水表表盘读数识别新体验,带你进入华为云ModelArts算法套件的世界【玩转华为云】

前言
数字时代,数字化服务已经发展到各行各业,我们的生活中也随处可见。
数字化服务的便捷了我们的衣食住行的方方面面,除了我们日常化的出行、饮食、购物,其实住方面也已有了很深的发展。
水电燃气这三项和我们生活息息相关的能源,也已经基本上数字化、线上化了,逐步实现了从传统的线下购买到线上购买的过渡。
其中水比较特殊,与另外两个预付费的方式不同,水是先用后付费,传统方式是定期人工上门抄水表的数据然后用户根据用水量进行费用缴纳。
而今,随着技术的快速发展,智能水表读数识别的功能开始广泛被应用。
1分钟了解水表读数识别
智能水表读数识别的功能,可实现对水表的智能监控。
智能化监控的意义在于:
- 分析用户用户量,给出优化建议,从而达到节约用水的目的;
- 实时获取水表数字,改变上门手抄方式,节约人力成本和时间;
- 生成用水数据,便于后续的数据分析。
3分钟了解华为云ModelArts算法套件
华为云ModelArts目前提供的算法开发套件中,主要包括自研(ivg系列)和开源(mm系列)两套算法资产。
可应用于分类、检测、分割和OCR等任务中。
华为云ModelArts使用自研分割算法(ivgSegmentation)和开源OCR算法(mmOCR)的组合完成水表读数识别项目,并使用算法开发套件将其部署为华为云在线服务。
