语义检索系统:基于Milvus 搭建召回系统抽取向量进行检索,加速索引

语义检索系统:基于Milvus 搭建召回系统抽取向量进行检索,加速索引
目标:使用 Milvus 搭建召回系统,然后使用训练好的语义索引模型,抽取向量,插入到 Milvus 中,然后进行检索。
语义搜索系列文章全流程教学:
更多文本匹配方案参考:
这个项目完成的同学,那我们举例整体的推荐系统就只差排序环节,这次基于milvus向量索引会遇到一些问题,请大家耐心看我给出的文档说明,慢慢解决。
1.Milvus简介(2019)
1.1 什么是向量检索
向量是具有一定大小和方向的量,可以简单理解为一串数字的集合,就像一行多列的矩阵,比如:[2,0,1,9,0,6,3,0]。每一行代表一个数据项,每一列代表一个该数据项的各个属性。
特征向量是包含事物重要特征的向量。大家比较熟知的一个特征向量是RGB (红-绿-蓝)色彩。每种颜色都可以通过对红®、绿(G)、蓝(B)三种颜色的比例来得到。这样一个特征向量可以描述为:颜色 = [红,绿,蓝]。
向量检索是指从向量库中检索出距离目标向量最近的 K 个向量。一般我们用两个向量间的欧式距离,余弦距离等来衡量两个向量间的距离,一次来评估两个向量的相似度。
1.2 Milvus简介
点击进入 Milvus 官网。

Milvus创建于2019年,其目标只有一个:存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大量嵌入向量。作为一个专门设计用于处理输入向量查询的数据库,它能够在万亿规模上对向量进行索引。与现有的关系数据库主要按照预定义的模式处理结构化数据不同,Milvus是从自底向上设计的,以处理从非结构化数据转换而来的嵌入向量。
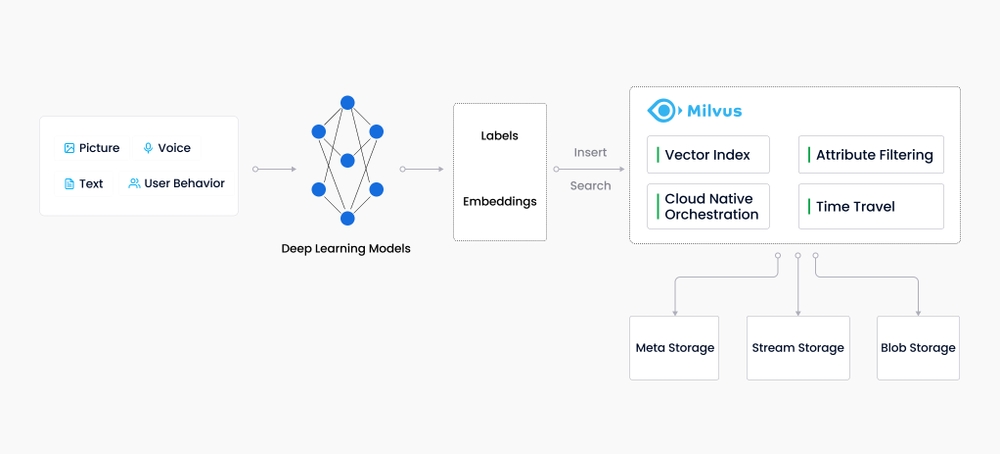
Milvus 是一款开源的向量数据库,支持针对 TB 级向量的增删改操作和近实时查询,具有高度灵活、稳定可靠以及高速查询等特点。Milvus 集成了 Faiss、NMSLIB、Annoy 等广泛应用的向量索引库,Milvus 支持数据分区分片、数据持久化、增量数据摄取、标量向量混合查询、time travel 等功能,同时大幅优化了向量检索的性能,可满足任何向量检索场景的应用需求,提供了一整套简单直观的 API,让你可以针对不同场景选择不同的索引类型。此外,Milvus 还可以对标量数据进行过滤,进一步提高了召回率,增强了搜索的灵活性。
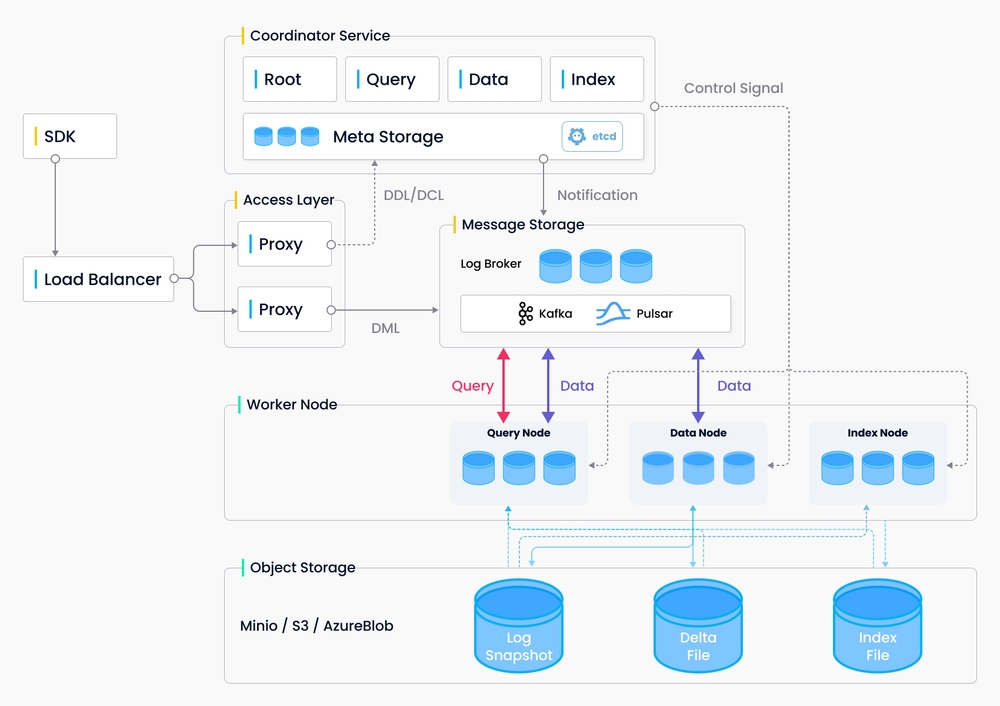
Milvus 采用共享存储架构,存储计算完全分离,计算节点支持横向扩展。从架构上来看,Milvus 遵循数据流和控制流分离,整体分为了四个层次:分别为接入层(access layer)、协调服务(coordinator service)、执行节点(worker node)和存储层(storage)。各个层次相互独立,独立扩展和容灾。
随着互联网的发展和发展,非结构化数据变得越来越普遍,包括电子邮件、论文、物联网传感器数据、Facebook照片、蛋白质结构等等。为了让计算机理解和处理非结构化数据,使用嵌入技术将这些数据转换为向量。Milvus存储并索引这些向量。Milvus能够通过计算两个向量的相似距离来分析它们之间的相关性。如果两个嵌入向量非常相似,则表示原始数据源也非常相似。Milvus 向量数据库专为向量查询与检索设计,能够为万亿级向量数据建立索引。与现有的主要用作处理结构化数据的关系型数据库不同,Milvus 在底层设计上就是为了处理由各种非结构化数据转换而来的 Embedding 向量而生。
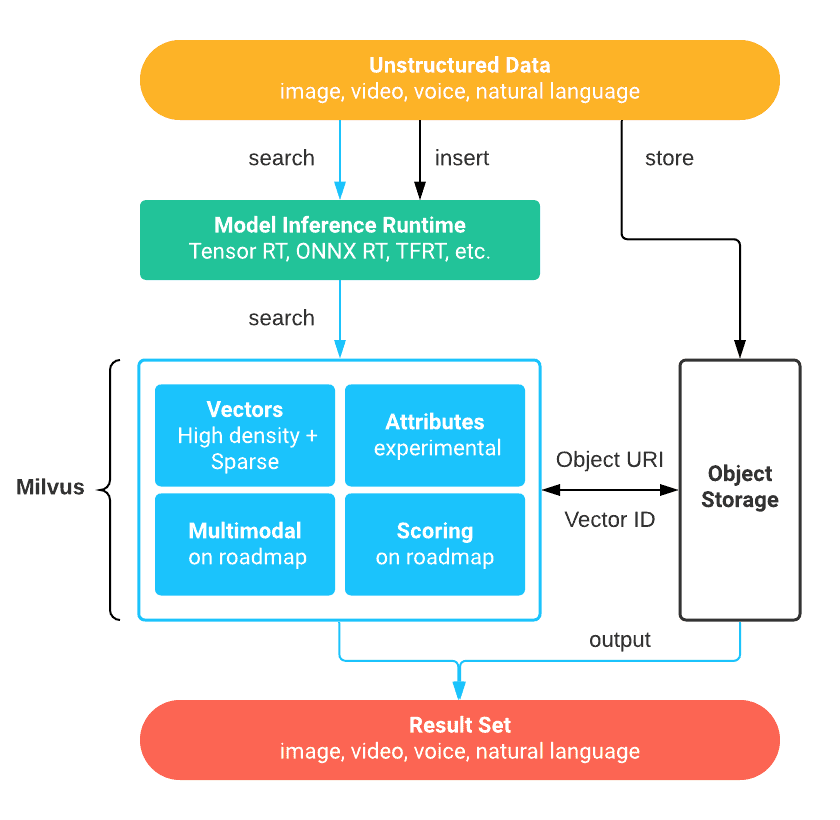
在服务端,Milvus 由 Milvus Core 和 Meta Store 两部分组成:
