归并排序详解(递归+非递归两种版本实现)

归并排序
接下来我们来学习归并排序:
其实归并排序的思想我们在之前做题的过程中也用到过,之前文章里我们有讲过一些顺序表和链表相关的习题,合并两个有序链表 还有 合并两个有序数组,解这两道题我们其实就用到了归并的思想。 就拿合并两个有序链表那个题来说,我们是怎么做的: 两个指针分别遍历两个链表,依次取小的尾插,最终就将两个链表合并成一个有序链表(升序)。 这其实就是归并的思想。
基本思想
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
1. 递归版本
思路讲解
那归并排序具体要怎么搞呢?(还是以升序举例)
我们上面提到的合并两个有序链表那种题目,虽然用的是归并的思想,但是是不是有一个前提啊,前提就是两个链表原本就是有序的,所以从前往后遍历才能依次取到从大到小的数据。
但是: 如果现在随便给我们一组数据,让我们对它进行归并排序,是不是没法直接搞啊? 我们可以从中间把它分成两个部分,但是这两组数据一定是有序的吗? 🆗,是不是不是有序的啊,就是需要我们排呢。
那应该怎么办?
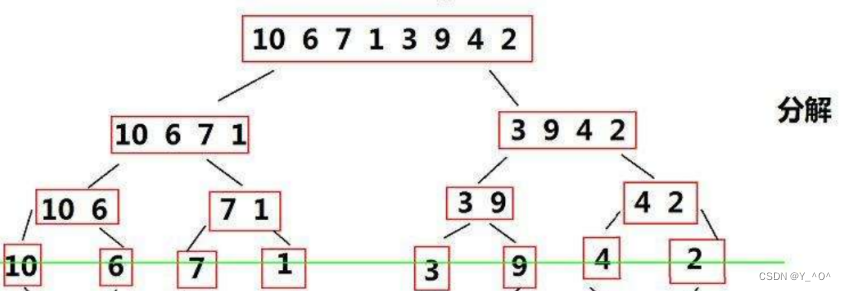
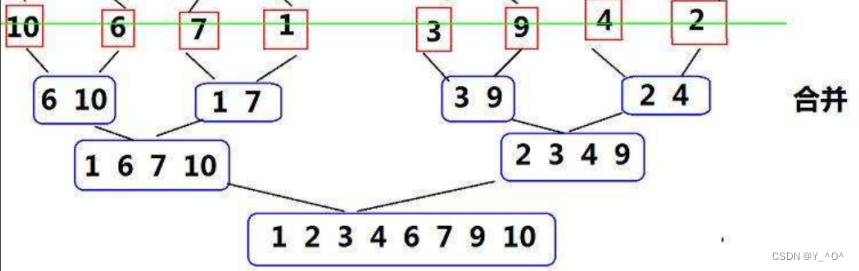
