【Django | 爬虫 】收集某吧评论集成舆情监控(附源码)


🤵♂️ 个人主页: @计算机魔术师
👨💻 作者简介:CSDN内容合伙人,全栈领域优质创作者。
@[toc]
一、爬取帖子、二级评论
爬取源码
from lxml import etree # 导入所需模块
import requests, re
root_url = "https://tieba.baidu.com"
headers = {
'Cookie': '你的cookie',
'Accept': 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
# 帖吧(第一页)
base_comment = []
page_first = 0 # 第一页
while page_first < 5: # 默认爬取五页
resp = requests.get('https://tieba.baidu.com/f?kw=佛山科学技术学院&ie=utf-8' + f'&pn={page_first * 50}', headers=headers)
html_baidu = resp.content.decode('utf-8') # 手动解码 text默认返回猜测的解码方式
# 根路由
tree_baidu = etree.HTML(html_baidu)
divs_daidu = tree_baidu.xpath('//*[@id="thread_list"]/li')
# 获取帖子字典
for div in divs_daidu:
dict_temp = {}
if div.xpath('./div/div[2]/div[1]/div[1]/a/@href'):
dict_temp['id'] = re.sub(r'/p/', '', div.xpath('./div/div[2]/div[1]/div[1]/a/@href')[0])
dict_temp['comment'] = div.xpath('./div/div[2]/div[1]/div[1]/a/text()')
dict_temp['href'] = root_url + div.xpath('./div/div[2]/div[1]/div[1]/a/@href')[0]
dict_temp['img'] = div.xpath(
f'//*[@id="fm{re.sub(r"/p/", "", div.xpath("./div/div[2]/div[1]/div[1]/a/@href")[0])}"]/li/a/img/@data-original')
base_comment.append(dict_temp)
# 二级评论参数
second_page = 1
param_second = {
'pn': str(second_page)
}
first_pagesize = 0
# todo 二轮循环 帖子收集
while first_pagesize < len(base_comment):
second_pagesize = 0
# todo 一轮循环 -> 帖子回复
resp_second = requests.get(url=base_comment[first_pagesize]['href'], params=param_second) # 获取响应
second_html = resp_second.content.decode('utf-8') # 获取源码
second_tree = etree.HTML(second_html) # 解析源代码
second_root = second_tree.xpath('//*[@id="j_p_postlist"]/div') # 获取节点树
while second_pagesize < len(second_root):
second_comments = [] # 收集所有二级评论
second_comment_dict = {}
for comment in second_root:
if comment.xpath('./div[2]/ul/li[3]/a/@href'): # 空字符串是广告
# print(comment.xpath('./div[2]/ul/li[3]/a/text()'))
# print(root_url + comment.xpath('./div[2]/ul/li[3]/a/@href')[0])
print(comment.xpath('./div[3]/div[1]/cc/div[2]')[0].xpath("string(.)").strip())
second_comment_dict = {
'user': comment.xpath('./div[2]/ul/li[3]/a/text()'), # 用户名
'user_url': root_url + comment.xpath('./div[2]/ul/li[3]/a/@href')[0], # 用户主页
'comment': comment.xpath('./div[3]/div[1]/cc/div[2]')[0].xpath("string(.)").strip()
} # 评论内容
if second_comment_dict not in second_comments: # 去重
second_comments.append(second_comment_dict)
base_comment[first_pagesize]['second_level'] = second_comments
second_pagesize += 1 # 二级评论数
print('下一条评论')
first_pagesize += 1 # 贴子条数
print('下一条帖子')
page_first += 1 # 贴吧页数
print('下一页帖吧')
print('over!')
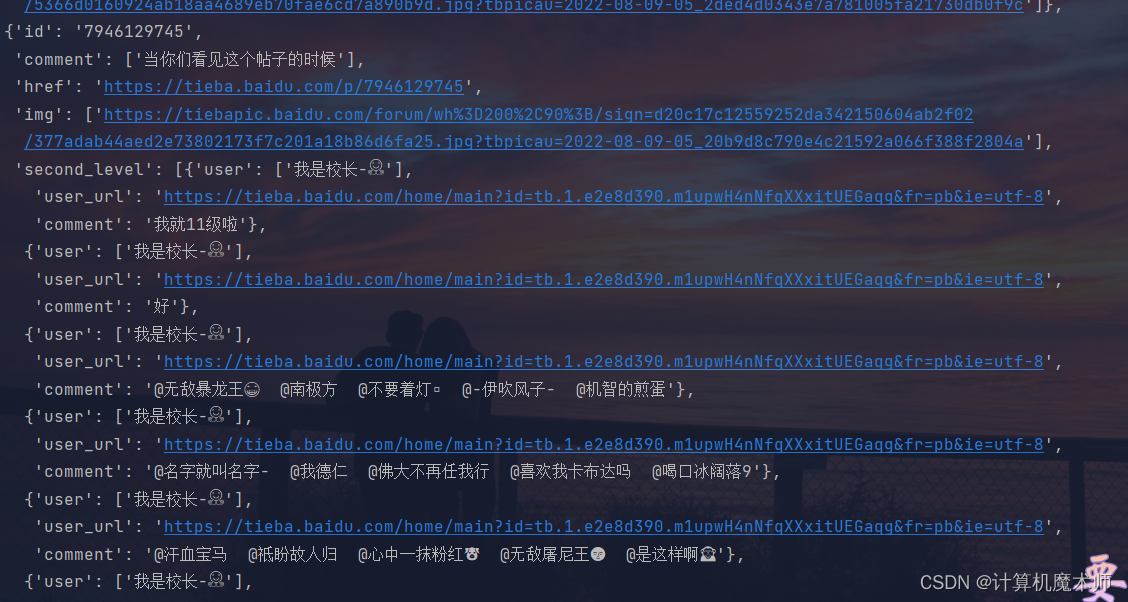
爬取数据结果:
注意: 爬取只做舆情监控,不做其他用途,不要用于恶意爬取(爬取次数多,某吧也会出现安全验证)
二、构建数据表
创建应用后,我们根据爬取数据格式建立表格:
{'id': '7946129745', //贴吧id
'comment': ['当你们看见这个帖子的时候'], //标题
'href': 'https://tieba.baidu.com/p/7946129745', // 贴吧链接
'img': //图片
['https://tiebapic.baidu.com/forum/wh%3D200%2C90%3B/sign=d20c17c12559252da342150604ab2f02/377adab44aed2e73802173f7c201a18b86d6fa25.jpg?tbpicau=2022-08-09-05_20b9d8c790e4c21592a066f388f2804a'],
'second_level':
[{'user': ['我是校长-🤗'], // 评论用户
'user_url': 'https://tieba.baidu.com/home/main?id=tb.1.e2e8d390.m1upwH4nNfqXXxitUEGaqg&fr=pb&ie=utf-8', // 用户信息地址
'comment': '我就11级啦'}, // 品论内容
{'user': ['我是校长-🤗'], // 多份评论
····
},
····
]
}
建立如下表以存贮舆情数据:
- 贴吧用户 ( 从评论中获取)
a. 用户名
b. 贴吧用户url
代码:
class Baidu_User(models.Model):
"""
a. 用户名
b. 贴吧用户`url`
"""
username = models.CharField(max_length=128, verbose_name='贴吧用户名', blank=True, null=True)
url = models.CharField(max_length=200, verbose_name='贴吧用户信息', blank=True, null=True)
create_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
modify_time = models.DateTimeField(auto_now=True, verbose_name='修改时间')
def __str__(self):
return self.username
class Meta:
db_table = "baidu_user"
verbose_name = _('贴吧用户')
verbose_name_plural = _('贴吧用户') # 复数形式
- 帖子 ( 从最外层获取)
a. 帖子唯一id
b. 帖子标题
c. 帖子照片
d. 帖子路由url
class Baidu_Post(models.Model):
"""
a. 帖子唯一`id`
b. 帖子标题
c. 帖子照片路由
d. 帖子路由`url`
e. 一对多外键 → 评论
"""
post_id = models.CharField(max_length=128, verbose_name='帖子ID', blank=True)
title = models.CharField(max_length=1024, verbose_name='标题', blank=True)
img_url = models.CharField(max_length=2048, verbose_name='图片', blank=True)
url = models.CharField(max_length=200, verbose_name='帖子地址', blank=True)
create_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
modify_time = models.DateTimeField(auto_now=True, verbose_name='修改时间')
def __str__(self):
return self.title
class Meta:
db_table = "baidu_post"
