语义检索系统排序模块:基于ERNIE-Gram的Pair-wise和基于RocketQA的CrossEncoder训练单塔模型

语义检索系统之排序模块:基于ERNIE-Gram的Pair-wise和基于RocketQA的CrossEncoder训练的单塔模型
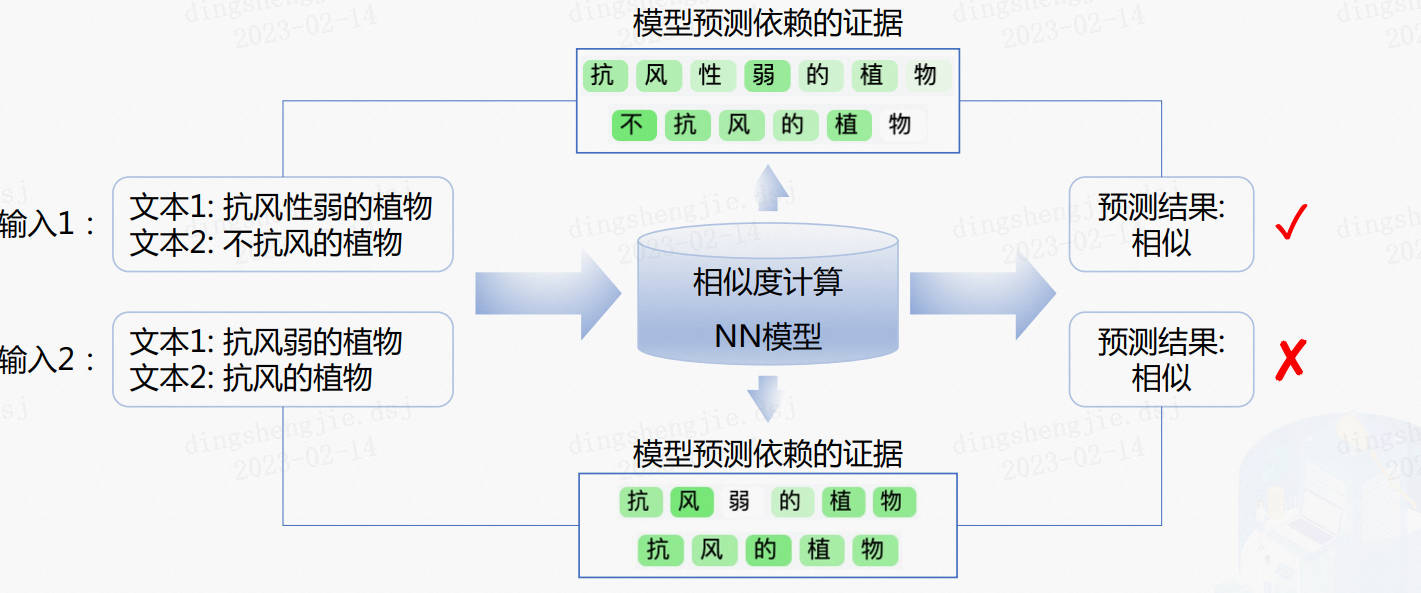
文本匹配任务数据每一个样本通常由两个文本组成(query,title)。类别形式为 0 或 1,0 表示 query 与 title 不匹配; 1 表示匹配。
- 基于单塔 Point-wise 范式的语义匹配模型 ernie_matching: 模型精度高、计算复杂度高, 适合直接进行语义匹配 2 分类的应用场景。
- 基于单塔 Pair-wise 范式的语义匹配模型 ernie_matching: 模型精度高、计算复杂度高, 对文本相似度大小的序关系建模能力更强,适合将相似度特征作为上层排序模块输入特征的应用场景。
- 基于双塔 Point-Wise 范式的语义匹配模型 这2 种方案计算效率更高,适合对延时要求高、根据语义相似度进行粗排的应用场景。
Pointwise:输入两个文本和一个标签,可看作为一个分类问题,即判断输入的两个文本是否匹配。Pairwise:输入为三个文本,分别为Query以及对应的正样本和负样本,该训练方式考虑到了文本之间的相对顺序。单塔:先将输入文本合并,然后输入到单一的神经网络模型。双塔:对输入文本分别进行编码成固定长度的向量,通过文本的表示向量进行交互计算得到文本之间的关系。
语义搜索系列文章全流程教学:
更多文本匹配方案参考:

1.排序模型任务简介和要求
1.1 技术方案和评估指标
- 技术方案
双塔模型,使用ERNIE-Gram预训练模型,使用margin_ranking_loss训练模型。
- 评估指标
(1)采用 AUC 指标来评估排序模型的排序效果。
效果评估先看
| 训练方式 | 模型 | epoch | AUC | 训练时长 | 其他 |
|---|---|---|---|---|---|
| pairwise | ERNIE-Gram | 1(仅1w steps) | 0.791 | 20min | 个人 |
| CrossEncoder | rocketqa-base-cross-encoder | 1(仅1w steps) | 0.785 | 20min | 个人 |
| CrossEncoder | rocketqa-base-cross-encoder | 1(仅4.5w steps) | 0.804 | 50 min | 个人 |
| pairwise | ERNIE-Gram | 3 | 0.801 | 20h | 官方 |
| CrossEncoder | rocketqa-base-cross-encoder | 3 | 0.835 | 20h | 官方 |
1.2 环境依赖和安装说明
环境依赖
- python >= 3.7
- paddlepaddle >= 2.3.7
- paddlenlp >= 2.3
- pandas >= 0.25.1
- scipy >= 1.3.1
1.3 代码结构
项目代码结构及说明:
ernie_matching/
├── deply # 部署
├── cpp
├── rpc_client.py # RPC 客户端的bash脚本
├── http_client.py # http 客户端的bash文件
└── start_server.sh # 启动C++服务的脚本
└── python
├── deploy.sh # 预测部署bash脚本
├── config_nlp.yml # Pipeline 的配置文件
├── web_service.py # Pipeline 服务端的脚本
├── rpc_client.py # Pipeline RPC客户端的脚本
└── predict.py # python 预测部署示例
|—— scripts
├── export_model.sh # 动态图参数导出静态图参数的bash文件
├── export_to_serving.sh # 导出 Paddle Serving 模型格式的bash文件
├── train_pairwise.sh # Pair-wise 单塔匹配模型训练的bash文件
├── evaluate.sh # 评估验证文件bash脚本
├── predict_pairwise.sh # Pair-wise 单塔匹配模型预测脚本的bash文件
├── export_model.py # 动态图参数导出静态图参数脚本
├── export_to_serving.py # 导出 Paddle Serving 模型格式的脚本
├── model.py # Pair-wise 匹配模型组网
├── data.py # Pair-wise 训练样本的转换逻辑 、Pair-wise 生成随机负例的逻辑
├── train_pairwise.py # Pair-wise 单塔匹配模型训练脚本
├── evaluate.py # 评估验证文件
├── predict_pairwise.py # Pair-wise 单塔匹配模型预测脚本,输出文本对是相似度
1.4 数据介绍
- 数据集说明
样例数据如下:
['英语委婉语引起的跨文化交际障碍\t英语委婉语引起的跨文化交际障碍及其翻译策略研究英语委婉语', '跨文化交际障碍', '翻译策略\t委婉语在英语和汉语中的文化差异委婉语', '文化', '跨文化交际']
['范迪慧 嘉兴市中医院\t滋阴疏肝汤联合八穴隔姜灸治疗肾虚肝郁型卵巢功能低下的临床疗效滋阴疏肝汤', '八穴隔姜灸', '肾虚肝郁型卵巢功能低下', '性脉甾类激素', '妊娠\t温针灸、中药薰蒸在半月板损伤术后康复中的疗效分析膝损伤', '半月板', '胫骨', '中医康复', '温针疗法', '薰洗']
['灰色关联分析\t灰色关联分析评价不同产地金果榄质量金果榄;灰色关联分析法;主成分分析法;盐酸巴马汀;盐酸药根碱\t江西省某三级甲等医院2型糖尿病患者次均住院费用新灰色关联分析2型糖尿病', '次均住院费用', '新灰色关联分析', '结构变动度']
['护理质量管理进展\t病区分类管理在护理工作中的应用进展综述', '病区分类', '护理管理\t介入手术室的护理安全管理研究进展介入手术室;护理安全管理;护理质量;研究进展']
['血糖波动认知功能障碍\t老年糖尿病患者血糖波动与认知功能障碍关系的研究进展老年人', '糖尿病', '认知功能', '血糖波动\t老年2型糖尿病患者血糖波动与认知功能障碍的关系2型糖尿病;血糖波动;认知功能障碍']
├── milvus # milvus建库数据集
├── milvus_data.csv. # 构建召回库的数据
├── recall # 召回(语义索引)数据集
├── corpus.csv # 用于测试的召回库
├── dev.csv # 召回验证集
├── test.csv # 召回测试集
├── train.csv # 召回训练集
├── train_unsupervised.csv # 无监督训练集
├── sort # 排序数据集
├── test_pairwise.csv # 排序测试集
├── dev_pairwise.csv # 排序验证集
└── train_pairwise.csv # 排序训练集
!unzip -d datasets /home/aistudio/data/data225060/literature_search_rank.zip
