机器学习 - [源码实现决策树小专题]决策树中子数据集的划分(不允许调用sklearn等库的源代码实现)

推荐: 本文中的代码另外有采用了TypeScript/JavaScript进行实现的版本。作者关注到,谷歌TensorFlow团队近几年在JavaScript语言上动作频频,自推出同接口的JavaSccript版本TensorFlow.js后,在2020年先后右推出与Pandas同接口的JavaScript版本库"Danfo.js",同时配套推出了一个类似于Jupyter的笔记本"Dnotebook"(Danfo Dotebook,这个笔记本不好用,但动向很引发人们的关注)。紧接着改团队出版了JavaScript领域头一本以TensorFlow为主详细讲解深度学习的图书,并在不久后于2021年4月被翻译为中文版在人民邮电出版社发行,他就是斯坦利`比列斯奇等人所著的《JavaScript深度学习》。本文笔者认为,使用JavaScript家族的语言实现数据领域的相关算法在未来有助于实现分布式的云计算等潜在商业价值巨大的特点,同时相比于Python语言,JavaScript(含TypeScript等)更能绘制精致并且具有动态效果的图标,数据可视化能力更是远非Python可比。对于感兴趣的同学可以参考本文的TypeScript/JavaScript版本,链接:TypeScript机器学习:决策树算法中子数据集的划分
李俊才 的 CSDN 博客
邮箱 :291148484@163.com
CSDN 主页:https://blog.csdn.net/qq_28550263?spm=1001.2101.3001.5343
本文地址:https://blog.csdn.net/qq_28550263/article/details/123649691
阅读本文后推荐先阅读:信息增益与信息增益率计算的Python实现:https://blog.csdn.net/qq_28550263/article/details/114891368
导读: 本文我们将解决两个问题,一个是为什么我们要划分数据集,另一个是如何用代码实现数据集划分。
1. 经典决策树算法思想回顾
决策树算法包括建树(训练)和查树(决策/预测)两个环节。在决策树算法的训练过程中对于决定一个事件最终决策的多个特征(决策考虑因素),我们一般基于如信息增益率、基尼系数等指标先确定出一个能最大化获取信息的特征作为当前最佳特征。一个特征映射为在一颗决策树中的一个节点。
第一个“最佳特征”对应的·节点我们称之为根节点。每次到达一个节点处,我们依据节点处特征的不同取值,对节点进行分支以生长出其子节点,子节点处继续着它们各自父辈的故事。直到某个时候,不满足人为干预的一些条件了,或者完美地完成分类了,这时子节点不再继续分支而成为决策树的叶子节点。
2.为什么需要划分数据集
已经说过,在决策树训练过程中需要不断地进行分支操作。从一颗树的生长过程来看每次分支是为了去树的下一个节点,而对应成特征的角度说,分支的本质其实是使用了上一个一个特征仍然没能完成最终决策时,使用下一个特征进行继续决策。
在我们的标签集(labels)中,它在训练之初拥有多条数据,每条数据都对应了实际情况中每个特征的取值。一次分支使用到的时一个特征,实际上就是比对哪些数据条需要划分到该该特征分支值与这条数据在该特征下取值相等的一侧。
从上面我们看到,只有划分数据集才能让数据集中的每一条数据各有归属,这就是为什么我们需要划分数据集。
举一个小例子并用绘图来示意。
【引例】:李华是否打球的决策分析。
以下是李华在过去9天是否打球的历史数据(原始数据集):
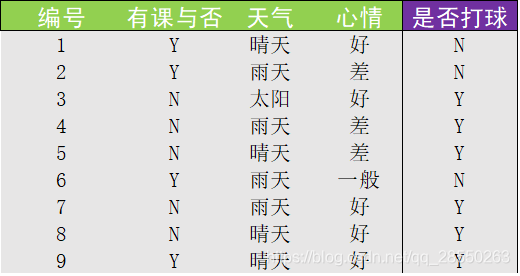
假设我们现在确定了"有课与否"作为是否打球的判断依据进行第一次划分,那么有两种分支情况:
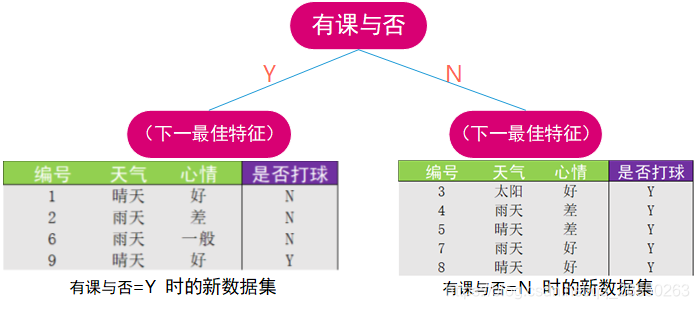
3. 如何进行数据集的划分(Python代码的实现)
3.1 划分步骤的详解
依上所述,划分数据集以获取子数据集的过程就是一个数据过滤的过程。这个过程的实现需要我们做两件事:
- 一是过滤掉非节点特征当前之路取值的数据
- 而是要在当前特征值划分所有数据过滤完成之后,删除已经用过的特征。
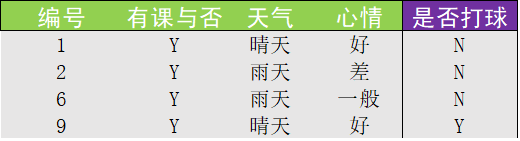
在上例中,以验证"有课与否"取"Y"划分数据集为例:
- 第一步:过滤掉所有"有课与否"取"N"的数据,得到结果如下:

- 第二步:删除已经用过的特征"有课与否",得到本次划分最终完成的数据集如下:
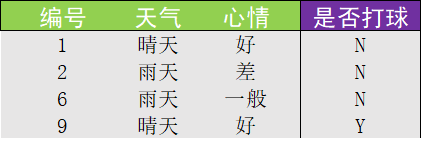
3.2 使用编程实现对数据集的划分
在理解了上述过程之后,我们趁热打铁,使用Python语言来编程实现该数据集划分的全部过程。
假设用x_train与y_train来表示训练集数据的特征列取值们与标签列,它们分别是多维和一维数组。
为了方便读者观察,以拥有10条数据、一共43个特征的数据集为例,其中x_train的样式形如:
