强化学习从基础到进阶–案例与实践[8]:近端策略优化(proximal policy optimization,PPO)算法
相关链接以及码源见文末
1.从同策略到异策略PPO算法
在介绍近端策略优化(proximal policy optimization,PPO) 之前,我们先回顾同策略和异策略这两种训练方法的区别。在强化学习里面,要学习的是一个智能体。如果要学习的智能体和与环境交互的智能体是相同的,我们称之为同策略。如果要学习的智能体和与环境交互的智能体不是相同的,我们称之为异策略。
为什么我们会想要考虑异策略?让我们回忆一下策略梯度。策略梯度是同策略的算法,因为在策略梯度中,我们需要一个智能体、一个策略和一个演员。演员去与环境交互搜集数据,搜集很多的轨迹
τ,根据搜集到的数据按照策略梯度的公式更新策略的参数,所以策略梯度是一个同策略的算法。PPO是策略梯度的变形,它是现在 OpenAI 默认的强化学习算法。
∇Rˉθ=Eτ∼pθ(τ)[R(τ)∇logpθ(τ)](8.1)
问题在于式(8.1)的
Eτ∼pθ(τ) 是对策略
πθ 采样的轨迹
τ 求期望。一旦更新了参数,从
θ 变成
θ′ ,概率
pθ(τ) 就不对了,之前采样的数据也不能用了。所以策略梯度是一个会花很多时间来采样数据的算法,其大多数时间都在采样数据。智能体与环境交互以后,接下来就要更新参数。我们只能更新参数一次,然后就要重新采样数据, 才能再次更新参数。这显然是非常花时间的,所以我们想要从同策略变成异策略,这样就可以用另外一个策略
πθ′、另外一个演员
θ′ 与环境交互(
θ′ 被固定了),用
θ′ 采样到的数据去训练
θ。假设我们可以用
θ′ 采样到的数据去训练
θ,我们可以多次使用
θ′ 采样到的数据,可以多次执行梯度上升(gradient ascent),可以多次更新参数, 都只需要用同一批数据。因为假设
θ 有能力学习另外一个演员
θ′ 所采样的数据,所以
θ′ 只需采样一次,并采样多一点的数据,让
θ 去更新很多次,这样就会比较有效率。
具体怎么做呢?这就需要介绍重要性采样(importance sampling) 的概念。
对于一个随机变量,我们通常用概率密度函数来刻画该变量的概率分布特性。具体来说,给定随机变量的一个取值,可以根据概率密度函数来计算该值对应的概率(密度)。反过来,也可以根据概率密度函数提供的概率分布信息来生成随机变量的一个取值,这就是采样。因此,从某种意义上来说,采样是概率密度函数的逆向应用。与根据概率密度函数计算样本点对应的概率值不同,采样过程往往没有那么直接,通常需要根据待采样分布的具体特点来选择合适的采样策略。
假设我们有一个函数
f(x),要计算从分布
p 采样
x,再把
x 代入
f ,得到
f(x)。我们该怎么计算
f(x) 的期望值呢?假设我们不能对分布
p 做积分,但可以从分布
p 采样一些数据
xi。把
xi 代入
f(x),取它的平均值,就可以近似
f(x) 的期望值。
现在有另外一个问题,假设我们不能从分布
