Flink 实例:处理 IoT 事件流

01、Flink 实例:处理 IoT 事件流
假设一台机器上安装了传感器,用户希望从这些传感器收集数据,并每 5min 计算每个传感器的平均温度。其架构如图 1 所示。
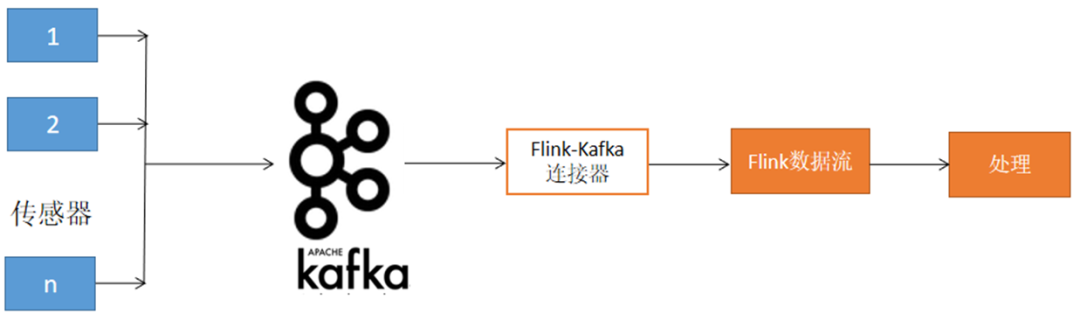
■ 图 1 IOT 事件处理架构
在这个场景中,假设传感器将信息发送给 Kafka 的主题 temp,数据格式为(传感器 id、时间戳、温度)。这里假设以字符串的形式接收 Kafka 主题中的事件,部分数据如下:
sensor_1,1629943899014,51.087254019871054
sensor_9,1629943899014,70.44743245583899
sensor_7,1629943899014,65.53215956486392
sensor_0,1629943899014,53.210570822216546
sensor_8,1629943899014,93.12876931817556
sensor_3,1629943899014,57.55153052162809
sensor_2,1629943899014,107.61249366604993
sensor_5,1629943899014,92.02083744773739
sensor_4,1629943899014,95.7688424087137
sensor_6,1629943899014,95.04398353316257
......现在需要编写 Flink 流处理代码从 Kafka 的 temp 主题读取这些数据,并使用 Flink 转换处理数据,因此 Kafka 作为数据源,Flink 流处理程序作为 Kafka 的消费者。
这里要考虑的是,既然有来自传感器的时间戳值,那么可以使用事件时间计算时间因素。这意味着可以处理乱序的传感器数据。
Scala 代码如下:
import Java.time.Duration
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.Windows.TimeWindow
import org.apache.flink.util.Collector
object KafkaIotDemo {
//case class,流数据类型
case class SensorReading(id:String, timestamp:Long, temperature:Double)
def main(args: Array[String]) {
//设置流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val source = KafkaSource.builder[String]
.setBootstrapServers("localhost:9092")
.setTopics("temp")
.setGroupId("group-test")
.setStartingOffsets(OffsetsInitializer.earliest)
.setValueOnlyDeserializer(new SimpleStringSchema)
.build
//水印策略
val watermarkStrategy = WatermarkStrategy
.forBoundedOutOfOrderness[String](Duration.ofSeconds(1))
.withTimestampAssigner(new SerializableTimestampAssigner[String]() {
override def extractTimestamp(s: String, l: Long): Long =
s.split(",")(1).toLong
})
env
//读取Kafka数据源
.fromSource(source, watermarkStrategy, "Sensor temperature Source")
//转换流数据类型
.map(s => {
val fields: Array[String] = s.split(",")
SensorReading(fields(0), fields(1).toLong, fields(2).toDouble)
})
//按key分区
.keyBy(sr => sr.id)
//开大小为 5 minutes 的滚动窗口(这里为了测试,设置为 5s)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
//执行增量聚合
.aggregate(new AggAvgTemp(),new ProcessAvgTemp())
//输出结果
.print()
//触发流程序执行
env.execute("Flink Sensor Temperature Demo")
}
//增量处理函数
class AggAvgTemp extends AggregateFunction[SensorReading, (Double, Long), Double] {
//创建初始ACC
override def createAccumulator() = (0.0, 0L)
//累加每个传感器(每个分区)的事件
override def add(sr: SensorReading, acc: (Double, Long)) =
(sr.temperature + acc._1, acc._2 + 1L)
//分区合并
override def merge(acc1: (Double, Long), acc2: (Double, Long)) =
(acc1._1 + acc2._1, acc1._2 + acc2._2)
//返回每个传感器的平均温度
override def getResult(acc: (Double, Long)): Double = acc._1 / acc._2
}
//窗口处理函数(注意这里引入的ProcessWindowFunction不要引错了Java的)
class ProcessAvgTemp extends ProcessWindowFunction[Double, (String, Long, Double), String, TimeWindow] {
override def process(key: String,
context: Context,
elements: Iterable[Double],
out: Collector[(String, Long, Double)]): Unit = {
//计算平均温度
