深度学习应用篇-计算机视觉-视频分类8:时间偏移模块(TSM)、TimeSformer无卷积视频分类方法、注意力机制

深度学习应用篇-计算机视觉-视频分类[8]:时间偏移模块(TSM)、TimeSformer无卷积视频分类方法、注意力机制
1.时间偏移模块(TSM)
视频流的爆炸性增长为以高精度和低成本执行视频理解任务带来了挑战。传统的2D CNN计算成本低,但无法捕捉视频特有的时间信息;3D CNN可以得到良好的性能,但计算量庞大,部署成本高。作者提出了一种通用且有效的时间偏移模块(TSM),它通过沿时间维度移动部分通道来促进相邻帧间的信息交换,同时它可以插入到2D CNN中实现零计算和零参数的时间建模,以此兼具2D卷积的高效与3D卷积的高性能。
1.2. TSM模型介绍
1.2.1 Intuition
首先考虑一个正常的卷积操作,以核大小为3的一维卷积为例。假设卷积的权重为 ,输入 是一个1D无限长的向量,则卷积操作 可被表示为:
将卷积操作解耦为两步,位移和乘法累加。对输入 进行 的位移,具体表示为:
乘法累加可表示为:
第一步位移是不需要时间成本的,第二步乘法累加需要更大的计算消耗,但是TSM将乘法累加部分合并在了2D卷积中,因此它和基本的2D CNN网络相比不存在额外开销。
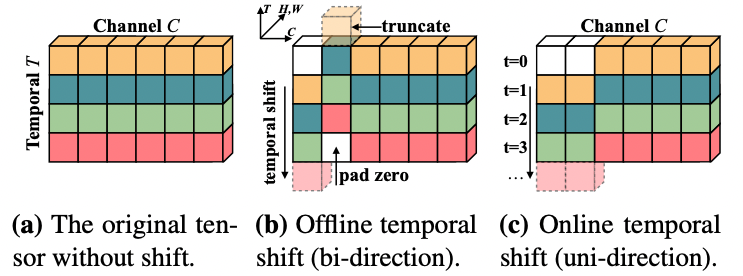
Temporal Shift Module(TSM) 如 图1 所示,在 图1 a 中,作者描述了一个具有C通道和T帧的张量,图片中每一行不同颜色代表在不同时间点的特征,沿时间维度,我们将一部分通道移动-1,另一部分通道移动+1,其余部分不动(如 图1 b 所示)。对于在线视频识别,作者也提供了在线版本的TSM(如 图1c 所示),由于在在线识别模式中,我们不能获得未来帧,因此只进行单一方向的移动。
1.2.2 简易的空间移动会带来什么问题