p 采样数据,只能从另外一个分布
q 采样数据
x,
q 可以是任何分布。如果我们从
q 采样
xi,就不能使用式(8.2)。因为式(8.2)是假设
x 都是从
p 采样出来的。
Ex∼p[f(x)]≈N1i=1∑Nf(xi)(8.2)
所以我们做一个修正,期望值
Ex∼p[f(x)] 就是
∫f(x)p(x)dx,我们对其做如下的变换:
∫f(x)p(x)dx=∫f(x)q(x)p(x)q(x)dx=Ex∼q[f(x)q(x)p(x)]
就可得
Ex∼p[f(x)]=Ex∼q[f(x)q(x)p(x)](8.3)
我们就可以写成对
q 里面所采样出来的
x 取期望值。我们从
q 里面采样
x,再计算
f(x)q(x)p(x),再取期望值。所以就算我们不能从
p 里面采样数据,但只要能从
q 里面采样数据,就可以计算从
p 采样
x 代入
f 以后的期望值。
因为是从
q 采样数据,所以我们从
q 采样出来的每一笔数据,都需要乘一个重要性权重(importance weight)
q(x)p(x) 来修正这两个分布的差异。
q(x) 可以是任何分布,唯一的限制就是
q(x) 的概率是 0 的时候,
p(x) 的概率不为 0,不然会没有定义。假设
q(x) 的概率是 0 的时候,
p(x) 的概率也都是 0,
p(x) 除以
q(x)是有定义的。所以这个时候我们就可以使用重要性采样,把从
p 采样换成从
q 采样。
重要性采样有一些问题。虽然我们可以把
p 换成任何的
q。但是在实现上,
p 和
q 的差距不能太大。差距太大,会有一些问题。比如,虽然式(8.3)成立(式(8.3)左边是
f(x) 的期望值,它的分布是
p,式(8.3)右边是
f(x)q(x)p(x) 的期望值,它的分布是
q),但如果不是计算期望值,而是计算方差,
Varx∼p[f(x)] 和
Varx∼q[f(x)q(x)p(x)] 是不一样的。两个随机变量的平均值相同,并不代表它们的方差相同。
我们可以将
f(x) 和
f(x)q(x)p(x) 代入方差的公式
Var[X]=E[X2]−(E[X])2,可得
Varx∼p[f(x)]=Ex∼p[f(x)2]−(Ex∼p[f(x)])2
Varx∼q[f(x)q(x)p(x)]=Ex∼q[(f(x)q(x)p(x))2]−(Ex∼q[f(x)q(x)p(x)])2=Ex∼p[f(x)2q(x)p(x)]−(Ex∼p[f(x)])2
Varx∼p[f(x)] 和
Varx∼q[f(x)q(x)p(x)] 的差别在于第一项是不同的,
Varx∼q[f(x)q(x)p(x)] 的第一项多乘了
q(x)p(x),如果
q(x)p(x) 差距很大,
f(x)q(x)p(x) 的方差就会很大。所以理论上它们的期望值一样,也就是,我们只要对分布
p采样足够多次,对分布
q采样足够多次,得到的结果会是一样的。但是如果我们采样的次数不够多,因为它们的方差差距是很大的,所以我们就有可能得到差别非常大的结果。
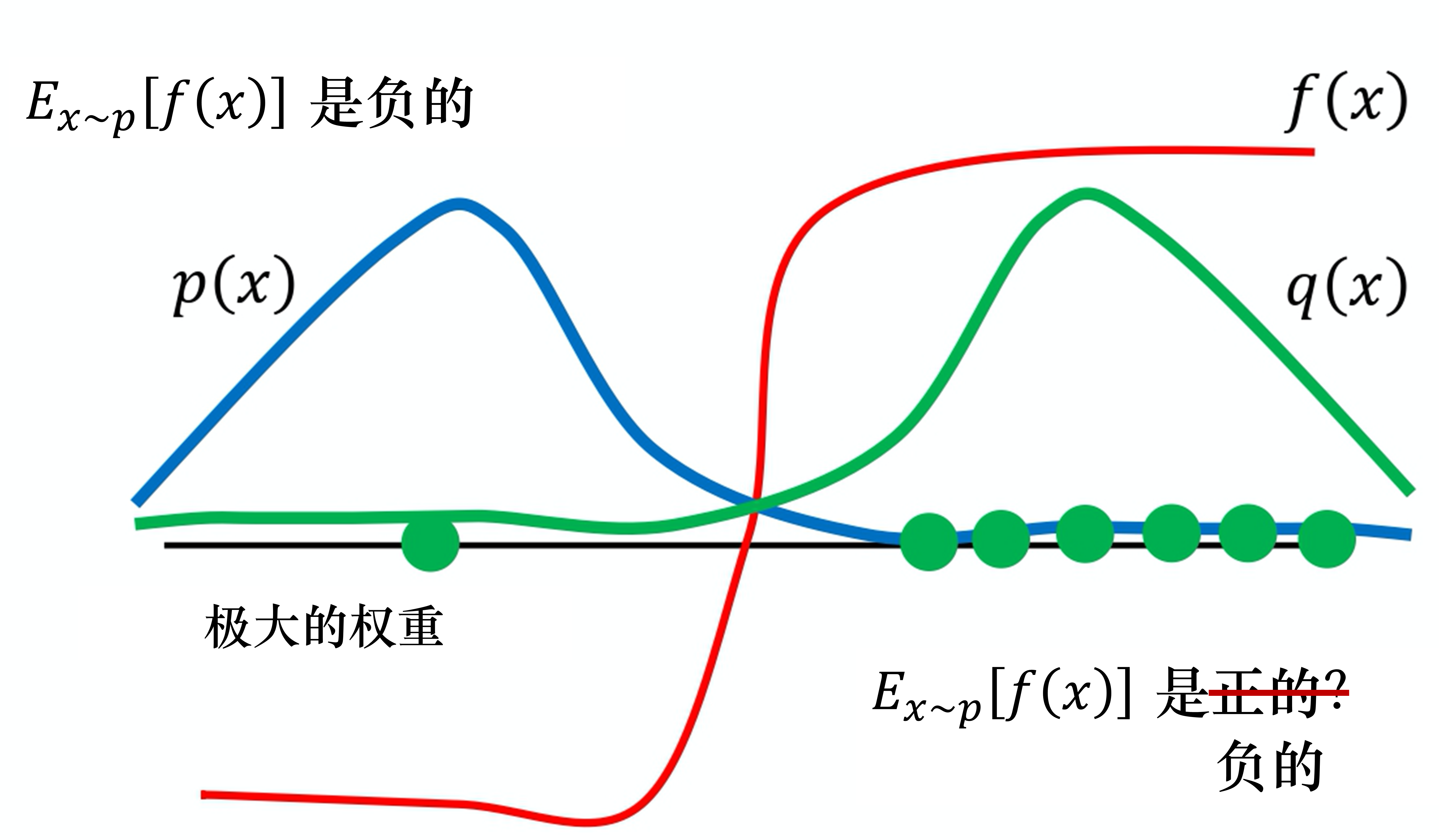