接下来,让我们真实的体验一下算法开发套件实现的水表表盘读数识别的实验。
水表表盘读数识别实验
前置工作
1、确保已经完成了华为云账号的开通与认证。
2、已开通OBS服务。
3、已开通ModelArts服务
进入实验
步骤1:准备数据
1、在“全局配置”页面查看是否已经配置授权,允许ModelArts访问OBS。
2、分别下载本案例的数据集:水表表盘分割数据集和水表表盘读数OCR识别数据集。区域选择“华北-北京四”
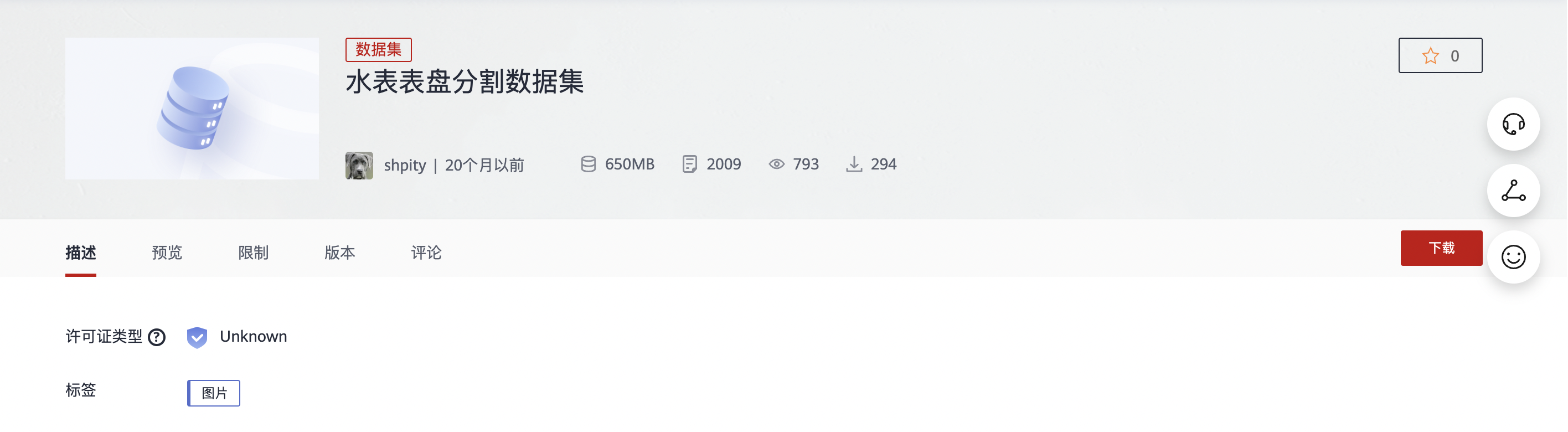

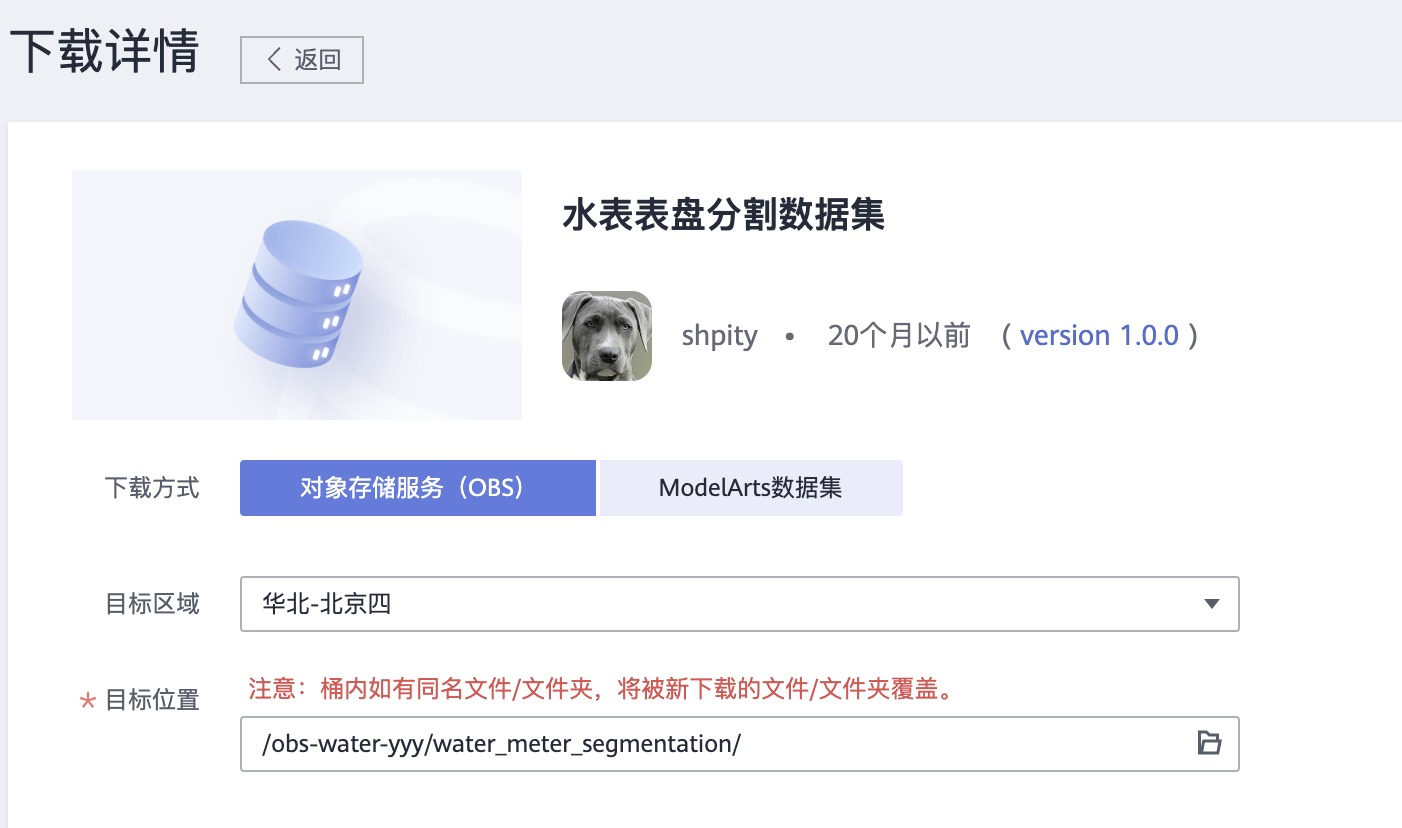
3、新增OBS桶文件,将下载的数据集上传到OBS桶中。OBS路径示例如下:
- obs://obs-water-yyy/water_meter_segmentation 水表表盘分割数据集
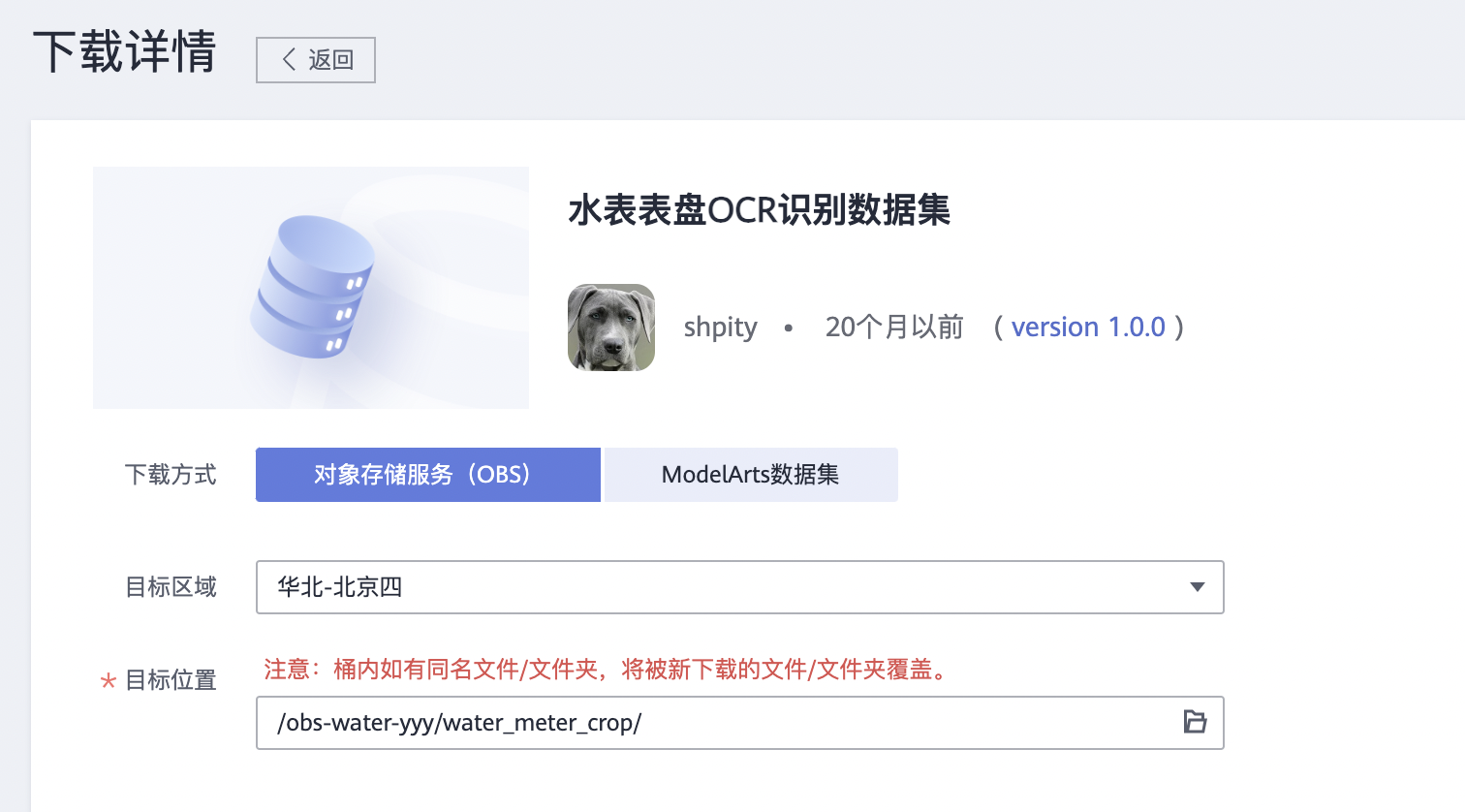
- obs://obs-water-yyy/water_meter_crop 水表表盘读数OCR识别数据集
步骤2:准备开发环境
1、在“ModelArts控制台 > 开发环境 > Notebook”页面中,创建基于pytorch1.8-cuda10.2-cudnn7-ubuntu18.04镜像,类型为GPU的Notebook,
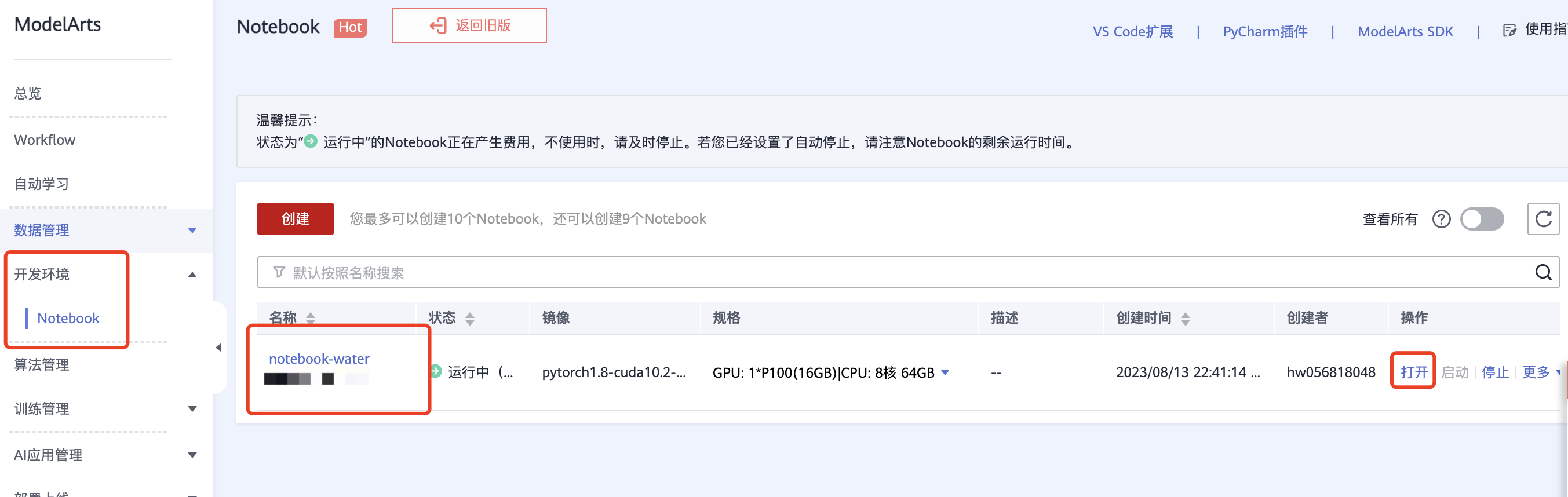