val average = Math.round(elements.iterator.next * 100) / 100.0
//发送到下游算子
out.collect((key, context.window.getEnd, average))
}
}
}Java 代码如下:
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.Windows.TimeWindow;
import org.apache.flink.util.Collector;
import Java.time.Duration;
public class KafkaIotDemo {
//POJO类,温度数据类型
public static class SensorReading {
public String id; //传感器id
public long timestamp; //读取时的时间戳
public double temperature; //读取的温度值
public SensorReading() { }
public SensorReading(String id, long timestamp, double temperature) {
this.id = id;
this.timestamp = timestamp;
this.temperature = temperature;
}
public String toString() {
return "(" + this.id + ", "
+ this.timestamp + ", "
+ this.temperature + ")";
}
}
public static void main(String[] args) throws Exception {
//设置流执行环境
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
//数据源
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("localhost:9092")
.setTopics("temp")
.setGroupId("group-test")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
//水印策略
WatermarkStrategy<String> watermarkStrategy = WatermarkStrategy
.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<String>(){
@Override
public long extractTimestamp(String s, long l) {
return Long.parseLong(s.split(",")[1]);
}
});
env
//指定Kafka数据源
.fromSource(source, watermarkStrategy, "Sensor temperature Source")
//转换为DataStream<SensorReading>
.map(new MapFunction<String, SensorReading>() {
@Override
public SensorReading map(String s) throws Exception {
String[] fields = s.split(",");
return new SensorReading(fields[0], Long.parseLong(fields[1]),
Double.parseDouble(fields[2]));
}
})
//转换为KeyedStream
.keyBy(new KeySelector<SensorReading, String>() {
@Override
public String getKey(SensorReading sensorReading) throws Exception {
return sensorReading.id;
}
})
//开大小为 5 minutes 的滚动窗口(这里为了测试,设置为 5s)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
//执行增量聚合
.aggregate(new AggAvgTemp(),new ProcessAvgTemp())
.print();
//触发流程序执行
env.execute("Flink Sensor Temperature Demo");
}
//增量处理函数
public static class AggAvgTemp implements AggregateFunction<
SensorReading, //input
Tuple2<Double,Long>, //acc, <sum, count>
Double> { //output, avg
//创建初始ACC
@Override
public Tuple2<Double,Long> createAccumulator() {
return new Tuple2<>(0.0,0L);
}
//累加每个传感器(每个分区)的事件
@Override
public Tuple2<Double,Long> add(SensorReading sr, Tuple2<Double,Long> acc) {
return new Tuple2<>(sr.temperature+acc.f0,acc.f1+1);
}
//分区合并
@Override
public Tuple2<Double,Long> merge(
Tuple2<Double,Long> acc1,
Tuple2<Double,Long> acc2) {
return new Tuple2<>(acc1.f0+acc2.f0,acc1.f1+acc2.f1);
}
//返回每个传感器的平均温度
@Override
public Double getResult(Tuple2<Double,Long> t2) {
return t2.f0/t2.f1;
}
}
//窗口处理函数
public static class ProcessAvgTemp extends ProcessWindowFunction<
Double, //input type
Tuple3<String, Long, Double>, //output type
String, //key type
TimeWindow> { //window type
@Override
