在小藤上实现WeNet自动语音识别

【摘要】 在小藤上实现WeNet自动语音识别
登录开发板:
cd ${HOME}/ascend_community_projects/SpeechRecognition
获取onnx模型文件:
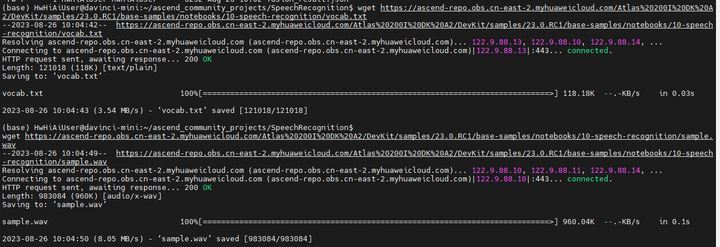
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Atlas%20200I%20DK%20A2/DevKit/samples/23.0.RC1/base-samples/notebook-demo-datasets/10-speech-recognition/offline_encoder_sim.onnx

onnx模型转为om模型:
atc --model=offline_encoder_sim.onnx --framework=5 --output=offline_encoder --input_format=ND --input_shape="speech:1,1478,80;speech_lengths:1" --log=error --soc_version=Ascend310B1

报了一个waring,但是om文件也生成了:

获取配置文件:
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Atlas%20200I%20DK%20A2/DevKit/samples/23.0.RC1/base-samples/notebooks/10-speech-recognition/vocab.txt
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Atlas%20200I%20DK%20A2/DevKit/samples/23.0.RC1/base-samples/notebooks/10-speech-recognition/sample.wav
运行推理:
python main.py
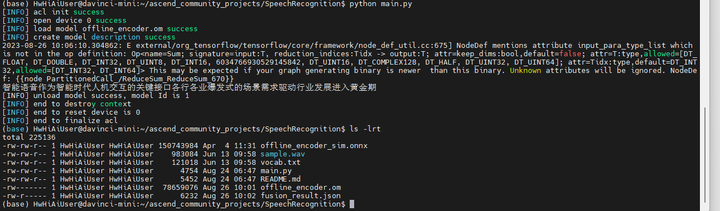
解析出来是这个:
智能语音作为智能时代人机交互的关键接口各行各业爆发式的场景需求驱动行业发展进入黄金期
好像解析得没问题。
我们再使用 windows自带的录音机录一段文字:据中央气象台消息,今年第十号台风达维在西北太平洋阳面上生成,气象局预计,达维将以每小时25到30公里的速度向东北方向移动。强度变化不大。