2、在“ModelArts控制台 > 开发环境 > Notebook”页面的列表中,单击操作栏的“打开”,进入JupyterLab页面。
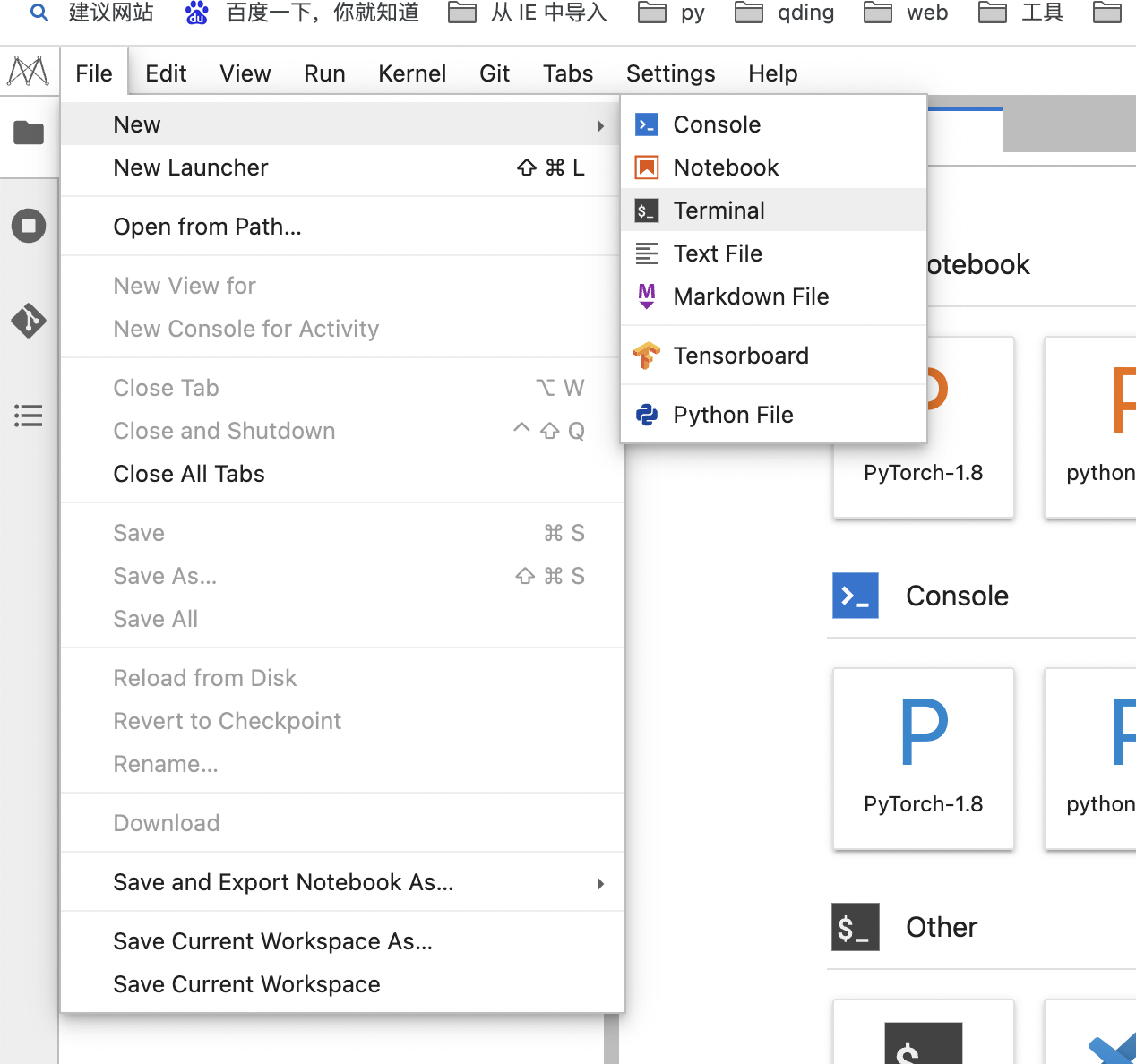
3、打开JupyterLab的Terminal。
步骤3:创建算法工程
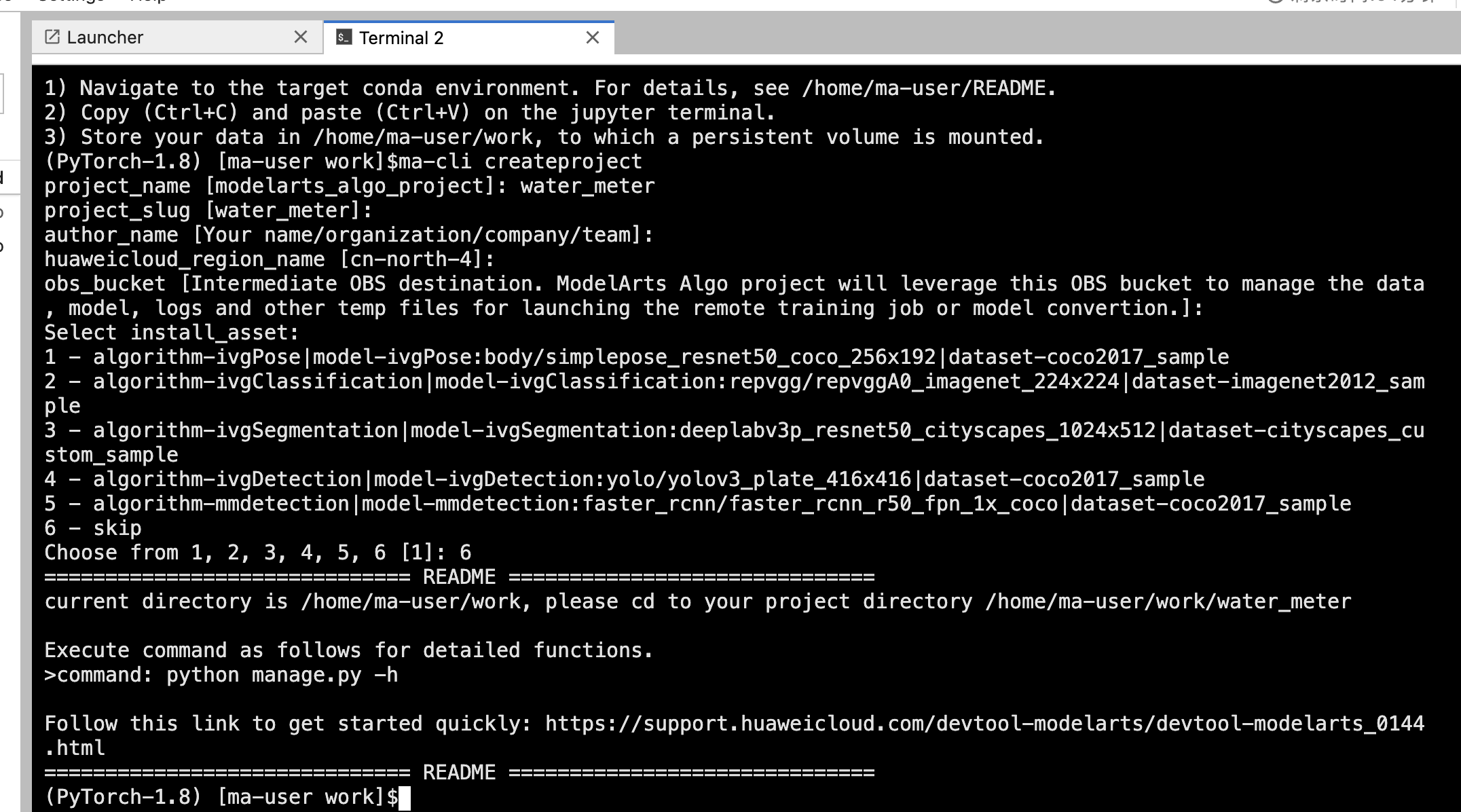
1、在JupyterLab的Terminal中,在work目录下执行ma-cli createproject命令创建工程,根据提示输入工程名称,例如:water_meter。然后直接回车选择默认参数,并选择跳过资产安装步骤(选择6)。
2、执行以下命令进入工程目录。
cd water_meter3、执行以下命令拷贝项目数据到Notebook中。
python manage.py copy --source obs://obs-water-yyy/water_meter_crop --dest ./data/raw/water_meter_crop
python manage.py copy --source obs://obs-water-yyy/water_meter_segmentation --dest ./data/raw/water_meter_segmentation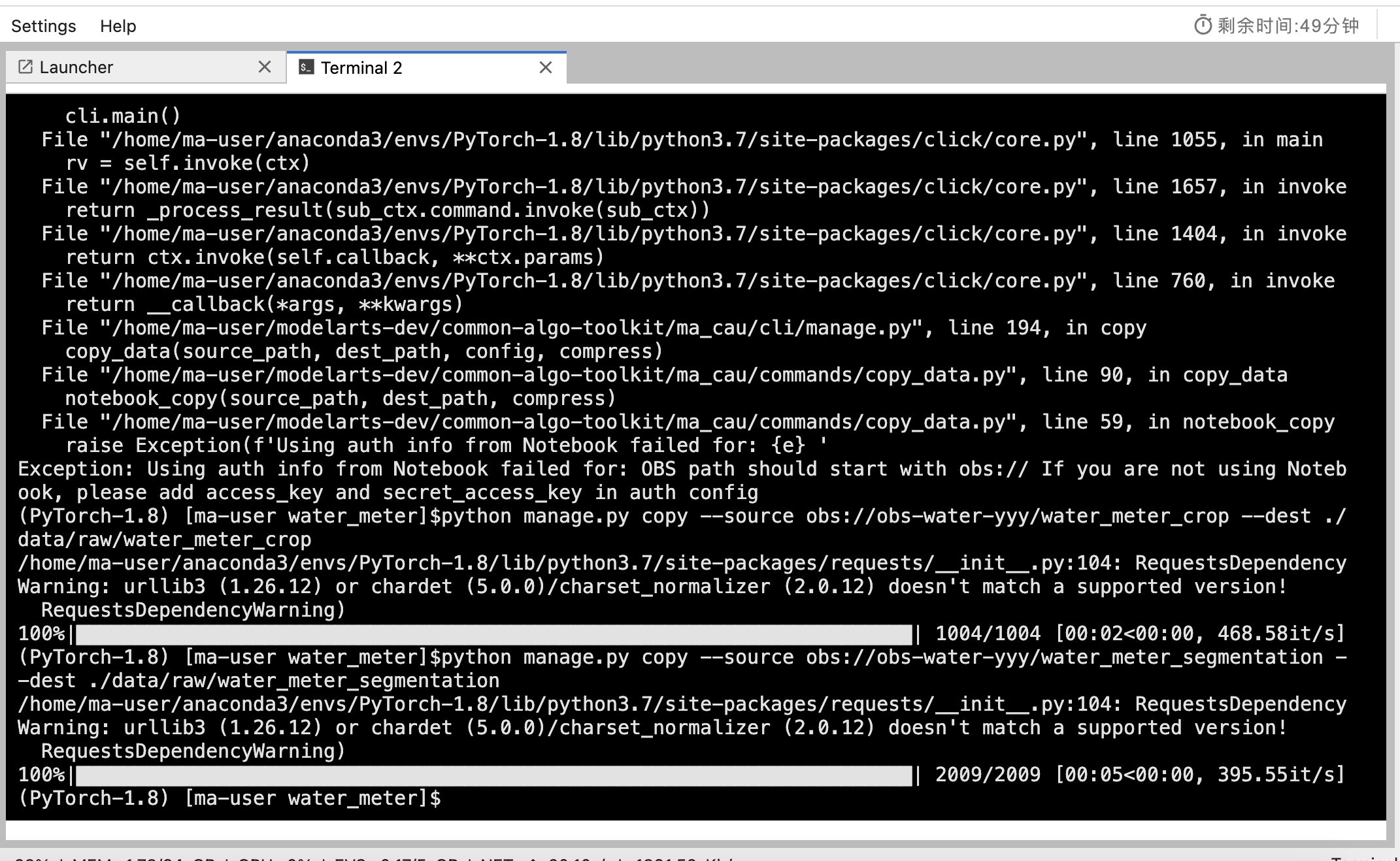
