如何实现AI的矢量数据库

推荐:使用NSDT场景编辑器助你快速搭建3D应用场景

然而,人工智能模型有点像美食厨师。他们可以创造奇迹,但他们需要优质的成分。人工智能模型在大多数输入上都做得很好,但如果它们以最优化的格式接收输入,它们就会真正发光。这就是矢量数据库的重点。
在本文的过程中,我们将深入探讨什么是矢量数据库,为什么它们在人工智能世界中变得越来越重要,然后我们将查看实现矢量数据库的分步指南。
跳跃前进:
- 什么是矢量数据库?
- 为什么需要矢量数据库?
- 实现矢量数据库:分步指南
- 先决条件
- 设置Weaviate项目
- 创建我们的节点.js项目
- 设置我们的矢量数据库
- 设置客户端
- 迁移数据
- 添加文档
- 删除文档
- 向数据库添加查询函数
- 结合向量嵌入和 AI
- 人工智能模型设置
- 查询我们的数据
- 测试我们的查询
什么是矢量数据库?
在我们开始探索矢量数据库之前,了解在编程和机器学习的上下文中什么是矢量非常重要。
在编程中,向量本质上是一个一维数字数组。如果您曾经编写过涉及 3D 图形或机器学习算法的代码,那么您很可能使用过向量。
const vector4_example = [0.5, 1.5, 6.0, 3.4]
它们只是数字数组,通常是浮点数,我们用它们的维度来指代。例如,a 是浮点数的三元素数组,a 是浮点数的四元素数组。就这么简单!vector3vector4
但向量不仅仅是数字数组。在机器学习的背景下,向量在高维空间中表示和操作数据方面发挥着关键作用。这使我们能够执行驱动AI模型的复杂操作和计算。
现在我们已经掌握了向量,让我们把注意力转向向量数据库。
乍一看,你可能会想,“嘿,既然向量只是数字数组,我们不能使用常规数据库来存储它们吗?好吧,从技术上讲,你可以。但这就是事情变得有趣的地方。
矢量数据库是一种特殊类型的数据库,针对存储和执行对大量矢量数据的操作进行了优化。因此,虽然您的常规数据库确实可以存储数组,但矢量数据库更进一步,提供了专门的工具和操作来处理矢量。
在下一节中,我们将讨论为什么矢量数据库是必要的,以及它们带来的优势。所以坚持下去,因为事情会变得更加有趣!
为什么需要矢量数据库?
现在我们已经对什么是矢量数据库有了深入的了解,让我们深入了解为什么它们在人工智能和机器学习领域如此必要。
这里的关键词是性能。矢量数据库通常每次查询处理数亿个向量,这种性能比传统数据库在处理向量时能够达到的性能要快得多。
那么,是什么让矢量数据库如此快速高效呢?让我们来看看使它们与众不同的一些关键功能。
复杂的数学运算
向量数据库旨在对向量执行复杂的数学运算,例如过滤和定位“附近”向量。这些操作在机器学习环境中至关重要,其中模型通常需要在高维空间中找到彼此接近的向量。
例如,一种常见的数据分析技术余弦相似性通常用于测量两个向量的相似程度。矢量数据库擅长这些类型的计算。
专用矢量索引
与组织良好的库一样,数据库需要一个良好的索引系统来快速检索请求的数据。矢量数据库提供专门的矢量索引,与传统数据库相比,检索数据的速度更快、更确定(与随机数据库相反)。
借助这些索引,向量数据库可以快速定位 AI 模型所需的向量并快速生成结果。
紧凑的存储
在大数据的世界里,存储空间是一种宝贵的商品。矢量数据库在这里也大放异彩,以使其更紧凑的方式存储矢量。压缩和量化向量等技术用于在内存中保留尽可能多的数据,从而进一步减少负载和查询延迟。
分片
在处理大量数据时,将数据分布在多台机器上可能是有益的,这个过程称为分片。许多数据库都可以执行此操作,但 SQL 数据库尤其需要付出更多努力才能横向扩展。另一方面,矢量数据库通常在其架构中内置分片,使它们能够轻松处理大量数据。
简而言之,虽然传统数据库可以存储和对向量执行操作,但它们并未针对任务进行优化。另一方面,矢量数据库正是为此目的而构建的。它们提供了处理大量矢量数据所需的速度、效率和专用工具,使其成为人工智能和机器学习领域必不可少的工具。
在下一节中,我们将向量数据库与其他类型的数据库进行比较,并解释它们如何适应更大的数据库生态系统。我们才刚刚开始!