- Milvus Core 存储与管理向量和标量数据。
- Meta Store 存储与管理 SQLite 和 MySQL 中的元数据,分别用于测试和生产。
Milvus 服务器采用主从式架构 (Client-server model),整体架构:
1.3 产品优势
全面的相似性指标:Milvus 支持各种常用的向量相似度计算指标,包括欧氏距离、内积、汉明距离和杰卡德距离等。高性能:Milvus 基于高度优化的 Approximate Nearest Neighbor Search (ANNS) 索引库构建,包括 faiss、 annoy、和 hnswlib 等。您可以针对不同使用场景选择不同的索引类型。动态数据管理:您可以随时对数据进行插入、删除、搜索、更新等操作而无需受到静态数据带来的困扰。高成本效益:Milvus 充分利用现代处理器的并行计算能力,可以在单台通用服务器上完成对十亿级数据的毫秒级搜索。近实时搜索:在插入或更新数据之后,您可以几乎立刻对插入或更新过的数据进行搜索。Milvus 负责保证搜索结果的准确率和数据一致性。支持多种数据类型和高级搜索: Milvus 的数据记录中的字段支持多种数据类型。高扩展性和可靠性:您可以在分布式环境中部署 Milvus。如果要对集群扩容或者增加可靠性,您只需增加节点。云原生:您可以轻松在公有云、私有云、或混合云上运行 Milvus。简单易用:Milvus 提供了易用的 Python、Java、Go 和 C++ SDK,另外还提供了 RESTful API。
1.4 Milvus 应用场景
你可以使用 Milvus 搭建符合自己场景需求的向量相似度检索系统。Milvus 的使用场景如下所示:
图片检索系统:以图搜图,从海量数据库中即时返回与上传图片最相似的图片。视频检索系统:将视频关键帧转化为向量并插入 Milvus,便可检索相似视频,或进行实时视频推荐。音频检索系统:快速检索海量演讲、音乐、音效等音频数据,并返回相似音频。分子式检索系统:超高速检索相似化学分子结构、超结构、子结构。推荐系统:根据用户行为及需求推荐相关信息或商品。智能问答机器人:交互式智能问答机器人可自动为用户答疑解惑。DNA 序列分类系统:通过对比相似 DNA 序列,仅需几毫秒便可精确对基因进行分类。文本搜索引擎:帮助用户从文本数据库中通过关键词搜索所需信息。更多资料参考:
2. 环境依赖和安装说明
环境依赖
python >= 3.6.2
paddlepaddle >= 2.2
paddlenlp >= 2.2
milvus >= 2.1.0
pymilvus >= 2.1.0
代码结构
|—— scripts
|—— feature_extract.sh 提取特征向量的bash脚本
|—— search.sh 插入向量和向量检索bash脚本
├── base_model.py # 语义索引模型基类
├── config.py # milvus配置文件
├── data.py # 数据处理函数
├── milvus_ann_search.py # 向量插入和检索的脚本
├── inference.py # 动态图模型向量抽取脚本
├── feature_extract.py # 批量抽取向量脚本
├── milvus_util.py # milvus的工具类
└── README.md
4. 数据准备
数据集的样例如下,有两种,第一种是 title+keywords 进行拼接;第二种是一句话。
煤矸石-污泥基活性炭介导强化污水厌氧消化煤矸石,污泥,复合基活性炭,厌氧消化,直接种间电子传递
睡眠障碍与常见神经系统疾病的关系睡眠觉醒障碍,神经系统疾病,睡眠,快速眼运动,细胞增殖,阿尔茨海默病
城市道路交通流中观仿真研究智能运输系统;城市交通管理;计算机仿真;城市道路;交通流;路径选择
....
