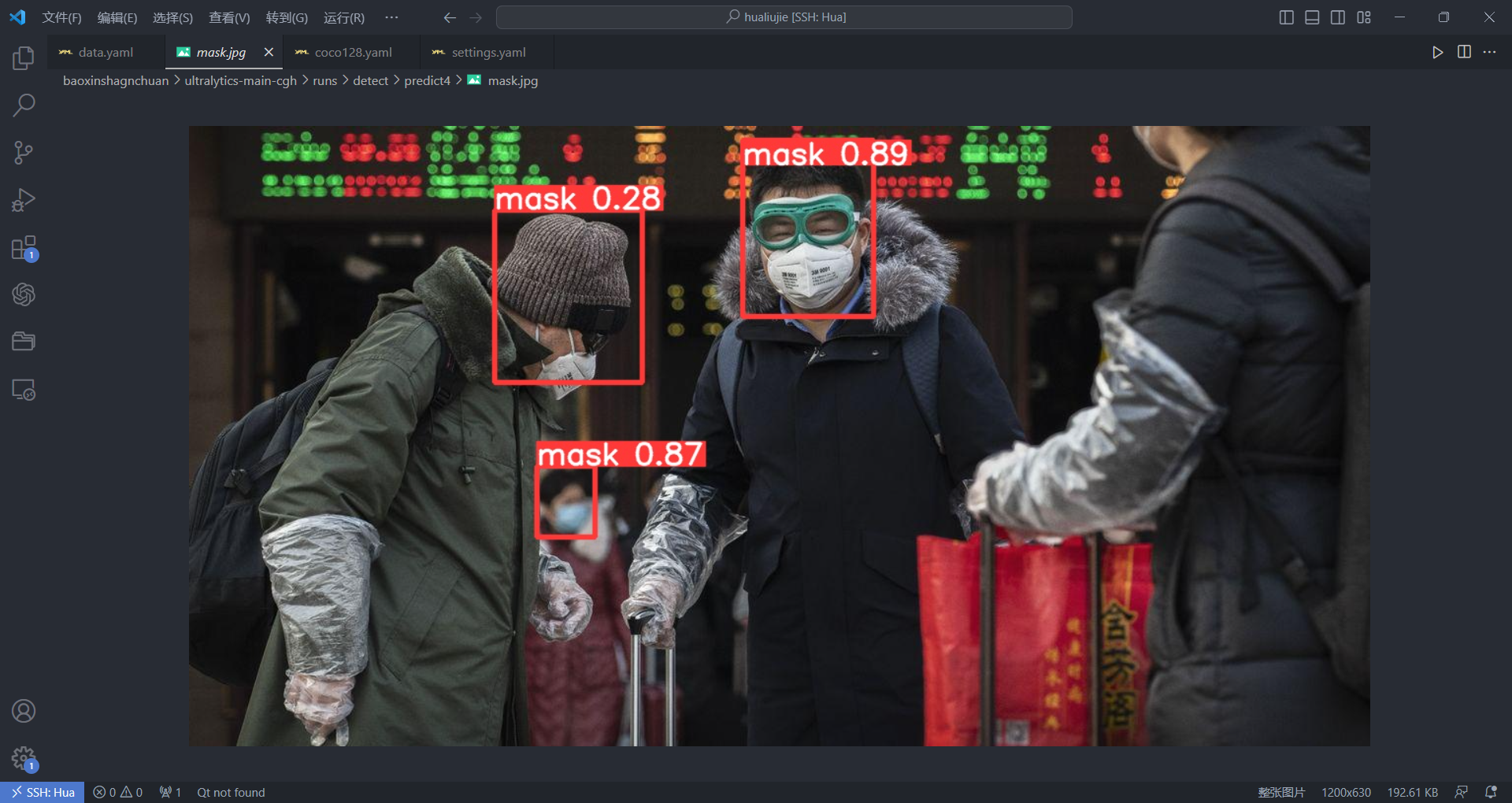
ultralytics/assets/mask.jpg口罩图片)
yolo predict model=runs/detect/train26/weights/best.pt source=ultralytics/assets/mask.jpg查看最终效果
参考文章

- 点赞
- 收藏
- 关注作者
评论(0)