二叉树

什么是二叉树以及什么时候可以使用它们?
二叉树是一种基本的树数据结构,由以分层方式连接的节点组成。二叉树中的每个节点最多可以有两个子节点:左子节点和右子节点。树中最顶层的节点称为根,而没有子节点的节点称为叶。
二叉树结构可以看作是一个分支结构,根在顶部,叶子在底部。每个节点可以有零个、一个或两个子节点,形成递归结构。这意味着每个子节点又可以有自己的左子节点和右子节点,从而创建层次结构。
二叉树在计算机科学的各个领域都有应用。一种常见的用途是数据存储和检索,其中二叉树可用于有效搜索和组织数据。例如,二叉搜索树利用二叉树结构和排序属性来实现快速搜索操作。
二叉树在表达式求值中也很有用,它们可以以分层方式表示数学表达式。通过使用适当的算法遍历二叉树,可以有效地评估表达式。
在网络路由中,可以采用二叉树来组织和导航网络节点。树结构通过根据二叉树的分支结构确定要遍历的下一个节点,可以进行有效的路由决策。
此外,二叉树是实现各种算法的基础,包括堆排序和二分搜索算法等排序算法。它们还可以扩展到更复杂的树结构,例如AVL树、红黑树和B树,以满足平衡、效率和空间优化方面的特定要求。
总之,二叉树是一种通用的数据结构,在计算机科学中有着广泛的应用,包括数据存储、表达式求值、网络路由和算法实现。它的层次性质和递归特性使其成为有效组织和操作数据的强大工具。
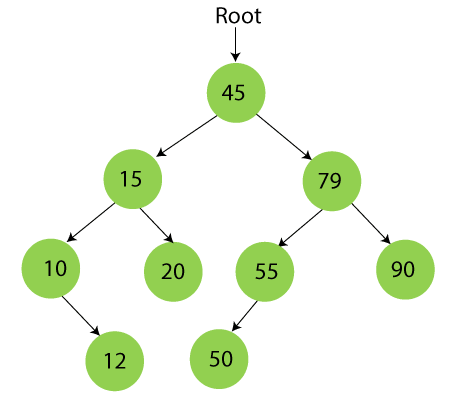
二叉树中的唯一键
二叉搜索树中的每个节点都有唯一的键值,这意味着树不能包含具有相同键的两个节点。这种唯一性允许精确的节点识别并有助于定位树中的特定值。
通常,我们规定的值成为节点的密钥。使用的密钥类型根据手头的任务而有所不同:
整数键:当使用整数作为键时,可以直接为每个节点分配一个整数值。这可以是来自数组、元素索引或任何其他唯一数字的值。
字符串键:如果键是字符串格式,您可以使用字符串本身或其哈希值作为键。利用散列字符串值可以加快比较和键查找操作,特别是在大型树中。
自定义类键:如果您使用面向对象的编程语言,则可以创建自定义类来定义其自己的键比较方法。这涉及实现比较方法或定义用于关键比较的接口。
以下是使用 TypeScript 的每个提到的树的简单示例。这些代码不包括所有可能的操作,例如删除、搜索等,但它们提供了对数据结构的基本理解。
二叉搜索树 (BST)
这里,key用于确定节点在树中的位置,value是节点中存储的数据。
class Node {
key: number;
value: number;
left: Node | null;
right: Node | null;
constructor(key: number, value: number) {
this.key = key;
this.value = value;
this.left = null;
this.right = null;
}
}
class BST {
root: Node | null;
constructor() {
this.root = null;
}
insert(key: number, value: number) {
let newNode = new Node(key, value);
if (this.root === null) {
this.root = newNode;
} else {
this.insertNode(this.root, newNode);
}
}
insertNode(node: Node, newNode: Node) {
if (newNode.key < node.key) {
if (node.left === null) {
node.left = newNode;
} else {
this.insertNode(node.left, newNode);
}
} else {
if (node.right === null) {
node.right = newNode;
} else {
this.insertNode(node.right, newNode);
}
}
}
}
红黑树(RBT)
就像BST中一样,key用于确定节点在树中的位置,value是节点中存储的数据。此外,每个节点都有一个颜色属性。
// Due to complexity, here's a simplified example without all operations.