步骤4:使用deeplabv3完成水表区域分割任务
1、首先安装ivgSegmentation套件。
python manage.py install algorithm ivgSegmentation==1.0.2
2、安装ivgSegmentation套件后,在JupyterLab界面左侧的工程目录中进入“./algorithms/ivgSegmentation/config/sample”文件夹中查看目前支持的分割模型,以sample为例(sample默认的算法就是deeplabv3),文件夹中包括config.py(算法外壳配置)和deeplabv3_resnet50_standard-sample_512x1024.py(模型结构)。
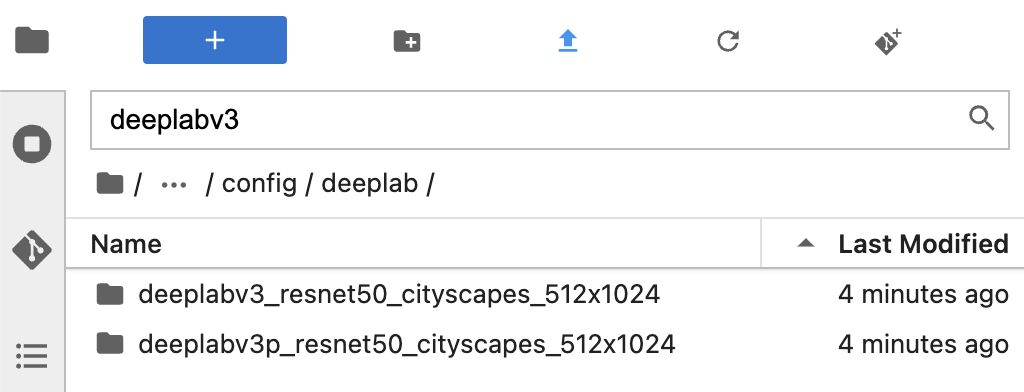
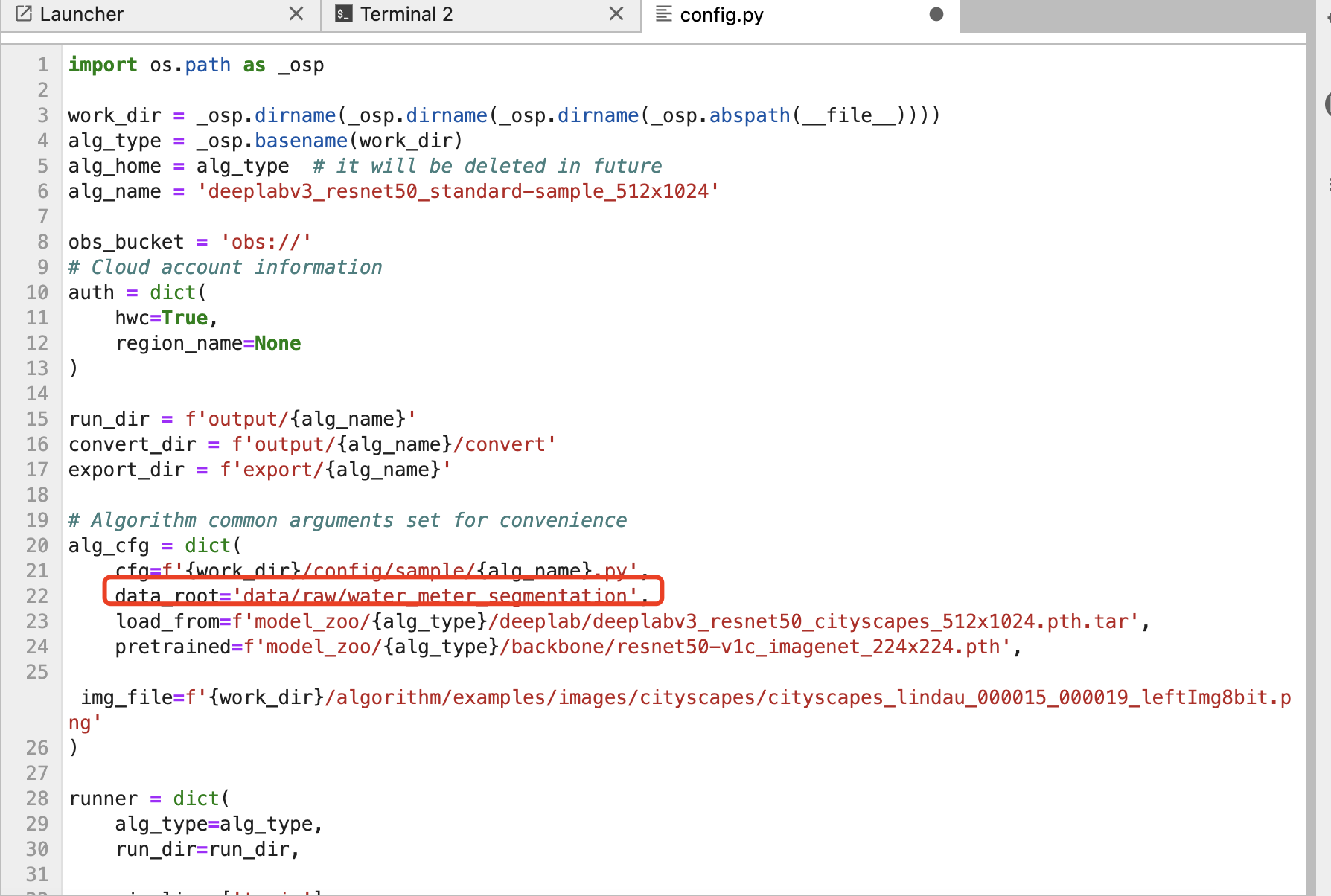
3、表盘分割只需要区分背景和读数区域,因此属于二分类,需要根据项目所需数据集对配置文件进行修改,如下所示:修改“./algorithms/ivgSegmentation/config/sample/config.py”文件。修改完后按Ctrl+S保存。
# config.py
alg_cfg = dict(
...
data_root='data/raw/water_meter_segmentation', # 修改为真实路径本地分割数据集路径
...
