使用小藤实现手写汉字识别

【摘要】 使用小藤实现手写汉字识别
由于这里使用的是paddlepaddle,为了不干扰其他编译环境,笔者决定创建一个新的conda环境:
cd ~/ascend_community_projects/ChineseOCR
conda create -n chineseocr python=3.9
conda activate chineseocr
pip install paddle2onnx==0.9.5 -i https://pypi.tuna.tsinghua.edu.cn/simple

没有0.9.5版本。换成0.9.2试试:
pip install paddle2onnx==0.9.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
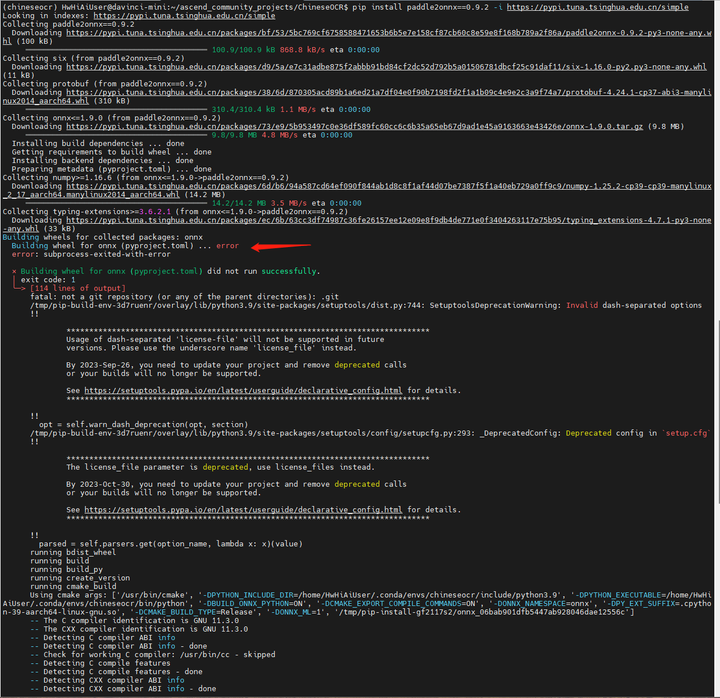
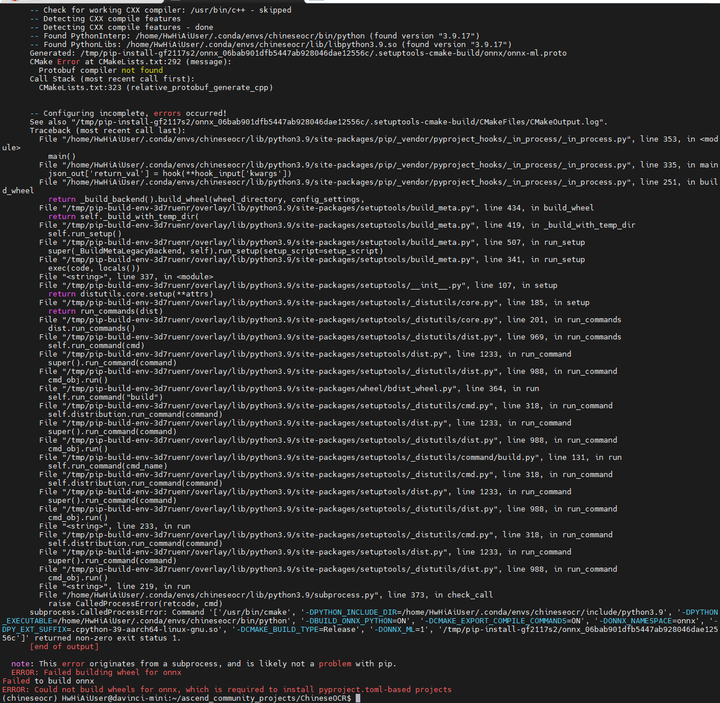
应该是新的pip环境少了什么包。
换成1.0.5试试:
pip install paddle2onnx==1.0.5 -i https://pypi.tuna.tsinghua.edu.cn/simple

貌似还是版本高的好一点。
pip install paddlepaddle==2.3.0 -i https://pypi.tuna.tsinghua.edu.cn/simple

咦,飞桨你下线了吗?
去飞桨官网看看是怎么回事:
打开
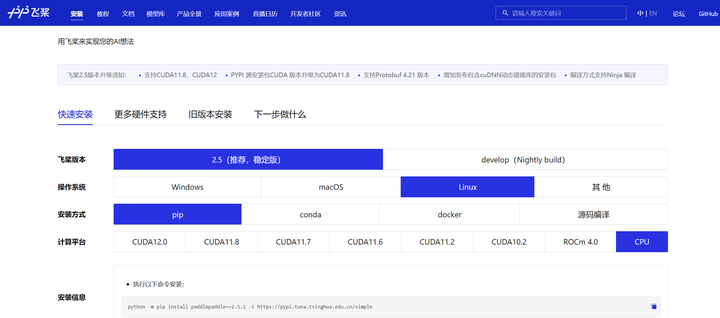
要装2.5.1版本:
python -m pip install paddlepaddle==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple

