【C++】泛型编程——模板初阶

1. 泛型编程
首先我们来思考一个问题:如何实现一个通用的交换函数呢?
那在C语言中肯定是没法解决这个问题的,不过我们之前学习过在C++里支持函数重载,所以呢,我们就可以这样搞:
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
void Swap(double& left, double& right)
{
double temp = left;
left = right;
right = temp;
}
void Swap(char& left, char& right)
{
char temp = left;
left = right;
right = temp;
}
...这几个函数的函数名相同,只是参数列表不同,构成重载,这样我们想交换不同类型的变量,都是去调用
Swap函数,然后根据参数类型的不同,会自动匹配去调用对应的交换函数。 这与C语言相比,确实有了一点进步。
但是呢,还是有一些不好的地方:
<font color = blue>使用函数重载虽然可以实现,但是有一下几个不好的地方:
<font color = blue>重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函数
代码的可维护性比较低,一个出错可能所有的重载均出错
这些重载的函数呢,干的事情都是一样的,只是处理的数据的类型不同。
那我们想:
能否告诉编译器一个模子(模板),让编译器根据不同的类型利用该模子来生成不同的代码呢?
就类似于这样。

那如果在C++中,也能够存在这样一个模具就好了:
通过给这个模具中填充不同材料(类型),来获得不同材料的铸件(即生成具体类型的代码),那将会节省许多头发。
巧的是前人早已将此树栽好,我们只需在此乘凉: <font color = black>

2. 函数模板
那我们先来学习一下函数模板。
2.1 函数模板的概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生特定类型版本的函数。
2.2 函数模板的使用
函数模板格式:
template<class T1, class T2,...,class Tn><font color = red>返回值类型 函数名(参数列表) { } 注意:class是用来定义模板参数的关键字,也可以使用typename(切记:不能使用struct代替class)
举个栗子,上面的Swap函数,有了模板,我们就可以这样搞:
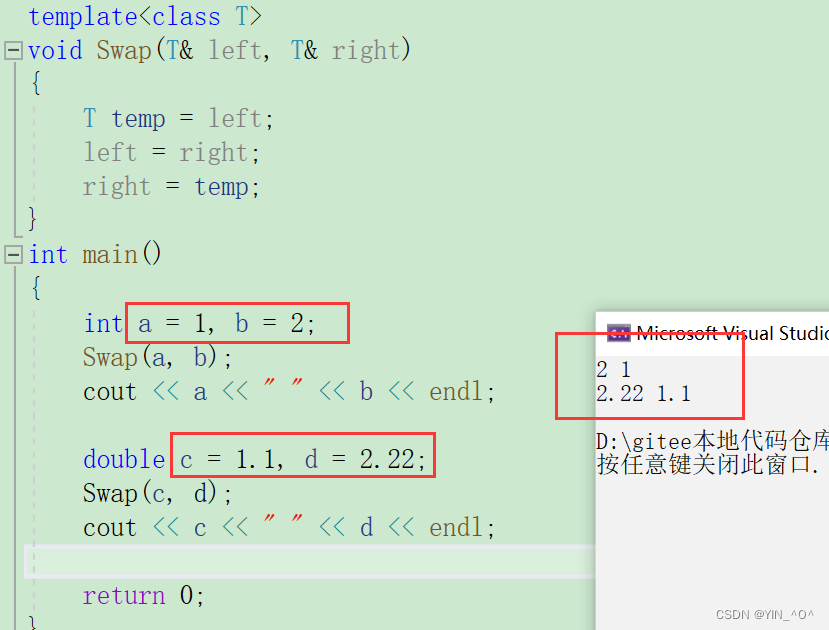
template<class T>
void Swap(T& left, T& right)
{
T temp = left;