然后使用格式工厂,将其转为wav文件:
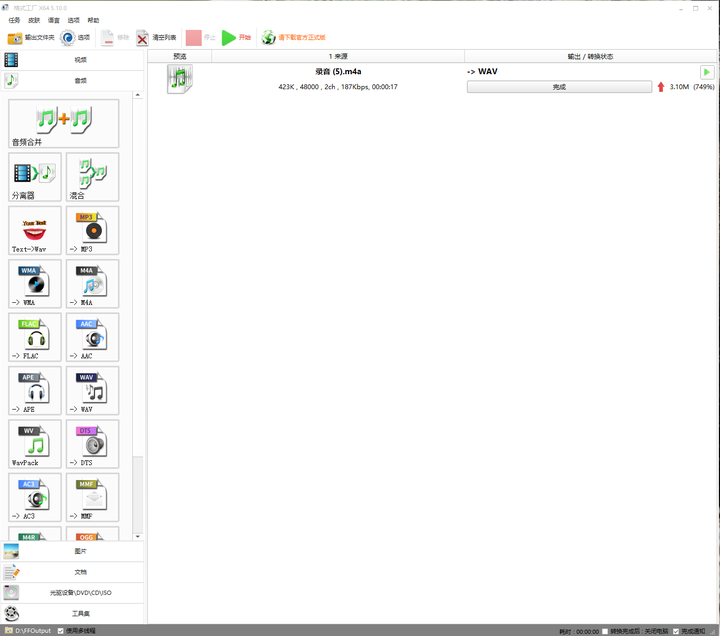
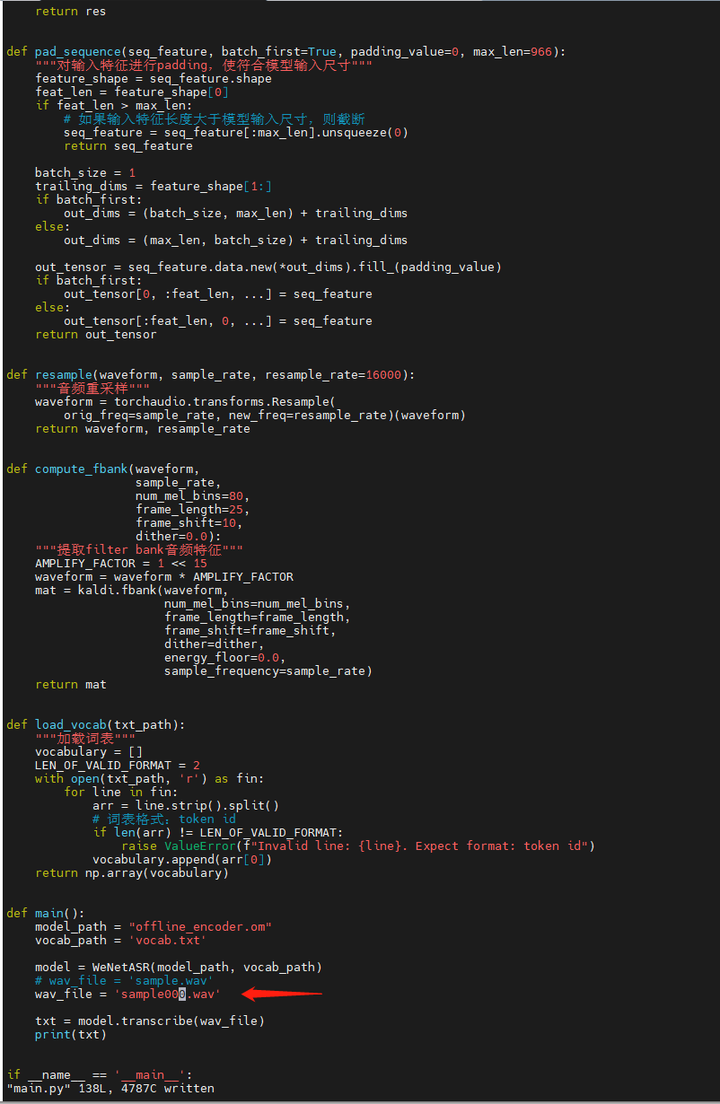
将其改名成sample000.wav,传到小藤的 SpeechRecognition 目录下。
修改main.py,将文件名改为sample000.wav
执行推理看看:
python main.py
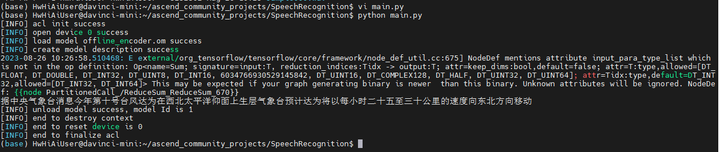
解析的结果如下:
据中央气象台消息 今年第十号台风达为在西北太平洋仰面上生层 气象台预计 达为将以每小时二十五至三十公里的速度向东北方向移动
据中央气象台消息,今年第十号台风达维在西北太平洋阳面上生成,气象局预计,达维将以每小时25到30公里的速度向东北方向移动。强度变化不大。
识别效果还不错。最后一句想必是超长了所以漏了。
(全文完,谢谢阅读)

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)