深度学习应用篇-计算机视觉-目标检测[4]:综述、边界框bounding box、锚框(Anchor box)、交并比、非极大值

深度学习应用篇-计算机视觉-目标检测[4]:综述、边界框bounding box、锚框(Anchor box)、交并比、非极大值抑制NMS、SoftNMS
1.目标检测综述
对计算机而言,能够“看到”的是图像被编码之后的数字,它很难理解高层语义概念,比如图像或者视频帧中出现的目标是人还是物体,更无法定位目标出现在图像中哪个区域。目标检测的主要目的是让计算机可以自动识别图片或者视频帧中所有目标的类别,并在该目标周围绘制边界框,标示出每个目标的位置,如 图1 所示。

图1 图像分类和目标检测示意图
- 图1(a)是图像分类任务,只需对这张图片进行类别识别。
- 图1(b)是目标检测任务,不仅要识别出这一张图片中的类别为斑马,还要标出图中斑马的位置。
1.1 应用场景
如 图2 所示,如今的目标检测不论在日常生活中还是工业生产中都有着非常多的应用场景。
消费娱乐:智能手机的人脸解锁以及支付APP中的人脸支付;自动售货机使用的商品检测;视频网站中图片、视频审核等;
智慧交通:自动驾驶中的行人检测、车辆检测、红绿灯检测等;
工业生产:工业生产中的零件计数、缺陷检测;设备巡检场景下的设备状态监控;厂区中的烟火检测、安全帽检测等;
智慧医疗:眼底、肺部等器官病变检测;新冠疫情中的口罩检测等。


图2 目标检测应用场景
1.2 目标检测发展历程
在图像分类任务中,我们会先使用卷积神经网络提取图像特征,然后再用这些特征预测分类概率,根据训练样本标签建立起分类损失函数,开启端到端的训练,如 图3 所示。
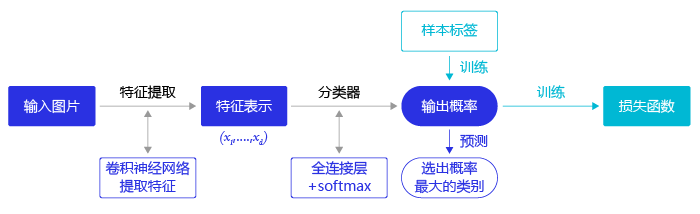
图3 图像分类流程示意图
但对于目标检测问题,按照 图3 的流程则行不通。因为在对整张图提取特征的过程中无法体现出不同目标之间的区别,最终也就没法分别标示出每个物体所在的位置。
为了解决这个问题,结合图片分类任务取得的成功经验,我们可以将目标检测任务进行拆分。假设我们使用某种方式在输入图片上生成一系列可能包含物体的区域,这些区域称为候选区域。对于每个候选区域,可以单独当成一幅图像来看待,使用图像分类模型对候选区域进行分类,看它属于哪个类别或者背景(即不包含任何物体的类别)。上一节我们已经学过如何解决图像分类任务,使用卷积神经网络对一幅图像进行分类不再是一件困难的事情。
那么,现在问题的关键就是如何产生候选区域?比如我们可以使用穷举法来产生候选区域,如 图4 所示。
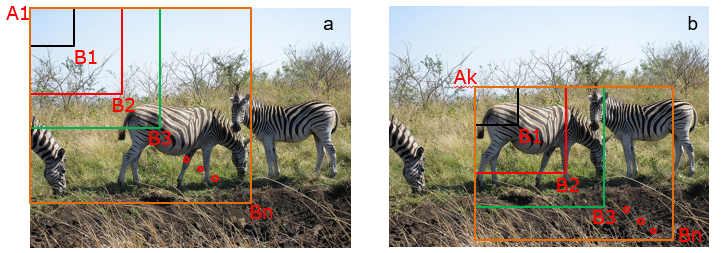
图4 候选区域
A为图像上的某个像素点,B为A右下方另外一个像素点,A、B两点可以确定一个矩形框,记作AB。
- 如图4(a)所示:A在图片左上角位置,B遍历除A之外的所有位置,生成矩形框
- 如图4(b)所示:A在图片中间某个位置,B遍历A右下方所有位置,生成矩形框
当A遍历图像上所有像素点,B则遍历它右下方所有的像素点,最终生成的矩形框集合 将会包含图像上所有可以选择的区域。
只要我们对每个候选区域的分类足够的准确,则一定能找到跟实际物体足够接近的区域来。穷举法也许能得到正确的预测结果,但其计算量也是非常巨大的,其所生成的总候选区域数目约为 ,假设 ,总数将会达到 个,如此多的候选区域使得这种方法几乎没有什么实用性。但是通过这种方式,我们可以看出,假设分类任务完成的足够完美,从理论上来讲检测任务也是可以解决的,亟待解决的问题是如何设计出合适的方法来产生候选区域。
科学家们开始思考,是否可以应用传统图像算法先产生候选区域,然后再用卷积神经网络对这些区域进行分类?