enum Color {
RED,
BLACK
}
class Node {
key: number;
value: number;
color: Color;
left: Node | null;
right: Node | null;
constructor(key: number, value: number, color: Color) {
this.key = key;
this.value = value;
this.color = color;
this.left = null;
this.right = null;
}
}
class RBT {
root: Node | null;
constructor() {
this.root = null;
}
// Simple insertion function without tree balancing
insert(key: number, value: number) {
let newNode = new Node(key, value, Color.RED);
if (this.root === null) {
this.root = newNode;
} else {
// insert node as per BST rules, without implementing node recoloring
}
}
}
AVL树
这里同样,key 用于确定节点在树中的位置,value 是节点中存储的数据。此外,每个节点都有一个高度属性,在树平衡期间使用。
// Simplified example without balancing the tree and all necessary operations.
class Node {
key: number;
value: number;
height: number;
left: Node | null;
right: Node | null;
constructor(key: number, value: number) {
this.key = key;
this.value = value;
this.height = 1; // leaf height is always 1
this.left = null;
this.right = null;
}
}
class AVL {
root: Node | null;
constructor() {
this.root = null;
}
insert(key: number, value: number) {
let newNode = new Node(key, value);
if (this.root === null) {
this.root = newNode;
} else {
// Inserting node according to BST rules, without implementing balancing
}
}
}
请注意,这些示例是高度简化的。每棵树的完整实现都会更加复杂,并且包括许多其他操作和细节。
