使用Apache IoTDB进行IoT相关开发的架构设计与功能实现(9)

降频聚合查询
本节主要介绍下频聚合查询的相关示例,使用分组依据子句,用于根据用户给定的分区条件对结果集进行分区,并聚合分区的结果集。IoTDB支持根据时间间隔和自定义滑动步长对结果集进行分区,不小于时间间隔,未设置则默认等于时间间隔。默认情况下,结果按时间升序排序。还可以使用Java JDBC用于执行相关查询的标准接口。
GROUP BY 语句为用户提供了三种类型的指定参数:
- 参数1:时间轴上的显示窗口
- 参数2:划分时间轴的时间间隔(应为正)
- 参数3:时间滑动步长(可选,不应小于时间间隔,如果未设置,则默认等于时间间隔)
这三类参数的实际含义如下图5.2所示。其中,参数 3 是可选的。接下来,我们将给出三个典型的降频聚合示例:未指定参数 3、指定参数 3 和指定值过滤条件。

图5.2 三类参数的实际含义
不指定滑动步长的降频聚合查询
SQL 语句为:
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00),1d);
这意味着:
由于用户未指定滑动步长,因此 GROUP BY 语句将默认将滑动步长设置为与时间间隔相同的时间间隔,即 。1d
上面 GROUP BY 语句的第一个参数是显示窗口参数,它决定了最终的显示范围是 [2017-11-01T00:00:00, 2017-11-07T23:00:00)。
上面 GROUP BY 语句的第二个参数是划分时间轴的时间间隔。将此参数(1d)作为时间间隔,显示窗口的开始时间作为划分原点,将时间轴划分为几个连续区间,分别是[0,1d),[1d,2d),[2d,3d)等。
然后系统将使用 WHERE 子句中的时间和值过滤条件和 GROUP BY 语句的第一个参数作为数据过滤条件,得到满足过滤条件的数据(本例中为 [2017-11-01T00:00:00, 2017-11-07 T23:00:00]范围内的数据),并将这些数据映射到之前分段的时间轴(本例中每 1 天有映射的数据)从2017-11-01T00:00:00到2017-11-07T23:00:00:00)。
由于结果范围内都有每个时间段的数据要显示,因此 SQL 语句的执行结果如下所示:
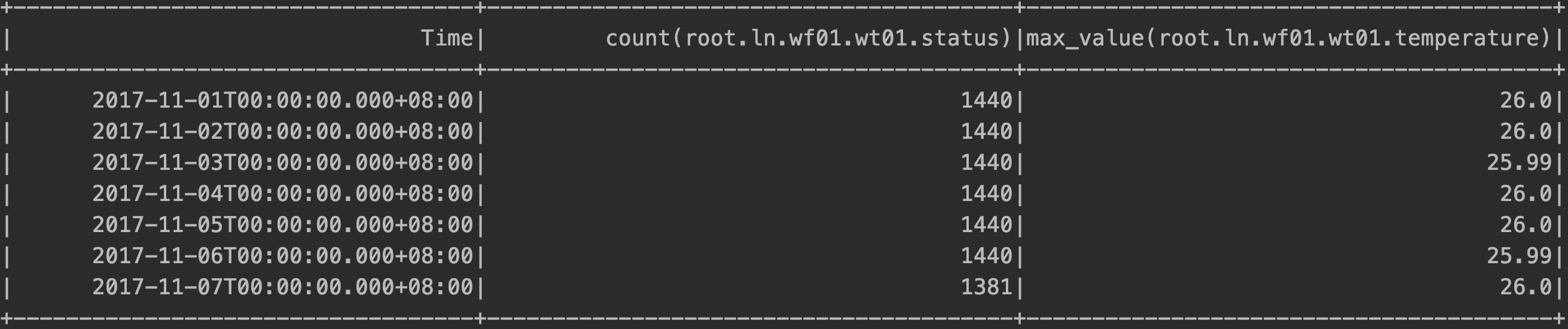
指定滑动步长的降频聚合查询
SQL 语句为:
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-07 23:00:00), 3h, 1d);
这意味着:
由于用户将滑动步长参数指定为 1d,因此 GROUP BY 语句将延长时间间隔,而不是默认。1 day3 hours
这意味着我们希望每天从 00-00-00 到 02-59-59 获取 2017:11:01 到 2017:11:07 的所有数据。
上面 GROUP BY 语句的第一个参数是显示窗口参数,它决定了最终的显示范围是 [2017-11-01T00:00:00, 2017-11-07T23:00:00)。