!unzip -d datasets /home/aistudio/data/data225060/literature_search_data.zip
!mv /home/aistudio/datasets/data /home/aistudio/datasets/literature_search_rank
#数据查看
import csv
def show_data(filename, num_rows=10):
with open(filename, 'r') as f:
reader = csv.reader(f)
header = next(reader) # 获取表头
print(header) # 打印表头
for i, row in enumerate(reader):
if i < num_rows: # 打印前num_rows行数据
print(row)
else:
break
line = '-' * 100
print(line)
show_data('/home/aistudio/datasets/sort/train_pairwise.csv', num_rows=5)
['query\ttitle\tneg_title']
['英语委婉语引起的跨文化交际障碍\t英语委婉语引起的跨文化交际障碍及其翻译策略研究英语委婉语', '跨文化交际障碍', '翻译策略\t委婉语在英语和汉语中的文化差异委婉语', '文化', '跨文化交际']
['范迪慧 嘉兴市中医院\t滋阴疏肝汤联合八穴隔姜灸治疗肾虚肝郁型卵巢功能低下的临床疗效滋阴疏肝汤', '八穴隔姜灸', '肾虚肝郁型卵巢功能低下', '性脉甾类激素', '妊娠\t温针灸、中药薰蒸在半月板损伤术后康复中的疗效分析膝损伤', '半月板', '胫骨', '中医康复', '温针疗法', '薰洗']
['灰色关联分析\t灰色关联分析评价不同产地金果榄质量金果榄;灰色关联分析法;主成分分析法;盐酸巴马汀;盐酸药根碱\t江西省某三级甲等医院2型糖尿病患者次均住院费用新灰色关联分析2型糖尿病', '次均住院费用', '新灰色关联分析', '结构变动度']
['护理质量管理进展\t病区分类管理在护理工作中的应用进展综述', '病区分类', '护理管理\t介入手术室的护理安全管理研究进展介入手术室;护理安全管理;护理质量;研究进展']
['血糖波动认知功能障碍\t老年糖尿病患者血糖波动与认知功能障碍关系的研究进展老年人', '糖尿病', '认知功能', '血糖波动\t老年2型糖尿病患者血糖波动与认知功能障碍的关系2型糖尿病;血糖波动;认知功能障碍']
----------------------------------------------------------------------------------------------------
2.基于ERNIE-Gram模型训练
排序模型下载链接:
| Model | 训练参数配置 | 硬件 |
|---|---|---|
| ERNIE-Gram-Sort | epoch:1 lr:5E-5 bs:64 max_len:128 | 4卡 v100-16g |
- 训练环境说明
- NVIDIA Driver Version: 440.64.00
- Ubuntu 16.04.6 LTS (Docker)
- Intel® Xeon® Gold 6148 CPU @ 2.40GHz
2.1 单机单卡训练/单机多卡训练
这里采用单机多卡方式进行训练,通过如下命令,指定 GPU 0,1,2,3 卡, 基于ERNIE-Gram训练模型,数据量比较大,需要20小时10分钟左右。如果采用单机单卡训练,只需要把--gpu参数设置成单卡的卡号即可
训练的命令如下:
pip install -U paddlenlp
cd /home/aistudio/ernie_matching
/home/aistudio/ernie_matching
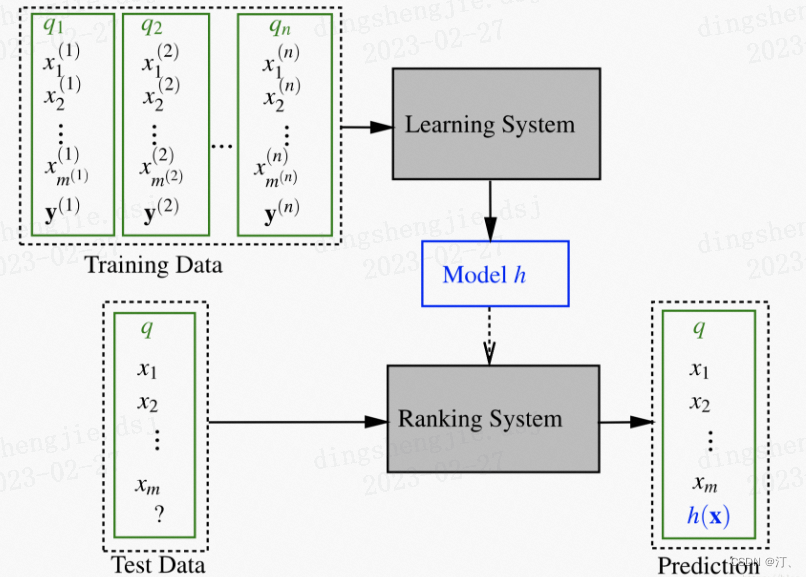
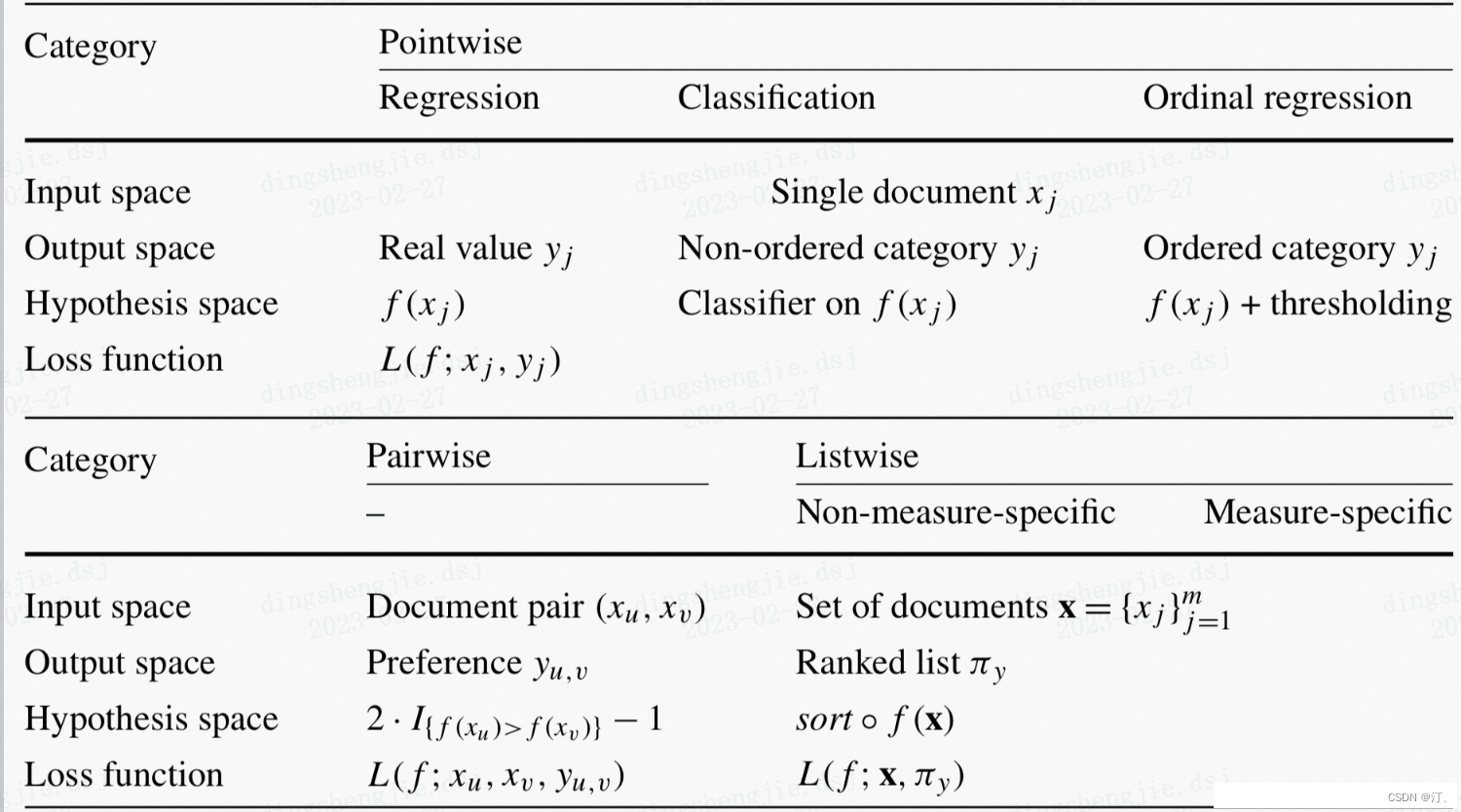
2.1.1 推荐系统中常用的两种优化损失函数的机器学习范式:pointwise loss 和 pairwise loss
- 精排简介
Learning to Rank (LTR)是一类技术方法,主要利用机器学习算法解决实际中的排序问题。传统的机器学习主要解决的问题是一个分类或者回归问题,比如对一个样本数据预测对应的类别或者预测一个数值分值。而LTR解决的是一个排序问题,对一个list的item进行一个排序,所以LTR并不太关注这个list的每个item具体得多少分值,更关注所有item的相对顺序。排序通常是信息检索的核心成分,所以LTR最常见的应用是搜索场景,对召回的document进行排序。
Pointwise 方法
Pointwise 方法是通过近似为回归问题解决排序问题,输入的单条样本为得分 - 文档,将每个查询 - 文档对的相关性得分作为实数分数或者序数分数,使得单个查询 - 文档对作为样本点 (Pointwise 的由来),训练排序模型。预测时候对于指定输入,给出查询 - 文档对的相关性得分。
- pointwise loss :
最小化预测输出与目标值之间的平分损失,具体处理是在处理负样本时:把未观察到的实体(即 user 与 item 没有交互)当作负样本,或者从未观察到的实体中采样负样本。
- pointwise loss :
Pairwise 方法
Pairwise 方法是通过近似为分类问题解决排序问题,输入的单条样本为标签 - 文档对。对于一次查询的多个结果文档,组合任意两个文档形成文档对作为输入样本。即学习一个二分类器,对输入的一对文档对 AB(Pairwise 的由来),根据 A 相关性是否比 B 好,二分类器给出分类标签 1 或 0。对所有文档对进行分类,就可以得到一组偏序关系,从而构造文档全集的排序关系。该类方法的原理是对给定的文档全集 S,降低排序中的逆序文档对的个数来降低排序错误,从而达到优化排序结果的目的。
- pairwise loss :
最大化观察到的(即正样本)预测输出和未观察到的(负样本)的预测输出的边缘,表现为观察到的实体得分排名高于未观察到的实体。
- pairwise loss :
2.1.2 深度学习框架中的 Ranking Loss 层
paddlepaddle
- margin_ranking_loss:计算输入 input,other 和 标签 label 间的 margin rank loss 损失。更多内容进行文章跳转看api文档
Caffe
- Constrastive Loss Layer. 限于 Pairwise Ranking Loss 计算. 例如,可以用于训练 Siamese 网络。
- PyCaffe Triplet Ranking Loss Layer. 用来训练 triplet 网络,by David Lu。
PyTorch
- CosineEmbeddingLoss. 使用余弦相似度的 Pairwise Loss。输入是一对二元组,标签标记它是一个正样本对还是负样本对,以及边距 margin。
- MarginRankingLoss. 同上, 但使用欧拉距离。
- TripletMarginLoss. 使用欧拉距离的 Triplet Loss。
进入Loss Functions查看具体没课函数
TensorFlow
- contrastive_loss. Pairwise Ranking Loss.