- 2013年,Ross Girshick等人于首次将CNN的方法应用在目标检测任务上,他们使用传统图像算法Selective Search产生候选区域,取得了极大的成功,这就是对目标检测领域影响深远的区域卷积神经网络(R-CNN[1])模型。
- 2015年,Ross Girshick对此方法进行了改进,提出了Fast R-CNN[2]模型。通过将不同区域的物体共用卷积层的计算,大大缩减了计算量,提高了处理速度,而且还引入了调整目标物体位置的回归方法,进一步提高了位置预测的准确性。
- 2015年,Shaoqing Ren等人提出了Faster R-CNN[3]模型,提出了RPN的方法来产生物体的候选区域,这一方法不再需要使用传统的图像处理算法来产生候选区域,进一步提升了处理速度。
- 2017年,Kaiming He等人提出了Mask R-CNN[4]模型,只需要在Faster R-CNN模型上添加比较少的计算量,就可以同时实现目标检测和物体实例分割两个任务。
以上都是基于R-CNN系列的著名模型,对目标检测方向的发展有着较大的影响力。此外,还有一些其他模型,比如SSD[5]、YOLO[6,7,8]、R-FCN[9]等也都是目标检测领域流行的模型结构。图5 为目标检测综述文章[10]中的一幅图,梳理了近些年目标检测算法的发展流程。
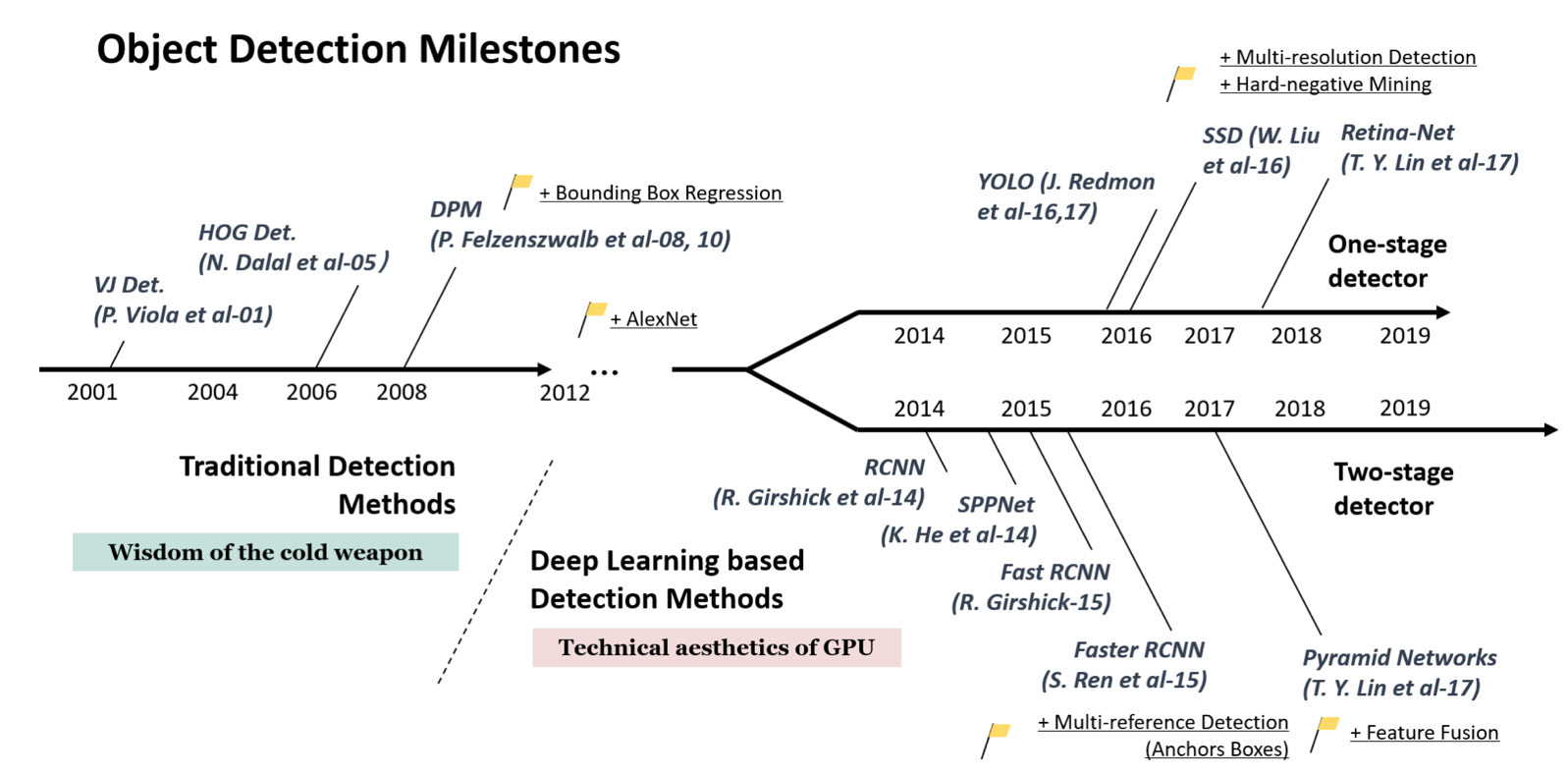
图5 目标检测算法发展流程
其中,由于上文所述的R-CNN的系列算法将目标检测任务分成两个阶段,先在图像上产生候选区域,再对候选区域进行分类并预测目标物体位置,所以它们通常被叫做两阶段检测算法。而SSD和YOLO系列算法则是使用一个网络同时产生候选区域并预测出物体的类别和位置,所以它们通常被叫做单阶段检测算法。
上文中提到,穷举法来获取候选区域是不现实的。因此在后来的经典算法中,常用的一个思路是使用Anchor提取候选目标框,Anchor是预先设定好比例的一组候选框集合,在图片上进行滑动就可以获取候选区域了。
由于这类算法都是使用Anchor提取候选目标框。在特征图的每一个点上,对Anchor进行分类和回归。所以这些算法也统称为基于Anchor的算法。
但是这种基于Anchor的方法,在实际应用中存在一些问题:
- Anchor是人为手工设计的,那我们换个数据集,应该设置多少?设置多大?长宽比如何设置?
- Anchor这种密集框,数量多,训练时如何选择正负样本?