例如,当
p(x) 和
q(x) 差距很大时,就会有问题。如图 8.1 所示,假设蓝线是
p(x) 的分布,绿线是
q(x) 的分布,红线是
f(x)。如果我们要计算
f(x)的期望值,从分布
p(x) 做采样,显然
Ex∼p[f(x)] 是负的。这是因为左边区域
p(x) 的概率很高,所以采样会到这个区域,而
f(x) 在这个区域是负的, 所以理论上这一项算出来会是负的。
接下来我们改成从
q(x) 采样,因为
q(x) 在右边区域的概率比较高,所以如果我们采样的点不够多,可能只会采样到右侧。如果我们只采样到右侧,可能
Ex∼q[f(x)q(x)p(x)] 是正的。
我们这边采样到这些点,去计算它们的
f(x)q(x)p(x) 都是正的。我们采样到这些点都是正的,取期望值以后也都是正的,这是因为采样的次数不够多。假设我们采样次数很少,只能采样到右边。左边虽然概率很低,但也有可能被采样到。假设我们好不容易采样到左边的点,因为左边的点的
p(x) 和
q(x) 是差很多的, 这边
p(x) 很大,
q(x) 很小。
f(x) 好不容易终于采样到一个负的,这个负的就会被乘上一个非常大的权重,这样就可以平衡刚才那边一直采样到正的值的情况。最终我们算出这一项的期望值,终究还是负的。但前提是我们要采样足够多次,这件事情才会发生。但有可能采样次数不够多,
Ex∼p[f(x)] 与
Ex∼q[f(x)q(x)p(x)] 可能就有很大的差距。这就是重要性采样的问题。
图 8.1 重要性采样的问题
现在要做的就是把重要性采样用在异策略的情况中,把同策略训练的算法改成异策略训练的算法。
怎么改呢?如式(8.4)所示,之前我们用策略
πθ 与环境交互,采样出轨迹
τ,计算
R(τ)∇logpθ(τ)。现在我们不用
θ 与环境交互,假设有另外一个策略
πθ′,它就是另外一个演员,它的工作是做示范(demonstration)。
∇Rˉθ=Eτ∼pθ′(τ)[pθ′(τ)pθ(τ)R(τ)∇logpθ(τ)](8.4)
θ′ 的工作是为
θ 做示范。它与环境交互,告诉
θ 它与环境交互会发生什么事,借此来训练
θ。我们要训练的是
θ ,
θ′ 只负责做示范,负责与环境交互。我们现在的
τ 是从
θ′ 采样出来的,是用
θ′ 与环境交互。所以采样出来的
τ 是从
θ′ 采样出来的,这两个分布不一样。但没有关系,假设我们本来是从
p 采样,但发现不能从
p 采样,所以我们不用
θ 与环境交互,可以把
p 换成
q,在后面补上一个重要性权重。同理,我们把
θ 换成
θ′ 后,要补上一个重要性权重
pθ′(τ)pθ(τ)。这个重要性权重就是某一个轨迹
τ 用
θ 算出来的概率除以这个轨迹
τ 用
θ′ 算出来的概率。这一项是很重要的,因为我们要学习的是演员
θ,而
θ 和
θ′ 是不太一样的,
θ′ 见到的情形与
θ 见到的情形可能不是一样的,所以中间要有一个修正的项。
Q:现在的数据是从
θ′ 采样出来的,从
θ 换成
θ′ 有什么好处呢?