- triplet_semihard_loss. 使用 semi-hard 负采样的 Triplet loss。
更多内容参考:
# !python -u -m paddle.distributed.launch --gpus "0,1,2,3" train_pairwise.py \
!python train_pairwise.py \
--device gpu \
--save_dir ./checkpoints \
--batch_size 32 \
--learning_rate 2E-5 \
--max_seq_length 128 \
--margin 0.1 \
--eval_step 200 \
--save_step 10000 \
--epochs 1 \
--weight_decay 0 \
--warmup_proportion 0.1 \
--model_name_or_path "ernie-3.0-medium-zh" \
--train_file /home/aistudio/datasets/sort/train_pairwise.csv \
--test_file /home/aistudio/datasets/sort/dev_pairwise.csv
#也可以运行bash脚本:自行修改参数
# sh scripts/train_pairwise.sh
参数说明:
- –
margin, default=0.2, type=float, help="Margin for pos_score and neg_score. - –
train_file, type=str, required=True, help="The full path of train file - –
test_file, type=str, required=True, help="The full path of test file - –
save_dir, default=’./checkpoint’, type=str, help="The output directory where the model checkpoints will be written. - –
max_seq_length, default=128, type=int, help="The maximum total input sequence length after tokenization. Sequences longer than this will be truncated, sequences shorter will be padded. - –
batch_size, default=32, type=int, help="Batch size per GPU/CPU for training. - –
learning_rate, default=5e-5, type=float, help="The initial learning rate for Adam. - –
weight_decay, default=0.0, type=float, help="Weight decay if we apply some. - –
epochs, default=3, type=int, help="Total number of training epochs to perform. - –
eval_step, default=200, type=int, help="Step interval for evaluation. - –
save_step, default=10000, type=int, help="Step interval for saving checkpoint. - –
warmup_proportion, default=0.0, type=float, help="Linear warmup proportion over the training process. - –
init_from_ckpt, type=str, default=None, help="The path of checkpoint to be loaded. - –
model_name_or_path, default=“ernie-3.0-medium-zh”, help="The pretrained model used for training - –
seed, type=int, default=1000, help="Random seed for initialization. - –
device, choices=[‘cpu’, ‘gpu’], default=“gpu”, help="Select which device to train model, defaults to gpu.
- –
部分结果展示:
global step 9890, epoch: 1, batch: 9890, loss: 0.07267, speed: 15.45 step/s
global step 9900, epoch: 1, batch: 9900, loss: 0.08693, speed: 15.39 step/s
global step 9910, epoch: 1, batch: 9910, loss: 0.08169, speed: 15.37 step/s
global step 9920, epoch: 1, batch: 9920, loss: 0.08853, speed: 15.57 step/s
global step 9930, epoch: 1, batch: 9930, loss: 0.07799, speed: 15.61 step/s
global step 9940, epoch: 1, batch: 9940, loss: 0.05505, speed: 15.51 step/s
global step 9950, epoch: 1, batch: 9950, loss: 0.08684, speed: 15.38 step/s
global step 9960, epoch: 1, batch: 9960, loss: 0.07803, speed: 15.45 step/s
global step 9970, epoch: 1, batch: 9970, loss: 0.08611, speed: 15.25 step/s
global step 9980, epoch: 1, batch: 9980, loss: 0.07934, speed: 15.16 step/s
global step 9990, epoch: 1, batch: 9990, loss: 0.08121, speed: 15.37 step/s
global step 10000, epoch: 1, batch: 10000, loss: 0.09317, speed: 15.45 step/s
eval_dev auc:0.791
[2023-07-27 11:03:52,312] [ INFO] - tokenizer config file saved in ./checkpoints/model_10000/tokenizer_config.json
[2023-07-27 11:03:52,312] [ INFO] - Special tokens file saved in ./checkpoints/model_10000/special_tokens_map.json
global step 10010, epoch: 1, batch: 10010, loss: 0.07487, speed: 0.31 step/s
2.1.3 更多 ERNIE 3.0模型选择
官网链接:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-3.0
- 更多技术细节可以参考论文:
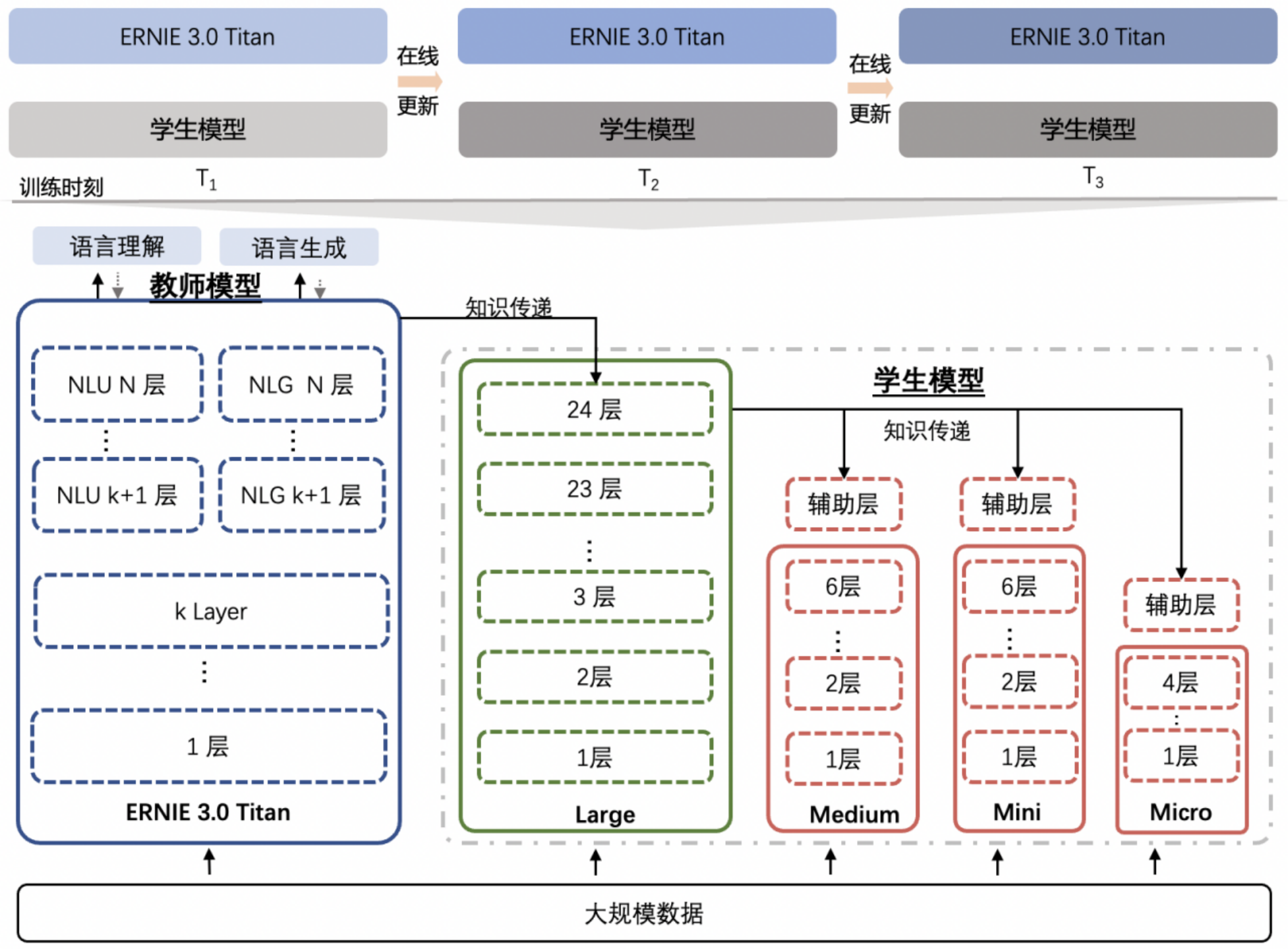
下表汇总介绍了目前 PaddleNLP 支持的 ERNIE 模型对应预训练权重。
| Pretrained Weight | Language | Details of the model |
|---|---|---|
ernie-1.0-base-zh |
Chinese | 12-layer, 768-hidden, 12-heads, 108M parameters. Trained on Chinese text. |
ernie-1.0-base-zh-cw |
Chinese | 12-layer, 768-hidden, 12-heads, 118M parameters. Trained on Chinese text. |
ernie-1.0-large-zh-cw |
Chinese | 24-layer, 1024-hidden, 16-heads, 272M parameters. Trained on Chinese text. |
ernie-tiny |
Chinese | 3-layer, 1024-hidden, 16-heads, _M parameters. Trained on Chinese text. |
ernie-2.0-base-en |
English | 12-layer, 768-hidden, 12-heads, 103M parameters. Trained on lower-cased English text. |
ernie-2.0-base-en-finetuned-squad |
English | 12-layer, 768-hidden, 12-heads, 110M parameters. Trained on finetuned squad text. |
ernie-2.0-large-en |
English | 24-layer, 1024-hidden, 16-heads, 336M parameters. Trained on lower-cased English text. |
ernie-3.0-xbase-zh |
Chinese | 20-layer, 1024-hidden, 16-heads, 296M parameters. Trained on Chinese text. |
ernie-3.0-base-zh |
Chinese | 12-layer, 768-hidden, 12-heads, 118M parameters. Trained on Chinese text. |
ernie-3.0-medium-zh |
Chinese | 6-layer, 768-hidden, 12-heads, 75M parameters. Trained on Chinese text. |
ernie-3.0-mini-zh |
Chinese | 6-layer, 384-hidden, 12-heads, 27M parameters. Trained on Chinese text. |
ernie-3.0-micro-zh |
Chinese | 4-layer, 384-hidden, 12-heads, 23M parameters. Trained on Chinese text. |
ernie-3.0-nano-zh |
Chinese | 4-layer, 312-hidden, 12-heads, 18M parameters. Trained on Chinese text. |
rocketqa-base-cross-encoder |
Chinese | 12-layer, 768-hidden, 12-heads, 118M parameters. Trained on DuReader retrieval text. |
rocketqa-medium-cross-encoder |
Chinese | 6-layer, 768-hidden, 12-heads, 75M parameters. Trained on DuReader retrieval text. |
rocketqa-mini-cross-encoder |
Chinese | 6-layer, 384-hidden, 12-heads, 27M parameters. Trained on DuReader retrieval text. |
rocketqa-micro-cross-encoder |
Chinese | 4-layer, 384-hidden, 12-heads, 23M parameters. Trained on DuReader retrieval text. |
rocketqa-nano-cross-encoder |
Chinese | 4-layer, 312-hidden, 12-heads, 18M parameters. Trained on DuReader retrieval text. |
rocketqa-zh-base-query-encoder |
Chinese | 12-layer, 768-hidden, 12-heads, 118M parameters. Trained on DuReader retrieval text. |
