Python案例分析|文本相似度比较分析


01、文本相似度比较概述
通过计算并比较文档的摘要可实现文本的相似度比较。
文档摘要的最简单形式可以使用文档中的k-grams(k个连续字符)的相对频率的向量来表示。假设字符的取值可能有128种不同的值(ASCII码),则向量的维度d为128k,对于Unicode编码,这更是天文数字。因此,一般使用哈希函数hash(s) % d把k-grams字符串s映射到0到d-1之间的整数,从而使得文档摘要向量的维度为d。
创建文档摘要向量之后,可通过比较两个文档摘要向量的距离的方法来判断两个文档的相似度。
下面先阐述向量类(Vector)和文档摘要类(Sketch)的设计与实现,然后使用文档摘要类来比较文档的相似度。
02、向量(Vector)类设计和实现
向量是一种数学抽象,n维向量可以使用一个n个实数的有序列表(x0, x1, …, xn-1)。向量支持基本的四则算数运算,故可通过运算符重载来实现。
向量的基本运算包括:两个向量的加法、一个向量乘以一个标量(一个实数)、计算两个向量的点积、计算向量大小和方向。
(1)加法:x + y = ( x0 + y0, x1 + y1, . . ., xn-1 + yn-1 )
(2)减法:x - y = ( x0 - y0, x1 - y1, . . ., xn-1 - yn-1 )
(3)标量积:αx = (αx0, αx1, . . ., αxn-1)
(4)点积:x·y = x0y0 + x1y1 + . . . + xn-1yn-1
(5)大小:|x| = (x02 + x12 + . . . + xn-12)1/2
(6)方向:x / |x| = ( x0/|x|, x1/|x|, . . ., xn-1/|x|)
基本的向量(Vector)类设计思路如下。
(1)定义带一个列表参数(向量的坐标,可以是任意维度)的构造函数,用于初始化对应向量的实例对象属性_coords。
(2)重载方法getitem(),返回第i个元素,即第i维坐标。
(3)重载方法add()、sub()、abs(),实现向量的运算,即加法、减法、大小(模)。
(4)定义方法scale()、dot()、direction(),实现向量的运算,即标量积、点积、方向。
(5)重载方法len(),返回向量的维度。
(6)重载方法str(),返回向量的字符串表示。
基于上述设计思想,向量(Vector)的实现和测试代码如下所示。
【例1】向量类(Vector)的实现和测试(vector.py)。
import math
class Vector:
"""笛卡尔坐标系向量"""
def __init__(self, a):
"""构造函数:切片拷贝列表参数a到对象实例变量_coords"""
self._coords = a[:] # 坐标列表
self._n = len(a) # 维度
def __getitem__(self, i):
"""返回第i个元素,即第i维坐标"""
return self._coords[i]
def __add__(self, other):
"""返回2个向量之和"""
result = []
for i in range(self._n):
result.append(self._coords[i] + other._coords[i])
return Vector(result)
def __sub__(self, other):
"""返回2个向量之差"""
result = []
for i in range(self._n):
result.append(self._coords[i] - other._coords[i])
return Vector(result)
def scale(self, n):
"""返回向量与数值的乘积差"""
result = []
for i in range(self._n):
result.append(self._coords[i] * n)
return Vector(result)
def dot(self, other):
"""返回2向量的内积"""
result = 0
for i in range(self._n):
result += self._coords[i] * other._coords[i]
return result
def __abs__(self):
"""返回向量的模"""
return math.sqrt(self.dot(self))
def direction(self):
"""返回向量的单位向量"""
return self.scale(1.0 / abs(self))
def __str__(self):
"""返回向量的字符串表示"""
return str(self._coords)
def __len__(self):
"""返回向量的维度"""
return self._n
#测试代码
def main():
xCoords = [2.0, 2.0, 2.0]
yCoords = [5.0, 5.0, 0.0]
x = Vector(xCoords)
y = Vector(yCoords)
print('x = {}, y = {}'.format(x, y))
print('x + y = {}'.format(x + y))
print('10x = {}'.format(x.scale(10.0)))
print('|x| = {}'.format(abs(x)))
print(' = {}'.format(x.dot(y)))
print('|x-y| = {}'.format(abs(x-y)))