verbose_name = _('贴子')
verbose_name_plural = _('帖子') # 复数形式
- 评论
a. 一对一外键 → 贴吧用户
b. 内容
c. 多对一外键 → 帖子
class Baidu_Comment(models.Model):
"""
a. 一对一外键 → 贴吧用户
b. 内容
c. 多对一外键 → 帖子
"""
baidu_user = models.OneToOneField(Baidu_User, on_delete=models.CASCADE, related_name="comment", verbose_name='某度用户')
comment = models.CharField(max_length=2048, verbose_name='评论', blank=True)
baidu_post = models.ForeignKey(Baidu_Post, on_delete=models.CASCADE, related_name="comment", verbose_name='对应帖子')
create_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
modify_time = models.DateTimeField(auto_now=True, verbose_name='修改时间')
def __str__(self):
return self.comment
class Meta:
db_table = "baidu_comment"
verbose_name = _('评论')
verbose_name_plural = _('评论') # 复数形式
数据迁移并在后台注册
三、并入项目
可以先以视图函数作为测试
1. spider代码
from django.shortcuts import render
# Create your views here.
from lxml import etree # 导入所需模块
import requests, re
from .models import Baidu_User, Baidu_Post, Baidu_Comment
from django.contrib import messages
from django.shortcuts import HttpResponseRedirect
root_url = "https://tieba.baidu.com"
headers = {
'Cookie': '你的cookie',
'Accept': 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
# 二级评论参数
second_page = 1 # 默认只爬取第一页
param_second = {
'pn': str(second_page)
}
# @register_job(scheduler, 'interval', id='baidu', minutes=1)
def async_collect_baidu():
# 获取帖吧内容
# base_comment = []
page_first = 0 # 第一页
while page_first < 5: # 默认爬取五页
resp = requests.get('https://tieba.baidu.com/f?kw=佛山科学技术学院&ie=utf-8' + f'&pn={page_first * 50}',
headers=headers)
html_baidu = resp.content.decode('utf-8') # 手动解码 text默认返回猜测的解码方式
# 根路由
tree_baidu = etree.HTML(html_baidu)
divs_daidu = tree_baidu.xpath('//*[@id="thread_list"]/li')
# 获取帖子字典
for div in divs_daidu:
dict_temp = {}
if bool(div.xpath('./div/div[2]/div[1]/div[1]/a/@href')):
dict_temp['id'] = re.sub(r'/p/', '', div.xpath('./div/div[2]/div[1]/div[1]/a/@href')[0])
dict_temp['comment'] = div.xpath('./div/div[2]/div[1]/div[1]/a/text()')
dict_temp['href'] = root_url + div.xpath('./div/div[2]/div[1]/div[1]/a/@href')[0]
dict_temp['img'] = div.xpath(
f'//*[@id="fm{re.sub(r"/p/", "", div.xpath("./div/div[2]/div[1]/div[1]/a/@href")[0])}"]/li/a/img/@data-original')
# base_comment.append(dict_temp)
# 保存到数据库
if not Baidu_Post.objects.filter(post_id=dict_temp['id']).first():
baidu_post = Baidu_Post.objects.create(
post_id=dict_temp['id'],
title=dict_temp['comment'][0],
url=dict_temp['href'],
img_url=dict_temp['img']
)
baidu_post.save()
resp_second = requests.get(url=dict_temp['href'], params=param_second) # 获取响应
second_html = resp_second.content.decode('utf-8') # 获取源码
second_tree = etree.HTML(second_html) # 解析源代码
second_root = second_tree.xpath('//*[@id="j_p_postlist"]/div') # 获取节点树
second_comments = [] # 收集所有二级评论
second_comment_dict = {}
for comment in second_root:
if comment.xpath('./div[2]/ul/li[3]/a/@href'): # 空字符串是广告
second_comment_dict = {
'user': comment.xpath('./div[2]/ul/li[3]/a/text()'), # 用户名
'user_url': root_url + comment.xpath('./div[2]/ul/li[3]/a/@href')[0], # 用户主页
'comment': comment.xpath('./div[3]/div[1]/cc/div[2]')[0].xpath("string(.)").strip()
} # 评论内容
if second_comment_dict not in second_comments: # 去重
second_comments.append(second_comment_dict)
# 保存到数据库
if not bool(Baidu_User.objects.filter(url=second_comment_dict['user_url']).first()) and bool(second_comment_dict['user'][0]):
baidu_user = Baidu_User.objects.create(
username=second_comment_dict['user'][0],
url=second_comment_dict['user_url']
)
baidu_user.save()
baidu_comment = Baidu_Comment.objects.create(
baidu_user=baidu_user,
comment=second_comment_dict['comment'],
baidu_post=baidu_post
)
baidu_comment.save()
print('帖子id: {},标题:{},帖子地址:{},图片:{},评论数:{}'.format(dict_temp['id'],
dict_temp['comment'],
dict_temp['href'],
dict_temp['img'],
len(second_comments)))
page_first += 1 # 贴吧页数
print('over!')
return HttpResponseRedirect('/admin')
2. view视图代码
from .baidu_spider import async_collect_baidu
from apscheduler.schedulers.background import BackgroundScheduler
from django_apscheduler.jobstores import DjangoJobStore
from datetime import datetime
# Create your views here.
# 监听的函数必须是视图函数,
def baidu_task():
print("[Apscheduler][Task](贴吧)--{}".format(datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")))
print('贴吧爬取任务开始')
async_collect_baidu()
# 5.开启定时任务
# 实例化调度器(后台运行,不阻塞)
scheduler = BackgroundScheduler()
# 调度器使用DjangoJobStore()
scheduler.add_jobstore(DjangoJobStore(), "default",) # 不添加数据库则没有进程
try:
print("定时任务启动...")
