Rust 语言中应用正则表达式

作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263
邮箱 :291148484@163.com
本文地址:https://blog.csdn.net/qq_28550263/article/details/130876707
【介绍】:本文讲解 正则表达式相关概念,以及如何在 Rust 语言中使用正则表达式。
- 1. 概述
- 2. 字符串规则描述符
- 3. 创建正则表达式对象的方法
- 4. 实现其它语言正则中匹配模式标志的功能
- 5. Regex API 解析
- 5.1 核心正则表达式方法
- 5.1.1 new 方法
- 5.1.2 is_match 方法
- 5.1.3 find 方法
- 5.4 find_iter 方法
- 5.1.5 captures 方法
- 5.1.6 captures_iter 方法
- 5.1.7 split 方法
- 5.1.8 splitn 方法
- 5.1.9 replace 方法
- 5.1.10 replace_all 方法
- 5.1.11 replacen 方法
- 5.2 高级或“低级”搜索方法
- 5.2.1 shortest_match 方法
- 5.2.2 shortest_match_at 方法
- 5.2.3 is_match_at 方法
- 5.2.4 find_at 方法
- 5.2.5 captures_at 方法
- 5.2.6 captures_read 方法
- 5.2.7 captures_read_at 方法
- 5.3 辅助方法
- 附录: 查询
正则表达式用于描述各种复杂的字符串关系,使用正则表达式能够更加灵活便捷地处理字符串,它是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串搜索模式。在 Rust 语言中,目前我们主要通过 regex 模块 来使用正则表达式。 regex 模块 是一个用于解析、编译和执行正则表达式的 Rust 库。
依据该模块自己的介绍,它的语法类似于 Perl 风格的正则表达式,但是缺少一些特性,比如环视和反向引用。作为交换,所有搜索都根据正则表达式和搜索文本的大小以线性时间执行。很多语法和实现都是受RE2的启发。你可以在 https://crates.io 的 regex 模块主页中查看器最新的发布信息:https://crates.io/crates/regex,或者直接进入该模块的 Github 开源仓库查看:https://github.com/rust-lang/regex。
现在我们准备一个新的 rust 项目,来讲解如何配置使用 regex 模块:
# 新建项目
cargo new use-regex
接着,进入该项目,并安装regex:
# 进入 use-regex 项目根目录
cd use-regex
# 安装 regex 模块
cargo add regex

Tip:
如果你的安装很慢,不妨参考博文 《Crate 国内源配置》 设置和使用 rust cargo 工具的国内源镜像进行安装。
安装成功可,可以看到项目的Cargo.toml配置文件新增了一个 regex 的依赖项:

| 符号 | 描述 | 说明 |
|---|---|---|
| ^ | 匹配一个字符串的起始字符 | 如果多行标志被设置为 true,那么也匹配换行符后紧跟的位置。 |
| $ | 匹配一个字符串的结尾字符 | 如果多行标志被设置为 true,那么也匹配换行符前的位置。 |
| \b | 匹配一个单词的边界 | - |
| \B | 匹配非单词边界 |
相当于\b匹配的反集 |
例如从一篇博客的博文中,提取所有的标题:
use regex::Regex;
fn main() {
let markdown_text = "# Header 1\n## Header 2\n### Header 3\n#### Header 4\n##### Header 5\n###### Header 6";
let re = Regex::new(r"(?m)^(#{1,6})\s+(.+)$").unwrap();
for cap in re.captures_iter(markdown_text) {
let level = cap[1].len();
let header = cap[2].trim();
println!("标题等级:{};文本:\"{}\"", level, header);
}
}
其输出结果为:
标题等级:1;文本:"Header 1"
标题等级:2;文本:"Header 2"
标题等级:3;文本:"Header 3"
标题等级:4;文本:"Header 4"
标题等级:5;文本:"Header 5"
标题等级:6;文本:"Header 6"
| 符号 | 描述 | 说明 |
|---|---|---|
| ? | 匹配该限定符前的字符0或1次 |
等价于 {0,1},如 colou?r 可以匹配colour和color |
| + | 匹配该限定符前的字符1或多次 |
等价于 {1,},如 hel+o可以匹配helo、hello、helllo、… |
| * | 匹配该限定符前的字符0或多次 |
等价于 {0,},如 hel*o可以匹配heo、helo、hello、helllo、… |
| {n} | 匹配该限定符前的字符n次 |
如 hel{2}o只可以匹配hello |
| {n,} | 匹配该限定符前的字符最少n次 |
如 hel{2,}o可以匹配hello、helllo、… |
| {n,m} | 匹配该限定符前的字符最少n次,最多m次 |
如 hel{2,3}o只可以匹配hello 和 helllo |
| 符号 | 描述 | 说明 |
|---|---|---|
| \d | 匹配任意数字 | |
| \s | 匹配任意空白符 | |
| \w | 匹配任意字母、数字、下划线、汉字等 | |
| \D | 匹配任意非数字 |
|
| \S | 匹配任意非空白符 |
|
