Similarities:精准相似度计算与语义匹配搜索工具包,多维度实现多种算法,覆盖文本、图像等领域,支持文搜、图搜文、图搜图

Similarities:精准相似度计算与语义匹配搜索工具包,多维度实现多种算法,覆盖文本、图像等领域,支持文搜、图搜文、图搜图匹配搜索
Similarities 相似度计算、语义匹配搜索工具包,实现了多种相似度计算、匹配搜索算法,支持文本、图像等。
1. 文本相似度计算(文本匹配)
- 余弦相似(Cosine Similarity):两向量求余弦
- 点积(Dot Product):两向量归一化后求内积
- 汉明距离(Hamming Distance),编辑距离(Levenshtein Distance),欧氏距离(Euclidean Distance),曼哈顿距离(Manhattan Distance)等
语义模型
- CoSENT文本匹配模型【推荐】
- BERT模型(文本向量表征)
- SentenceBERT文本匹配模型
字面模型
- Word2Vec文本浅层语义表征【推荐】
- 同义词词林
- 知网Hownet义原匹配
- BM25、RankBM25
- TFIDF
- SimHash
2.图像相似度计算(图像匹配)
语义模型
- CLIP(Contrastive Language-Image Pre-Training)
- VGG(doing)
- ResNet(doing)
特征提取
- pHash【推荐】, dHash, wHash, aHash
- SIFT, Scale Invariant Feature Transform(SIFT)
- SURF, Speeded Up Robust Features(SURF)(doing)
3.图文相似度计算
4.匹配搜索
- SemanticSearch:向量相似检索,使用Cosine
Similarty + topk高效计算,比一对一暴力计算快一个数量级
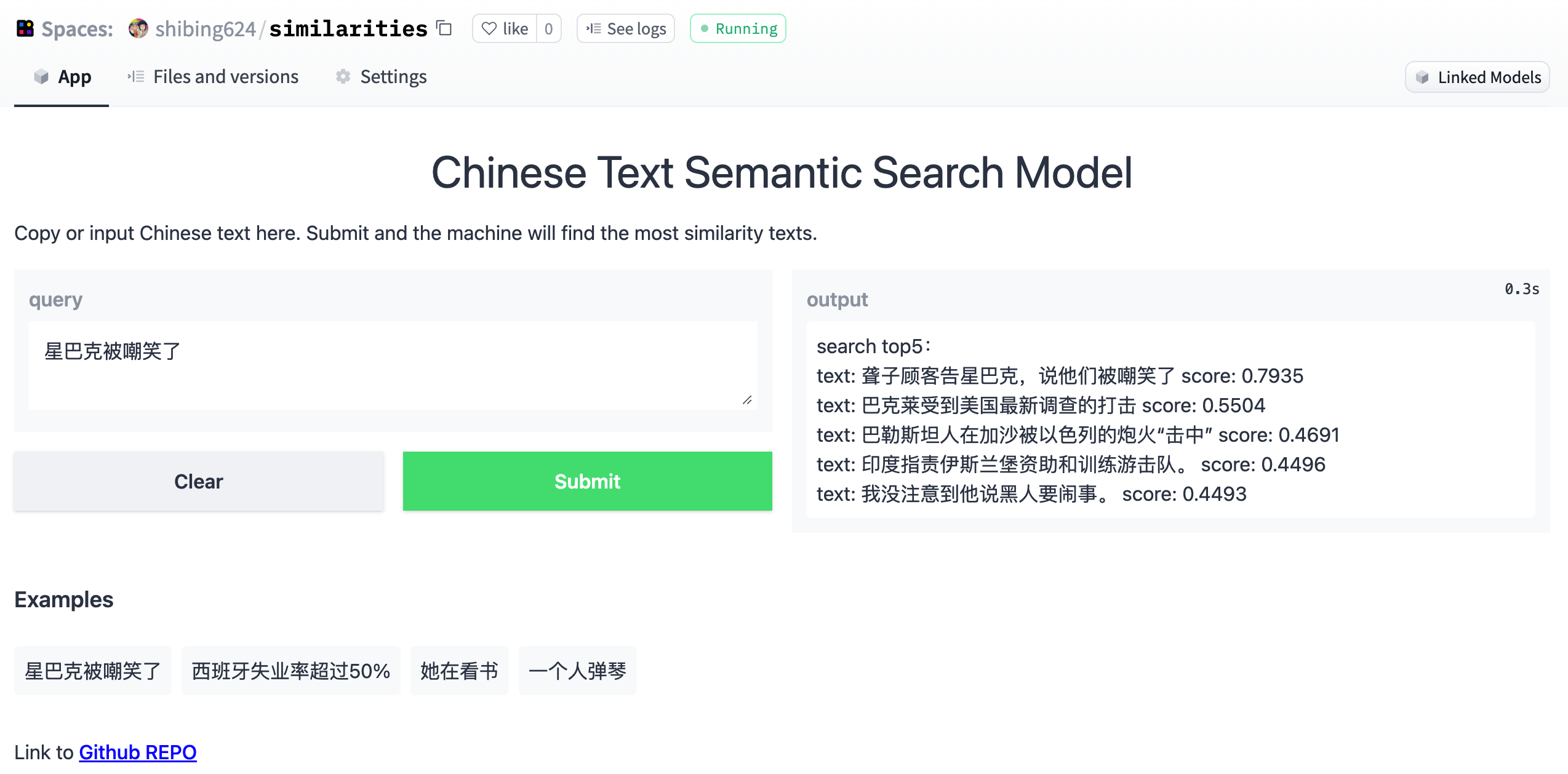
6.Demo展示
Compute similarity score Demo: https://huggingface.co/spaces/shibing624/text2vec

Semantic Search Demo: https://huggingface.co/spaces/shibing624/similarities
6.1 中文文本匹配模型评测结果
| Model | ATEC | BQ | LCQMC | PAWSX | STS-B | Avg | QPS |
|---|---|---|---|---|---|---|---|
| Word2Vec | 20.00 | 31.49 | 59.46 | 2.57 | 55.78 | 33.86 | 10283 |
| SBERT-multi | 18.42 | 38.52 | 63.96 | 10.14 | 78.90 | 41.99 | 2371 |