A:因为现在与环境交互的是
θ′ 而不是
θ,所以采样的数据与
θ 本身是没有关系的。因此我们就可以让
θ′ 与环境交互采样大量的数据,
θ 可以多次更新参数,一直到
θ 训练到一定的程度。更新多次以后,
θ′ 再重新做采样,这就是同策略换成异策略的妙处。
实际在做策略梯度的时候,我们并不是给整个轨迹
τ 一样的分数,而是将每一个状态-动作对分开计算。实际更新梯度的过程可写为
E(st,at)∼πθ[Aθ(st,at)∇logpθ(atn∣stn)]
我们用演员
θ 采样出
st 与
at,采样出状态-动作的对,我们会计算这个状态-动作对的优势(advantage)
Aθ(st,at), 就是它有多好。
Aθ(st,at) 即用累积奖励减去基线,这一项就是估测出来的。它要估测的是,在状态
st 采取动作
at 是好的还是不好的。接下来在后面乘
∇logpθ(atn∣stn),也就是如果
Aθ(st,at) 是正的,就要增大概率;如果是负的,就要减小概率。
我们可以通过重要性采样把同策略变成异策略,从
θ 变成
θ′。所以现在
st、
at 是
θ′ 与环境交互以后所采样到的数据。 但是训练时,要调整的参数是模型
θ。因为
θ′ 与
θ 是不同的模型,所以我们要有一个修正的项。这个修正的项,就是用重要性采样的技术,把
st、
at 用
θ 采样出来的概率除以
st、
at 用
θ′ 采样出来的概率。
E(st,at)∼πθ′[pθ′(st,at)pθ(st,at)Aθ(st,at)∇logpθ(atn∣stn)]
其中,
Aθ(st,at) 有一个上标
θ,
θ 代表
Aθ(st,at) 是演员
θ 与环境交互的时候计算出来的。但是实际上从
θ 换到
θ′ 的时候,
Aθ(st,at) 应该改成
Aθ′(st,at),为什么呢?
A(st,at) 这一项是想要估测在某一个状态采取某一个动作,接下来会得到累积奖励的值减去基线的值。我们怎么估计
A(st,at)?我们在状态
st 采取动作
at,接下来会得到的奖励的总和,再减去基线就是
A(st,at)。之前是
θ 与环境交互,所以我们观察到的是
θ 可以得到的奖励。但现在是
θ′ 与环境交互,所以我们得到的这个优势是根据
θ′ 所估计出来的优势。但我们现在先不要管那么多,就假设
Aθ(st,at) 和
Aθ′(st,at) 可能是差不多的。
接下来,我们可以拆解
pθ(st,at) 和
pθ′(st,at),即
pθ(st,at)pθ′(st,at)=pθ(at∣st)pθ(st)=pθ′(at∣st)pθ′(st)
于是我们可得
E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)pθ′(st)pθ(st)Aθ′(st,at)∇logpθ(atn∣stn)]
这里需要做的一件事情是,假设模型是
θ 的时候,我们看到
st 的概率,与模型是
θ′ 的时候,我们看到
st 的概率是一样的,即
pθ(st)=pθ′(st)。因为
pθ(st)和
pθ′(st)是一样的,所以我们可得
E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)∇logpθ(atn∣stn)](8.5)
Q:为什么我们可以假设
pθ(st) 和
pθ′(st) 是一样的?
A:因为我们会看到状态往往与采取的动作是没有太大的关系的。比如我们玩不同的雅达利游戏,其实看到的游戏画面都是差不多的,所以也许不同的
θ 对