| \W | 匹配除了字母、数字、下划线、汉字以外的字符 |
|
| . | 匹配除了换行符以外的任意字符 |
| 形式 | 描述 | 说明 |
|---|---|---|
| [A-Z] | 区间匹配,匹配字母表该区间所有大写字母 | 如[C-F]匹配字符C、D、E、F |
| [a-z] | 区间匹配,匹配字母表该区间所有小写字母 | 如[c-f]匹配字符c、d、e、f |
| [0-9] | 区间匹配,匹配该区间内的所有数字 | 如[3-6]匹配字符3、4、5、6 |
| [ABCD] | 列表匹配,匹配[]中列出的所有字母 |
如这里列出的A、B、C、D都会被匹配 |
| [^ABCD] | 列表排除,匹配除了[]中列出的字符外的所有字符 |
如这里列出的A、B、C、D都会被排除而匹配其它字符 |
例如,使用正则表达式提取文本中的数字和非数字分类返回:
use regex::Regex;
use std::collections::HashMap;
// 定义一个函数,接收一个字符串参数,返回一个哈希表
fn classify_text(text: &str) -> HashMap<&str, Vec<&str>> {
// 定义一个正则表达式,匹配数字和非数字字符
let re = Regex::new(r"(\d+)|(\D+)").unwrap();
let mut map = HashMap::new();
// 遍历匹配结果
for cap in re.captures_iter(text) {
// 获取匹配到的数字或非数字字符
let value = cap.get(0).unwrap().as_str();
// 根据匹配到的数字或非数字字符,将其加入到对应的向量中
if cap.get(1).is_some() {
map.entry("数字").or_insert(Vec::new()).push(value);
} else {
map.entry("非数字").or_insert(Vec::new()).push(value);
}
}
map
}
fn main() {
let text = "abc123def456";
let result = classify_text(text);
println!("{:?}", result);
}
运行项目:
cargo run
可以看到输出结果为:
{"非数字": ["abc", "def"], "数字": ["123", "456"]}
再如,匹配IPV4地址:
use regex::Regex;
fn main() {
let re = Regex::new(r"[1-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[1-9]{1,3}").unwrap();
let text = "这是一段用于演示匹配的文本。192.168.0.1 是一个合法的 IP 地址,然而 900.300.700.600 不是.";
for cap in re.captures_iter(text) {
println!("匹配到合法的IP地址: {}", &cap[0]);
}
}
然后在你的项目目录下运行命令:
cargo run
可以从输出结果中看到文本中的前一个地址被提取出来了:
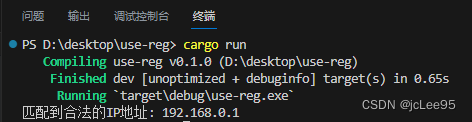
管道符就是一根竖线:|,再正则表达式中标识”或“。由于匹配方向时从左向右进行的,假如有两个正则表达式A和B,那么使用 A|B 匹配字符串时,只要前一个样式完全匹配成功,那么后一个就不再匹配。
例如:
use regex::Regex;
fn main() {
let re = Regex::new(r"hello|world").unwrap();
let text = "hello world";
for mat in re.find_iter(text) {
println!("{}", mat.as_str());
}
}
输出为:
hello
world
在正则表达式中用于标识特殊含义的符号如.用于标识一个任意的非换行符字符,^标识起始字符,等等。但是我们希望匹配到这些字符本身也是经常遇到的情况,如IPV4地址使用.作为分割符。因此我们如果需要完整提取IPV4地址就需要表示.本身。由于直接使用点已经有了其它的含义,因此我们使用一个\号进行转义,即使用\.来表示点(.)。其它在正则中有特殊含义的符号也可以使用类似的方式。
与数学计算中采用小括号()进行算式分组一样,正则模板也能够分组表达,目的是将某一部分正则模板作为一个整体表达,例如模板:
use regex::Regex;
fn main() {
let re = Regex::new(r"(\d{4})-(\d{2})-(\d{2})").unwrap();
let text = "当前的日期是 2023-05-28";
if let Some(captures) = re.captures(text) {
println!("年: {}", captures.get(1).unwrap().as_str());
println!("月: {}", captures.get(2).unwrap().as_str());
println!("日: {}", captures.get(3).unwrap().as_str());
}
}
运行项目:
cargo run
可以从输出结果中看到从文本中分别取出了年、月、日:
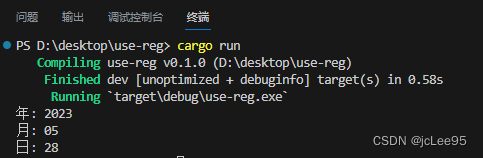
Rust中的正则表达式字面量是由斜杠(/)包围的字符串。可以使用正则表达式的方法来匹配和搜索字符串。
例如,下面的代码将匹配所有以字母“a”开头的单词:
let re = Regex::new(r"\ba\w+").unwrap();
这个正则表达式使用了单词边界(\b)和一个或多个字母数字字符(\w+)来匹配以字母“a”开头的单词。
再比如使用正则表达式来替换字符串中的所有匹配项:
let re = Regex::new(r"(\d{4})-(\d{2})-(\d{2})").unwrap();