实现矢量数据库:分步指南
出于本指南的目的,我们将使用 Weaviate(一种流行的矢量数据库服务)来实现一个简单的矢量数据库,您可以基于该数据库为任何用例进行构建。
您可以在此处克隆初学者模板并运行以进行设置。npm install
先决条件
- 先前的JS知识将有所帮助:本教程中编写的所有代码都将使用JavaScript,我们也将使用Weaviate JavaScript SDK。
- Node 和 npm:我们将在服务器上的 JavaScript 环境中工作。
- OpenAI API密钥:我们将使用他们的嵌入模型将我们的数据转换为嵌入以存储在我们的数据库中
- Weaviate帐户:我们将使用他们的托管数据库服务;您可以在此处获得免费帐户
设置Weaviate项目
创建帐户后,您需要通过Weaviate仪表板设置项目。转到 WCS 控制台,然后单击创建集群:

选择“免费沙盒”层并提供群集名称。当它要求您启用身份验证时,请选择“是”:
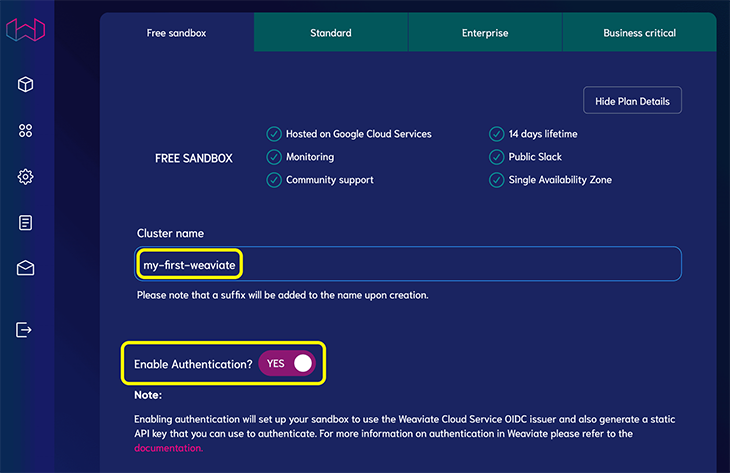
单击创建。几分钟后,您应该会在完成后看到一个复选标记。
单击“详细信息”以查看群集详细信息,因为我们将在下一部分用到它们。其中包括:
- 一个编织的网址
- 身份验证详细信息(Weaviate API 密钥;单击密钥图标以显示)
创建我们的节点.js项目
有了先决条件,我们可以创建向量数据库并查询它。要继续操作,您需要一个新的 Node 项目;您可以在此处克隆 GitHub 上的模板,其中包括入门所需的一切。
或者,您可以通过运行以下命令创建一个:
mkdir weaviate-vector-database && cd weaviate-vector-database
npm init -y && npm install dotenv openai weaviate-ts-client
mkdir src
编辑文件并添加脚本,如下所示:package.jsonstart
// ...rest of package.json
"scripts": {
"start": "node src/index.js"
},
// ...rest of package.json
创建一个文件来存储敏感信息,如 API 密钥。编写命令并在代码编辑器中打开新创建的文件,然后粘贴以下内容并确保将占位符替换为实际值:.envtouch .env.env
// .env
OPENAI_KEY="<OPENAI_API_KEY>"
WEAVIATE_API_KEY="<WEAVIATE_API_KEY>"
WEAVIATE_URL="<WEAVIATE_URL>"
DATA_CLASSNAME="Document"
设置我们的矢量数据库
项目设置完成后,我们可以添加一些代码来设置和使用我们的矢量数据库。让我们快速总结一下我们将要实现的内容:
- 帮助程序函数,它:
- 连接到我们的数据库
- 批量矢量化和上传文档
- 查询最相似的项目
- 一个 main 函数,它使用上面的辅助函数一次性上传文档和查询数据库
设置客户端
话虽如此,让我们创建第一个文件来存储数据库连接和帮助程序函数。通过运行创建一个新文件,让我们开始填写它:touch src/database.js
// src/database.js
import weaviate, { ApiKey } from "weaviate-ts-client";
import { config } from "dotenv";
config();
async function setupClient() {
let client;
try {
client = weaviate.client({
scheme: "https",
host: process.env.WEAVIATE_URL,
apiKey: new ApiKey(process.env.WEAVIATE_API_KEY),
headers: { "X-OpenAI-Api-Key": process.env.OPENAI_API_KEY },
});
} catch (err) {
console.error("error >>>", err.message);
}
return client;
}
// ... code continues below
让我们分解一下这里发生的事情。首先,我们导入必要的软件包,Weaviate客户端和dotenv配置。dotenv 是一个将环境变量从文件加载到 .Weaviate和OpenAI密钥和URL通常存储在环境变量中,以保持机密性并远离代码库。.envprocess.env
以下是函数中发生的情况:setupClient()
- 我们初始化了一个变量
client - 我们有一个块,用于设置与 Weaviate 服务器的连接。如果在此过程中发生任何错误,我们会将错误消息打印到控制台
try…catch
- 在块内,我们使用该方法创建一个新的 Weaviate 客户端。、 和 参数取自我们设置的环境变量
tryweaviate.client()schemehostapiKey
- 最后,我们传入OpenAI的标头,因为我们将使用OpenAI的Ada模型来矢量化我们的数据。
迁移数据
设置客户端后,让我们使用一些虚拟数据、虚构生物、地点和事件的集合来运行迁移。稍后,我们将针对此数据查询 GPT-3。
如果您没有克隆初学者模板,请按照以下步骤操作:
- 通过运行创建新文件
touch src/data.js - 从此处复制文件的内容并将其粘贴到
花一些时间浏览 中的数据。然后,在文件顶部添加新导入:src/data.jssrc/database.js
