如何使用PyTorch训练LLM

推荐:使用NSDT场景编辑器快速搭建3D应用场景
像LangChain这样的库促进了上述端到端AI应用程序的实现。我们的教程介绍 LangChain for Data Engineering & Data Applications 概述了您可以使用 Langchain 做什么,包括 LangChain 解决的问题,以及数据用例的示例。
本文将解释训练大型语言模型的所有过程,从设置工作区到使用 Pytorch 2.0.1 的最终实现,Pytorch <>.<>.<> 是一个动态且灵活的深度学习框架,允许简单明了的模型实现。
先决条件
为了充分利用这些内容,重要的是要熟悉 Python 编程,对深度学习概念和转换器有基本的了解,并熟悉 Pytorch 框架。完整的源代码将在GitHub上提供。
在深入研究核心实现之前,我们需要安装和导入相关库。此外,重要的是要注意,训练脚本的灵感来自 Hugging Face 中的这个存储库。
库安装
安装过程详述如下:
首先,我们使用语句在单个单元格中运行安装命令作为 Jupyter 笔记本中的 bash 命令。%%bash
- Trl:用于通过强化学习训练转换器语言模型。
- Peft使用参数高效微调(PEFT)方法来有效地适应预训练的模型。
- Torch:一个广泛使用的开源机器学习库。
- 数据集:用于帮助下载和加载许多常见的机器学习数据集。
变形金刚:由Hugging Face开发的库,带有数千个预训练模型,用于各种基于文本的任务,如分类,摘要和翻译。
现在,可以按如下方式导入这些模块:
数据加载和准备
羊驼数据集,在拥抱脸上免费提供,将用于此插图。数据集有三个主要列:指令、输入和输出。这些列组合在一起以生成最终文本列。
加载数据集的指令在下面通过提供感兴趣的数据集的名称给出,即:tatsu-lab/alpaca

我们可以看到,结果数据位于包含两个键的字典中:
- 特点:包含主列数据
- Num_rows:对应于数据中的总行数

train_dataset的结构
可以使用以下说明显示前五行。首先,将字典转换为熊猫数据帧,然后显示行。


train_dataset的前五行
为了获得更好的可视化效果,让我们打印有关前三行的信息,但在此之前,我们需要安装库以将每行的最大字数设置为 50。第一个 print 语句用 15 个短划线分隔每个块。textwrap