- Anchor设置也导致超参数较多,实际业务扩展中,相对来说,就有点麻烦。
由于上述缺点的存在,近些年研究者们还提出了另外一类效果优异的算法,这些算法不再使用anchor回归预测框,因此也称作Anchor-free的算法,例如:CornerNet[11]和CenterNet[12]等。图6 为大家简单罗列了经典的Anchor-base和Anchor-free的算法。
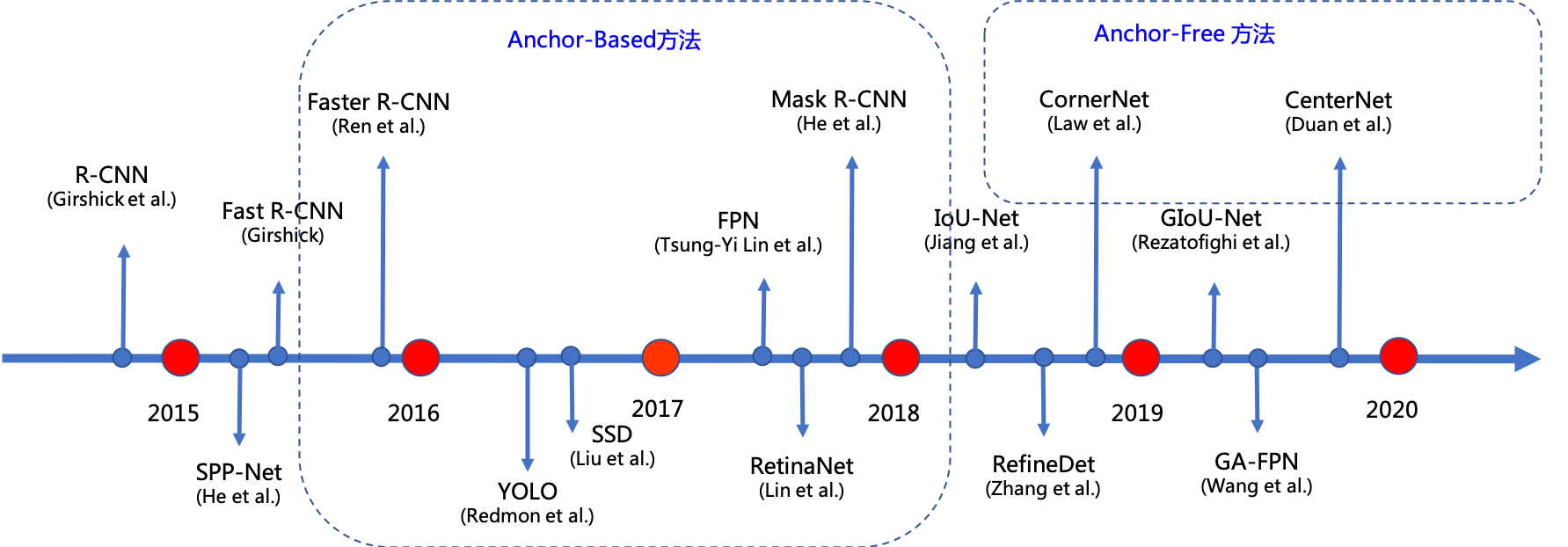
图6 基于深度学习的目标检测算法发展流程
Anchor-base和Anchor-free的算法也各具优势,下表为大家简单对比了几类算法各自的优缺点。
| Anchor-Based单阶段 | Anchor-Based两阶段 | Anchor-Free | |
|---|---|---|---|
| 网络结构 | 简单 | 复杂 | 简单 |
| 精度 | 优 | 更优 | 较优 |
| 预测速度 | 快 | 稍慢 | 快 |
| 超参数 | 较多 | 多 | 相对少 |
| 扩展性 | 一般 | 一般 | 较好 |
1.3 常用数据集
在目标检测领域,常用的开源数据集主要包含以下4个:Pascal VOC[13]、COCO[14]、Object365[15]、OpenImages[16]。这些数据集的类别数、图片数、目标框的总数量各不相同,因此难易也各不相同。这里整理了4个数据集的具体情况,如下表所示。
| 数据集 | 类别数 | train图片数,box数 | val图片数,box数 | boxes/Image |
|---|---|---|---|---|
| Pascal VOC-2012 | 20 | 5717, 1.3万+ | 5823, 1.3万+ | 2.4 |
| COCO | 80 | 118287, 4万+ | 5000,3.6万+ | 7.3 |
| Object365 | 365 | 600k, 9623k | 38k, 479k | 16 |
| OpenImages18 | 500 | 1643042, 86万+ | 100000,69.6万+ | 7.0 |
- Pascal VOC-2012:VOC数据集是 PASCAL VOC挑战赛使用的数据集,包含了20种常见类别的图片,是目标检测领域的经典学术数据集之一。
- COCO:COCO数据集是一个经典的大规模目标检测、分割、姿态估计数据集,图片数据主要从复杂的日常场景中截取,共80类。目前的学术论文经常会使用COCO数据集进行精度评测。
- Object365:旷世科技发布的大规模通用物体检测数据集,共365类。
- OpenImages18:谷歌发布的超大规模数据集,共500类。
- 参考文献
[1] Rich feature hierarchies for accurate object detection and semantic segmentation
[2] Fast R-CNN
[3] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
[4] Mask R-CNN
[5] SSD: Single Shot MultiBox Detector
[6] You Only Look Once: Unified, Real-Time Object Detection
[7] YOLO9000: Better, Faster, Stronger
[8] YOLOv3: An Incremental Improvement
[9] R-FCN: Object Detection via Region-based Fully Convolutional Networks
[10] Object Detection in 20 Years: A Survey
[11] CornerNet: Detecting Objects as Paired Keypoints
[12] Objects as Points
[13] Pascal VOC
[14] COCO
[15] Object365
[16] OpenImages
2.边界框(bounding box)
在检测任务中,我们需要同时预测物体的类别和位置,因此需要引入一些跟位置相关的概念。通常使用边界框(bounding box,bbox)来表示物体的位置,边界框是正好能包含物体的矩形框,如 图1 所示,图中3个人分别对应3个边界框。

图1 边界框
通常表示边界框的位置有两种方式:
- 即 ,其中 是矩形框左上角的坐标, 是矩形框右下角的坐标。图1 中3个红色矩形框用 格式表示如下:
- 左: 。
- 中: 。
- 右: 。
- ,即 ,其中 是矩形框中心点的坐标, 是矩形框的宽度, 是矩形框的高度。
在检测任务中,训练数据集的标签里会给出目标物体真实边界框所对应的 ,这样的边界框也被称为真实框(ground truth box),图1 画出了3个人像所对应的真实框。模型会对目标物体可能出现的位置进行预测,由模型预测出的边界框则称为预测框(prediction box)。
要完成一项检测任务,我们通常希望模型能够根据输入的图片,输出一些预测的边界框,以及边界框中所包含的物体的类别或者说属于某个类别的概率,例如这种格式: ,其中 是预测出的类别标签, 是预测物体属于该类别的概率。一张输入图片可能会产生多个预测框,接下来让我们一起学习如何完成这项任务。