scheduler.add_job(baidu_task, trigger='cron', hour=12,timezone='Asia/Shanghai', id='贴吧',replace_existing=True)
scheduler.start()
except Exception as e:
print(e)
scheduler.shutdown()
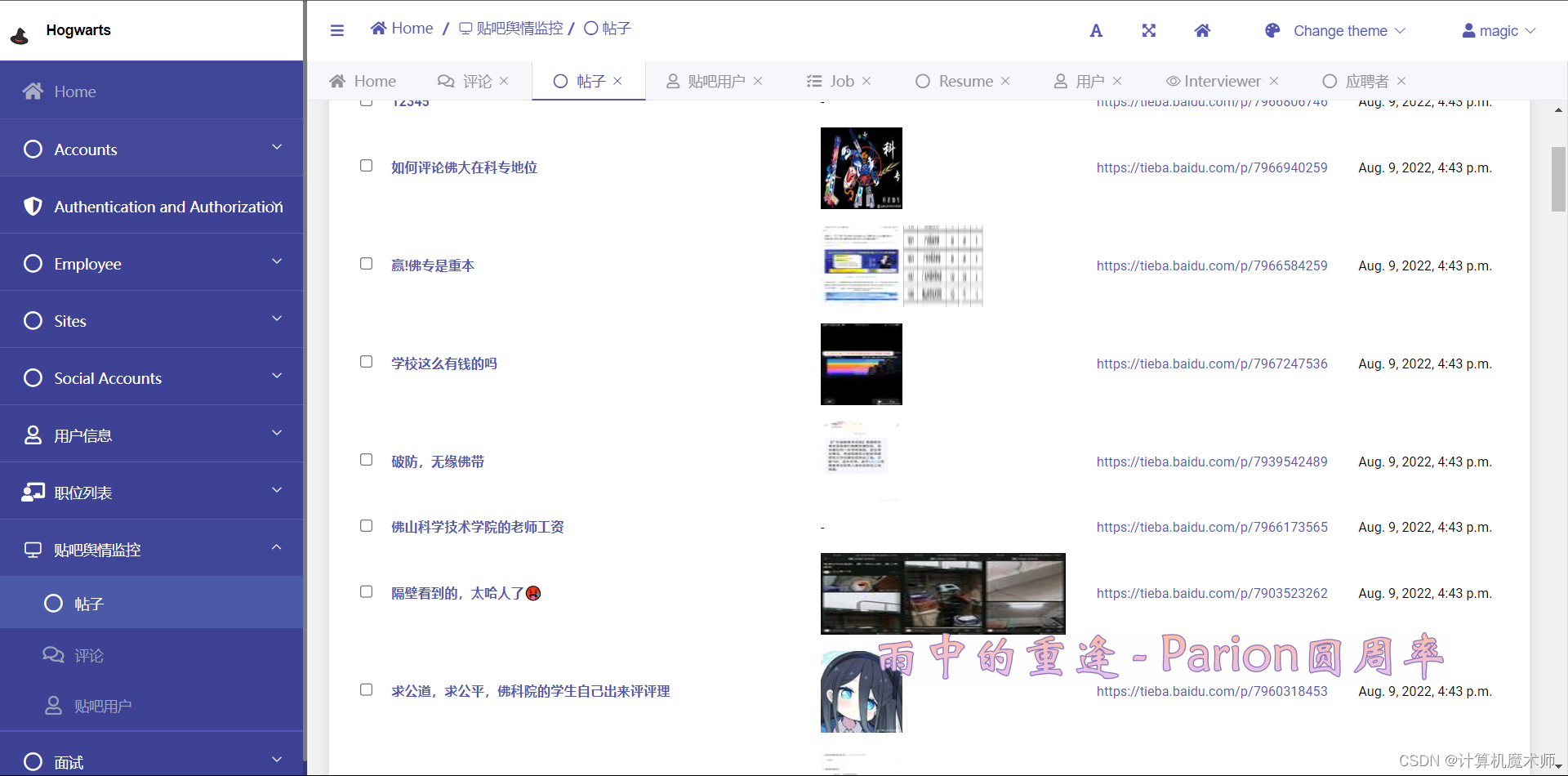
效果:
![💯:[图片]](https://img-blog.csdnimg.cn/56be1c2a375c4f8a8171e8892e587d6a.png)
![💯:[图片]](https://img-blog.csdnimg.cn/069b48c335984d0cb17451c3e3a23e17.png)
3. 优化后台界面
admin 代码
from django.contrib import admin
from .models import Baidu_User, Baidu_Post, Baidu_Comment
from django.utils.safestring import mark_safe
import re
# Register your models here.
# 嵌入外键
class TiebaCommentInline(admin.StackedInline):
model = Baidu_Comment
readonly_fields = ['baidu_user', 'comment', 'baidu_post', ]
class TiebaPostInline(admin.StackedInline):
model = Baidu_Post
readonly_fields = ['post_id', 'title', 'url', ]
class TiebaUserInline(admin.StackedInline):
model = Baidu_User
readonly_fields = ['username', 'url', ]
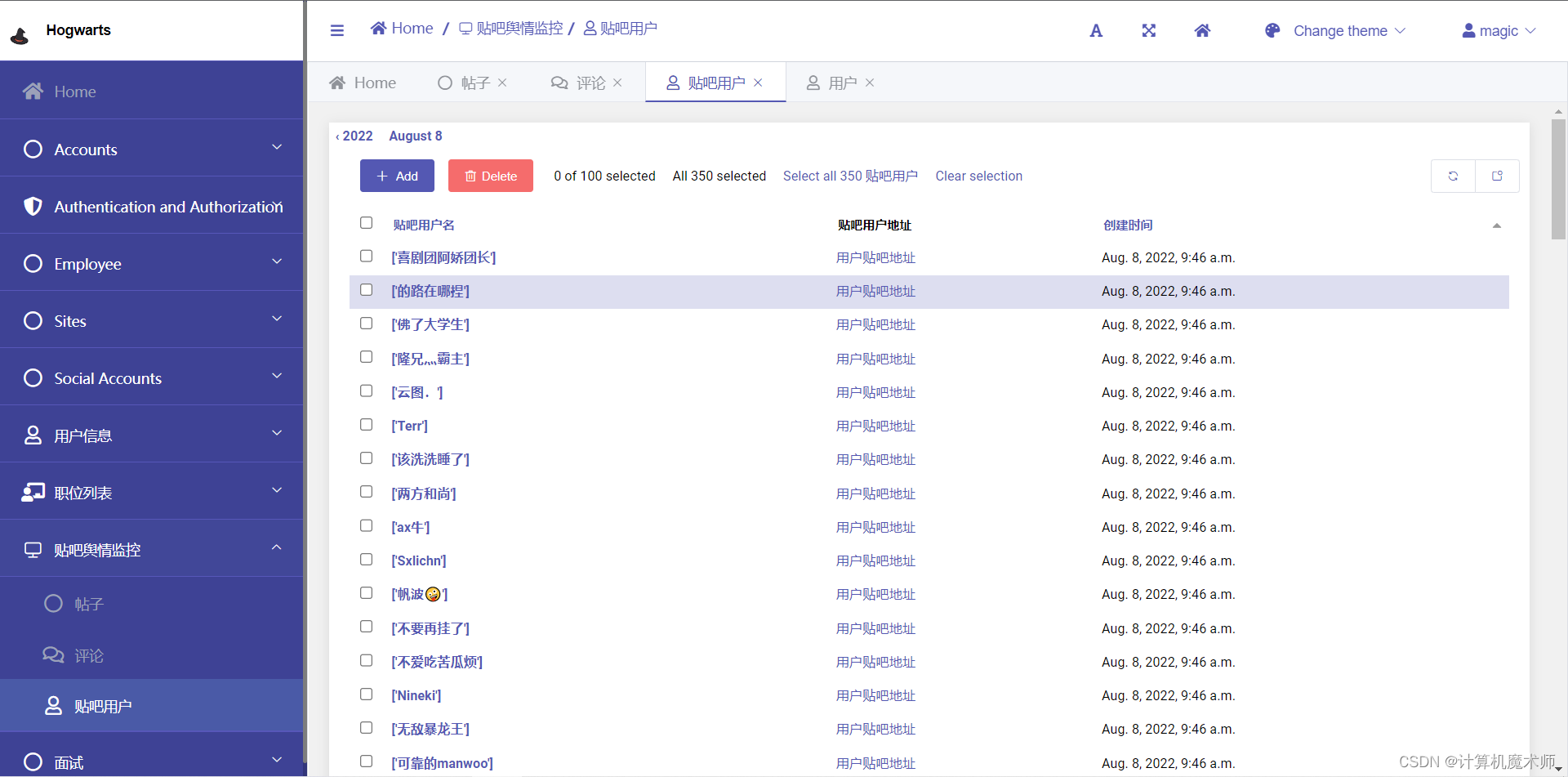
@admin.register(Baidu_User)
class Baidu_UserAdmin(admin.ModelAdmin):