前三行的详细信息
模型训练
在继续训练模型之前,我们需要设置一些先决条件:
- 预训练模型:我们将使用预训练模型Salesforce/xgen-7b-8k-base,该模型可在Hugging Face上使用。Salesforce 训练了这一系列名为 XGen-7B 的 7B LLM,对高达 8K 的序列进行了标准的密集关注,最多可获得 1.5T 代币。
- 分词器: 这是训练数据上的标记化任务所必需的。加载预训练模型和分词器的代码如下:
pretrained_model_name = "Salesforce/xgen-7b-8k-base"
model = AutoModelForCausalLM.from_pretrained(pretrained_model_name, torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name, trust_remote_code=True)
训练配置
训练需要一些训练参数和配置,下面定义了两个重要的配置对象,一个是 TrainingArguments 的实例,一个是 LoraConfig 模型的实例,最后是 SFTTrainer 模型。
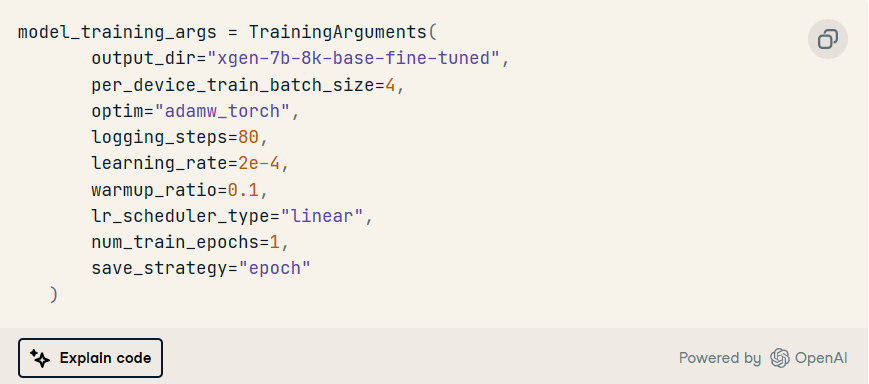
训练参数
这用于定义模型训练的参数。
在此特定场景中,我们首先使用属性定义存储训练模型的目标,然后再定义其他超参数,例如优化方法、优化方法、、 等。output_dirlearning ratenumber of epochs
洛拉康菲格
用于此方案的主要参数是 LoRA 中低秩转换矩阵的秩, 设置为 16.然后, LoRA 中其他参数的比例因子设置为 32.
此外,辍学比率为 0.05,这意味着在训练期间将忽略 5% 的输入单元。最后,由于我们正在处理一个普通语言建模,因此该任务使用属性进行初始化。CAUSAL_LM
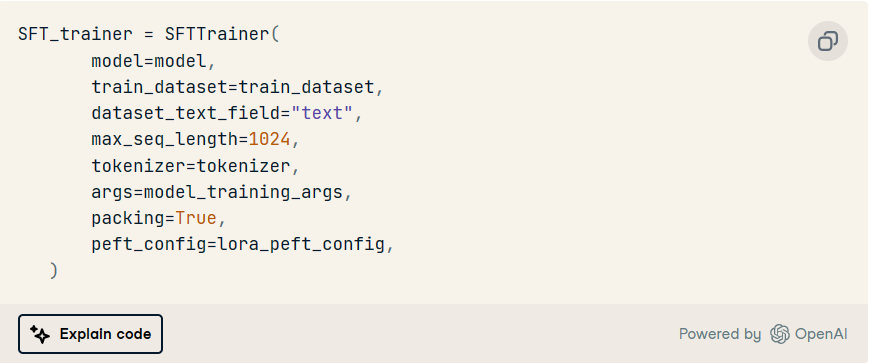
SFTTrainer
这旨在使用训练数据、分词器和附加信息(如上述模型)来训练模型。
由于我们使用训练数据中的文本字段,因此查看分布以帮助设置给定序列中的最大令牌数非常重要。
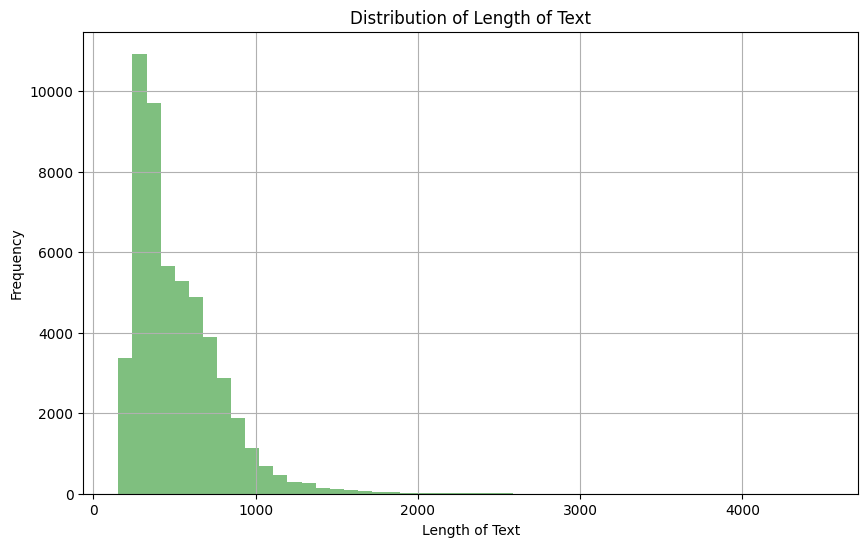
文本列长度的分布
基于上述观察,我们可以看到大多数文本的长度在 0 到 1000 之间。此外,我们可以在下面看到,只有 4.5% 的文本文档的长度大于 1024。
mask = pandas_format['text_length'] > 1024
percentage = (mask.sum() / pandas_format['text_length'].count()) * 100
print(f"The percentage of text documents with a length greater than 1024 is: {percentage}%")

然后,我们将序列中的最大标记数设置为 1024,以便任何比此长度的文本都被截断。
培训执行
满足所有先决条件后,我们现在可以按如下方式运行模型的训练过程:

值得一提的是,此培训是在具有GPU的云环境中进行的,这使得整个培训过程更快。但是,在本地计算机上进行培训需要更多时间才能完成。
我们的博客,在云中使用LLM与在本地运行LLM的优缺点,提供了为LLM选择最佳部署策略的关键考虑因素
让我们了解上面的代码片段中发生了什么:
- tokenizer.pad_token = tokenizer.eos_token:将填充标记设置为与句尾标记相同。
- model.resize_token_embeddings(len(tokenizer)):调整模型的标记嵌入层的大小,以匹配分词器词汇表的长度。
- model = prepare_model_for_int8_training(model):准备模型以进行 INT8 精度的训练,可能执行量化。
- model = get_peft_model(model, lora_peft_config):根据 PEFT 配置调整给定的模型。
- training_args = model_training_args:将预定义的训练参数分配给training_args。
- trainer = SFT_trainer:将 SFTTrainer 实例分配给变量训练器。
- trainer.train():根据提供的规范触发模型的训练过程。
结论
本文提供了使用 PyTorch 训练大型语言模型的明确指南。从数据集准备开始,它演练了准备先决条件、设置训练器以及最后运行训练过程的步骤。
尽管它使用了特定的数据集和预先训练的模型,但对于任何其他兼容选项,该过程应该大致相同。现在您已经了解如何训练LLM,您可以利用这些知识为各种NLP任务训练其他复杂的模型。

- 点赞
- 收藏
- 关注作者
评论(0)