2023-07-03:讲一讲Redis缓存的数据一致性问题和处理方案。

2023-07-03:讲一讲Redis缓存的数据一致性问题和处理方案。
答案2023-07-03:
数据一致性
当使用缓存时,无论是在本地内存中缓存还是使用 Redis 等外部缓存系统,会引入数据同步的问题。下面以 Tomcat 向 MySQL 中进行数据的插入、更新和删除操作为例,来说明具体的过程。
分析下面几种解决方案的数据同步方案:
1.先更新缓存,再更新数据库:先更新缓存可以提高读取性能,但如果更新缓存成功而更新数据库失败,可能导致数据不一致。
2.先更新数据库,再更新缓存:确保数据的持久性,但如果更新数据库成功而更新缓存失败,也可能导致数据不一致。
3.先删除缓存,后更新数据库:通过先删除缓存,再更新数据库的方式,可以在数据更新后保证数据的一致性,但会降低读取操作的性能。
4.先更新数据库,后删除缓存:确保数据的持久性,并在更新数据库成功后再删除缓存,以保持数据的一致性。
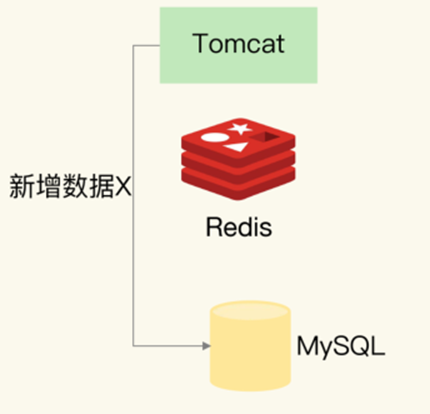
新增数据类
对于新增数据的情况,数据会直接写入数据库,无需对缓存进行操作。在这种情况下,缓存中本身就没有新增数据,而数据库中保存的是最新值。因此,缓存和数据库的数据是一致的。
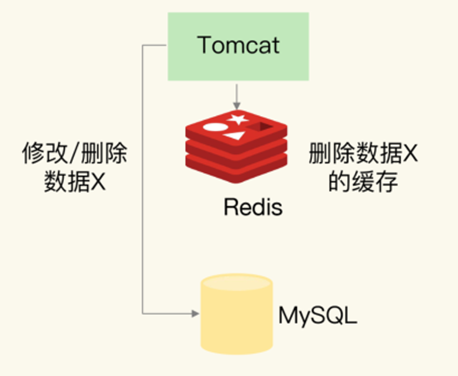
更新缓存类
1、先更新缓存,再更新DB
