Elasticsearch 搜索测试与集成Springboot3

👏 Hi! 我是 Yumuing,一个技术的敲钟人
👨💻 每天分享技术文章,永远做技术的朝拜者
📚 欢迎关注我的博客:Yumuing’s blog
Elasticsearch是专门做搜索的,它非常擅长以下方面的问题
- Elasticsearch对模糊搜索非常擅长(搜索速度很快)
- 从Elasticsearch搜索到的数据可以根据评分过滤掉大部分的,只要返回评分高的给用户就好了(原生就支持排序)
- 没有那么准确的关键字也能搜出相关的结果(能匹配有相关性的记录)
它能够一定程度上解决,在一个普通数据库处理上亿条数据时的查询效率低下的同时无法优秀地排列好用户所需要的数据,一次性上亿条数据没有经过正确地排列,用户很难找到想要的数据。并且,用户输入的数据可能不太准确,它也能够进行模糊查询,这种模糊查询是依靠计算得来的,而不是简单地匹配数据。本系列博文将从零开始一步步实现将 ES 集成到 springboot3 中,并在一个社区项目中进行实际应用测试,本文为系列第一篇,后续,博文仍在整理,请持续关注博主,了解更多相关知识。
@[toc]
本文将在以下环境进行测试:
- window11
- SpringBoot:3.0.2
- Elasticsearch:8.5.0
- elasticsearch-analysis-ik:8.5.0
- Kibana:8.5.0
搭建 Elasticsearch 服务器以及分词扩展
先从 Elasticsearch 官网下载:Elasticsearch 8.5.0 | Elastic 该版本,再去 Github 下载分词器扩展:Release v8.5.0 · medcl/elasticsearch-analysis-ik (github.com) 下载完成之后,分别进行解压缩,注意后者(ik)必须解压缩在前者(Elasticsearch)解压后的 plugins 中的 ik 目录下,如下:
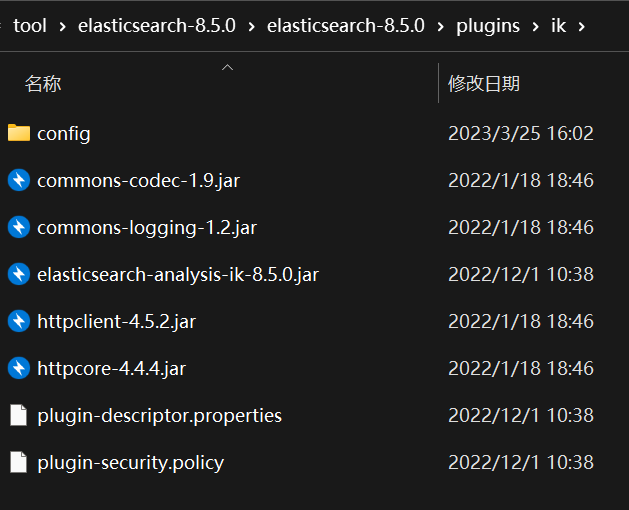
进入 config 目录下,我们可以看到几个配置文件:
- extra_main.dic:中文分词词典,词语,例如:皇帝
- extra_stopword.dic:中文停止词词典,结束词:也、了
- IKAnalyzer.cfg.xml:配置额外词典文件
如果需要自定义词典,在 config 目录下自定义一个英文名称的以 dic 结尾的文件,里面填入自定义词,一行一个,之后从 IKAnalyzer.cfg.xml 配置自定义词典即可生效。配置方法就是在指定位置填入对应词库名称加后缀,远程需要添加 url,并以 dic 结尾,获取到的也必须是一行一个分词。该 url 也需要返回两个头部(header),一个是Last-Modified,一个是ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。远程更新不需要重启服务器,本地词库文件更新需要重启服务器。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
完成这些之后,我们就来配置一下 Elasticsearch 的环境变量以及本地服务器名称、数据、日志的保存路径。在系统变量处添加你解压缩的 Elasticsearch 对应的 bin 目录。在 elasticsearch-8.5.0 下找到 config 中的 elasticsearch.yml 文件,这就是配置文件,需要更改的就以下三个位置:17行、33行、37行,注意把这三行前面的 “#” 去掉。
cluster.name: yumuing
