深度学习应用篇-推荐系统[12]:经典模型-DeepFM模型、DSSM模型召回排序策略以及和其他模型对比

深度学习应用篇-推荐系统[12]:经典模型-DeepFM模型、DSSM模型召回排序策略以及和其他模型对比
1.DeepFM模型
1.1.模型简介
CTR预估是目前推荐系统的核心技术,其目标是预估用户点击推荐内容的概率。DeepFM模型包含FM和DNN两部分,FM模型可以抽取low-order(低阶)特征,DNN可以抽取high-order(高阶)特征。低阶特征可以理解为线性的特征组合,高阶特征,可以理解为经过多次线性-非线性组合操作之后形成的特征,为高度抽象特征。无需Wide&Deep模型人工特征工程。由于输入仅为原始特征,而且FM和DNN共享输入向量特征,DeepFM模型训练速度很快。
注解:Wide&Deep是一种融合浅层(wide)模型和深层(deep)模型进行联合训练的框架,综合利用浅层模型的记忆能力和深层模型的泛化能力,实现单模型对推荐系统准确性和扩展性的兼顾。
该模型的Paddle实现请参考链接:PaddleRec版本
1.2.DeepFM模型结构
为了同时利用low-order和high-order特征,DeepFM包含FM和DNN两部分,两部分共享输入特征。对于特征i,标量wi是其1阶特征的权重,该特征和其他特征的交互影响用隐向量Vi来表示。Vi输入到FM模型获得特征的2阶表示,输入到DNN模型得到high-order高阶特征。
DeepFM模型结构如下图所示,完成对稀疏特征的嵌入后,由FM层和DNN层共享输入向量,经前向反馈后输出。
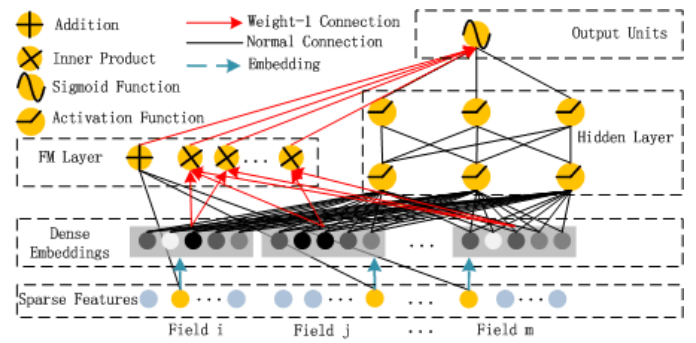
为什么使用FM和DNN进行结合?
- 在排序模型刚起步的年代,FM很好地解决了LR需要大规模人工特征交叉的痛点,引入任意特征的二阶特征组合,并通过向量内积求特征组合权重的方法大大提高了模型的泛化能力。
- 标准FM的缺陷也恰恰是只能做二阶特征交叉。
所以,将FM与DNN结合可以帮助我们捕捉特征之间更复杂的非线性关系。
为什么不使用FM和RNN进行结合?
- 如果一个任务需要处理序列信息,即本次输入得到的输出结果,不仅和本次输入相关,还和之前的输入相关,那么使用RNN循环神经网络可以很好地利用到这样的序列信息
- 在预估点击率时,我们会假设用户每次是否点击的事件是独立的,不需要考虑序列信息,因此RNN于FM结合来预估点击率并不合适。还是使用DNN来模拟出特征之间的更复杂的非线性关系更能帮助到FM。
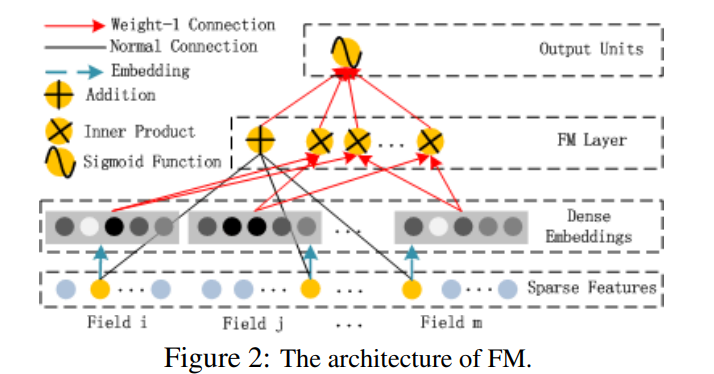
1.3.FM
FM(Factorization Machines,因子分解机)最早由Steffen Rendle于2010年在ICDM上提出,它是一种通用的预测方法,在即使数据非常稀疏的情况下,依然能估计出可靠的参数进行预测。与传统的简单线性模型不同的是,因子分解机考虑了特征间的交叉,对所有嵌套变量交互进行建模(类似于SVM中的核函数),因此在推荐系统和计算广告领域关注的点击率CTR(click-through rate)和转化率CVR(conversion rate)两项指标上有着良好的表现。
为什么使用FM?