// ...other imports
import { FAKE_XORDIA_HISTORY } from "./data";
在函数下方,添加一个新函数,如下所示:setupClient
async function migrate(shouldDeleteAllDocuments = false) {
try {
const classObj = {
class: process.env.DATA_CLASSNAME,
vectorizer: "text2vec-openai",
moduleConfig: {
"text2vec-openai": {
model: "ada",
modelVersion: "002",
type: "text",
},
},
};
const client = await setupClient();
try {
const schema = await client.schema
.classCreator()
.withClass(classObj)
.do();
console.info("created schema >>>", schema);
} catch (err) {
console.error("schema already exists");
}
if (!FAKE_XORDIA_HISTORY.length) {
console.error(`Data is empty`);
process.exit(1);
}
if (shouldDeleteAllDocuments) {
console.info(`Deleting all documents`);
await deleteAllDocuments();
}
console.info(`Inserting documents`);
await addDocuments(FAKE_XORDIA_HISTORY);
} catch (err) {
console.error("error >>>", err.message);
}
}
再一次,让我们分解一下这里发生的事情。
该函数接受单个参数,该参数确定在迁移数据时是否清除数据库。migrateshouldDeleteAllDocuments
在我们的块中,我们创建一个名为 .此对象表示 Weaviate 中类的架构(确保在文件中添加 a),该类使用矢量化器。这决定了文本文档在数据库中的配置和表示方式,并告诉Weaviate使用OpenAI的“ada”模型对我们的数据进行矢量化。try…catchclassObjCLASS_NAME.envtext2vec-openai
然后,我们使用方法链创建模式。这会向 Weaviate 服务器发送请求,以创建 中定义的文档类。成功创建架构后,我们将模式对象记录到控制台,并显示消息 .现在,错误通过记录到控制台的简单消息进行处理。client.schema.classCreator().withClass(classObj).do()classObjcreated schema >>>
我们可以检查要迁移的虚拟数据的长度。如果为空,则代码在此处结束。我们可以使用函数(稍后会添加)清除数据库,如果 是 .deleteAllDocumentsshouldDeleteAllDocumentstrue
最后,使用一个函数(我们接下来将添加),我们上传所有要矢量化并存储在 Weaviate 中的条目。addDocuments
添加文档
我们可以继续矢量化和上传我们的文本文档。这实际上是一个两步过程,其中:
- 原始文本字符串使用 OpenAI Ada 模型转换为矢量
- 转换后的载体将上传到我们的 Weaviate 数据库
值得庆幸的是,这些是由我们使用的Weaviate SDK自动处理的。让我们继续创建函数来执行此操作。打开同一文件并粘贴以下内容:src/database.js
// code continues from above
const addDocuments = async (data = []) => {
const client = await setupClient();
let batcher = client.batch.objectsBatcher();
let counter = 0;
const batchSize = 100;
for (const document of data) {
const obj = {
class: process.env.DATA_CLASSNAME,
properties: { ...document },
};
batcher = batcher.withObject(obj);
if (counter++ == batchSize) {
await batcher.do();
counter = 0;
batcher = client.batch.objectsBatcher();
}
}
const res = await batcher.do();
return res;
};
// ... code continues below
和以前一样,让我们分解一下这里发生的事情。
- 首先,我们调用前面定义的函数来设置并获取 Weaviate 客户端实例
setupClient() - 我们使用初始化一个批处理器,用于收集文档并一次性将它们上传到Weaviate,使过程更高效
client.batch.objectsBatcher() - 我们还定义了一个计数器变量和一个变量,并将其设置为 100。计数器跟踪已添加到当前批次的文档数,并定义每个批次中应包含的文档数