数据集下载
├── milvus # milvus建库数据集
├── milvus_data.csv. # 构建召回库的数据
├── recall # 召回(语义索引)数据集
├── corpus.csv # 用于测试的召回库
├── dev.csv # 召回验证集
├── test.csv # 召回测试集
├── train.csv # 召回训练集
├── train_unsupervised.csv # 无监督训练集
├── sort # 排序数据集
├── test_pairwise.csv # 排序测试集
├── dev_pairwise.csv # 排序验证集
└── train_pairwise.csv # 排序训练集
!pip install -r requirements.txt
#解压数据集
# !unzip -d /home/aistudio/literature_search_data /home/aistudio/data/data225060/literature_search_data.zip
#数据查看
import csv
def show_data(filename, num_rows=10):
with open(filename, 'r') as f:
reader = csv.reader(f)
header = next(reader) # 获取表头
print(header) # 打印表头
for i, row in enumerate(reader):
if i < num_rows: # 打印前num_rows行数据
print(row)
else:
break
line = '-' * 100
print(line)
show_data('/home/aistudio/literature_search_data/milvus/milvus_data.csv', num_rows=5)
['wodem又出了花月瑶的鞋']
['黄电容信仰加持']
['15、andy从废柴到欧洲巡演发唱片到学会了一个人生活,errol长大了声线粗了也有了自己的同龄朋友,这是我看过最好的英剧前三。']
['结语:随着国家“二孩”政策的放开,越来越多的消费者倾向于购买空间更宽敞,舒适性更强的mpv车型。']
['玩一慧?']
['Study of New Driving Force for Quality Improvement of the Cultivation of Applied College Talents - Centering on Career Planning for College Students']
----------------------------------------------------------------------------------------------------
5. 向量检索
5.1 基于Milvus的向量检索系统搭建
数据准备结束以后,开始搭建 Milvus 的语义检索引擎,用于语义向量的快速检索,使用Milvus开源工具进行召回,Milvus 的搭建教程请参考官方教程 Milvus官方安装教程本案例使用的是 Milvus 的2.1版本,建议使用官方的 Docker 安装方式,简单快捷。
Milvus 搭建完系统以后就可以插入和检索向量了,首先生成 embedding 向量,每个样本生成256维度的向量,使用的是32GB的V100的卡进行的提取:
5.1.1 生成 embedding 向量
#默认GPU,A100下需要转换1h20min
!CUDA_VISIBLE_DEVICES=0 python feature_extract.py \
--model_dir=./output \
--model_name_or_path rocketqa-zh-base-query-encoder \
--corpus_file "/mnt/data_1/model/Vector_retrieval/literature_search_data/milvus/milvus_data.csv"
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/_distutils_hack/__init__.py:33: UserWarning: Setuptools is replacing distutils.
warnings.warn("Setuptools is replacing distutils.")
[1m[35m--- Running analysis [ir_graph_build_pass][0m
I0713 16:49:07.969594 6532 executor.cc:187] Old Executor is Running.