- 特征组合是许多机器学习建模过程中遇到的问题,如果对特征直接建模,很有可能忽略掉特征与特征之间的关联信息,一次可以通过构建新的交叉特征这一特征组合方式提高模型的效果。FM可以得到特征之间的关联信息。
- 高维的稀疏矩阵是实际工程中常见的问题,并且直接导致计算量过大,特征权值更新缓慢。试想一个10000100的表,每一列都有8中元素,经过one-hot编码之后,会产生一个10000800的表。
而FM的优势就在于对这两方面问题的处理。首先是特征组合,通过两两特征组合,引入交叉项特征(二阶特征),提高模型得分;其次是高维灾难,通过引入隐向量(对参数矩阵进行分解),完成特征参数的估计。
FM模型不单可以建模1阶特征,还可以通过隐向量点积的方法高效的获得2阶特征表示,即使交叉特征在数据集中非常稀疏甚至是从来没出现过。这也是FM的优势所在。
单独的FM层结构如下图所示:
1.4.DNN
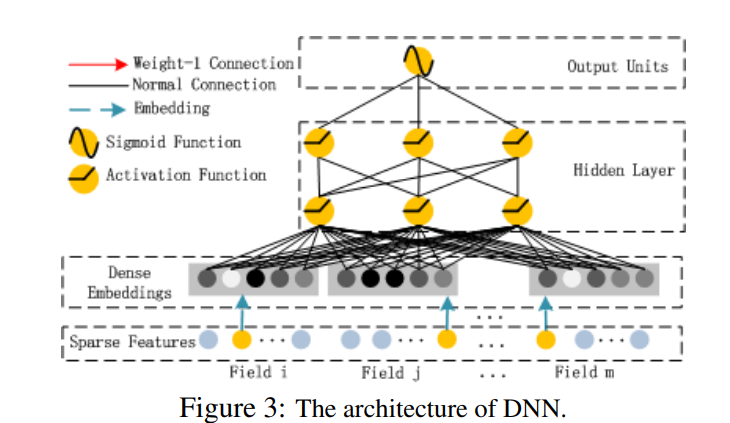
该部分和Wide&Deep模型类似,是简单的前馈网络。在输入特征部分,由于原始特征向量多是高纬度,高度稀疏,连续和类别混合的分域特征,因此将原始的稀疏表示特征映射为稠密的特征向量。
假设子网络的输出层为:
DNN网络第l层表示为:
再假设有H个隐藏层,DNN部分的预测输出可表示为:
DNN深度神经网络层结构如下图所示:
1.5.Loss及Auc计算
DeepFM模型的损失函数选择Binary_Cross_Entropy(二值交叉熵)函数
对于公式的理解,y是样本点,p(y)是该样本为正样本的概率,log(p(y))可理解为对数概率。
Auc是Area Under Curve的首字母缩写,这里的Curve指的就是ROC曲线,AUC就是ROC曲线下面的面积,作为模型评价指标,他可以用来评价二分类模型。其中,ROC曲线全称为受试者工作特征曲线 (receiver operating characteristic curve),它是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(敏感性)为纵坐标,假阳性率(1-特异性)为横坐标绘制的曲线。
可使用paddle.metric.Auc()进行调用。