let date_replaced = re.replace_all("Today's date is 2022-01-01", "$2/$3/$1");
这个正则表达式匹配日期格式“YYYY-MM-DD”,然后使用捕获组来重新排列日期格式为“MM/DD/YYYY”。
例如:
let re = Regex::new("^\\d{3}-\\d{2}-\\d{4}$").unwrap();
例如:
let re = Regex::new_with_options("^\\d{3}-\\d{2}-\\d{4}$", RegexOptions::MULTILINE).unwrap();
例如:
let re = match Regex::new_with_options("^\\d{3}-\\d{2}-\\d{4}$", RegexOptions::MULTILINE) {
Ok(re) => re,
Err(err) => panic!("Failed to create regex: {}", err),
};
一些语言的正则表达式,如 JavaScript、Python 等等,可以使用一定的形式指定 匹配模式,比如 JavaScript 语言中的正则表达式可以在正则表达式字面量末尾附加以下模式符号,实现相关的匹配功能:
| 符号 | 描述 | 说明 |
|---|---|---|
g |
全局匹配 | 找到所有的匹配,而不是在第一个匹配之后停止。 |
i |
忽略大小写 | 如果u标志也被启用,使用Unicode大小写折叠。 |
m |
多行匹配 | 将开始和结束字符(^ and $)视为在多行上工作。换句话说,匹配每一行的开头或结尾each line (由\n或者\r 分隔),而不仅仅是整个输入字符串的开头或结尾。 |
s |
点号匹配所有字符 | 允许. 去匹配新的行 |
u |
unicode | 将 pattern 视为 Unicode 码位序列。 参考 二进制字符串 |
y |
sticky,粘性匹配 | 仅从目标字符串中此正则表达式的 lastIndex 属性指示的索引中匹配。不尝试从任何后续索引中匹配 |
从目前笔者所使用过的所有编程看,个人最喜欢 JavaScript 提供的正则表达式用法,因为它用起来最方便。很遗憾的是,Rust 正则表达式没有类似的匹配模式写法,不过部分功能的实现,可以借用也有很多语言在用的 内联匹配模式 语法,如 C#。可以参考 内联匹配模式,以及正则对象提供的各种方法来实现。
我们先看一段使用 JavaScript 正则表达式的代码,对比使用全局匹配与否有什么区别:
const str = 'hello1 world1, hello2 world2';
const reg1 = /hello/;
const reg2 = /hello/g;
console.log(str.match(reg1));
console.log(str.match(reg2));
其输出为:
[
'hello',
index: 0,
input: 'hello1 world1, hello2 world2',
groups: undefined
]
[ 'hello', 'hello' ]
可看出,不使用全局匹配g,只匹配到第一个符合条件的字符串。而使用全局匹配g,匹配到所有符合条件的字符串。
目前在 rust 这边会显得比较 笨拙 一些,需要使用不同的方式来实现。
以查找字符串为例。如果我们不希望全局匹配,只要求第一个匹配结果时,我们可以使用 find 方法。
例如下面这个例子中,我们提取第一个年月日:
let re = Regex::new(r"(\d{4})-(\d{2})-(\d{2})").unwrap();
let text = "第一个年月日:2021-01-01, 第二个年月日:2022-02-01, 第三个年月日:2023-03-01";
let res = re.find(text).unwrap();
println!("{}",res.as_str())
其输出结果为:
2021-01-01
然而如果我们需要全局匹配,应该在返回一个包含所有满足要求结果的迭代器的方法中进行,然后对这个被返回的迭代器进行迭代遍历,以实现全局匹配效果。仍然以提取字符串为例,我们需要将上一个例子中的 find 方法改成 find_iter 方法。实现上一个例子的全局匹配提取字符串的代码改版如下:
let re = Regex::new(r"(\d{4})-(\d{2})-(\d{2})").unwrap();
let text = "第一个年月日:2021-01-01, 第二个年月日:2022-02-01, 第三个年月日:2023-03-01";
for date in re.find_iter(text) {
println!("{}", date.as_str());
}
其输出结果为:
2021-01-01
2022-02-01
2023-03-01
实际上,这个返回的迭代器就可以视为类似的数据容器使用,当然你也可以使用一个 vector 去容纳这些匹配的结果。不过总之而言相比于 JavaScript 中的那个例子,确实还是麻烦了不少。
大小写是针对英文字符的,这种匹配模式中,对于字母的大小写形式将不做区分,比如 i 和 I 都将被视作同一个字符。
以 JavaScript 为例,只需要在正则表达式末尾使用一个 i,表示忽略大小写:
console.log(/^h/i.test("Hello")); // true
console.log(/^h/i.test("hello")); // true
在 rust 中,我们目前使用只能 内联匹配模式 语法,给一个忽略指定字符大小写的例子:
let re = Regex::new(r"(?i)hello").unwrap();
let text1 = "Hello world!";
let text2 = "hello world!";
println!("{}", re.find(text1).unwrap().as_str());