left = right;
right = temp;
}这里的T是我们定义的模板的类型名称,是自己起的,我们调用Swap时,传的参数是什么类型,T就会被替换成对应的类型,然后Swap函数就对该类型的参数进行相应的处理。
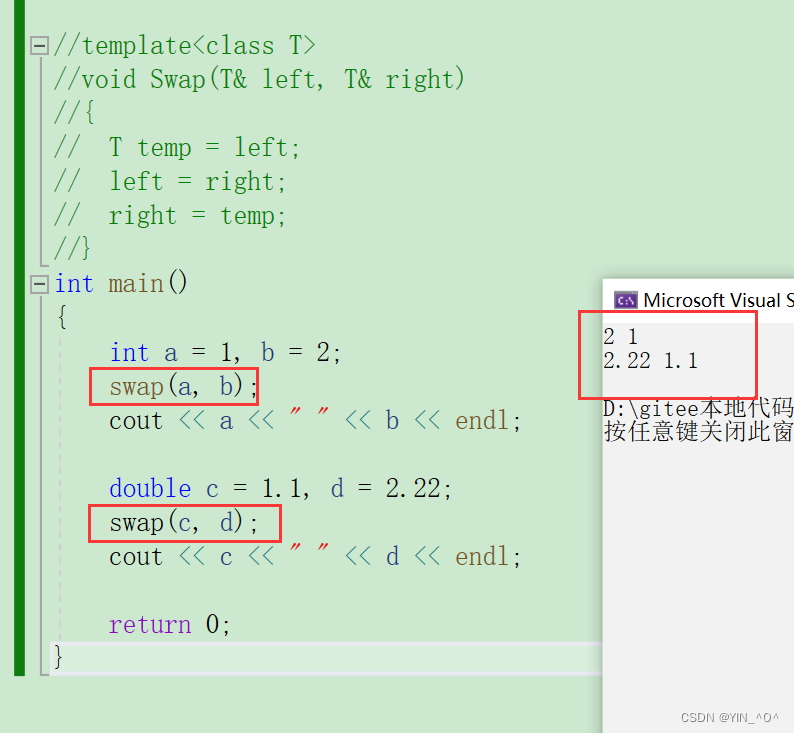
那现在我们交换不同类型的变量,还需要一种类型写一个嘛,不需要了,用这一个就够了:
那现在问大家一个问题:
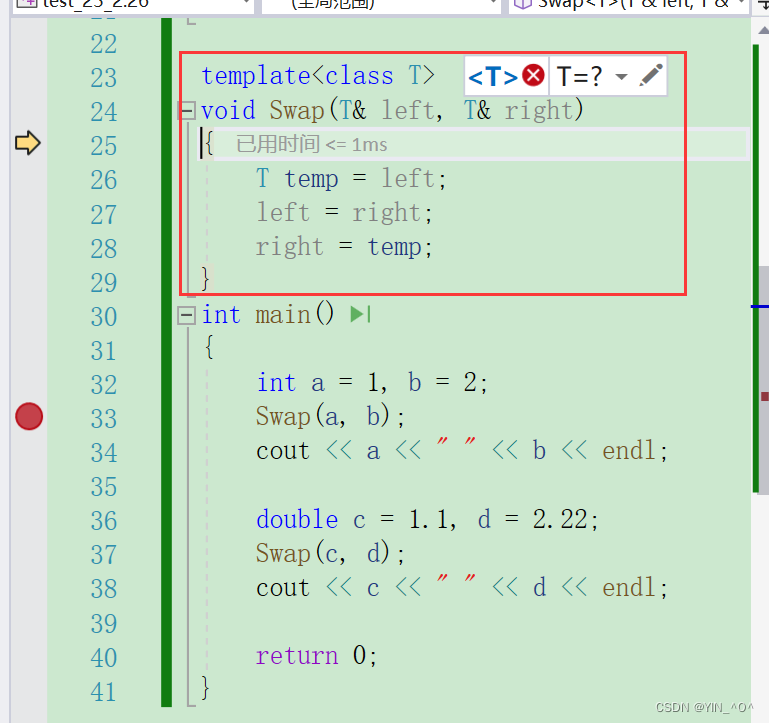
我们上面的
Swap(a, b)和Swap(c, d)调用的是同一个函数吗? <font color = black>但是: <font color = black>我们刚才写的是个啥,是一个具体的函数吗? 是不是一个函数模板啊,并不是一个函数。
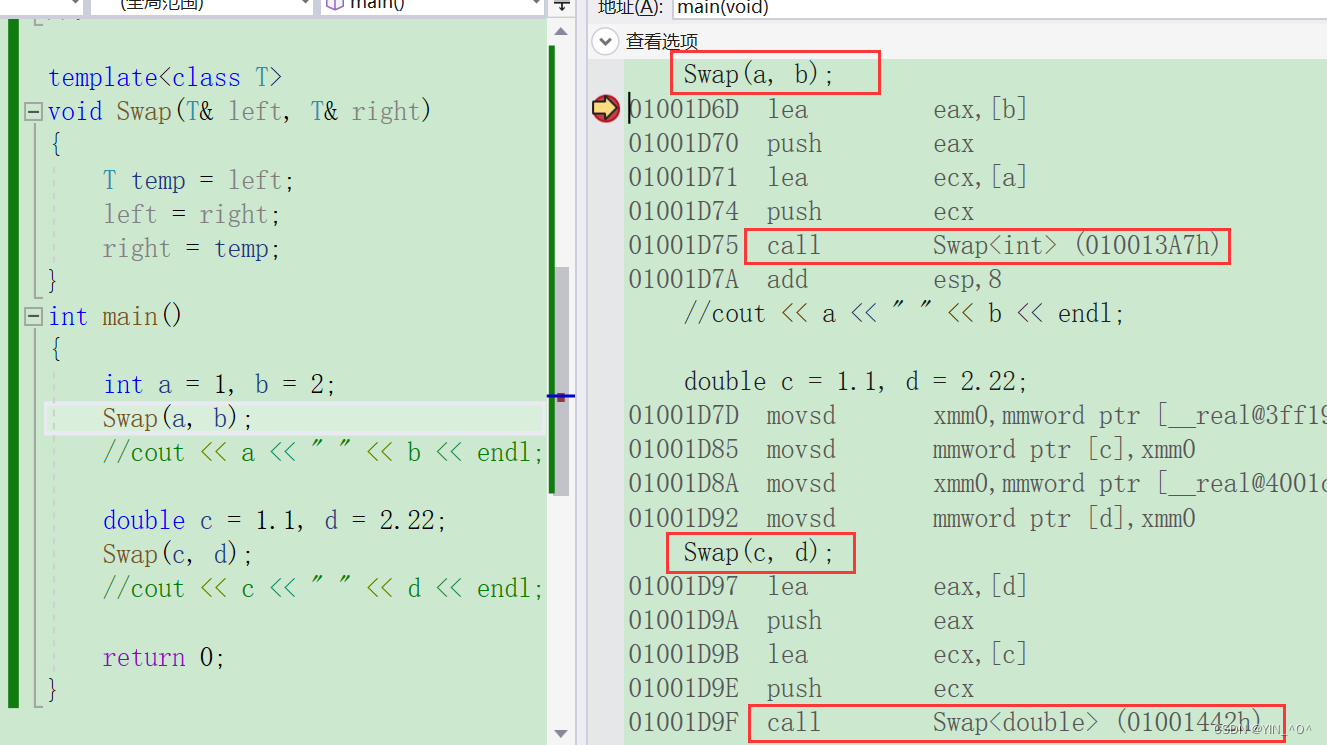
2.3 函数模板的原理
那这样的话,大家再思考一下:
<font color = black>函数模板的原理是什么呢?

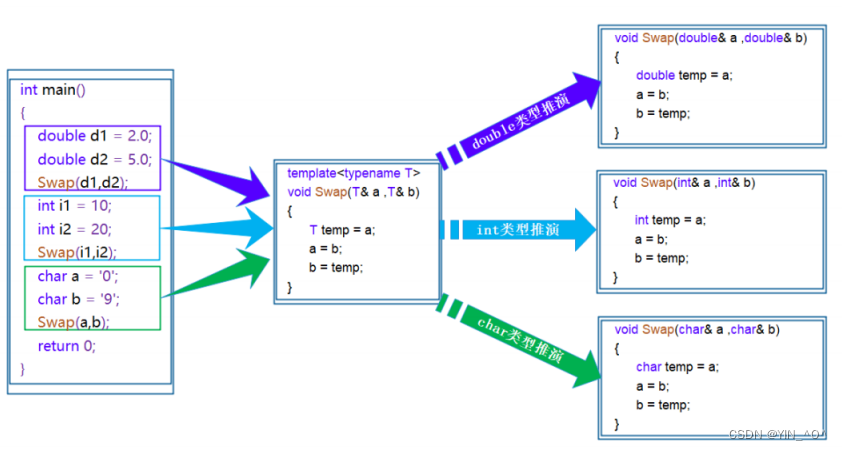
🆗,那函数模板的原理呢其实也是这样:
函数模板是一个蓝图,它本身并不是函数,是编译器用来产生特定具体类型函数的模具。 所以其实模板就是将本来应该我们做的重复的事情交给了编译器去做。
那具体是怎么做的呢?