st 是没有影响的。但更直接的理由就是
pθ(st) 很难算,
pθ(st)有一个参数
θ,它表示的是我们用
θ 去与环境交互,计算
st 出现的概率,而这个概率很难算。尤其是如果输入的是图片,同样的
st 可能根本就不会出现第二次。我们根本没有办法估计
pθ(st),所以干脆就无视这个问题。
但是
pθ(at∣st)很好算,我们有参数
θ ,它就是一个策略网络。我们输入状态
st 到策略网络中,它会输出每一个
at 的概率。所以我们只要知道
θ 和
θ′ 的参数就可以计算
pθ′(at∣st)pθ(at∣st)。
式(8.5)是梯度,我们可以从梯度反推原来的目标函数:
∇f(x)=f(x)∇logf(x)
注意,对
θ 求梯度时,
pθ′(at∣st) 和
Aθ′(st,at) 都是常数。
所以实际上,当我们使用重要性采样的时候,要去优化的目标函数为
Jθ′(θ)=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)]
我们将其记为
Jθ′(θ),因为
Jθ′(θ) 括号里面的
θ 代表我们要去优化的参数。
θ′ 是指我们用
θ′ 做示范,就是现在真正在与环境交互的是
θ′。因为
θ 不与环境交互,是
θ′ 在与环境交互。然后我们用
θ′ 与环境交互,采样出
st、
at 以后,要去计算
st 与
at 的优势
Aθ′(st,at),再用它乘
pθ′(at∣st)pθ(at∣st)。
pθ′(at∣st)pθ(at∣st) 是容易计算的,我们可以从采样的结果来估测
Aθ′(st,at) ,所以
Jθ′(θ) 是可以计算的。实际上在更新参数的时候,我们就是按照式(8.5)来更新参数的。
2.近端策略优化
我们可以通过重要性采样把同策略换成异策略,但重要性采样有一个问题:如果
pθ(at∣st) 与
pθ′(at∣st) 相差太多,即这两个分布相差太多,重要性采样的结果就会不好。
怎么避免它们相差太多呢?这就是PPO要做的事情。
注意,由于在 PPO 中
θ′ 是
θold,即行为策略也是
πθ,因此 PPO 是同策略的算法。 如式(8.6)所示,PPO 实际上做的事情就是这样,在异策略的方法里优化目标函数
Jθ′(θ)。但是这个目标函数又牵涉到重要性采样。在做重要性采样的时候,
pθ(at∣st) 不能与
pθ′(at∣st)相差太多。做示范的模型不能与真正的模型相差太多,相差太多,重要性采样的结果就会不好。我们在训练的时候,应多加一个约束(constrain)。这个约束是
θ 与
θ′ 输出的动作的 KL 散度(KL divergence),这一项用于衡量
θ 与
θ′ 的相似程度。我们希望在训练的过程中,学习出的
θ 与
θ′ 越相似越好。因为如果
θ 与
θ′ 不相似,最后的结果就会不好。所以在 PPO 里面有两项:一项是优化本来要优化的
Jθ′(θ),另一项是一个约束。这个约束就好像正则化(regularization)的项(term) 一样,它所做的就是希望最后学习出的
θ 与
θ′ 相差不大。
JPPOθ′(θ)=Jθ′(θ)−βKL(θ,θ′)Jθ′(θ)=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)](8.6)
PPO 有一个前身:信任区域策略优化(trust region policy optimization,TRPO)。TRPO 可表示为