# 展示列表
list_display = ('username', 'url_tag', 'create_time')
list_display_links = ('username',)
readonly_fields = ['username', 'url', ]
date_hierarchy = 'create_time' # 根据创建时间划分等级
ordering = ['-create_time', ] # 默认按照最新时间排序
search_fields = ('username',) # 设置搜索栏范围,如果有外键,要注明外键的哪个字段,双下划线
search_help_text = '搜索用户' # 搜索提示文本, 默认为False
list_filter = ['create_time', ]
inlines = [TiebaCommentInline, ]
def url_tag(self, obj):
if obj.url:
return mark_safe( # obj.picture 是相对路径, obj.picture.url是完整路径
f'<a href="{obj.url}" target="_blank" >用户贴吧地址</a>')
return '-'
url_tag.short_description = '贴吧用户地址'
@admin.register(Baidu_Post)
class Baidu_PostAdmin(admin.ModelAdmin):
# 展示列表
list_display = ('title', 'img_tag', 'url_tag', 'create_time')
# list_display_links = ('title',)
exclude = ('img_url',)
search_fields = ('title',) # 设置可搜索内容
search_help_text = '搜索帖子' # 搜索提示文本, 默认为False
readonly_fields = ['post_id', 'title', 'url', ]
date_hierarchy = 'create_time' # 根据创建时间划分等级
ordering = ['-create_time', ] # 默认按照最新时间排序
inlines = [TiebaCommentInline, ]
list_filter = ['create_time', ]