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。 比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于其它类型也是如此。
另外再给大家提一个东西就是:
<font color = black>其实
swap这个函数C++库里面是提供了的,我们可以直接用:
2.4 函数模板的实例化
用不同类型的参数使用函数模板时,函数模板生成对应类型参数的具体函数,称为函数模板的实例化。 模板参数实例化分为:隐式实例化和显式实例化。
隐式实例化
让编译器根据实参推演模板参数的实际类型
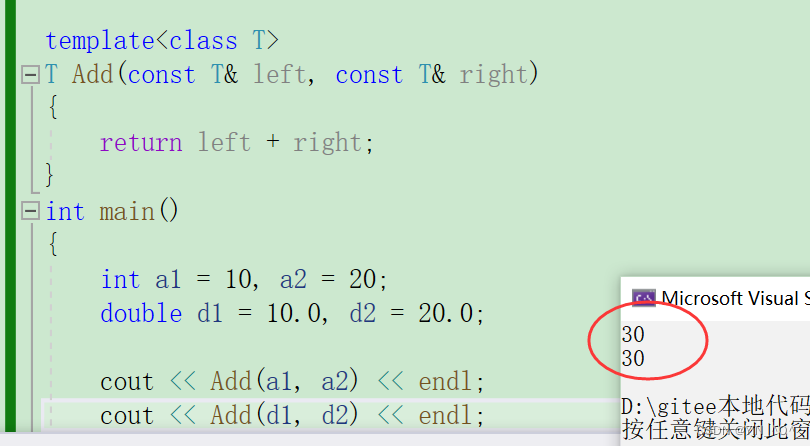
我们来看这样一段代码:
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.0, d2 = 20.0;
Add(a1, a2);
Add(d1, d2);
return 0;
}<font color = black>我们提供了一个加法函数的模板,然后在main函数里分别加了两个整型和浮点型。
那如果这样呢? 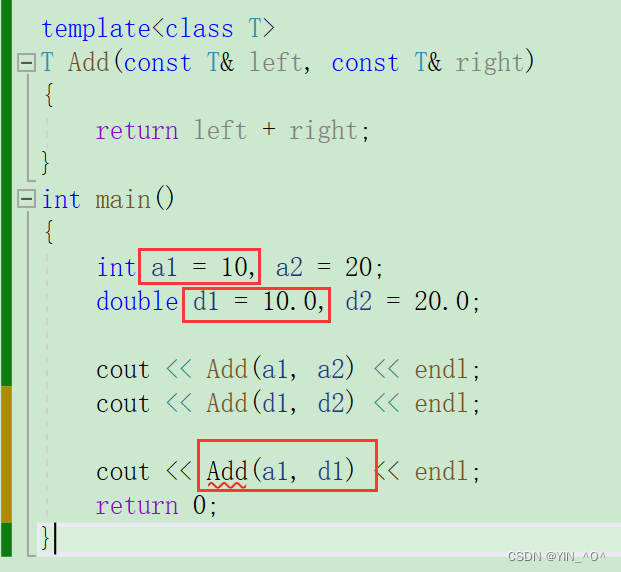
这样就不行了,为什么呢? 因为这时候函数模板在推演实例化的时候会出现歧义: 该语句不能通过编译,因为在编译期间,该函数模板实例化时,需要推演其实参类型。这时通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有一个T,编译器无法确定此处到底该将T确定为int 或者 double类型而报错。 注意:在模板中,编译器一般不会进行类型转换操作,因为一旦转化出问题,编译器就需要背黑锅
那面对这种情况,有两种解决方式:
首先第一种方法就是我们自己去进行强制类型转换。

那另一种方法呢?