batchSizebatchSize - 然后,我们遍历数据数组中的每个文档:
- 对于每个文档,我们创建一个对象,该对象以Weaviate期望的格式表示文档,以便可以将其扩展到该对象的属性中
- 然后,我们使用
batcher.withObject(obj) - 如果计数器等于批大小(意味着批已满),我们将批上传到 Weaviate,将计数器重置为 ,并为下一批文档创建一个新的批处理器
batcher.do()0
处理完所有文档并将其添加到批处理后,如果还有剩余的批处理尚未上载(因为它未到达 ),则可以使用 上载剩余的批处理。batchSizebatcher.do()
此处的最后一步发生在函数返回上次调用的响应时。此响应将包含有关上传的详细信息,例如上传是否成功以及发生的任何错误。batcher.do()
从本质上讲,该函数通过将大量文档分组为可管理的批次来帮助我们有效地将大量文档上传到我们的 Weaviate 实例。addDocuments()
删除文档
让我们添加函数中使用的代码。在函数下方,添加以下代码:deleteAllDocumentsmigrateaddDocuments
// code continues from above
async function deleteAllDocuments() {
const client = await setupClient();
const documents = await client.graphql
.get()
.withClassName(process.env.DATA_CLASSNAME)
.withFields("_additional { id }")
.do();
for (const document of documents.data.Get[process.env.DATA_CLASSNAME]) {
await client.data
.deleter()
.withClassName(process.env.DATA_CLASSNAME)
.withId(document._additional.id)
.do();
}
}
// ... code continues below
这个函数相对简单。
- 我们使用类名为
setupClientidDocument - 然后使用循环,我们使用其删除每个文档
for...ofid
这种方法之所以有效,是因为我们拥有少量数据。对于较大的数据库,需要一种技术来删除所有文档,因为每个请求的限制是一次只有 200 个条目。batching
向数据库添加查询函数
现在我们有了将数据上传到数据库的方法,让我们添加一个函数来查询数据库。在本例中,我们将执行“最近邻搜索”以查找与我们的查询相似的文档。
在同一文件中,添加以下内容:src/database.js
// code continues from above
async function nearTextQuery({
concepts = [""],
fields = "text category",
limit = 1,
}) {
const client = await setupClient();
const res = await client.graphql
.get()
.withClassName("Document")
.withFields(fields)
.withNearText({ concepts })
.withLimit(limit)
.do();
return res.data.Get[process.env.DATA_CLASSNAME];
}
export { migrate, addDocuments, deleteAllDocuments, nearTextQuery };
同样,让我们对这里发生的事情进行细分:
nearTextQuery()是一个接受对象作为参数的异步函数。此对象可以包含三个属性:
概念:表示我们正在搜索的术语的字符串数组- 字段:一个字符串,表示我们希望在搜索结果中返回的
字段。在本例中,我们从 和 字段请求textcategory 限制:我们希望从搜索查询中返回的最大结果数
- 我们调用函数来获取 Weaviate 客户端实例
setupClient() - 我们使用一系列方法构建 GraphQL 查询:
client.graphql.get():初始化 GraphQL 查询.withClassName("Document"):我们指定要在“文档”对象中搜索.withFields(fields):我们指定要在结果中返回哪些字段.withNearText({ concepts }):这就是魔术发生的地方!我们指定了 Weaviate 将用于搜索语义相似的文档的概念.withLimit(limit):我们指定要返回的最大结果数- 最后,执行查询
.do()
- 来自查询的响应存储在变量中,然后在下一行返回
res - 最后,我们导出此处定义的所有函数以在其他地方使用
简而言之,该函数帮助我们根据提供的术语在 Weaviate 实例中搜索语义相似的文档。nearTextQuery()
让我们迁移数据,以便在下一节中查询它。打开终端并运行 。npm run start"migrate"
结合向量嵌入和 AI
像 GPT-3 和 ChatGPT 这样的大型语言模型旨在处理输入并生成有用的输出,这是一项需要了解单词和短语之间复杂含义和关系的任务。
他们通过将单词、句子甚至整个文档表示为高维向量来做到这一点。通过分析这些向量之间的异同,人工智能模型可以理解我们语言中的上下文、语义甚至细微差别。