path.data: C:\tool\elasticsearch-8.5.0\data
path.logs: C:\tool\elasticsearch-8.5.0\data\logs
配置完这些之后,就可以在其 bin 目录下,找到 elasticsearch.bat 文件,双击启动即可,等待出现如下即为启动成功,第一次启动较慢,耐心等待:
注意不要使用管理员权限启动,会启动卡住,一直不动。

如果还是卡住不动,可以尝试在 config 目录下找到 elasticsearch.yml 增加以下代码,关闭geoip数据库的更新。
ingest.geoip.downloader.enabled: false
如果,自身内存少于 16 g ,建议将 config 目录下的 jvm.options 申请内容配置修改为如下,注意删除最前面的 “##”,将初始内存改为 256m,最大内存修改为 512m。
-Xms512m
-Xmx1g
使用第一次运行 Elasticsearch 时 会自动进行安全配置,会在控制台输出账号密码,如下:
-> Password for the elastic user (reset with `bin/elasticsearch-reset-password -u elastic`):
RGiwCn4abvxC4CYHNqvU
默认账号为:elastic
如果你忘记了账户密码,可以到你上面设置的 logs 目录寻找关键词:password,如果实在找不到的话,可以在 bin 目录下调取 cmd 命令行,输入:elasticsearch-reset-password -u elastic ,稍等一会就会输出密码。如果还不能输出密码,可以尝试在 elasticsearch.yml 输入以下代码
discovery.type: single-node
设置为单节点应用,在尝试输入:elasticsearch-reset-password -u elastic 修改密码。
默认端口号为 9200 ,打开 cmd 命令窗口,输入
curl -u <用户名>:<密码> -X GET "localhost:9200/_cat/health"
检查服务状态,为 green 即可开始尝试使用了。返回的 json 如下:
{
"cluster_name":"yumuing",
"status":"green",
"timed_out":false,
"number_of_nodes":1,
"number_of_data_nodes":1,
"active_primary_shards":1,
"active_shards":1,
"relocating_shards":0,
"initializing_shards":0,
"unassigned_shards":0,
"delayed_unassigned_shards":0,
"number_of_pending_tasks":0,
"number_of_in_flight_fetch":0,
"task_max_waiting_in_queue_millis":0,
"active_shards_percent_as_number":100
}
当然,在控制台中没有进行格式美化,是一长串,注意一下。
如果不想要安全认证的话,可以添加以下代码到 elasticsearch.yml 中
xpack.security.enabled: false
输入:
curl -X GET "localhost:9200/_cat/health"
即可得到健康状态。
常见 http 命令
索引在 MySql 中代表数据库,文档代表一行数据,字段代表一列数据。
添加索引:put 请求