虽然时间位移的原理很简单,但作者发现直接将空间位移策略应用于时间维度并不能提供高性能和效率。具体来说,如果简单的转移所有通道,则会带来两个问题:(1)由于大量数据移动而导致的效率下降问题。位移操作不需要计算但是会涉及数据移动,数据移动增加了硬件上的内存占用和推理延迟,作者观察到在视频理解网络中,当使用naive shift策略时,CPU延迟增加13.7%,GPU延迟增加12.4%,使整体推理变慢。(2)空间建模能力变差导致性能下降,由于部分通道被转移到相邻帧,当前帧不能再访问通道中包含的信息,这可能会损失2D CNN主干的空间建模能力。与TSN基线相比,使用naive shift会降低2.6%的准确率。
1.2.3 TSM模块
为了解决naive shift的两个问题,TSM给出了相应的解决方法。
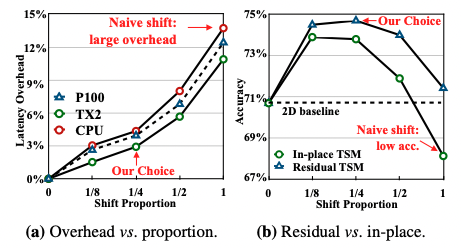
- 减少数据移动。 为了研究数据移动的影响,作者测量了TSM模型在不同硬件设备上的推理延迟,作者移动了不同比例的通道数并测量了延迟,位移方式分为无位移、部分位移(位移1/8、1/4、1/2的通道)和全部位移,使用ResNet-50主干和8帧输入测量模型。作者观察到,如果移动所有的通道,那么延迟开销将占CPU推理时间的13.7%(如 图2 a 所示),如果只移动一小部分通道,如1/8,则可将开销限制在3%左右。
保持空间特征学习能力。 一种简单的TSM使用方法是将其直接插入到每个卷基层或残差模块前,如 图3 a 所示,这种方法被称为 in-place shift,但是它会损失主干模型的空间特征学习能力,尤其当我们移动大量通道时,存储在通道中的当前帧信息会随着通道移动而丢失。为解决这个问题,作者提出了另一种方法,即将TSM放在残差模块的残差分支中,这种方法被称为 residual TSM,如 图3 b 所示,它可以解决退化的空间特征学习问题,因为原始的激活信息在时间转移后仍可通过identity映射访问。

图3 In-place TSM 和 Residual TSM