rocketqa-zh-base-para-encoder |
Chinese | 12-layer, 768-hidden, 12-heads, 118M parameters. Trained on DuReader retrieval text. |
rocketqa-zh-medium-query-encoder |
Chinese | 6-layer, 768-hidden, 12-heads, 75M parameters. Trained on DuReader retrieval text. |
rocketqa-zh-medium-para-encoder |
Chinese | 6-layer, 768-hidden, 12-heads, 75M parameters. Trained on DuReader retrieval text. |
rocketqa-zh-mini-query-encoder |
Chinese | 6-layer, 384-hidden, 12-heads, 27M parameters. Trained on DuReader retrieval text. |
rocketqa-zh-mini-para-encoder |
Chinese | 6-layer, 384-hidden, 12-heads, 27M parameters. Trained on DuReader retrieval text. |
rocketqa-zh-micro-query-encoder |
Chinese | 4-layer, 384-hidden, 12-heads, 23M parameters. Trained on DuReader retrieval text. |
rocketqa-zh-micro-para-encoder |
Chinese | 4-layer, 384-hidden, 12-heads, 23M parameters. Trained on DuReader retrieval text. |
rocketqa-zh-nano-query-encoder |
Chinese | 4-layer, 312-hidden, 12-heads, 18M parameters. Trained on DuReader retrieval text. |
rocketqa-zh-nano-para-encoder |
Chinese | 4-layer, 312-hidden, 12-heads, 18M parameters. Trained on DuReader retrieval text. |
2.2 模型评估
#查看训练模型情况
%cd /home/aistudio/ernie_matching/checkpoints
!ls
/home/aistudio/ernie_matching/checkpoints
model_10000
%cd model_10000
!ls
/home/aistudio/ernie_matching/checkpoints/model_10000
model_30000 special_tokens_map.json vocab.txt
model_state.pdparams tokenizer_config.json
%cd /home/aistudio/ernie_matching
!unset CUDA_VISIBLE_DEVICES
!python -u -m paddle.distributed.launch --gpus "0" evaluate.py \
--device gpu \
--batch_size 32 \
--max_seq_length 128 \
--margin 0.1 \
--init_from_ckpt "/home/aistudio/ernie_matching/checkpoints/model_10000/model_state.pdparams" \
--test_file /home/aistudio/datasets/sort/dev_pairwise.csv
#也可以运行bash脚本:自行修改参数
# sh scripts/evaluate.sh
在排序阶段使用的指标为AUC,AUC反映的是分类器对样本的排序能力,如果完全随机得对样本分类,那么AUC应该接近0.5。分类器越可能把真正的正样本排在前面,AUC越大,分类性能越好。
部分结果展示:
I0727 11:22:54.375491 43830 interpretercore.cc:237] New Executor is Running.
eval_dev auc:0.791
LAUNCH INFO 2023-07-27 11:23:29,410 Pod completed
[2023-07-27 11:23:29,410] [ INFO] controller.py:104 - Pod completed
LAUNCH INFO 2023-07-27 11:23:29,410 Exit code 0
[2023-07-27 11:23:29,410] [ INFO] controller.py:149 - Exit code 0
2.3 模型预测
准备预测数据:待预测数据为 tab 分隔的 tsv 文件,每一行为 1 个文本 Pair,和文本pair的语义索引相似度,部分示例如下:
#数据查看
import csv
def show_data(filename, num_rows=10):
with open(filename, 'r') as f:
reader = csv.reader(f)
header = next(reader) # 获取表头
print(header) # 打印表头
for i, row in enumerate(reader):
if i < num_rows: # 打印前num_rows行数据
print(row)
else:
break
line = '-' * 100
print(line)
show_data('/home/aistudio/datasets/sort/test_pairwise.csv', num_rows=5)
['中西方语言与文化的差异\t中西方文化差异以及语言体现中西方文化', '差异', '语言体现\t0.43203747272491455']
['中西方语言与文化的差异\t论中西方文化差异在非言语交际中的体现中西方文化', '差异', '非言语交际\t0.4644506871700287']
['中西方语言与文化的差异\t中西方体态语文化差异跨文化', '体态语', '非语言交际', '差异\t0.4917311668395996']
['中西方语言与文化的差异\t由此便可以发现两种语言以及两种文化的差异。\t0.5039259195327759']
['中西方语言与文化的差异\t文化空缺视域下的中西方体态语对比研究体态语;中西方差异;文化空缺;跨文化交际\t0.5056567192077637']
['中西方语言与文化的差异\t浅析中西方文化差异在语言中的体现及其对翻译的影响中西方文化', '差异', '语言', '翻译', '影响\t0.5060906410217285']
----------------------------------------------------------------------------------------------------
#以上述 demo 数据为例,运行如下命令基于我们开源的 ERNIE-Gram模型开始计算文本 Pair 的语义相似度:
!python -u -m paddle.distributed.launch --gpus "0" \
predict_pairwise.py \
--device gpu \
--params_path "/home/aistudio/ernie_matching/checkpoints/model_40000/model_state.pdparams"\
--batch_size 32 \
--max_seq_length 128 \
--input_file '/home/aistudio/datasets/sort/test_pairwise.csv'
# 也可以直接执行下面的命令:
# sh scripts/predict_pairwise.sh
部分效果展示:
{'query': '中西方语言与文化的差异', 'title': '浅析中西方文化差异在语言中的体现及其对翻译的影响中西方文化,差异,语言,翻译,影响', 'pred_prob': 0.89284337}
{'query': '中西方语言与文化的差异', 'title': '跨文化交流中文化差异对不同语言运用的影响跨文化交流,语言运用,价值取向,审美观', 'pred_prob': 0.86786854}
{'query': '中西方语言与文化的差异', 'title': '文化与语言的关系在中西文化中的映射交际,符号,语言,文化', 'pred_prob': 0.9189855}
{'query': '中西方语言与文化的差异', 'title': '从中西方文化价值差异看跨文化交际——以电影《推手》为例中西方文化,差异,跨文化交际', 'pred_prob': 0.8503387}
{'query': '中西方语言与文化的差异', 'title': '跨文化交际中的文化误读研究文化误读,影响,中华文化,西方文明', 'pred_prob': 0.8349946}
{'query': '中西方语言与文化的差异', 'title': '中西方文化差异在翻译中的体现中西方,文化差异,翻译,体现', 'pred_prob': 0.8750714}
{'query': '中西方语言与文化的差异', 'title': '从文化差异的角度浅谈汉韩语言对比文化,差异,语言,对比', 'pred_prob': 0.84906375}
{'query': '中西方语言与文化的差异', 'title': '跨文化交际中的中西方价值观差异跨文化交际,价值观,差异,中西方', 'pred_prob': 0.83270866}
{'query': '中西方语言与文化的差异', 'title': '从体态语看中西文化差异体态语,文化差异,跨文化交际', 'pred_prob': 0.91430384}
{'query': '中西方语言与文化的差异', 'title': '高、低语境文化的成因及认识差异跨文化交际,高低语境,文化差异', 'pred_prob': 0.8576788}
{'query': '中西方语言与文化的差异', 'title': '中西文化的差异对跨文化交际的影响文化差异,中式英语,跨文化交际', 'pred_prob': 0.88660836}
{'query': '中西方语言与文化的差异', 'title': '语言视角下的文化内涵比较--以中韩为例', 'pred_prob': 0.8284185}
{'query': '中西方语言与文化的差异', 'title': '从言语交际上看中美文化差异中国文化,美国文化,语言,差异,成因,策略', 'pred_prob': 0.9041654}
{'query': '中西方语言与文化的差异', 'title': '论如何应对中西方文化差异中西方,语言,价值观,社会,应对', 'pred_prob': 0.9386222}
{'query': '中西方语言与文化的差异', 'title': '相反,只有语言间的差异尤其是这些差异所体现的文化差异才是真正重要的,认识和掌握这些差异会有助于克服其造成的交际障碍。', 'pred_prob': 0.8395447}
2.3.1 使用 FastTokenizer 加速
FastTokenizer 是飞桨提供的速度领先的文本处理算子库,集成了 Google 于 2021 年底发布的 LinMaxMatch 算法,该算法引入 Aho-Corasick 将 WordPiece 的时间复杂度从 O(N2) 优化到 O(N),已在 Google 搜索业务中大规模上线。FastTokenizer 速度显著领先,且呈现 batch_size 越大,优势越突出。例如,设置 batch_size = 64 时,FastTokenizer 切词速度比 HuggingFace 快 28 倍。
在 ERNIE 3.0 轻量级模型裁剪、量化基础上,当设置切词线程数为 4 时,使用 FastTokenizer 在 NVIDIA Tesla T4 环境下在 IFLYTEK (长文本分类数据集,最大序列长度为 128)数据集上性能提升了 2.39 倍,相比 BERT-Base 性能提升了 7.09 倍,在 Intel® Xeon® Gold 6271C CPU @ 2.60GHz、线程数为 8 的情况下性能提升了 1.27 倍,相比 BERT-Base 性能提升了 5.13 倍。加速效果如下图所示:
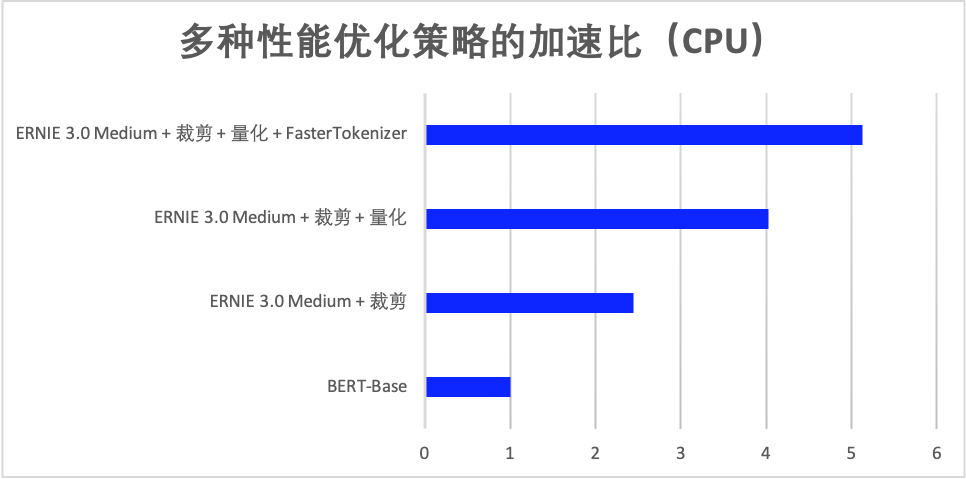
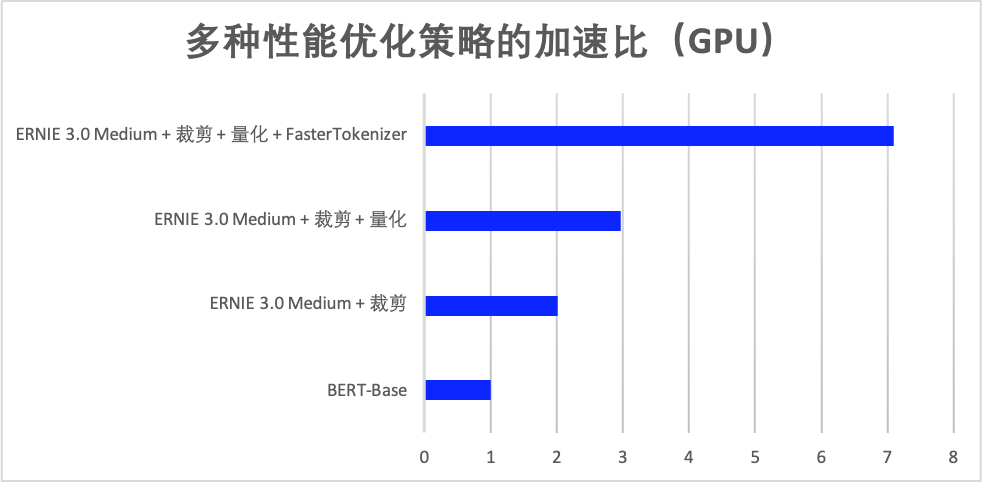
使用 FastTokenizer 的方式非常简单,在安装 fast_tokenizer 包之后,仅需在 tokenizer 实例化时直接传入 use_fast=True 即可。目前已在 Linux 系统下支持 BERT、ERNIE、TinyBERT 等模型。