[1m[35m--- Running analysis [ir_analysis_pass][0m
[32m--- Running IR pass [map_op_to_another_pass][0m
[32m--- Running IR pass [identity_scale_op_clean_pass][0m
[32m--- Running IR pass [is_test_pass][0m
[32m--- Running IR pass [simplify_with_basic_ops_pass][0m
[32m--- Running IR pass [delete_quant_dequant_linear_op_pass][0m
[32m--- Running IR pass [delete_weight_dequant_linear_op_pass][0m
[32m--- Running IR pass [constant_folding_pass][0m
[32m--- Running IR pass [silu_fuse_pass][0m
[32m--- Running IR pass [conv_bn_fuse_pass][0m
[32m--- Running IR pass [conv_eltwiseadd_bn_fuse_pass][0m
[32m--- Running IR pass [embedding_eltwise_layernorm_fuse_pass][0m
[32m--- Running IR pass [multihead_matmul_fuse_pass_v2][0m
I0713 16:49:08.685951 6532 fuse_pass_base.cc:59] --- detected 12 subgraphs
[32m--- Running IR pass [vit_attention_fuse_pass][0m
[32m--- Running IR pass [fused_multi_transformer_encoder_pass][0m
[32m--- Running IR pass [fused_multi_transformer_decoder_pass][0m
[32m--- Running IR pass [fused_multi_transformer_encoder_fuse_qkv_pass][0m
[32m--- Running IR pass [fused_multi_transformer_decoder_fuse_qkv_pass][0m
[32m--- Running IR pass [multi_devices_fused_multi_transformer_encoder_pass][0m
[32m--- Running IR pass [multi_devices_fused_multi_transformer_encoder_fuse_qkv_pass][0m
[32m--- Running IR pass [multi_devices_fused_multi_transformer_decoder_fuse_qkv_pass][0m
[32m--- Running IR pass [fuse_multi_transformer_layer_pass][0m
[32m--- Running IR pass [gpu_cpu_squeeze2_matmul_fuse_pass][0m
[32m--- Running IR pass [gpu_cpu_reshape2_matmul_fuse_pass][0m
[32m--- Running IR pass [gpu_cpu_flatten2_matmul_fuse_pass][0m
[32m--- Running IR pass [gpu_cpu_map_matmul_v2_to_mul_pass][0m
I0713 16:49:09.470413 6532 fuse_pass_base.cc:59] --- detected 38 subgraphs
[32m--- Running IR pass [gpu_cpu_map_matmul_v2_to_matmul_pass][0m
[32m--- Running IR pass [matmul_scale_fuse_pass][0m
[32m--- Running IR pass [multihead_matmul_fuse_pass_v3][0m
[32m--- Running IR pass [gpu_cpu_map_matmul_to_mul_pass][0m
[32m--- Running IR pass [fc_fuse_pass][0m
I0713 16:49:09.519965 6532 fuse_pass_base.cc:59] --- detected 38 subgraphs
[32m--- Running IR pass [fc_elementwise_layernorm_fuse_pass][0m
I0713 16:49:09.542423 6532 fuse_pass_base.cc:59] --- detected 24 subgraphs
[32m--- Running IR pass [conv_elementwise_add_act_fuse_pass][0m
[32m--- Running IR pass [conv_elementwise_add2_act_fuse_pass][0m
[32m--- Running IR pass [conv_elementwise_add_fuse_pass][0m
[32m--- Running IR pass [transpose_flatten_concat_fuse_pass][0m
[32m--- Running IR pass [conv2d_fusion_layout_transfer_pass][0m
[32m--- Running IR pass [transfer_layout_elim_pass][0m
[32m--- Running IR pass [auto_mixed_precision_pass][0m
[32m--- Running IR pass [inplace_op_var_pass][0m
I0713 16:49:09.547497 6532 fuse_pass_base.cc:59] --- detected 1 subgraphs
[1m[35m--- Running analysis [save_optimized_model_pass][0m
W0713 16:49:09.548242 6532 save_optimized_model_pass.cc:28] save_optim_cache_model is turned off, skip save_optimized_model_pass
[1m[35m--- Running analysis [ir_params_sync_among_devices_pass][0m
I0713 16:49:09.548257 6532 ir_params_sync_among_devices_pass.cc:51] Sync params from CPU to GPU
[1m[35m--- Running analysis [adjust_cudnn_workspace_size_pass][0m
[1m[35m--- Running analysis [inference_op_replace_pass][0m
[1m[35m--- Running analysis [ir_graph_to_program_pass][0m
I0713 16:49:09.937587 6532 analysis_predictor.cc:1660] ======= optimize end =======
I0713 16:49:09.937990 6532 naive_executor.cc:164] --- skip [feed], feed -> token_type_ids
I0713 16:49:09.938001 6532 naive_executor.cc:164] --- skip [feed], feed -> input_ids
I0713 16:49:09.938807 6532 naive_executor.cc:164] --- skip [elementwise_div_1], fetch -> fetch
[32m[2023-07-13 16:49:09,939] [ INFO][0m - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'rocketqa-zh-base-query-encoder'.[0m
[32m[2023-07-13 16:49:09,939] [ INFO][0m - Downloading https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_base_zh_vocab.txt and saved to /home/aistudio/.paddlenlp/models/rocketqa-zh-base-query-encoder[0m
[32m[2023-07-13 16:49:10,063] [ INFO][0m - Downloading ernie_3.0_base_zh_vocab.txt from https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_base_zh_vocab.txt[0m
100%|████████████████████████████████████████| 182k/182k [00:00<00:00, 3.51MB/s]
[32m[2023-07-13 16:49:10,249] [ INFO][0m - tokenizer config file saved in /home/aistudio/.paddlenlp/models/rocketqa-zh-base-query-encoder/tokenizer_config.json[0m
[32m[2023-07-13 16:49:10,249] [ INFO][0m - Special tokens file saved in /home/aistudio/.paddlenlp/models/rocketqa-zh-base-query-encoder/special_tokens_map.json[0m
0%| | 0/10000000 [00:00<?, ?it/s]W0713 16:49:20.130687 6532 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.6
W0713 16:49:20.137218 6532 gpu_resources.cc:149] device: 0, cuDNN Version: 8.4.
100%|███████████████████████████| 10000000/10000000 [1:27:15<00:00, 1910.02it/s]
执行过程部分展示:
8.0, Driver API Version: 11.2, Runtime API Version: 11.6
W0713 16:49:20.137218 6532 gpu_resources.cc:149] device: 0, cuDNN Version: 8.4.