localhost:9200/test
查询索引:get 请求
localhost:9200/_cat/indices
删除索引:delete 请求
localhost:9200/test
插入文档:put 请求,也可作为更新数据,如有相同值文档,会先删除再增加,变相地更新
localhost:9200/test/_doc/{id}
并提交对应的 json 数据,如下:
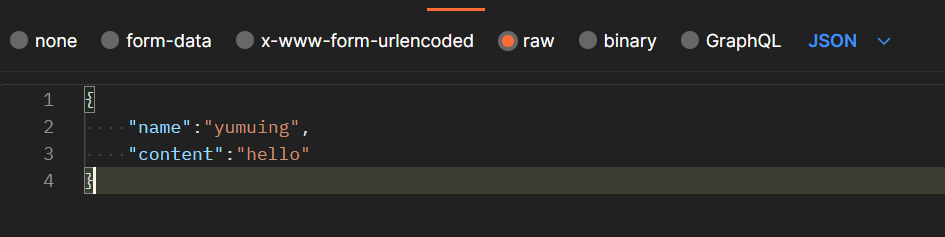
获得回复:本次请求中 id 值设为 1,类型在版本8.5.0已被舍弃,故没有 _type 字段。但 _doc 还是得保留在请求中。“result”: “created”,
{
"_index": "test",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
更新文档的回复:“result”: “updated”,
{
"_index": "test",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}
查询文档:get请求, _source 即为文档数据
localhost:9200/test/_doc/{id}
{
"_index": "test",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"name": "yumuing",
"content": "hello"
}
}
或者查询不到数据: “found”: false
{
"_index": "test",
"_id": "1",
"found": false
}
删除文档:delete 请求
localhost:9200/test/_doc/{id}
返回数据:“result”: “deleted”
{
"_index": "test",
"_id": "1",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
搜索所有数据:get请求 “hits”: 为所有数据, “value”: 3:搜索到多少条数据
localhost:9200/{索引}/_search
回复:
{
"took": 809,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "test",
"_id": "1",
"_score": 1.0,
"_source": {
"title": "test",
"content": "测试一下"
}
},
{
"_index": "test",
"_id": "3",
"_score": 1.0,
"_source": {
"title": "test",
"content": "测试2"
}
},
{
"_index": "test",
"_id": "2",
"_score": 1.0,
"_source": {
"title": "test",
"content": "测试3"
}
}
]
}
}
搜索单一特定内容:get 请求,内容无需双引号,搜索时,会自动提取内容中的词组再分别搜索包含对应词组的文档,多少个词组就有多少个搜索条件。就像运营实习,会被分为三个词组去搜索,一个是运营实习,一个是运营,一个是实习。
localhost:9200/{索引}/_search?q=字段名:内容
返回数据与搜索全部数据类似,就不展示了。
搜索多个字段内容:get 请求,携带 json
“query”:“搜索关键词”
“fields”:[“字段1”,“字段2”]
{
"query":{
"multi_match":{
