基于Python的机器学习工具包:Scikit-learn

Scikit-learn是一个基于Python的机器学习工具包,旨在为用户提供简单而高效的工具来进行数据挖掘和数据分析。作为Python数据科学生态系统中最受欢迎的机器学习库之一,Scikit-learn提供了广泛的机器学习算法和工具,还包括数据预处理、特征选择、模型评估等功能。本文将详细介绍Scikit-learn库的特点、常见功能和应用场景,并通过具体案例演示其在Python数据分析中的具体应用。
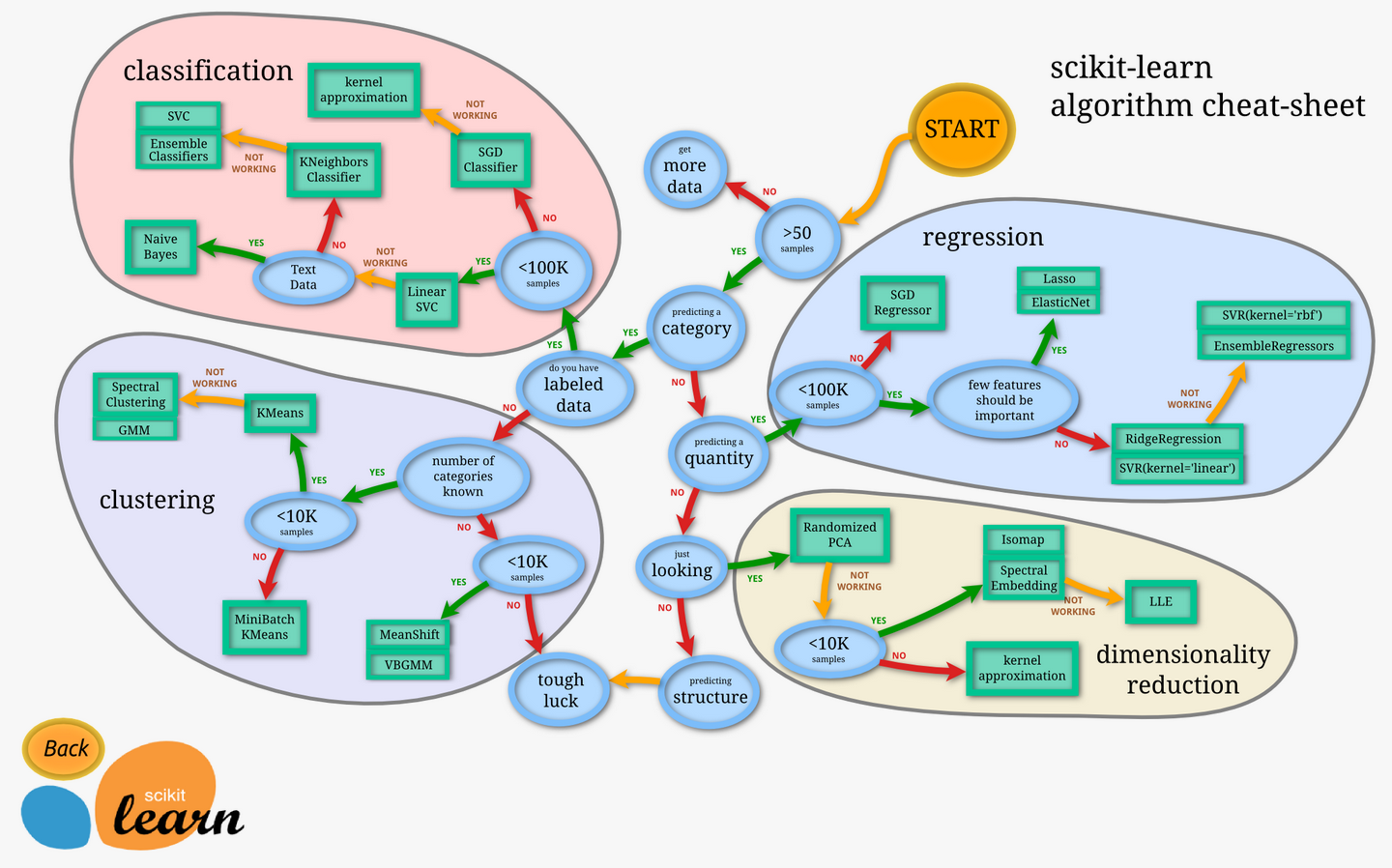
1. Scikit-learn库概述
1.1 定义
Scikit-learn是一个开源的机器学习工具包,由丰富的统计和机器学习算法构成,旨在成为Python数据科学生态系统中的核心组件之一。它建立在NumPy、SciPy和Matplotlib等库的基础上,为用户提供了简单而强大的工具来处理各种数据分析任务。
1.2 特点
Scikit-learn具有以下特点:
- 简单易用:Scikit-learn提供了简洁一致的API设计,使用户能够轻松地使用各种机器学习算法和工具。
- 广泛的机器学习算法:Scikit-learn包含了众多的机器学习算法,涵盖了监督学习、无监督学习、半监督学习等各种领域。
- 丰富的数据预处理功能:Scikit-learn提供了多种数据预处理方法,如特征缩放、特征选择、数据清洗等,帮助用户准备好用于训练的数据集。
- 模型评估与选择:Scikit-learn提供了多种模型评估和选择的指标和工具,帮助用户评估模型性能、选择合适的模型。
- 高性能运算:Scikit-learn底层使用了NumPy和SciPy等高性能计算库,能够快速处理大规模数据。
1.3 应用场景
Scikit-learn广泛应用于各种数据分析和机器学习任务,包括但不限于以下领域:
- 分类和回归:Scikit-learn提供了多种经典的分类和回归算法,如线性回归、决策树、随机森林、支持向量机等。
- 聚类:Scikit-learn包含了用于聚类分析的算法,如K-means、层次聚类、DBSCAN等。
- 特征工程:Scikit-learn提供了丰富的特征工程方法,包括特征缩放、特征选择、特征变换等,帮助用户提取和构建有信息量的特征。
- 异常检测:Scikit-learn提供了多种异常检测算法,帮助用户发现数据中的异常点。
- 数据预处理:Scikit-learn提供了多种数据预处理方法,如缺失值处理、标准化、归一化等,帮助用户准备好用于训练的数据集。
2. Scikit-learn库的常见功能
2.1 数据预处理
在进行机器学习任务之前,通常需要对原始数据进行预处理。Scikit-learn提供了多种数据预处理方法,如特征缩放、特征选择、数据清洗等。
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 特征缩放
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 特征选择
from sklearn.feature_selection import SelectKBest, chi2
selector = SelectKBest(chi2, k=5)
X_selected = selector.fit_transform(X, y)
# 数据清洗
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean')
X_cleaned = imputer.fit_transform(X)
2.2 分类和回归
Scikit-learn提供了多种经典的分类和回归算法,可以应用于各种预测任务。
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
# 分类任务
clf = LogisticRegression()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
# 回归任务
reg = RandomForestRegressor()
reg.fit(X_train, y_train)
y_pred = reg.predict(X_test)
2.3 聚类
Scikit-learn提供了多种聚类算法,可以帮助用户将数据样本划分为不同的群组。
from sklearn.cluster import KMeans
from sklearn.mixture import GaussianMixture