可参考已有的资料:机器学习常用评估指标
1.6.与其他模型的对比
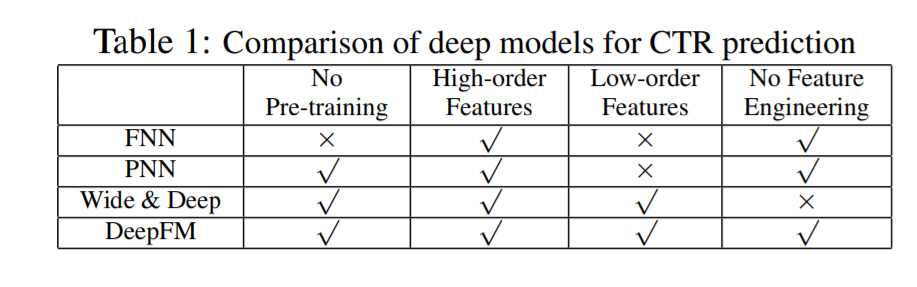
如表1所示,关于是否需要预训练,高阶特征,低阶特征和是否需要特征工程的比较上,列出了DeepFM和其他几种模型的对比。DeepFM表现更优。
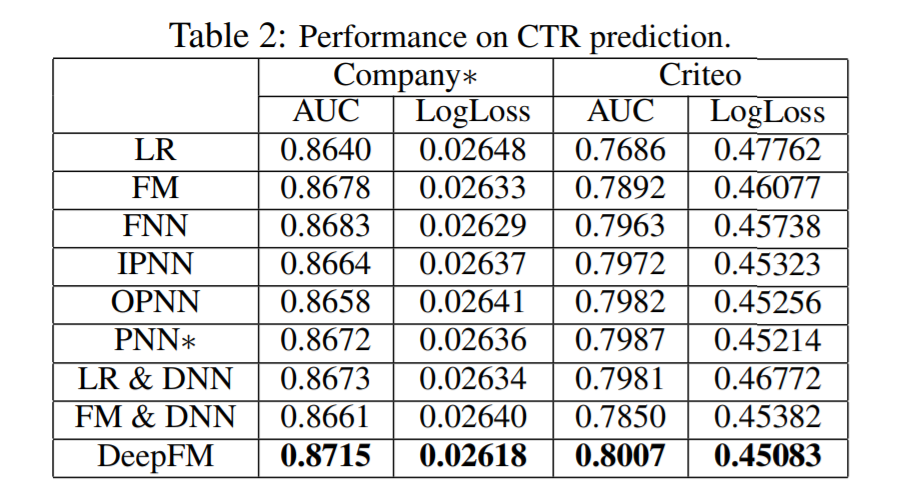
如表2所示,不同模型在Company*数据集和Criteo数据集上对点击率CTR进行预估的性能表现。DeepFM在各个指标上表现均强于其他模型。
- 参考文献
2.DSSM
以搜索引擎和搜索广告为例,最重要的也最难解决的问题是语义相似度,这里主要体现在两个方面:召回和排序。
在召回时,传统的文本相似性如 BM25,无法有效发现语义类 query-Doc 结果对,如"从北京到上海的机票"与"携程网"的相似性、“快递软件"与"菜鸟裹裹"的相似性。
在排序时,一些细微的语言变化往往带来巨大的语义变化,如"小宝宝生病怎么办"和"狗宝宝生病怎么办”、“深度学习"和"学习深度”。
DSSM(Deep Structured Semantic Models)为计算语义相似度提供了一种思路。
该模型的Paddle实现请参考链接:PaddleRec版本
2.1DSSM模型结构
DSSM(Deep Structured Semantic Models)的原理很简单,通过搜索引擎里 Query 和 Title 的海量的点击曝光日志,用 DNN 把 Query 和 Title 表达为低纬语义向量,并通过 cosine 距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低纬语义向量表达。
DSSM 从下往上可以分为三层结构:输入层、表示层、匹配层
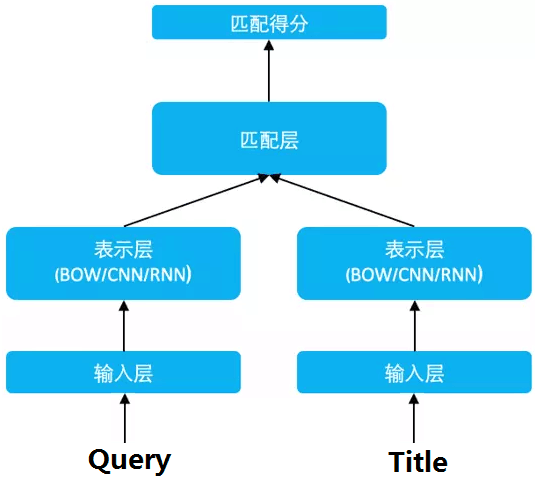
2.1.1 输入层
输入层做的事情是把句子映射到一个向量空间里并输入到 DNN 中,这里英文和中文的处理方式有很大的不同。
英文
英文的输入层处理方式是通过word hashing。举个例子,假设用 letter-trigams 来切分单词(3 个字母为一组,#表示开始和结束符),boy 这个单词会被切为 #-b-o, b-o-y, o-y-#