"query":"2",
"fields":["title","content"]
}
}
}
返回数据与其他搜索数据类似不展示。
当然,es 的搜索语法并不只有这些,还有很多,建议查看官方文档,本文仅对 es 做简单介绍,下文将介绍如何集成进 springboot中,并进行实际应用。

图形化界面
一、Kibana是什么
Kibana 是为 Elasticsearch设计的开源分析和可视化平台。你可以使用 Kibana 来搜索,查看存储在 Elasticsearch 索引中的数据并与之交互。你可以很容易实现高级的数据分析和可视化,以图表的形式展现出来。
使用前我们肯定需要先有Elasticsearch啦,安装使用Elasticsearch可以参考Elasticsearch构建全文搜索系统
下面分别演示一下Kibana的安装、自定义索引,搜索,控制台调用es的api和可视化等操作,特别需要注意的是,控制台可以非常方便的来调用es的api,强烈推荐使用
二、如何安装
直接下载对应平台的版本就可以,参考地址Installing Kibana
这里我直接下载了 windows 平台的 Kibana 8.5.0 | Elastic
配置可以参考Configring Kibana
设置监听端口号、es地址、索引名

默认情况下,kibana启动时将生成随机密钥,这可能导致重新启动后失败,需要配置多个实例中有相同的密钥
设置
xpack.reporting.encryptionKey: "chenqionghe"
xpack.security.encryptionKey: "122333444455555666666777777788888888"
xpack.encryptedSavedObjects.encryptionKey: "122333444455555666666777777788888888"
启动
./bin/kibana
打开http://localhost:5601,画风如下
提示我们可以使用示例数据,也可以使用自己已有的数据,我把示例数据都下载了,单击侧面导航中的 Discover 进入 Kibana 的数据探索功能:
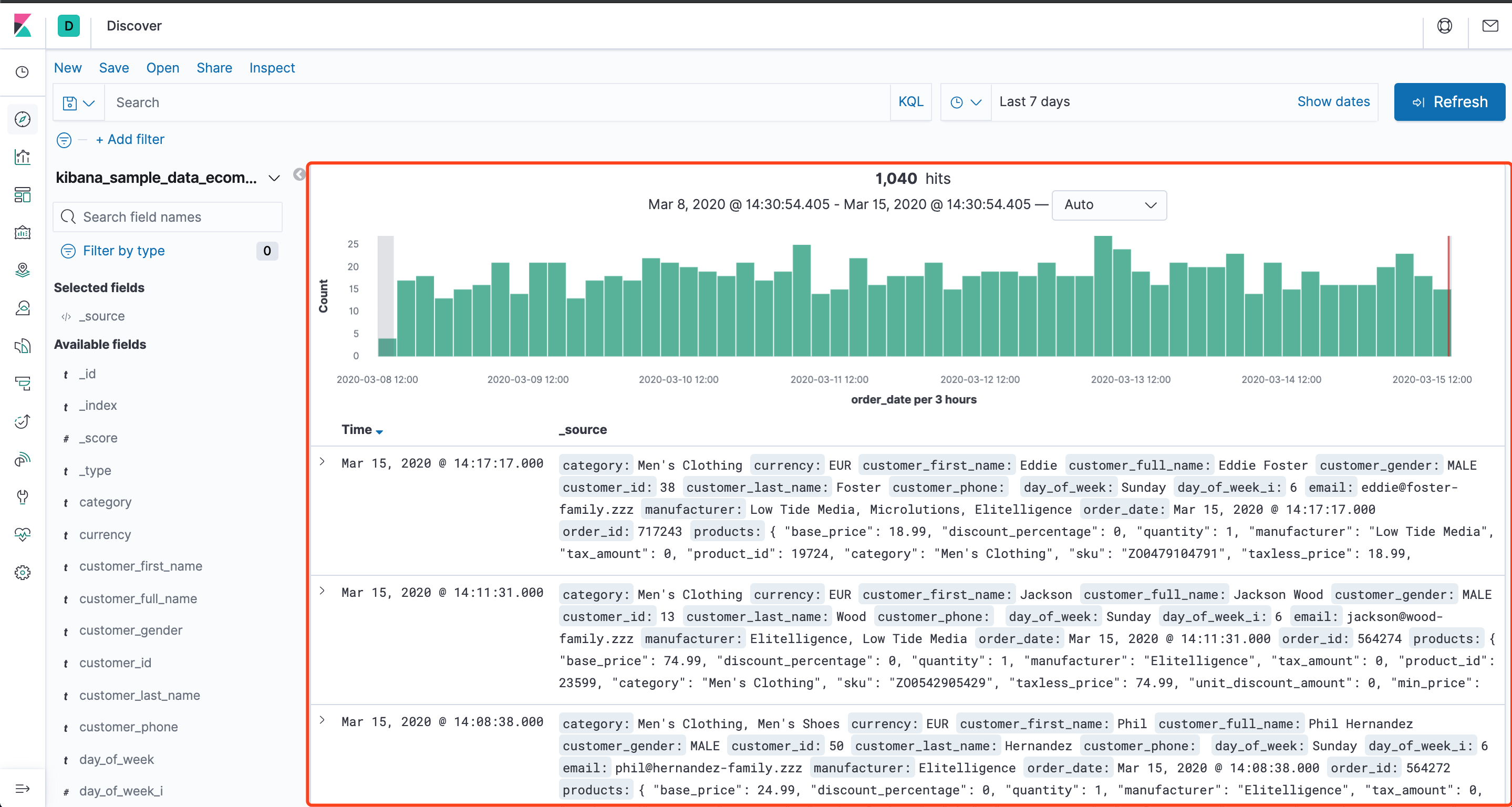
可以看到数据已经导入了,我们可以直接使用查询栏编写语句查询
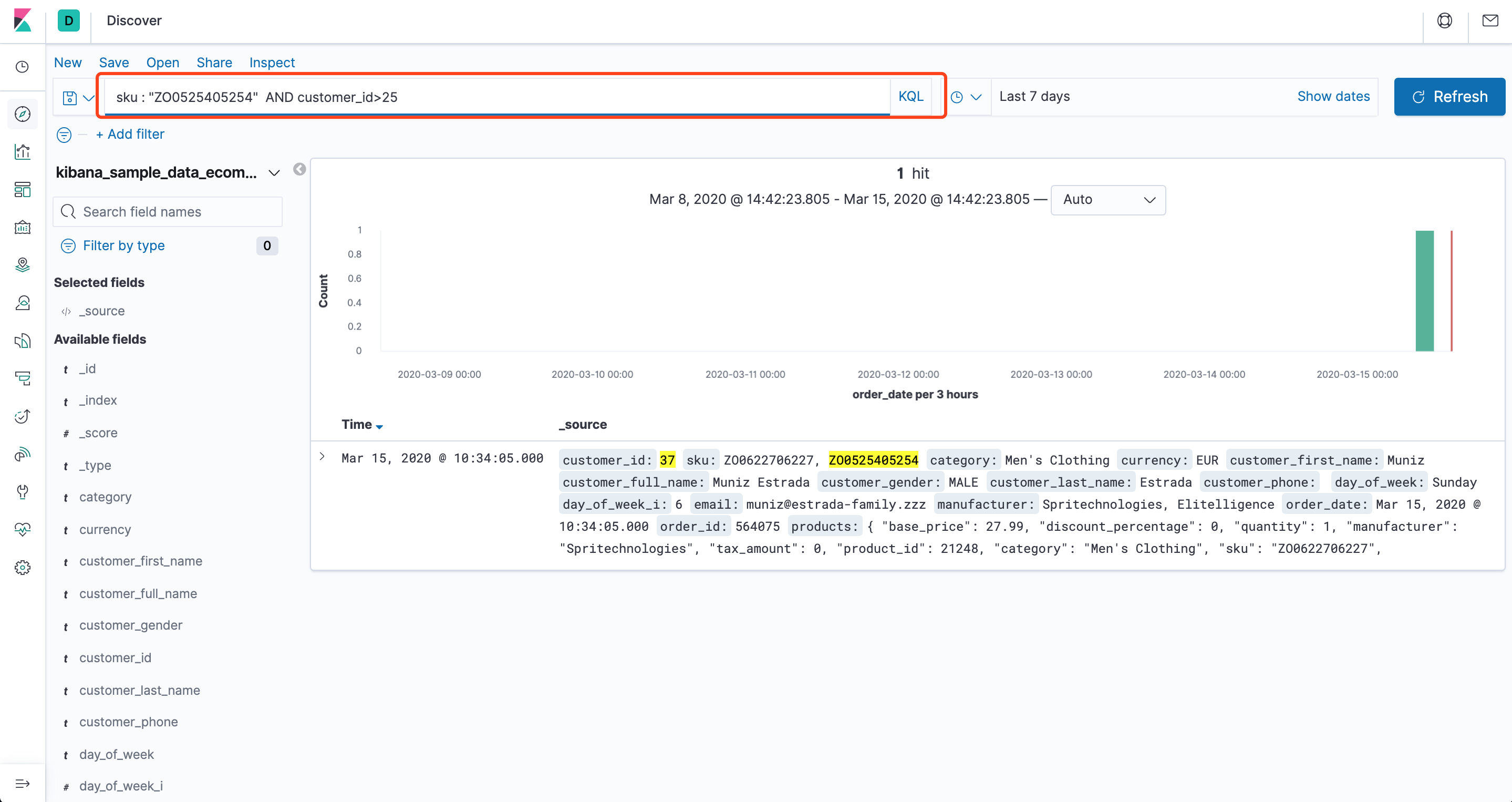
三、如何加载自定义索引
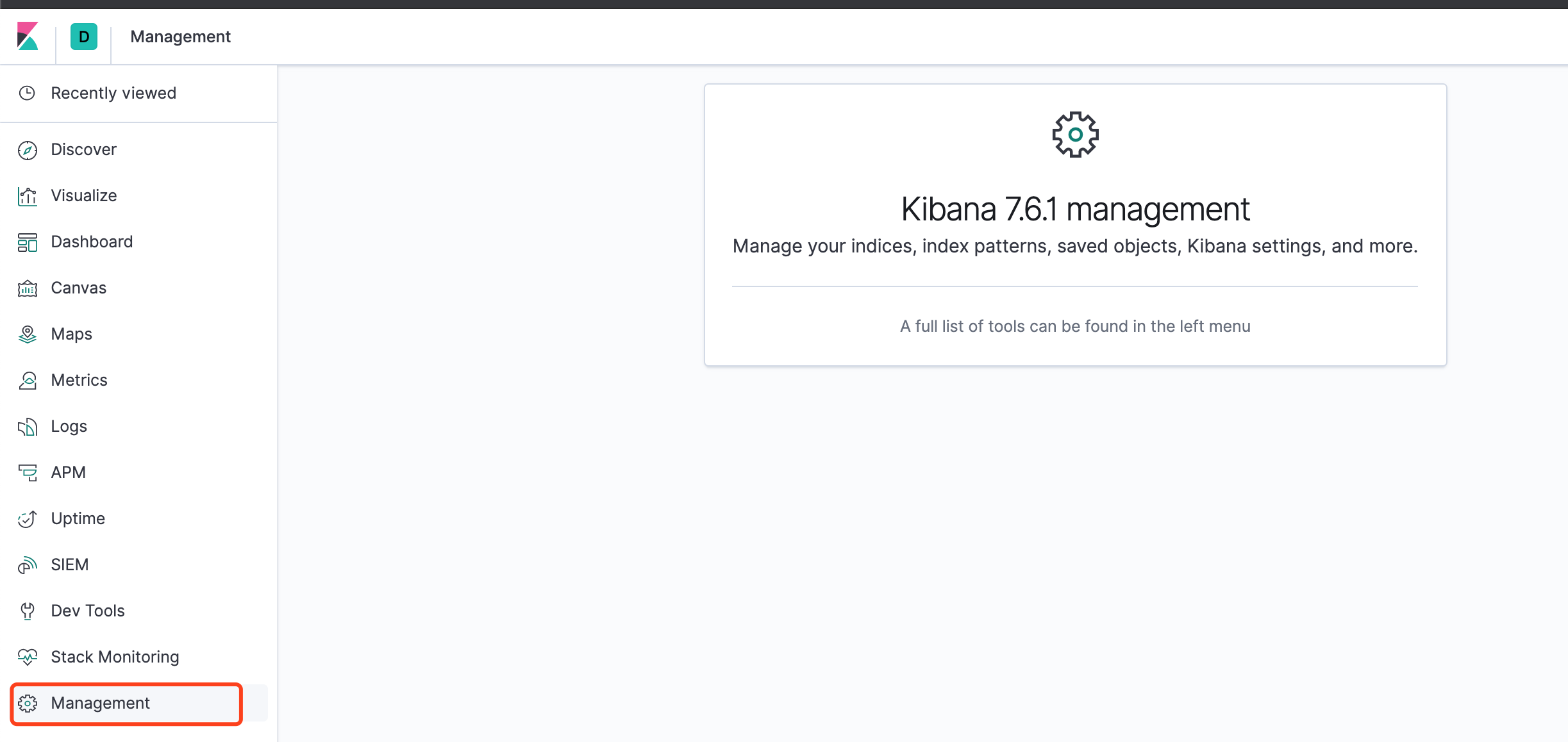
接下来演示加载已经创建book索引
单击 Management 选项
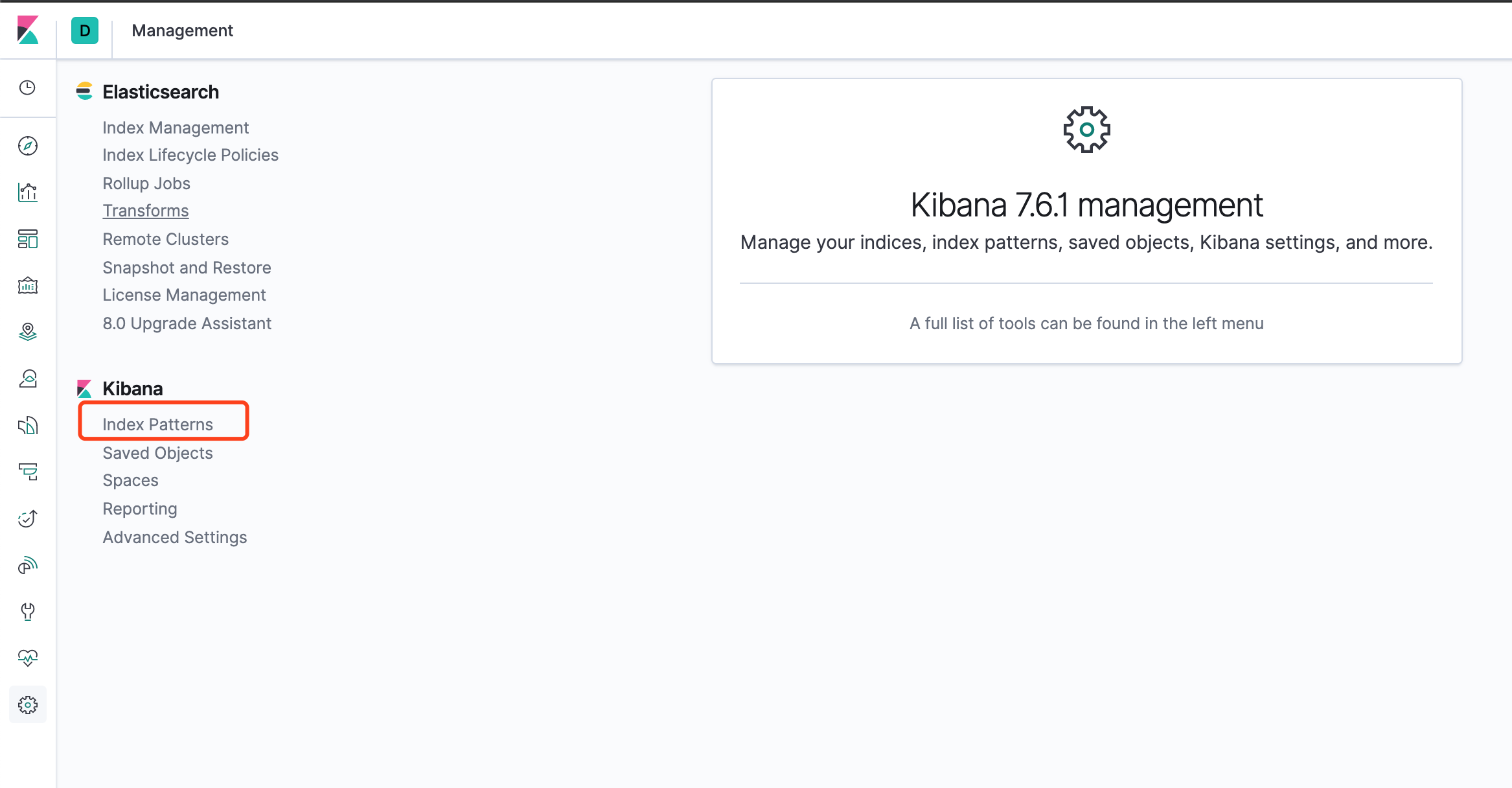
然后单击 Index Patterns 选项。
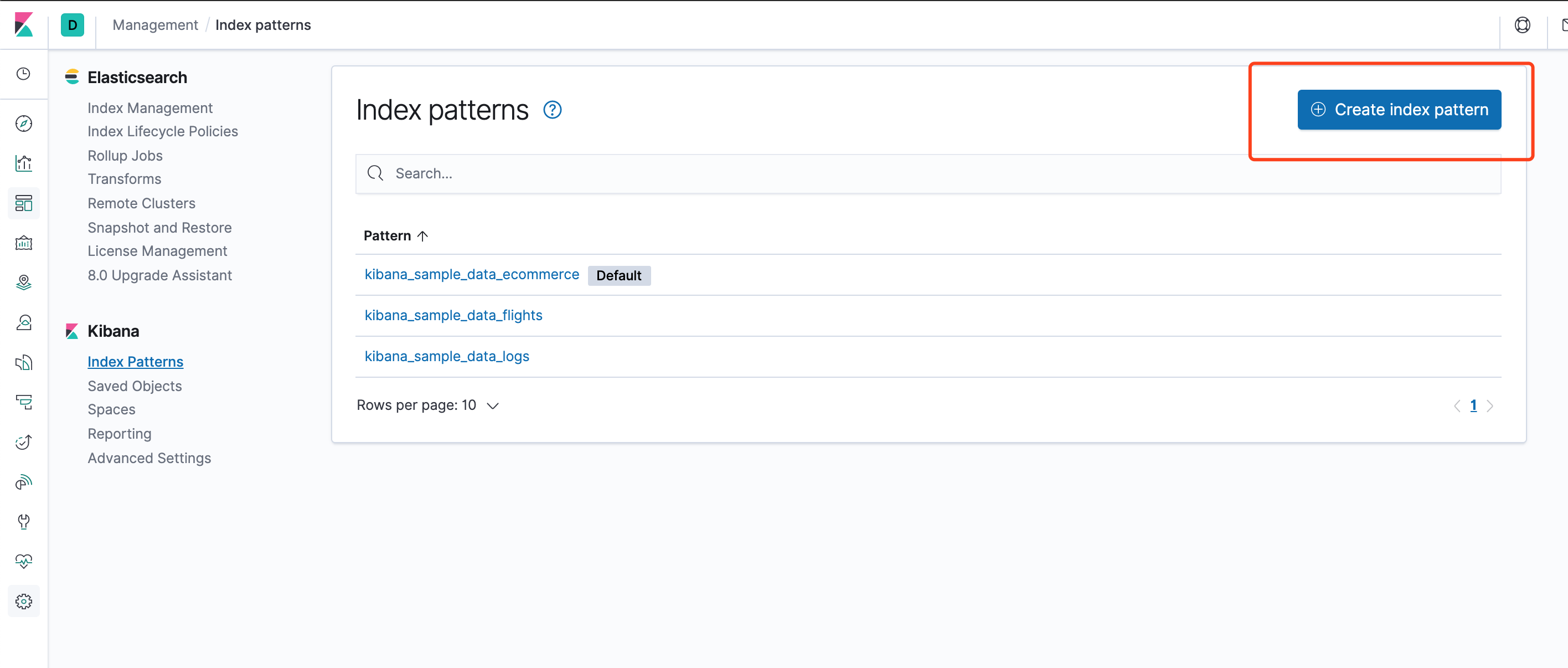
点击Create index pattern定义一个新的索引模式。
点击Next step
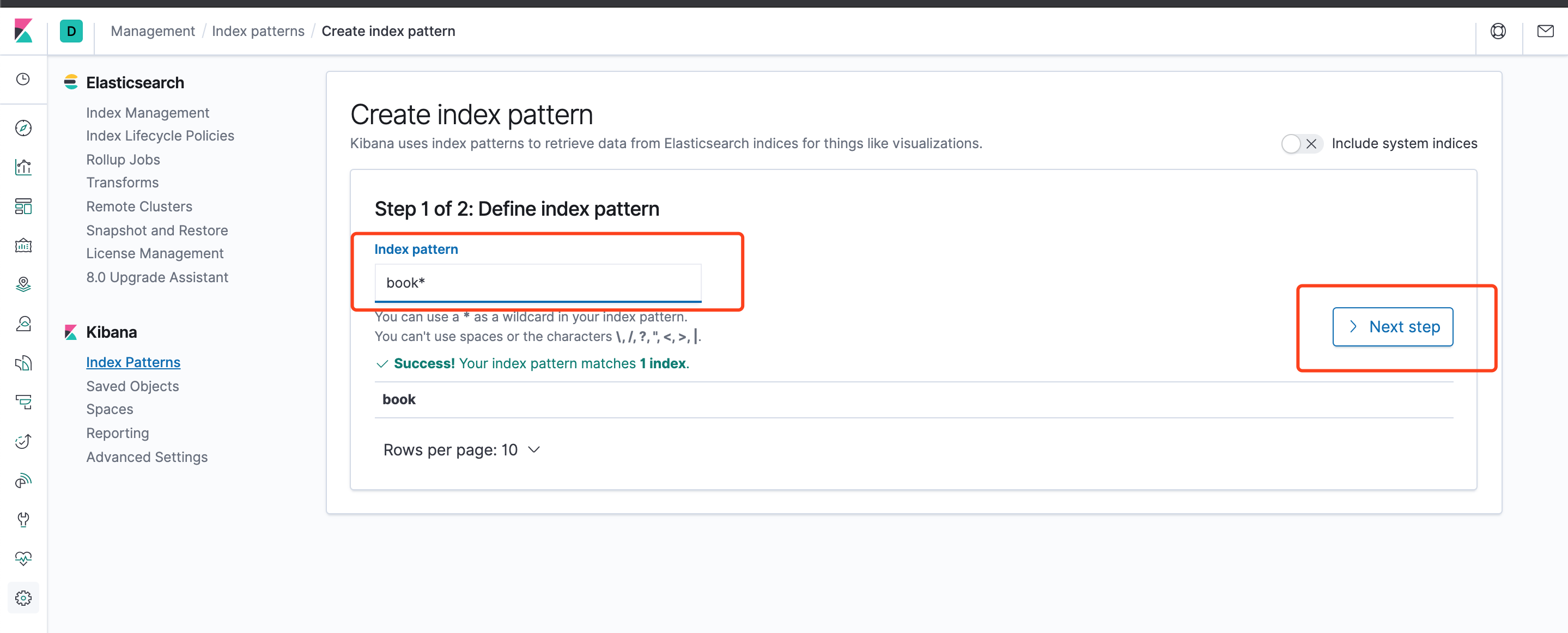
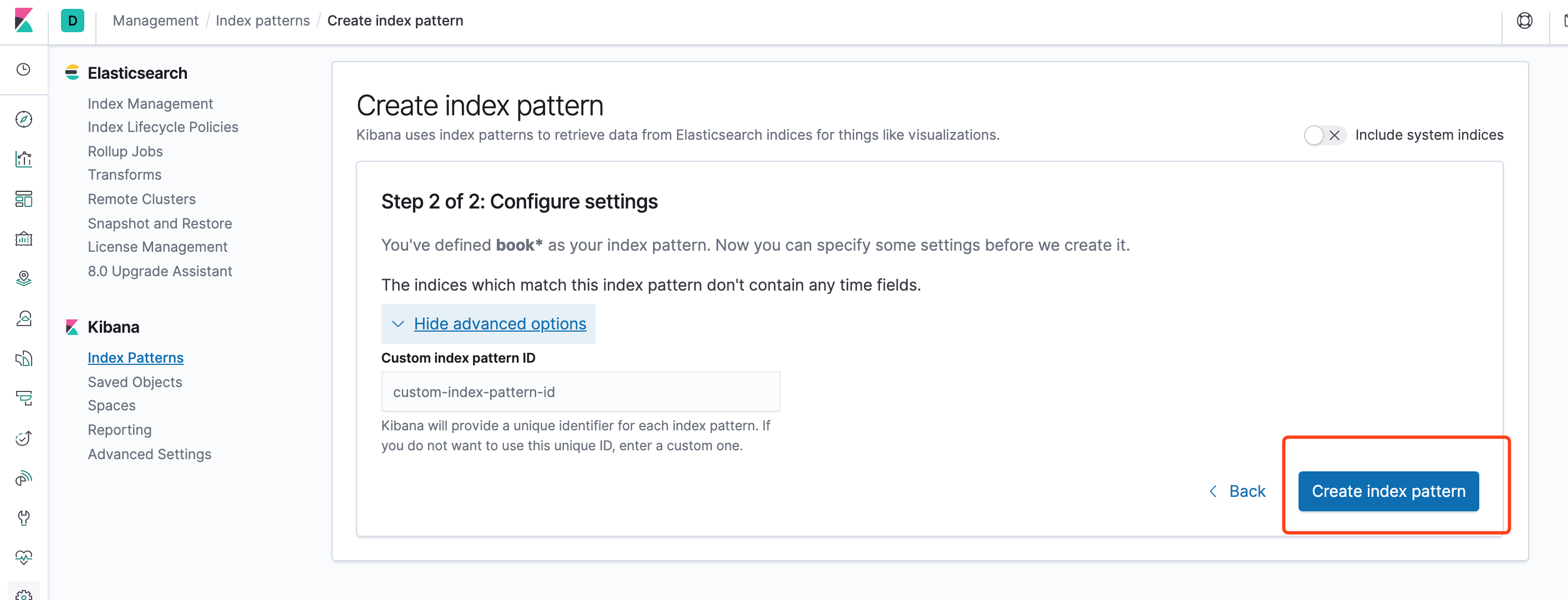
点击Create index pattern
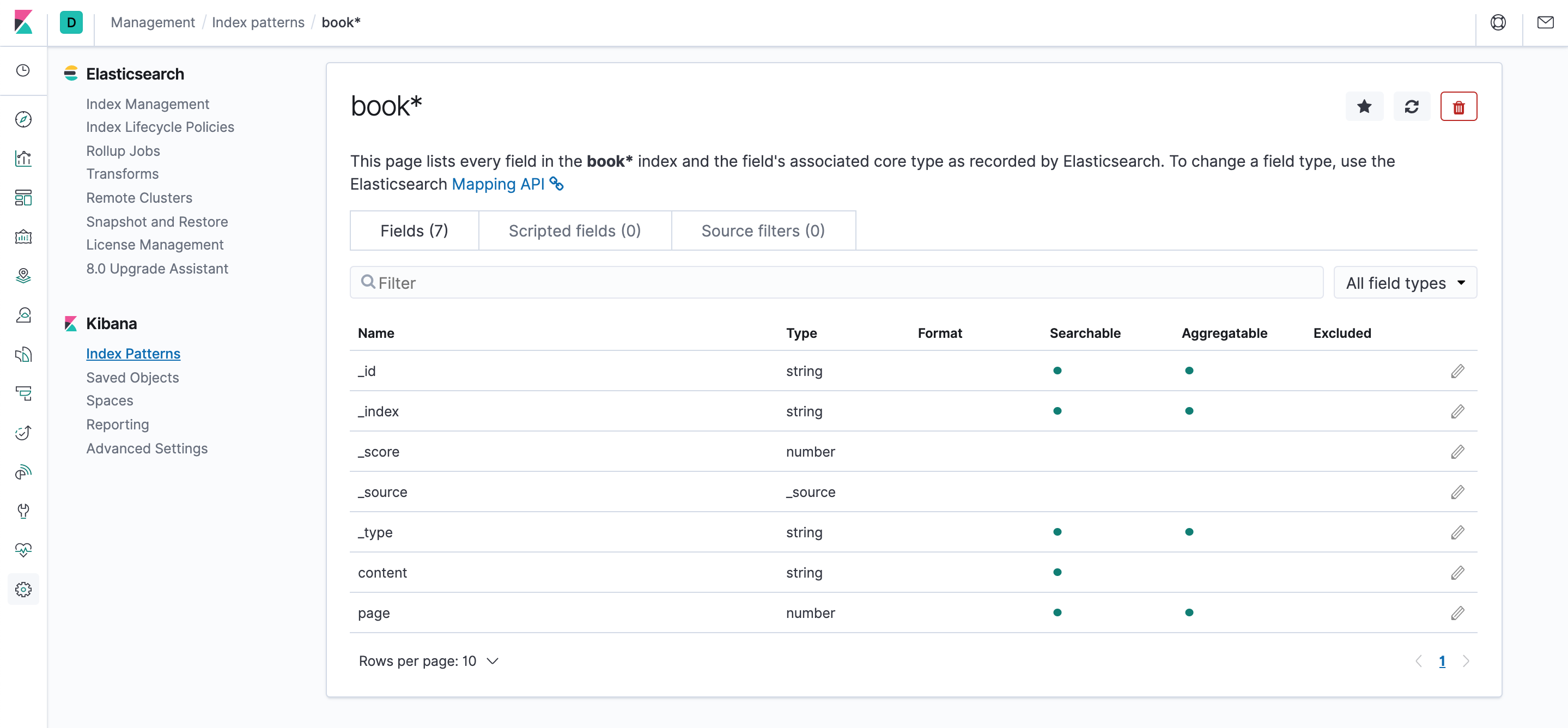
出来如下界面,列出了所有index中的字段
接下来,我们再来使用一下kibana查看已经导入的索引数据
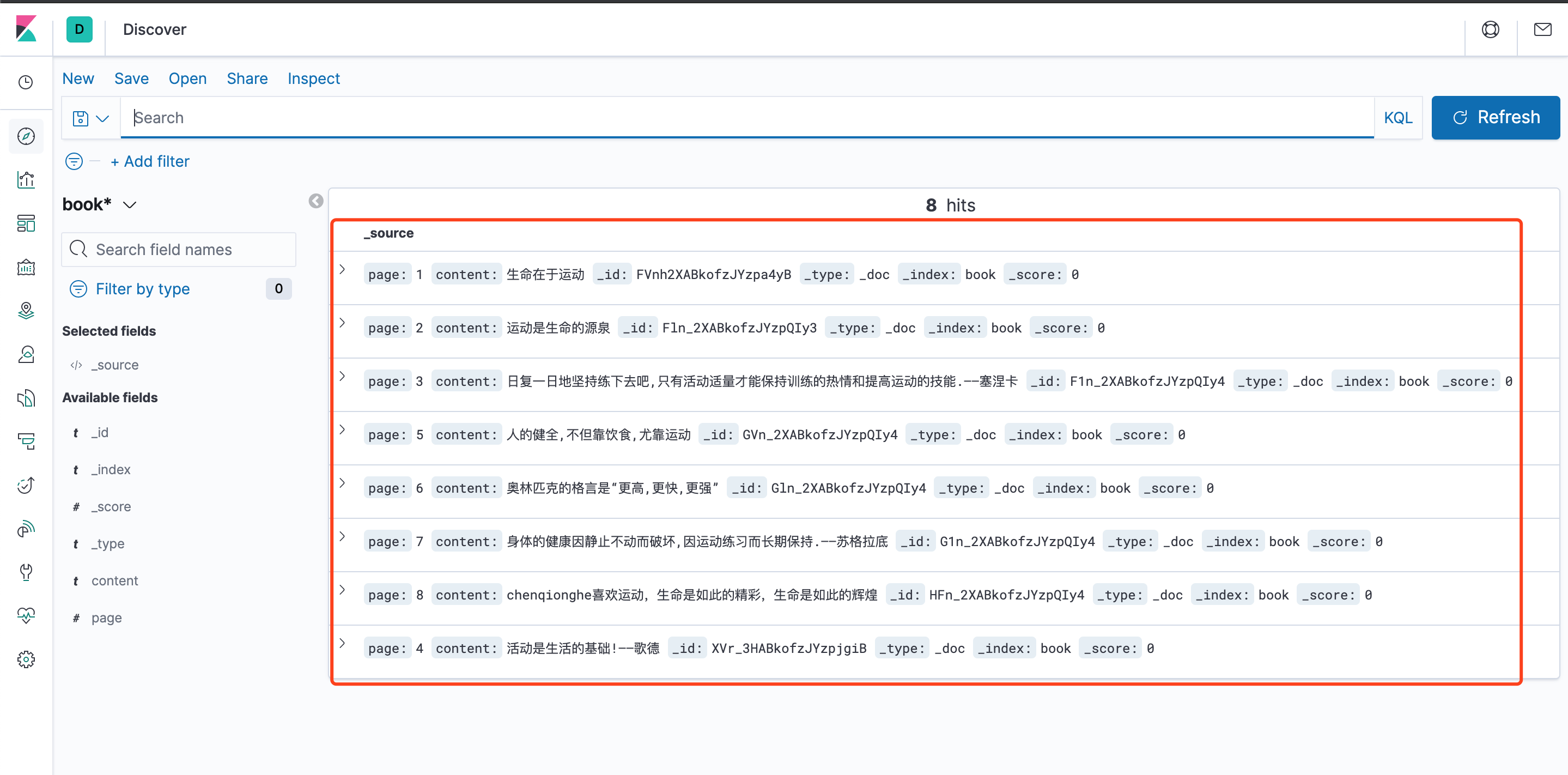
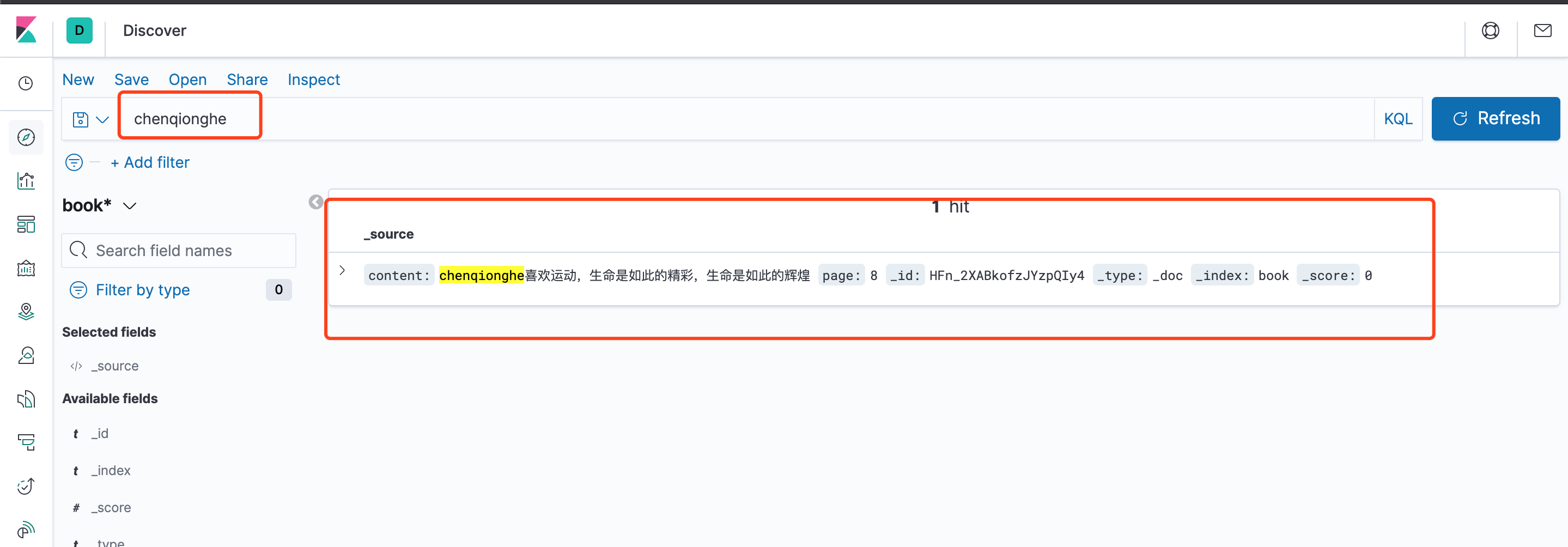
可以看到,已经能展示和检索出我们之前导入的数据,奥利给!