println!("{}", re.find(text2).unwrap().as_str());
输出结果为:
Hello
hello
可以看到不论 h 字母大小写,都成功匹配提取出了hello。
在上一节已经接触了 内联匹配模式 的用法。这一节同样使用内联匹配模式给出一个 rust 多行匹配的例子:
let re = Regex::new(r"(?m)^\d+").unwrap();
let text = "1. First line\n2. Second line\n3. Third line";
for line in re.find_iter(text) {
println!("{}", line.as_str());
}
输出为:
1
2
3
这一节同样使用内联匹配模式给出一个 rust 中,允许 . 去匹配新的行模式的例子:
let re = Regex::new(r"(?s)hello.world").unwrap();
let text = "hello\nworld";
if let Some(matched) = re.find(text) {
println!("已匹配:{}", matched.as_str());
}
输出为:
已匹配:hello
world
你可以使用 i、s、m 的组合,实现同时使用多个匹配模式,如 (?is) 和 (?im),可以参考 内联匹配模式 。
这一节给出一个 Rust 中,将 pattern 视为 Unicode 码位序列的例子:
let re = Regex::new(r"\p{Han}+").unwrap();
let text = "你好,世界!";
if let Some(matched) = re.find(text) {
println!("已匹配: {}", matched.as_str());
}
输出结果为:
已匹配: 你好
本节解析 Regex 的 API,内容主要为对 API 文档 https://docs.rs/regex/1.8.3/regex/struct.Regex.html 的中文翻译,对于部分 API,增加了一些实际使用的例子。
pub fn new(re: &str) -> Result<Regex, Error>
编译正则表达式。一旦编译,它可以重复使用,以搜索,分割或替换字符串中的文本。
如果给出了无效的表达式,则返回一个错误。
Pub FN is_match(&self, text: &str) -> bool
当且仅当给定的字符串中有匹配的正则表达式时,返回true。
如果您需要做的只是测试一个匹配,那么建议使用这种方法,因为底层的匹配引擎可以做更少的工作。
测试某些文本是否包含至少一个正好为13个 Unicode 单词字符的单词:
let text = "I categorically deny having triskaidekaphobia.";
assert!(Regex::new(r"\b\w{13}\b").unwrap().is_match(text));
pub fn find<'t>(&self, text: &'t str) -> Option<Match<'t>>
返回文本中最左边第一个匹配的开始和结束字节范围。如果不存在匹配,则返回 None。
请注意,这应该只在您想要发现匹配的位置时使用。如果使用 is_match,测试匹配的存在会更快。
用13个Unicode单词字符查找第一个单词的开始和结束位置:
let text = "I categorically deny having triskaidekaphobia.";
let mat = Regex::new(r"\b\w{13}\b").unwrap().find(text).unwrap();
assert_eq!(mat.start(), 2);
assert_eq!(mat.end(), 15);
pub fn find_iter<'r, 't>(&'r self, text: &'t str) -> Matches<'r, 't>
为 text 中每个连续的非重叠匹配返回一个迭代器,返回相对于 text 的起始和结束字节索引。
查找每个单词的开始和结束位置,每个单词正好有13个Unicode单词字符:
let text = "Retroactively relinquishing remunerations is reprehensible.";
for mat in Regex::new(r"\b\w{13}\b").unwrap().find_iter(text) {
println!("{:?}", mat);
}
pub fn captures<'t>(&self, text: &'t str) -> Option<Captures<'t>>
返回与文本中最左边的第一个匹配相对应的捕获组。捕获组 0 始终对应于整个匹配。如果找不到匹配,则不返回任何内容。
如果您需要访问捕获组匹配的位置,您应该只使用捕获。否则,查找会更快地发现整个匹配的位置。
假设您有一些带有电影名称及其上映年份的文本,如“‘Citizen Kane’ (1941)”。如果我们可以搜索这样的文本,同时还可以分别提取电影名称和上映年份,那就太好了。
let re = Regex::new(r"'([^']+)'\s+\((\d{4})\)").unwrap();
let text = "Not my favorite movie: 'Citizen Kane' (1941).";
let caps = re.captures(text).unwrap();
assert_eq!(caps.get(1).unwrap().as_str(), "Citizen Kane");
assert_eq!(caps.get(2).unwrap().as_str(), "1941");
assert_eq!(caps.get(0).unwrap().as_str(), "'Citizen Kane' (1941)");
// You can also access the groups by index using the Index notation.