| Text2vec | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 48.25 | 2572 |
结果值使用spearman系数
Model:
- Cilin
- Hownet
- SimHash
- TFIDF
- Install
pip3 install torch # conda install pytorch
pip3 install -U similarities
or
git clone https://github.com/shibing624/similarities.git
cd similarities
python3 setup.py install
7.使用场景推荐
7.1. 文本语义相似度计算
example: examples/text_similarity_demo.py
from similarities import Similarity
m = Similarity()
r = m.similarity('如何更换花呗绑定银行卡', '花呗更改绑定银行卡')
print(f"similarity score: {float(r)}") # similarity score: 0.855146050453186
Similarity的默认方法:
Similarity(corpus: Union[List[str], Dict[str, str]] = None,
model_name_or_path="shibing624/text2vec-base-chinese",
max_seq_length=128)
- 返回值:余弦值
score范围是[-1, 1],值越大越相似 corpus:搜索用的doc集,仅搜索时需要,输入格式:句子列表List[str]或者{corpus_id: sentence}的Dict[str, str]格式model_name_or_path:模型名称或者模型路径,默认会从HF model hub下载并使用中文语义匹配模型shibing624/text2vec-base-chinese,如果是多语言景,可以替换为多语言匹配模型shibing624/text2vec-base-multilingualmax_seq_length:输入句子的最大长度,最大为匹配模型支持的最大长度,BERT系列是512
7.2. 文本语义匹配搜索
一般在文档候选集中找与query最相似的文本,常用于QA场景的问句相似匹配、文本相似检索等任务。
example: examples/text_semantic_search_demo.py
import sys
sys.path.append('..')
from similarities import Similarity
#1.Compute cosine similarity between two sentences.