如需设置切词线程数,需要调用fast_tokenizer.set_thread_num接口进行设置:
# 设置切词线程数为 4
import fast_tokenizer
fast_tokenizer.set_thread_num(4)
调用 from_pretrained 时只需轻松传入一个参数 use_fast=True:
from paddlenlp.transformers import AutoTokenizer
AutoTokenizer.from_pretrained("ernie-3.0-medium-zh", use_fast=True)
!pip install fast-tokenizer-python
!python -u -m paddle.distributed.launch --gpus "0" \
predict_pairwise_fast.py \
--device gpu \
--params_path "/home/aistudio/ernie_matching/checkpoints/model_10000/model_state.pdparams"\
--batch_size 32 \
--max_seq_length 128 \
--input_file '/home/aistudio/datasets/sort/test_pairwise.csv'
2.5 部署
2.5.1 动转静导出:首先把动态图模型转换为静态图:
!python export_model.py --params_path /home/aistudio/ernie_matching/checkpoints/model_10000/model_state.pdparams \
--output_path=./output \
--model_name_or_path ernie-3.0-medium-zh
# 也可以运行下面的bash脚本:自行修改参数
# sh deploy/python/deploy.sh
2.5.2 Paddle Inference
使用PaddleInference:
也可以运行下面的bash脚本:自行修改参数
sh deploy/python/deploy.sh
!python deploy/python/predict.py --model_dir ./output \
--input_file /home/aistudio/datasets/sort/test_pairwise.csv \
--model_name_or_path ernie-3.0-medium-zh
部分结果展示::
Data: {'query': '中西方语言与文化的差异', 'title': '论中西方文化差异在非言语交际中的体现中西方文化,差异,非言语交际'} prob: [0.92894065]
Data: {'query': '中西方语言与文化的差异', 'title': '中西方体态语文化差异跨文化,体态语,非语言交际,差异'} prob: [0.96251774]
Data: {'query': '中西方语言与文化的差异', 'title': '由此便可以发现两种语言以及两种文化的差异。'} prob: [0.85981095]
Data: {'query': '中西方语言与文化的差异', 'title': '文化空缺视域下的中西方体态语对比研究体态语;中西方差异;文化空缺;跨文化交际'} prob: [0.90623915]
Data: {'query': '中西方语言与文化的差异', 'title': '浅析中西方文化差异在语言中的体现及其对翻译的影响中西方文化,差异,语言,翻译,影响'} prob: [0.8928792]
Data: {'query': '中西方语言与文化的差异', 'title': '跨文化交流中文化差异对不同语言运用的影响跨文化交流,语言运用,价值取向,审美观'} prob: [0.8678842]
Data: {'query': '中西方语言与文化的差异', 'title': '文化与语言的关系在中西文化中的映射交际,符号,语言,文化'} prob: [0.919002]
Data: {'query': '中西方语言与文化的差异', 'title': '从中西方文化价值差异看跨文化交际——以电影《推手》为例中西方文化,差异,跨文化交际'} prob: [0.85036314]
Data: {'query': '中西方语言与文化的差异', 'title': '跨文化交际中的文化误读研究文化误读,影响,中华文化,西方文明'} prob: [0.8350103]
Data: {'query': '中西方语言与文化的差异', 'title': '中西方文化差异在翻译中的体现中西方,文化差异,翻译,体现'} prob: [0.87509054]
Data: {'query': '中西方语言与文化的差异', 'title': '从文化差异的角度浅谈汉韩语言对比文化,差异,语言,对比'} prob: [0.8490204]
Data: {'query': '中西方语言与文化的差异', 'title': '跨文化交际中的中西方价值观差异跨文化交际,价值观,差异,中西方'} prob: [0.83267444]
Data: {'query': '中西方语言与文化的差异', 'title': '从体态语看中西文化差异体态语,文化差异,跨文化交际'} prob: [0.91427475]
Data: {'query': '中西方语言与文化的差异', 'title': '高、低语境文化的成因及认识差异跨文化交际,高低语境,文化差异'} prob: [0.8577143]
Data: {'query': '中西方语言与文化的差异', 'title': '中西文化的差异对跨文化交际的影响文化差异,中式英语,跨文化交际'} prob: [0.88657594]
2.5.3 Paddle Serving部署
Paddle Serving 的详细文档请参考 Pipeline_Design和Serving_Design,首先把静态图模型转换成Serving的格式:
#安装依赖
!pip install paddle_serving_client
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting paddle_serving_client
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/d4/78/287bbb4d27ccce75ae7a6206a93196a45b832a39315f0a6b45f0f17f136a/paddle_serving_client-0.9.0-cp37-none-any.whl (44.4 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m44.4/44.4 MB[0m [31m7.2 MB/s[0m eta [36m0:00:00[0m:00:01[0m00:01[0m
[?25hRequirement already satisfied: requests in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle_serving_client) (2.24.0)
Requirement already satisfied: six>=1.10.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle_serving_client) (1.16.0)
Requirement already satisfied: protobuf>=3.11.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle_serving_client) (3.20.0)
Requirement already satisfied: numpy>=1.12 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle_serving_client) (1.19.5)
Collecting grpcio<=1.33.2
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/7a/46/d08d8a5d0e0449f541fe9e7a226854019a41a4fa41fd14332e55b0e4394f/grpcio-1.33.2-cp37-cp37m-manylinux2014_x86_64.whl (3.8 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m3.8/3.8 MB[0m [31m5.2 MB/s[0m eta [36m0:00:00[0m:00:01[0m00:01[0m
[?25hCollecting grpcio-tools<=1.33.2
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/77/1e/91eaee901589ebee04c21df2f551502e7ba946bab99338f77a1f8a4237e1/grpcio_tools-1.33.2-cp37-cp37m-manylinux2014_x86_64.whl (2.5 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m2.5/2.5 MB[0m [31m3.7 MB/s[0m eta [36m0:00:00[0m:00:01[0m00:01[0m
[?25hRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->paddle_serving_client) (1.25.11)
Requirement already satisfied: chardet<4,>=3.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->paddle_serving_client) (3.0.4)
Requirement already satisfied: idna<3,>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->paddle_serving_client) (2.8)
Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->paddle_serving_client) (2019.9.11)
Installing collected packages: grpcio, grpcio-tools, paddle_serving_client
Attempting uninstall: grpcio
Found existing installation: grpcio 1.35.0
Uninstalling grpcio-1.35.0:
Successfully uninstalled grpcio-1.35.0
[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
parl 1.4.1 requires pyzmq==18.1.1, but you have pyzmq 23.2.1 which is incompatible.[0m[31m
[0mSuccessfully installed grpcio-1.33.2 grpcio-tools-1.33.2 paddle_serving_client-0.9.0
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip available: [0m[31;49m22.1.2[0m[39;49m -> [0m[32;49m23.2.1[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m
%cd /home/aistudio/ernie_matching
/home/aistudio/ernie_matching
!python export_to_serving.py \
--dirname "output" \
--model_filename "inference.predict.pdmodel" \
--params_filename "inference.predict.pdiparams" \
--server_path "serving_server" \
--client_path "serving_client" \
--fetch_alias_names "predict"
- 参数含义说明
dirname: 需要转换的模型文件存储路径,Program 结构文件和参数文件均保存在此目录。model_filename: 存储需要转换的模型 Inference Program 结构的文件名称。如果设置为 None ,则使用__model__作为默认的文件名params_filename: 存储需要转换的模型所有参数的文件名称。当且仅当所有模型参数被保>存在一个单独的二进制文件中,它才需要被指定。如果模型参数是存储在各自分离的文件中,设置它的值为 Noneserver_path: 转换后的模型文件和配置文件的存储路径。默认值为 serving_serverclient_path: 转换后的客户端配置文件存储路径。默认值为 serving_clientfetch_alias_names: 模型输出的别名设置,比如输入的 input_ids 等,都可以指定成其他名字,默认不指定feed_alias_names: 模型输入的别名设置,比如输出 pooled_out 等,都可以重新指定成其他模型,默认不指定