// Note that this will panic on an invalid index.
assert_eq!(&caps[1], "Citizen Kane");
assert_eq!(&caps[2], "1941");
assert_eq!(&caps[0], "'Citizen Kane' (1941)");
请注意,完全匹配发生在捕获组0。每个后续捕获组按其开始的顺序进行索引 ( 。
通过使用命名的捕获组,我们可以使这个示例更加清晰:
let re = Regex::new(r"'(?P<title>[^']+)'\s+\((?P<year>\d{4})\)")
.unwrap();
let text = "Not my favorite movie: 'Citizen Kane' (1941).";
let caps = re.captures(text).unwrap();
assert_eq!(caps.name("title").unwrap().as_str(), "Citizen Kane");
assert_eq!(caps.name("year").unwrap().as_str(), "1941");
assert_eq!(caps.get(0).unwrap().as_str(), "'Citizen Kane' (1941)");
// You can also access the groups by name using the Index notation.
// Note that this will panic on an invalid group name.
assert_eq!(&caps["title"], "Citizen Kane");
assert_eq!(&caps["year"], "1941");
assert_eq!(&caps[0], "'Citizen Kane' (1941)");
这里我们命名捕获组,我们可以用 name 方法或带 &str 的Index 符号来访问它。请注意,使用 get 或带有 usize 的 Index 符号仍然可以访问命名的捕获组。
第 0 个捕获组始终未命名,因此必须始终使用 get(0)或[0]` 来访问它。
pub fn captures_iter<'r, 't>(&'r self, text: &'t str) -> CaptureMatches<'r, 't>
返回文本中匹配的所有非重叠捕获组的迭代器。这在操作上与 find_iter 相同,除了它产生关于捕获组匹配的信息。
我们可以使用它在一些文本中查找所有电影名称及其发行年份,其中电影的格式类似于“’ Title’ (xxxx)”:
let re = Regex::new(r"'(?P<title>[^']+)'\s+\((?P<year>\d{4})\)")
.unwrap();
let text = "'Citizen Kane' (1941), 'The Wizard of Oz' (1939), 'M' (1931).";
for caps in re.captures_iter(text) {
println!("Movie: {:?}, Released: {:?}",
&caps["title"], &caps["year"]);
}
输出为:
Movie: Citizen Kane, Released: 1941
Movie: The Wizard of Oz, Released: 1939
Movie: M, Released: 1931
pub fn split<'r, 't>(&'r self, text: &'t str) -> Split<'r, 't>
返回由匹配的正则表达式分隔的文本子字符串的迭代器。也就是说,迭代器的每个元素对应于正则表达式不匹配的文本。
此方法不会复制给定的文本。
要拆分由任意数量的空格或制表符分隔的字符串:
let re = Regex::new(r"[ \t]+").unwrap();
let fields: Vec<&str> = re.split("a b \t c\td e").collect();
assert_eq!(fields, vec!["a", "b", "c", "d", "e"]);
pub fn splitn<'r, 't>(&'r self, text: &'t str, limit: usize) -> SplitN<'r, 't>
返回最多有限个文本子字符串的迭代器,这些子字符串由正则表达式的匹配项分隔。(限制为0将不会返回任何子字符串。)也就是说,迭代器的每个元素对应于正则表达式不匹配的文本。字符串中未被拆分的剩余部分将是迭代器中的最后一个元素。
此方法不会复制给定的文本。
获取某些文本中的前两个单词:
let re = Regex::new(r"\W+").unwrap();
let fields: Vec<&str> = re.splitn("Hey! How are you?", 3).collect();
assert_eq!(fields, vec!("Hey", "How", "are you?"));
pub fn replace<'t, R: Replacer>(&self, text: &'t str, rep: R) -> Cow<'t, str>
用提供的替换项替换最左边的第一个匹配项。替换可以是一个常规字符串(其中�和name被扩展以匹配捕获组),也可以是一个获取匹配捕获并返回替换字符串的函数。
如果没有找到匹配,则返回该字符串的副本,不做任何更改。
替换文本中 $name 的所有实例都将替换为相应的捕获组 name。
name 可以是与捕获组的索引相对应的整数(按左括号的顺序计数,其中0表示整个匹配),也可以是与命名的捕获组相对应的名称(由字母、数字或下划线组成)。
如果 name 不是有效的捕获组(无论该名称不存在还是不是有效的索引),那么它将被替换为空字符串。
使用尽可能长的名称。例如,$1a 查找名为 1a 的捕获组,而不是索引 1 处的捕获组。要对名称进行更精确的控制,请使用大括号,例如 ${1}a。
要编写文字 $请使用$$。
注意,这个函数对于替换是多态的。在典型的用法中,这可能只是一个普通的字符串:
let re = Regex::new("[^01]+").unwrap();
assert_eq!(re.replace("1078910", ""), "1010");
但是任何满足替代品特性的东西都可以工作。例如,类型为 |&Captures| -> String 的闭包提供了对与匹配相对应的捕获的直接访问。这允许人们容易地访问捕获组匹配:
let re = Regex::new(r"([^,\s]+),\s+(\S+)").unwrap();
