【Python】爬虫

一、Python爬虫介绍
1.1 什么是爬虫
网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或者脚本。
由于互联网数据的多样性和资源的有限性,
根据用户需求定向抓取网页并分析已成为如今主流的爬取策略。
1.2 爬虫可以做什么
爬虫可以爬取网络上的数据,例如公司企业人物之间的关系,(天眼查);
爬虫可以爬取网络上的视频,例如电影电视剧评分介绍,(电影天堂)。
获取到的数据经过数据采集,数据清洗,数据聚合,数据建模
数据产品化为一体的大数据解决方案。
以前我们使用网络产生了大量的数据,现在有人将数据整理起来供人们使用,
就形成了大数据产品,这也就是大数据火起来的原因。
1.3 爬虫的本质
模拟浏览器打开网页,获取网页中我们想要的那部分数据。
![]()
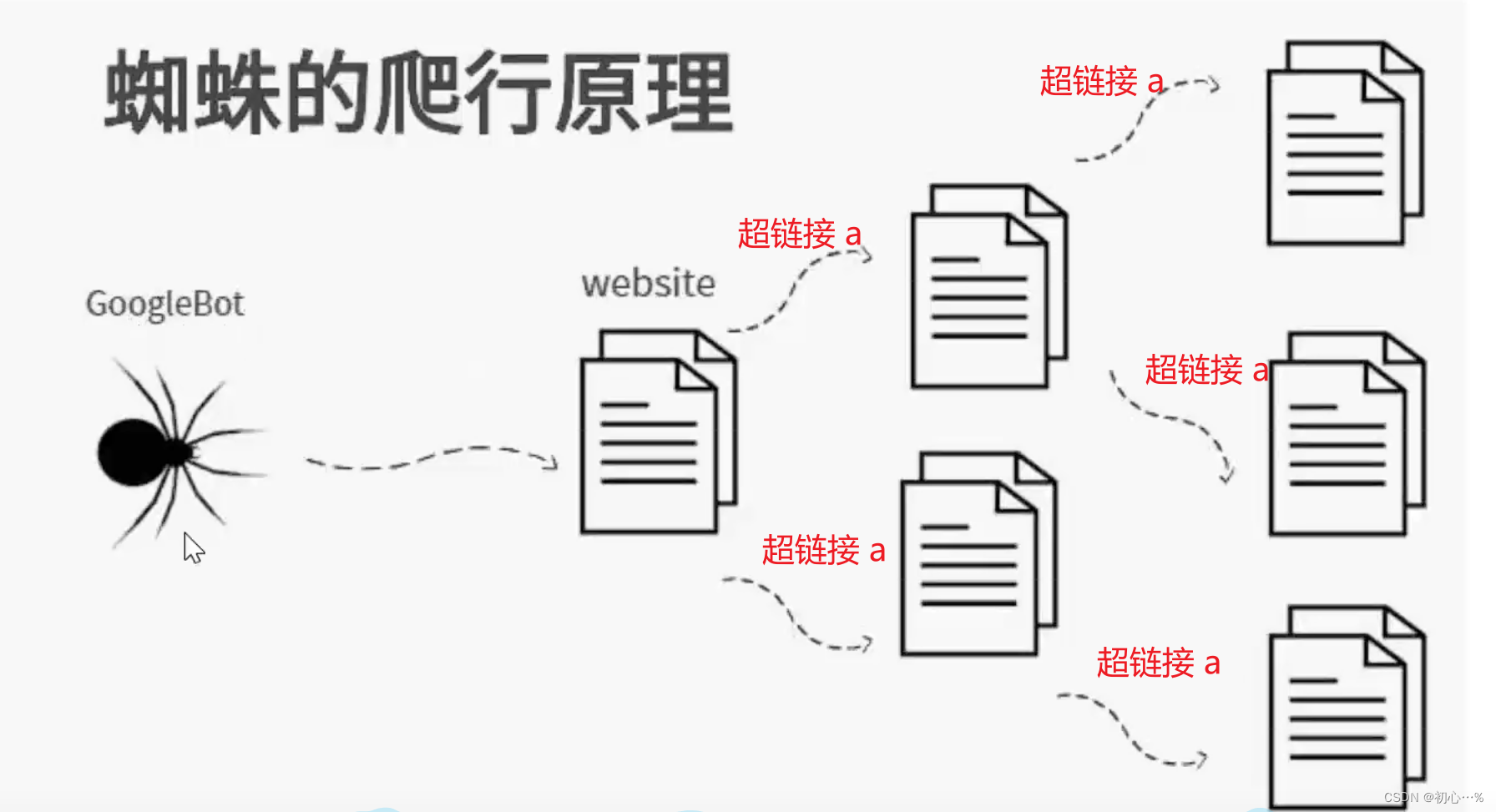