def img_tag(self, obj):
img_html = ''
if obj.img_url != '[]':
temp = re.sub("'", '520', obj.img_url)
img_list = re.findall('520(.*?)520', temp) # 在字符串提取内容
for img in img_list:
img_html += f'<image src="{img}" style="width:80px; height:80px;" alt="图片" />'
return mark_safe(img_html)
return '-'
img_tag.short_description = '帖子图片'
def url_tag(self, obj):
if obj.url:
return mark_safe(f"<a href='{obj.url}' target='_blank'>{obj.url}</a>")
return '-'
url_tag.short_description = "帖子地址"
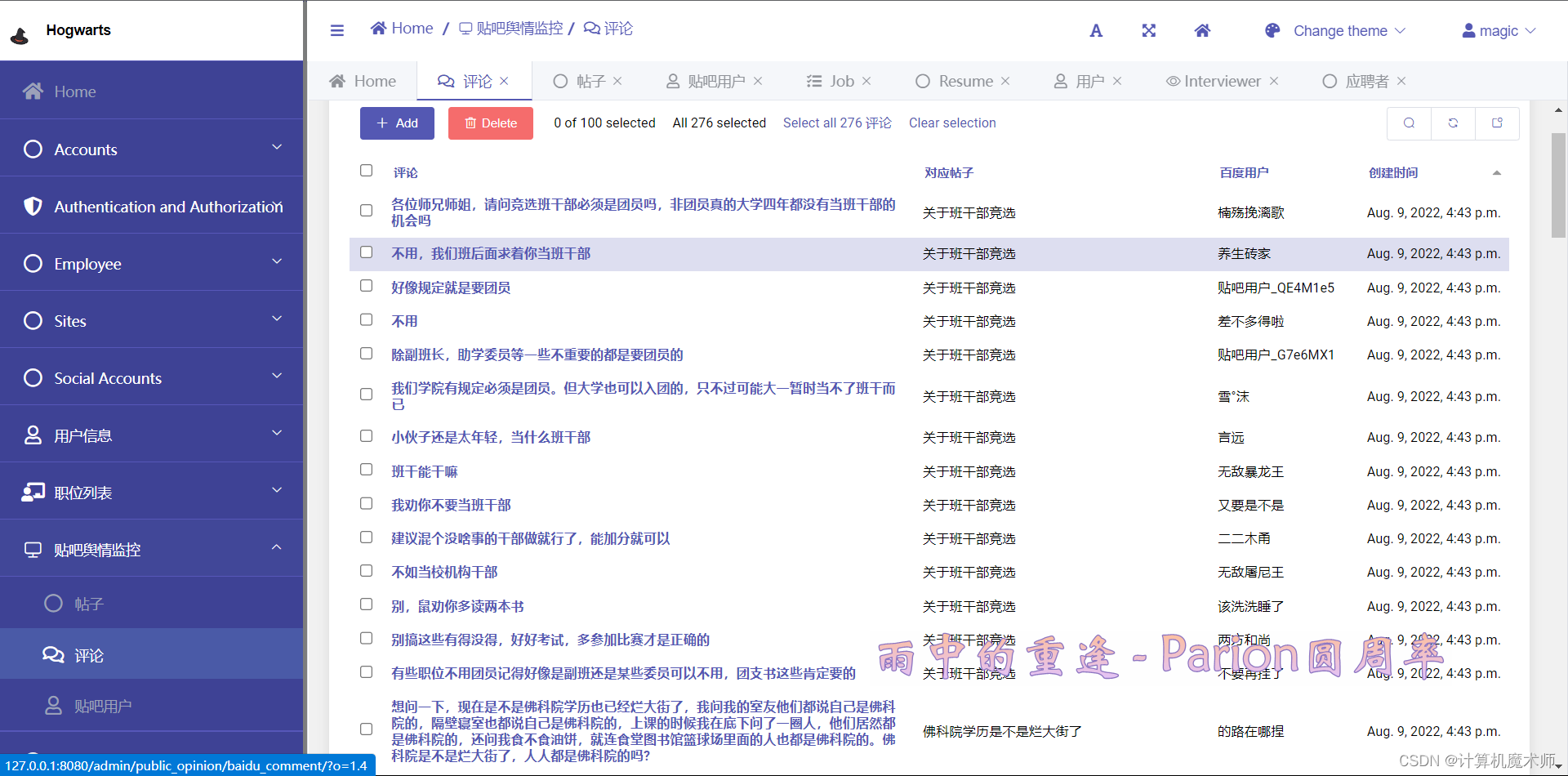
@admin.register(Baidu_Comment)
class Baidu_CommentAdmin(admin.ModelAdmin):
# 展示列表
list_display = ('comment', 'baidu_post', 'baidu_user', 'create_time')
# list_display_links = ('comment',)
search_fields = ('comment', 'baidu_user__username', 'baidu_post__title') # 设置搜索栏范围,如果有外键,要注明外键的哪个字段,双下划线
search_help_text = '搜索帖子评论或者用户评论记录' # 搜索提示文本, 默认为False
readonly_fields = ['baidu_user', 'comment', 'baidu_post', ]
date_hierarchy = 'create_time' # 根据创建时间划分等级
ordering = ['-create_time', ] # 默认按照最新时间排序
list_filter = ['create_time', ]