100%|███████████████████████████| 10000000/10000000 [1:27:15<00:00, 1910.02it/s]
运行时长:5269.243秒结束时间:2023-07-13 18:16:52
其中 output 目录下存放的是召回的 Paddle Inference 静态图模型。参考项目,导出自己的静态图模型:语义检索系统:基于in-batch Negatives策略的有监督训练语义召回
| 数据量 | 显卡 | 时间 |
|---|---|---|
| 1000万条 | V100 32GB | 3h41min |
| 1000万条 | A100 40GB | 1h27min |
运行结束后会生成 corpus_embedding.npy
5.1.2 把向量插入到Milvus库
生成了向量后,需要把数据插入到 Milvus 库中,首先修改配置:
修改 config.py 的配置 ip 和端口,本项目使用的是8530端口,而 Milvus 默认的是19530,需要根据情况进行修改:
MILVUS_HOST='your milvus ip'
MILVUS_PORT = 8530
然后运行下面的命令把向量插入到Milvus库中:
这里会有比较多的坑下面总结一下:
issue总结
解决方案:
针对第一个问题:我在aistudio中运行,是不能访问外网还, 在本地就可以很好的运行
针对第二个问题:这里会遇到两个错误,总结一下就是:–batch_size不能设置太大;要小于64MB,不然通信数据传输会出错 2.词嵌入字符长度不能超过1000,暂时影响不大
- RPC error: [batch_insert], <MilvusException: (code=1, message=the length (1027) of 7940th string exceeds max length (1000))>, <Time:{‘RPC start’: '2023-07-21 17RPC error: [batch_insert], <MilvusException: (code=1, message=the length (1092) of 734th string exceeds max length (1000))>, <Time:{‘RPC start’: ‘2023-07-21 17:44:15.949226’, ‘RPC error’: ‘2023-07-21 17:44:16.494690’}>
- Milvus insert error: <MilvusException: (code=1, message=the length (1092) of 734th string exceeds max length (1000))>RPC error: [batch_insert], <MilvusException: (code=1, message=the length (1074) of 121th string exceeds max length (1000))>, <Time:{‘RPC start’: ‘2023-07-21 17:45:46.076491’, ‘RPC error’: ‘2023-07-21 17:45:46.115044’}>Milvus insert error: <MilvusException: (code=1, message=the length (1074) of 121th string exceeds max length (1000))>
针对第三个问题:Milvus只起到加速的效果,这个跟模型相关,并且关键字匹配不推荐使用语义检索,如果是句子级别的匹配,使用语义检索更合适;推荐进行双路召回【语义+关键字】
进入重点如何启动milvus向量库以及涉及到docker使用等,我把遇到问题总结成一份文档,遇到问题请参考下文:
其中:docker-compose.yml文件也放在项目根目录了。
# !python milvus_ann_search.py --data_path /home/aistudio/literature_search_data/milvus/milvus_data.csv \
# --embedding_path corpus_embedding.npy \
# --batch_size 1000 \
# --insert
参数含义说明
data_path: 数据的路径embedding_path: 数据对应向量的路径index: 选择检索向量的索引,用于向量检索insert: 是否插入向量search: 是否检索向量batch_size: 表示的是一次性插入的向量的数量
| 数据量 | 显卡 | 时间 |
|---|---|---|
| 1000万条 | V100 32GB | 23min |
| 1000万条 | A100 40GB | – |
- 插入过程进程:
Number of entities in Milvus: 9406000
Does collection literature_search exist in Milvus: True
Number of entities in Milvus: 9406000
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▌| 9975/10000 [23:27<00:02, 11.53it/s]Does collection literature_search exist in Milvus: True
Number of entities in Milvus: 9406000
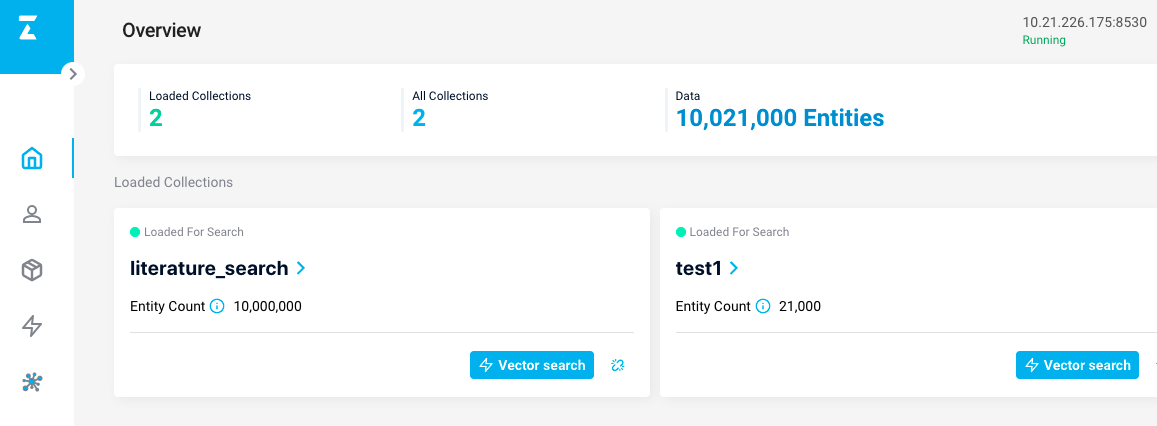
另外,Milvus提供了可视化的管理界面,可以很方便的查看数据,安装地址为Attu.