array([[1, 4, 2, 0, 3, 1, 1, 0, 1, 4, 2, 4, 4, 2, 4, 2, 0, 2, 2, 0, 0, 0, 0, 0, 1, 0, 0, 2, 0, 3, 1, 3, 1, 3, 1, 1, 0, 1, 4, 3, 4, 4, 2],
[0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 1, 2, 3, 0, 3, 1, 1, 0, 0, 4, 2, 2, 4, 1, 1, 0, -1, 0, 4, 0, -1, -1, 0, 0, 0, 0, 0, 0, 2],
[4, 2, 2, 3, 1, 2, 1, 1, 0, 2, 1, 1, 1, 0, 3, 0, 3, 2, 2, 0, 0, 0, 0, 3, 1, 1, 2, 3, 4, 3, 1, 1, 3, 1, 2, 1, 1, 0, 1, 2, 2, 1, 0],
[1, 4, 2, 2, 3, 1, 1, 0, 0, 2, 1, 1, 1, 0, 3, 4, 2, 2, 4, 1, 0, 1, 0, 3, 2, 2, 4, 3, 1, 2, -1, 2, 2, 1, 0, 1, -1, 0, 1, 1, 1, 0, 0],
[1, 2, 2, 1, 3, 1, 1, 0, 0, 2, 2, 1, 1, 0, 0, 4, 1, 2, 1, 0, 0, 0, 0, 2, 1, 1, 2, 3, 3, 0, -1, 2, 1, 3, 1, 1, 0, 0, 2, 3, 2, 1, 0],
[1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 3, 3, 2, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 3, 3, 2, 4, 2, 2, -1, 2, 2, 3, 0, 0, 0, 0, 2, 2, 2, 2, 0],
[1, 1, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 2, 0, 3, 2, 1, 1, 0, 2, 2, 1, 0, 3, 3, 2, 1, 1, 3, 0, -2, -1, -1, 0, 1, 0, 2, 2, 1],
[0, 0, 3, 3, 2, 0, 0, 0, 0, 3, 3, 3, 0, 2, 1, 3, 3, 3, 2, 1, 1, 0, 0, 3, 4, 4, 1, 2, 1, 0, 1, 2, 2, 1, -1, -1, 0, 0, 2, 1, 2, 1, 2],
[2, 4, 2, 0, 2, 1, 0, 1, 0, 2, 2, 3, 4, 2, 2, 3, 0, 2, 0, 1, 1, 0, 0, 0, 3, 3, 0, 4, 2, 2, 1, 3, 1, 4, 0, -1, 1, 0, 3, 1, 2, 4, 0],
[1, 4, 1, 0, 1, 0, 0, 0, 0, 3, 2, 3, 3, 4, 4, 1, 0, 1, 0, 1, 0, 1, 0, 0, 2, 1, 4, 2, 0, 4, 1, 3, 1, 3, -1, 0, -1, 0, 3, 2, 3, 2, 3]],
dtype=object)
其中y_train的样式形如:
array([1, 0, 0, 1, 0, 0, 1, 0, 0, 1], dtype=int64)
接下来到了激动人心的数据集划分函数dividing_data_set()的编程环节。
为了方便在数据集中索引到各个特征,我们先将数据集转换为方便索引的数据字典。以下采用jupyter调试。
import numpy as np
# 定义模拟数据
x_train = ... # 采用上面的x_train,这里省略
y_train = ... # 采用上面的y_train,这里省略
features = ["feature_"+str(i) for i in range(43)] # 产生43个不同的特征名字
node_feature = "feature_13" # 定义当前节点的特征名
node_feature_value = 2 # 定义对于当前节点的特征取值为2,之后就是求 node_feature 在 node_feature取2下的划分
# 转换为数据集字典
date_set = dict(zip(features,x_train.T)) # 注意x_train需要转置
date_set.update({"labels":y_train}) # 将标签集(labels,也就是输出y们)也加入数据集
date_set # 查看一下整理的数据样式
Out[i]:
{'feature_0': array([1, 0, 4, 1, 1, 1, 1, 0, 2, 1]),
'feature_1': array([4, 0, 2, 4, 2, 0, 1, 0, 4, 4]),
'feature_2': array([2, 0, 2, 2, 2, 0, 0, 3, 2, 1]),
'feature_3': array([0, 3, 3, 2, 1, 0, 2, 3, 0, 0]),
'feature_4': array([3, 0, 1, 3, 3, 1, 0, 2, 2, 1]),