效果:
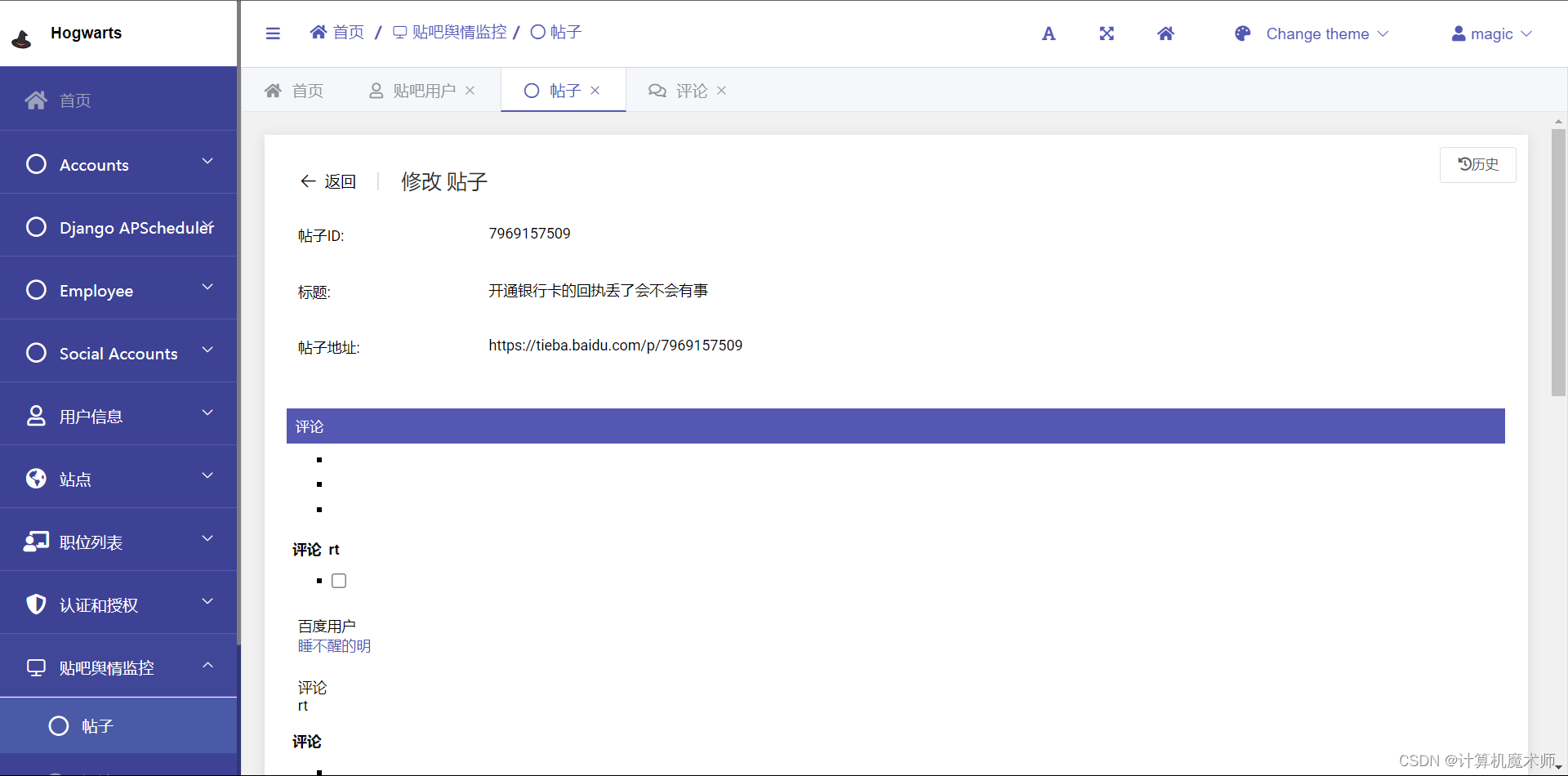
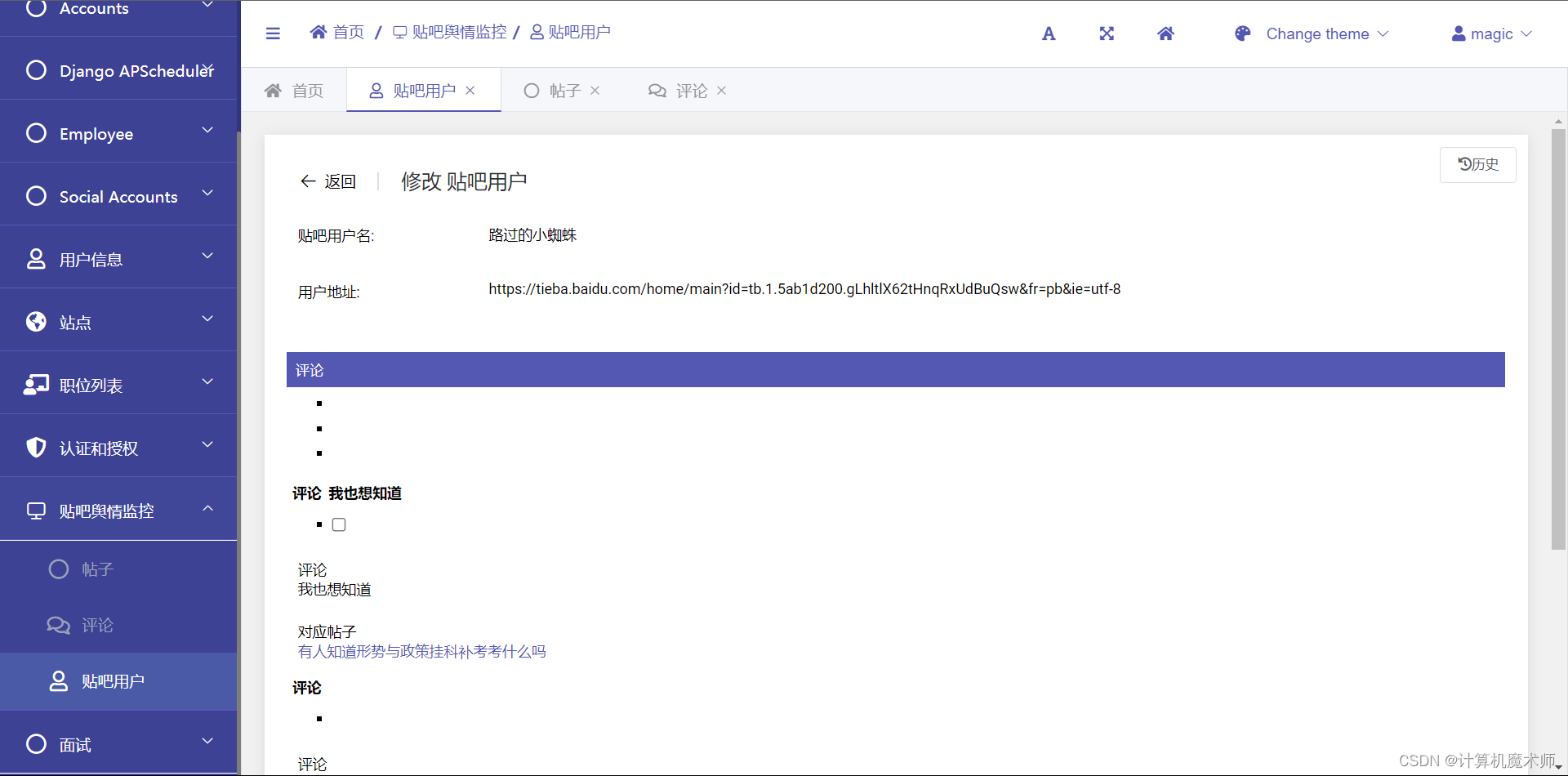
3. urls路由
from django.contrib import admin
from django.urls import re_path
from . import views
app_name = 'public_opinion'
urlpatterns = [
re_path(r'^$', views.collect_baidu, name="crawler")
]
测试效果
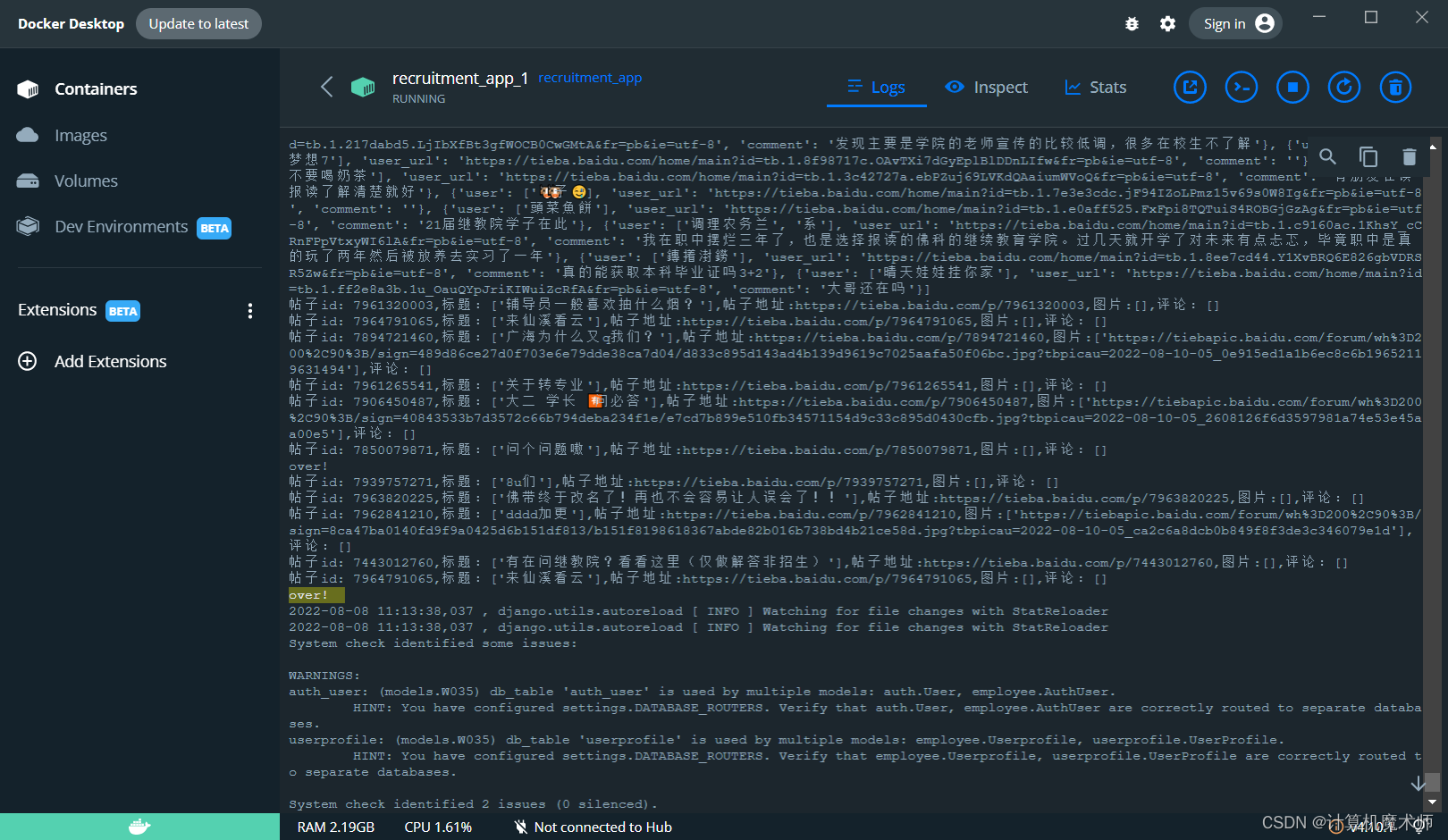
四、定时任务爬取
定时爬取某吧评论进行舆情监控
4.1 安装
官方的 github地址 https://github.com/jcass77/django-apscheduler
官方文档https://apscheduler.readthedocs.io/en/latest/userguide.html#choosing-the-right-scheduler-job-store-s-executor-s-and-trigger-s
pip install django-apscheduler`
4.2 配置
在 setting.py 的 app 里面加入
INSTALLED_APPS = (
# ...
"django_apscheduler",
)
apscheduler 存在数据库依赖. migrate 一下
会在数据库中生成两行表

表结构在下面的使用中再说
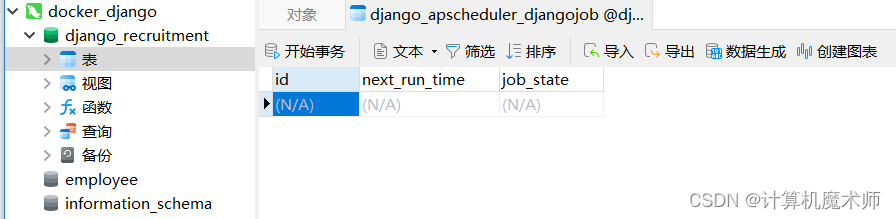

4.3 简单的原理解释
注册后的任务会根据 id 以及相关的配置进行定时任务, 定时任务分为两种
定时循环任务 (循环不断触发 比如每 20s 执行一次)
定点执行任务 (只触发一次 比如 周一执行一次)
定时定点循环任务 (比如 每周一执行一次)
任务的执行存在撞车的可能性, 即上一次任务没执行完, 下次任务就来了
此时下次任务会被错过 (missed) 上次任务不执行完. 下次任务永远都会错过
4.4 书写代码
可以在任意view.py中实现代码 ( 通常习惯将所有定时任务放在一个APP里),可能会莫名不运行定时任务,见文章末问题解决
这里设置为每天早上8:30定时爬取评论!