JTRPOθ′(θ)=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)],KL(θ,θ′)<δ
TRPO 与 PPO 不一样的地方是约束所在的位置不一样,PPO 直接把约束放到要优化的式子里面,我们就可以用梯度上升的方法去最大化式(8.6)。但 TRPO 是把 KL 散度当作约束,它希望
θ 与
θ′ 的 KL 散度小于
δ。如果我们使用的是基于梯度的优化,有约束是很难处理的。TRPO 是很难处理的,因为它把 KL 散度约束当作一个额外的约束,没有放在目标(objective)里面,所以它很难计算。因此我们一般就使用 PPO,而不使用 TRPO 。PPO 与 TRPO 的性能差不多,但 PPO 在实现上比 TRPO 容易得多。
KL 散度到底指的是什么?这里我们直接把 KL 散度当作一个函数,输入是
θ 与
θ′,但并不是把
θ 或
θ′ 当作一个分布,计算这两个分布之间的距离。所谓的
θ 与
θ′ 的距离并不是参数上的距离,而是行为(behavior)上的距离。假设我们有两个演员————
θ 和
θ′,所谓参数上的距离就是计算这两组参数有多相似。这里讲的不是参数上的距离, 而是它们行为上的距离。我们先代入一个状态
s,它会对动作的空间输出一个分布。假设我们有 3 个动作,3 个可能的动作就输出 3 个值。行为距离(behavior distance)就是,给定同样的状态,输出动作之间的差距。这两个动作的分布都是概率分布,所以我们可以计算这两个概率分布的 KL 散度。把不同的状态输出的这两个分布的 KL 散度的平均值就是我们所指的两个演员间的 KL 散度。
Q:为什么不直接计算
θ 和
θ′ 之间的距离?计算这个距离甚至不用计算 KL 散度,L1 与 L2 的范数(norm)也可以保证
θ 与
θ′ 很相似。
A:在做强化学习的时候,之所以我们考虑的不是参数上的距离,而是动作上的距离,是因为很有可能对于演员,参数的变化与动作的变化不一定是完全一致的。有时候参数稍微变了,它可能输出动作的就差很多。或者是参数变很多,但输出的动作可能没有什么改变。所以我们真正在意的是演员的动作上的差距,而不是它们参数上的差距。因此在做 PPO 的时候,所谓的 KL 散度并不是参数的距离,而是动作的距离。
2.1 近端策略优化惩罚
PPO 算法有两个主要的变种:近端策略优化惩罚(PPO-penalty)和近端策略优化裁剪(PPO-clip)。
我们来看一下 PPO1 算法,即近端策略优化惩罚算法。它先初始化一个策略的参数
θ0。在每一个迭代里面,我们用前一个训练的迭代得到的演员的参数
θk 与环境交互,采样到大量状态-动作对。根据
θk 交互的结果,我们估测
Aθk(st,at)。我们使用 PPO 的优化公式。但与原来的策略梯度不一样,原来的策略梯度只能更新一次参数,更新完以后,我们就要重新采样数据。但是现在不同,我们用
θk 与环境交互,采样到这组数据以后,我们可以让
θ 更新很多次,想办法最大化目标函数,如式(8.7)所示。这里面的
θ 更新很多次也没有关系,因为我们已经有重要性采样,所以这些经验,这些状态-动作对是从
θk 采样出来的也没有关系。
θ 可以更新很多次,它与
θk 变得不太一样也没有关系,我们可以照样训练
θ。
JPPOθk(θ)=Jθk(θ)−βKL(θ,θk)(8.7)
在 PPO 的论文里面还有一个自适应KL散度(adaptive KL divergence)。这里会遇到一个问题就,即
β 要设置为多少。这个问题与正则化一样,正则化前面也要乘一个权重,所以 KL 散度前面也要乘一个权重,但