上面 GROUP BY 语句的第二个参数是划分时间轴的时间间隔。以此参数(3h)为时间间隔,以显示窗口的开始时间为划分原点,将时间轴划分为几个连续区间,分别是[2017-11-01T00:00:00、2017-11-01T03:00:00)、[2017-11-02T00:00:00、2017-11-02T03:00:00)、[2017-11-03T00:00:00、2017-11-03T03:00:00)等。
上面 GROUP BY 语句的第三个参数是每个时间间隔移动的滑动步长。
然后系统将使用 WHERE 子句中的时间和值过滤条件和 GROUP BY 语句的第一个参数作为数据过滤条件,得到满足过滤条件的数据(本例中为 [2017-11-01T00:00:00, 2017-11-07T23:00:00]范围内的数据),并将这些数据映射到之前分段的时间轴(本例中每 3 小时有映射的数据为每天从2017-11-01T00:00:00到2017-11-07T23:00:00:00)。
由于结果范围内都有每个时间段的数据要显示,因此 SQL 语句的执行结果如下所示:
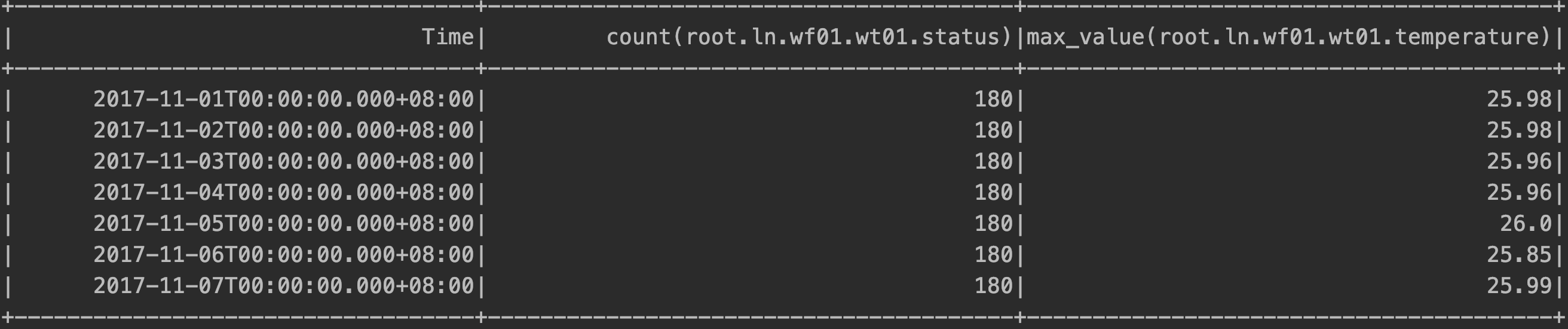
指定值的降频聚合查询 过滤条件
SQL 语句为:
select count(status), max_value(temperature) from root.ln.wf01.wt01 where time > 2017-11-01T01:00:00 and temperature > 20 group by([2017-11-01T00:00:00, 2017-11-07T23:00:00), 3h, 1d);
这意味着:
由于用户将滑动步长参数指定为 1d,因此 GROUP BY 语句将延长时间间隔,而不是默认。1 day3 hours
上面 GROUP BY 语句的第一个参数是显示窗口参数,它决定了最终的显示范围是 [2017-11-01T00:00:00, 2017-11-07T23:00:00)。
上面 GROUP BY 语句的第二个参数是划分时间轴的时间间隔。以此参数(3h)为时间间隔,以显示窗口的开始时间为划分原点,将时间轴划分为几个连续区间,分别是[2017-11-01T00:00:00、2017-11-01T03:00:00)、[2017-11-02T00:00:00、2017-11-02T03:00:00)、[2017-11-03T00:00:00、2017-11-03T03:00:00)等。
上面 GROUP BY 语句的第三个参数是每个时间间隔移动的滑动步长。
然后系统将使用 WHERE 子句中的时间和值过滤条件和 GROUP BY 语句的第一个参数作为数据过滤条件,得到满足过滤条件的数据(本例中为(2017-11-01T01:00:00,2017-11-07T23:00:00]且满足root.ln.wf01.wt01.温度>20)范围内的数据, 并将这些数据映射到之前分段的时间轴(在这种情况下,从 3-2017-11T01:00:00 到 00-2017-11T07:23:00,每天每 00 小时都有映射的数据)。
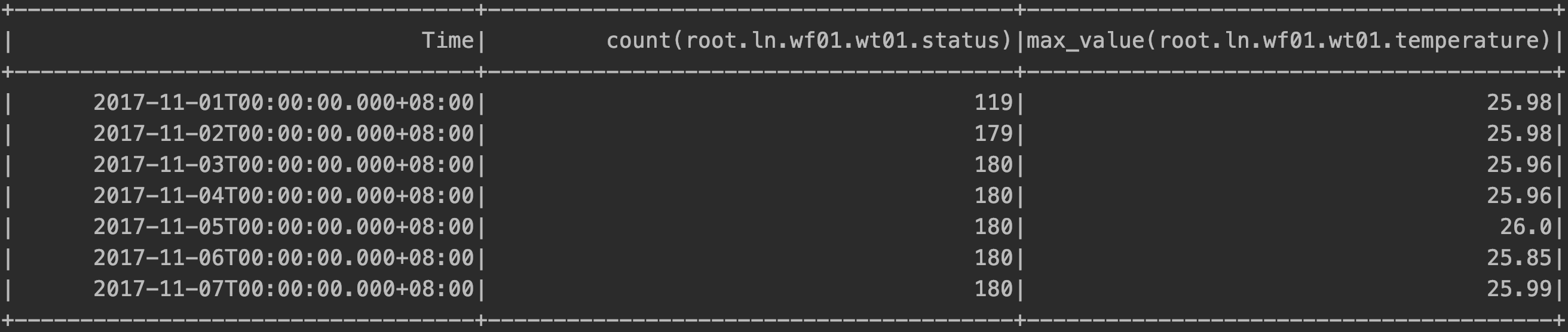