显式实例化
在函数名后的<>中指定模板参数的实际类型
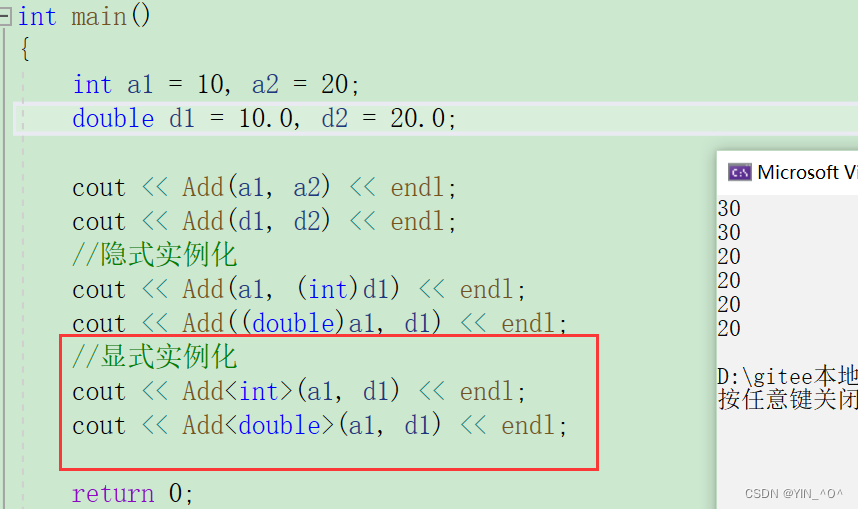
2.5 模板参数的匹配原则
来看这两个函数可以同时存在吗?
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)
{
return left + right;
}
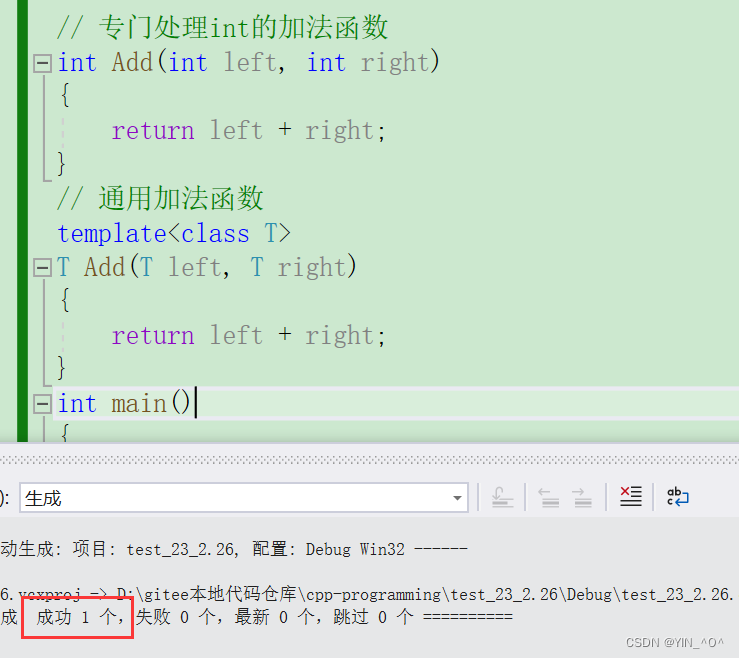
然后再看: 
<font color = black>这里会调用哪一个?
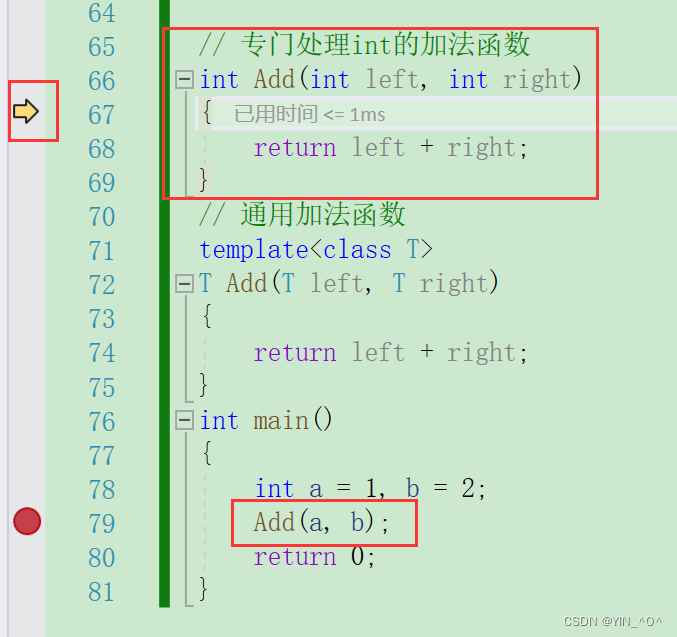
那如果我们就想调函数模板生成的那个呢?可以做到吗?