public void process(String id, //key
Context context,
Iterable<Double> events,
Collector<Tuple3<String, Long, Double>> out) {
double average = Math.round(events.iterator().next()*100) / 100.0;
out.collect(new Tuple3<>(id,context.window().getEnd(),average));
}
}
}对以上程序打 jar 包。在命令行下,执行的命令如下:
$ mvn clean package要执行作业,首先需要启动 Zookeeper 集群和 Kafka 服务,并创建主题 temp。请按以下步骤操作:
(1) 启动 zookeeper 服务,启动 kafka 服务。
打开一个终端窗口,启动 ZooKeeper(不要关闭),命令如下:
$ ./bin/zookeeper-server-start.sh config/zookeeper.properties打开另一个终端窗口,启动 Kafka 服务(不要关闭),命令如下:
$ ./bin/kafka-server-start.sh config/server.properties(2) 在 Kafka 中创建一个名为 temp 的主题(topic),命令如下:
$ ./bin/kafka-topics.sh --create --Bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic temp查看已经创建的 Topic,命令如下:
$ ./bin/kafka-topics.sh --list --Bootstrap-server localhost:9092要将作业提交到 Flink 集群上运行,请按以下步骤操作:
(1) 编写 Shell 脚本 streamiot.sh,读取每行 iot 数据,发送给 kafka 的 temp 主题,代码如下:
#!/bin/bash
BROKER=$1
if [ -z "$1" ]; then
BROKER="localhost:9092"
fi
cat sensortemp.csv | while read line; do
echo "$line"
sleep 0.1
done | ~/bigdata/kafka_2.12-2.4.1/bin/kafka-console-producer.sh --broker-list $BROKER --topic temp注意/
streamiot.sh 脚本应该具有可执行权限。如果没有,使用以下命令添加执行权限:$ chmod a+x streamiot.sh
(2)然后执行脚本 streamiot.sh,命令如下:
$ ./streamiot.sh localhost:9092(3) 提交程序 jar 包到集群上运行,抓取 kafka 的 temp 主题中消息,并输出在控制台,命令如下:
$ cd ~/bigdata/flink-1.13.2/
$ ./bin/flink run --class com.xueai8.java.ch03.StreamingJob ~/flinkdemos/FlinkJavaDemo-1.0-SNAPSHOT.jar当提交作业到 Flink 集群上运行时,标准输出其实是到了 flink-hduser-taskexecutor-0-localhost.out 文件中去了,因此要查看此结果,需要查看该文件才是。使用 kafka 消费者脚本测试 kafka 中主题内容,命令如下:
$ ./bin/kafka-console-consumer.sh --Bootstrap-server localhost:9092 --topic temp --consumer-property group.id=test观察到输出结果如下:
2> (sensor_2,1629943900000,107.4)
7> (sensor_7,1629943900000,66.11)
1> (sensor_0,1629943900000,52.86)
8> (sensor_9,1629943900000,71.53)
3> (sensor_8,1629943900000,93.09)
1> (sensor_3,1629943900000,57.93)
7> (sensor_4,1629943900000,96.48)
5> (sensor_1,1629943900000,51.64)
6> (sensor_5,1629943900000,92.0)
1> (sensor_0,1629943905000,50.59)
3> (sensor_8,1629943905000,91.96)
8> (sensor_9,1629943905000,71.15)
2> (sensor_2,1629943905000,107.48)
3> (sensor_8,1629943910000,91.13)
1> (sensor_3,1629943905000,60.1)
6> (sensor_6,1629943900000,96.08)
7> (sensor_7,1629943905000,64.93)
5> (sensor_1,1629943905000,53.84)
2> (sensor_2,1629943910000,109.88)
3> (sensor_8,1629943915000,94.77)
1> (sensor_3,1629943910000,62.18)
5> (sensor_1,1629943910000,59.87)
7> (sensor_4,1629943905000,97.99)
5> (sensor_1,1629943915000,63.32)
6> (sensor_6,1629943905000,95.86)
8> (sensor_9,1629943910000,71.55)
7> (sensor_7,1629943910000,67.59)
1> (sensor_0,1629943910000,50.96)
2> (sensor_2,1629943915000,105.35)
7> (sensor_4,1629943910000,100.87)
8> (sensor_9,1629943915000,75.48)
6> (sensor_5,1629943905000,91.47)
7> (sensor_7,1629943915000,69.73)
1> (sensor_0,1629943915000,51.91)
...

- 点赞
- 收藏
- 关注作者
评论(0)