'feature_5': array([1, 0, 2, 1, 1, 0, 0, 0, 1, 0]),
'feature_6': array([1, 0, 1, 1, 1, 0, 0, 0, 0, 0]),
'feature_7': array([0, 0, 1, 0, 0, 0, 0, 0, 1, 0]),
'feature_8': array([1, 0, 0, 0, 0, 0, 0, 0, 0, 0]),
'feature_9': array([4, 0, 2, 2, 2, 1, 0, 3, 2, 3]),
'feature_10': array([2, 0, 1, 1, 2, 3, 0, 3, 2, 2]),
'feature_11': array([4, 0, 1, 1, 1, 3, 0, 3, 3, 3]),
'feature_12': array([4, 1, 1, 1, 1, 2, 0, 0, 4, 3]),
'feature_13': array([2, 2, 0, 0, 0, 0, 2, 2, 2, 4]),
'feature_14': array([4, 1, 3, 3, 0, 1, 0, 1, 2, 4]),
'feature_15': array([2, 2, 0, 4, 4, 0, 0, 3, 3, 1]),
'feature_16': array([0, 3, 3, 2, 1, 0, 2, 3, 0, 0]),
'feature_17': array([2, 0, 2, 2, 2, 0, 0, 3, 2, 1]),
'feature_18': array([2, 3, 2, 4, 1, 0, 3, 2, 0, 0]),
'feature_19': array([0, 1, 0, 1, 0, 0, 2, 1, 1, 1]),
'feature_20': array([0, 1, 0, 0, 0, 0, 1, 1, 1, 0]),
'feature_21': array([0, 0, 0, 1, 0, 0, 1, 0, 0, 1]),
'feature_22': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0]),
'feature_23': array([0, 4, 3, 3, 2, 1, 2, 3, 0, 0]),
'feature_24': array([1, 2, 1, 2, 1, 3, 2, 4, 3, 2]),
'feature_25': array([0, 2, 1, 2, 1, 3, 1, 4, 3, 1]),
'feature_26': array([0, 4, 2, 4, 2, 2, 0, 1, 0, 4]),
'feature_27': array([2, 1, 3, 3, 3, 4, 3, 2, 4, 2]),
'feature_28': array([0, 1, 4, 1, 3, 2, 3, 1, 2, 0]),
'feature_29': array([3, 0, 3, 2, 0, 2, 2, 0, 2, 4]),
'feature_30': array([ 1, -1, 1, -1, -1, -1, 1, 1, 1, 1]),
'feature_31': array([3, 0, 1, 2, 2, 2, 1, 2, 3, 3]),
'feature_32': array([1, 4, 3, 2, 1, 2, 3, 2, 1, 1]),
'feature_33': array([3, 0, 1, 1, 3, 3, 0, 1, 4, 3]),
'feature_34': array([ 1, -1, 2, 0, 1, 0, -2, -1, 0, -1]),
'feature_35': array([ 1, -1, 1, 1, 1, 0, -1, -1, -1, 0]),
'feature_36': array([ 0, 0, 1, -1, 0, 0, -1, 0, 1, -1]),
'feature_37': array([1, 0, 0, 0, 0, 0, 0, 0, 0, 0]),
'feature_38': array([4, 0, 1, 1, 2, 2, 1, 2, 3, 3]),
'feature_39': array([3, 0, 2, 1, 3, 2, 0, 1, 1, 2]),
'feature_40': array([4, 0, 2, 1, 2, 2, 2, 2, 2, 3]),
'feature_41': array([4, 0, 1, 0, 1, 2, 2, 1, 4, 2]),
'feature_42': array([2, 2, 0, 0, 0, 0, 1, 2, 0, 3]),
'labels': array([1, 0, 0, 1, 0, 0, 1, 0, 0, 1])}
def dividing_data_set(date_set,node_feature,node_feature_value):
"""
划分数据集
整个划分方法的思想是"记录索引-重索引"。简而言之就是先记住特征取值为指定取值的索引号,然