当然可以,我们只要显示实例化就行了:

另外:
对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模板产生出一个实例。 但如果模板可以产生一个具有更好匹配的函数, 那么将选择模板。
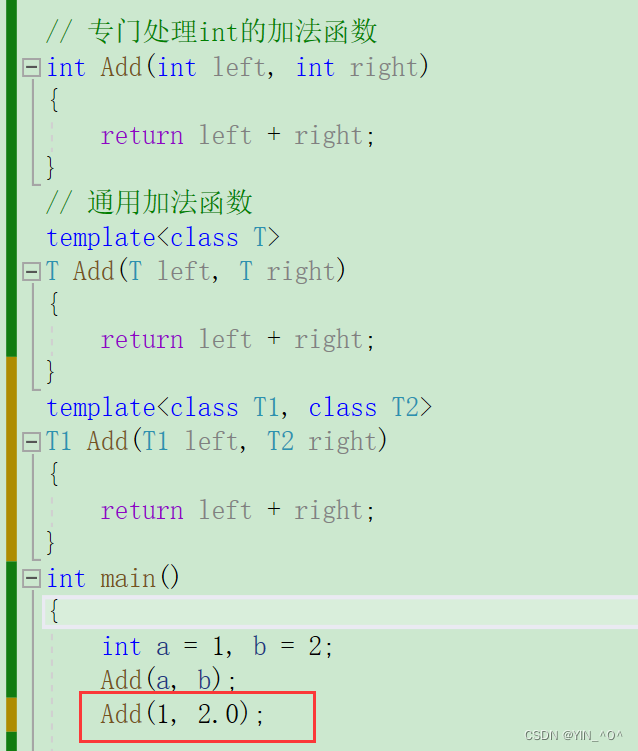
举个栗子,在刚才的基础上,我们再增加一个模板函数:
template<class T1, class T2>
T1 Add(T1 left, T2 right)
{
return left + right;
}<font color = black>
Add(a, b)默认调用非模板函数,这个我们上面刚说过,那大家思考一下Add(1, 2.0)会调用哪个?T1和T2,那调用的时候模板是不是可以产生一个具有更好匹配的函数。Add(1, 2.0),T1自动推演为int,T2自动推演为double。 所以这里就选择调用模板生成的函数了。
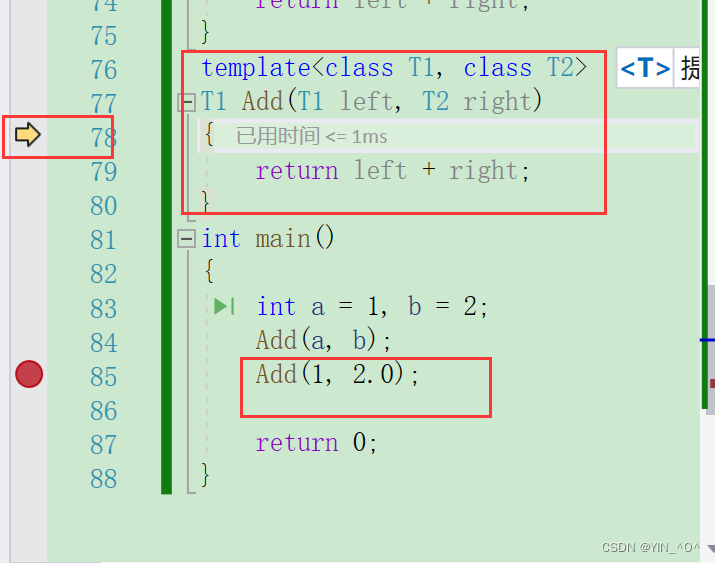
那除了函数模板之外呢,还有类模板。
3. 类模板
那学习了上面的内容,相信类模板大家就能很容易理解了。
举个栗子:
如果没有类模板的话,在C++里我们想写一个栈类一般是这样的:
typedef int DataType;
class Stack
{
public:
//构造函数
Stack(size_t capacity = 4)
{
_array = (DataType*)malloc(sizeof(DataType) * capacity);
if (NULL == _array)
{
perror("malloc申请空间失败!!!");
return;
}
_capacity = capacity;
_size = 0;
}
void Push(DataType data)
{
// CheckCapacity();
_array[_size] = data;
_size++;
}
// 其他方法...
private:
DataType* _array;
int _capacity;
int _size;
};一般我们会
typedef一下,这样如果我们想改变栈里存储数据的类型,就比较方便了。
但是:
<font color = black>如果我们在main函数里定义了2个或者多个栈,想让它们分别存储不同类型的数据,能不能做到呢?