sentences = ['如何更换花呗绑定银行卡',
'花呗更改绑定银行卡']
corpus = [
'花呗更改绑定银行卡',
'我什么时候开通了花呗',
'俄罗斯警告乌克兰反对欧盟协议',
'暴风雨掩埋了东北部;新泽西16英寸的降雪',
'中央情报局局长访问以色列叙利亚会谈',
'人在巴基斯坦基地的炸弹袭击中丧生',
]
model = Similarity(model_name_or_path="shibing624/text2vec-base-chinese")
print(model)
similarity_score = model.similarity(sentences[0], sentences[1])
print(f"{sentences[0]} vs {sentences[1]}, score: {float(similarity_score):.4f}")
print('-' * 50 + '\n')
#2.Compute similarity between two list
similarity_scores = model.similarity(sentences, corpus)
print(similarity_scores.numpy())
for i in range(len(sentences)):
for j in range(len(corpus)):
print(f"{sentences[i]} vs {corpus[j]}, score: {similarity_scores.numpy()[i][j]:.4f}")
print('-' * 50 + '\n')
#3.Semantic Search
model.add_corpus(corpus)
res = model.most_similar(queries=sentences, topn=3)
print(res)
for q_id, c in res.items():
print('query:', sentences[q_id])
print("search top 3:")
for corpus_id, s in c.items():
print(f'\t{model.corpus[corpus_id]}: {s:.4f}')
output:
如何更换花呗绑定银行卡 vs 花呗更改绑定银行卡, score: 0.8551
...
如何更换花呗绑定银行卡 vs 花呗更改绑定银行卡, score: 0.8551
如何更换花呗绑定银行卡 vs 我什么时候开通了花呗, score: 0.7212
如何更换花呗绑定银行卡 vs 俄罗斯警告乌克兰反对欧盟协议, score: 0.1450
如何更换花呗绑定银行卡 vs 暴风雨掩埋了东北部;新泽西16英寸的降雪, score: 0.2167
如何更换花呗绑定银行卡 vs 中央情报局局长访问以色列叙利亚会谈, score: 0.2517
如何更换花呗绑定银行卡 vs 人在巴基斯坦基地的炸弹袭击中丧生, score: 0.0809
花呗更改绑定银行卡 vs 花呗更改绑定银行卡, score: 1.0000
花呗更改绑定银行卡 vs 我什么时候开通了花呗, score: 0.6807
花呗更改绑定银行卡 vs 俄罗斯警告乌克兰反对欧盟协议, score: 0.1714
花呗更改绑定银行卡 vs 暴风雨掩埋了东北部;新泽西16英寸的降雪, score: 0.2162
花呗更改绑定银行卡 vs 中央情报局局长访问以色列叙利亚会谈, score: 0.2728
花呗更改绑定银行卡 vs 人在巴基斯坦基地的炸弹袭击中丧生, score: 0.1279
query: 如何更换花呗绑定银行卡
search top 3:
花呗更改绑定银行卡: 0.8551
我什么时候开通了花呗: 0.7212
中央情报局局长访问以色列叙利亚会谈: 0.2517
余弦
score的值范围[-1, 1],值越大,表示该query与corpus的文本越相似。
7.2.1 多语言文本语义相似度计算和匹配搜索
多语言:包括中、英、韩、日、德、意等多国语言
example: examples/text_semantic_search_multilingual_demo.py
7.3. 快速近似文本语义匹配搜索
支持Annoy、Hnswlib的近似语义匹配搜索,常用于百万数据集的匹配搜索任务。
example: examples/fast_text_semantic_search_demo.py
7.4. 基于字面的文本相似度计算和匹配搜索
支持同义词词林(Cilin)、知网Hownet、词向量(WordEmbedding)、Tfidf、SimHash、BM25等算法的相似度计算和字面匹配搜索,常用于文本匹配冷启动。
example: examples/literal_text_semantic_search_demo.py
from similarities import SimHashSimilarity, TfidfSimilarity, BM25Similarity, \
WordEmbeddingSimilarity, CilinSimilarity, HownetSimilarity
text1 = "如何更换花呗绑定银行卡"
text2 = "花呗更改绑定银行卡"
corpus = [
'花呗更改绑定银行卡',
'我什么时候开通了花呗',
'俄罗斯警告乌克兰反对欧盟协议',
'暴风雨掩埋了东北部;新泽西16英寸的降雪',
'中央情报局局长访问以色列叙利亚会谈',
'人在巴基斯坦基地的炸弹袭击中丧生',
]
queries = [
'我的花呗开通了?',
'乌克兰被俄罗斯警告'
]
m = TfidfSimilarity()
print(text1, text2, ' sim score: ', m.similarity(text1, text2))
m.add_corpus(corpus)
res = m.most_similar(queries, topn=3)
print('sim search: ', res)
for q_id, c in res.items():
print('query:', queries[q_id])
print("search top 3:")
for corpus_id, s in c.items():
print(f'\t{m.corpus[corpus_id]}: {s:.4f}')
output:
如何更换花呗绑定银行卡 花呗更改绑定银行卡 sim score: 0.8203384355246909
sim search: {0: {2: 0.9999999403953552, 1: 0.43930041790008545, 0: 0.0}, 1: {0: 0.7380483150482178, 1: 0.0, 2: 0.0}}
query: 我的花呗开通了?