为检验上述假设,作者在 Kinetics 数据集上比较了 In-place TSM 和 Residual TSM 的性能。在 图2 b 中我们可以看到,对于所有比例的位移,Residual TSM 都具有更好的性能。同时,作者发现,性能与位移通道的比例有关:如果比例太小,则时间推理的能力可能不足以处理复杂的时间关系;如果太大,则会损害空间特征学习能力,选择1/4的通道偏移时,性能会达到峰值。
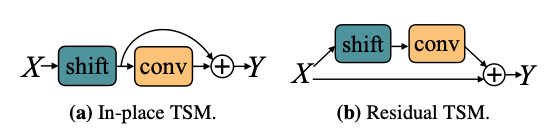
1.2.4 TSM 视频网络
Offline Models with Bi-directional TSM
作者使用双向TSM来构建离线视频识别模型。给定视频 V,首先从视频中采样T帧 。帧采样后,2D CNN单独处理每个帧,并对输出logits求平均值以给出最终预测。我们为每个残差模块插入了TSM,无需计算即可实现时间信息融合。在论文中,作者使用ResNet50作为网络主干。
Online Models with Uni-directional TSM
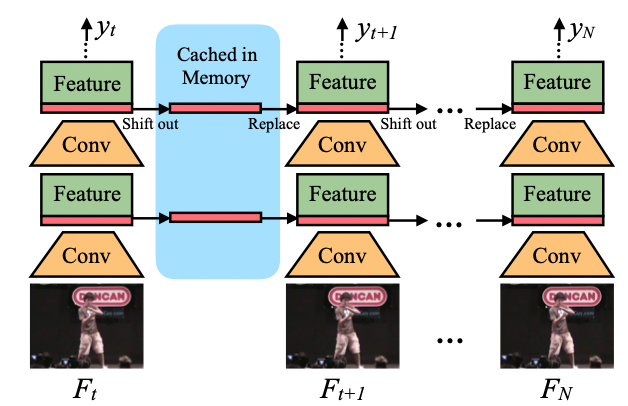
在线视频理解是现实生活中很重要的任务,单向TSM将特征从前一帧转移到当前帧。用于在线识别的单向TSM 推理图如 图4 所示,在推理过程中,对于每一帧,我们保存每个残差块的前 1/8 特征图并将其缓存在内存中,对于下一帧,我们用缓存的特征图来替换当前特征图的前 1/8。我们使用 7/8 当前特征图和 1/8 前一帧的特征图组合来生成下一层,并重复。
1.3 实验结果
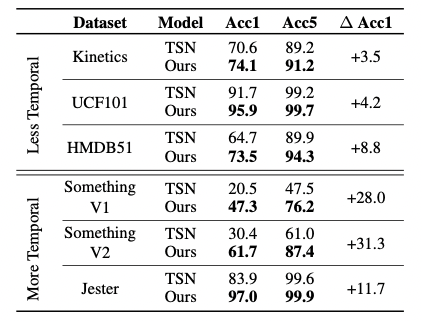
如 表1 所示,作者在不同的数据集上分别测试了TSN的精度和TSM的精度。该表格可分为两部分,上部分涉及的数据集在时间关系上没有那么重要,TSM的计算结果小幅度优于2D TSN基线。下部分数据集,Something-Something V1和V2 以及 Jester,它们很大程度上取决于时间关系,TSM在这些数据集上性能有大幅度的明显提升。
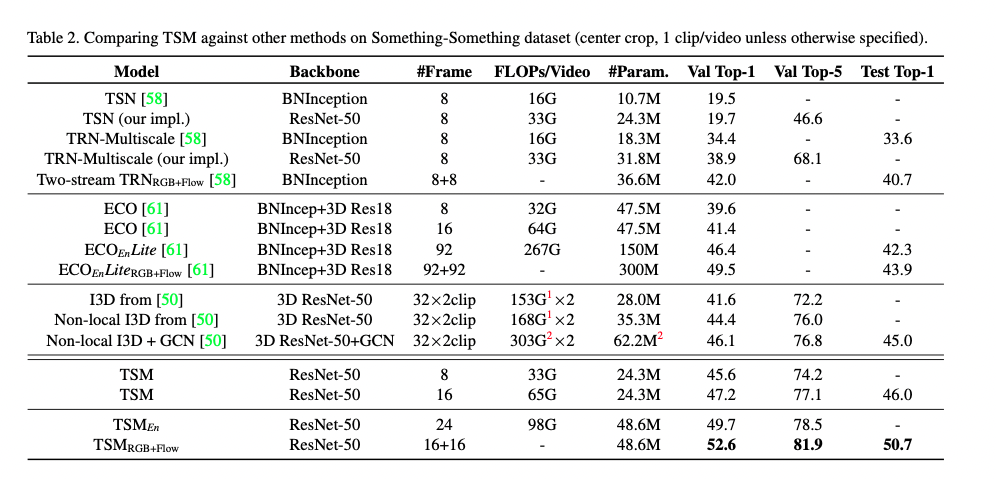