我们是不是还可以考虑用递归来搞。 现在有一组数据,我们的思路是什么呢? 首先可以从中间把它分为两组,如果这两组数据都变成有序的话,我们是不是就可以对它们进行归并了,归并之后整体不就有序了嘛。 那现在问题来了,如何让它的左右两个区间变得有序? 🆗,让它的两个左右区间有序,是不是又是与原问题类似但规模较小的子问题啊,那我们就可以递归了,递归的主要思想是啥,就是大事化小。 所以呢,我们对它的左右区间再划分,但是左右区间又各划分成两个子区间,是不是还是需要先把子区间变有序,然后才能归并啊。 所以我们可以要进行多次划分,不断分割成子问题,那啥时候结束呢? 当被划分出来的区间只有一个数时,只有一个数,那是不是就可以认为它是一个有序区间了,那我们就可以开始一层一层的往回合并了。 将所有的区间归并完,排序也就完成了。
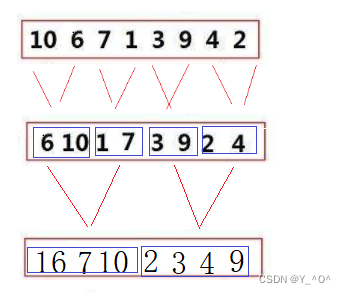
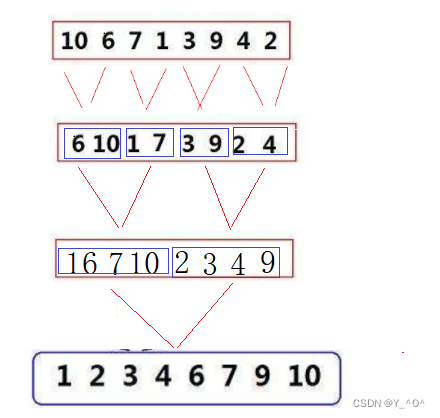
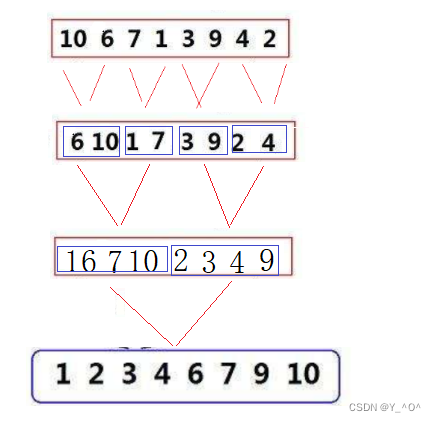
举个栗子: 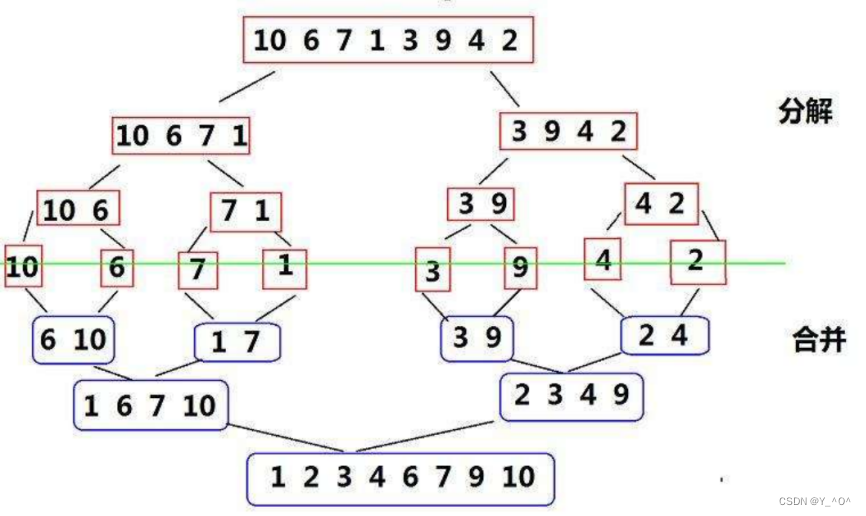 大家可以看一下这张图,这就是对一组数据进行归并排序的一个大致过程。
大家可以看一下这张图,这就是对一组数据进行归并排序的一个大致过程。
这里呢,也有一个动图大家可以看一下: 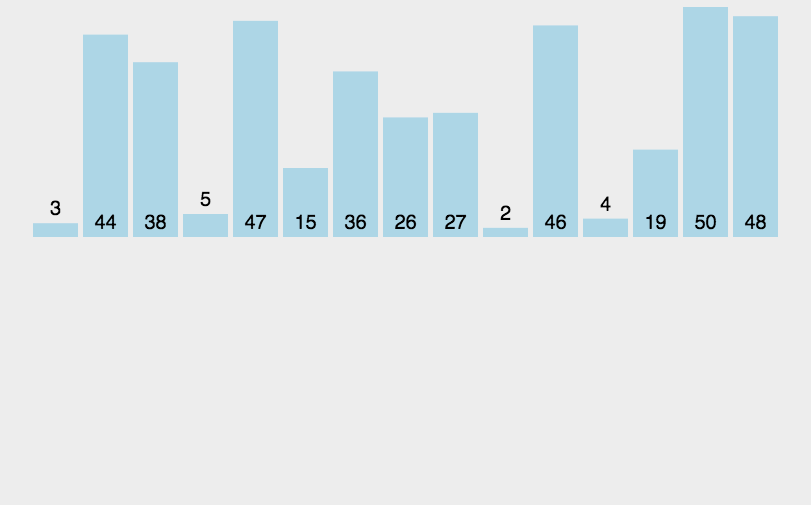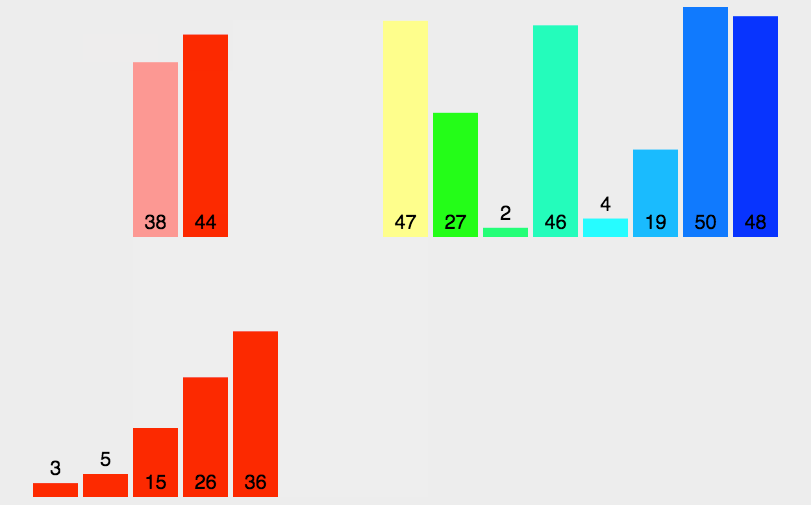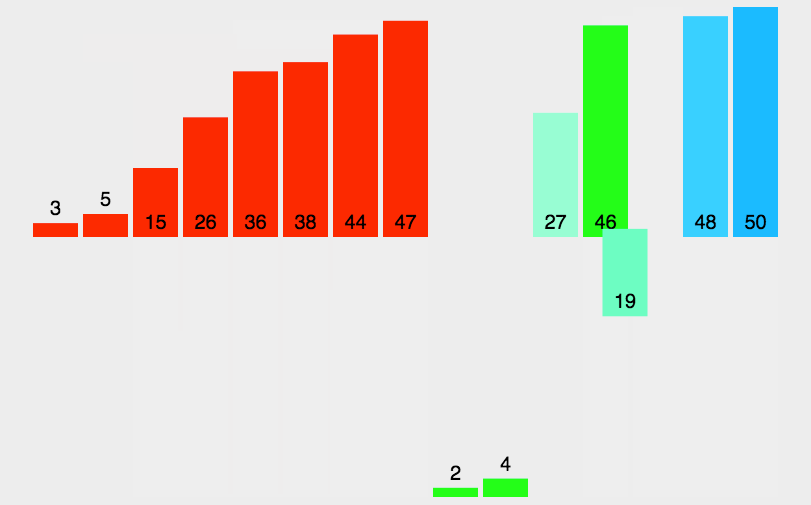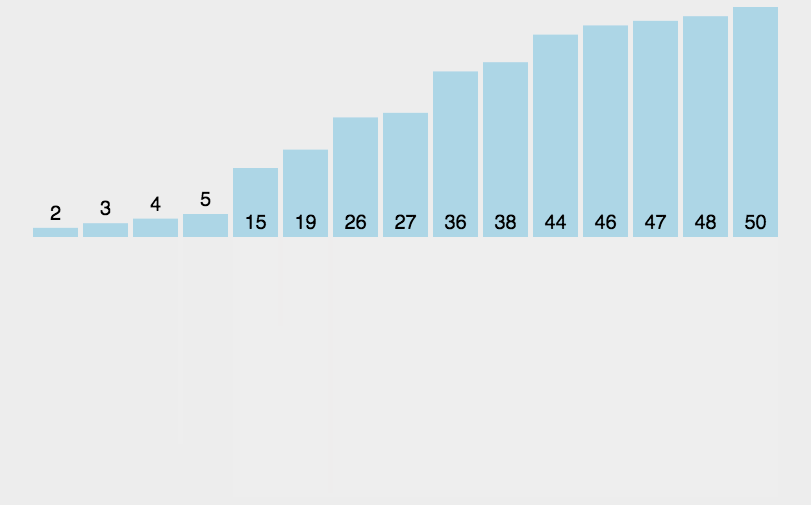