四、如何搜索数据
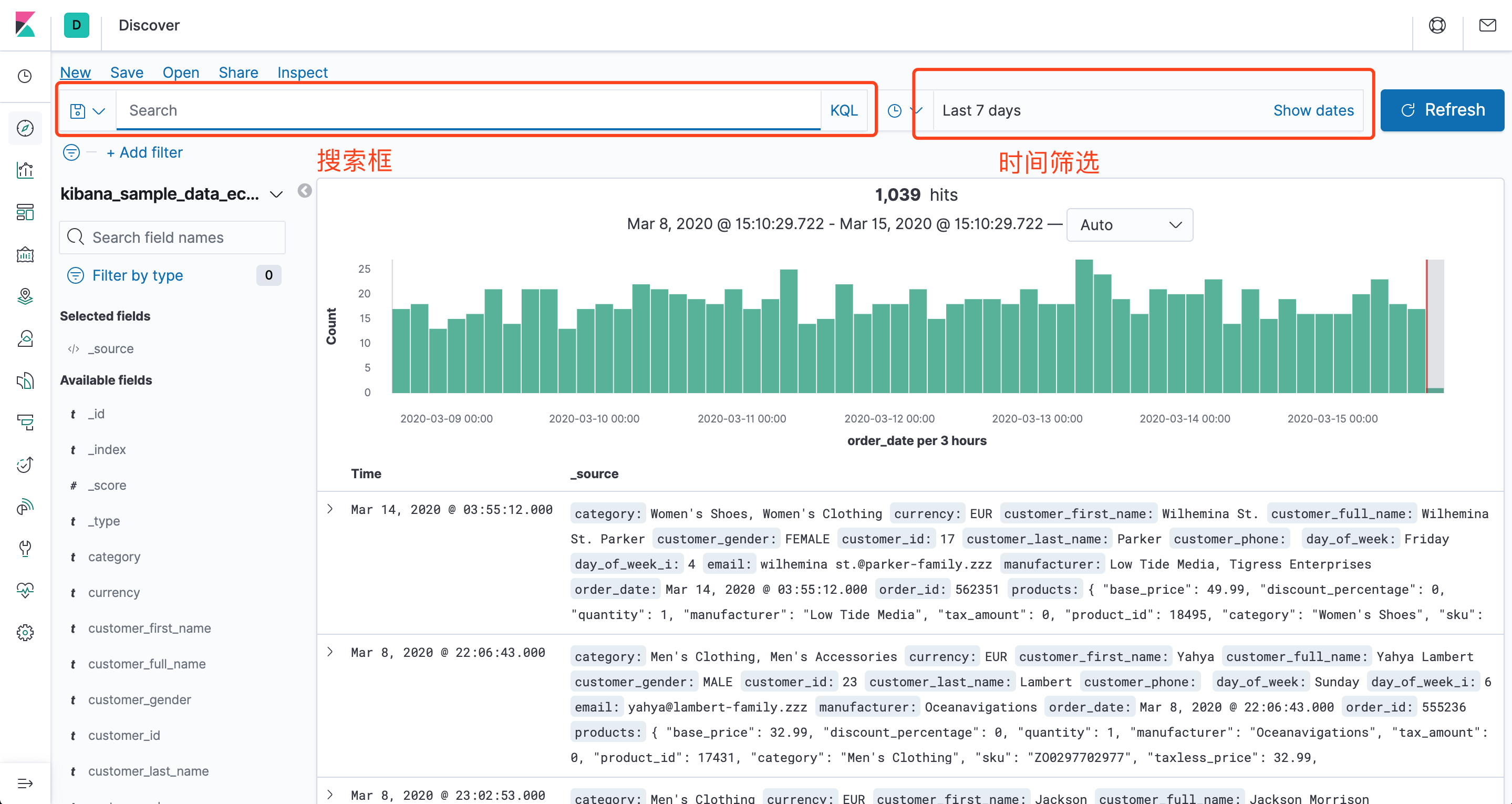
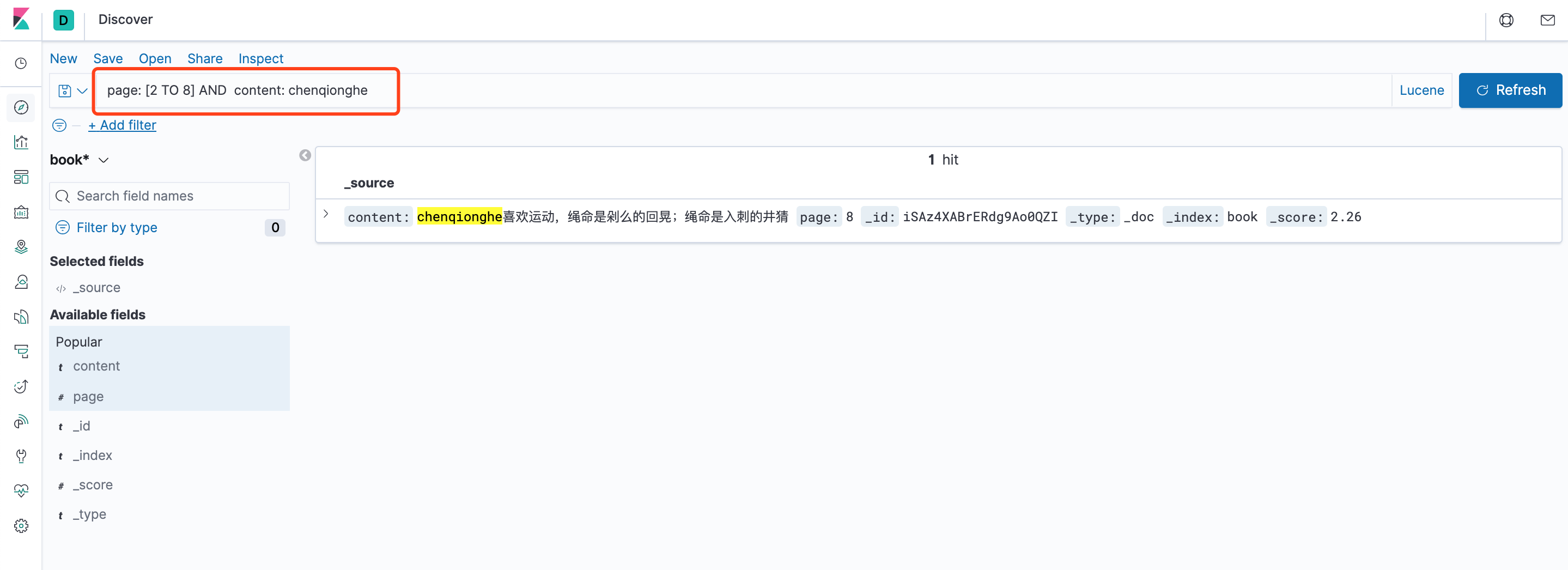
可以看到,我们能很方便地搜索栏使用Llucene查询,查询语法可以参考Lucene查询语法汇总
五、如何切换中文
在config/kibana.yml添加
i18n.locale: "zh-CN"
重新启动,即可生效
六、如何使用控制台
控制台插件提供一个用户界面来和 Elasticsearch 的 REST API 交互。控制台有两个主要部分: editor ,用来编写提交给 Elasticsearch 的请求; response 面板,用来展示请求结果的响应。在页面顶部的文本框中输入 Elasticsearch 服务器的地址。默认地址是:“localhost:9200”。
点击左侧栏的[Dev Tools],可以看到如下界面,可以很方便地执行命令
示例操作
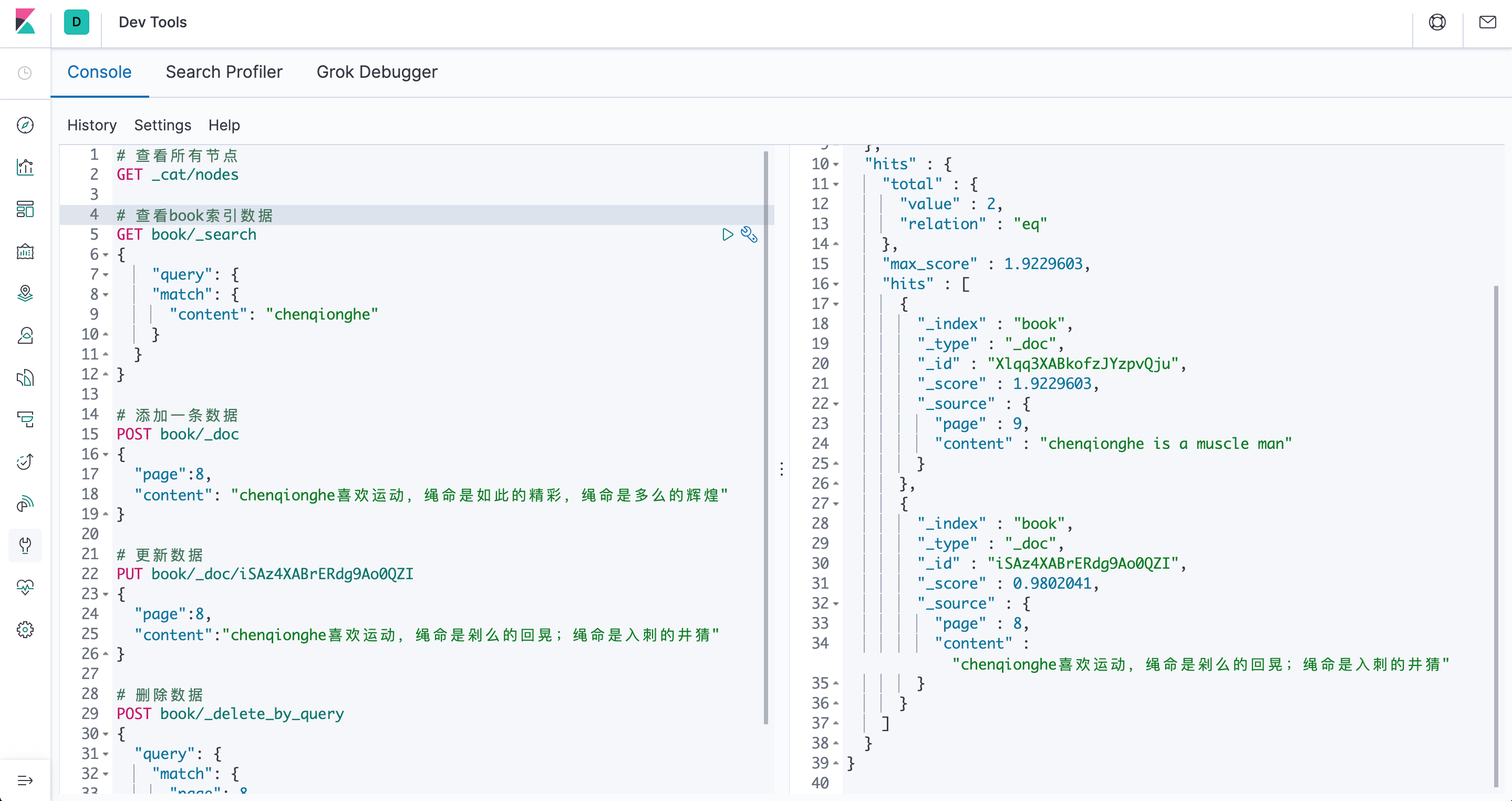
# 查看所有节点
GET _cat/nodes