# #运行召回脚本:
# !python milvus_ann_search.py --data_path /home/aistudio/literature_search_data/milvus/milvus_data.csv \
# --embedding_path corpus_embedding.npy \
# --batch_size 1000 \
# --index 18 \
# --search
运行以后的结果的输出为:
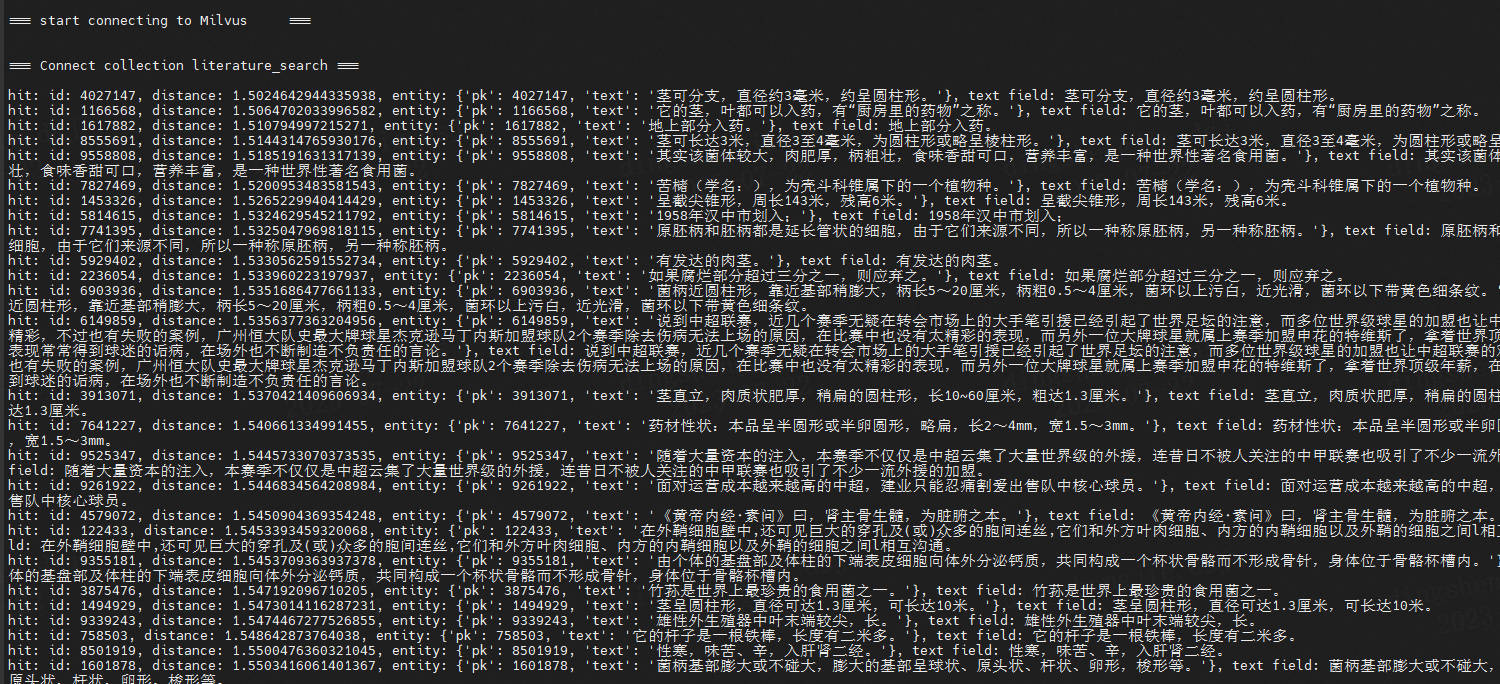
=== start connecting to Milvus ===
=== Connect collection literature_search ===
time cost 0.28903651237487793 s
hit: id: 18, distance: 0.0, entity: {'pk': 18, 'text': '吉林铁合金集团资产管理现状分析及对策资产管理;资金控制;应收帐款风险;造价控制;集中化财务控制'}, text field: 吉林铁合金集团资产管理现状分析及对策资产管理;资金控制;应收帐款风险;造价控制;集中化财务控制
hit: id: 3447131, distance: 0.4164842963218689, entity: {'pk': 3447131, 'text': '完善国有资产经营管理体制和有效监管形式,防止国有资产流失,实现保值增值。'}, text field: 完善国有资产经营管理体制和有效监管形式,防止国有资产流失,实现保值增值。
hit: id: 9189138, distance: 0.42778316140174866, entity: {'pk': 9189138, 'text': '加强国有企业资产管理的有效措施探析国有企业,资产管理,保值增值'}, text field: 加强国有企业资产管理的有效措施探析国有企业,资产管理,保值增值
hit: id: 9702226, distance: 0.43116235733032227, entity: {'pk': 9702226, 'text': '国有资产管理工作的理论基础与合理策略国资,国有资产保值增值,理论基础,国有资产管理'}, text field: 国有资产管理工作的理论基础与合理策略国资,国有资产保值增值,理论基础,国有资产管理
hit: id: 4845361, distance: 0.43486106395721436, entity: {'pk': 4845361, 'text': '加强国有资产管理、保障国有资产安全社会主义制度,资产安全,国有资产保值增值,国有资产管理体制改革,物质基础,社会职能,国有资产管理体系,财产权利,经济建设,资产管理制度'}, text field: 加强国有资产管理、保障国有资产安全社会主义制度,资产安全,国有资产保值增值,国有资产管理体制改革,物质基础,社会职能,国有资产管理体系,财产权利,经济建设,资产管理制度
hit: id: 8007081, distance: 0.4396001100540161, entity: {'pk': 8007081, 'text': '以核心企业主导的装配式建筑供应链金融风险研究与应用建筑企业;供应链金融;财务管理;风险识别'}, text field: 以核心企业主导的装配式建筑供应链金融风险研究与应用建筑企业;供应链金融;财务管理;风险识别
hit: id: 8771703, distance: 0.44080764055252075, entity: {'pk': 8771703, 'text': '拟定国有资产管理的有关政策和规章;'}, text field: 拟定国有资产管理的有关政策和规章;
hit: id: 1728735, distance: 0.4446617662906647, entity: {'pk': 1728735, 'text': '基于价值链会计的钢铁制造企业成本管理研究钢铁行业;成本管理体系;价值链会计;财务框架'}, text field: 基于价值链会计的钢铁制造企业成本管理研究钢铁行业;成本管理体系;价值链会计;财务框架
hit: id: 4639662, distance: 0.446344792842865, entity: {'pk': 4639662, 'text': '关于加强国有企业资产管理的思考国有企业,资产管理,国有资产'}, text field: 关于加强国有企业资产管理的思考国有企业,资产管理,国有资产
hit: id: 2088649, distance: 0.44682809710502625, entity: {'pk': 2088649, 'text': '加强国有资产监管,确保国有资产保值增值。'}, text field: 加强国有资产监管,确保国有资产保值增值。
hit: id: 9613810, distance: 0.44720369577407837, entity: {'pk': 9613810, 'text': '关于加强国有企业资产管理的思考国有企业,资产管理,思考'}, text field: 关于加强国有企业资产管理的思考国有企业,资产管理,思考
hit: id: 8809465, distance: 0.4491455852985382, entity: {'pk': 8809465, 'text': '负责市级直接管理企业的国有资产的基础管理工作,监交国有资产收益,并提出国有资产预算编制草案;'}, text field: 负责市级直接管理企业的国有资产的基础管理工作,监交国有资产收益,并提出国有资产预算编制草案;
hit: id: 393027, distance: 0.4522324204444885, entity: {'pk': 393027, 'text': '调查研究国有资产管理中的重大问题,提出国有资产调整方案以及加强国有资产管理的政策建议;'}, text field: 调查研究国有资产管理中的重大问题,提出国有资产调整方案以及加强国有资产管理的政策建议;