这里需要注意,
dirname参数在paddle2.5.0版本中serving_io.inference_model_to_serving算子中被移除了,目前使用paddle2.4.2版本即可。最后在serving_sever会生成4-5个文件
也可以运行下面的 bash 脚本:自行修改参数
sh scripts/export_to_serving.sh
Paddle Serving的部署有两种方式,第一种方式是Pipeline的方式,第二种是C++的方式,下面分别介绍这两种方式的用法:
Pipeline方式部署
修改config_nlp.yml文件中model路径
修改Tokenizer,web_service.py
self.tokenizer = AutoTokenizer.from_pretrained('ernie-3.0-medium-zh')
启动 Pipeline Server:
%cd /home/aistudio/ernie_matching/deploy/python
/home/aistudio/ernie_matching/deploy/python
#安装依赖
!pip install --user paddle-serving-app
!pip install --user paddle-serving-client
!pip install --user paddle-serving-server
#去终端执行
# !python web_service.py
启动客户端调用 Server。
首先修改rpc_client.py中需要预测的样本:
list_data = [{"query":"中西方语言与文化的差异","title":"中西方体态语文化差异跨文化,体态语,非语言交际,差异"}]`
# !python rpc_client.py
模型输出:

Traceback (most recent call last):
File "rpc_client.py", line 33, in <module>
result = np.array(eval(ret.value[0]))
IndexError: list index (0) out of range
如果遇到结果越界等问题,请更改paddle版本,目前使用paddle 2.4.0 develop版本 【介于2.40 2.50之间】
C++的方式部署
启动C++的Serving:
cd /home/aistudio/ernie_matching
# !python -m paddle_serving_server.serve --model serving_server --port 8600 --gpu_id 0 --thread 5 --ir_optim True
遇到相关问题请参考:https://blog.csdn.net/sinat_39620217/article/details/131675175
# python deploy/cpp/rpc_client.py
# python deploy/cpp/http_client.py
time to cost :0.006819009780883789 seconds
[0.96249247]
也可以使用curl方式发送Http请求:
curl -XPOST http://0.0.0.0:8600/GeneralModelService/inference -d ' {"tensor":[{"int64_data":[ 1, 12, 213, 58, 405, 545, 54, 68, 73,
5, 859, 712, 2, 131, 177, 405, 545, 489,
116, 5, 7, 19, 843, 1767, 113, 10, 68,
73, 859, 712, 12043, 2],"elem_type":0,"name":"input_ids","alias_name":"input_ids","shape":[1,32]},
{"int64_data":[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1],"elem_type":0,"name":"token_type_ids","alias_name":"token_type_ids","shape":[1,32]}
],
"fetch_var_names":["sigmoid_2.tmp_0"],
"log_id":0
}'
3.基于RocketQA的CrossEncoder训练的单塔模型
基于RocketQA的CrossEncoder(交叉编码器)训练的单塔模型,该模型用于搜索的排序阶段,对召回的结果进行重新排序的作用。
CrossEncoder和Pairwise区别:
输入方式:
- Pairwise模型:接受两个文本对作为输入,通常是一个正例和一个负例。正例表示相关的文本对,负例表示不相关的文本对。
- CrossEncoder模型:接受多个文本对作为输入,可以同时处理多个文本对的相关性判断。
训练方式:
- Pairwise模型:通过训练模型来学习区分正例和负例之间的特征。模型会比较两个文本对之间的相似度或相关性,并为每个文本对产生一个得分或预测标签。
通过将文本对转化为三个样本来训练:正样本(相关的文本对),负样本(不相关的文本对),以及参考样本(用于度量两个样本之间的相关性)。这个模型的目标是训练一个二分类器,将正样本得分高于负样本。经过编码器(通常是基于深度学习的模型,如BERT)进行编码。然后,编码后的文本会通过一个相似度计算方法(如余弦相似度或点积)生成一个相关性得分,用于判断文本对的相关性。
- CrossEncoder模型:一次性对多个文本对进行编码和判断。模型会将多个文本对作为整体输入,学习捕捉多个文本对之间的关系,并输出它们之间的相关性得分或标签。
将一对文本作为单个样本来训练,不需要额外的负样本和参考样本。这个模型的目标是训练一个多分类器,将不同的文本对分为相关的和不相关的类别。它们经过编码器进行编码,并在编码后的表示上应用一个多层感知机或其他类型的全连接网络。该网络将文本对的编码表示映射到相关性得分或概率。
处理效率:
- Pairwise模型:由于是逐对比较,处理效率相对较低。需要遍历每对文本对进行比较和预测,特别是在大规模的文本对数据集上训练和推断时,效率会较低。
- CrossEncoder模型:可以一次性处理多个文本对,因此在处理大规模文本对任务时具有较高的效率。能够进行批量处理,减少了逐对比较的时间消耗。
应用场景:
- Pairwise模型:常用于文本排序或排名任务,如搜索引擎中的搜索结果排序、推荐系统中的推荐列表排序等。
- CrossEncoder模型:适用于需要同时处理多个文本对的任务,如阅读理解中的问题-答案匹配、文本匹配中的相似性判断等。
Pairwise模型更适用于在大规模数据集上进行训练,因为它可以从大量的正样本和负样本中学习到相关性特征。而CrossEncoder模型则不需要额外的负样本,因此在训练数据有限的情况下可能更容易实现。
3.1 代码结构
cross_encoder/
├── deply # 部署
├── cpp
├── rpc_client.py # RPC 客户端的bash脚本
├── http_client.py # http 客户端的bash文件
└── start_server.sh # 启动C++服务的脚本
└── python
├── deploy.sh # 预测部署bash脚本
├── config_nlp.yml # Pipeline 的配置文件
├── web_service.py # Pipeline 服务端的脚本
├── rpc_client.py # Pipeline RPC客户端的脚本
└── predict.py # python 预测部署示例
|—— scripts
├── export_model.sh # 动态图参数导出静态图参数的bash文件
├── export_to_serving.sh # 导出 Paddle Serving 模型格式的bash文件
├── train_ce.sh # 匹配模型训练的bash文件
├── evaluate_ce.sh # 评估验证文件bash脚本
├── predict_ce.sh # 匹配模型预测脚本的bash文件
├── export_model.py # 动态图参数导出静态图参数脚本
├── export_to_serving.py # 导出 Paddle Serving 模型格式的脚本
├── data.py # 训练样本的转换逻辑
├── train_ce.py # 模型训练脚本
├── evaluate.py # 评估验证文件
├── predict.py # Pair-wise 模型预测脚本,输出文本对是相似度
- [literature_search_rank]数据集情况
├── data # 排序数据集
├── test.csv # 测试集
├── dev_pairwise.csv # 验证集
└── train.csv # 训练集
#数据查看
import csv
def show_data(filename, num_rows=10):
with open(filename, 'r') as f:
reader = csv.reader(f)
header = next(reader) # 获取表头
print(header) # 打印表头
for i, row in enumerate(reader):
if i < num_rows: # 打印前num_rows行数据
print(row)
else:
break
line = '-' * 100
print(line)
show_data('/home/aistudio/datasets/literature_search_rank/test.csv', num_rows=5)
['加强科研项目管理有效促进医学科研工作\t科研项目管理策略科研项目', '项目管理', '实施', '必要性', '策略\t0.32163668']
['加强科研项目管理有效促进医学科研工作\t关于推进我院科研发展进程的相关问题研究医院科研', '主体', '环境', '信息化\t0.32922596']
['加强科研项目管理有效促进医学科研工作\t深圳科技计划对高校科研项目资助现状分析与思考基础研究', '高校', '科技计划', '科技创新\t0.36869502']
['加强科研项目管理有效促进医学科研工作\t普通高校科研管理模式的优化与创新普通高校', '科研', '科研管理\t0.3688045']
['加强科研项目管理有效促进医学科研工作\t科研项目管理在研究院的应用研究科研项目管理', '研究院', '应用\t0.38164502']
['加强科研项目管理有效促进医学科研工作\t转化医学理念下的医学研究生科研能力培养转化医学', '医学研究生', '科研能力\t0.3912356']
----------------------------------------------------------------------------------------------------
3.2 模型训练
%cd /home/aistudio/cross_encoder
/home/aistudio/cross_encoder
!unset CUDA_VISIBLE_DEVICES
!python -u -m paddle.distributed.launch --gpus "0" --log_dir="logs" train_ce.py \
--device gpu \
--train_set /home/aistudio/datasets/literature_search_rank/train.csv \
--test_file /home/aistudio/datasets/literature_search_rank/dev_pairwise.csv \
--save_dir ./checkpoints \
--model_name_or_path rocketqa-base-cross-encoder \
--batch_size 64 \
--save_steps 10000 \
--max_seq_len 128 \
--learning_rate 2E-5 \
--weight_decay 0.0 \
--warmup_proportion 0.1 \
--logging_steps 10 \
--seed 1 \
--epochs 1 \
--eval_step 5000
参数情况:
parser.add_argument("--save_dir", default='./checkpoint', type=str, help="The output directory where the model checkpoints will be written.")