基于子节点数量的二叉树类型
以下是基于子节点数量的二叉树类型:
- 满二叉树;
- 退化二叉树;
- 倾斜二叉树;
满二叉树
满二叉树是一种二叉树,其中每个节点都有零个或两个子节点。换句话说,在满二叉树中,除了叶节点之外的所有节点都恰好有两个子节点。
满二叉树的结构是每个内部节点(非叶节点)恰好有两个子节点。此属性将完整二叉树与其他类型的二叉树区分开来,其中节点可能具有不同数量的子节点。
根据定义,满二叉树中的叶节点是没有任何子节点的节点。这些节点是树结构的端点。
满二叉树的概念常用于各种算法和数据结构中。它为某些应用程序提供了平衡且有效的表示。例如,堆数据结构(例如二叉堆)通常利用完全二叉树(完全二叉树的一种)来有效地维护堆属性。
总而言之,满二叉树是一种二叉树,其中除叶节点外的所有内部节点都恰好有两个子节点。这种树结构确保了某些算法和数据结构的平衡和高效表示。

退化(或病态)树
退化树或病态树是一种树,其中每个内部节点只有一个子节点。换句话说,除了叶节点之外,所有节点在左侧或右侧都有一个子节点。
退化树的结构比典型的树更类似于链表。这是因为从一个节点到下一个节点是线性进展的,每个节点只有一个子节点。
在性能方面,退化树的行为与链表类似。遍历或搜索退化树需要以线性方式访问每个节点,导致时间复杂度为 O(n),其中 n 是树中节点的数量。这是因为每个级别没有分支点或多个选择来有效缩小搜索空间。
由于缺乏分支和不平衡,退化树被认为对于许多基于树的算法和操作来说效率低下。它们不具备平衡树(例如二叉搜索树或 AVL 树)的优点,平衡树为搜索、插入和删除操作提供对数时间复杂度。
然而,值得注意的是,在某些情况下,退化树可能有特定的用例或应用程序。例如,它们可用于表示有序列表或序列,其中维护线性顺序比高效搜索或基于树的操作更重要。
总之,退化树或病态树是一种每个内部节点只有一个子节点的树。这些树表现出与链表相似的性能特征,导致与平衡树相比操作效率低下。虽然退化树可能有特定的用例,但它们通常对于大多数基于树的算法和操作来说并不是最佳的。
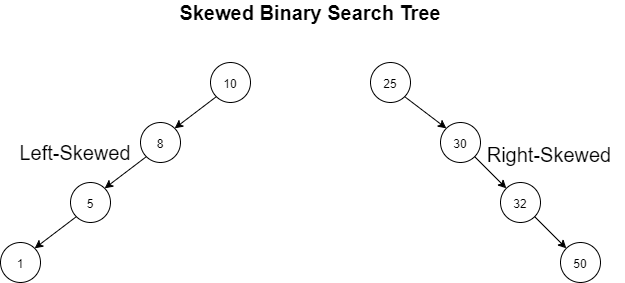
偏斜二叉树
偏斜二叉树是一种特殊类型的病态或退化树,其中该树严重偏向左子树或右子树。这种偏差意味着树的一侧占主导地位,而另一侧的节点很少或没有。
偏斜二叉树有两种变体:左偏二叉树和右偏二叉树。
左偏二叉树:在左偏二叉树中,除了叶节点之外,每个节点都只有一个左子节点。这意味着当我们从根到叶子遍历树时,我们只遇到左子节点。
右偏二叉树:在右偏二叉树中,除了叶节点之外,每个节点都只有一个右子节点。当我们从根到叶子遍历树时,我们只遇到右子节点。
倾斜二叉树表现出类似于链表或线性数据结构的性能特征。遍历或搜索倾斜二叉树需要以线性方式访问每个节点,导致时间复杂度为 O(n),其中 n 是树中节点的数量。
由于结构不平衡,倾斜二叉树通常不适合高效的搜索、插入或删除操作。它们缺乏更平衡的树结构(例如 AVL 树或红黑树)的分支和平衡特性。
然而,倾斜二叉树可能会找到特定的应用程序或用例。例如,它们可用于表示有序序列或列表,其中维护特定顺序比高效的基于树的操作更重要。