通过超链接 a标签,只要给定一个网页,
网页中含有超链接的话爬虫程序就可以不断的爬取数据。
![]()
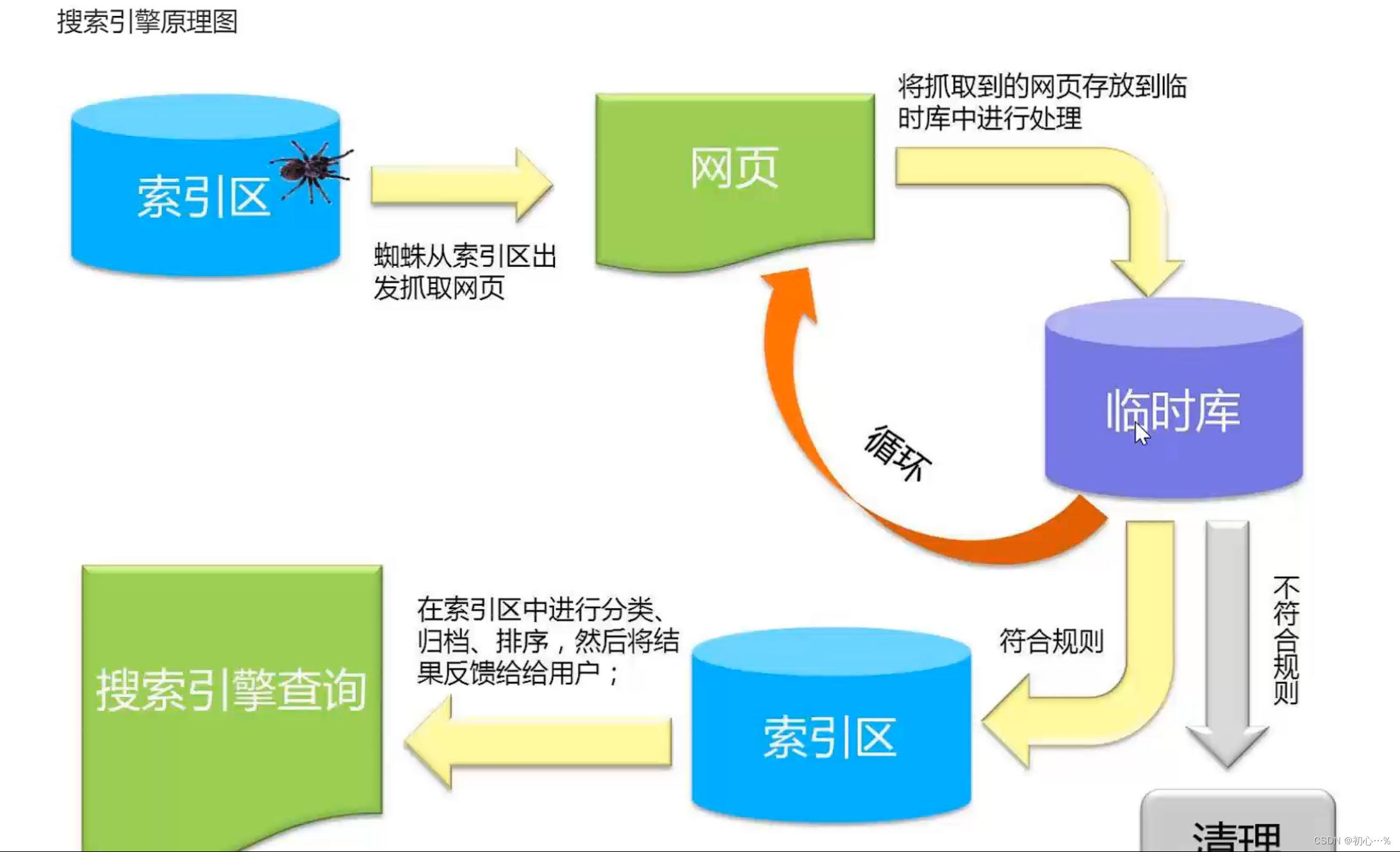
搜索引擎的原理图。
1.4 爬虫的基本流程
1.准备工作
通过浏览器查看并分析目标网页,学习编程基础规范.
2.获取数据
通过Http库向目标站点发起请求,请求可以包含额外的header等信息,
如果服务器能正常响应,
会得到一个Response,便是所要获取的页面内容。
3.解析内容
得到的内容可能是HTML、json格式,可以用页面解析库、正则表达式等解析。
4.保存数据
可以将数据保存为文本、保存到数据库、或者特定格式的文件。
二、爬虫准备工作
2.1 浏览器请求与响应
下面以请求某电影网的一个网页为例,
讲解浏览器请求服务器和服务器响应数据的过程。