复杂度计算
该算法的基本思想我们理解了,我们来计算一下它的复杂度:
来看这张图: 我们对原始数据一直分解,直到分割成不可再分的子问题,大家看如果我们像上面那样一直从正中间分,最后分解完毕是不是可以看成是一棵满二叉树。 那它的高度(层数)我们可以认为是log2N(logN),那每一层我们都要进行合并:
代码实现
那我们接下来就一起来一步一步地去实现一下归并排序的代码:
首先经过上面的分析,我们需要一个额外的数组来辅助我们完成归并排序,所以我们先开辟一个数组:

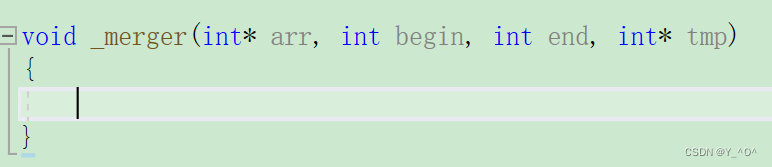


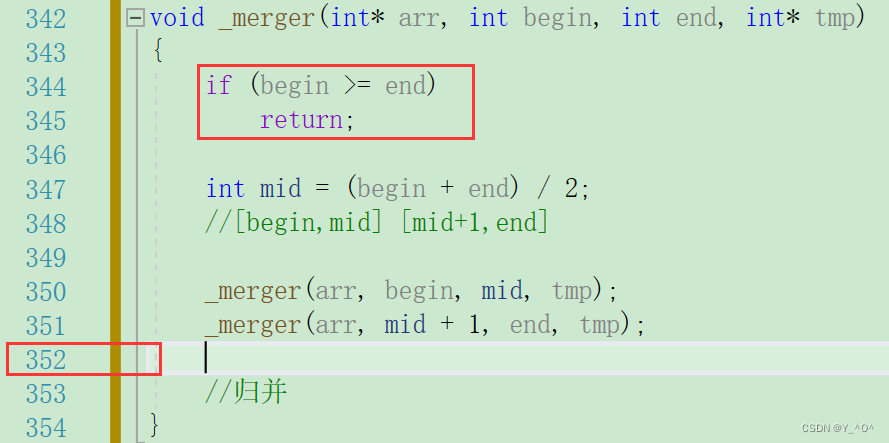


那到这里,整个归并排序就完成了:
void _merger(int* arr, int begin, int end, int* tmp)
{
if (begin >= end)
return;
int mid = (begin + end) / 2;
//[begin,mid] [mid+1,end]
_merger(arr, begin, mid, tmp);
_merger(arr, mid + 1, end, tmp);
//归并
int begin1 = begin;
int end1 = mid;
int begin2 = mid + 1;