后依据记录索引号保对其它特征下同索引号的元素进行保留。最终实现留下当前划分数据条的目的。
Parameters
----------
date_set: "dict"结构的数据集,其中键为”labels“的键值对对应为标签集(源于x_train),其余
的对应为特征取值键值对(源于y_train)。
node_feature:可以是num、str等类型,但是必须和date_set中的键的类型保持一致。表示需要划分
数据集的节点处对应的特征名。
node_feature_value:是对应与 node_feature 的一个特定取值。
Returns
-------
result : dict
返回子数据集字典,其形式与date_set保持一致。其中键`labels`对应的值类似是子标签集数组。
"""
# 先获取对应特征 node_feature 在数据集中所有条数据的有序取值数组
feature_in_sets = date_set[node_feature]
# 记录所有取值为 node_feature_value 数据编号
reserved_group = [i for i in range(len(feature_in_sets)) if feature_in_sets[i]==node_feature_value]
# 接着依据 reserved_group 中的组号保留属于当前分支的数据
sub_date_set = {}
for the_key in date_set:
sub_date_set[the_key] = np.array([date_set[the_key][i] for i in reserved_group])
# 最后,删除用过的特征列
del(sub_date_set[node_feature])
return sub_date_set
# 调用函数,执行子数据集划分
dividing_data_set(date_set,node_feature,node_feature_value)
Out[i]:
{'feature_0': array([1, 0, 1, 0, 2]),
'feature_1': array([4, 0, 1, 0, 4]),
'feature_2': array([2, 0, 0, 3, 2]),
'feature_3': array([0, 3, 2, 3, 0]),
'feature_4': array([3, 0, 0, 2, 2]),
'feature_5': array([1, 0, 0, 0, 1]),
'feature_6': array([1, 0, 0, 0, 0]),
'feature_7': array([0, 0, 0, 0, 1]),
'feature_8': array([1, 0, 0, 0, 0]),
'feature_9': array([4, 0, 0, 3, 2]),
'feature_10': array([2, 0, 0, 3, 2]),
'feature_11': array([4, 0, 0, 3, 3]),
'feature_12': array([4, 1, 0, 0, 4]),
'feature_14': array([4, 1, 0, 1, 2]),
'feature_15': array([2, 2, 0, 3, 3]),
'feature_16': array([0, 3, 2, 3, 0]),
'feature_17': array([2, 0, 0, 3, 2]),
'feature_18': array([2, 3, 3, 2, 0]),
'feature_19': array([0, 1, 2, 1, 1]),
'feature_20': array([0, 1, 1, 1, 1]),
'feature_21': array([0, 0, 1, 0, 0]),
'feature_22': array([0, 0, 0, 0, 0]),
'feature_23': array([0, 4, 2, 3, 0]),
'feature_24': array([1, 2, 2, 4, 3]),
'feature_25': array([0, 2, 1, 4, 3]),
'feature_26': array([0, 4, 0, 1, 0]),
'feature_27': array([2, 1, 3, 2, 4]),
'feature_28': array([0, 1, 3, 1, 2]),
'feature_29': array([3, 0, 2, 0, 2]),
'feature_30': array([ 1, -1, 1, 1, 1]),
'feature_31': array([3, 0, 1, 2, 3]),
'feature_32': array([1, 4, 3, 2, 1]),
'feature_33': array([3, 0, 0, 1, 4]),
'feature_34': array([ 1, -1, -2, -1, 0]),
'feature_35': array([ 1, -1, -1, -1, -1]),