search top 3:
我什么时候开通了花呗: 1.0000
花呗更改绑定银行卡: 0.4393
俄罗斯警告乌克兰反对欧盟协议: 0.0000
...
7.5. 图像相似度计算和匹配搜索
支持CLIP、pHash、SIFT等算法的图像相似度计算和匹配搜索。
example: examples/image_semantic_search_demo.py
import sys
import glob
from PIL import Image
sys.path.append('..')
from similarities import ImageHashSimilarity, SiftSimilarity, ClipSimilarity
def sim_and_search(m):
print(m)
# similarity
sim_scores = m.similarity(imgs1, imgs2)
print('sim scores: ', sim_scores)
for (idx, i), j in zip(enumerate(image_fps1), image_fps2):
s = sim_scores[idx] if isinstance(sim_scores, list) else sim_scores[idx][idx]
print(f"{i} vs {j}, score: {s:.4f}")
# search
m.add_corpus(corpus_imgs)
queries = imgs1
res = m.most_similar(queries, topn=3)
print('sim search: ', res)
for q_id, c in res.items():
print('query:', image_fps1[q_id])
print("search top 3:")
for corpus_id, s in c.items():
print(f'\t{m.corpus[corpus_id].filename}: {s:.4f}')
print('-' * 50 + '\n')
image_fps1 = ['data/image1.png', 'data/image3.png']
image_fps2 = ['data/image12-like-image1.png', 'data/image10.png']
imgs1 = [Image.open(i) for i in image_fps1]
imgs2 = [Image.open(i) for i in image_fps2]
corpus_fps = glob.glob('data/*.jpg') + glob.glob('data/*.png')
corpus_imgs = [Image.open(i) for i in corpus_fps]
#2.image and image similarity score
sim_and_search(ClipSimilarity()) # the best result
sim_and_search(ImageHashSimilarity(hash_function='phash'))
sim_and_search(SiftSimilarity())
output:
Similarity: ClipSimilarity, matching_model: CLIPModel
sim scores: tensor([[0.9580, 0.8654],
[0.6558, 0.6145]])
data/image1.png vs data/image12-like-image1.png, score: 0.9580
data/image3.png vs data/image10.png, score: 0.6145
sim search: {0: {6: 0.9999999403953552, 0: 0.9579654932022095, 4: 0.9326782822608948}, 1: {8: 0.9999997615814209, 4: 0.6729235649108887, 0: 0.6558331847190857}}
query: data/image1.png
search top 3:
data/image1.png: 1.0000
data/image12-like-image1.png: 0.9580
data/image8-like-image1.png: 0.9327

7.6. 图文互搜
CLIP 模型不仅支持以图搜图,还支持中英文图文互搜:
import sys
import glob
from PIL import Image
sys.path.append('..')
from similarities import ImageHashSimilarity, SiftSimilarity, ClipSimilarity
m = ClipSimilarity()
print(m)
#similarity score between text and image
image_fps = ['data/image3.png', # yellow flower image
'data/image1.png'] # tiger image
texts = ['a yellow flower', '老虎']
imgs = [Image.open(i) for i in image_fps]
sim_scores = m.similarity(imgs, texts)
print('sim scores: ', sim_scores)
for (idx, i), j in zip(enumerate(image_fps), texts):
s = sim_scores[idx][idx]
print(f"{i} vs {j}, score: {s:.4f}")
output:
sim scores: tensor([[0.3220, 0.2409],
[0.1677, 0.2959]])
data/image3.png vs a yellow flower, score: 0.3220
data/image1.png vs 老虎, score: 0.2112
参考链接:https://github.com/shibing624/similarities
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。


- 点赞
- 收藏
- 关注作者
评论(0)