int end2 = end;
int i = begin;
//归并,取小的尾插(升序)
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] <= arr[begin2])
{
tmp[i++] = arr[begin1++];
}
else
{
tmp[i++] = arr[begin2++];
}
}
//循环结束时哪个区间还有剩余数据,就把剩余数据续到后面
while (begin1 <= end1)
{
tmp[i++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = arr[begin2++];
}
//最后把排好数据再拷回原数组(只拷贝当前归并的区间)
memcpy(arr + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}
//归并排序
void merger(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
_merger(arr, 0, n - 1, tmp);
free(tmp);
tmp = NULL;
}我们来测试一下: 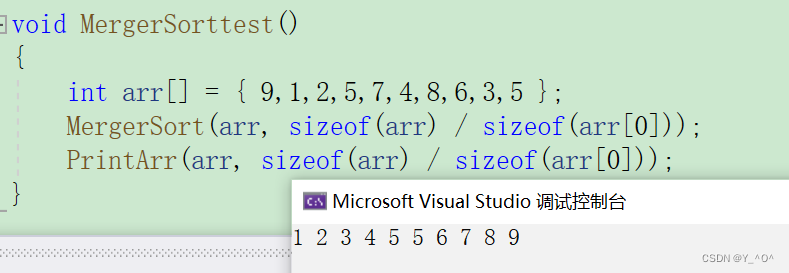 没问题。
没问题。
2. 非递归版本
接下来我们再来学习一下归并排序的非递归实现。
思路讲解
那归并排序不用递归,应该怎么实现呢?