总之,偏斜二叉树是一种病态或退化树,其中树的一侧占主导地位,要么只有左子节点(左偏二叉树),要么只有右子节点(右偏二叉树)。倾斜二叉树通常表现出线性性能特征,并且对于大多数基于树的操作来说并不是最佳的。
基于级别完成的二叉树类型
以下是基于级别完成情况的二叉树类型:
- 完全二叉树;
- 完美二叉树;
- 平衡二叉树;
完全二叉树
完全二叉树是一种特定类型的二叉树,具有以下特征:
每个级别(可能除了最后一个级别)都完全充满了节点。这意味着所有级别都从左到右填充节点,中间没有任何缺失的节点。
所有叶节点(没有子节点的节点)都位于树的左侧。换句话说,首先填充每层最左边的叶节点,然后填充其右侧的节点。
树的最后一层可能未完全填满。如果最后一个级别中有任何缺失的节点,则它们必须放置在左侧,并且在该级别的右侧不留任何间隙。
需要注意的是,完整二叉树不一定是完整二叉树。在完全二叉树中,最后一层可能不会被完全填充,这与每个节点都有零个或两个子节点的完全二叉树不同。
完全二叉树的概念通常用于高效的基于数组的二叉树表示。通过使用数组并遵循特定的索引规则,可以紧凑地存储完整的二叉树,而不会浪费任何空间。
完全二叉树在各种算法和数据结构中都有实际应用。例如,它们用于堆数据结构(例如二叉堆),其中完整的二叉树属性允许高效的堆操作(例如插入和删除)。
总之,完全二叉树是一种二叉树,其中除了最后一层之外,每个级别都已完全填充,叶节点向左倾斜,并且最后一层可能未完全填充。这个概念为某些应用程序和基于数组的二叉树表示提供了平衡且有效的结构。

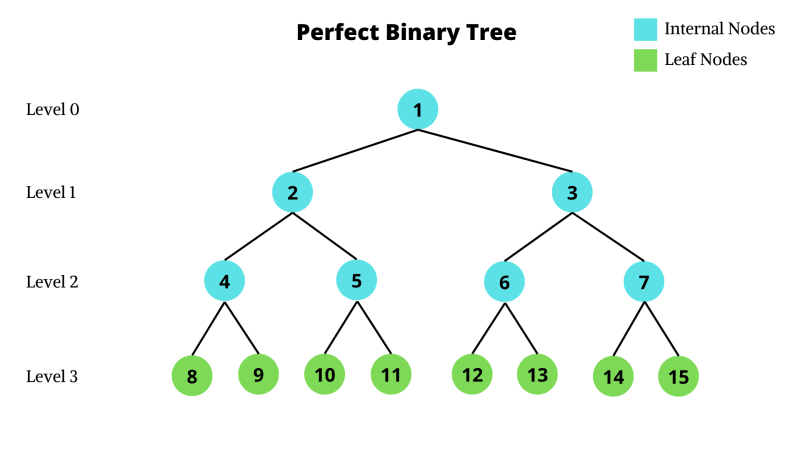
完美二叉树
完美二叉树是一种特定类型的二叉树,它满足两个主要条件:
树中的每个内部节点都有两个子节点。这意味着所有非叶节点都有两个子节点。
所有叶节点(没有子节点的节点)都位于相同的级别或深度。换句话说,从根到叶节点的每条路径都具有相同的长度。
在完美二叉树中,叶节点的数量等于内部节点的数量加一。这种关系成立,因为每个内部节点都有两个子节点,除了最后一层,其中所有叶节点都存在。
完美二叉树的一个实际例子是家谱中祖先的表示。以一个人为根开始,每一层代表上一代的父母,树向上生长。在这种结构中,每个人恰好有两个父母,并且所有叶节点(没有父母的个人)都处于同一代级别。
完美二叉树具有平衡且对称的结构。由于它们的规律性,它们允许高效的索引和搜索算法。此外,完美二叉树还用作其他二叉树变体的基础,例如完全二叉树和平衡二叉树。
总之,完美二叉树是一种二叉树,其中所有内部节点都有两个子节点,并且所有叶节点位于同一级别。这种结构确保了树的平衡和对称,并且在索引、搜索方面具有实际应用,并可作为其他二叉树变体的基础。
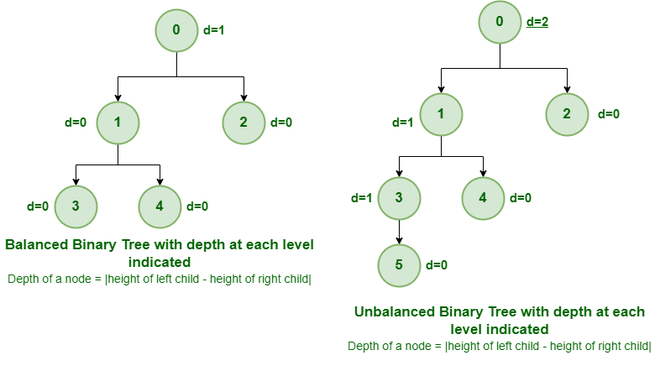
平衡二叉树
平衡二叉树是一种二叉树,其左右子树的高度保持在一定限制内,以确保树保持相对平衡。这种平衡是通过遵守特定的条件或属性来维持的,这些条件或属性根据平衡二叉树的类型而变化。