那么,矢量数据库从何而来?让我们将矢量数据库视为 AI 模型的图书馆员。在庞大的书籍库(或者,在我们的例子中,向量)中,人工智能模型需要快速找到与特定查询最相关的书籍。矢量数据库通过有效地存储这些“书籍”并在需要时提供快速精确的检索来实现这一点。
这对于许多AI应用程序至关重要。例如,在聊天机器人应用程序中,AI 模型需要找到对用户问题最相关的响应。它通过将用户的问题和潜在响应转换为向量,然后使用向量数据库查找与用户问题最相似的响应来实现这一点。
考虑到这一点,我们将使用上面的数据库来提供一个 AI 模型 GPT-3.5,其中包含我们自己数据的上下文。这将允许模型回答有关未训练的数据的问题。
人工智能模型设置
通过运行并粘贴以下内容来创建新文件:touch src/data.js
import { Configuration, OpenAIApi } from "openai";
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
async function getChatCompletion({ prompt, context }) {
const chatCompletion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{
role: "system",
content: You are a knowledgebase oracle. You are given a question and a context. You answer the question based on the context. Analyse the information from the context and draw fundamental insights to accurately answer the question to the best of your ability. Context: ${context} ,
},
{ role: "user", content: prompt },
],
});
return chatCompletion.data.choices[0].message;
}
export { getChatCompletion };
像往常一样,让我们分解一下文件:
- 我们从包中导入一些必需的模块并初始化一个实例
openaiopenai - 我们定义了一个函数,该函数接受提示、一些上下文,并将 GPT-3.5 模型配置为作为知识库预言机进行响应
getChatCompletion - 最后,我们返回响应并导出函数
查询我们的数据
通过设置我们的矢量数据库和 AI 模型,我们最终可以通过结合这两个系统来查询我们的数据。利用嵌入的强大效果和 GPT-3.5 令人印象深刻的自然语言功能,我们将能够以更具表现力和可定制的方式与我们的数据进行交互。
首先创建一个新文件并运行 .然后粘贴以下内容:touch src/index.js
import { config } from "dotenv";
import { nearTextQuery } from "./database.js";
import { getChatCompletion } from "./model.js";
config();
const queryDatabase = async (prompt) => {
console.info(Querying database);
const questionContext = await nearTextQuery({
concepts: [prompt],
fields: "title text date",
limit: 50,
});
const context = questionContext
.map((context, index) => {
const { title, text, date } = context;
return Document ${index + 1} Date: ${date} Title: ${title} ${text} ;
})
.join("\n\n");
const aiResponse = await getChatCompletion({ prompt, context });
return aiResponse.content;
};
const main = async () => {
const command = process.argv[2];
const params = process.argv[3];
switch (command) {
case "migrate":
return await migrate(params === "--delete-all");
case "query":
return console.log(await queryDatabase(params));
default:
// do nothing
break;
}
};
main();
在此文件中,我们将到目前为止所做的所有工作汇集在一起,以允许我们通过命令行查询数据。像往常一样,让我们探讨一下这里发生了什么:
- 首先,我们导入必要的模块并使用包设置我们的环境变量
dotenv - 接下来,我们创建一个接受文本提示的函数,我们使用它对向量数据库执行“近文本”查询。我们将结果限制为 50 个,并且我们特别要求提供匹配概念的“标题”、“文本”和“日期”字段
queryDatabase - 这基本上返回了语义上类似于我们搜索查询中的任何重要术语的文档(嵌入功能强大!