我们通常不考虑这个方案,因为存在以下问题:即使在更新缓存成功后,若出现更新数据库时的异常,会导致缓存中的数据与数据库数据完全不一致。由于缓存数据一直存在,这种不一致性很难察觉到。
2、先更新DB,再更新缓存
我们一般不考虑先更新数据库再更新缓存的方案,与第一个方案存在相同的问题。数据库更新成功但缓存更新失败时,仍然会导致数据不一致的问题。此外,这种方案还存在以下问题:
并发问题:当有请求A和请求B同时进行更新操作时,可能出现以下情况:线程A先更新数据库,然后线程B也更新了数据库,随后线程B更新了缓存,最后线程A也更新了缓存。这导致了请求A应该先更新缓存,但由于网络等原因,请求B却比请求A更早更新了缓存,从而产生脏数据。
业务场景问题:如果写数据库的操作比读数据的操作更频繁,采用这种方案会导致数据还没有被读取,就频繁更新缓存,从而浪费性能。
除了更新缓存,我们还可以考虑删除缓存的方案。具体选择更新缓存还是淘汰缓存取决于“更新缓存的复杂度”。如果更新缓存的成本较低,我们更倾向于更新缓存以提高缓存命中率;而如果更新缓存的代价较高,我们则更倾向于淘汰缓存。
删除缓存类
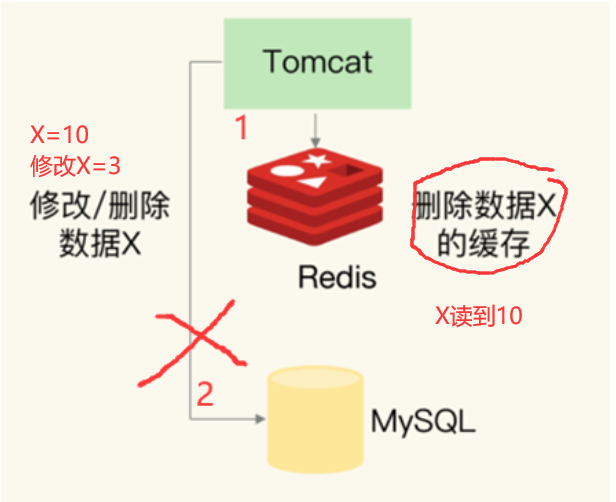
3、先删除缓存,后更新DB
该方案也会出问题,具体出现的原因如下。
1、此时来了两个请求,请求 A(更新操作) 和请求 B(查询操作)
2、请求 A 会先删除 Redis 中的数据,然后去数据库进行更新操作;