注意:
- 在阅读代码时,请注意使用的是哪一种格式的表示方式。
- 图片坐标的原点在左上角, 轴向右为正方向, 轴向下为正方向。
3.锚框(Anchor box)
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边缘从而更准确地预测目标的真实边界框(ground-truth bounding box)。不同的模型使用的区域采样方法可能不同。这里我们介绍其中的一种方法:它以每个像素为中心生成多个大小和宽高比(aspect ratio)不同的边界框。这些边界框被称为锚框(anchor box)。
在目标检测任务中,我们会先设定好锚框的大小和形状,再以图像上某一个点为中心画出这些锚框,将这些锚框当成可能的候选区域。
目前,常用的锚框尺寸选择方法有:
- 人为经验选取
- k-means聚类
- 作为超参数进行学习
模型对这些候选区域是否包含物体进行预测,如果包含目标物体,则还需要进一步预测出物体所属的类别。还有更为重要的一点是,模型需要预测出微调的幅度。这是因为锚框位置是固定的,它不大可能刚好跟物体边界框重合,所以需要在锚框的基础上进行微调以形成能准确描述物体位置的预测框。
在训练过程中,模型通过学习不断的调整参数,最终能学会如何判别出锚框所代表的候选区域是否包含物体,如果包含物体的话,物体属于哪个类别,以及物体边界框相对于锚框位置需要调整的幅度。而不同的模型往往有着不同的生成锚框的方式。
在下图中,以像素点[300, 500]为中心可以使用下面的程序生成3个框,如 图2 中蓝色框所示,其中锚框A1跟人像区域非常接近。

图2 锚框
#画图展示如何绘制边界框和锚框
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.image import imread
import math
#定义画矩形框的程序
def draw_rectangle(currentAxis, bbox, edgecolor = 'k', facecolor = 'y', fill=False, linestyle='-'):
# currentAxis,坐标轴,通过plt.gca()获取
# bbox,边界框,包含四个数值的list, [x1, y1, x2, y2]
# edgecolor,边框线条颜色
# facecolor,填充颜色
# fill, 是否填充
# linestype,边框线型
# patches.Rectangle(xy, width, height,linewidth,edgecolor,facecolor,fill, linestyle)
# xy:左下角坐标; width:矩形框的宽; height:矩形框的高; linewidth:线宽; edgecolor:边界颜色; facecolor:填充颜色; fill:是否填充; linestyle:线断类型
rect=patches.Rectangle((bbox[0], bbox[1]), bbox[2]-bbox[0]+1, bbox[3]-bbox[1]+1, linewidth=1,
edgecolor=edgecolor,facecolor=facecolor,fill=fill, linestyle=linestyle)
currentAxis.add_patch(rect)
plt.figure(figsize=(10, 10))
#传入图片路径
filename = '/home/aistudio/work/images/section3/000000086956.jpg'
im = imread(filename)
plt.imshow(im)
#使用xyxy格式表示物体真实框
bbox1 = [214.29, 325.03, 399.82, 631.37]
bbox2 = [40.93, 141.1, 226.99, 515.73]
bbox3 = [247.2, 131.62, 480.0, 639.32]
currentAxis=plt.gca()
#绘制3个真实框
draw_rectangle(currentAxis, bbox1, edgecolor='r')
draw_rectangle(currentAxis, bbox2, edgecolor='r')
draw_rectangle(currentAxis, bbox3,edgecolor='r')
#绘制锚框
def draw_anchor_box(center, length, scales, ratios, img_height, img_width):
"""
以center为中心,产生一系列锚框
其中length指定了一个基准的长度
scales是包含多种尺寸比例的list
ratios是包含多种长宽比的list
img_height和img_width是图片的尺寸,生成的锚框范围不能超出图片尺寸之外
"""
bboxes = []
for scale in scales:
for ratio in ratios:
h = length*scale*math.sqrt(ratio)
w = length*scale/math.sqrt(ratio)
x1 = max(center[0] - w/2., 0.)
y1 = max(center[1] - h/2., 0.)