作者在Something-Something V1数据集上将TSM模型的性能与最先进的方法进行了对比。首先,由于TSN缺少时间建模,因此无法获得良好的性能。对于 TRN,虽然在特征提取后添加了后期时间融合,但其性能仍显著低于最先进的方法,跨所有层的时间融合的重要性。
在第二部分中,TSM与高效视频理解框架ECO进行对比。ECO使用早期2D + 晚期3D的结构,可实现中级时间融合。与ECO相比,TSM在较小的FLOP上获得了更好的性能。
第三部分包含当前的最新方法: Non-local I3D + GCN,可实现所有级别的时间融合。但由于GCN需要使用一个在MSCOCO对象检测数据集上训练的地区提议网络来生成边界框,这引入了额外的数据和训练成本,因此不能公平的进行比较。只将TSM与它的CNN部分(Non-local I3D)比较的话,TSM在验证集上的FLOP减小了10倍,精度提升1.2%。
2.TimeSformer
2.1. TimeSformer 简介
论文地址:Is Space-Time Attention All You Need for Video Understanding?
TimeSformer是Facebook AI于2021年提出的无卷积视频分类方法,该方法使用ViT网络结构作为backbone,提出时空自注意力机制,以此代替了传统的卷积网络。与图像只具有空间信息不同,视频还包含时间信息,因此TimeSformer对一系列的帧级图像块进行时空特征提取,从而适配视频任务。TimeSformer在多个行为识别基准测试中达到了SOTA效果,其中包括TimeSformer-L在Kinetics-400上达到了80.7的准确率,超过了经典的基于CNN的视频分类模型TSN、TSM及Slowfast,而且有更短的训练用时(Kinetics-400数据集训练用时39小时)。同时,与3D卷积网络相比,TimeSformer的模型训练速度更快,拥有更高的测试效率,并且可以处理超过一分钟的视频片段。
2.2 模型介绍
输入视频片段
TimeSformer的输入 为一段视频片段,由 个从视频中采样的大小为 的 RGB 图片帧组成。