例如,AVL树是一种自平衡二叉搜索树,其左右子树之间的最大高度差保持为1。这种平衡是通过在插入和删除过程中必要时执行轮换和重新平衡操作来实现的。因此,AVL 树提供了高效的搜索、插入和删除操作,时间复杂度为 O(log n),其中 n 是节点数。
另一个例子是红黑树,它是另一种自平衡二叉搜索树。红黑树通过执行特定规则来确保平衡,例如要求每个根到叶路径上的黑色节点数量相同,并且没有相邻节点被涂成红色。通过保持这些属性,红黑树还保证了对数高度,从而能够对树进行高效操作。
平衡二叉搜索树(例如 AVL 树和红黑树)与不平衡二叉树相比具有显着的性能优势。这些树具有对数高度,可确保搜索、插入和删除操作的时间复杂度保持在 O(log n),从而非常适合大型数据集和频繁操作。
总之,平衡二叉树(例如 AVL 树和红黑树)通过强制执行特定条件或属性来保持对数高度。这种平衡允许高效的搜索、插入和删除操作,时间复杂度为 O(log n)。平衡二叉搜索树比不平衡树具有性能优势,使其适合需要高效数据存储和检索的各种应用程序。
其他特殊树种
根据节点的值,二叉树可以分为几种重要类型:
- 二叉搜索树;
- AVL 树;
- 红黑树;
- B树;
- B+树;
- 线段树;
在实践中,二叉搜索树、AVL树和红黑树由于其平衡性和高效运算而经常遇到并广泛使用。但B树、B+树、线段树在大规模数据存储、索引、范围查询等场景下有其特定的应用和优势。
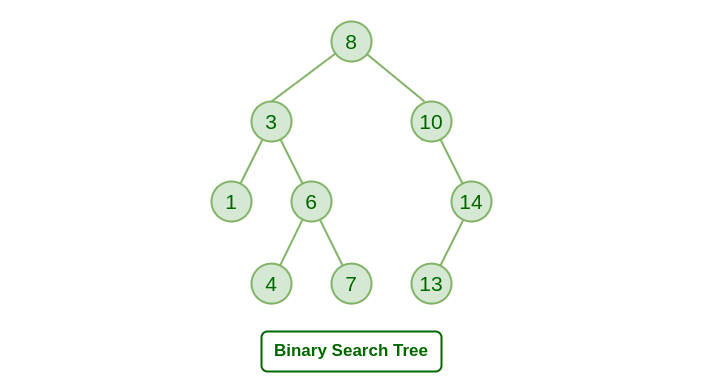
二叉搜索树
二叉搜索树 (BST) 是一种特定类型的二叉树,它遵循某些属性:
排序性质:在二叉搜索树中,对于每个节点,其左子树中的所有节点的值都小于其自身的值,而其右子树中的所有节点的值都大于其自身的值。此属性可以根据值的比较缩小搜索空间,从而实现高效搜索。
唯一键属性:二叉搜索树中的每个节点都有唯一的键值。这确保了树中没有两个节点具有相同的密钥,从而能够明确地识别节点。
二叉搜索树中存在的排序和唯一键属性允许高效的搜索、插入和删除操作。排序属性通过根据值的比较来指导搜索路径,从而减少每一步的搜索空间,从而加快查找速度。
值得注意的是,虽然二叉搜索树是二叉树的一种特定类型,但并非所有二叉树都是二叉搜索树。在二叉搜索树中,值按特定顺序组织,而二叉树可以在没有任何特定顺序或约束的情况下排列节点。
总之,二叉树是一种通用的树结构,其中节点最多可以有两个子节点,而二叉搜索树是一种特定类型的二叉树,它根据其节点的值维护有序结构。二叉搜索树的排序属性允许通过利用节点值的比较来进行高效的搜索、插入和删除操作。
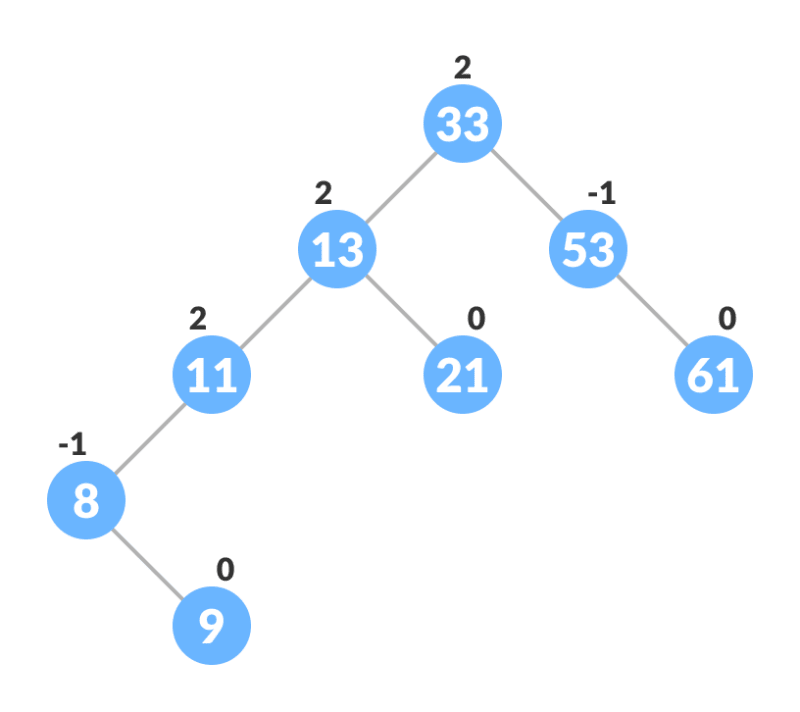
AVL树
AVL 树以其发明者 Adelson-Velsky 和 Landis 命名,是一种自平衡二叉搜索树 (BST)。它的目的是通过确保每个节点的左右子树的高度差不超过1来保持树内的平衡。
换句话说,在AVL树中,每个节点的左右子树的高度保持平衡,最大差值为1。如果在插入或删除操作后违反平衡条件,树将进行旋转以恢复平衡。