- 装饰器
from apscheduler.schedulers.background import BackgroundScheduler
from django_apscheduler.jobstores import register_job
# 实例化调度器(后台运行,不阻塞)
scheduler = BackgroundScheduler()
scheduler.add_jobstore(DjangoJobStore(), "default") # 不添加数据库则没有进程
try:
# 设置定时任务
@register_job(scheduler, 'cron', id='baidu', hour=8, minute=30)
def collect_baidu():
pass
# 5.开启定时任务
scheduler.start()
except Exception as e:
print(e)
# 有错误停止运行
scheduler.shutdown()
- 方法(建议)
# 5.开启定时任务
# 实例化调度器(后台运行,不阻塞)
scheduler = BackgroundScheduler()
# 2.调度器使用DjangoJobStore()
scheduler.add_jobstore(DjangoJobStore(), "default")# 不添加数据库则没有进程
scheduler.add_job(async_collect_baidu, trigger='interval', minutes=1, id='async_collect_baidu') # 注意 minutes 是复数
scheduler.start()
接着注释掉用于测试的路由url
4.5 执行结果查看
在admin 里面查看也较为方便, 对 admin 进行了相应的封装方便过滤啥的, 以及状态清晰
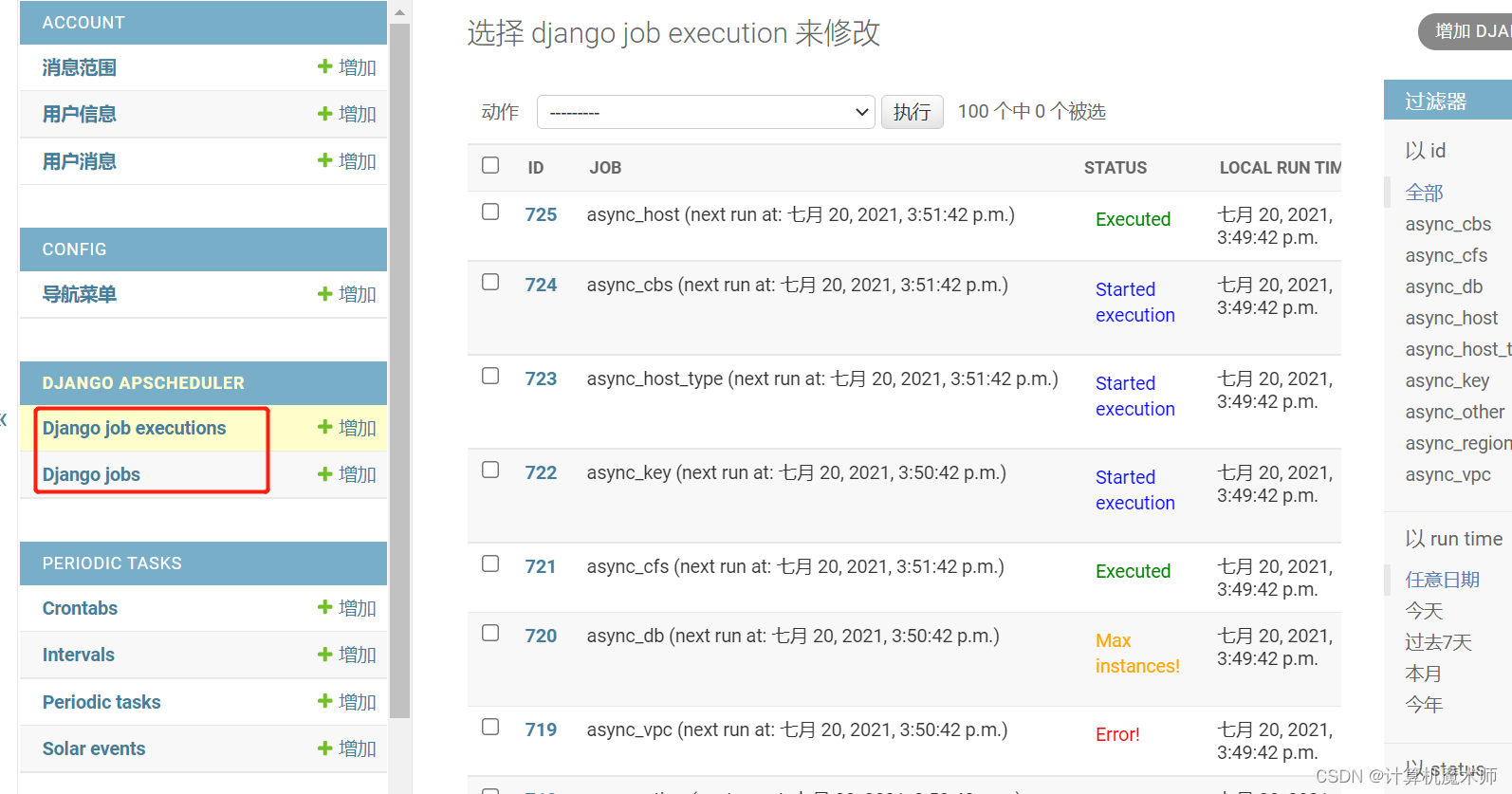
django_apscheduler_djangojob 表保存注册的任务以及下次执行的时间
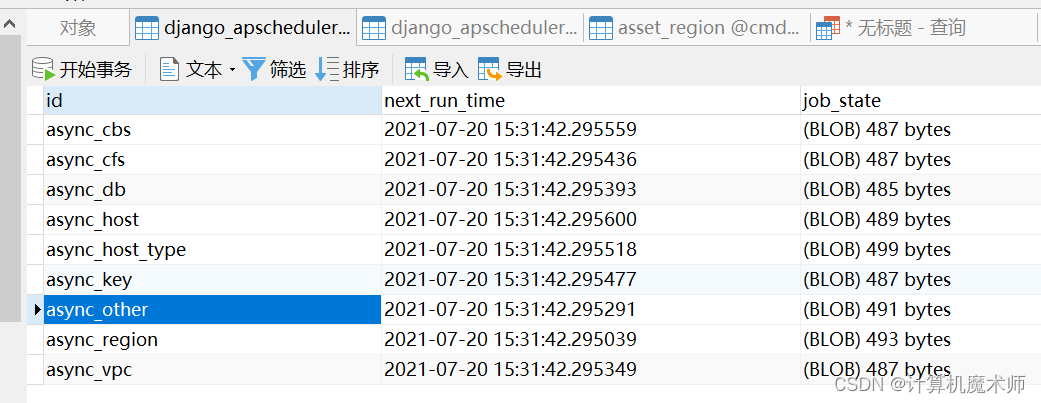