图像块拆分
与 ViT 结构相同,TimeSformer将每一帧的图像分割成 个不重叠的图像块,每个图像块的大小为 。因为要确保每一帧被划分为 个不重叠的图像块,因此 的计算方式为: 。我们将划分好的图像块展平为 的向量,其中 代表图像块的位置, 代表帧的索引。
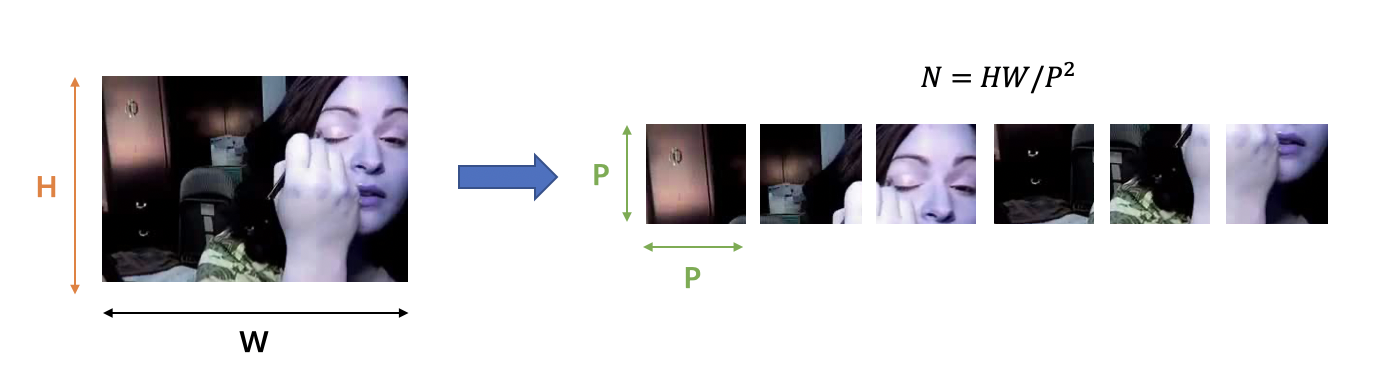
图2:将图像帧切割成图像块
线性嵌入
我们将每一个图像块 通过一个线性嵌入层转化为向量 :
其中, 是一个可学习的矩阵, 代表一个可学习的位置embedding, 可以对每个图像块的位置信息进行编码。因为transformer的序列式处理方式减弱了空间位置关系,因此需要给每个图像块加上一个位置信息。 代表 transformer 结构的输入,同时,额外增加一个 来表示分类token的embedding,作为分类器的输入。
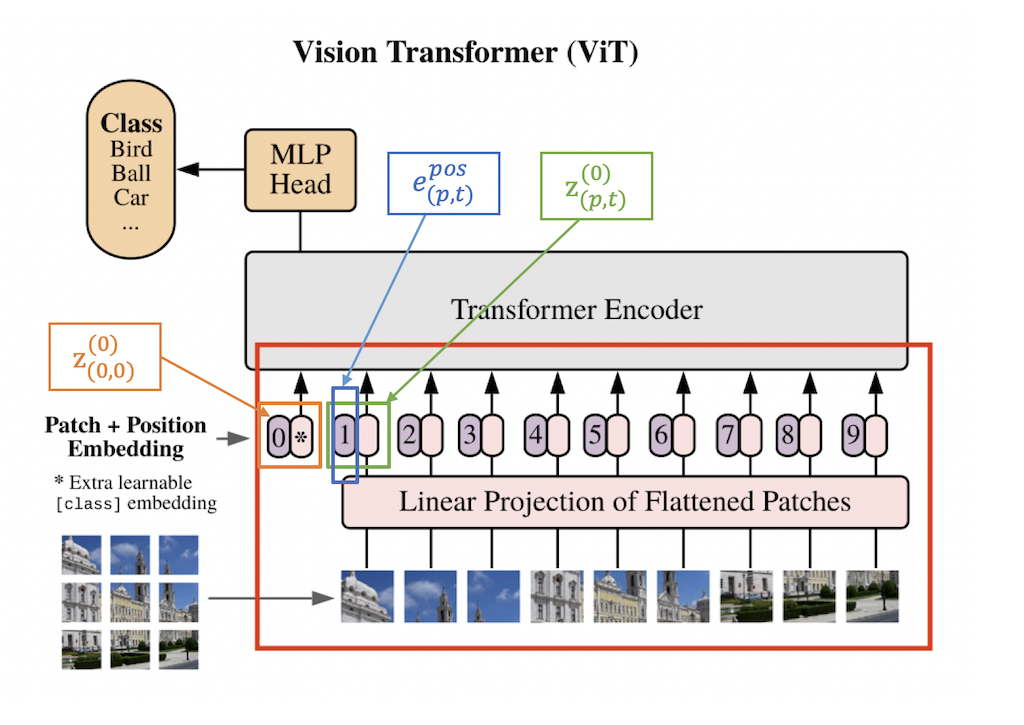
图3:线性嵌入层
QKV计算
TimeSformer采用的 transformer 结构中包含 个编码模块。对于每一个模块 ,一个query/key/value的向量都会由下述公式进行计算:
其中,LN() 代表层归一化, 代表多个注意力头的索引, 表示注意力头的总数。每个注意力头的潜在维度为 。
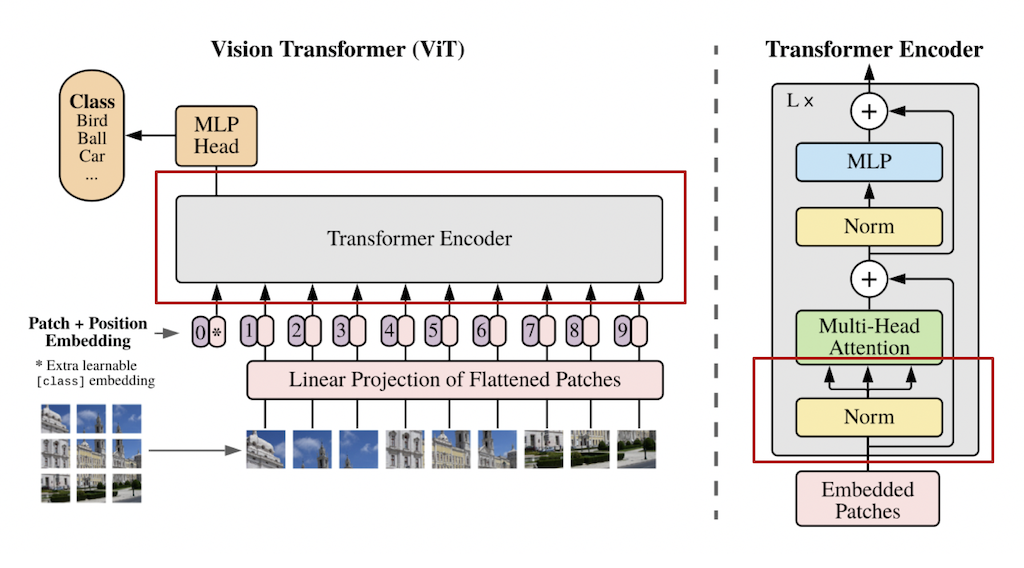
自注意力计算
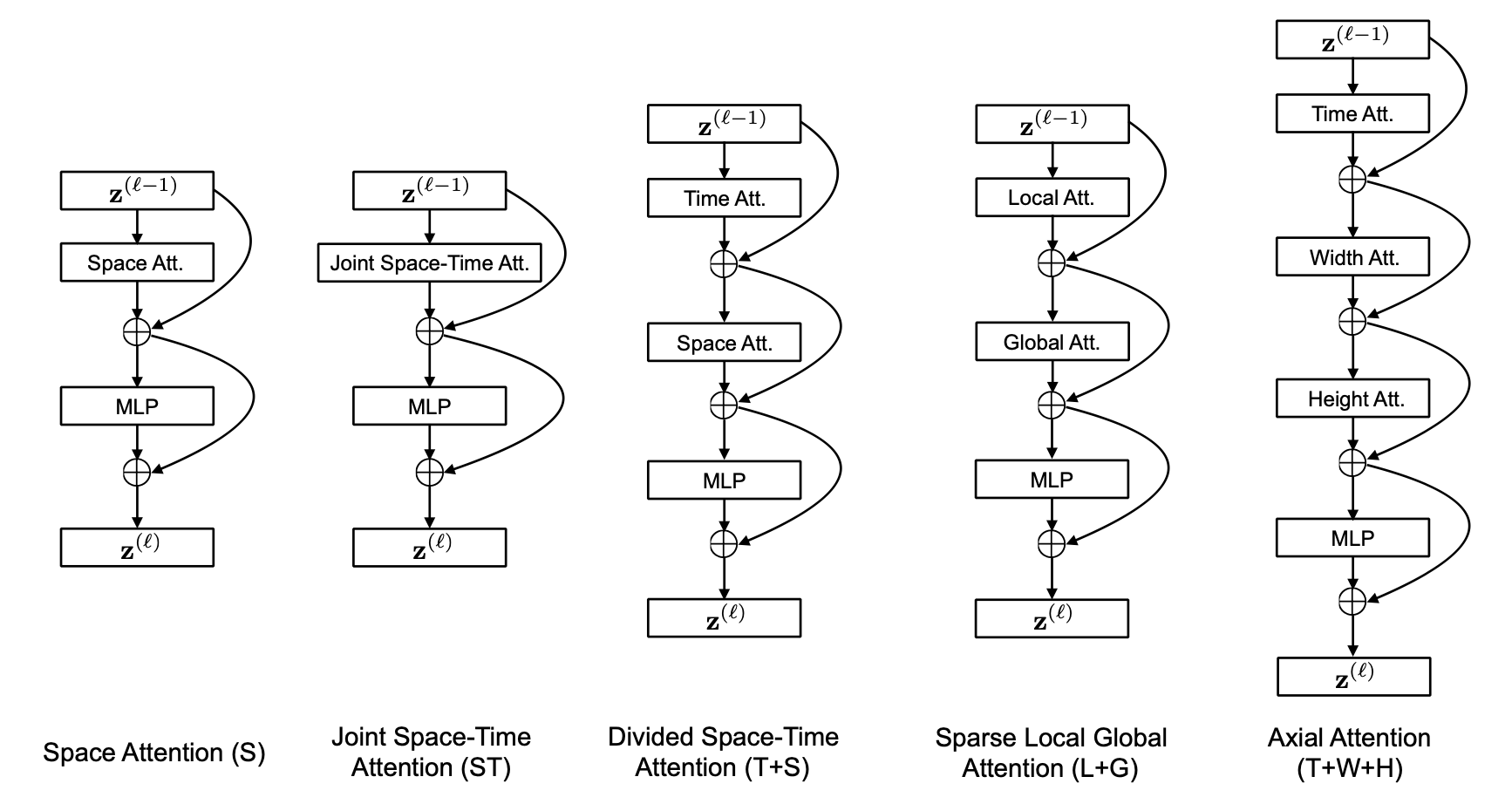
作者在实验过程中对不同的视频自注意力模块进行了调研。实验发现,单一维度的自注意力(只有时间维度或空间维度的自注意力)(S)相比于时空注意力模块(ST)极大的减小了计算量,但只采取单一的时间或空间维度进行自注意力计算,对于视频分类任务来说,势必会极大的影响模型的分类精度,因此,作者提出了一种 “Divided Space-Time Attention”(T+S),在先进行时间注意力后再进行空间注意力,不同的注意力模块结构 如图5 所示。对于分离的注意力,我们先将每一个图片块 与其他在相同空间位置但是不同时间帧的图像块进行对比(自注意力工作机制可视化 如图6 所示),得到权重矩阵 :