AVL 树的自平衡特性有助于防止退化并确保树保持相对平衡。通过保持平衡,AVL 树提供高效的搜索、插入和删除操作,时间复杂度为 O(log n),其中 n 是树中的节点数。
AVL树的概念广泛应用于需要高效搜索和动态更新的各种应用中,例如数据库系统、编译器实现和数据结构库。
综上所述,AVL树是一种自平衡二叉搜索树,其中每个节点的左右子树的高度差限制为最大值1。这种平衡特性确保了高效的操作,并防止树变得高度不平衡或退化。
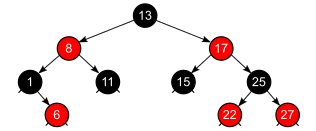
红黑树
红黑树是一种自平衡二叉搜索树,其中每个节点都包含一个表示其颜色(通常为红色或黑色)的附加位。这种着色方案用于在插入和删除过程中保持平衡。
红黑树的设计目的是确保树保持相对平衡,尽管不是完全平衡。通过维护与节点颜色相关的特定属性和规则,红黑树可以实现高效搜索并使树的高度接近对数,大约为 O(log n),其中 n 是树中元素的总数。
红黑树的平衡规则包括:
- 红黑属性:每个节点要么是红色,要么是黑色。
- 根属性:根节点始终为黑色。
- 红色属性:每个红色节点必须有两个黑色子节点。
- 深度属性:对于每个节点,从该节点到其后代叶子的每条路径都包含相同数量的黑色节点。通过遵守这些规则,红黑树保持平衡,并确保从根到任何叶子的最长路径不超过最短路径长度的两倍。与不平衡二叉搜索树相比,这种平衡属性提供了高效的搜索、插入和删除操作。
红黑树在各个领域都有应用,包括数据存储、索引和数据库系统。它们广泛用于实现平衡且高效的数据结构,以及需要高效搜索和动态更新的算法。
总之,红黑树是一种自平衡二叉搜索树,其中每个节点都包含一个颜色位(红色或黑色),以在插入和删除过程中保持平衡。尽管平衡并不完美,但红黑树通过遵守与节点颜色相关的特定属性和规则来实现对数搜索时间。这使得红黑树适合需要高效数据存储和检索的应用程序。
B-树
B 树是一种自平衡树数据结构,旨在高效访问、插入和删除数据项。由于其能够有效处理大量数据,因此广泛应用于数据库和文件系统。B 树的特点是固定的最大度或阶数,它决定了父节点可以拥有的子节点的最大数量。
在 B 树中,每个节点可以有多个子节点和多个键。键用作定位和组织数据项的索引。B 树的结构可以利用键在树中导航并定位所需的数据项,从而实现高效的搜索操作。
B 树的主要优点之一是它能够保持平衡,确保树的高度保持相对较小并提供高效的操作。通过遵守平衡规则,例如在每个节点中维护最小数量的键以及在插入和删除期间重新分配键,B树实现了对数据的平衡和高效访问。
B 树的平衡结构可实现快速搜索操作,时间复杂度约为 O(log n),其中 n 表示存储在树中的数据项的数量。这种对数时间复杂度使得B树适合涉及大规模数据存储和检索的场景。
总之,B树是一种自平衡树数据结构,允许高效的访问、插入和删除操作。由于它能够处理大量数据并保持平衡,因此通常用于数据库和文件系统。B 树提供高效的搜索操作,时间复杂度约为 O(log n),非常适合涉及大量数据存储和检索需求的应用程序。

B+ - 树