hit: id: 5888623, distance: 0.45243215560913086, entity: {'pk': 5888623, 'text': '我国国有资产管理现状分析与对策研究国有资产;管理;研究'}, text field: 我国国有资产管理现状分析与对策研究国有资产;管理;研究
hit: id: 6423627, distance: 0.4537673890590668, entity: {'pk': 6423627, 'text': '强化国有资产监督管理,确保国有资产收益最大化。'}, text field: 强化国有资产监督管理,确保国有资产收益最大化。
hit: id: 2038200, distance: 0.45380961894989014, entity: {'pk': 2038200, 'text': '浅谈企业如何提高资产管理水平企业,资产管理,提高水平,措施'}, text field: 浅谈企业如何提高资产管理水平企业,资产管理,提高水平,措施
...
返回的是向量的距离,向量的id,以及对应的文本。
也可以一键执行上述的过程:
sh scripts/search.sh
5.2 文本检索
首先修改代码的模型路径和样本:
params_path='checkpoints/model_40/model_state.pdparams'
id2corpus={0:'国有企业引入非国有资本对创新绩效的影响——基于制造业国有上市公司的经验证据'}
# !unzip /home/aistudio/data/data225060/checkpoints.zip
Archive: /home/aistudio/data/data225060/checkpoints.zip
inflating: checkpoints/inbatch/model_90/vocab.txt
inflating: checkpoints/inbatch/model_90/model_state.pdparams
inflating: checkpoints/inbatch/model_90/tokenizer_config.json
inflating: checkpoints/inbatch/model_90/special_tokens_map.json
inflating: checkpoints/inbatch/recall_log/default.talqnj.log
inflating: checkpoints/inbatch/recall_log/workerlog.0
inflating: checkpoints/inbatch/recall_log/default.gpu.log
inflating: checkpoints/simcse_inbatch_negative/model_300/special_tokens_map.json
inflating: checkpoints/simcse_inbatch_negative/model_300/vocab.txt
inflating: checkpoints/simcse_inbatch_negative/model_300/tokenizer_config.json
inflating: checkpoints/simcse_inbatch_negative/model_300/model_state.pdparams
#运行命令
# !python inference.py
# cd /home/aistudio/checkpoints
/home/aistudio/checkpoints
运行的输出为,分别是抽取的向量和召回的结果:
[1, 256]
Tensor(shape=[1, 256], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[ 0.07830613, -0.14036864, 0.03433795, -0.14967985, -0.03386058,
0.06630671, 0.01357946, 0.03531205, 0.02411086, 0.02000865,
0.05724005, -0.08119474, 0.06286906, 0.06509133, 0.07193415,
....
hit: (distance: 0.40141725540161133, id: 2742485), text field: 完善国有企业技术创新投入机制的探讨--基于经济责任审计实践国有企业,技术创新,投
入机制
hit: (distance: 0.40258315205574036, id: 1472893), text field: 企业技术创新与组织冗余--基于国有企业与非国有企业的情境研究
hit: (distance: 0.4121206998825073, id: 51831), text field: 企业创新影响对外直接投资决策—基于中国制造业上市公司的研究企业创新;对外直接投资;
制造业;上市公司
hit: (distance: 0.42234909534454346, id: 8682312), text field: 政治关联对企业创新绩效的影响——国有企业与民营企业的对比政治关联,创新绩效,国有
企业,民营企业,双重差分
hit: (distance: 0.46187296509742737, id: 9324797), text field: 财务杠杆、股权激励与企业创新——基于中国A股制造业经验数据制造业;上市公司;股权激
励;财务杠杆;企业创新
....
6.FAQ
6.1 抽取文本语义向量后,利用 Milvus 进行 ANN 检索查询到了完全相同的文本,但是计算出的距离为什么不是 0?