β 要设置为多少呢?我们有一个动态调整
β 的方法。在这个方法里面,我们先设一个可以接受的 KL 散度的最大值。假设优化完式(8.7)以后,KL 散度的值太大,这就代表后面惩罚的项
βKL(θ,θk) 没有发挥作用,我们就把
β 增大。另外,我们设一个 KL 散度的最小值。如果优化完式(8.7)以后,KL 散度比最小值还要小,就代表后面这一项的效果太强了,我们怕他只优化后一项,使
θ 与
θk 一样,这不是我们想要的,所以我们要减小
β。
β 是可以动态调整的,因此我们称之为自适应KL惩罚(adaptive KL penalty)。我们可以总结一下自适应KL惩罚:
- 如果
KL(θ,θk)>KLmax,增大
β;
- 如果
KL(θ,θk)<KLmin,减小
β。
近端策略优化惩罚可表示为
JPPOθk(θ)=Jθk(θ)−βKL(θ,θk)Jθk(θ)≈(st,at)∑pθk(at∣st)pθ(at∣st)Aθk(st,at)
2.2 近端策略优化裁剪
如果我们觉得计算 KL 散度很复杂,那么还有一个 PPO2算法,PPO2 即近端策略优化裁剪。近端策略优化裁剪的目标函数里面没有 KL 散度,其要最大化的目标函数为
JPPO2θk(θ)≈(st,at)∑min(pθk(at∣st)pθ(at∣st)Aθk(st,at),clip(pθk(at∣st)pθ(at∣st),1−ε,1+ε)Aθk(st,at))(8.8)
其中,
- 操作符(operator)min 是在第一项与第二项里面选择比较小的项。
- 第二项前面有一个裁剪(clip)函数,裁剪函数是指,在括号里面有3项,如果第一项小于第二项,那就输出
1−ε;第一项如果大于第三项,那就输出
1+ε。
-
ε 是一个超参数,是我们要调整的,可以设置成 0.1 或 0.2 。
假设设置
ε=0.2,我们可得
clip(pθk(at∣st)pθ(at∣st),0.8,1.2)
如果
pθk(at∣st)pθ(at∣st) 算出来小于 0.8,那就输出 0.8;如果算出来大于 1.2,那就输出1.2。
我们先要理解
clip(pθk(at∣st)pθ(at∣st),1−ε,1+ε)
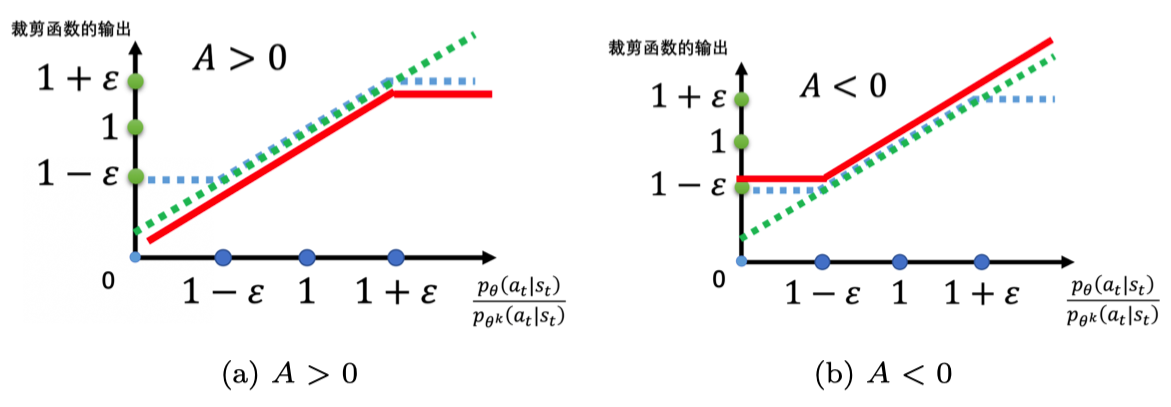
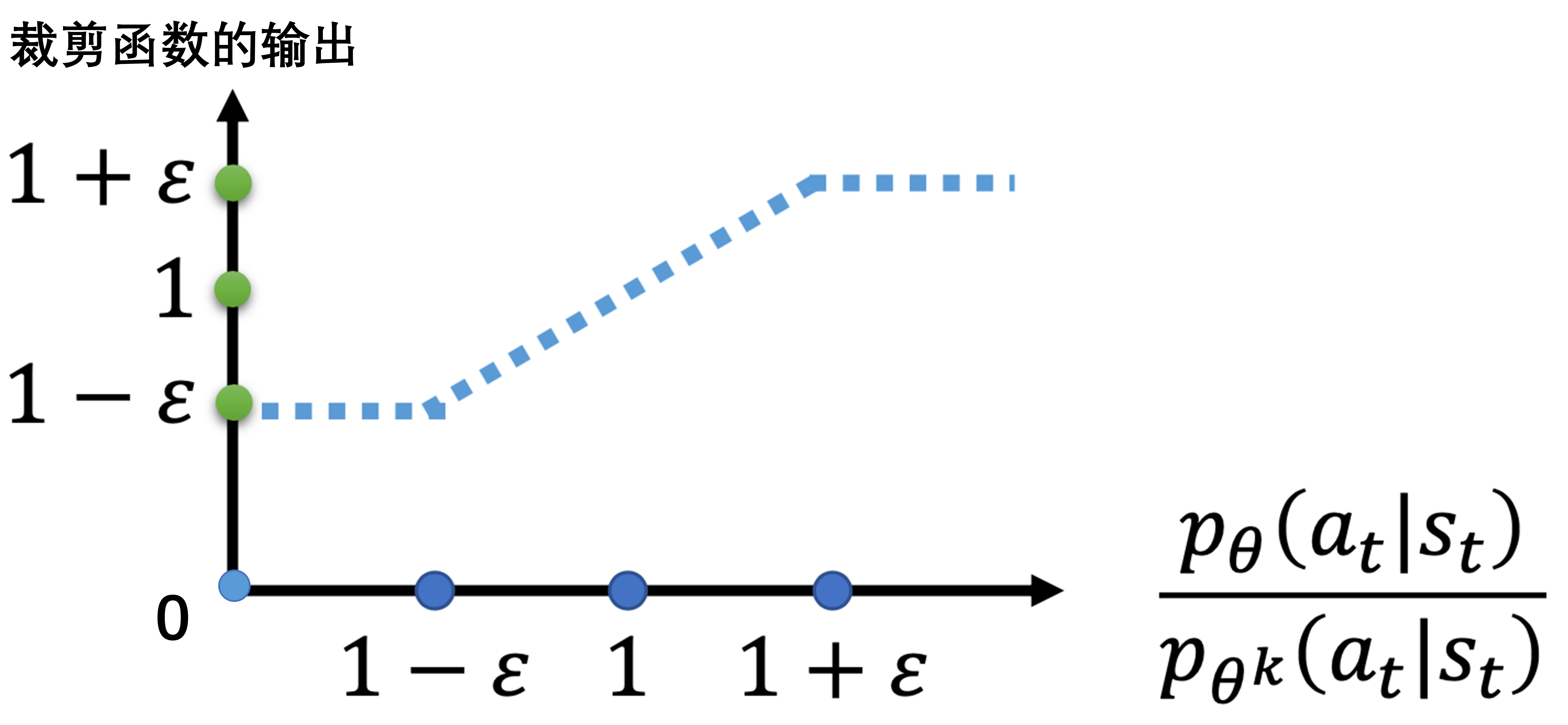
图 8.2 的横轴代表
pθk(at∣st)pθ(at∣st),纵轴代表裁剪函数的输出。
- 如果
pθk(at∣st)pθ(at∣st) 大于
1+ε,输出就是
1+ε;
- 如果小于
1−ε,输出就是
1−ε;
- 如果介于
1+ε ~{}
1−ε,输出等于输入。
图 8.2 裁剪函数
如图 8.3a 所示,
pθk(at∣st)pθ(at∣st) 是绿色的线;
clip(pθk(at∣st)pθ(at∣st),1−ε,1+ε) 是蓝色的线;在绿色的线与蓝色的线中间,我们要取一个最小的结果。假设前面乘上的项
A 大于 0,取最小的结果,就是红色的这条线。如图 8.3b 所示,如果
A 小于 0 ,取最小结果的以后,就得到红色的这条线。
图 8.3
A对裁剪函数输出的影响
虽然式(8.8)看起来有点儿复杂,但实现起来是比较简单的,因为式(8.8)想要做的就是希望
pθ(at∣st) 与
pθk(at∣st)比较接近,也就是做示范的模型与实际上学习的模型在优化以后不要差距太大。
怎么让它做到不要差距太大呢?
