这个Python项目让古诗变得更易读,看完《长安三万里》惊艳了!


大家好,这里是程序员晚枫,最近在小红薯更新生活VLOG,被骂惨了!
周末和小明去看了一场电影:《长安三万里》。
看电影的过程中发生了一件尴尬的事情:很多诗词里的字我都不认识。
回家以后,我赶紧打开电脑,开发了一个给古诗注音的开源项目:pohan。实现的效果如下。👇
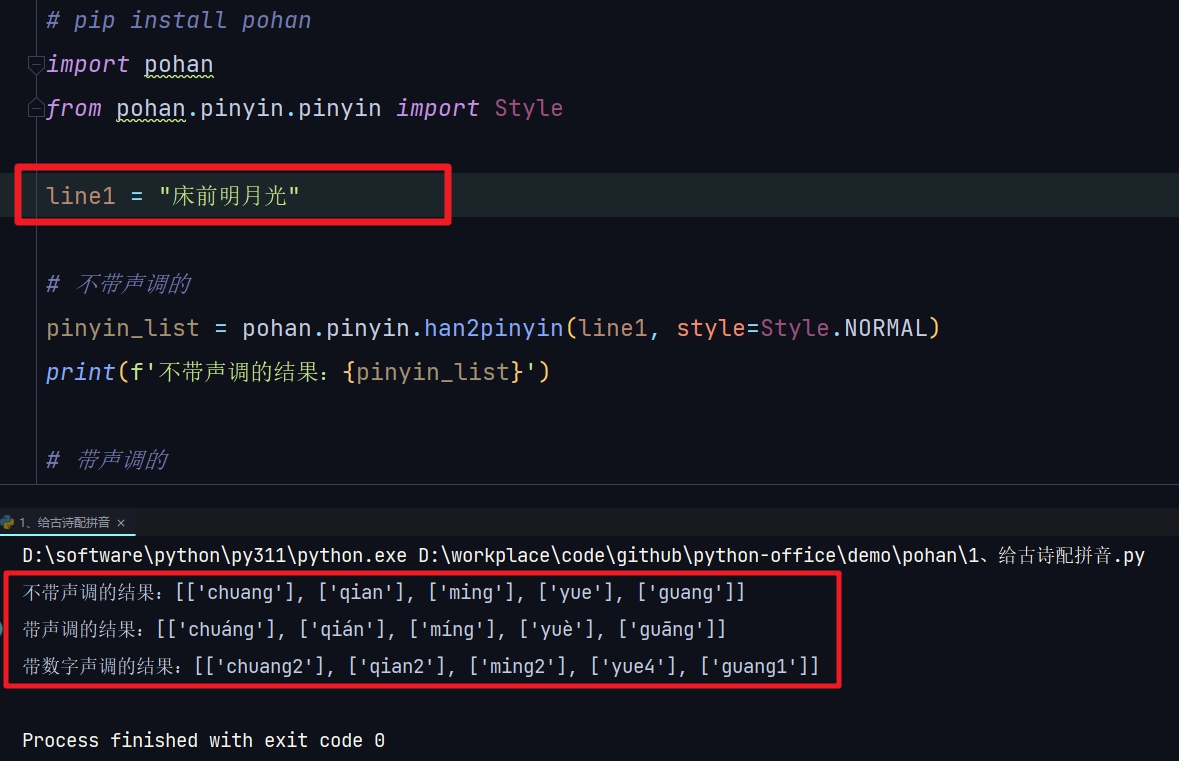
今天给大家分享一下,如何通过1行Python代码,给古诗标注拼音
1、先上代码
实现汉语转拼音效果的第三方库是:pohan,免费下载&安装命令如下:
pip install pohan
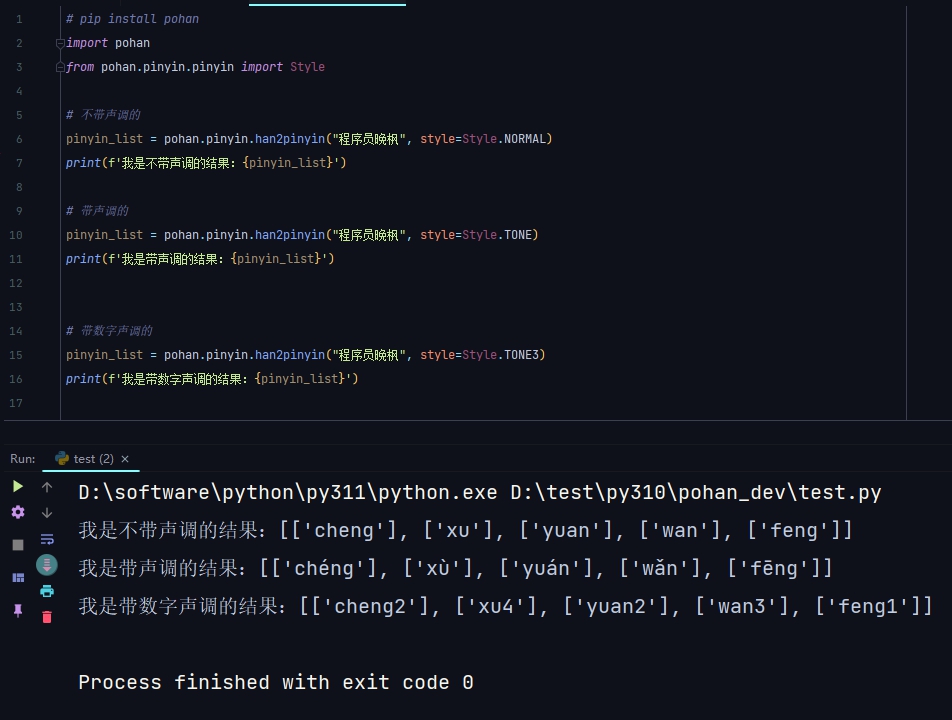
1行代码,实现汉语转拼音的效果。
# pip install pohan
import pohan
from pohan.pinyin.pinyin import Style
# 不带声调的
pinyin_list = pohan.pinyin.han2pinyin("程序员晚枫", style=Style.NORMAL)
print(f'我是不带声调的结果:{pinyin_list}')
# 带声调的
pinyin_list = pohan.pinyin.han2pinyin("程序员晚枫", style=Style.TONE)
print(f'我是带声调的结果:{pinyin_list}')
# 带数字声调的
pinyin_list = pohan.pinyin.han2pinyin("程序员晚枫", style=Style.TONE3)