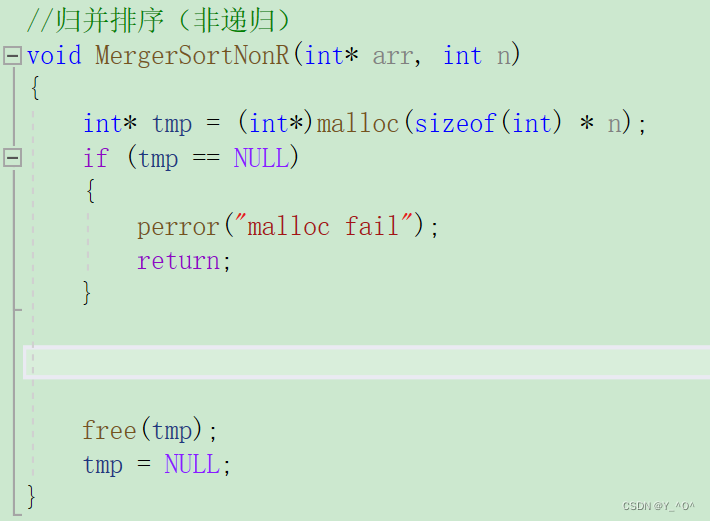
首先呢数组还是需要的:
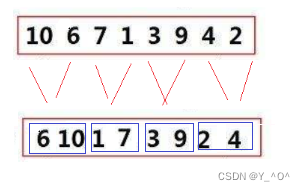
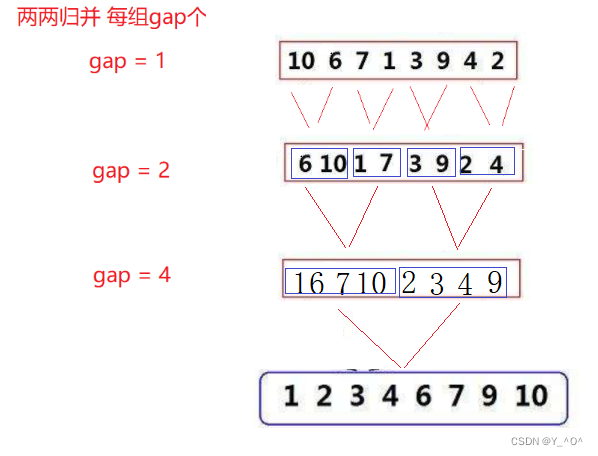
那现在不用递归,我们是不是可以反过来啊 <font color = red>先把原始数据一个一个分为一组,每组只有一个数据,那就可以认为是有序了,然后从前到后两两进行归并:


代码实现
那我们如何用代码控制着去走这个过程呢?