)
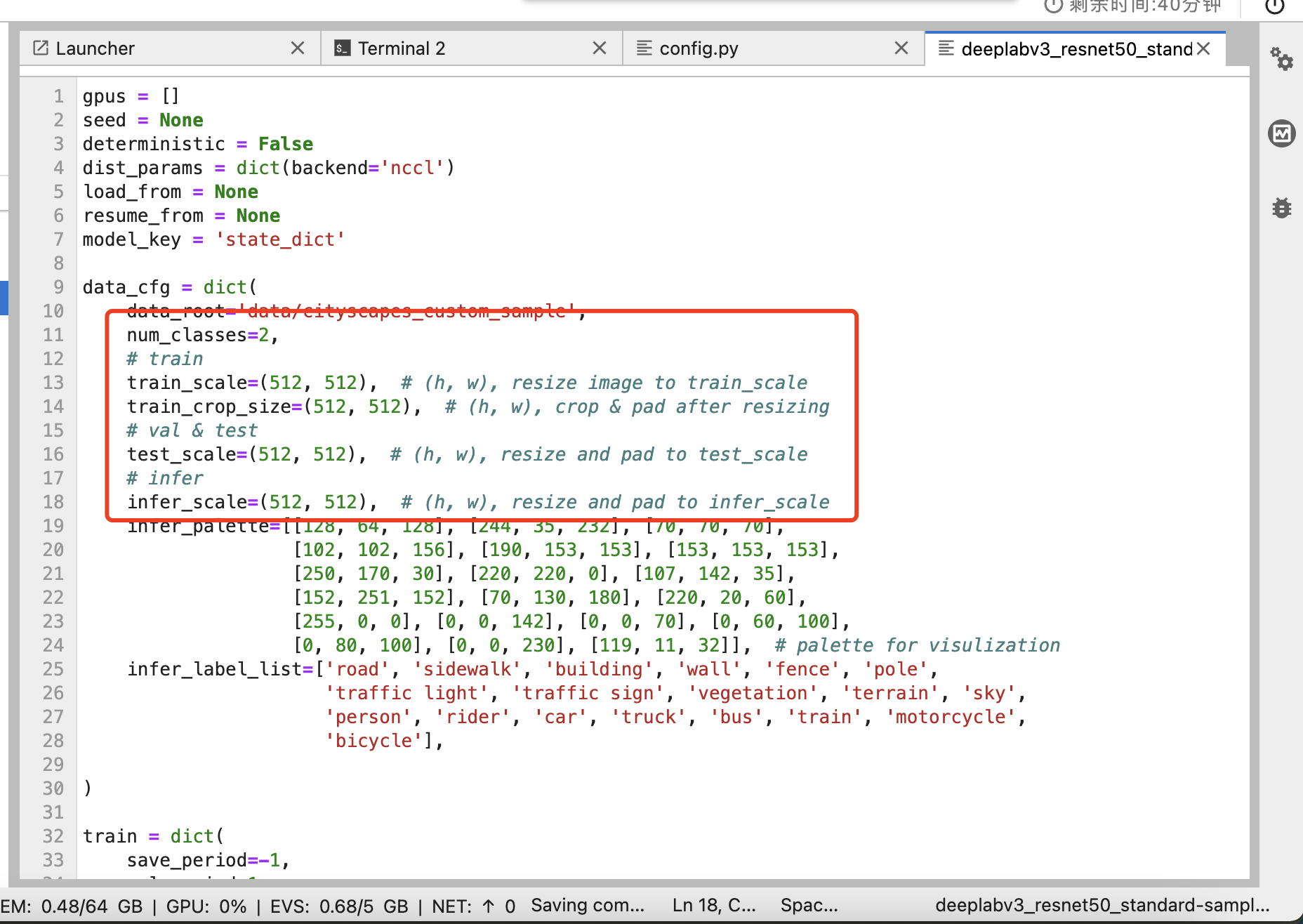
4、修改“./algorithms/ivgSegmentation/config/sample/deeplabv3_resnet50_standard-sample_512x1024.py”文件。修改完后按Ctrl+S保存。
# deeplabv3_resnet50_standard-sample_512x1024.py
gpus=[0]
...
data_cfg = dict(
... num_classes=2, # 修改为2类
...
... train_scale=(512, 512), # (h, w)#size全部修改为(512, 512)
... train_crop_size=(512, 512), # (h, w)
... test_scale=(512, 512), # (h, w)
... infer_scale=(512, 512), # (h, w)
)
5、在water_meter工程目录下,安装deeplabv3预训练模型。
python manage.py install model ivgSegmentation:deeplab/deeplabv3_resnet50_cityscapes_512x1024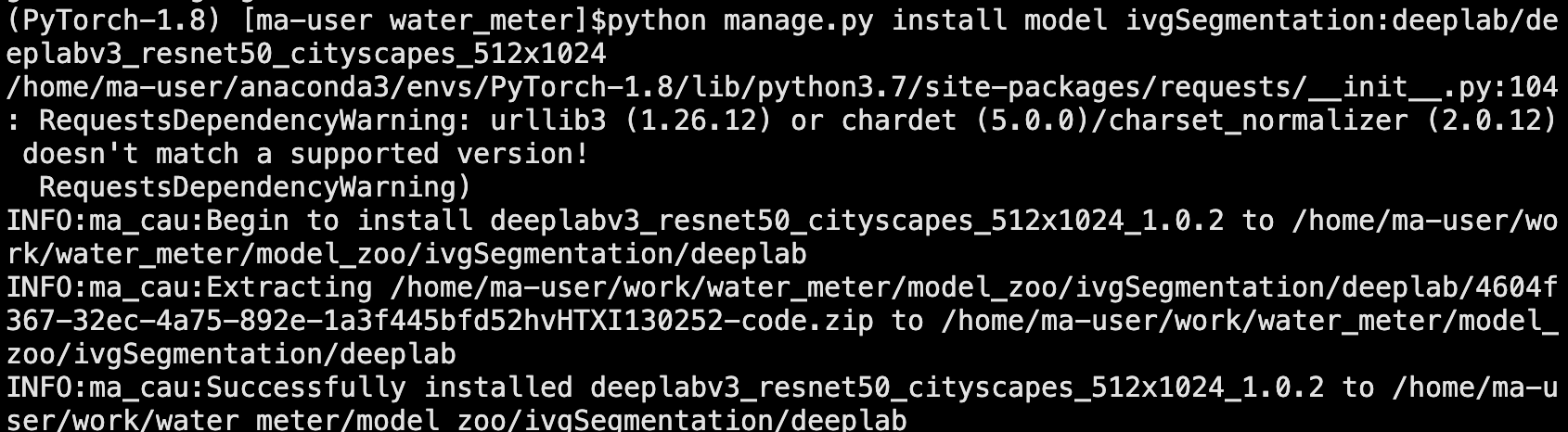