B+ 树是 B 树的特殊变体,专门针对文件系统和数据库的使用进行了优化。虽然在固定最大度和高效访问、插入和删除操作方面与 B 树类似,但 B+ 树有一些关键区别。
在B+树中,所有数据项都存储在树的叶节点中。这种设计选择确保 B+ 树的内部节点仅包含用于索引和定位数据项的键。通过将数据项与内部节点分离,B+树实现了多个优点。
一项主要优点是提高了搜索性能。由于叶子节点专门存储数据项,因此在 B+ 树内搜索只需遍历叶子节点,与传统 B 树相比,搜索速度更快。此外,B+ 树的叶节点通常在链表中链接在一起,从而允许高效的顺序访问和范围查询。
仅将数据项存储在叶节点中的另一个好处是简化范围查询和数据范围扫描。通过叶节点形成链表,按特定顺序扫描数据项变得更加高效,使得 B+ 树非常适合需要高效基于范围的操作的应用程序。
通过结合高效搜索、顺序访问和简化范围查询的优点,B+ 树已成为文件系统和数据库的流行选择。它们提供了高效且平衡的数据结构,用于组织和管理大量数据,确保快速访问和优化性能。
总之,B+ 树是 B 树的一种专门变体,针对文件系统和数据库进行了优化。它将数据项专门存储在叶节点中,同时使用内部节点进行索引。B+树的设计可实现高效的搜索操作、快速的顺序访问和简化的范围查询,使其非常适合涉及文件系统和数据库的应用程序。

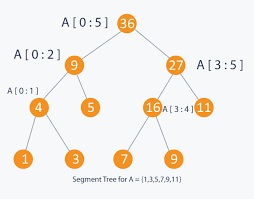
线段树
在计算机科学中,线段树,也称为统计树,是一种基于树的数据结构,用于存储和检索有关间隔或线段的信息。其主要目的是有效地回答有关哪些存储的段包含给定点的查询。
线段树被认为是静态结构,这意味着它通常构建一次,之后无法修改。它旨在处理提前已知间隔并且需要基于间隔的高效查询的场景。
与线段树类似的数据结构是区间树,它也处理基于区间的操作。虽然线段树侧重于与间隔内的点包含相关的查询,但间隔树提供了附加功能,例如查找重叠间隔或执行范围查询。
通过采用分层树结构,线段树允许按间隔进行有效操作。它将空间细分为更小的段,并将有关这些段的信息存储在树节点中。这些信息可以预先计算和聚合,以便根据具体需求进行快速查询。
线段树在计算几何、数据库和算法设计等各个领域都有应用。它们通常用于解决涉及基于区间的查询的问题,例如范围总和查询、范围最小/最大查询以及识别包含特定点的区间。
总之,线段树是一种基于树的数据结构,用于高效存储和查询基于区间的信息。它提供了一个静态框架来处理与间隔相关的操作,特别是确定哪些存储的段包含给定点。线段树广泛应用于计算几何、数据库和其他需要基于区间的高效查询和分析的领域。
编程面试中关于二叉树的小任务
在最近的一次编码面试中,我遇到了一个有趣的任务,涉及在二叉树中搜索。
在面试过程中,我面临的挑战是实现搜索算法以在二叉树中查找特定值。该任务要求我遍历树并确定是否存在所需的值。
Write a function which takes a binary tree and a number as an input.
It should find in the tree and output minimum number that is greater than given.