let result = re.replace("Springsteen, Bruce", |caps: &Captures| {
format!("{} {}", &caps[2], &caps[1])
});
assert_eq!(result, "Bruce Springsteen");
但是一直使用这个有点麻烦。相反,支持一个简单的语法,将 $name 展开到相应的捕获组中。这是最后一个示例,但是使用命名捕获组的扩展技术:
let re = Regex::new(r"(?P<last>[^,\s]+),\s+(?P<first>\S+)").unwrap();
let result = re.replace("Springsteen, Bruce", "$first $last");
assert_eq!(result, "Bruce Springsteen");
请注意,使用 $2 而不是 $first 或 $1 而不是 $last 会产生相同的结果。要编写文字 $ 请使用 $$。
有时,替换字符串需要使用花括号来描述捕获组替换和周围的文字文本。例如,如果我们想用下划线将两个单词连在一起:
let re = Regex::new(r"(?P<first>\w+)\s+(?P<second>\w+)").unwrap();
let result = re.replace("deep fried", "${first}_$second");
assert_eq!(result, "deep_fried");
如果没有花括号,将使用捕获组名 first_ 因为它不存在,所以将被空字符串替换。
最后,有时您只想替换一个文字字符串,而不考虑捕获组扩展。这可以通过用NoExpand包装一个字节字符串来实现:
use regex::NoExpand;
let re = Regex::new(r"(?P<last>[^,\s]+),\s+(\S+)").unwrap();
let result = re.replace("Springsteen, Bruce", NoExpand("$2 $last"));
assert_eq!(result, "$2 $last");
pub fn replace_all<'t, R: Replacer>(
&self,
text: &'t str,
rep: R
) -> Cow<'t, str>
用提供的替换内容替换文本中所有不重叠的匹配内容。这与调用limit设置为0的replacen是一样的。
pub fn replacen<'t, R: Replacer>(
&self,
text: &'t str,
limit: usize,
rep: R
) -> Cow<'t, str>
pub fn shortest_match(&self, text: &str) -> Option<usize>
返回给定文本中匹配的结束位置。
该方法可以具有与 is_match 相同的性能特征,除了它提供了匹配的结束位置。特别是,返回的位置可能比通过 Regex::find 找到的最左边第一个匹配的正确结尾要短。
注意,不能保证这个例程找到最短或“最早”的可能匹配。相反,这个 API 的主要思想是,它返回内部正则表达式引擎确定发生匹配的点的偏移量。这可能因使用的内部正则表达式引擎而异,因此偏移量本身可能会改变。
通常,a+ 会匹配某个文本中 a 的整个第一个序列,但是shortest_match 一看到第一个 a 就会放弃:
let text = "aaaaa";
let pos = Regex::new(r"a+").unwrap().shortest_match(text);
assert_eq!(pos, Some(1));
pub fn shortest_match_at(&self, text: &str, start: usize) -> Option<usize>
返回与 shortest_match 相同的值,但从给定的偏移量开始搜索。
起点的意义在于它考虑了周围的环境。例如,\A 定位点只能在 start == 0 时匹配。
let re = Regex::new(r"\d+").unwrap();
// 在字符串中查找最短匹配
let text = "123456789";
let shortest_match = re.shortest_match_at(text, 0).unwrap();
println!("Shortest match found at index {}", shortest_match.end());
pub fn is_match_at(&self, text: &str, start: usize) -> bool
返回与 is_match 相同的值,但从给定的偏移量开始搜索。
起点的意义在于它考虑了周围的环境。例如,\A 锚点只能在 start == 0 时匹配。
let re = Regex::new(r"\d{3}-\d{2}-\d{4}").unwrap();
let s = "123-45-6789";
// 使用is_match_at方法判断字符串是否匹配正则表达式
if re.is_match_at(s, 0) {
println!("Matched!");
} else {
println!("Not matched!");
}
pub fn find_at<'t>(&self, text: &'t str, start: usize) -> Option<Match<'t>>
返回与 find 相同的值,但从给定的偏移量开始搜索。
起点的意义在于它考虑了周围的环境。例如,\A 锚点只能在 start == 0 时匹配。
let s = "hello world";
let re = Regex::new(r"world").unwrap();
// 使用find_at方法查找字符串中第一个匹配正则表达式的位置
let pos = re.find_at(s, 0).unwrap().start();
// 输出匹配位置
println!("Match found at position: {}", pos);
ub fn captures_at<'t>(
&self,
text: &'t str,
start: usize
) -> Option<Captures<'t>>
返回与 Regex::captures 相同的值,但从给定的偏移量开始搜索。
起点的意义在于它考虑了周围的环境。例如,\A 锚点只能在 start == 0 时匹配。
let re = Regex::new(r"(\d{4})-(\d{2})-(\d{2})").unwrap();
let text = "2022-10-31";