# 查看book索引数据
GET book/_search
{
"query": {
"match": {
"content": "chenqionghe"
}
}
}
# 添加一条数据
POST book/_doc
{
"page":8,
"content": "chenqionghe喜欢运动,绳命是如此的精彩,绳命是多么的辉煌"
}
# 更新数据
PUT book/_doc/iSAz4XABrERdg9Ao0QZI
{
"page":8,
"content":"chenqionghe喜欢运动,绳命是剁么的回晃;绳命是入刺的井猜"
}
# 删除数据
POST book/_delete_by_query
{
"query": {
"match": {
"page": 8
}
}
}
# 批量插入数据
POST book/_bulk
{ "index":{} }
{ "page":22 , "content": "Adversity, steeling will strengthen body.逆境磨练意志,锻炼增强体魄。"}
{ "index":{} }
{ "page":23 , "content": "Reading is to the mind, such as exercise is to the body.读书之于头脑,好比运动之于身体。"}
{ "index":{} }
{ "page":24 , "content": "Years make you old, anti-aging.岁月催人老,运动抗衰老。"}
{ "index":{} }
七、如何使用可视化
Kibana可视化控件基于 Elasticsearch 的查询。利用一系列的 Elasticsearch 查询聚合功能来提取和处理数据,再通过创建图表来呈现数据分布和趋势
点击Visualize菜单,进入可视化图表创建界面,Kibana自带有上10种图表,我们来创建一个自己的图表
我们来添加一个直方图
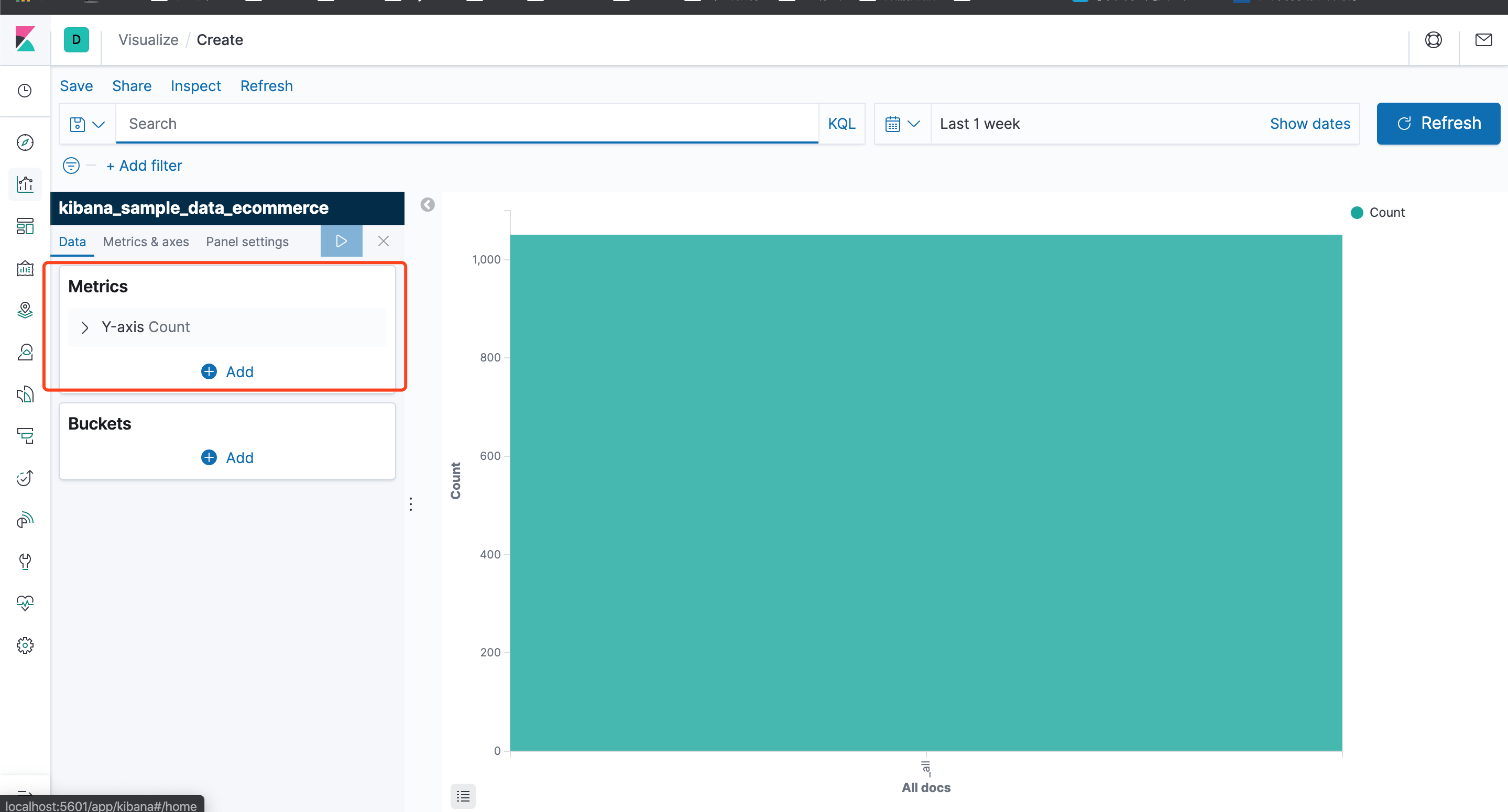
可以看到,默认已经有一个Y轴了,统计的是数量,我们添加一个X轴,点击Buckets下的Add

如下,我选择了customer_id字段作为x轴