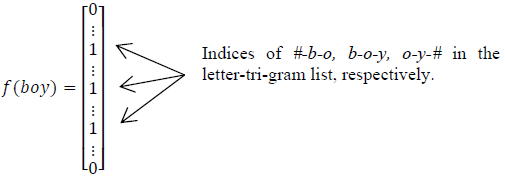
这样做的好处有两个:首先是压缩空间,50 万个词的 one-hot 向量空间可以通过 letter-trigram 压缩为一个 3 万维的向量空间。其次是增强范化能力,三个字母的表达往往能代表英文中的前缀和后缀,而前缀后缀往往具有通用的语义。
这里之所以用 3 个字母的切分粒度,是综合考虑了向量空间和单词冲突:
| Letter-Bigram | Letter-Trigram | |||
|---|---|---|---|---|
| word Size | Token Size | Collision | Token Size | Collision |
| 40k | 1107 | 18 | 10306 | 2 |
| 500k | 1607 | 1192 | 30621 | 22 |
如上表,以 50 万个单词的词库为例,2 个字母的切分粒度的单词冲突为 1192(冲突的定义:至少有两个单词的 letter-bigram 向量完全相同),而 3 个字母的单词冲突降为 22 效果很好,且转化后的向量空间 3 万维不是很大,综合考虑选择 3 个字母的切分粒度。
中文
中文的输入层处理方式与英文有很大不同,首先中文分词是个让所有 NLP 从业者头疼的事情,即便业界号称能做到 95%左右的分词准确性,但分词结果极为不可控,往往会在分词阶段引入误差。所以这里我们不分词,而是仿照英文的处理方式,对应到中文的最小粒度就是单字了。
由于常用的单字为 1.5 万左右,而常用的双字大约到百万级别了,所以这里出于向量空间的考虑,采用字向量(one-hot)作为输入,向量空间约为 1.5 万维。
2.1.2表示层
DSSM 的表示层采用 BOW(Bag of words)的方式,相当于把字向量的位置信息抛弃了,整个句子里的词都放在一个袋子里了,不分先后顺序。
紧接着是一个含有多个隐层的 DNN,如下图所示:
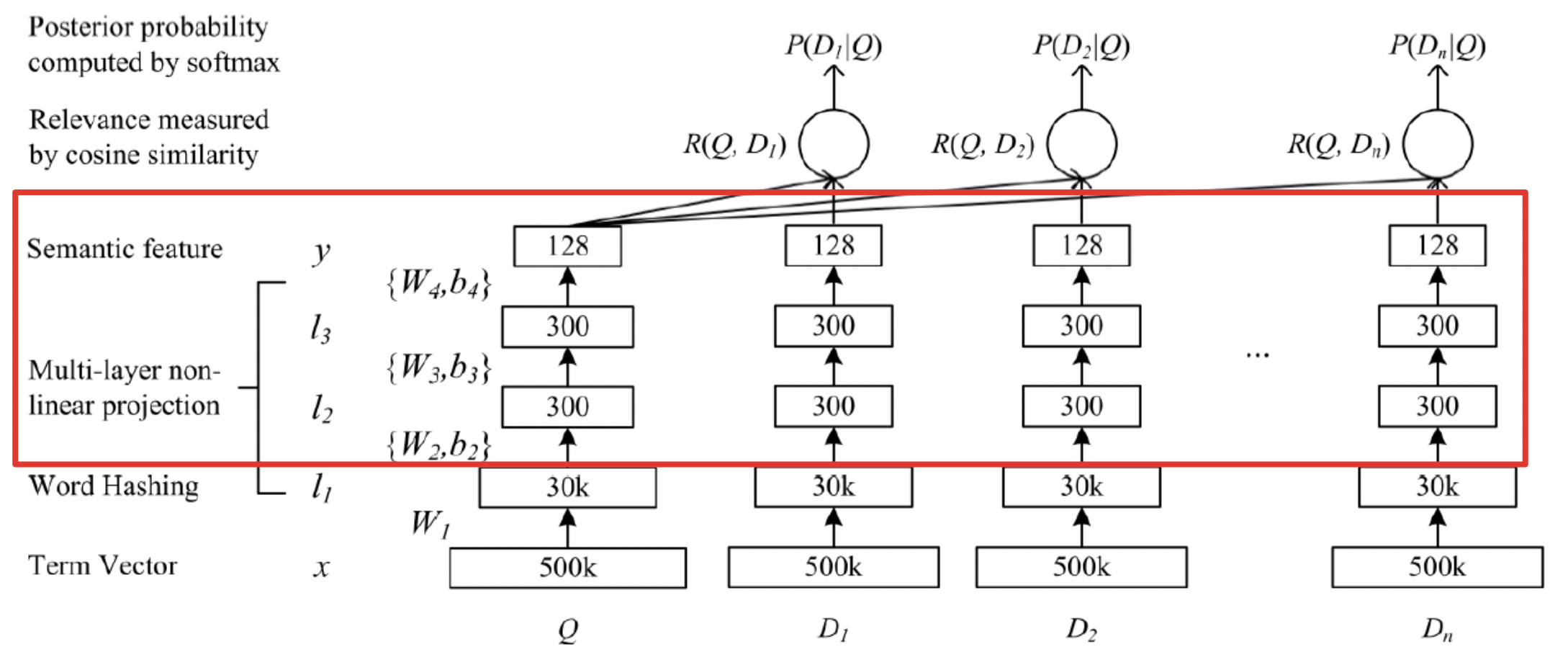
用 表示第 i 层的权值矩阵, 表示第 i 层的偏置项。则第一隐层向量 l2(300 维),第 二个隐层向量 l3(300 维),输出向量 y(128 维),用数学公式可以分别表示为:
