迅雷笔试题知识点总结

情景回顾
时间:2016.9.19 19:00-21:00
地点:山东省网络环境智能计算技术重点实验室
事件:迅雷笔试
总体来说,迅雷笔试内容体量不算多,主要分为30道选择题,2道编程题,半小时将选择题做完,1个半小时两道编程题一道29%,一道超时。关键是第二道编程题直接输出错误语句居然通过17%!也是醉了,绝对的判题系统BUG。
知识点回忆
希尔排序
给定一数组元素{50,40,95,20,15,70,60,45},经过一趟希尔排序(参考博文《》)后,数组元素变为
[15 40 60 20 50 70 95 45]
WPL、全局变量与局部变量的区别(存储?)
Java里面“==”与equals()的区别:前者比较的是地址,后者比较的是内容。
int 是在栈里创建的,Integer是在堆里创建的。栈里创建的变量要比在堆创建的速度快得多。
根据“静态型变量是存放在内存的数据区中的,它们在程序开始运行前就分配了固定的字节,在程序运行过程中被分配的字节大小是不改变的.只有程序运行结束后,才释放所占用的内存.” 这段话可以得知,全局变量就是所谓的静态变量,存放在栈中。
Java栈由栈帧元素组成。栈帧由三部分组成:局部变量区、操作数栈、帧数据区。
堆(Heap)
Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建;
Java虚拟机规范描述:所有的对象实例及数组都要在堆上分配;
Java堆可以处于物理上不连续的内存空间,只要逻辑上连续即可;
栈(Stack)
存放基本类型的数据和对象的引用,即存放变量;
如果存放的是基本类型数据(非静态变量),则直接将变量名和值存入stack中的内存中;
如果是引用类型,则将变量名存入栈,然后指向它new出的对象(存放在堆中);
有关堆与栈的区别,详情参见博文《》。
编程题
1.LRUCache(29%)
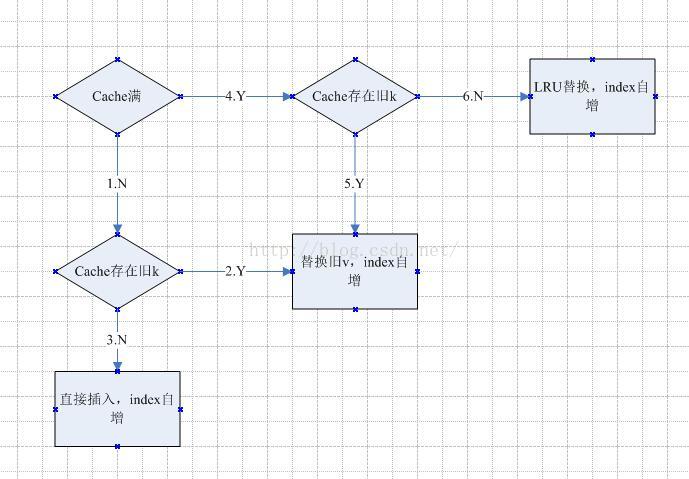
程序流程图(set操作)
package cn.edu.ujn.practice;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
import java.util.regex.Pattern;
/**
*
* @author SHQ
*
LRUCache
时间限制:C/C++语言 1000MS;其他语言 3000MS
内存限制:C/C++语言 65536KB;其他语言 589824KB
题目描述:
为LRU Cache设计一个数据结构,它支持两个操作:
1)get(key):如果key在cache中,则返回对应的value值,否则返回-1。
2)set(key,value):如果key不在cache中,则将该(key,value)插入cache中(注意,如果cache已满,则必须把最近最久未使用的元素从cache中删除);
如果key在cache中,则重置value的值。
3)key,value为int型数据。
输入
第一行为capacity(capacity>0), 后面输入的每行数据,有两种情况:
一种有key和value(key,value以空格分隔),这种情况为set数据,一种只有一个key值,这种为get数据。
输出
根据给定的capacity和多组测试数据,输出指定key值对应value值,如果该key值不存在,返回-1。
样例输入
3
100 100
200 200
300 300
100 100
400 400
100
200
300
500
样例输出
100
-1
300
-1
*/
public class XunLei_1 {
public static void main(String[] args) {
StringBuffer sb =new StringBuffer();
Scanner in = new Scanner(System.in);
// 容量
int capacity = in.nextInt();
// 用于接收换行符
in.nextLine();
while (in.hasNextLine()) {
String s = in.nextLine();
if(s == null || s.length() == 0)
break;
sb.append(s + "\r");
}
resolution(capacity, sb.toString());
}
private static void resolution(int capacity, String str){
/* System.out.println(capacity);
System.out.println(str);*/
int index = 0;
Map> map = new HashMap>();
Map mapTmp;
Pattern pat = Pattern.compile("[ ]+");
Pattern pattern = Pattern.compile("[\r]");
String [] sr = pattern.split(str);
boolean flag = false;
for(String s : sr){
// 注意map集合m的创建位置
HashMap m = new HashMap();
String [] string = pat.split(s);
// set操作
if(string.length == 2){
// 如果key不在cache中,则将该(key,value)插入cache中;如果key在cache中,则重置value的值。
// 1.cache未满
if(map.size() == 0){
m.put(string[0], string[1]);
map.put(index++, m);
}else if(map.size() < capacity){
for(int key : map.keySet()){
mapTmp = map.get(key);
// 2.cache存在旧k,替换旧v
if(mapTmp.containsKey(string[0])){
m.put(string[0], string[1]);
flag = true;
break;
}
}
if(!flag){
// 3.cache不存在旧k,直接插入
m.put(string[0], string[1]);
}
map.put(index++, m);
}
// 4.cache已满
else{
for(int key : map.keySet()){
mapTmp = map.get(key);
// 5.cache存在旧k,替换旧v
if(mapTmp.containsKey(string[0])){
m.put(string[0], string[1]);
map.put(index++, m);
map.remove(key);
break;
}
else{
// 6.cache不存在旧k,使用LRU将元素从cache中删除
int min = Collections.min(map.keySet());
int max = Collections.max(map.keySet());
/* for(int i : map.keySet()){
if(i < min){
min = i;
}
if(i > max)
max = i;
}*/
// 根据LRU规则,将元素从cache中删除
map.remove(min);
// 将元素存入cache中最大位置+1处
m.put(string[0], string[1]);
map.put(max+1, m);
break;
}
}
}
}else if(string.length == 1){
flag = false;
// get操作
for(int in : map.keySet()){
mapTmp = map.get(in);
if(mapTmp.containsKey(string[0])){
flag = true;
System.out.println(mapTmp.get(string[0]));
break;
}
}
if(!flag)
System.out.println("-1");
}
}
}
} 注
其中,有关map类型m的创建位置,自己再次犯了错误。new的m为引用类型,存放在栈中。应保证m在循环体内创建,这样结果才不会出现map累加的现象。类似错误同样出现在博文《》。
2迅雷专用链提取(正则超时)
感触
做编程题之前,首先要画出流程图,使编程逻辑更加清晰。编程完成后,要设计测试用例,分为功能性测试和特殊测试。尤其要特别注意边界值的测试。
美文美图


- 点赞
- 收藏
- 关注作者
评论(0)