3、此时请求 B 看到 Redis 中的数据时空的,会去数据库中查询该值,补录到 Redis 中;
4、但是此时请求 A 并没有更新成功,或者事务还未提交,请求B去数据库查询得到旧值;
5、那么这时候就会产生数据库和 Redis 数据不一致的问题。
如何解决呢?其实最简单的解决办法就是延时双删的策略。就是
(1)先淘汰缓存
(2)再写数据库
(3)休眠1秒,再次淘汰缓存
这段伪代码就是“延迟双删”
redis.delKey(X)
db.update(X)
Thread.sleep(N)
redis.delKey(X)
这么做,可以将1秒内所造成的缓存脏数据,再次删除。
那么,这个1秒怎么确定的,具体该休眠多久呢?
针对上面的情形,读该自行评估自己的项目的读数据业务逻辑的耗时。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上,加几百ms即可。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
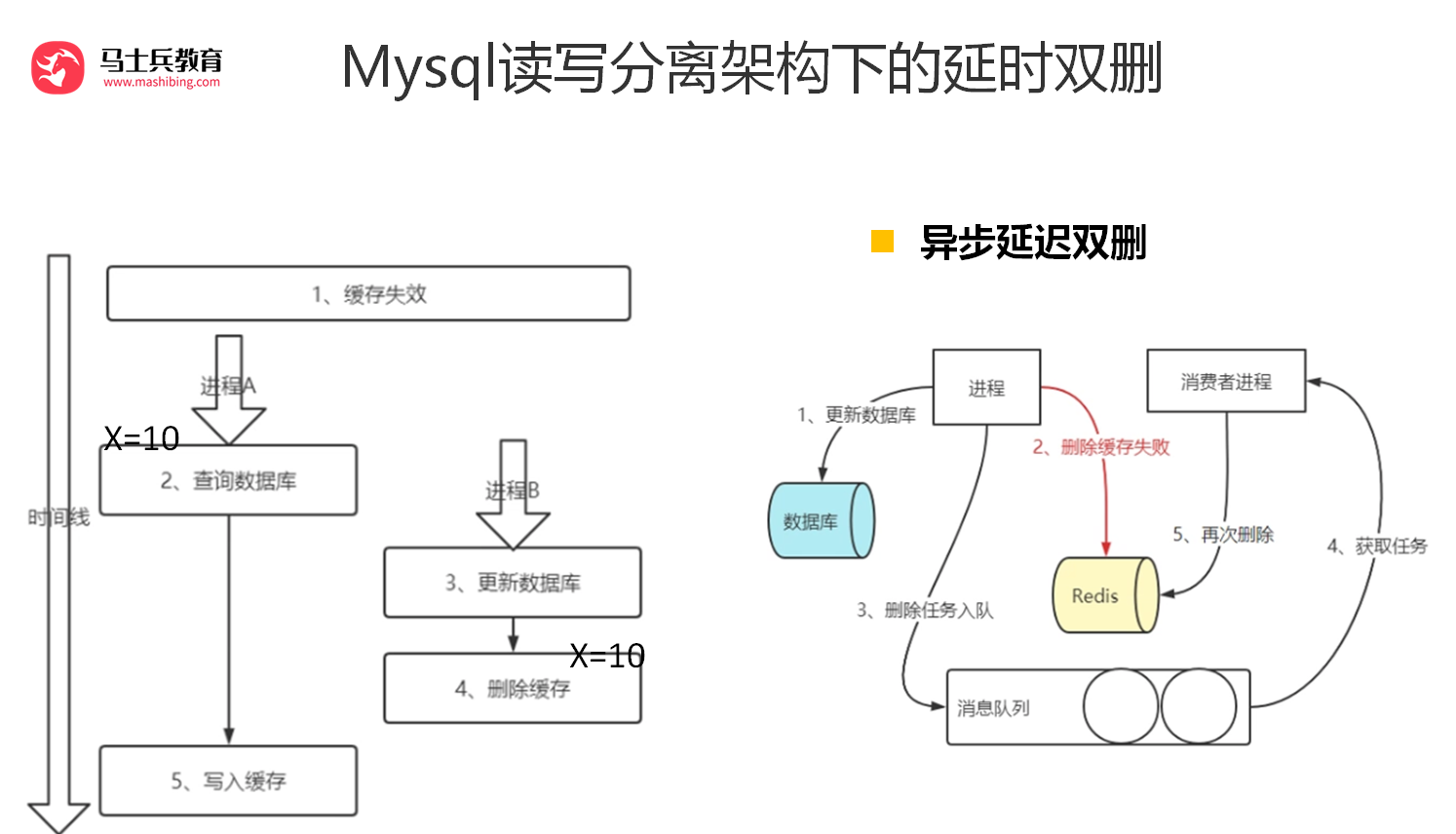
但是上述的保证事务提交完以后再进行删除缓存还有一个问题,就是如果你使用的是** Mysql ****的读写分离的架构**的话,那么其实主从同步之间也会有时间差。
此时来了两个请求,请求 A(更新操作) 和请求 B(查询操作)