x2 = min(center[0] + w/2. - 1.0, img_width - 1.0)
y2 = min(center[1] + h/2. - 1.0, img_height - 1.0)
print(center[0], center[1], w, h)
bboxes.append([x1, y1, x2, y2])
for bbox in bboxes:
draw_rectangle(currentAxis, bbox, edgecolor = 'b')
img_height = im.shape[0]
img_width = im.shape[1]
#绘制锚框
draw_anchor_box([300., 500.], 100., [2.0], [0.5, 1.0, 2.0], img_height, img_width)
################# 以下为添加上图中的文字说明和箭头###############################
plt.text(285, 285, 'G1', color='red', fontsize=20)
plt.arrow(300, 288, 30, 40, color='red', width=0.001, length_includes_head=True, \
head_width=5, head_length=10, shape='full')
plt.text(190, 320, 'A1', color='blue', fontsize=20)
plt.arrow(200, 320, 30, 40, color='blue', width=0.001, length_includes_head=True, \
head_width=5, head_length=10, shape='full')
plt.text(160, 370, 'A2', color='blue', fontsize=20)
plt.arrow(170, 370, 30, 40, color='blue', width=0.001, length_includes_head=True, \
head_width=5, head_length=10, shape='full')
plt.text(115, 420, 'A3', color='blue', fontsize=20)
plt.arrow(127, 420, 30, 40, color='blue', width=0.001, length_includes_head=True, \
head_width=5, head_length=10, shape='full')
plt.show()
锚框的概念最早在Faster rcnn[1]目标检测算法中被提出,后来被YOLOv2[2]等各种目标检测算法借鉴。对比于早期目标检测算法中使用的滑动窗口或Selective Search方法,使用锚框来提取候选区域大大减少了时间开销。而对比YOLOv1[3]中直接回归坐标值来计算检测框,使用锚框可以简化目标检测问题,使得网络仅仅学习锚框的位置偏移量即可,从而使得网络模型更容易学习。
[1] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
[2] YOLO9000: Better, Faster, Stronger
[3] You Only Look Once: Unified, Real-Time Object Detection
4.交并比
在目标检测任务中,通常会使用交并比(Intersection of Union,IoU)作为衡量指标,来衡量两个矩形框之间的关系。例如在基于锚框的目标检测算法中,我们知道当锚框中包含物体时,我们需要预测物体类别并微调锚框的坐标,从而获得最终的预测框。此时,判断锚框中是否包含物体就需要用到交并比,当锚框与真实框交并比足够大时,我们就可以认为锚框中包含了该物体;而锚框与真实框交并比很小时,我们就可以认为锚框中不包含该物体。此外,在后面NMS的计算过程中,同样也要使用交并比来判断不同矩形框是否重叠。
交并比这一概念来源于数学中的集合,用来描述两个集合 和 之间的关系,它等于两个集合的交集里面所包含的元素个数,除以它们的并集里面所包含的元素个数,具体计算公式如下:
我们将用这个概念来描述两个框之间的重合度。两个框可以看成是两个像素的集合,它们的交并比等于两个框重合部分的面积除以它们合并起来的面积。下图“交集”中青色区域是两个框的重合面积,下图“并集”中蓝色区域是两个框的相并面积。用这两个面积相除即可得到它们之间的交并比,如 图1 所示。
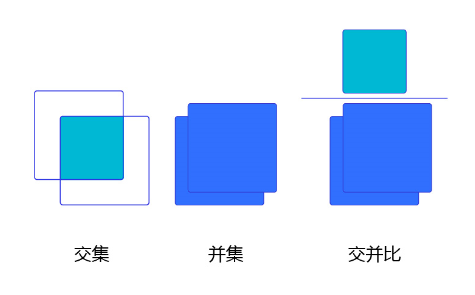
图1 交并比
假设两个矩形框A和B的位置分别为:
假如位置关系如 图2 所示:
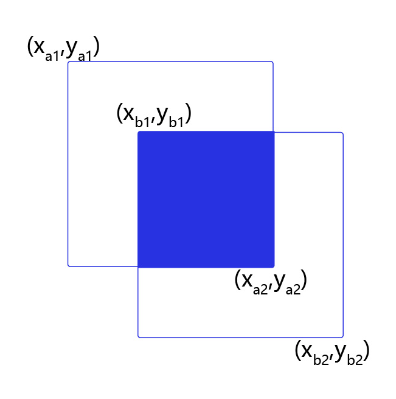
图2 计算交并比
如果二者有相交部分,则相交部分左上角坐标为:
相交部分右下角坐标为:
计算先交部分面积:
矩形框A和B的面积分别是:
计算相并部分面积:
计算交并比:
交并比实现代码如下:
- 当矩形框的坐标形式为xyxy时
import numpy as np
#计算IoU,矩形框的坐标形式为xyxy
def box_iou_xyxy(box1, box2):
# 获取box1左上角和右下角的坐标
x1min, y1min, x1max, y1max = box1[0], box1[1], box1[2], box1[3]
# 计算box1的面积
s1 = (y1max - y1min + 1.) * (x1max - x1min + 1.)
# 获取box2左上角和右下角的坐标
x2min, y2min, x2max, y2max = box2[0], box2[1], box2[2], box2[3]
# 计算box2的面积
s2 = (y2max - y2min + 1.) * (x2max - x2min + 1.)