如果
A>0,也就是某一个状态-动作对是好的,我们希望增大这个状态-动作对的概率。也就是,我们想让
pθ(at∣st) 越大越好,但它与
pθk(at∣st) 的比值不可以超过
1+ε。如果超过
1+ε ,就没有好处了。红色的线就是目标函数,我们希望目标函数值越大越好,我们希望
pθ(at∣st) 越大越好。但是
pθk(at∣st)pθ(at∣st) 只要大过
1+ε,就没有好处了。所以在训练的时候,当
pθ(at∣st) 被训练到
pθk(at∣st)pθ(at∣st)>1+ε 时,它就会停止。假设
pθ(at∣st) 比
pθk(at∣st) 还要小,并且这个优势是正的。因为这个动作是好的,我们希望这个动作被采取的概率越大越好,希望
pθ(at∣st) 越大越好。所以假设
pθ(at∣st) 还比
pθk(at∣st) 小,那就尽量把它变大,但只要大到
1+ε 就好。
如果
A<0,也就是某一个状态-动作对是不好的,那么我们希望把
pθ(at∣st) 减小。如果
pθ(at∣st) 比
pθk(at∣st) 还大,那我们就尽量把它减小,减到
pθk(at∣st)pθ(at∣st) 是
1−ε 的时候停止,此时不用再减得更小。
这样的好处就是,我们不会让
pθ(at∣st) 与
pθk(at∣st) 差距太大。要实现这个其实很简单。
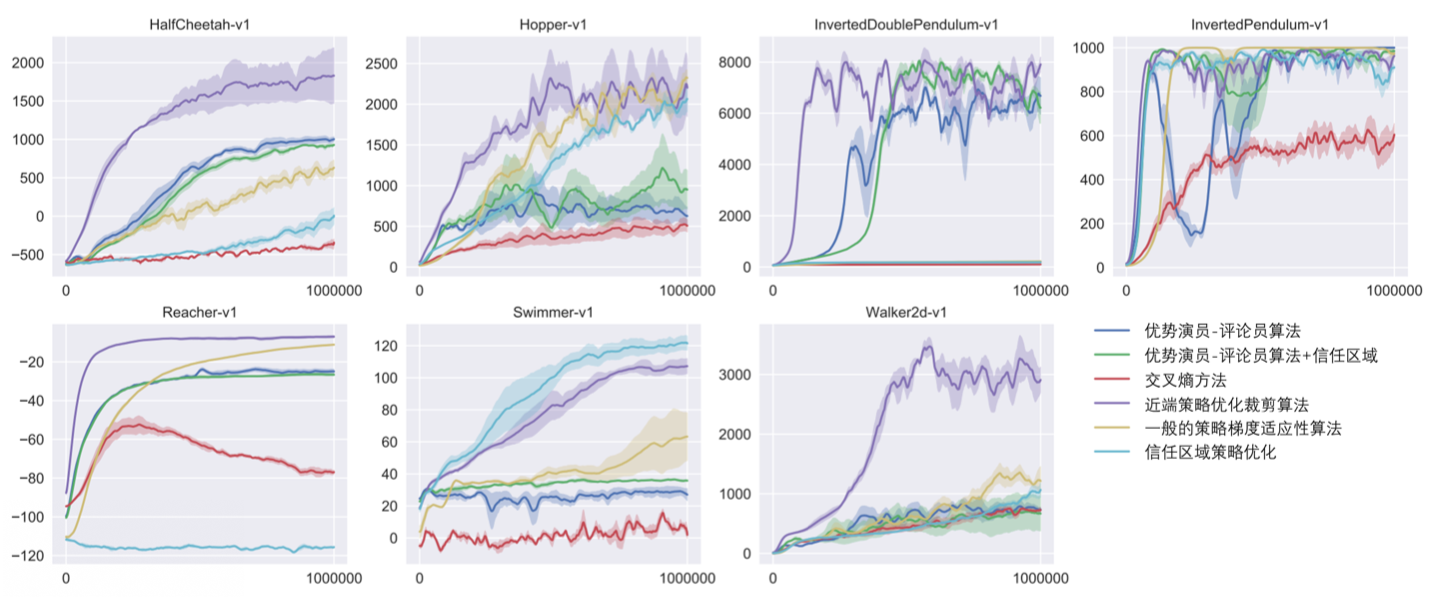
图 8.4 所示为 PPO 与其他算法的比较。优势演员-评论员和优势演员-评论员+信任区域(trust region)算法是基于演员-评论员的方法。PPO 算法是用紫色线表示,图 8.4 中每张子图表示某一个强化学习的任务,在多数情况中,PPO 都是不错的,即时不是最好的,也是第二好的。
图 8.4 PPO与其他算法的比较
参考文献
更多优质内容请关注公号:汀丶人工智能
相关链接以及码源见文末
强化学习从基础到进阶-案例与实践含码源-强化学习全系列超详细算法码源齐全


评论(0)