左开和右闭合范围
SQL 语句为:
select count(status) from root.ln.wf01.wt01 group by((5, 40], 5ms);
在此 sql 中,时间间隔为左打开和右关闭,因此我们不会包含时间戳 5 的值,而是包含时间戳 40 的值。
我们将得到如下结果:
| 时间 | count(root.ln.wf01.wt01.status) |
|---|---|
| 10 | 1 |
| 15 | 2 |
| 20 | 3 |
| 25 | 4 |
| 30 | 4 |
| 35 | 3 |
| 40 | 5 |
使用 Fill 子句的降频聚合查询
在按填充分组中,分组依据子句不支持滑动步骤
现在,分组按填充仅支持last_value聚合函数。
在按填充分组中不支持线性填充。
上一个和以前的区别
- PREVIOUS 将填充任何空值,只要存在它之前的值不是空值。
- PREVIOUSUNTILLAST 不会填充时间在该时间序列的最后一个时间之后的结果。
SQL 语句为:
SELECT last_value(temperature) FROM root.ln.wf01.wt01 GROUP BY([8, 39), 5m) FILL (int32[PREVIOUSUNTILLAST])
这意味着:
使用上一页填充方式填充源下频聚合查询结果。
GROUP BY 语句中 SELECT 后面的路径必须是聚合函数,否则系统会给出相应的错误提示,如下所示:

最后一点查询
在 IoT 设备快速更新数据的场景中,用户对 IoT 设备的最新点更感兴趣。
最后一个点查询是以三列格式返回给定时间序列的最新数据点。
SQL 语句定义为:
select last <Path> [COMMA <Path>]* from < PrefixPath > [COMMA < PrefixPath >]* <DISABLE ALIGN>
这意味着:查询并返回时间序列前缀 Path.path 的最后一个数据点。
结果将以三列表格式返回。
| Time | Path | Value |
示例 1:获取 root.ln.wf01.wt01.speed 的最后一点:
> select last speed from root.ln.wf01.wt01| Time | Path | Value || --- | ----------------------- | ----- || 5 | root.ln.wf01.wt01.speed | 100 |
示例 2:获取 root.ln.wf01.wt01 的最后一个速度、状态和温度点
> select last speed, status, temperature from root.ln.wf01.wt01| Time | Path | Value || --- | ---------------------------- | ----- || 5 | root.ln.wf01.wt01.speed | 100 || 7 | root.ln.wf01.wt01.status | true || 9 | root.ln.wf01.wt01.temperature| 35.7 |