# K-means聚类
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
labels = kmeans.labels_
# 高斯混合模型聚类
gmm = GaussianMixture(n_components=3)
gmm.fit(X)
labels = gmm.predict(X)
2.4 特征工程
Scikit-learn提供了多种特征工程方法,包括特征缩放、特征选择、特征变换等,帮助用户提取和构建有信息量的特征。
from sklearn.preprocessing import PolynomialFeatures
from sklearn.feature_selection import SelectFromModel
# 多项式特征
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
# 基于模型的特征选择
selector = SelectFromModel(estimator=RandomForestClassifier())
X_selected = selector.fit_transform(X, y)
2.5 模型评估与选择
Scikit-learn提供了丰富的模型评估和选择的指标和工具,帮助用户评估模型性能、选择最合适的模型。
from sklearn.metrics import accuracy_score, mean_squared_error
from sklearn.model_selection import cross_val_score, GridSearchCV
# 评估分类模型
accuracy = accuracy_score(y_true, y_pred)
# 评估回归模型
rmse = mean_squared_error(y_true, y_pred, squared=False)
# 使用交叉验证评估模型性能
scores = cross_val_score(clf, X, y, cv=5)
# 使用网格搜索选择最佳超参数
param_grid = {'C': [0.1, 1, 10]}
grid_search = GridSearchCV(estimator=clf, param_grid=param_grid, cv=5)
grid_search.fit(X, y)
best_params = grid_search.best_params_
3. Scikit-learn库的应用场景
3.1 监督学习任务
Scikit-learn适用于各种监督学习任务,如分类、回归等。用户可以根据具体需求选择合适的算法和模型,并利用Scikit-learn提供的功能进行数据预处理、特征工程、模型训练和评估。
3.2 无监督学习任务
Scikit-learn也适用于无监督学习任务,如聚类、降维等。用户可以使用Scikit-learn提供的聚类算法将数据样本划分为不同的群组,或使用降维方法减少数据的维度。
3.3 特征工程
在数据分析和机器学习的过程中,特征工程起着至关重要的作用。Scikit-learn提供了多种特征工程方法,如特征缩放、特征选择、特征变换等,帮助用户提取和构建有信息量的特征。这对于改善模型性能和降低过拟合风险非常有帮助。
3.4 异常检测
在一些情况下,我们希望发现数据中的异常点。Scikit-learn提供了多种异常检测算法,帮助用户识别潜在的异常数据点。这对于异常检测和数据清洗非常有帮助。
3.5 数据预处理
在进行机器学习任务之前,通常需要对原始数据进行预处理。Scikit-learn提供了多种数据预处理方法,如缺失值处理、标准化、归一化等,帮助用户准备好用于训练的数据集。这对于提高模型性能和数据质量非常重要。
3.6 其他应用场景
除了上述应用场景外,Scikit-learn还可以在时间序列分析、自然语言处理、图像处理等领域发挥重要作用。用户可以根据具体需求选择合适的算法和模型,并结合Scikit-learn提供的功能进行数据分析和建模。
结论
Scikit-learn是一个强大且易于使用的机器学习工具包,为Python数据分析提供了丰富的算法和工具。它在数据预处理、特征工程、分类、回归、聚类、异常检测、模型评估等方面提供了多种功能,适用于各种数据分析和机器学习任务。无论是初学者还是专业人士,都可以通过Scikit-learn快速构建和部署机器学习模型,并解决实际问题。

- 点赞
- 收藏
- 关注作者
评论(0)