int,那它们两个里面就都只能存int,如果我们改成double,那就都只能存double。 如果想做到,那就只能定义两个栈的类,一个int的,一个double的。但是这样它们除了数据类型不一样,其它是不是都一样啊。 🆗,那这种没有什么技术含量的事情我们就可以交给编译器帮我们做。

怎么搞呢?用类模板就行了:
template<class T>
class Stack
{
public:
Stack(int capaicty = 4)
{
_a = new T[capaicty];
_top = 0;
_capacity = capaicty;
}
~Stack()
{
delete[] _a;
_capacity = _top = 0;
}
private:
T* _a;
size_t _top;
size_t _capacity;
};<font color = black>
Stack是类名,
Stack<int>才是类型 这样我们就可以让不同的栈对象里面存不同类型的数据了。

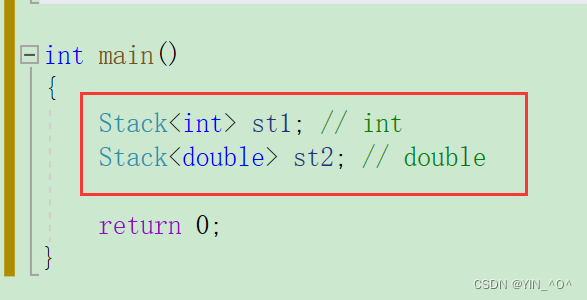
然后还需要注意的是:
<font color = black>如果类模板里的成员函数声明和定义分离的话:
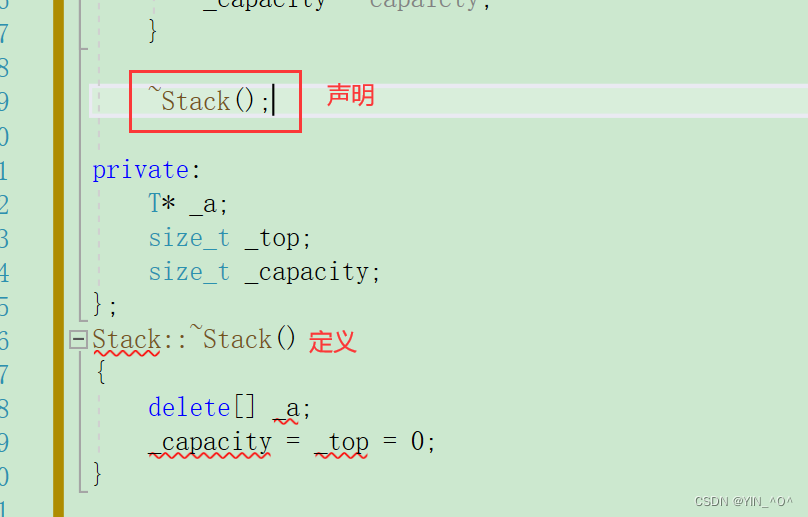
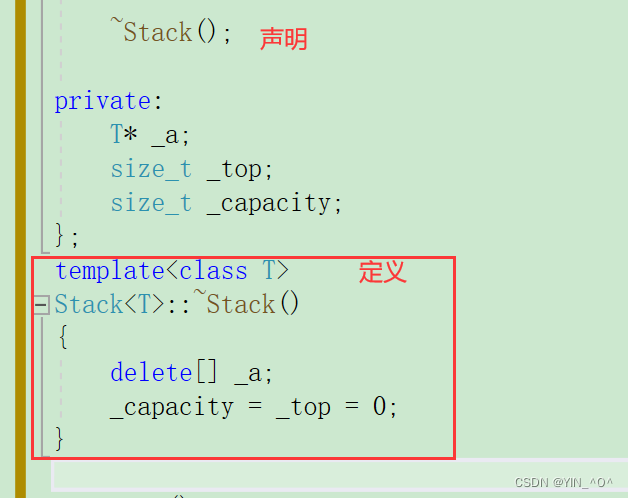
其次:
<font color = black>我们定义一个类可能习惯头文件和源文件分开来,那普通类这样搞是没问题的,就像我们之前实现的日期类就是多文件管理的。 但是呢,类模板不行,类模板如果这样搞,会链接错误的,至于原因呢,我们后面到模板进阶的时候会讲,大家先了解一下。
🆗,那这篇文章就先到这里,欢迎大家指正!!!


- 点赞
- 收藏
- 关注作者
评论(0)