实验证明,相比于每个图像块都需要进行 次对比的时空联合注意力模块(ST),空间-时间分离的注意力模块(T+S)对于每个图像块只需要进行 次对比,极大的提高了计算效率的同时,同时也获得了更好的分类准确率。
作者还试验了“稀疏局部全局”(L+G)和 “轴向” (T+W+H) 注意力模型。其结构如 图5 所示,图6 显示attention过程中涉及到的图像块。对每个图像块 ,(L+G)首先考虑相邻的 图像块来计算局部注意力,然后以两个图像块的步长对整个视频片段沿时间维度和空间维度计算稀疏全局注意力。“轴向”注意力将注意力计算分解为三个不同的步骤:时间、宽度和高度。Ho et al., 2019[1]; Huang et al., 2019[2]; Wang et al., 2020b[3] 中提出了对图像两个空间轴的分解注意力,作者针对视频的情况添加了时间维度。
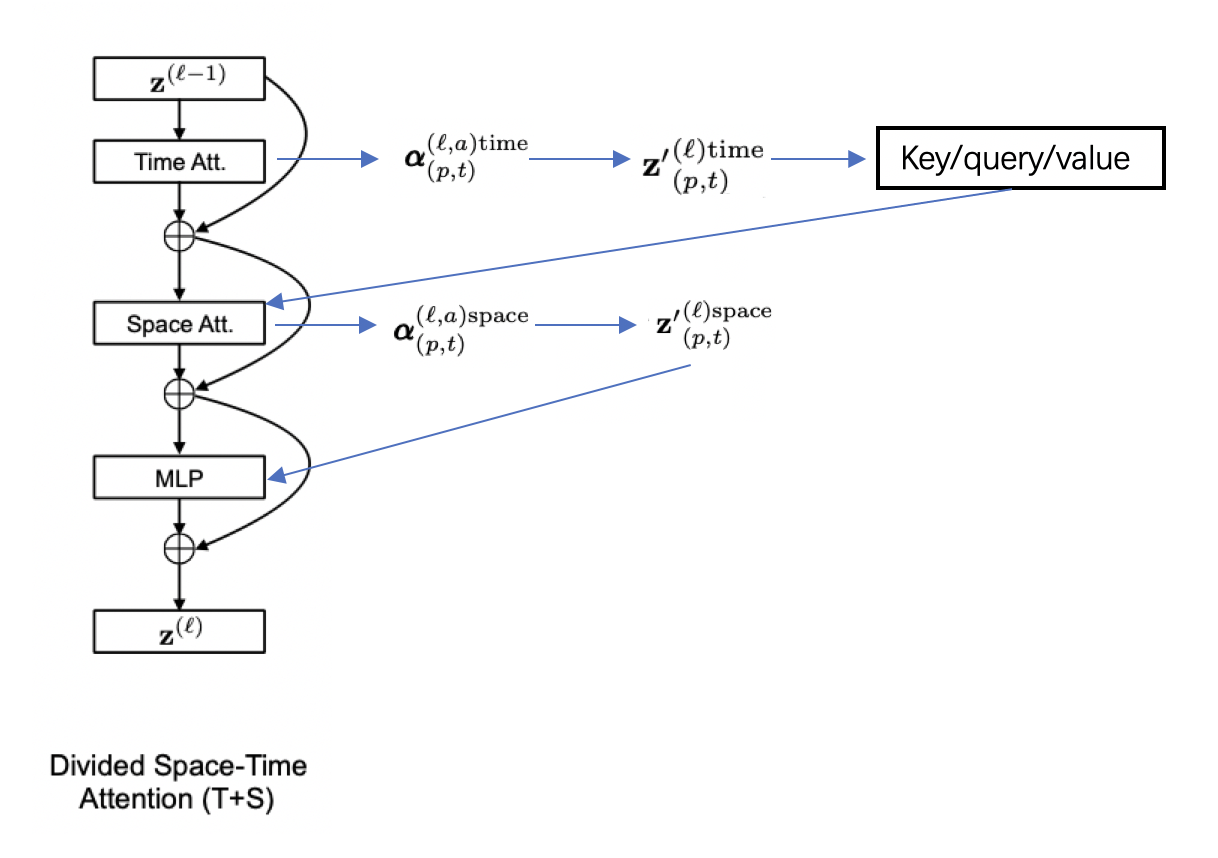
针对分离的时空自注意力模块,具体的计算流程如 图7 所示,在通过time attention获得 , 根据权重矩阵计算得到encoding 并由此计算出新的key/query/value向量。使用新得到的key/query/value来进行空间维度的计算,通过space attention得到 ,最终经过MLP层得到:
Classification
最后,通过一个MLP对class token进行处理,得到最终的预测结果。
2.3. 实验结果
作者对不同的attention模块分别在Kinetics-400(K400)和Something-Something-V2(SSv2)数据集上进行了实验,实验结果如 表1 所示。可以看到,分离的时空自注意力在两个数据集上都达到了很好的效果。
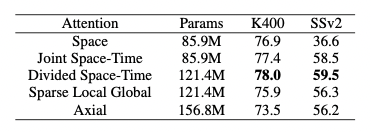