或者换成老版本:
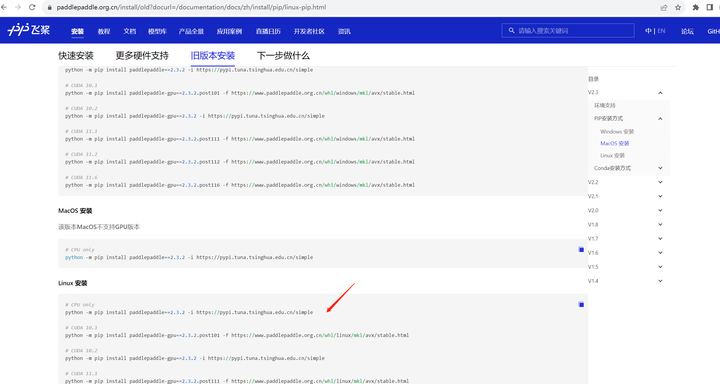
python -m pip install paddlepaddle==2.3.2 -i https://pypi.tuna.tsinghua.edu.cn/simple

只能说,飞桨貌似没有linux arm的安装包。
下载模型文件:
cd model
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar
解压:
tar xvf ch_ppocr_server_v2.0_rec_infer.tar
将paddlepaddle模型转为onnx模型:
paddle2onnx --model_dir ./ch_ppocr_server_v2.0_rec_infer/ --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./ch_ppocr_server_v2.0_rec_infer.onnx --opset_version 11 --enable_onnx_checker True

可以看到 ch_ppocr_server_v2.0_rec_infer.onnx 文件已生成。(貌似可以不用装paddlepaddle)

将onnx模型转为om离线模型
创建一个aipp.cfg文件,内容如下:
aipp_op{
related_input_rank: 0
crop: false
input_format: 3
aipp_mode: static
csc_switch: false
mean_chn_0: 0
mean_chn_1: 0
mean_chn_2: 0
min_chn_0: 127.5
min_chn_1: 127.5
min_chn_2: 127.5
var_reci_chn_0: 0.007843137718737125
var_reci_chn_1: 0.007843137718737125
var_reci_chn_2: 0.007843137718737125
}
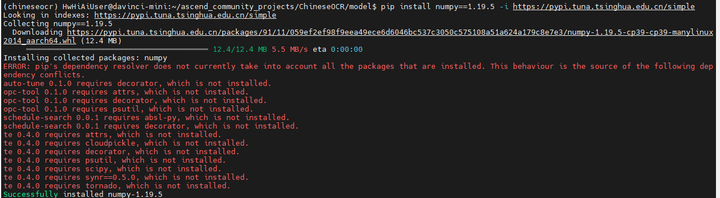
缺numpy:
pip install numpy==1.19.5 -i https://pypi.tuna.tsinghua.edu.cn/simple
再来:
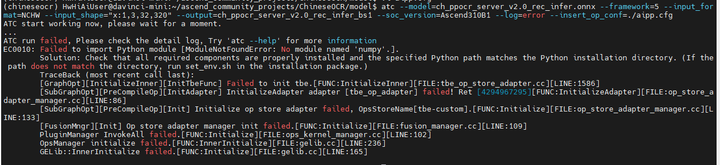
atc --model=ch_ppocr_server_v2.0_rec_infer.onnx --framework=5 --input_format=NCHW --input_shape="x:1,3,32,320" --output=ch_ppocr_server_v2.0_rec_infer_bs1 --soc_version=Ascend310B1 --log=error --insert_op_conf=./aipp.cfg
进入缺什么补什么的模式。。。
或者,conda环境切换回base环境,因为atc应该不需要paddlepaddle环境。(更何况paddlepaddle环境还没装起来)
conda deactivate
atc --model=ch_ppocr_server_v2.0_rec_infer.onnx --framework=5 --input_format=NCHW --input_shape="x:1,3,32,320" --output=ch_ppocr_server_v2.0_rec_infer_bs1 --soc_version=Ascend310B1 --log=error --insert_op_conf=./aipp.cfg

耐心等待模型转换结束:
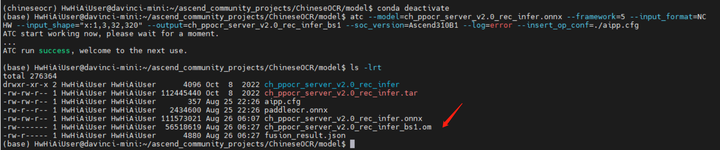
可见 ch_ppocr_server_v2.0_rec_infer_bs1.om 离线模型已生成。
下载手写汉字数据集
mkdir dataset
浏览器 下载 https://mindx.sdk.obs.cn-north-4.myhuaweicloud.com/ascend_community_projects/chineseOcr/6.rar
解压后传到A2的dataset目录:
执行推理:
cd ~/ascend_community_projects/ChineseOCR
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /home/HwHiAiUser/mxVision-5.0.RC2/set_env.sh

python main.py

pip install textdistance -i https://pypi.tuna.tsinghua.edu.cn/simple

再来:
python main.py



准确率如下:
the accuracy is: 0.41395649474331114
(base) HwHiAiUser@davinci-mini:~/ascend_community_projects/ChineseOCR$
(base) HwHiAiUser@davinci-mini:~/ascend_community_projects/ChineseOCR$
差错率大不大呢?
看看原文:
(base) HwHiAiUser@davinci-mini:~/ascend_community_projects/ChineseOCR/dataset$ cat *.txt

我们只看最后一段:
原文:来了个一百八十度的大转弯,又把两条后腿 往上一掀, 把我倒扔下来了, 左脚还塞在马蹬里呢。这匹讨厌的马! 它踢着, 鼻子大声打着呼呼, 拉着我拼命朝山坡上跑。
译文:来了个一百八十度码大传弯 把两务后同息往上一折,把我低扔下来了,左陆区墨在马隆里呢。这匹讨妥的马!也陽着,算子大声打着呼呼,拉着我拼命朝山坡上跑
错别字还是蛮多的。感觉这种机翻还不如人翻了。。。
(全文完,谢谢阅读)

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)