'feature_36': array([ 0, 0, -1, 0, 1]),
'feature_37': array([1, 0, 0, 0, 0]),
'feature_38': array([4, 0, 1, 2, 3]),
'feature_39': array([3, 0, 0, 1, 1]),
'feature_40': array([4, 0, 2, 2, 2]),
'feature_41': array([4, 0, 2, 1, 4]),
'feature_42': array([2, 2, 1, 2, 0]),
'labels': array([1, 0, 1, 0, 0])}
可以看到,划分数据集后在子数据集中,所有特征中对应划分前"feature_13"取值为2的数据被保留了下来,同时由于特征"feature_13"已经使用过了,子数据集中不再有"feature_13"。符合数据集划分要求。
附: 举个更简单的实例
| Q:上面例子数据太复杂了,我没看明白。能否用文章开头的引例给我们来一次? |
| A:必须安排! |
import numpy as np
# 定义数据
x_train = np.array([["Y","晴天","好"],
["Y","雨天","差"],
["N","太阳","好"],
["N","雨天","差"],
["N","晴天","差"],
["Y","雨天","一般"],
["N","雨天","好"],
["N","晴天","好"],
["Y","晴天","好"],
])
y_train = np.array(["N", "N", "Y", "Y", "Y", "N", "Y", "Y", "Y"])
features = ["有课与否","天气","心情"] # 产生43个不同的特征名字
node_feature = "有课与否" # 定义当前节点的特征名
node_feature_value = "Y" # 定义对于当前节点的特征取值为2,之后就是求 node_feature 在 node_feature取2下的划分
# 转换为数据集字典
date_set = dict(zip(features,x_train.T)) # 注意需要转置
date_set.update({"labels":y_train}) # 将标签集(labels,也就是输出y们)也加入数据集
date_set
Out[i]:
{'有课与否': array(['Y', 'Y', 'N', 'N', 'N', 'Y', 'N', 'N', 'Y'], dtype='<U2'),
'天气': array(['晴天', '雨天', '太阳', '雨天', '晴天', '雨天', '雨天', '晴天', '晴天'], dtype='<U2'),
'心情': array(['好', '差', '好', '差', '差', '一般', '好', '好', '好'], dtype='<U2'),
'labels': array(['N', 'N', 'Y', 'Y', 'Y', 'N', 'Y', 'Y', 'Y'], dtype='<U1')}
def dividing_data_set(date_set,node_feature,node_feature_value):
"""划分数据集"""
# 先获取对应特征 node_feature 在数据集中所有条数据的有序取值数组
feature_in_sets = date_set[node_feature]
# 记录所有取值为 node_feature_value 数据编号
reserved_group = [i for i in range(len(feature_in_sets)) if feature_in_sets[i]==node_feature_value]
# 接着依据 reserved_group 中的组号保留属于当前分支的数据
sub_date_set = {}
for the_key in date_set:
sub_date_set[the_key] = np.array([date_set[the_key][i] for i in reserved_group])
# 最后,删除用过的特征列
del(sub_date_set[node_feature])
return sub_date_set
dividing_data_set(date_set,node_feature,node_feature_value)
Out[i]:
{'天气': array(['晴天', '雨天', '雨天', '晴天'], dtype='<U2'),
'心情': array(['好', '差', '一般', '好'], dtype='<U2'),
'labels': array(['N', 'N', 'N', 'Y'], dtype='<U1')}
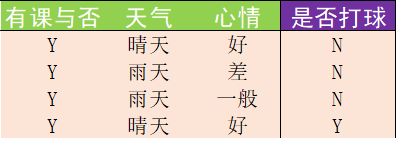
这不就是在文章开头的引例中,我们手动划分当特征'有课与否'取"Y"下的子数据集的么:
觉得写的不错或者对你有帮助的话,记得来个三连加关注噢!

- 点赞
- 收藏
- 关注作者
评论(0)