Milvus 是一个基于向量的相似度搜索引擎,它使用欧氏距离或内积来度量向量之间的相似性。尽管两个向量可能代表完全相同的文本内容,但由于计算过程中的浮点数舍入误差等原因,计算出的距离可能会接近于 0,但不会完全等于 0。因此,在实际应用中,当使用 Milvus 进行 ANN(Approximate Nearest Neighbor)近似最近邻搜索时,我们通常会设置一个阈值来判断两个向量是否相似。可以根据实际需求,选择一个适当的阈值来确定相似度的界限,并根据距离的大小进行筛选和排序。
使用的是近似索引,详情请参考Milvus官方文档,索引创建机制
7.更多Milvus信息
7.1 API 参考文档
Python SDK 项目源码: Pymilvus
pymilvus:使用手册
Java SDK 项目源码: milvus-sdk-java
java SDk: 使用手册
Go SDK 项目源码: milvus-sdk-go
Go SDK:使用手册
RESTful SDK 项目源码及使用手册: milvus-sdk-restful
C++ SDK 项目源码及使用手册: milvus-sdk-c++
7.2 Milvus 系统配置相关文档
7.3 Milvus 技术细节相关文档
7.4 milvus 常见问题
还有其他问题? 请参考以下文档
7.5 Milvus 相关工具
为来优化开发者的 Milvus 体验,我们推出来一下几款工具:
Milvus Enterprise Manager: Milvus 服务端图形化交互与管理工具
Milvus Sizing Tool: 硬件配置估算工具
MilvusDM:Milvus数据迁移工具
7.6 应用示例
为了使开发者更好的了解和使用 Milvus,我们创建了一系列完整的示例应用。
这些项目源码都已经上传在 Github 上,也给出了详细的快速搭建和代码详解文档。
- 图像视频检索
深度学习模型最开始就是用来对图像、视频等进行处理,通过训练可以精准的提取图片、视频中的特征从而对图片、视频进行分类,打标签,以图搜图,以图搜视频等等。Milvus凭借其出色的性能和数据管理能力,可以支持各种深度学习模型,实现对海量图片和视频的高性能分析检索能力。
- 智能问答机器人
传统的问答机器人大都是基于规则的知识图谱方式实现,这种方式需要对大量的语料进行分类整理。而基于深度学习模型的实现方式可以彻底摆脱对语料的预处理,只需提供问题和答案的对应关系,通过自然语言处理的语义分析模型对问题库提取语义特征向量存入Milvus中,然后对提问的问题也进行语义特征向量提取,通过对向量特征的匹配就可以实现自动回复,轻松实现智能客服等应用。
- 音频数据处理
利用深度学习模型对音频数据进行分析和处理能够大大提高语音识别的准确率,而其核心也是对相关音频切片进行向量化处理并且通过向量距离的计算来判断其表达的含义,因此,Milvus在语音、音乐等音频数据处理领域的也有丰富的应用。
- 化学分子式相似性分析
在传统的数据处理领域也存在大量向量计算的场景,使用传统的计算方式需要消耗大量的算力而Milvus凭借先进的算法可以在同等算力资源下将向量数据处理能力提高至少两个数量级。
- 推荐系统
该项目是 Milvus 结合 PaddleRec 实现的一个电影推荐系统中的召回服务,已经发布在 AI Studio 上,你可以进入该项目中快速体验。
PaddleRec与Milvus深度结合,手把手带你体验工业级推荐系统召回速度
7.7 在线项目体验
不会搭建?搭建太耗时?想要一秒体验上述项目。
不用担心,上述应用示例中给出的项目,我们都提供了在线服务供用户体验。
7.8 用户案例
-
由于大量视频内容高度重复,为提升视频内容推荐的体验,多媒体处理平台需要在视频审核时过滤内容过于相似的视频。本案例中,通过将一个视频抽取为多个关键帧的特征向量(这里将一个视频视为多张图片的集合)。在查询相似视频时,先计算图⽚相似度,再计算图⽚集间的相似度,最终得出视频间的相似度。对于图片间的相似度计算,可以将图片通过深度学习模型转化为特征向量,然后利用 Milvus 向量搜索引擎来计算图片特征向量的相似度。
-
近几年,网络购物平台日益流行,大众对网购的热情也日益高涨。但是大部分传统购物网站只支持关键词搜索,当用户无法用词汇准确描述商品时,就很难搜索到心仪的商品。因此,通过图片搜索相似产品,能够帮助用户更准确地找到想要的商品。为方便用户体验快捷的一站式购物,本案例的用户推出拍照购功能。如果消费者在影视屏幕、广告牌、报刊杂志、行人身上等任何地方看到自己喜欢的商品,他们只需拍照并上传,便可找到相似商品。
-
本项目主要用于构建移动安全 APP。工作流程为爬取 Google play 等平台上的外部 APK (Android application package,即 Android 应用程序包),运用特定算法检测出携带病毒的 APK,然后将表示该 APK 的向量存入 Milvus 中。然后使用 Milvus 在 APK 病毒库中对外部 APK 进行相似性检索。如发现外部某 APK 与库中携带病毒的 APK 相似,需要及时通知企业与个人用户相关的病毒信息。
-
在海量信息中,不乏非法分子利用网络骗取用户信任并从中获利,钓鱼网站就是其中之一。“钓鱼”网站的网址、网页内容、布局等与真实网站极其相似,没有安全意识的网民容易因此上当受骗,造成严重后果。现有的比较典型的检测钓鱼网站的方法有:基于黑白名单机制的检测,基于文本特征或网页图像特征的匹配检测,和基于机器学习的分类检测。然而,基于黑白名单的检测方法时效性较差,名单范围也存在着不足;基于特征的算法的准确性和鲁棒性又不是很理想。近年来,机器学习应用于各领域并取得巨大成功,尤其是将深度学习应用于检测识别可以有效得提高检测效率。因此我们结合深度学习与 Milvus 向量搜索引擎,以提高对钓鱼网站的正确检测率和检测速度。
-
本案例主要用于浏览器的推荐系统中,用以寻找用户可能感兴趣的新闻。首先通过提取用户历史浏览新闻的关键词,获得用户感兴趣的关键词。之后,基于这些关键词从海量文章中快速查找用户感兴趣的文章,根据点击率判断新闻热度,最终确定推荐给用户的新闻。这里我们将新闻语义向量存入 Milvus 中,然后将用户历史浏览新闻的关键词转化为语义向量,在库中查找语义相似的新闻。
-
在用户的音乐平台库中有海量的音乐,其首要任务是如何基于用户的历史行为,从海量音乐中筛选出用户感兴趣的音乐。在本案例中首先将歌曲转成梅尔频谱图,然后设计 CNN 网络来提取特征向量,作为歌曲的表征。最后通过查找相似向量来实现音乐推荐。
更多 Milvus 用户案例请参考 https://zilliz.blog.csdn.net/
更多内容请关注:公众号:汀丶人工智能

- 点赞
- 收藏
- 关注作者
评论(0)