Example of tree:
10
/ \
5 15
/ | / \
2 7 12 17
n = 16
expected output is 17
我不仅需要设计解决方案,还需要编写实际的工作代码并进行测试。为了有效地解决这个任务,我首先考虑二叉树结构的模型。
由于二叉树中的每个节点都包含一个值以及对其左子节点和右子节点的引用,因此我决定创建一个基类来表示该树。此类充当在二叉树中创建节点实例的蓝图。
通过使用类对树结构进行建模,我可以轻松创建和操作节点、设置它们的值并在父节点和子节点之间建立适当的连接。这使我能够在解决方案中有效地构建和遍历树。
为了确保我的代码的正确性,我实现了一系列测试用例。我精心设计了涵盖问题各个方面的测试场景,包括搜索现有值、搜索不存在的值以及处理空树等边缘情况。
class Node {
constructor(value) {
this.value = value;
this.left = null;
this.right = null;
}
}
伟大的!使用基类对二叉树进行建模后,该过程的下一步是根据给定任务的要求模拟该树。
const root = new Node(10);
root.left = new Node(5);
root.right = new Node(15);
root.left.left = new Node(2);
root.left.right = new Node(7);
root.right.left = new Node(12);
root.right.right = new Node(17);
为了解决树的遍历问题,我最初考虑了两种常见的方法:递归和使用循环。为了清楚起见,我决定从基于循环的方法开始。
在这种方法中,第一步是创建传递给函数的原始树的副本。这个副本保证了我们在遍历过程中没有修改原始树。此外,我设置了我们想要在树中找到的初始最小值。
let currentTree = tree;
let minValue = number;
现在,让我们继续构建基于循环的遍历算法。循环的主要条件是存在要遍历的树。在循环中,我们将根据当前节点的值和所需的最小值来处理两种情况。
如果当前节点的值大于所需的最小值,我们将把最小值更新为当前节点的值,并移动到树的左分支。这是因为我们知道左子树中的数字将小于父节点。
另一方面,如果当前节点的值小于所需的最小值,我们将移动到树的右分支。这样,我们将在搜索最小值时探索更大的数字。
通过遵循这种简单直观的算法,我们可以有效地遍历树并识别其中的最小值。
while ( currentTree ) {
if (currentTree.value > number )
{
minValue = currentTree.value;
currentTree = currentTree.left;
} else {
currentTree = currentTree.right;
}
}
现在,让我们根据定义的条件确定函数的返回值。如果遍历过程中找到的最小值不等于所需的数字,我们将返回这个最小值。但是,如果最小值等于所需的数字,我们将返回null。
return minValue !== number ? minValue : null;
任务已成功解决,代码运行正常!
~ node test.js
n = 16, expected output = 17
result: 17
n = 1, expected output = 2
result: 2
n = 17, expected output = null
result: null
Kotlin 中的解决方案
class Node {
var value: Int? = null
var left: Node? = null
var right: Node? = null
companion object {
fun add(node: Node?, value: Int): Node {
if (node == null)
return this.createNode(value)
if (node.value != null && value < node.value!!)
node.left = add(node.left, value);
else if (node.value != null && value > node.value!!)
node.right = add(node.right, value);
return node
}
fun createNode(item: Int): Node {
val temp = Node()
temp.value = item
temp.right = null
temp.left = null
return temp
}
fun findMinForN(node: Node?, target: Int): Int {
if (node?.left == null && node?.right == null && node?.value == null) {
return -1;
}
if ((node.value!! >= target && node.left == null) ||
((node.value!! >= target && node.left?.value!! < target))
) {
return if (node.value == target) -1 else node.value!!
}
return if (node.value != null && node.value!! <= target)
findMinForN(node.right, target)
else
findMinForN(node.left, target)
}
}
override fun toString(): String {
return "Node(value=$value, left=$left, right=$right)"
}
}
fun main() {
var root: Node? = null
root = Node.add(root, 10)
root = Node.add(root, 5)
root = Node.add(root, 15)
root = Node.add(root, 2)
root = Node.add(root, 7)
root = Node.add(root, 12)
root = Node.add(root, 17)
println(Node.findMinForN(root, 16))
}更多精彩内容欢迎B站搜索“千锋教育”

- 点赞
- 收藏
- 关注作者
评论(0)