6、训练分割模型。(推荐使用GPU进行训练)
# shell
python manage.py run --cfg algorithms/ivgSegmentation/config/sample/config.py --gpus 0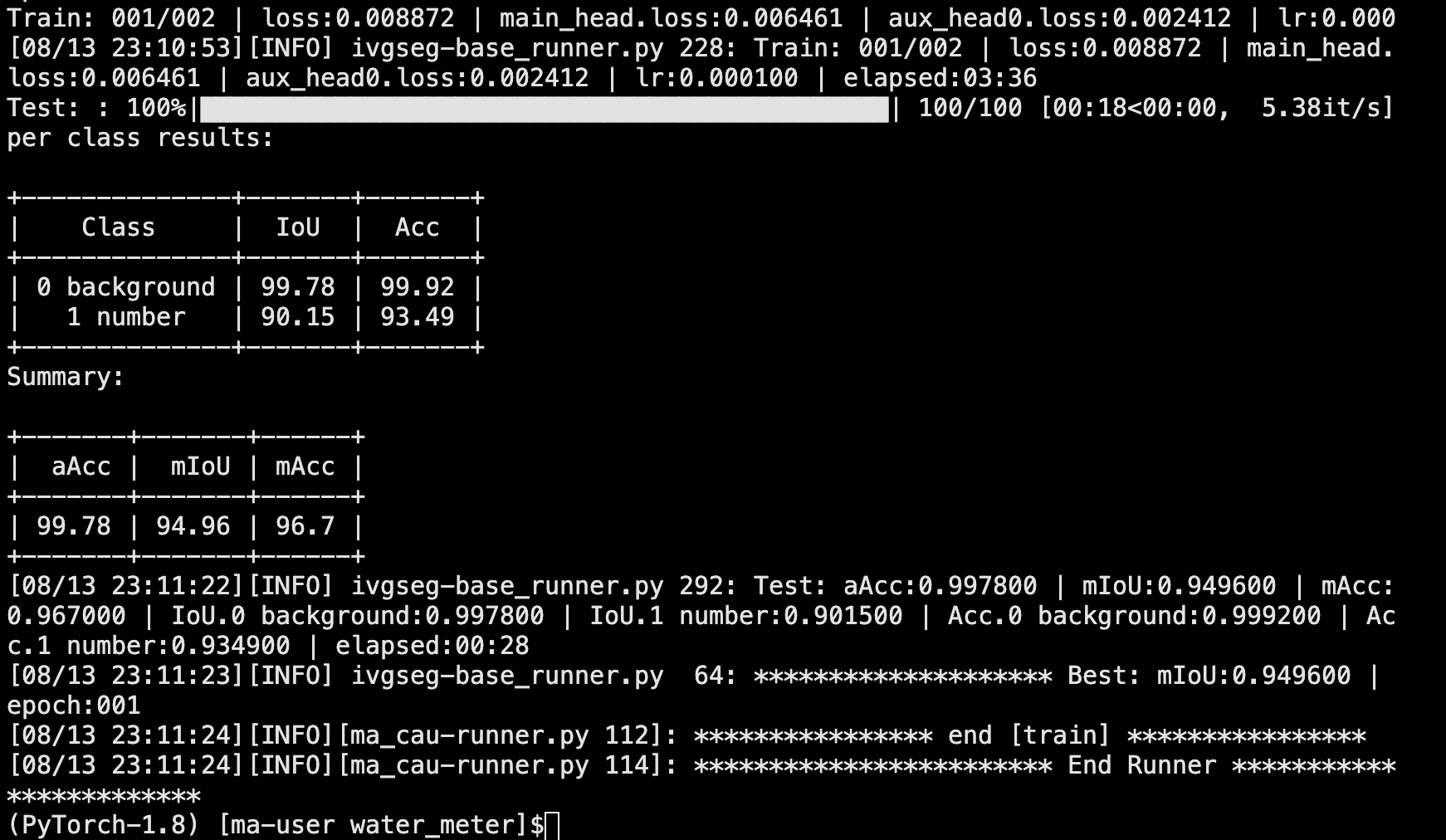 训练好的模型会保存在指定位置中,默认为“output/deeplabv3_resnet50_standard-sample_512x1024/checkpoints/”中。
训练好的模型会保存在指定位置中,默认为“output/deeplabv3_resnet50_standard-sample_512x1024/checkpoints/”中。

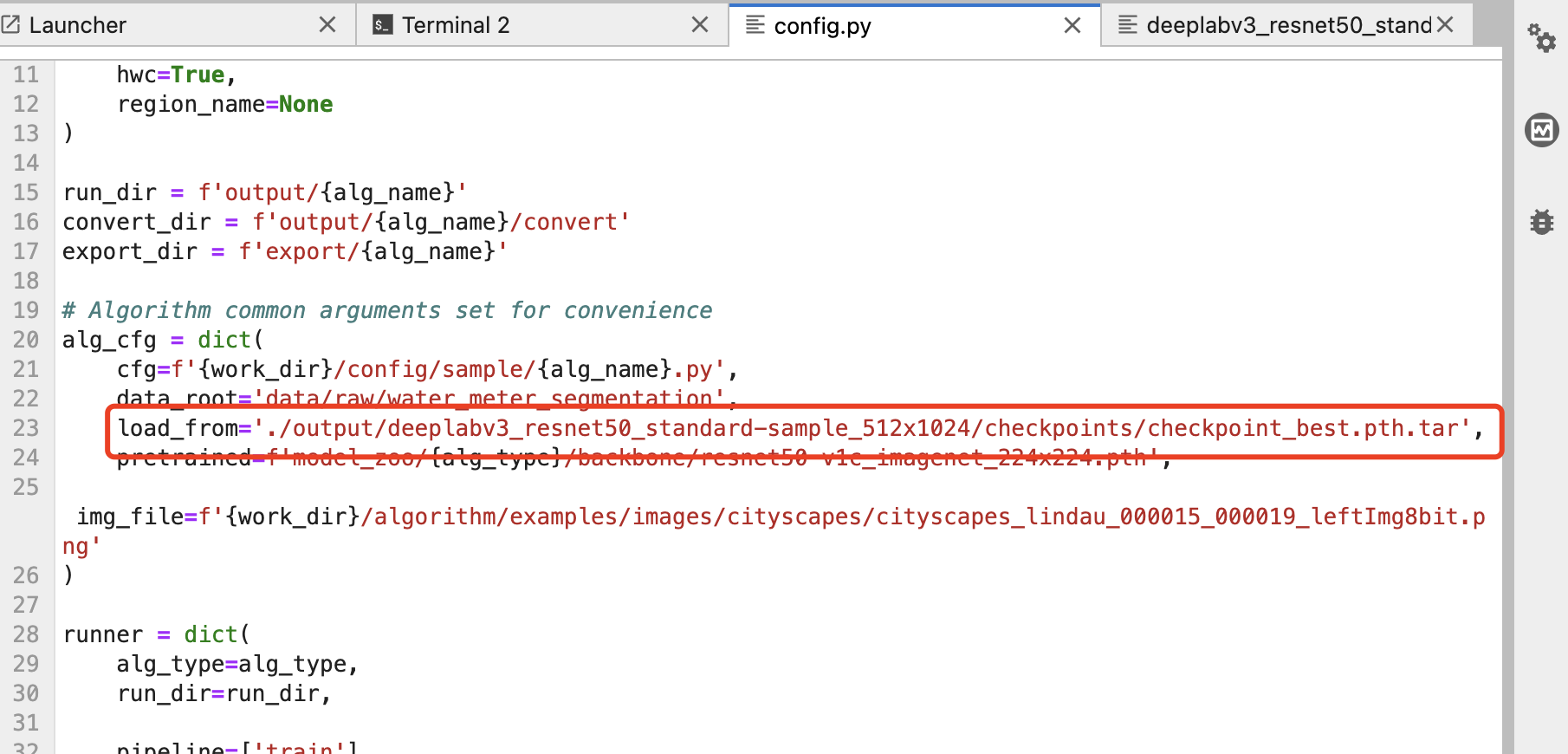
7、验证模型效果。模型训练完成后,可以在验证集上计算模型的指标,首先修改配置文件的模型位置。修改“./algorithms/ivgSegmentation/config/sample/config.py”。
# config.py
alg_cfg = dict(
...
load_from='./output/deeplabv3_resnet50_standard-sample_512x1024/checkpoints/checkpoint_best.pth.tar', # 修改训练模型的路径
...