<font color = red>其实最不好搞的就是去控制好每次归并的区间的边界,那我们肯定还是搞一个循环,每次归并两组数据,每组数据的个数我们用gap控制,gap第一次是1

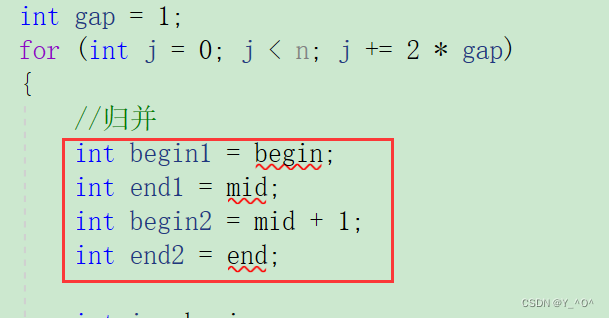

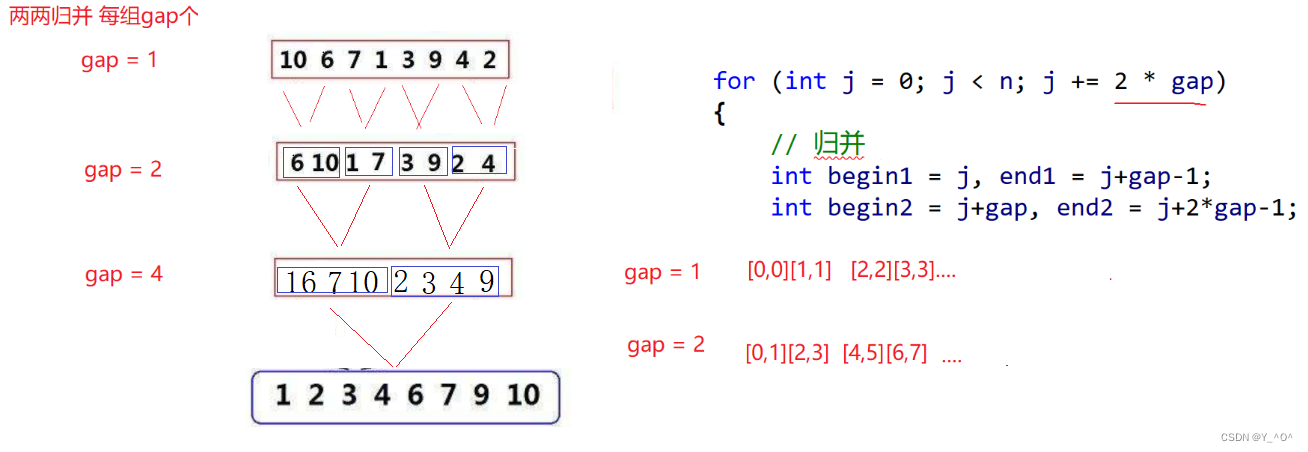
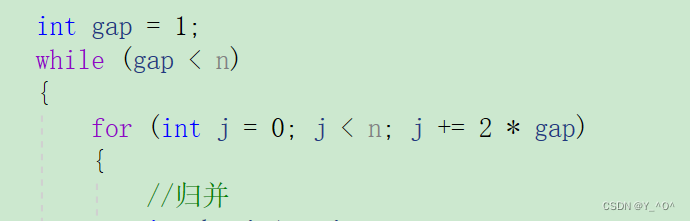

那代码应该是这样的:
//归并排序(非递归)
void MergerSortNonR(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
int gap = 1;
while (gap < n)
{
for (int j = 0; j < n; j += 2 * gap)
{
//归并
int begin1 = j;
int end1 = j + gap - 1;
int begin2 = j + gap;
int end2 = j + 2 * gap - 1;
int i = j;
//归并,取小的尾插(升序)
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] <= arr[begin2])
{