![]()

![]()

![]()
2.2 main方法
Python中也有main()方法,main方法是函数执行的入口。
如果没有main方法,Python将自顶而下解释执行;
# 没有main方法
def say():
print("say ...")
def get():
print("get ...")
say()
get()

![]()
如果有main方法,将以main方法为入口开始执行;
def say():
print("say ...")
def get():
print("get ...")
# 有main方法
if __name__ == '__main__':
get()
![]()
如果同时含有main方法和调用方法,将自顶而下执行;
def say():
print("say ...")
def get():
print("get ...")
say()
# 同时含有main方法和调用方法
if __name__ == '__main__':
get()
![]()
因此,main方法的作用就是控制函数执行流程。
2.3 模块、包和库
模块是一种以.py为后缀的文件,在.py文件中定义了一些常量和函数,模块名称是文件名
模块的导入通过import来实现。
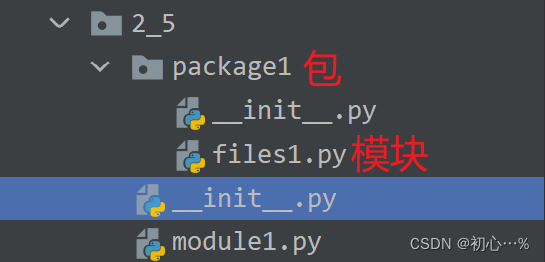
包体现了模块的结构化管理思想,包一般由__init__.py文件和其他模块文件构成,
将众多具有相关功能的模块结构化组合在一起形成包。
库没有具体的定义,着重强调功能性,具有某些功能的函数、模块和包都可以称为库。
![]()
# 引用模块
from package1 import files1
print(files1.add(2, 3))引入模块的方式:
1.通过命令行引入