)
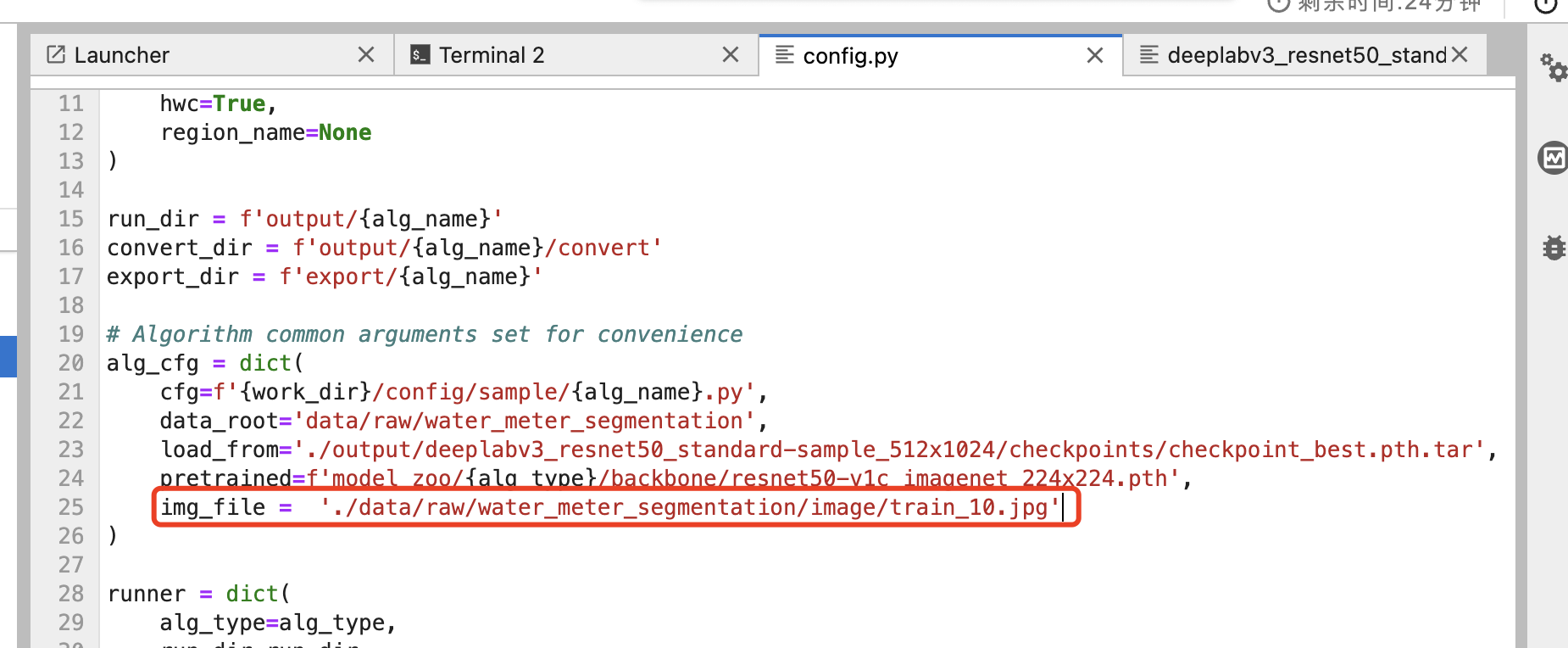
8、模型推理。模型推理能够指定某一张图片,并且推理出图片的分割区域,并进行可视化,首先需要指定需要推理的图片路径。修改“./algorithms/ivgSegmentation/config/sample/config.py”
alg_cfg = dict(
...
img_file = './data/raw/water_meter_segmentation/image/train_10.jpg' # 指定需要推理的图片路径
...
)
执行如下命令推理模型效果:
python manage.py run --cfg algorithms/ivgSegmentation/config/sample/config.py --pipeline infer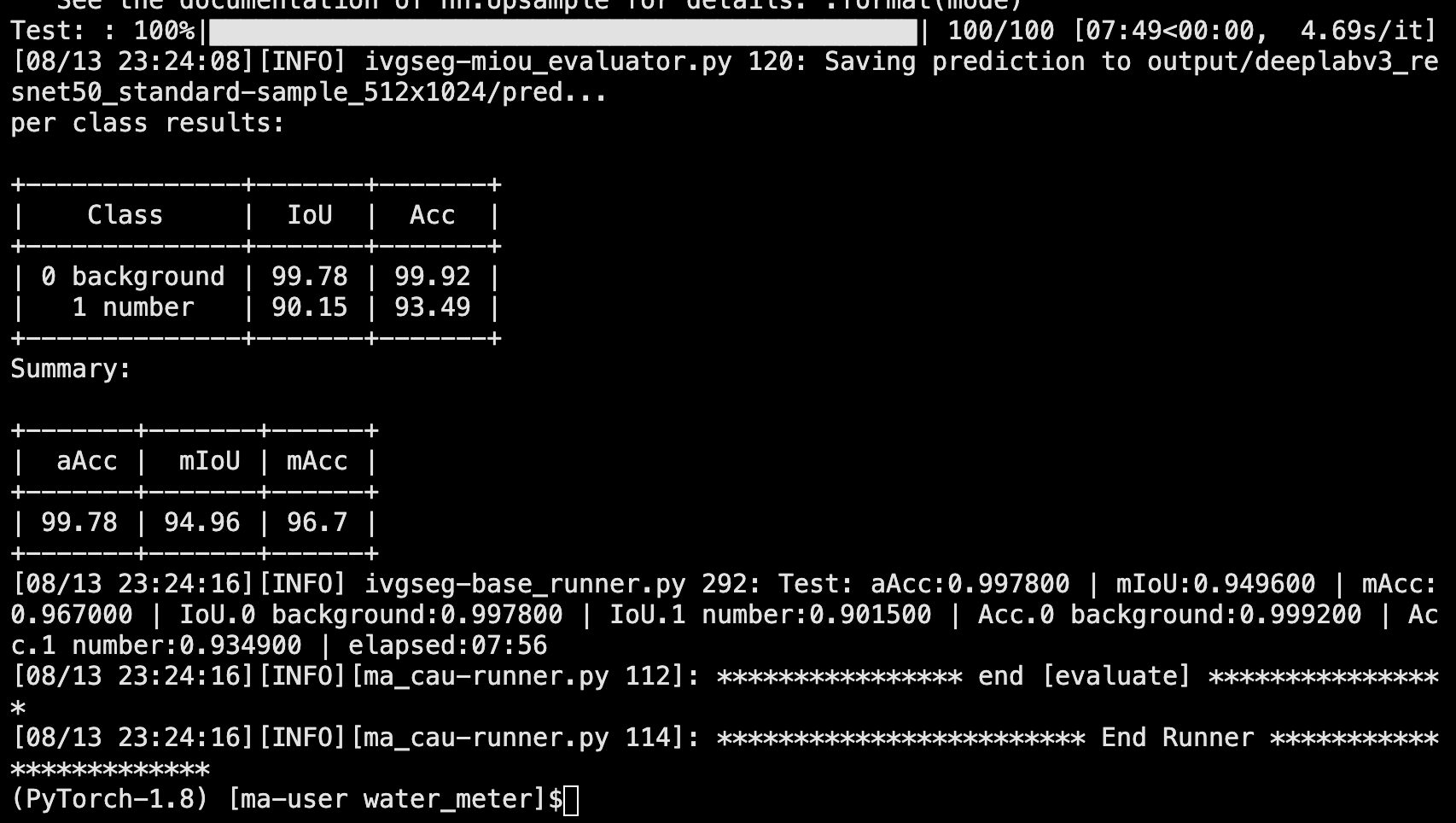
推理输出的图片路径在“./output/deeplabv3_resnet50_standard-sample_512x1024”下。
9、导出算法SDK。算法开发套件支持将模型导出成一个模型SDK,方便进行模型部署等下游任务。
# shell
python manage.py export --cfg algorithms/ivgSegmentation/config/sample/config.py --is_deploy

步骤5:水表读数识别
1、首先安装mmocr套件。
python manage.py install algorithm mmocr==0.2.12、安装mmocr套件后,“./algorithms/mmocr/config/textrecog”文件夹中包括config.py(算法外壳配置),需要根据所需算法和数据集路径修改配置文件。以下以robust_scanner算法为例。修改“./algorithms/mmocr/algorithm/configs/textrecog/robustscanner_r31_academic.py”,
# robustscanner_r31_academic.py
...