# 计算相交矩形框的坐标
xmin = np.maximum(x1min, x2min)
ymin = np.maximum(y1min, y2min)
xmax = np.minimum(x1max, x2max)
ymax = np.minimum(y1max, y2max)
# 计算相交矩形行的高度、宽度、面积
inter_h = np.maximum(ymax - ymin + 1., 0.)
inter_w = np.maximum(xmax - xmin + 1., 0.)
intersection = inter_h * inter_w
# 计算相并面积
union = s1 + s2 - intersection
# 计算交并比
iou = intersection / union
return iou
bbox1 = [100., 100., 200., 200.]
bbox2 = [120., 120., 220., 220.]
iou = box_iou_xyxy(bbox1, bbox2)
print('IoU is {}'.format(iou))
- 当矩形框的坐标形式为xywh时
import numpy as np
#计算IoU,矩形框的坐标形式为xywh
def box_iou_xywh(box1, box2):
x1min, y1min = box1[0] - box1[2]/2.0, box1[1] - box1[3]/2.0
x1max, y1max = box1[0] + box1[2]/2.0, box1[1] + box1[3]/2.0
s1 = box1[2] * box1[3]
x2min, y2min = box2[0] - box2[2]/2.0, box2[1] - box2[3]/2.0
x2max, y2max = box2[0] + box2[2]/2.0, box2[1] + box2[3]/2.0
s2 = box2[2] * box2[3]
xmin = np.maximum(x1min, x2min)
ymin = np.maximum(y1min, y2min)
xmax = np.minimum(x1max, x2max)
ymax = np.minimum(y1max, y2max)
inter_h = np.maximum(ymax - ymin, 0.)
inter_w = np.maximum(xmax - xmin, 0.)
intersection = inter_h * inter_w
union = s1 + s2 - intersection
iou = intersection / union
return iou
bbox1 = [100., 100., 200., 200.]
bbox2 = [120., 120., 220., 220.]
iou = box_iou_xywh(bbox1, bbox2)
print('IoU is {}'.format(iou))
为了直观的展示交并比的大小跟重合程度之间的关系,图3 示意了不同交并比下两个框之间的相对位置关系,从 IoU = 0.95 到 IoU = 0。
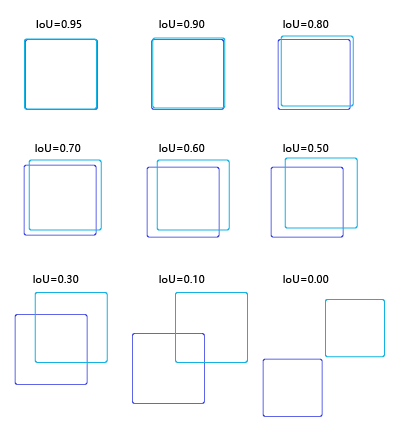
图3 不同交并比下两个框之间相对位置示意图
问题:
什么情况下两个矩形框的IoU等于1?
答案:两个矩形框完全重合。
什么情况下两个矩形框的IoU等于0?
答案:两个矩形框完全不相交。
5.非极大值抑制NMS
在实际的目标检测过程中,不管是用什么方式获取候选区域,都会存在一个通用的问题,那就是网络对同一个目标可能会进行多次检测。这也就导致对于同一个物体,会产生多个预测框。因此需要消除重叠较大的冗余预测框。具体的处理方法就是非极大值抑制(NMS)。
假设使用模型对图片进行预测,一共输出了11个预测框及其得分,在图上画出预测框如 图1 所示。在每个人像周围,都出现了多个预测框,需要消除冗余的预测框以得到最终的预测结果。

图1 预测框示意图
输出11个预测框及其得分的代码实现如下:
#画图展示目标物体边界框
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.image import imread
import math
#定义画矩形框的程序
def draw_rectangle(currentAxis, bbox, edgecolor = 'k', facecolor = 'y', fill=False, linestyle='-'):
# currentAxis,坐标轴,通过plt.gca()获取
# bbox,边界框,包含四个数值的list, [x1, y1, x2, y2]
# edgecolor,边框线条颜色
# facecolor,填充颜色
# fill, 是否填充
# linestype,边框线型
# patches.Rectangle(xy, width, height,linewidth,edgecolor,facecolor,fill, linestyle)
# xy:左下角坐标; width:矩形框的宽; height:矩形框的高; linewidth:线宽; edgecolor:边界颜色; facecolor:填充颜色; fill:是否填充; linestyle:线断类型
rect=patches.Rectangle((bbox[0], bbox[1]), bbox[2]-bbox[0]+1, bbox[3]-bbox[1]+1, linewidth=1,
edgecolor=edgecolor,facecolor=facecolor,fill=fill, linestyle=linestyle)
currentAxis.add_patch(rect)
plt.figure(figsize=(10, 10))
#传入图片路径
filename = '/home/aistudio/work/images/section3/000000086956.jpg'
im = imread(filename)
plt.imshow(im)
currentAxis=plt.gca()
#预测框位置,由网络预测得到
boxes = np.array([[4.21716537e+01, 1.28230896e+02, 2.26547668e+02, 6.00434631e+02],
[3.18562988e+02, 1.23168472e+02, 4.79000000e+02, 6.05688416e+02],
[2.62704697e+01, 1.39430557e+02, 2.20587097e+02, 6.38959656e+02],
[4.24965363e+01, 1.42706665e+02, 2.25955185e+02, 6.35671204e+02],
[2.37462646e+02, 1.35731537e+02, 4.79000000e+02, 6.31451294e+02],
[3.19390472e+02, 1.29295090e+02, 4.79000000e+02, 6.33003845e+02],
[3.28933838e+02, 1.22736115e+02, 4.79000000e+02, 6.39000000e+02],
[4.44292603e+01, 1.70438187e+02, 2.26841858e+02, 6.39000000e+02],
[2.17988785e+02, 3.02472412e+02, 4.06062927e+02, 6.29106628e+02],
[2.00241089e+02, 3.23755096e+02, 3.96929321e+02, 6.36386108e+02],
[2.14310303e+02, 3.23443665e+02, 4.06732849e+02, 6.35775269e+02]])
#预测框得分,由网络预测得到
scores = np.array([0.5247661 , 0.51759845, 0.86075854, 0.9910175 , 0.39170712,
0.9297706 , 0.5115228 , 0.270992 , 0.19087596, 0.64201415, 0.879036])
#画出所有预测框
for box in boxes:
draw_rectangle(currentAxis, box)
这里使用非极大值抑制(Non-Maximum Suppression, NMS)来消除冗余框。基本思想是,如果有多个预测框都对应同一个物体,则只选出得分最高的那个预测框,剩下的预测框被丢弃掉。
如何判断两个预测框对应的是同一个物体呢,标准该怎么设置?