print(f'我是带数字声调的结果:{pinyin_list}')
以上代码运行的结果,如下图所示:
2、参数说明
1行代码实现功能,可以填入的参数有以下几个(小白可以不填,都有默认值):
hans (unicode 字符串或字符串列表) – 汉字字符串( ‘程序员晚枫’ )或列表( [‘程序员’, ‘晚枫’] ). 可以使用自己喜爱的分词模块对字符串进行分词处理,
只需将经过分词处理的字符串列表传进来就可以了。style: 指定拼音风格,默认是 TONE 风格。 更多拼音风格详见 Style
errors: 指定如何处理没有拼音的字符。详见 处理不包含拼音的字符
default: 保留原始字符
ignore: 忽略该字符
replace: 替换为去掉 \u 的 unicode 编码字符串 (’\u90aa’ => ‘90aa’)
callable 对象: 回调函数之类的可调用对象。
heteronym: 是否启用多音字
strict: 只获取声母或只获取韵母相关拼音风格的返回结果 是否严格遵照《汉语拼音方案》来处理声母和韵母, 详见 strict 参数的影响
v_to_u (bool): 无声调相关拼音风格下的结果是否使用 ü 代替原来的 v 当为 False 时结果中将使用 v 表示 ü
neutral_tone_with_five (bool): 声调使用数字表示的相关拼音风格下的结果是否 使用 5 标识轻声
以上参数中,最常使用的是style,使用方法,见上面的代码。
觉得本文有帮助或者使用中有疑问,请在评论区告诉我吧~

- 点赞
- 收藏
- 关注作者
评论(0)