tmp[i++] = arr[begin1++];
}
else
{
tmp[i++] = arr[begin2++];
}
}
//循环结束时哪个区间还有剩余数据,就把剩余数据续到后面
while (begin1 <= end1)
{
tmp[i++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = arr[begin2++];
}
//最后把排好数据再拷回原数组(只拷贝当前归并的区间)
memcpy(arr + j, tmp + j, (end2 - j + 1) * sizeof(int));
}
gap *= 2;
}
free(tmp);
tmp = NULL;
}测试一下,就拿我们上面分析的那个例子: 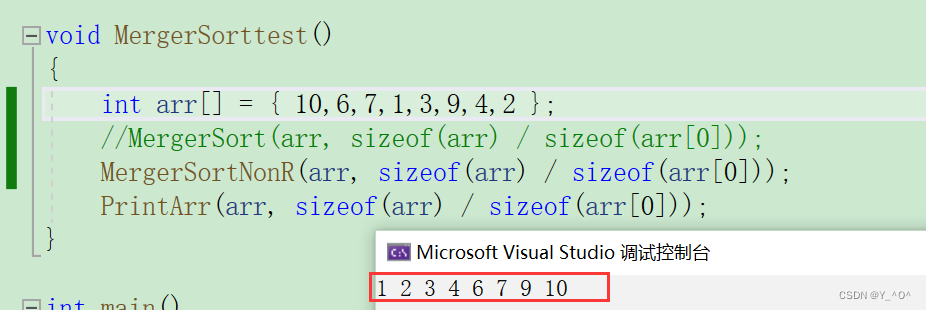 哦豁,确实排好了。
哦豁,确实排好了。
我们再测一组,在原数组上再加一个数: 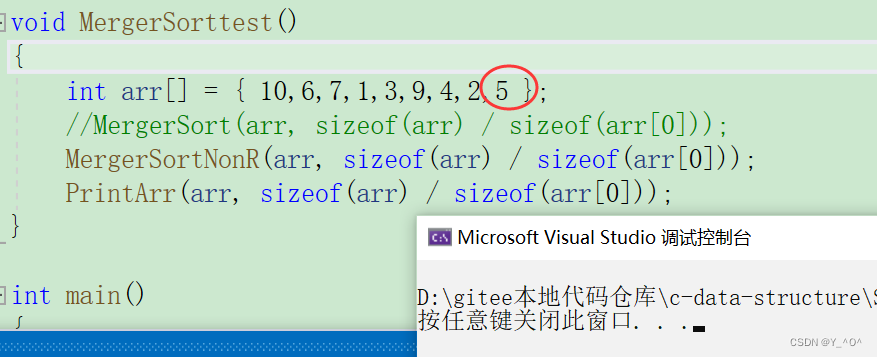
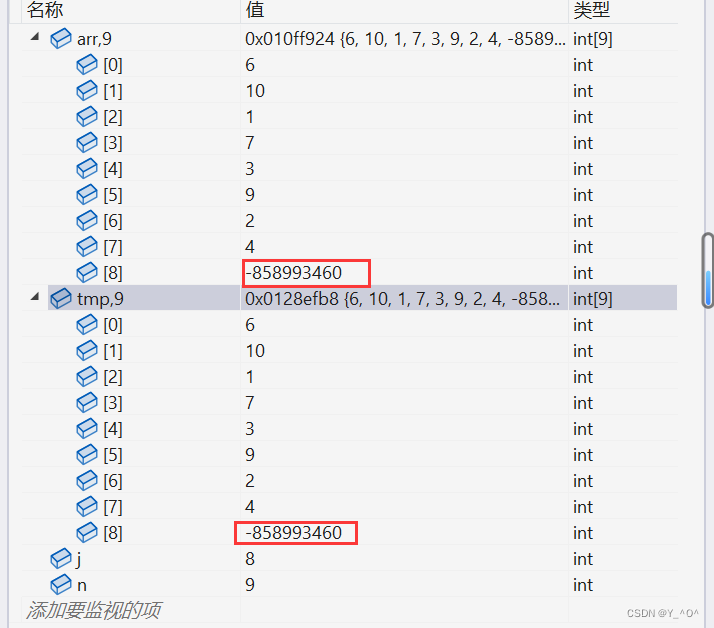
啥也没打印,其实我们的程序已经崩掉了。 我们来调试一下:

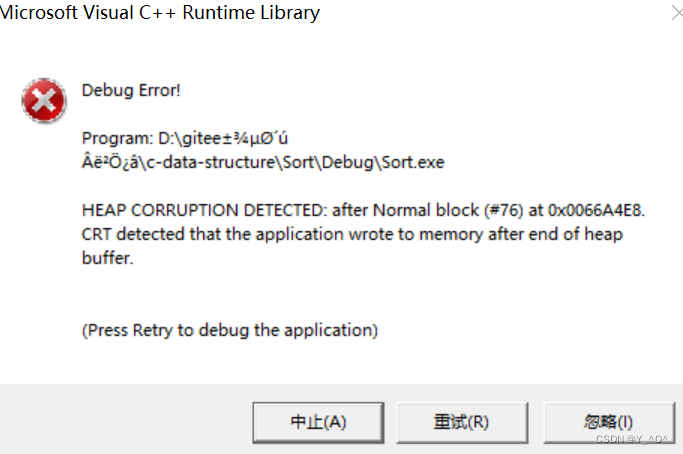

发现问题
为什么会这样呢?