自动灌装
在IoTDB的实际使用中,在进行时间序列的查询操作时,可能会出现某些时间点值为null的情况,这会阻碍用户的进一步分析。为了更好地反映数据更改的程度,用户希望自动填充缺失值。因此,IoTDB系统引入了自动填充功能。
自动填充功能是指在对单列或多列进行时间序列查询时,根据用户指定的方法和有效时间范围填充空值。如果查询点的值不为 null,则填充函数将不起作用。
注意:在当前版本中,IoTDB为用户提供了两种方法:先前和线性。上一种方法用以前的值填充空白。线性方法通过线性拟合填充空白。并且 fill 函数只能在执行时间点查询时使用。
填充功能
- 上一个函数
当查询时间戳的值为 null 时,使用上一个时间戳的值来填充空白。形式化的先前方法如下(有关详细语法,请参见第 7.1.3.6 节):
select <path> from <prefixPath> where time = <T> fill(<data_type>[previous, <before_range>], …)
所有参数的详细说明见表3-4。
**表3-4 以前的填充参数列表**
| 参数名称(不区分大小写) | 解释 |
|---|---|
| 路径,前缀路径 | 查询路径;必填项 |
| T | 查询时间戳(只能指定一个);必填项 |
| data_type | 填充方法使用的数据类型。可选值为 int32、int64、浮点型、双精度型、布尔值、文本;可选字段 |
| before_range | 表示上一种方法的有效时间范围。当存在 [T-before_range, T] 范围内的值时,前一种方法有效。如果未指定before_range,before_range采用默认值default_fill_interval;-1 表示无穷大;可选字段 |
在这里,我们给出了使用前面的方法填充空值的示例。SQL 语句如下:
select temperature from root.sgcc.wf03.wt01 where time = 2017-11-01T16:37:50.000 fill(float[previous, 1m])
这意味着:
由于时间序列 root.sgcc.wf03.wt01.temperature在 2017-11-01T16:37:50.000 为空,因此系统使用之前的时间戳 2017-11-01T16:37:00.000(时间戳在 [2017-11-01T16:36:50.000, 2017-11-01T16:37:50.000] 时间范围内)进行填充和显示。
在示例数据 ,此语句的执行结果如下所示:
,此语句的执行结果如下所示:

值得注意的是,如果在指定的有效时间范围内没有值,系统将不会填充null值,如下所示:

- 线性法
当查询时间戳的值为 null 时,使用上一个和下一个时间戳的值来填充空白。形式化的线性方法如下:
select <path> from <prefixPath> where time = <T> fill(<data_type>[linear, <before_range>, <after_range>]…)

- 点赞
- 收藏
- 关注作者
评论(0)