如果两个预测框的类别一样,而且他们的位置重合度比较大,则可以认为他们是在预测同一个目标。非极大值抑制的做法是,选出某个类别得分最高的预测框,然后看哪些预测框跟它的IoU大于阈值,就把这些预测框给丢弃掉。这里IoU的阈值是超参数,需要提前设置,这里我们参考YOLOv3算法,里面设置的是0.5。
比如在上面的程序中,boxes里面一共对应11个预测框,scores给出了它们预测"人"这一类别的得分,NMS的具体做法如下。
- Step0:创建选中列表,keep_list = []
- Step1:对得分进行排序,remain_list = [ 3, 5, 10, 2, 9, 0, 1, 6, 4, 7, 8],
- Step2:选出boxes[3],此时keep_list为空,不需要计算IoU,直接将其放入keep_list,keep_list = [3], remain_list=[5, 10, 2, 9, 0, 1, 6, 4, 7, 8]
- Step3:选出boxes[5],此时keep_list中已经存在boxes[3],计算出IoU(boxes[3], boxes[5]) = 0.0,显然小于阈值,则keep_list=[3, 5], remain_list = [10, 2, 9, 0, 1, 6, 4, 7, 8]
- Step4:选出boxes[10],此时keep_list=[3, 5],计算IoU(boxes[3], boxes[10])=0.0268,IoU(boxes[5], boxes[10])=0.0268 = 0.24,都小于阈值,则keep_list = [3, 5, 10],remain_list=[2, 9, 0, 1, 6, 4, 7, 8]
- Step5:选出boxes[2],此时keep_list = [3, 5, 10],计算IoU(boxes[3], boxes[2]) = 0.88,超过了阈值,直接将boxes[2]丢弃,keep_list=[3, 5, 10],remain_list=[9, 0, 1, 6, 4, 7, 8]
- Step6:选出boxes[9],此时keep_list = [3, 5, 10],计算IoU(boxes[3], boxes[9]) = 0.0577,IoU(boxes[5], boxes[9]) = 0.205,IoU(boxes[10], boxes[9]) = 0.88,超过了阈值,将boxes[9]丢弃掉。keep_list=[3, 5, 10],remain_list=[0, 1, 6, 4, 7, 8]
- Step7:重复上述Step6直到remain_list为空。
非极大值抑制的具体实现代码如下面的nms函数的定义。
#非极大值抑制
def nms(bboxes, scores, score_thresh, nms_thresh):
"""
nms
"""
inds = np.argsort(scores)
inds = inds[::-1]
keep_inds = []
while(len(inds) > 0):
cur_ind = inds[0]
cur_score = scores[cur_ind]
# if score of the box is less than score_thresh, just drop it
if cur_score < score_thresh:
break
keep = True
for ind in keep_inds:
current_box = bboxes[cur_ind]
remain_box = bboxes[ind]
iou = box_iou_xyxy(current_box, remain_box)
if iou > nms_thresh:
keep = False
break
if keep:
keep_inds.append(cur_ind)
inds = inds[1:]
return np.array(keep_inds)
最终得到keep_list=[3, 5, 10],也就是预测框3、5、10被最终挑选出来了,如 图2 所示。

图2 NMS结果示意图
整个过程的实现代码如下:
#画图展示目标物体边界框
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.image import imread
import math
#定义画矩形框的程序
def draw_rectangle(currentAxis, bbox, edgecolor = 'k', facecolor = 'y', fill=False, linestyle='-'):
# currentAxis,坐标轴,通过plt.gca()获取
# bbox,边界框,包含四个数值的list, [x1, y1, x2, y2]
# edgecolor,边框线条颜色
# facecolor,填充颜色
# fill, 是否填充
# linestype,边框线型
# patches.Rectangle需要传入左上角坐标、矩形区域的宽度、高度等参数
rect=patches.Rectangle((bbox[0], bbox[1]), bbox[2]-bbox[0]+1, bbox[3]-bbox[1]+1, linewidth=1,
edgecolor=edgecolor,facecolor=facecolor,fill=fill, linestyle=linestyle)
currentAxis.add_patch(rect)
plt.figure(figsize=(10, 10))
filename = '/home/aistudio/work/images/section3/000000086956.jpg'
im = imread(filename)
plt.imshow(im)
currentAxis=plt.gca()
boxes = np.array([[4.21716537e+01, 1.28230896e+02, 2.26547668e+02, 6.00434631e+02],
[3.18562988e+02, 1.23168472e+02, 4.79000000e+02, 6.05688416e+02],
[2.62704697e+01, 1.39430557e+02, 2.20587097e+02, 6.38959656e+02],
[4.24965363e+01, 1.42706665e+02, 2.25955185e+02, 6.35671204e+02],
[2.37462646e+02, 1.35731537e+02, 4.79000000e+02, 6.31451294e+02],
[3.19390472e+02, 1.29295090e+02, 4.79000000e+02, 6.33003845e+02],
[3.28933838e+02, 1.22736115e+02, 4.79000000e+02, 6.39000000e+02],
[4.44292603e+01, 1.70438187e+02, 2.26841858e+02, 6.39000000e+02],