<font color = blue>我们给定第一组数据非常完美,直接就排好了,我们分析过程也没发现什么问题:
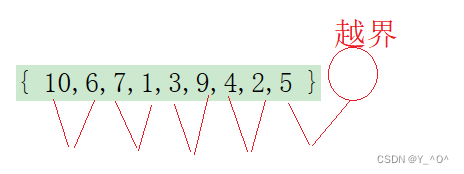
解决问题
那接下来我们就分析一下哪些情况下会出现越界,然后进行相应的处理:
<font color = red>我们每次要归并的两组数据的区间是第一组【begin1,end1】和第二组【begin2,end2】。 首先begin1是肯定不会越界的,每次循环我们是j赋给begin1的,j小于n才进入循环的:

所以呢,出现越界无非就这几种情况:
<font color = red>第一组部分越界,即end1越界 <font color = blue>如果end1越界的话,哪那begin2,end2必定也都超过了数组的有效范围,即第二组是不存在的。 那只有一组,也就没法进行归并了,所以这种情况直接break就行了。
<font color = red>第一组没有越界,第二组全部越界(即begin2越界了) <font color = blue>那这种情况第二组也是不存在的,直接break
<font color = red>第一组未越界,第二组部分越界(即begin2没有越界但end2越界了) <font color = blue>这时两组都是有数据的,只不过第二组数据少一些罢了,所以这种情况就不能直接break了,我们要休整一下end2的取值,然后对两组数据进行归并。 那end2的取值应该怎么修改,n是数据个数,n-1就是最后一个元素下标,所以让end2等于n-1就行了。
那我们接下来处理一下这几种情况就行了: 
最终代码
所以最终的代码是这样的:
//归并排序(非递归)
void MergerSortNonR(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
int gap = 1;
while (gap < n)
{
for (int j = 0; j < n; j += 2 * gap)
{
//归并
int begin1 = j;
int end1 = j + gap - 1;
int begin2 = j + gap;
int end2 = j + 2 * gap - 1;
//判断越界的情况并进行处理
//第一组部分越界
if (end1 >= n)
break;
//第二组全部越界
if (begin2 >= n)
break;
//第二组部分越界
if (end2 >= n)
end2 = n - 1;
int i = j;
//归并,取小的尾插(升序)
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] <= arr[begin2])
{
tmp[i++] = arr[begin1++];
}
else
{
tmp[i++] = arr[begin2++];
}
}
//循环结束时哪个区间还有剩余数据,就把剩余数据续到后面
while (begin1 <= end1)
{
tmp[i++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = arr[begin2++];
}
//最后把排好数据再拷回原数组(只拷贝当前归并的区间)
memcpy(arr + j, tmp + j, (end2 - j + 1) * sizeof(int));
}
gap *= 2;
}
free(tmp);
tmp = NULL;
}这下我们再来测试刚才的那组数据: 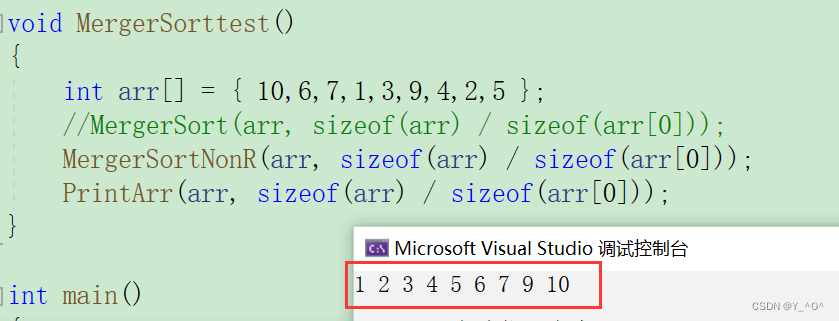 就没问题了。
就没问题了。
归并排序特性总结
<font color = red>归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
<font color = red>时间复杂度:O(N*logN)
<font color = red>空间复杂度:O(N)
稳定性:稳定 因为在归并的时候是取小的尾插嘛,那如果有相等的我们取前面的那一个就行了嘛。

- 点赞
- 收藏
- 关注作者
评论(0)