django_apscheduler_djangojobexecution 保存每次任务执行的时间和结果和任务状态
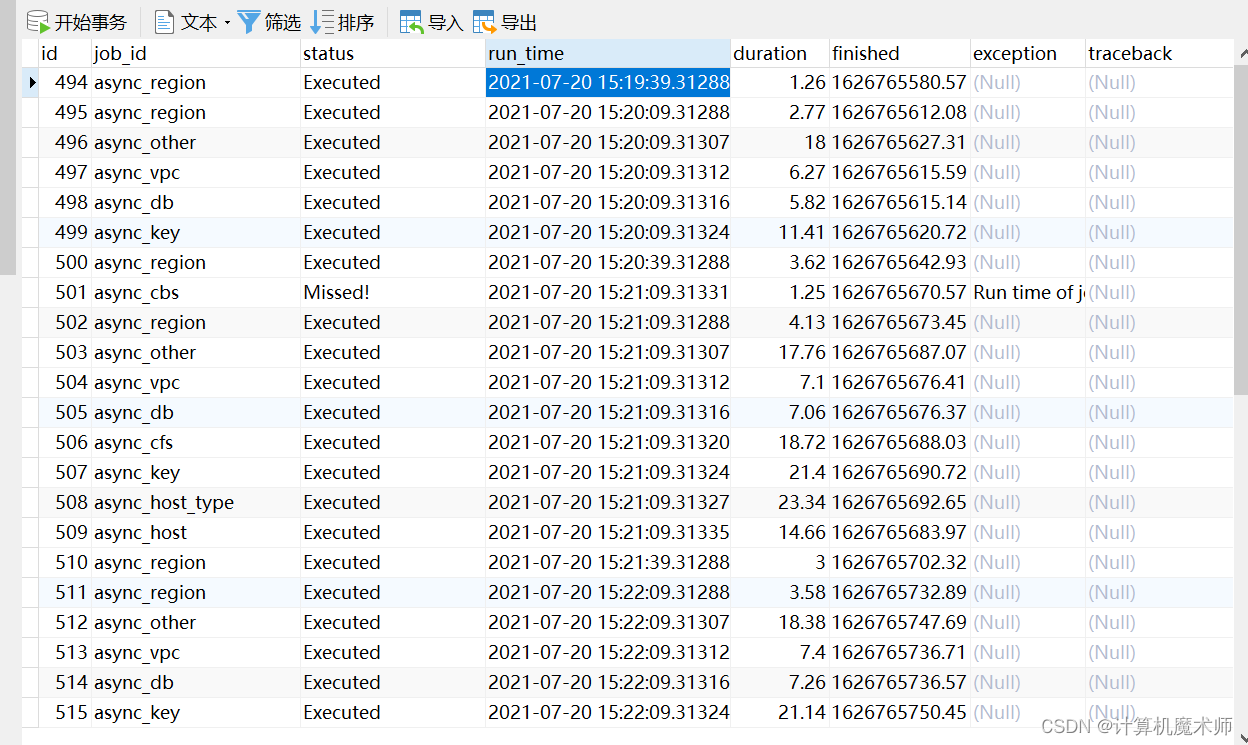
这里注意 missed 则是表示撞车的场景, 为避免这种场景需要在 周期的长度以及是否进行强制结束进行选择
4.6 其他问题
- APScheduler 在 uwsgi 环境下会有存在复数个进程同时启用的问题, 从而重复执行占用资源
解决方式 姊妹篇, 最后面使用socket解决了该问题
舆情监测(某吧评论定期生成词云图)
- django定时任务没有运行
原因:创建了一个app,但是没有运行,这是因为这个app的view只有一个函数,没有连接在django进程,没有经过该view,
解决方式:
在任意django进程中添加
from app improt views 导入即可
建议在项目路由导入应用路由,再由路由导入视图函数,将应用于项目分离
- 应用
url
from . import view
# from . import views
app_name = 'public_opinion'
urlpatterns = [
]
- 项目
url( 添加路由为"",这样服务器一启动就会自动启动定时任务)
urlpatterns = [
path('', include('public_opinion.urls')),
]
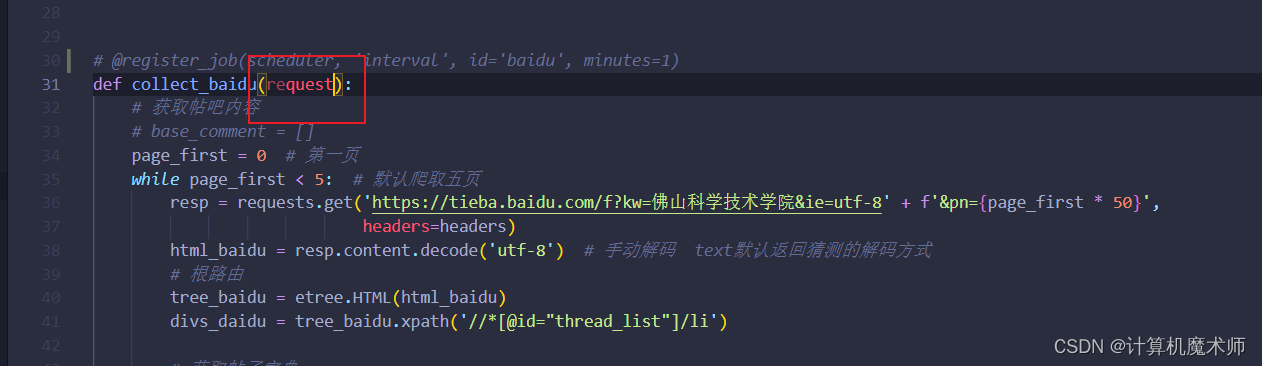
- ValueEerror

解决方式:
删掉request
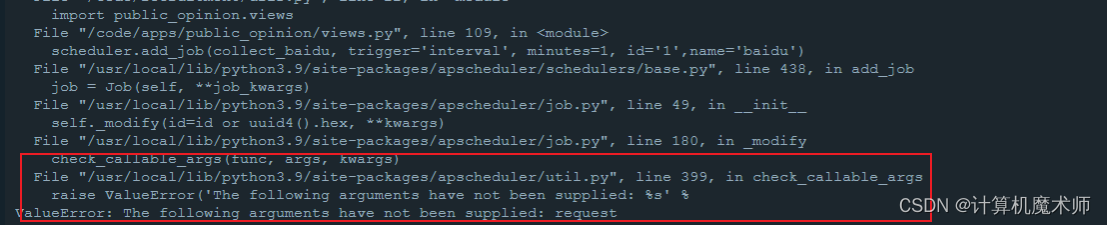
参考文章:
博客园定时任务参考文章
csdn定时任务讲解文章
源码讲解文章
腾讯云定时任务详解
博主正在参加年度博客之星评选呀,请大家帮我投票打分,您的每一分都是对我的支持与鼓励🥰🥰
http://t.csdn.cn/mUABI
下一篇 : 姊妹篇
舆情监测(某吧评论定期生成词云图)
敬请期待!

- 点赞
- 收藏
- 关注作者
评论(0)