parser.add_argument("--train_set", type=str, required=True, help="The full path of train_set_file.")
parser.add_argument("--test_file", type=str, required=True, help="The full path of test file")
parser.add_argument("--max_seq_length", default=128, type=int, help="The maximum total input sequence length after tokenization. Sequences longer than this will be truncated, sequences shorter will be padded.")
parser.add_argument("--batch_size", default=32, type=int, help="Batch size per GPU/CPU for training.")
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
parser.add_argument("--epochs", default=3, type=int, help="Total number of training epochs to perform.")
parser.add_argument("--warmup_proportion", default=0.0, type=float, help="Linear warmup proportion over the training process.")
parser.add_argument("--valid_steps", default=100, type=int, help="The interval steps to evaluate model performance.")
parser.add_argument("--save_steps", default=100, type=int, help="The interval steps to save checkppoints.")
parser.add_argument("--logging_steps", default=10, type=int, help="The interval steps to logging.")
parser.add_argument("--init_from_ckpt", type=str, default=None, help="The path of checkpoint to be loaded.")
parser.add_argument("--seed", type=int, default=1000, help="random seed for initialization")
parser.add_argument('--device', choices=['cpu', 'gpu', 'xpu', 'npu'], default="gpu", help="Select which device to train model, defaults to gpu.")
parser.add_argument("--use_amp", type=strtobool, default=False, help="Enable mixed precision training.")
parser.add_argument("--scale_loss", type=float, default=2**15, help="The value of scale_loss for fp16.")
parser.add_argument('--model_name_or_path', default="rocketqa-base-cross-encoder", help="The pretrained model used for training")
parser.add_argument("--eval_step", default=200, type=int, help="Step interval for evaluation.")
部分结果展示:
global step 44910, epoch: 1, batch: 44910, loss: 0.65030, accuracy: 0.59375, speed: 10.82 step/s
global step 44920, epoch: 1, batch: 44920, loss: 0.68002, accuracy: 0.51562, speed: 10.63 step/s
global step 44930, epoch: 1, batch: 44930, loss: 0.61875, accuracy: 0.70312, speed: 11.07 step/s
global step 44940, epoch: 1, batch: 44940, loss: 0.61720, accuracy: 0.64062, speed: 10.94 step/s
global step 44950, epoch: 1, batch: 44950, loss: 0.59746, accuracy: 0.75000, speed: 10.87 step/s
global step 44960, epoch: 1, batch: 44960, loss: 0.66000, accuracy: 0.60938, speed: 11.00 step/s
global step 44970, epoch: 1, batch: 44970, loss: 0.64734, accuracy: 0.57812, speed: 10.60 step/s
global step 44980, epoch: 1, batch: 44980, loss: 0.63164, accuracy: 0.67188, speed: 11.12 step/s
global step 44990, epoch: 1, batch: 44990, loss: 0.65815, accuracy: 0.60938, speed: 10.77 step/s
global step 45000, epoch: 1, batch: 45000, loss: 0.58931, accuracy: 0.75000, speed: 10.08 step/s
eval_dev auc:0.804
3.3 模型评估
!python evaluate.py --model_name_or_path rocketqa-base-cross-encoder \
--init_from_ckpt /home/aistudio/cross_encoder/checkpoints/model_20000/model_state.pdparams \
--test_file /home/aistudio/datasets/literature_search_rank/dev_pairwise.csv
3.4 模型预测+FastTokenizer 加速
!unset CUDA_VISIBLE_DEVICES
!python predict.py \
--device 'gpu' \
--params_path /home/aistudio/cross_encoder/checkpoints/model_10000/model_state.pdparams \
--model_name_or_path rocketqa-base-cross-encoder \
--test_set /home/aistudio/datasets/literature_search_rank/test.csv \
--topk 10 \
--batch_size 128 \
--max_seq_length 384
#使用 FastTokenizer 加速
!unset CUDA_VISIBLE_DEVICES
!python predict.py \
--device 'gpu' \
--params_path /home/aistudio/cross_encoder/checkpoints/model_10000/model_state.pdparams \
--model_name_or_path rocketqa-base-cross-encoder \
--test_set /home/aistudio/datasets/literature_search_rank/test.csv \
--topk 10 \
--batch_size 128 \
--max_seq_length 384
部分结果展示:
{'text_a': '加强科研项目管理有效促进医学科研工作', 'text_b': '科研项目管理策略科研项目,项目管理,实施,必要性,策略', 'pred_prob': 0.6349033}
{'text_a': '加强科研项目管理有效促进医学科研工作', 'text_b': '某医院科研现状的剖析及对策科研,发展,课题,管理,科室', 'pred_prob': 0.5942339}
{'text_a': '加强科研项目管理有效促进医学科研工作', 'text_b': '关于推进我院科研发展进程的相关问题研究医院科研,主体,环境,信息化', 'pred_prob': 0.5800889}
{'text_a': '加强科研项目管理有效促进医学科研工作', 'text_b': '医学临床科研选题原则和方法医学临床,科学研究,选题', 'pred_prob': 0.57478607}
{'text_a': '加强科研项目管理有效促进医学科研工作', 'text_b': '普通高校科研管理模式的优化与创新普通高校,科研,科研管理', 'pred_prob': 0.5666871}
{'text_a': '加强科研项目管理有效促进医学科研工作', 'text_b': '科研项目管理在研究院的应用研究科研项目管理,研究院,应用', 'pred_prob': 0.5654926}
{'text_a': '加强科研项目管理有效促进医学科研工作', 'text_b': '全科医生进行科学研究的必要性及可行性分析', 'pred_prob': 0.5641118}
{'text_a': '加强科研项目管理有效促进医学科研工作', 'text_b': '对中国高校科研组织创新与改革的思考高校,科研组织,创新', 'pred_prob': 0.55624706}
{'text_a': '加强科研项目管理有效促进医学科研工作', 'text_b': '我国高校科研经费投入与科研进实证研究--以1997-2015年自然科学研究为例高校科研经费,科研进程,自然科学,面板固定效应', 'pred_prob': 0.54644823}
{'text_a': '加强科研项目管理有效促进医学科研工作', 'text_b': '浅析临床科研不端行为及其对策研究临床科研,不端行为,原因,对策研究', 'pred_prob': 0.54628867}
3.5 部署
- 动转静导出:首先把动态图模型转换为静态图:
!python export_model.py \
--params_path /home/aistudio/cross_encoder/checkpoints/model_20000/model_state.pdparams \
--model_name_or_path rocketqa-base-cross-encoder \
--output_path=./output
#Paddle Inference使用PaddleInference
!python deploy/python/predict.py --model_dir ./output \
--input_file /home/aistudio/datasets/literature_search_rank/test.csv \
--model_name_or_path rocketqa-base-cross-encoder
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '科研项目管理策略科研项目,项目管理,实施,必要性,策略'} prob: 0.019560515880584717
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '关于推进我院科研发展进程的相关问题研究医院科研,主体,环境,信息化'} prob: 0.017550336197018623
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '深圳科技计划对高校科研项目资助现状分析与思考基础研究,高校,科技计划,科技创新'} prob: 0.011902198195457458
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '普通高校科研管理模式的优化与创新普通高校,科研,科研管理'} prob: 0.01703336462378502
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '科研项目管理在研究院的应用研究科研项目管理,研究院,应用'} prob: 0.016974376514554024
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '转化医学理念下的医学研究生科研能力培养转化医学,医学研究生,科研能力'} prob: 0.015649331733584404
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '校企科研合作项目管理模式创新校企科研合作项目,管理模式,问题,创新'} prob: 0.01423538289964199
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '某医院科研现状的剖析及对策科研,发展,课题,管理,科室'} prob: 0.018114319071173668
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '香港科技大学的科研经费来源和项目管理科研经费,研究型大学,科研管理,香港科技大学'} prob: 0.012444108724594116
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '创业实践引领医学实验技术学生创新能力培养的研究与实践医学实验技术,创新创业,学生培养,教育改革'} prob: 0.01428439561277628
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '戴明环在医院科研管理中的应用戴明环,质量管理,医院科研管理'} prob: 0.012266729027032852
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '对中国高校科研组织创新与改革的思考高校,科研组织,创新'} prob: 0.016747653484344482
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '高校医疗卫生转化协同组织建设的新思考——理论·案例·创新协同创新,转化医学,高校医疗卫生转化协同组织'} prob: 0.012818017043173313
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '高校科研项目经费管理流程优化研究——以z大学为例高校,科研项目经费\\全流程\\管理,流程优化'} prob: 0.014895331114530563
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '科研院所项目经费管理问题探究科研院所,科研项目,经费管理,预算管理'} prob: 0.015510806813836098