请求 A 更新操作,删除了
Redis,
请求主库进行更新操作,主库与从库进行同步数据的操作,
请 B 查询操作,发现 Redis
中没有数据,
去从库中拿去数据,此时同步数据还未完成,拿到的数据是旧数据。
此时的解决办法有两个:
1、还是使用双删延时策略。只是,睡眠时间修改为在主从同步的延时时间基础上,加几百ms。
2、就是如果是对 Redis
进行填充数据的查询数据库操作,那么就强制将其指向主库进行查询。
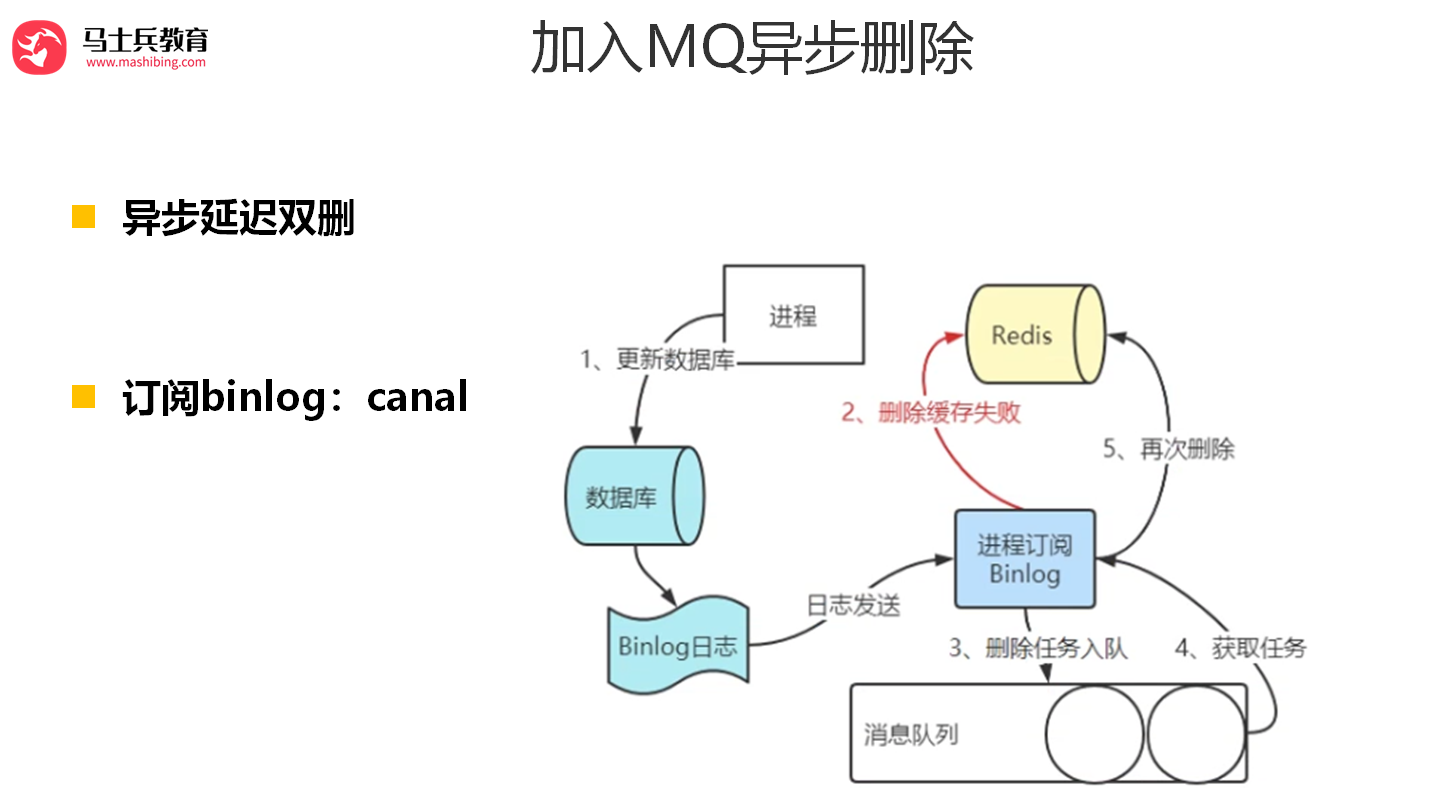
继续深入,采用这种同步淘汰策略,吞吐量降低怎么办?
那就将第二次删除作为异步的。自己起一个线程,异步删除。这样,写的请求就不用沉睡一段时间后了,再返回。这么做,加大吞吐量。
继续深入,第二次删除,如果删除失败怎么办?
所以,我们引出了,下面的第四种策略,先更新数据库,再删缓存。
4、先更新DB,后删除缓存
Cache Aside模式是一种常用的缓存处理方式。在读取数据时,先检查缓存,如果缓存中存在数据,则直接返回;如果缓存中不存在,则从数据库中读取,并将数据写入缓存,最后返回响应。在更新数据时,先更新数据库,然后再删除缓存。
通常情况下,我们更倾向于使用删除缓存的操作,因为删除缓存的速度比在数据库中更新数据的速度更快,能更有效地避免数据不一致的问题。通过延时双删的处理方式,可以进一步减少缓存不一致性的可能性。

- 点赞
- 收藏
- 关注作者
评论(0)