let year = re.captures_at(text, 1).unwrap().as_str();
let month = re.captures_at(text, 2).unwrap().as_str();
let day = re.captures_at(text, 3).unwrap().as_str();
println!("Year: {}, Month: {}, Day: {}", year, month, day);
pub fn captures_read<'t>(
&self,
locs: &mut CaptureLocations,
text: &'t str
) -> Option<Match<'t>>
这类似于 captures ,但使用 CaptureLocations 而不是 Captures 来分摊分配。
若要创建 CaptureLocations 值,请使用Regex::capture_locations 方法。
如果匹配成功,将返回总匹配,总匹配等同于第 0 个捕获组。
// 用于匹配字符串中的数字
let re = Regex::new(r"\d+").unwrap();
let test_str = "abc123def456ghi789jkl";
// 使用captures_read方法,从字符串中读取匹配到的数字
let mut captures = re.captures_read(test_str.as_bytes());
// 遍历匹配到的数字
while let Some(capture) = captures.next() {
println!("{}", std::str::from_utf8(capture.unwrap().as_bytes()).unwrap());
}
fn captures_read_at<'t>(
&self,
locs: &mut CaptureLocations,
text: &'t str,
start: usize
) -> Option<Match<'t>>
返回与捕获相同的值,但从给定的偏移量开始搜索,并填充给定的捕获位置。
起点的意义在于它考虑了周围的环境。例如,\A锚点只能在start == 0时匹配。
let re = Regex::new(r"(\d{4})-(\d{2})-(\d{2})").unwrap();
let text = "Today is 2022-01-01.";
if let Some(captures) = re.captures(text) {
println!("Year: {}, Month: {}, Day: {}", captures.get(1).unwrap().as_str(), captures.get(2).unwrap().as_str(), captures.get(3).unwrap().as_str());
} else {
println!("No match found");
}
pub fn as_str(&self) -> &str
返回该正则表达式的原始字符串。
let re = Regex::new(r"\d+").unwrap();
let text = "2021-08-01";
let result = re.find(text).unwrap();
println!("{}", result.as_str());
pub fn capture_names(&self) -> CaptureNames<'_>
返回捕获名称的迭代器。
pub fn captures_len(&self) -> usize
返回捕获的数量。
pub fn static_captures_len(&self) -> Option<usize>
返回出现在每个可能匹配项中的捕获组的总数。
如果捕获组的数量因匹配而异,则返回 None。也就是说,只有当匹配组的数量不变或“static”时,才会返回值。
注意,像 Regex::captures_len 一样,这也包含了对应于整个匹配的隐式捕获组。因此,当返回一个非 None 值时,它保证至少为 1。换句话说,返回值 Some(0) 是不可能的。
这个例子显示了静态数量的捕获组可用和不可用的几种情况。
use regex::Regex;
let len = |pattern| {
Regex::new(pattern).map(|re| re.static_captures_len())
};
assert_eq!(Some(1), len("a")?);
assert_eq!(Some(2), len("(a)")?);
assert_eq!(Some(2), len("(a)|(b)")?);
assert_eq!(Some(3), len("(a)(b)|(c)(d)")?);
assert_eq!(None, len("(a)|b")?);
assert_eq!(None, len("a|(b)")?);
assert_eq!(None, len("(b)*")?);
assert_eq!(Some(2), len("(b)+")?);
pub fn capture_locations(&self) -> CaptureLocations
返回一组空的捕获位置,这些位置可以在多次调用 captures_read 或 captures_read_at 时重用。
| 字符 | 描述 |
|---|---|
\ |
将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,‘n’ 匹配字符 “n”。‘\n’ 匹配一个换行符。序列 ‘\’ 匹配 “” 而 “(” 则匹配 “(”。 |
^ |
匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 |
$ |
匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。 |
* |
匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。 |
+ |
匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
? |
匹配前面的子表达式零次或一次。例如,“do(es)?” 可以匹配 “do” 或 “does” 。? 等价于 {0,1}。 |
{n} |
n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
{n,} |
n 是一个非负整数。至少匹配n 次。例如,‘o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。‘o{1,}’ 等价于 ‘o+’。‘o{0,}’ 则等价于 ‘o*’。 |