![]()
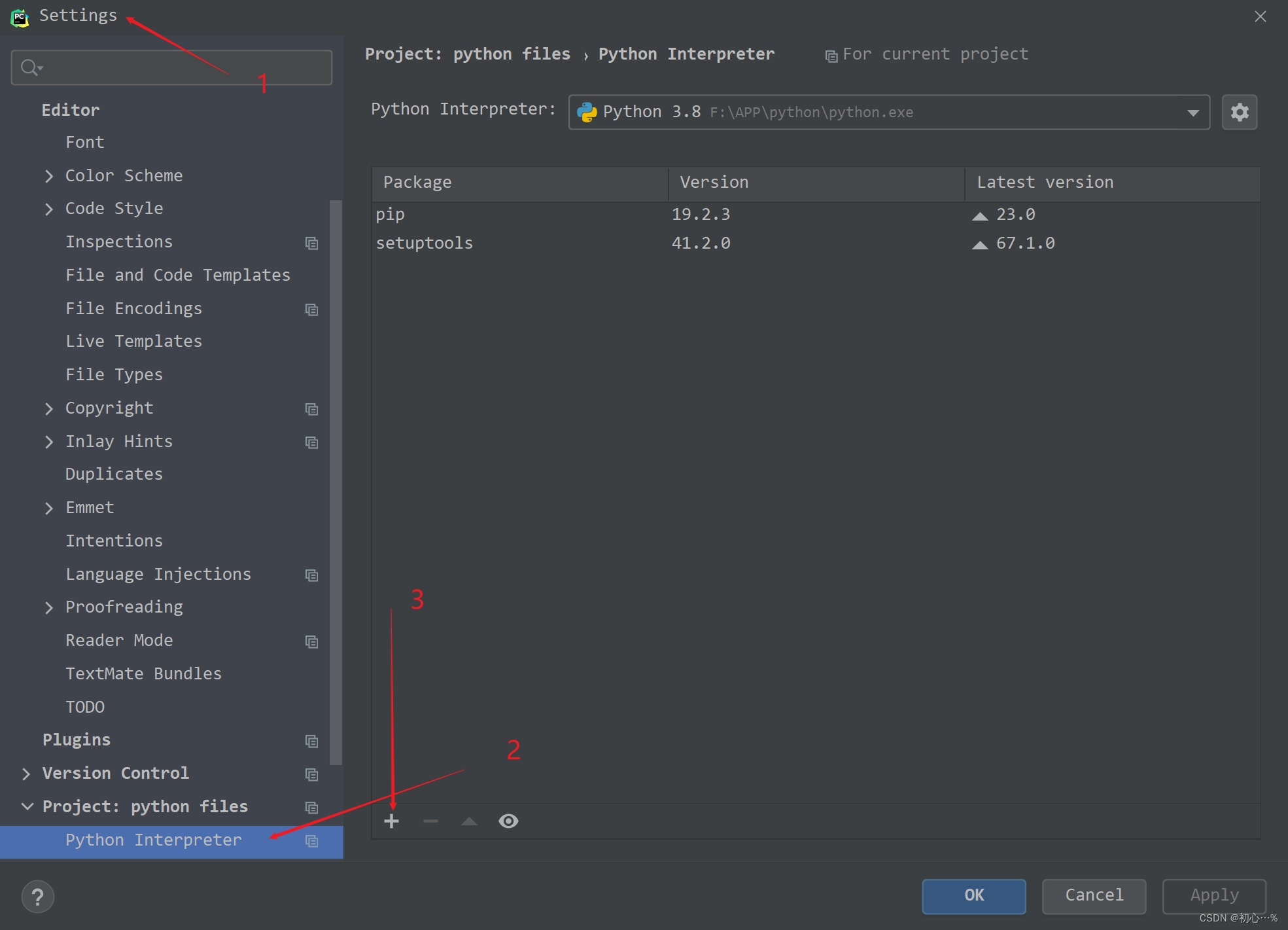
2.idea加载
![]()
import bs4 # 网页解析、获取数据
import re # 正则表达式、文字匹配(python内置)
import urllib.request,urllib.error #置顶url、获取网页数据(python内置)
import xlwt # 进行excel操作
import sqlite3 # 进行sqlite数据库操作(python内置)三、爬取网页
3.1 发送get请求
下面以某度为例:
response = urllib.request.urlopen("HTTP://www.baidu.com")
# www.baidu.com 报错-ValueError: unknown url type: 'www.baidu.com'-要加HTTP/HTTPS
# utf-8解码得到网页源代码
print(response.read().decode("utf-8"))得到的打印是整个html文档,即下面这个页面的源代码:
![]()
3.2 发送POST请求
1.以这个链接为例:(httpbin.org)
# 模拟表单数据并设置编码
form = bytes(urllib.parse.urlencode({"name":"xiao_guo",}),encoding="utf-8")
resp = urllib.request.urlopen("http://httpbin.org/post",form)
print(resp.read().decode("utf-8"))得到的响应如下
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "xiao_guo"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "13",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.8",
"X-Amzn-Trace-Id": "Root=1-63e0b6fa-1b4d392244fbc41d4f22f203"
},
"json": null,
"origin": "171.35.80.31",
"url": "http://httpbin.org/post"
}2.测试本地tomcat启动的Web服务
form = bytes(urllib.parse.urlencode({"name": "xiao_guo", }), encoding="utf-8")
resp = urllib.request.urlopen("http://localhost:8080/order/userPage", form)
print(resp.read().decode("utf-8"))
# 打印:{"code":0,"map":{},"msg":"NOTLOGIN"},因为请求中的浏览器没有相关登录信息3.3 超时处理
try:
response = urllib.request.urlopen("http://httpbin.org/get",timeout=0.01)
# 报错:urllib.error.URLError: <urlopen error timed out>
print(response.read().decode("utf-8"))
except urllib.error.URLError as e:
print("Time Out! %s"%e)3.4 模拟浏览器获取数据
1.模拟浏览器发送POST请求
# 缺少//,报错-urllib.error.URLError: <urlopen error no host given>
url = "http://httpbin.org/post"
# POST请求要求data是bytes,缺少bytes,报错-TypeError: POST data should be bytes, an iterable of bytes, or a file object. It cannot be of type str.
form_data = bytes(urllib.parse.urlencode({
"name": "XiaoGuo"
}),encoding="utf-8")
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Mobile Safari/537.36 Edg/109.0.1518.78"
}
# 封装请求对象req
req = urllib.request.Request(url, form_data, headers, method="POST")
# 传递req发送请求
resp = urllib.request.urlopen(req)
print(resp.read().decode("utf-8"))2.模拟浏览器发送GET请求
url = "https://www.douban.com"
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Mobile Safari/537.36 Edg/109.0.1518.78"
}
req = urllib.request.Request(url=url, headers=headers)
resp = urllib.request.urlopen(req)
print(resp.read().decode("utf-8"))四、总结
下面是根据这篇文章内容封装的函数,用于获取网页数据.
# 2.获取网页数据
def ask_url(url):
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Mobile Safari/537.36 Edg/109.0.1518.78"
}
# 创建请求对象
requset = urllib.request.Request(url=url, headers=headers)
# 结果对象html
html = ""
try:
# 发送请求
response = urllib.request.urlopen(requset)
# 获取并解析请求
html = response.read().decode("utf-8")
print(html)
except urllib.error.URLError as e:
# 如果包含这个错误状态码属性
if hasattr(e, "code"):
print("status code :%s" % str(e.code))
# 如果包含错误原因
if hasattr(e, "reason"):
print("error reason :%s" % str(e.reason))
# 返回网页数据
return html本期的分享就到这里啦,我们下期再见,拜拜!

- 点赞
- 收藏
- 关注作者
评论(0)