train_prefix = 'data/raw/water_meter_crop/' # 修改数据集路径改为水表ocr识别数据集路径
train_img_prefix1 = train_prefix + 'train'
train_ann_file1 = train_prefix + 'train.txt'
...
test_prefix = 'data/raw/water_meter_crop/'
test_img_prefix1 = test_prefix + 'val/'
test_ann_file1 = test_prefix + 'val.txt'3、安装robust_scanner预训练模型。
python manage.py install model mmocr:textrecog/robust_scanner/robustscanner_r31_academic4、训练OCR模型。初次使用mmcv时需要编译mmcv-full,该过程较慢,可以直接使用官方预编译的依赖包。预编译包URL: https://download.openmmlab.com/mmcv/dist/cu102/torch1.6.0/index.html
pip uninstall mmcv -y
pip install https://download.openmmlab.com/mmcv/dist/cu102/torch1.6.0/mmcv_full-1.3.9-cp37-cp37m-manylinux1_x86_64.whl将./algorithms/mmocr/config/textrecog/config.py中的epoch(迭代数量)改为2。
训练OCR模型。(仅使用GPU进行训练,大概需要四分钟)训练好的模型会保存在指定位置中,默认为output/robustscanner_r31_academic/文件夹中。
5、验证模型效果。模型训练完成后,可以在验证集上计算模型的指标,首先修改配置文件的模型位置。修改./algorithms/mmocr/config/textrecog/config.py
# config.py
...
model_path = './output/robustscanner_r31_academic/latest.pth'
...步骤6:部署为在线服务
1、在“algorithms/mmocr/config/textrecog/config.py”文件中配置OBS桶。
修改./algorithms/mmocr/algorithm/configs/textrecog/robust_scanner/config.py
# 替换为用户自己的OBS桶信息
obs_bucket = 'obs://{your_obs_bucket_path}'2、依次执行下述命令:
python manage.py export --cfg algorithms/mmocr/config/textrecog/config.py --is_deploy # 导出部署模型所需文件
python manage.py deploy --cfg algorithms/mmocr/config/textrecog/config.py # 本地部署调试3、本地部署成功后的输出结果
#
...
[Conda environment created successfully.]
local_service_port is 127.0.0.1:42153
Deploying the local service ...
Successfully deployed the local service. You can check the log in /home/ma-user/work/water_meter/export/robustscanner_r31_academic/Linux_x86_64_GPU_PyTorch_Common_py/log.txt
[07/05 09:40:14][INFO][ma_cau-deployer.py 49]: {
"text": "00326",
"score": 0.9999999046325684
}
[07/05 09:40:14][INFO][ma_cau-deployer.py 59]: ************************ End Deployer ************************python manage.py deploy --cfg algorithms/mmocr/config/textrecog/config.py --launch_remote本地部署成功后可直接进行在线部署,大约需要12分钟。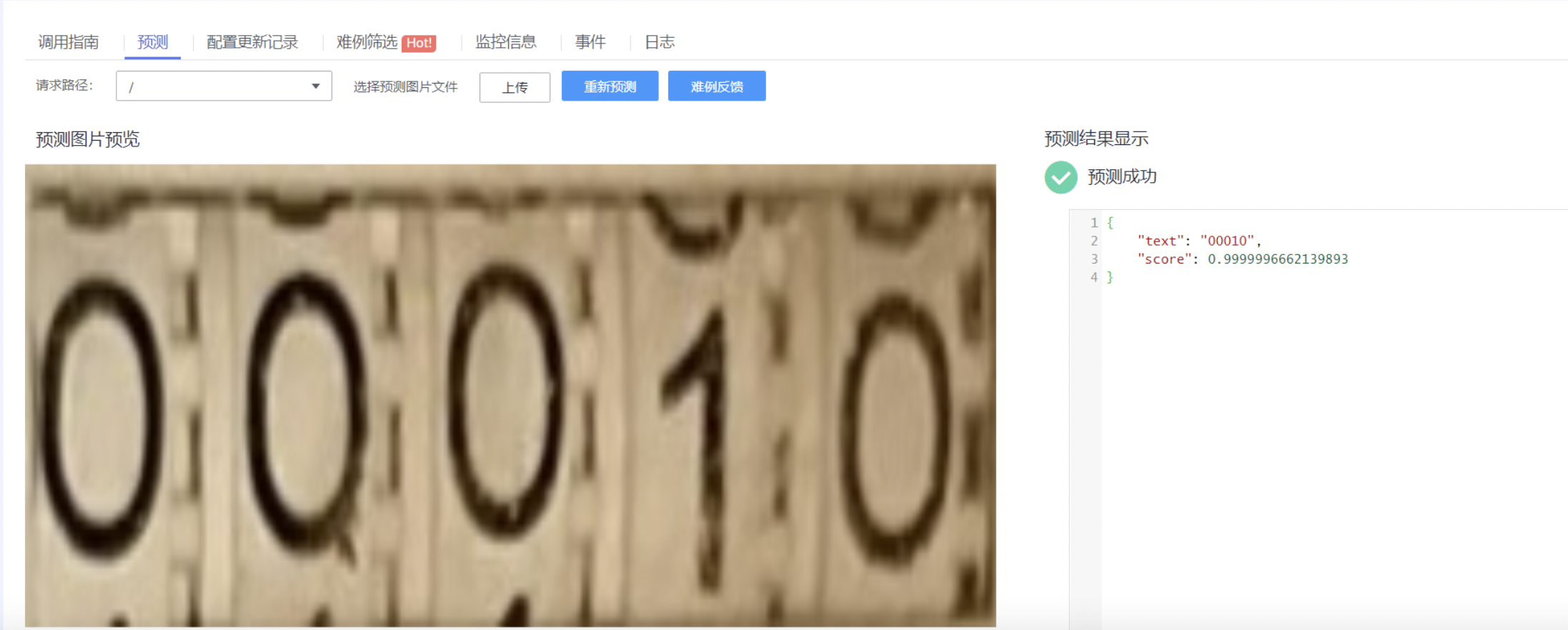
步骤7:清除资源和数据
完成之后,记得清除资源和数据,避免产生不必要的费用:
- 停止Notebook:在“Notebook”页面,单击对应实例操作列的“停止”。
- 删除数据:前往OBS,删除上传的数据,然后删除文件夹及OBS桶。
- 停止在线服务:在Modelarts部署上线->在线服务界面,单击对应在线服务操作列的“更多”->“停止”。
总结
完成水表表盘读数识别的实验之后,对华为云提供的算法开发套件功能有了更深一些的了解。
华为云提供的算法开发套件,可以实现目标检测功能,通过导入数据集、选择模型、训练等一系列流程,快速完成目标检测任务(详见:目标检测算法套件使用Demo)。
接下来,对于算法开发套件,我会继续进行研究和实验,掌握更多的业务用途。
未来,也期待与华为云ModelArts一起实现更多的可能。
作者:非职业「传道授业解惑」的开发者叶一一
简介:「趣学前端」、「CSS畅想」系列作者,华夏美食、国漫、古风重度爱好者,刑侦、无限流小说初级玩家。
如果看完文章有所收获,欢迎点赞👍 | 收藏⭐️ | 留言📝。

- 点赞
- 收藏
- 关注作者
评论(0)