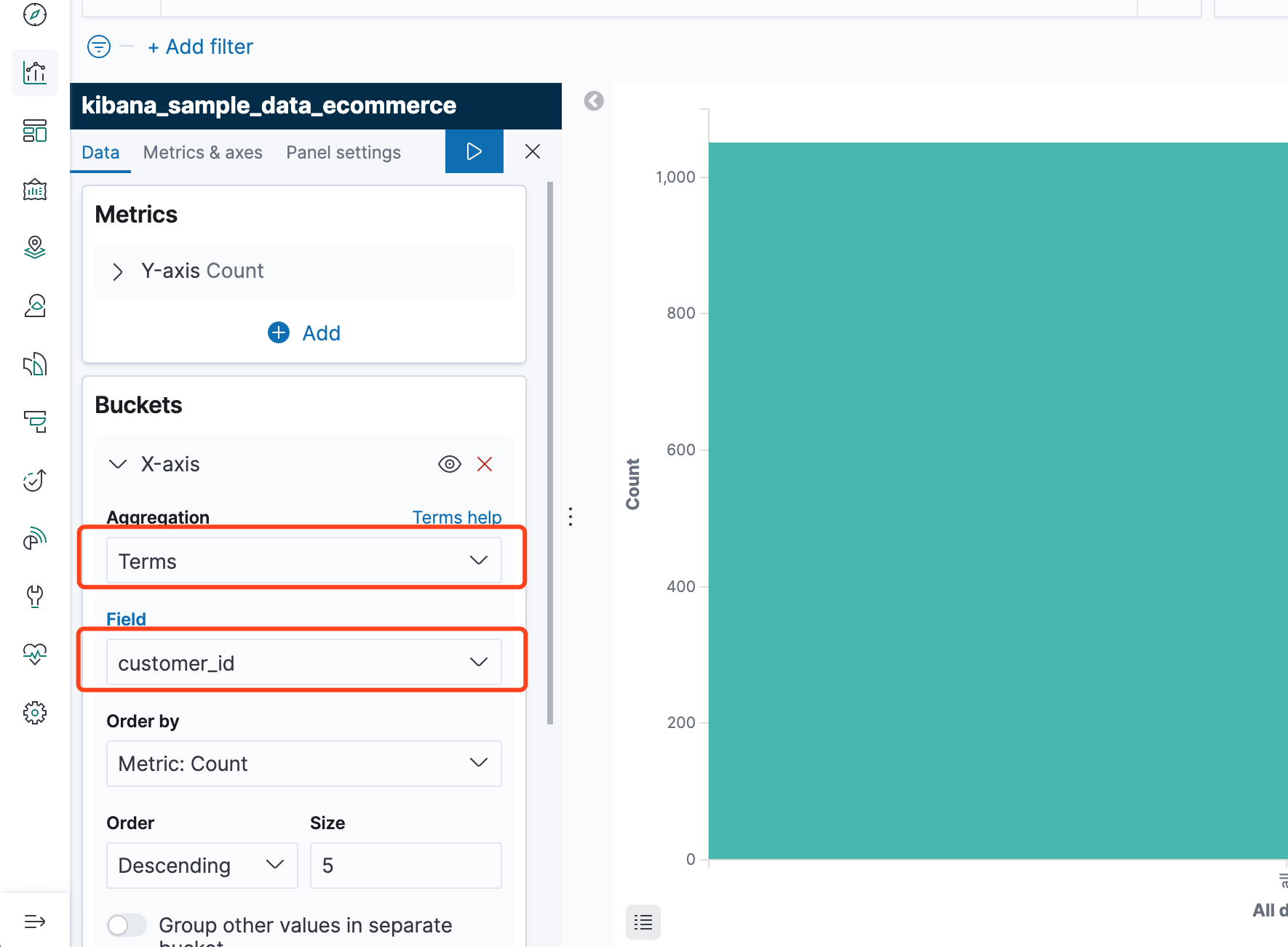
执行后如下
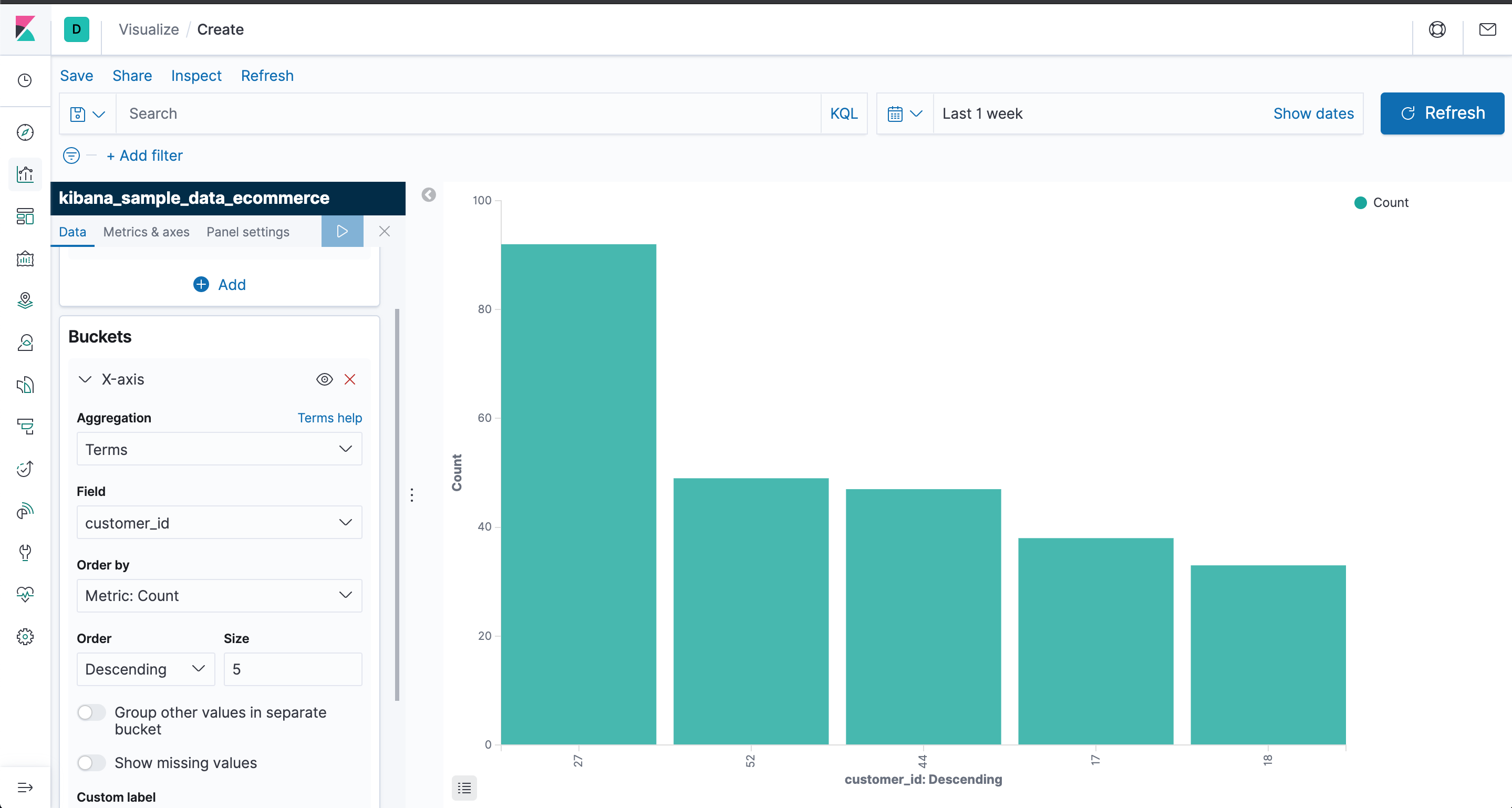
保存一下
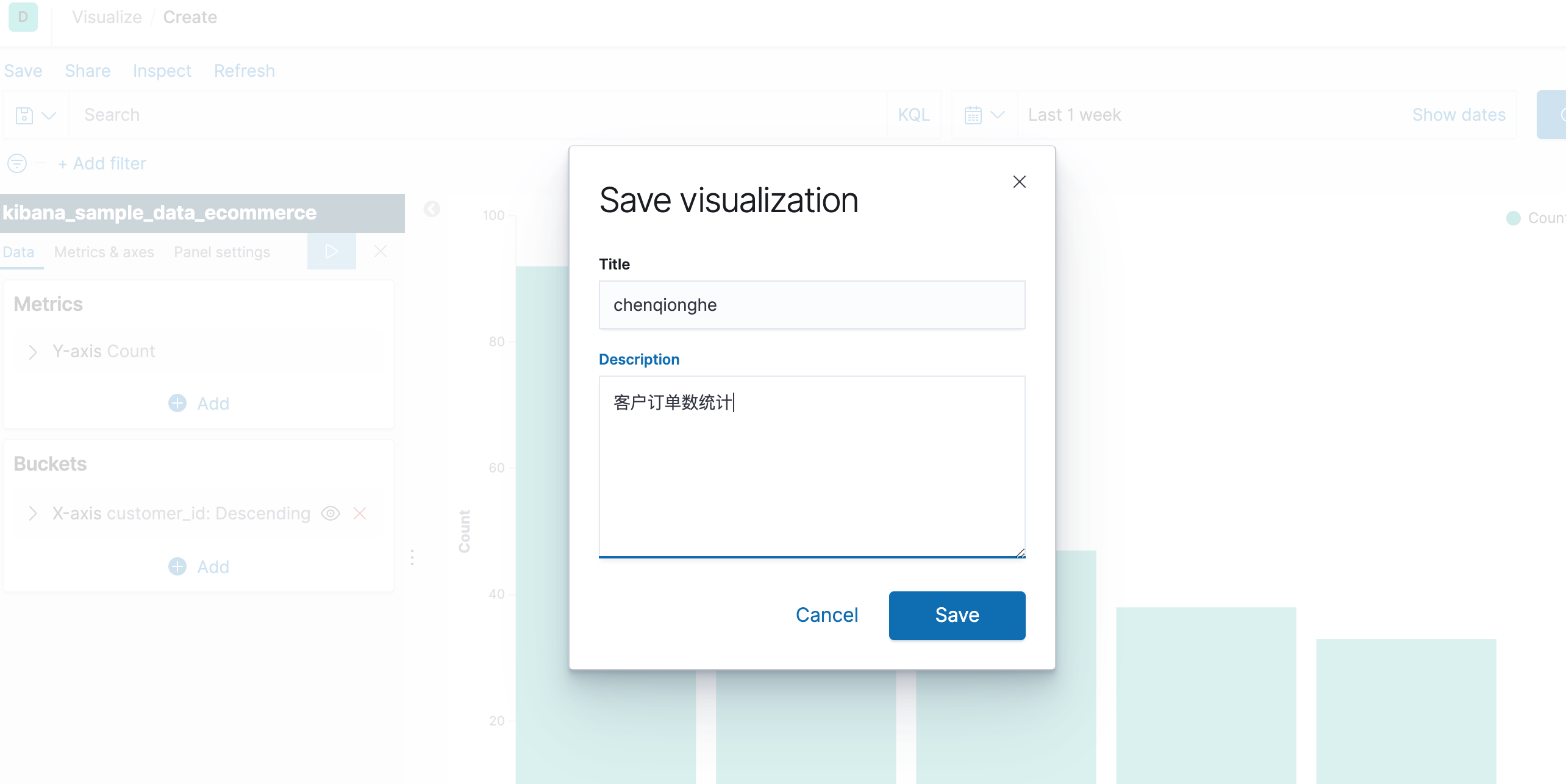
八、如何使用仪表盘
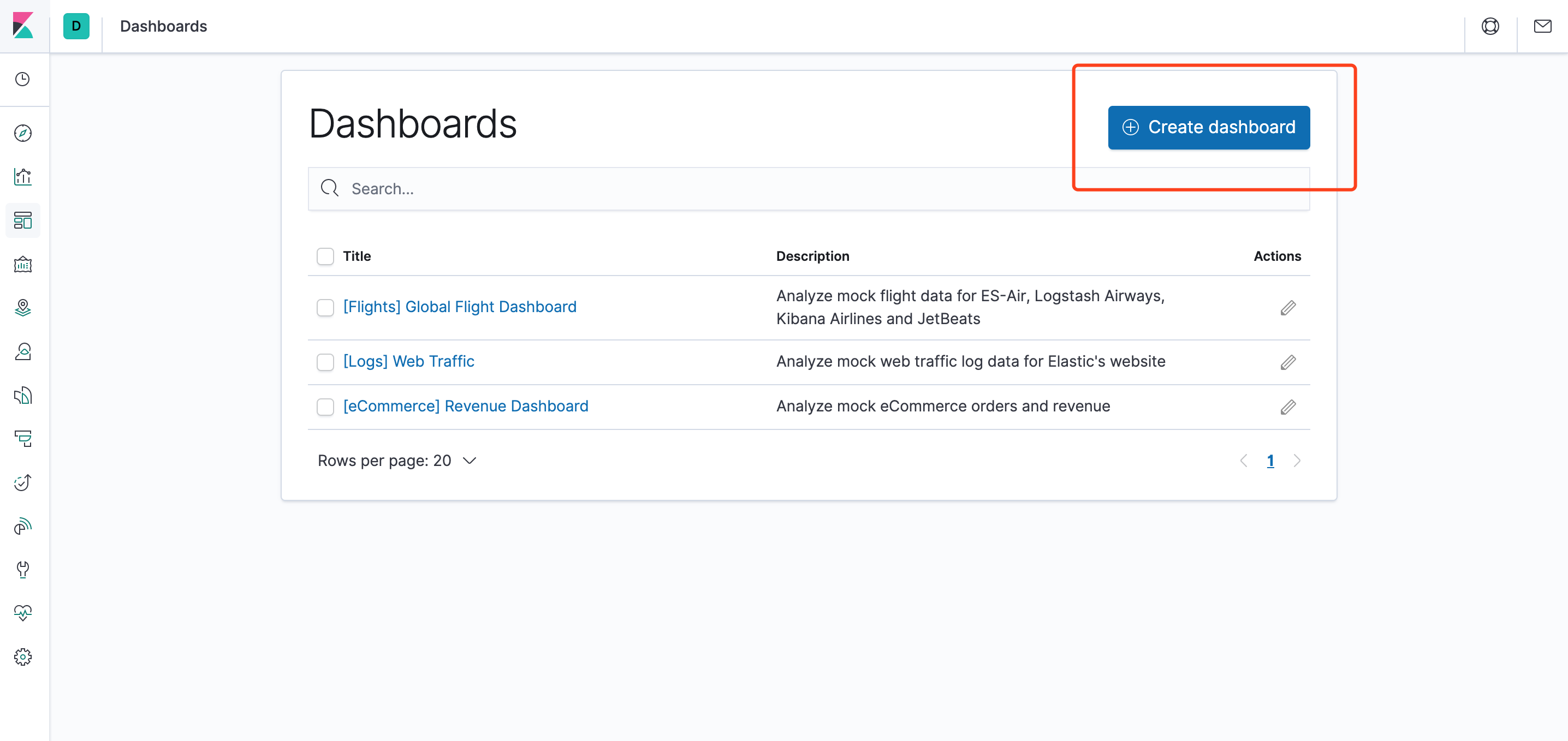
Kibana 仪表板(Dashboard) 展示保存的可视化结果集合。
就是可以把上面定义好的图表展示
创建一个Dashboard
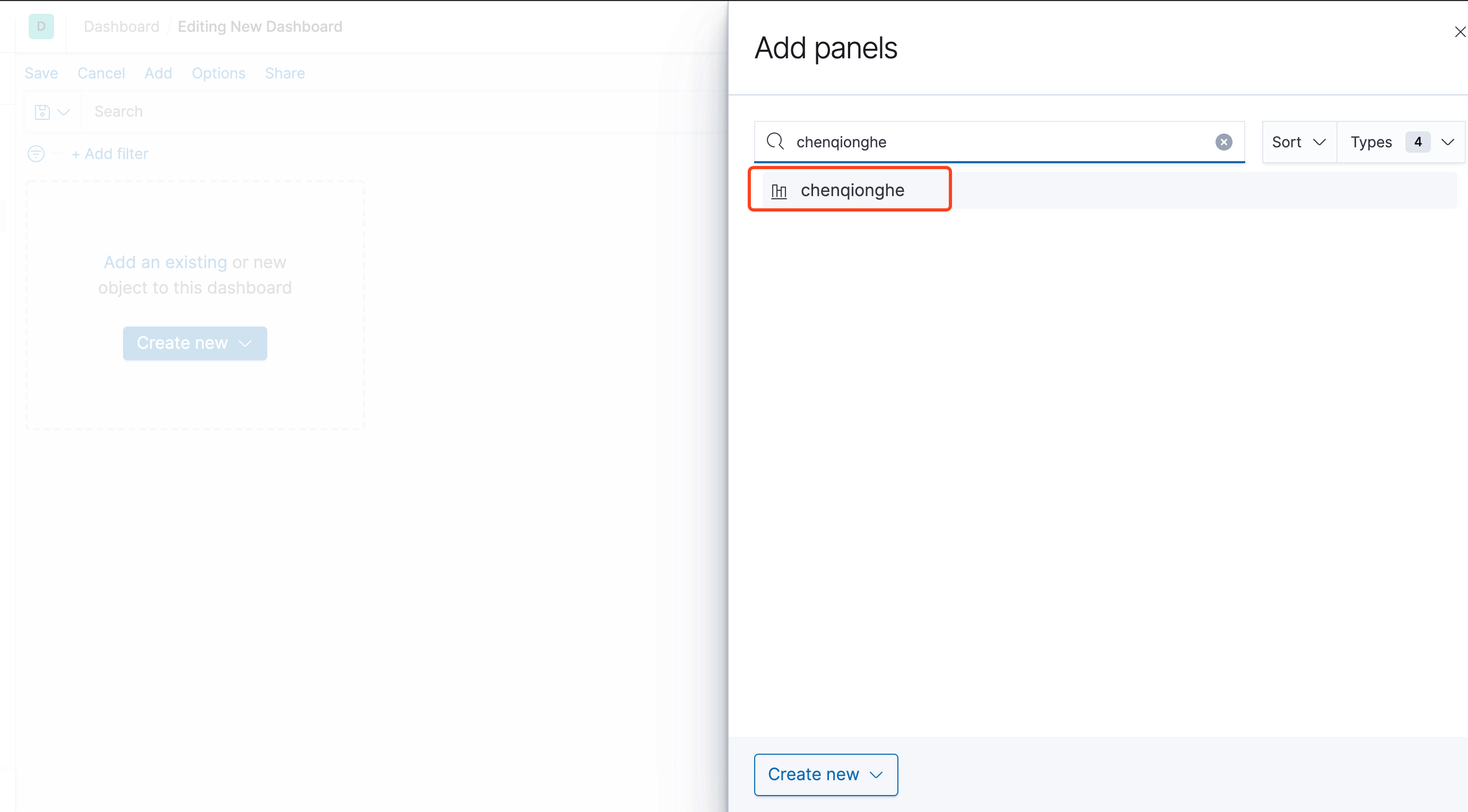
添加已经存在的图表
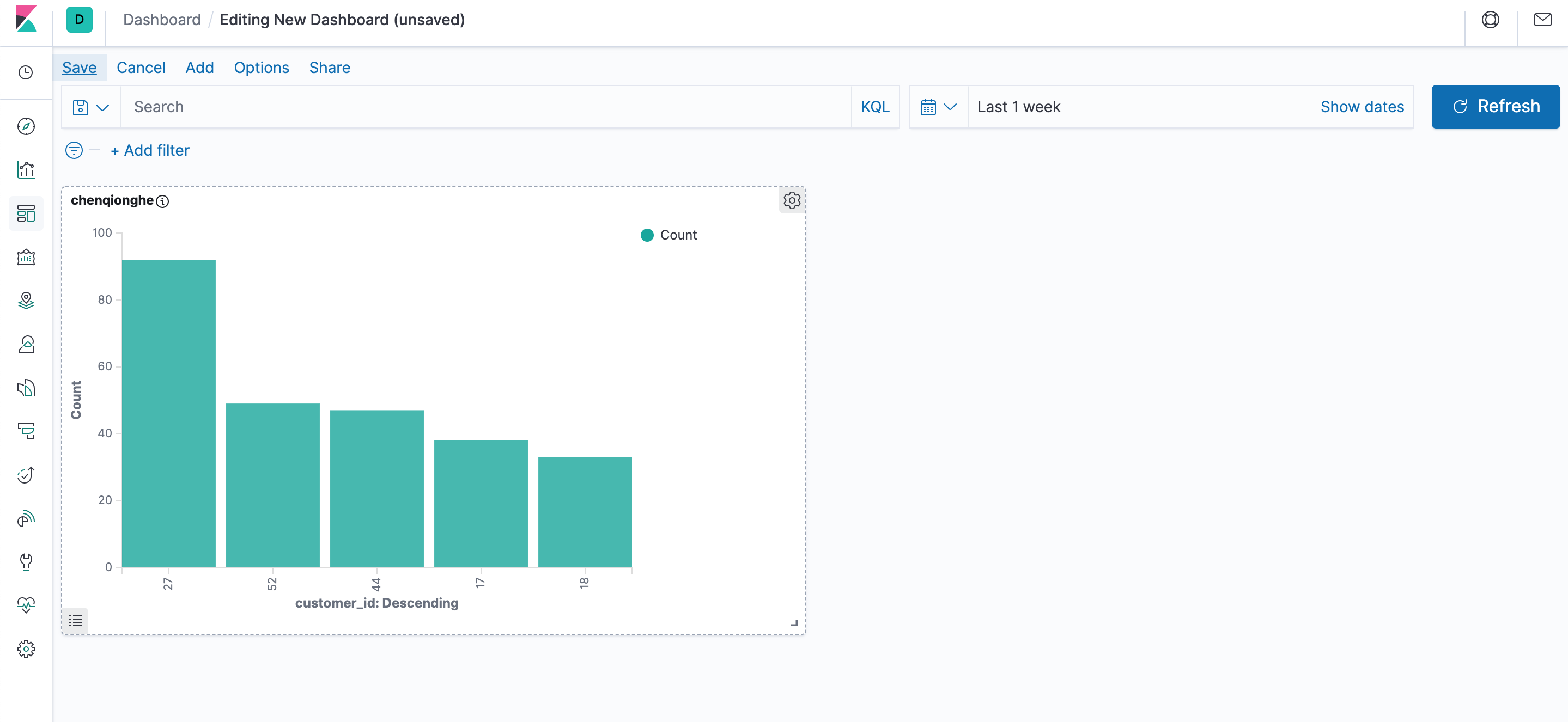
添加完后保存即可,我们可以定制出非常丰富的面板,如下
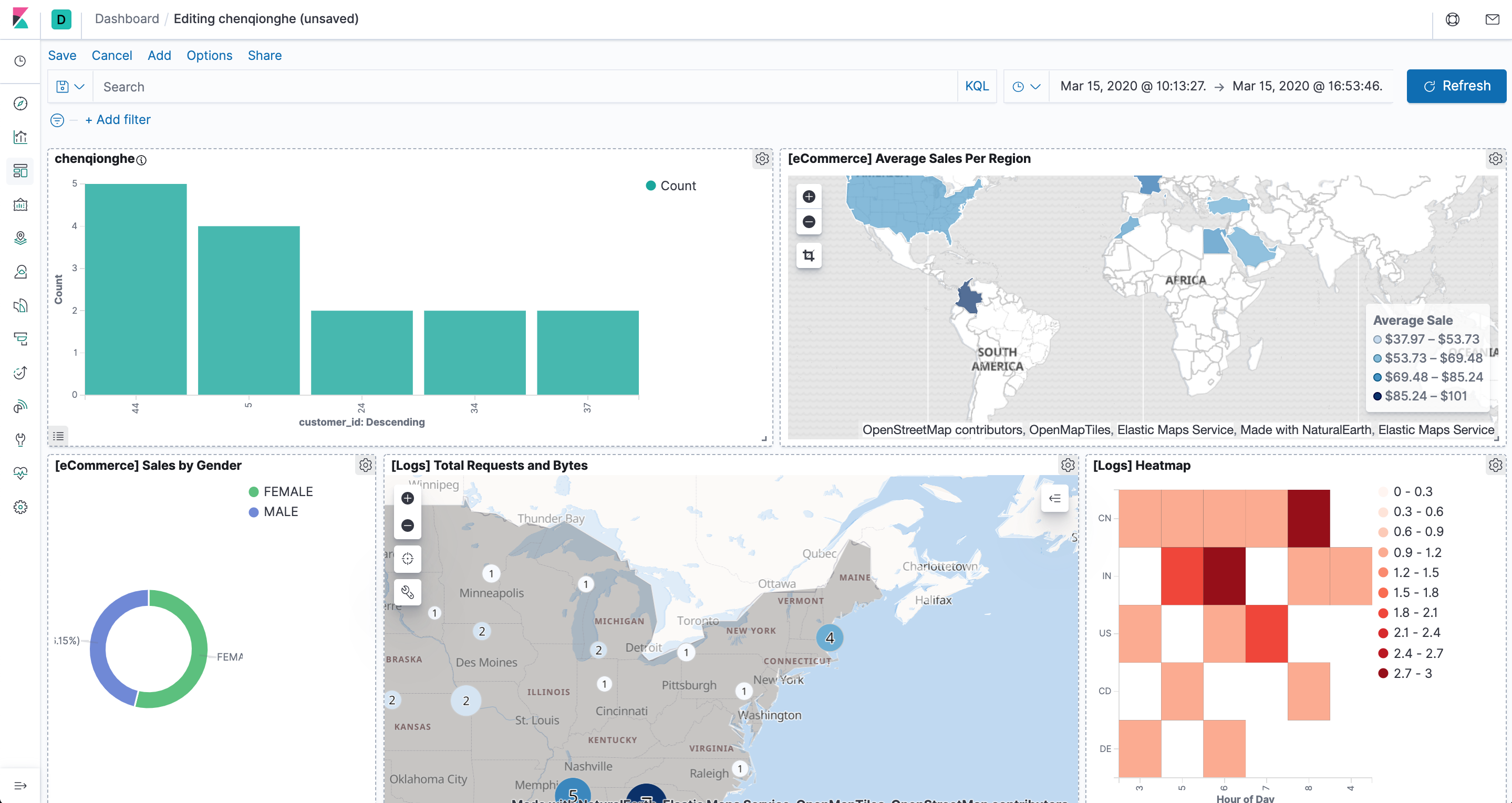
Kibana的使用就是这么简单,是不是觉得超简单,建议自己去安装使用一下,加深印象。


- 点赞
- 收藏
- 关注作者
评论(0)