[2.17988785e+02, 3.02472412e+02, 4.06062927e+02, 6.29106628e+02],
[2.00241089e+02, 3.23755096e+02, 3.96929321e+02, 6.36386108e+02],
[2.14310303e+02, 3.23443665e+02, 4.06732849e+02, 6.35775269e+02]])
scores = np.array([0.5247661 , 0.51759845, 0.86075854, 0.9910175 , 0.39170712,
0.9297706 , 0.5115228 , 0.270992 , 0.19087596, 0.64201415, 0.879036])
left_ind = np.where((boxes[:, 0]<60) * (boxes[:, 0]>20))
left_boxes = boxes[left_ind]
left_scores = scores[left_ind]
colors = ['r', 'g', 'b', 'k']
# 画出最终保留的预测框
inds = nms(boxes, scores, score_thresh=0.01, nms_thresh=0.5)
# 打印最终保留的预测框是哪几个
print(inds)
for i in range(len(inds)):
box = boxes[inds[i]]
draw_rectangle(currentAxis, box, edgecolor=colors[i])
需要说明的是当数据集中含有多个类别的物体时,需要做多分类非极大值抑制,其实现原理与非极大值抑制相同,区别在于需要对每个类别都做非极大值抑制,实现代码如下面的multiclass_nms所示。
#多分类非极大值抑制
def multiclass_nms(bboxes, scores, score_thresh=0.01, nms_thresh=0.45, pre_nms_topk=1000, pos_nms_topk=100):
"""
This is for multiclass_nms
"""
batch_size = bboxes.shape[0]
class_num = scores.shape[1]
rets = []
for i in range(batch_size):
bboxes_i = bboxes[i]
scores_i = scores[i]
ret = []
# 对每个类别都进行NMS操作
for c in range(class_num):
scores_i_c = scores_i[c]
keep_inds = nms(bboxes_i, scores_i_c, score_thresh, nms_thresh)
if len(keep_inds) < 1:
continue
keep_bboxes = bboxes_i[keep_inds]
keep_scores = scores_i_c[keep_inds]
keep_results = np.zeros([keep_scores.shape[0], 6])
keep_results[:, 0] = c
keep_results[:, 1] = keep_scores[:]
keep_results[:, 2:6] = keep_bboxes[:, :]
ret.append(keep_results)
if len(ret) < 1:
rets.append(ret)
continue
ret_i = np.concatenate(ret, axis=0)
scores_i = ret_i[:, 1]
if len(scores_i) > pos_nms_topk:
inds = np.argsort(scores_i)[::-1]
inds = inds[:pos_nms_topk]
ret_i = ret_i[inds]
rets.append(ret_i)
return rets
6.Soft NMS
6.1Soft NMS 提出背景
NMS(非极大值抑制)方法是目标检测任务中常用的后处理方法,其基本思想是:如果有多个预测框都对应同一个物体,则只选出得分最高的那个预测框,剩下的预测框被丢弃掉。在这种方法的处理下,可以有效地减少冗余的检测框。但是,传统的 NMS 算法会存在以下缺点:IOU阈值难以确定,阈值太小,则容易发生漏检现象,当两个相同类别的物体重叠非常多的时候,类别得分较低的物体则会被舍弃;阈值太大,则难以消除大部分冗余框。
因此,在《Improving Object Detection With One Line of Code》[1]论文中,作者提出了 Soft NMS 方法来有效减轻上述问题。
6.2 Soft NMS 算法流程
假设当前得分最高的检测框为 ,对于另一个类别得分为 的检测框 ,传统的 NMS 算法的计算方式可以表示为下式:
其中, 为设定好的IOU阈值。
而 Soft NMS 算法的计算方式可以表示为下式:
这里其实我们就可以看出两个方法的区别了。传统的 NMS 算法中,如果得分较低的检测框与得分最高的检测框的IOU大于阈值,则得分较低的检测框就会直接被舍弃掉;而 Soft NMS 算法中,没有将得分较低的检测框得分直接置0,而是将其降低。具体来说,Soft NMS 算法中,最终的边框得分是依赖原始得分与IOU结果共同决定的,对原始得分进行了线性衰减。
但是,如果使用上述公式进行 Soft NMS 的计算,当IOU大于阈值时,边框得分会发生一个较大的变化。此时,检测结果有可能会也就会因此受到较大的影响。因此, Soft NMS 算法中,还提出了另一种边框得分的计算方式,如下式所示。
此时,新的边界框得分变化较小,在后续的计算过程中也就又有了被计算为正确检测框的机会。
6.3 Soft NMS 算法示例
这里使用一个简单示例来说明 Soft NMS 算法的计算过程以及其与标准NMS算法的差异。

图1 SoftNMS算法示例
假设使用马匹检测模型对上述图像进行预测,得到如上的两个检测结果。其中红色检测框中的马匹类别得分为0.95,绿色虚线检测框中的马匹类别得分为0.8。可以看到,距离镜头更近的马匹几乎将距离镜头远的马匹完全遮挡住了,此时,两个检测框的IOU是非常大的。
在传统NMS算法中,对于这种检测框的IOU非常大,超过预先设定的阈值的情况,会仅仅保留得分最大的检测框,将得分较小的检测框的得分直接置0。此时,绿色虚线框中的马匹也就直接被舍弃掉了。但是,这两个检测框本身分别对应了两个不同的马匹,因此,这种NMS的方法会造成漏检的现象。
而在SoftNMS算法中,绿色虚线的检测框对应的新得分则不会被置0,而是使用上文中提到的两种计算方式进行计算。此时,绿色虚线框中的马匹不会直接被舍弃掉,而是降低了类别得分,继续参与后续计算。对应原图中的情况,两个马匹则有很大的概率在最后同时被保留,避免了漏检现象的发生。
更多文章请关注公重号:汀丶人工智能
- 参考文献

- 点赞
- 收藏
- 关注作者
评论(0)