{n,m} |
m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,“o{1,3}” 将匹配 “fooooood” 中的前三个 o。‘o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
? |
当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 “oooo”,‘o+?’ 将匹配单个 “o”,而 ‘o+’ 将匹配所有 ‘o’。 |
. |
匹配除换行符(\n、\r)之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用像"(.|\n)"的模式。 |
(pattern) |
匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 ‘(’ 或 ‘)’。 |
(?:pattern) |
匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 “或” 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 ‘industry|industries’ 更简略的表达式。 |
(?=pattern) |
正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)“能匹配"Windows2000"中的"Windows”,但不能匹配"Windows3.1"中的"Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
(?!pattern) |
正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如"Windows(?!95|98|NT|2000)“能匹配"Windows3.1"中的"Windows”,但不能匹配"Windows2000"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
(?<=pattern) |
反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,"`(?<=95 |
(?<!pattern) |
反向否定预查,与正向否定预查类似,只是方向相反。例如"`(?<!95 |
x|y |
匹配 x 或 y。例如,‘z|food’ 能匹配 “z” 或 “food”。‘(z|f)ood’ 则匹配 “zood” 或 “food”。 |
[xyz] |
字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 |
[^xyz] |
负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’、‘l’、‘i’、‘n’。 |
[a-z] |
字符范围。匹配指定范围内的任意字符。例如,‘[a-z]’ 可以匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符。 |
[^a-z] |
负值字符范围。匹配任何不在指定范围内的任意字符。例如,‘[^a-z]’ 可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符。 |
\b |
匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
\B |
匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
\cx |
匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
\d |
匹配一个数字字符。等价于 [0-9]。 |
\D |
匹配一个非数字字符。等价于 [^0-9]。 |
\f |
匹配一个换页符。等价于 \x0c 和 \cL。 |
\n |
匹配一个换行符。等价于 \x0a 和 \cJ。 |
\r |
匹配一个回车符。等价于 \x0d 和 \cM。 |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
\S |
匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
\t |
匹配一个制表符。等价于 \x09 和 \cI。 |
\v |
匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
\w |
匹配字母、数字、下划线。等价于’[A-Za-z0-9_]'。 |
\W |
匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]’。 |
\xn |
匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,‘\x41’ 匹配 “A”。‘\x041’ 则等价于 ‘\x04’ & “1”。正则表达式中可以使用 ASCII 编码。 |
\num |
匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,‘(.)\1’ 匹配两个连续的相同字符。 |
\n |
标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
\nm |
标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
\nml |
如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
\un |
匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
| 运算符 | 描述 |
|---|---|
\ |
转义符 |
(), (?:), (?=), [] 圆括号和方括号 |
|
*, +, ?, {n}, {n,}, {n,m} |
限定符 |
^, $, \任何元字符、任何字符 |
定位点和序列(即:位置和顺序) |
| ` | ` |
| 匹配模式语法 | 描述 |
|---|---|
(?i) |
右侧的表达式忽略大小写 |
(?s) |
右侧的表达式单行匹配 |
(?m) |
右侧的表示式开启指定多行 |
(?is) |
右侧的表示式忽略大小写 且 单行匹配 |
(?im) |
右侧的表示式忽略大小写 且 多行匹配 |

- 点赞
- 收藏
- 关注作者
评论(0)