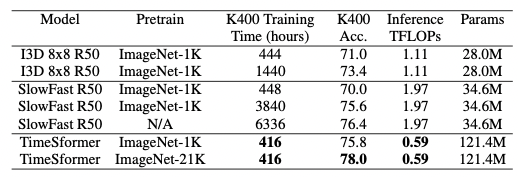
作者也对TimeSformer和SlowFast以及I3D在K400数据集上进行了比较,可以看到尽管TimeSformer的参数量较大但是其推理成本较低。同时,在ImageNet-21K上进行预训练,则可达到78%的分类准确率。
更多文章请关注公重号:汀丶人工智能
- References
[1] Ho, J., Kalchbrenner, N., Weissenborn, D., and Salimans, T. Axial attention in multidimensional transformers. CoRR, 2019. https://arxiv.org/pdf/1912.12180.pdf
[2] Huang, Z., Wang, X., Huang, L., Huang, C., Wei, Y., and Liu, W. Ccnet: Criss-cross attention for semantic seg- mentation. 2019. https://openaccess.thecvf.com/content_ICCV_2019/papers/Huang_CCNet_Criss-Cross_Attention_for_Semantic_Segmentation_ICCV_2019_paper.pdf
[3] Wang, H., Zhu, Y., Green, B., Adam, H., Yuille, A. L., and Chen, L. Axial-deeplab: Stand-alone axial-attention for panoptic segmentation. In Computer Vision - ECCV 2020 - 16th European Conference, 2020b. https://link.springer.com/chapter/10.1007/978-3-030-58548-8_7

- 点赞
- 收藏
- 关注作者
评论(0)