- 然后,我们映射接收到的上下文,对其进行格式化,并将其传递给AI模型以生成完成。使用上下文,GPT-3.5 的自然语言处理 (NLP) 功能大放异彩,因为它能够根据我们的数据生成更准确和有意义的响应
- 最后,我们到达函数。在这里,我们使用命令行参数来执行各种任务。如果我们通过,我们可以迁移我们的数据(带有可选标志,以防万一我们想清理我们的石板并重新开始),并且有了,我们可以测试我们的查询函数
mainmigrate--delete-allquery
测试我们的查询
祝贺。如果你走到了这一步,你应该得到拍拍——你终于可以测试你的代码了。
打开终端并运行以下命令:
npm run start "query" "what are the 3 most impressive achievements of humanity in the story?"
查询将发送到您的 Weaviate 矢量数据库,在那里它与其他类似矢量进行比较,并根据其文本返回 50 个最相似的矢量。然后,此上下文数据将被格式化并与您的查询一起发送到 OpenAI 的 GPT-3.5 模型,在那里对其进行处理并生成响应。
如果一切顺利,您应该得到与以下类似的响应:

随意探索这个虚构的世界,更多的查询,或者更好的是,带上自己的数据,亲眼目睹向量和嵌入的力量。
如果此时遇到任何错误,请在此处将您的代码与最终版本进行比较,并确保已创建并填写文件。.env
结论和今后的步骤
在本教程中,我们略微探索了矢量和矢量数据库的强大功能。使用Weaviate和GPT-3等工具,我们亲眼目睹了这些技术在塑造AI应用程序方面的潜力,从改进个性化聊天机器人到增强机器学习算法。请务必也看看我们的GitHub!
然而,这仅仅是个开始。如果您想了解有关使用矢量数据库的更多信息,请考虑:
- 深入了解高级概念,例如使用矢量元数据、分片、压缩,以实现更灵活、更高效的数据存储和检索
- 尝试更复杂的方法将向量嵌入集成到 AI 应用程序中,以获得更丰富、更细微的结果
感谢您坚持到最后,希望这是对您的时间的有效利用。
您是否正在添加新的 JS 库以提高性能或构建新功能?如果他们反其道而行之呢?
毫无疑问,前端变得越来越复杂。当您向应用添加新的 JavaScript 库和其他依赖项时,您将需要更高的可见性,以确保您的用户不会遇到未知问题。
LogRocket 是一个前端应用程序监控解决方案,可让您重播 JavaScript 错误,就好像它们发生在您自己的浏览器中一样,这样您就可以更有效地对错误做出反应。
LogRocket 可以完美地与任何应用程序配合使用,无论框架如何,并且具有用于记录来自 Redux、Vuex 和 @ngrx/store 的其他上下文的插件。无需猜测问题发生的原因,您可以汇总并报告问题发生时应用程序所处的状态。LogRocket 还会监控应用的性能,报告客户端 CPU 负载、客户端内存使用情况等指标。

- 点赞
- 收藏
- 关注作者
评论(0)