用 tanh 作为隐层和输出层的激活函数:
最终输出一个 128 维的低纬语义向量。
2.1.3 匹配层
Query 和 Doc 的语义相似性可以用这两个语义向量(128 维) 的 cosine 距离来表示:
通过softmax 函数可以把Query 与正样本 Doc 的语义相似性转化为一个后验概率:
其中 r 为 softmax 的平滑因子,D 为 Query 下的正样本,D-为 Query 下的负样本(采取随机负采样),D 为 Query 下的整个样本空间。
在训练阶段,通过极大似然估计,我们最小化损失函数:
残差会在表示层的 DNN 中反向传播,最终通过随机梯度下降(SGD)使模型收敛,得到各网络层的参数 。
负样本出现在计算softmax中,loss反向传播只用正样本。
2.1.4优缺点
优点:DSSM 用字向量作为输入既可以减少切词的依赖,又可以提高模型的泛化能力,因为每个汉字所能表达的语义是可以复用的。另一方面,传统的输入层是用 Embedding 的方式(如 Word2Vec 的词向量)或者主题模型的方式(如 LDA 的主题向量)来直接做词的映射,再把各个词的向量累加或者拼接起来,由于 Word2Vec 和 LDA 都是无监督的训练,这样会给整个模型引入误差,DSSM 采用统一的有监督训练,不需要在中间过程做无监督模型的映射,因此精准度会比较高。
缺点:上文提到 DSSM 采用词袋模型(BOW),因此丧失了语序信息和上下文信息。另一方面,DSSM 采用弱监督、端到端的模型,预测结果不可控。
更多优质内容请关注公重号:汀丶人工智能
- 参考文献
[1]. Huang P S, He X, Gao J, et al. Learning deep structured semantic models for web search using clickthrough data[C]// ACM International Conference on Conference on Information & Knowledge Management. ACM, 2013:2333-2338.

- 点赞
- 收藏
- 关注作者
评论(0)