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '高校\\十四五\\规划中学科建设要处理好五对关系\\十四五\\规划,学科建设,科技创新,人才培养'} prob: 0.014887562021613121
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '科学基金资助主题的演化路径分析与预测——以科技管理与政策学科为例主题演化路径分析,文本挖掘,科技管理与政策,国家自然科学基金'} prob: 0.01249507162719965
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '建立国家基金数据库作用初探科技论文,基金标注,国家数据库'} prob: 0.010099323466420174
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '——以泰州学院为例科技创新,科研管理,新建本科院校'} prob: 0.012956062331795692
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '如何破解科技型中小企业研发资金短缺难题——政府科研项目申报中小企业,政府补贴,科研经费,项目申报'} prob: 0.013188485987484455
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '中国研究型医院学会加速康复外科专业委员会在杭州成立研究型医院,外科专业,中国科学院院士,名誉主任委员,医院院长,黎介寿院士,王学浩,汪忠镐,赵玉,陈孝'} prob: 0.011520893312990665
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '不断向科学技术广度和深度进军'} prob: 0.016157878562808037
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '依托综合性实验培养中药、制药专业学生创新能力的探索与实践'} prob: 0.011441102251410484
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '浅析科技计划管理工作中的问题及对策工作中的问题,科技计划管理,管理工作,科技计划项目'} prob: 0.015905817970633507
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '加强高校研究生组织建设,提升研究生培养质量研究生组织,管理体系,培养质量'} prob: 0.014584081247448921
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '医学临床科研选题原则和方法医学临床,科学研究,选题'} prob: 0.01737641729414463
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '科研院校横向项目技术合同的签订与管理科研院校,横向项目,技术合同,签订,管理'} prob: 0.013706715777516365
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '我国科技信息机构科研现状分析科研信息,机构,现状,不足'} prob: 0.014352910220623016
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '中医药院校研究生科研能力培养途径探析中医药院校,研究生,科研能力,培养途径'} prob: 0.01295175775885582
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '面向新基建交叉学科人才培养推进高校科技智库建设——西北工业大学经验探析新型基础设施建设(新基建),学科交叉,高校智库,高等教育,人才培养'} prob: 0.011521492153406143
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '医学本科生团队式自主学习模式的构建及实践研究高等教育;医学专业;团队式自主学习;人才培养'} prob: 0.014391692355275154
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '课题研究中别忘了研究'} prob: 0.015797043219208717
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '加强中小学教科研管理的有效策略一线教师,教师专业化发展,贯彻落实,科研管理,教育教学,科学发展观,教育科研,第一生产力,教学质量,教科研'} prob: 0.020737258717417717
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '高校国家重点实验室创新管理运行机制探讨'} prob: 0.024756591767072678
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '加强团队协作,促进临床研究的发展'} prob: 0.02781500667333603
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '充分发挥专业知识,更高效率地开展中医药科学普及工作'} prob: 0.025189649313688278
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '浅析临床科研不端行为及其对策研究临床科研,不端行为,原因,对策研究'} prob: 0.02854585275053978
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '湖北省科技计划项目档案管理现状及对策科技计划项目档案管理,现状,对策'} prob: 0.018492119386792183
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '加大学科竞赛建设,促进高校创新型人才培养'} prob: 0.02778143435716629
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '我国高校科研经费投入与科研进实证研究--以1997-2015年自然科学研究为例高校科研经费,科研进程,自然科学,面板固定效应'} prob: 0.029364528134465218
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '“线索引探法”教学模式的探索与实践化学教学;线索引探;教学模式'} prob: 0.01699548400938511
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '\\医工交叉\\科研训练在医学生化学教学中的应用化学,教学改革,\\医工交叉\\科研训练'} prob: 0.022152472287416458
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '精准育人因群施教——高校研究生会参与研究生培养的创新与实践研究生会,精准育人,因“群”施教,研究生教育'} prob: 0.017730163410305977
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '高职院校教学科研一体化的有效融合高职院校,教学科研一体化,有效融合'} prob: 0.019837621599435806
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '高新技术企业成本控制存在的问题与对策研究——以信威集团为例成本控制;高新技术企业;人力资源;技术管理'} prob: 0.01853526011109352
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '多学科团队诊疗模式在新建综合医院肿瘤临床教学中的作用探讨多学科团队诊疗模式,新建综合医院,肿瘤医学,临床教学'} prob: 0.022034015506505966
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '国家自然科学基金对科研人员科研绩效的影响研究国家自然科学基金;科研人员;科研绩效'} prob: 0.023988042026758194
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '科技社团在国家创新体系中促进知识流动的积极作用'} prob: 0.027556443586945534
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '协同育人背景下医学研究生培养与过程管理问题浅析协同育人,医学研究生,培养,管理'} prob: 0.026658549904823303
Data: {'query': '加强科研项目管理有效促进医学科研工作', 'title': '全科医生进行科学研究的必要性及可行性分析'} prob: 0.02971765026450157
#安装依赖
!pip install paddle_serving_client
!pip install --user paddle-serving-app
!pip install --user paddle-serving-client
!pip install --user paddle-serving-server
# Paddle Serving部署
!python export_to_serving.py \
--dirname "output" \
--model_filename "inference.pdmodel" \
--params_filename "inference.pdiparams" \
--server_path "serving_server" \
--client_path "serving_client" \
--fetch_alias_names "predict"
I0728 16:23:59.050568 12655 interpretercore.cc:273] New Executor is Running.
参数含义说明
dirname: 需要转换的模型文件存储路径,Program 结构文件和参数文件均保存在此目录。model_filename: 存储需要转换的模型 Inference Program 结构的文件名称。如果设置为 None ,则使用__model__作为默认的文件名params_filename: 存储需要转换的模型所有参数的文件名称。当且仅当所有模型参数被保>存在一个单独的二进制文件中,它才需要被指定。如果模型参数是存储在各自分离的文件中,设置它的值为 Noneserver_path: 转换后的模型文件和配置文件的存储路径。默认值为 serving_serverclient_path: 转换后的客户端配置文件存储路径。默认值为 serving_clientfetch_alias_names: 模型输出的别名设置,比如输入的 input_ids 等,都可以指定成其他名字,默认不指定feed_alias_names: 模型输入的别名设置,比如输出 pooled_out 等,都可以重新指定成其他模型,默认不指定
#Pipeline方式
# %cd /home/aistudio/cross_encoder/deploy/python
# !python web_service.py
# !python rpc_client.py
终端启动效果如下:
C++的方式:Client 可以使用 http 或者 rpc 两种方式参考第二章节相关步骤即可
总结
| 训练方式 | 模型 | epoch | AUC | 训练时长 | 其他 |
|---|---|---|---|---|---|
| pairwise | ERNIE-Gram | 1(仅1w steps) | 0.791 | 20min | 个人 |
| CrossEncoder | rocketqa-base-cross-encoder | 1(仅1w steps) | 0.785 | 20min | 个人 |
| CrossEncoder | rocketqa-base-cross-encoder | 1(仅4.5w steps) | 0.804 | 50 min | 个人 |
| pairwise | ERNIE-Gram | 3 | 0.801 | 20h | 官方 |
| CrossEncoder | rocketqa-base-cross-encoder | 3 | 0.835 | 20h | 官方 |
整体CrossEncoder训练方式优于pairwise,这里我就不长时间训练下去,仅简单增加训练时长进行对比验证了一下。
本项目提供了排序模块有2种选择:
第一种基于前沿的预训练模型 ERNIE,训练 Pair-wise 语义匹配模型;
第二种是基于RocketQA模型训练的Cross Encoder模型。
CrossEncoder和Pairwise区别:
输入方式:
- Pairwise模型:接受两个文本对作为输入,通常是一个正例和一个负例。正例表示相关的文本对,负例表示不相关的文本对。
- CrossEncoder模型:接受多个文本对作为输入,可以同时处理多个文本对的相关性判断。
训练方式:
- Pairwise模型:通过训练模型来学习区分正例和负例之间的特征。模型会比较两个文本对之间的相似度或相关性,并为每个文本对产生一个得分或预测标签。
通过将文本对转化为三个样本来训练:正样本(相关的文本对),负样本(不相关的文本对),以及参考样本(用于度量两个样本之间的相关性)。这个模型的目标是训练一个二分类器,将正样本得分高于负样本。经过编码器(通常是基于深度学习的模型,如BERT)进行编码。然后,编码后的文本会通过一个相似度计算方法(如余弦相似度或点积)生成一个相关性得分,用于判断文本对的相关性。
- CrossEncoder模型:一次性对多个文本对进行编码和判断。模型会将多个文本对作为整体输入,学习捕捉多个文本对之间的关系,并输出它们之间的相关性得分或标签。
将一对文本作为单个样本来训练,不需要额外的负样本和参考样本。这个模型的目标是训练一个多分类器,将不同的文本对分为相关的和不相关的类别。它们经过编码器进行编码,并在编码后的表示上应用一个多层感知机或其他类型的全连接网络。该网络将文本对的编码表示映射到相关性得分或概率。
处理效率:
- Pairwise模型:由于是逐对比较,处理效率相对较低。需要遍历每对文本对进行比较和预测,特别是在大规模的文本对数据集上训练和推断时,效率会较低。
- CrossEncoder模型:可以一次性处理多个文本对,因此在处理大规模文本对任务时具有较高的效率。能够进行批量处理,减少了逐对比较的时间消耗。
应用场景:
- Pairwise模型:常用于文本排序或排名任务,如搜索引擎中的搜索结果排序、推荐系统中的推荐列表排序等。
- CrossEncoder模型:适用于需要同时处理多个文本对的任务,如阅读理解中的问题-答案匹配、文本匹配中的相似性判断等。
Pairwise模型更适用于在大规模数据集上进行训练,因为它可以从大量的正样本和负样本中学习到相关性特征,但对于噪声数据更为敏感,即一个错误的标注会导致多个pair对的错误。而CrossEncoder模型则不需要额外的负样本,因此在训练数据有限的情况下可能更容易实现。
语义搜索系列文章全流程教学:
更多文本匹配方案参考:
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

- 点赞
- 收藏
- 关注作者
评论(0)