if __name__ == '__main__': main()
程序运行结果如下。
x = [2.0, 2.0, 2.0], y = [5.0, 5.0, 0.0]
x + y = [7.0, 7.0, 2.0]
10x = [20.0, 20.0, 20.0]
|x| = 3.4641016151377544
= 20.0
|x-y| = 4.69041575982343
03、文档摘要类(Sketch)的设计和实现
文档摘要类(Sketch)用于封装文档的摘要信息。设计思路如下。
(1)定义带3个列表参数(text(文本)、k(k-grams)、d(文档摘要向量的维度))的构造函数。使用列表解析创建一个包含d个元素的列表freq(初始值为0),用于存储k-grams的频率。循环抽取文本的所有k-grams,并使用hash函数映射到0-d之间的整数,从而更新对应的列表freq的元素值(递增)。然后使用freq创建Vector对象vector,并调用向量对象的direction()方法进行归一化。最后把文档摘要向量vector并保存到实例对象属性_sketch。
(2)定义方法similarTo(),计算两个文档摘要向量的余弦相似度。
比较两个向量的常用方法包括欧几里得距离和余弦相似性度。给定向量x和y,其欧几里得距离定义为:
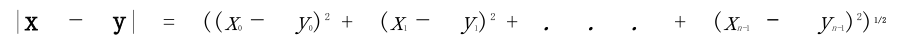
余弦相似性度定义为:
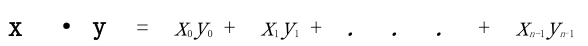
基于Vector对象,给定向量x和y,其欧几里得距离为abs(x – y),余弦相似性度的计算方法为x.dot(y)。
(3)重载方法str(),返回向量的字符串表示。
基于上述设计思想,向量(Sketch)的实现和测试代码如下所示。
【例2】文档摘要类(Sketch)的实现和测试(sketch.py)。
import sys
from vector import Vector
class Sketch:
"""计算文本text的k-grams的文档摘要向量(d维)"""
def __init__(self, text, k, d):
"""初始化函数:计算文本text的文档摘要向量"""
freq = [0 for i in range(d)] #创建长度为d的列表,初始值0
for i in range(len(text) - k): #循环抽取k-grams,计算频率
kgram = text[i:i+k]
freq[hash(kgram) % d] += 1
vector = Vector(freq) #创建文档摘要向量
self._sketch = vector.direction() #归一化并赋值给对象实例变量
def similarTo(self, other):
"""比较两个文档摘要对象Sketch的余弦相似度"""
return self._sketch.dot(other._sketch)
def __str__(self):
return str(self._sketch)
#测试代码
def main():
with open("tomsawyer.txt","r") as f:
text = f.read()
sketch = Sketch(text, 5, 100)
print(sketch)
if __name__ == '__main__': main()
程序的运行结果如下。
[0.09151094195152963, …, 0.08903767325013694]
说明 /
哈希函数基于一个数值“种子”计算,在Python 3中,哈希种子会改变(缺省情况下),即给定对象的哈希值可能每次运行结果都不一样。因而,程序输出结果可能不同。
04、通过比较文档摘要确定文档的相似度
使用前文设计和实现的类Sketch,可以比较文档的相似度。
【例3】使用Sketch类比较文档的相似度(document_compare.py)。
import sys
from vector import Vector
from sketch import Sketch
#测试文档列表
filenames = [ 'gene.txt', 'pride.txt', 'tomsawyer.txt']
k = 5 #k-grams
d = 100000 #文档摘要向量维度
sketches = [0 for i in filenames]
for i in range(len(filenames)):
with open(filenames[i], 'r') as f:
text = f.read()
sketches[i] = Sketch(text, k, d)
#输出结果标题
print(' '*15, end='')
for filename in filenames:
print('{:>22}'.format(filename), end='')
print()
#输出结果比较明细
for i in range(len(filenames)):
print('{:15}'.format(filenames[i]), end='')
for j in range(len(filenames)):
print('{:22}'.format(sketches[i].similarTo(sketches[j])), end='')
print()
程序运行结果如下:

结果表明,相同文档的相似度为1,相同类型的文档(pride.txt和tomsawyer.txt)相似度比较大,而不同类型的文档(gene.txt和pride.txt)的相似度则比较低。

华为开发者空间发布
让每位开发者拥有一台云主机
- 点赞
- 收藏
- 关注作者
评论(0)