【编程实践】利用Python看看那些QQ好友都在QQ空间发了啥

前言
本文使用Python第三方库和浏览器实'企鹅'空间的的爬取,利用Matplotlib库实现词云的绘制,对于matplotlib感兴趣的童鞋可以参考《Python绘制精美可视化数据分析图表(一)-Matplotlib》,这里不再赘述。
Selenium的介绍
Selenium库是一个web的自动化测试工具,最初是为网站自动化测试而开发的,类似我们以前玩游戏用的“按键精灵”软件。他跟按键精灵一样,可以按指定的命令自动操作,不同的是,Selenium模块可以直接运行在浏览器上,他支持所有主流的浏览器.Selenium可以根据指令,让浏览器自动加载页面,获取需要的数据,进行页面截屏,或判断网站上某些动作是否发生.是不是很神奇,由于Selenium能够直接运行在浏览器上,所以selenium也常用于网站数据的爬取.Selenium支持多种操作系统如Windows、Linux、IOS、Android等。
Selenium的安装
Selenium安装极其简单和其他的Python的安装一样使用pip install命令安装;安装命令如下:
pip install selenium不过Selenium的使用需要浏览器driver的支持,所以除了selenium的安装,还需要为你的测试浏览器下载驱动,我用的是谷歌Chrome,对应的去百度一下Chrome webdrive下载,并解压到python安装目录scripts下或放到Selenium的安装目录下的webdriver文件夹(如下图)。下面是下载地址,选择跟自己本地浏览器版本一致就可以,本文用到的是谷歌浏览器,查看谷歌版本如下图:

Chrome驱动文件下载:https://chromedriver.storage.googleapis.com/index.html
Firefox驱动文件下载:https://github.com/mozilla/geckodriver/releases
Selenium基本的用法
使用自动化测试程序编写爬虫是因为有的网页是动态生成的,如包含大量代码动态执行的网页,这种网页无法用之前用Requests的方法直接爬取数据,必须使用动态的方法去获取,这时就需要Selenium和浏览器配合.
webdriver.Chrome() : 调用浏览器
find_element_by_:元素查找
switch_to.from():切入或切出Frame元素
get_attribute('***'):获取所需要的元素
关于元素的定位新版本和旧版有些变化
旧版本的元素定位如下图:
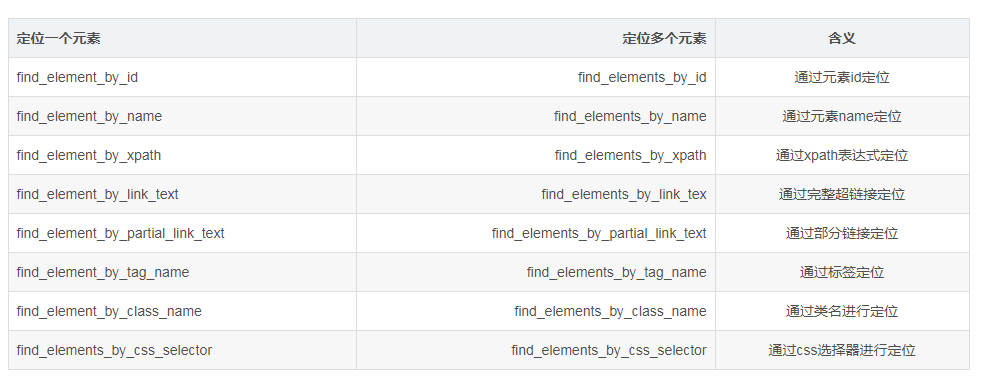
新版版的用法如下:
webdriver更新之后的报错
报错:执行代码时出现DeprecationWarning: find_element_by_* commands are deprecated
解决方案:版本更新不匹配的原因旧版的find_element_by_*命令在最新的SeleniumPython库中已被弃。
要使用find_element(By.*,"对应的名称")代替
使用前导入以下模块:
from selenium.webdriver.common.by import By
和
from selenium.common.exceptions import NoSuchElementException在from selenium import 旧版改为新版用法如下:
find_element()内容:
使用class_name定位元素
button = driver.find_element_by_class_name("quiz_button")
替换为
button = driver.find_element(By.CLASS_NAME, "quiz_button")使用id定位元素
element = find_element_by_id("element_id")
替换为
element = driver.find_element(By.ID, "element_id")使用name定位元素
element = find_element_by_name("element_name")
替换为
element = driver.find_element(By.NAME, "element_name")使用link_text定位元素
element = find_element_by_link_text("element_link_text")
替换为
element = driver.find_element(By.LINK_TEXT, "element_link_text")使用partial_link_text定位元素
element = find_element_by_partial_link_text("element_partial_link_text")
替换为
element = driver.find_element(By.PARTIAL_LINK_TEXT, "element_partial_link_text")使用tag_name定位元素
element = find_element_by_tag_name("element_tag_name")
替换为
element = driver.find_element(By.TAG_NAME, "element_tag_name")使用css_selector定位元素
element = find_element_by_css_selector("element_css_selector")
替换为
element = driver.find_element(By.CSS_SELECTOR, "element_css_selector")使用xpath定位元素
element = find_element_by_xpath("element_xpath")
替换为
element = driver.find_element(By.XPATH, "element_xpath")除了selenium库,本文还用到wordcloud和jieba分词两个库:
其他库的安装
安装命令如下:
pip install jieba
pip install wordcloud
pip install lxml #标签解析库

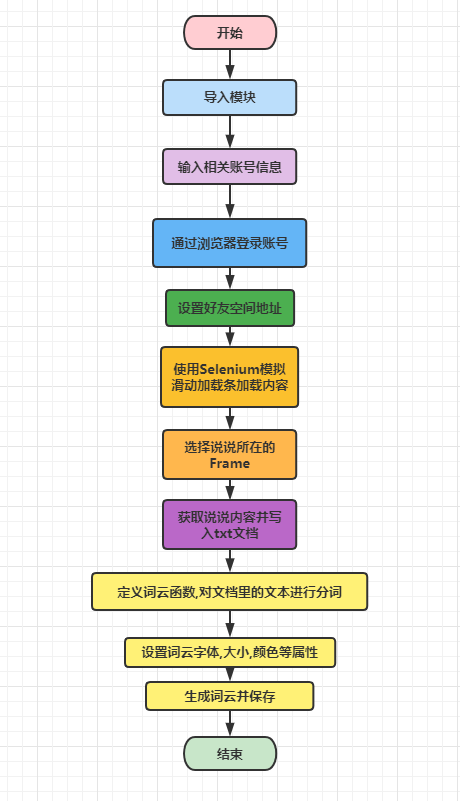
编程实践
程序流程
导入相关模块
输入相关账号信息
打开浏览器,定向到QQ登录页面,进行模拟登录
让webdriver操控浏览器.跳转到好友空间
下拉滚动条,让浏览器自动加载内容,并将内容存储到txt文件
一页加载结束继续加载下一页内容,并将内容保存到txt,直到最后一页
把爬取txt里面的数据进行分词操作,通过空格进行分隔
设置词云的字体,大小,颜色和背景等属性,生成词云
将词云可视化并保存词云
代码实现
导入模块,以及设置账号信息
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from lxml import etree
friend= "888888888" #好友的qq号码
user='8888888888' #你的qq账号
pw='88888888888' #你的qq密码
使用Selenium调用浏览器,实现自动登录和访问好友空间
driver=webdriver.Chrome()
driver.maximize_window()
driver.get("http://i.qq.com")
driver.switch_to.frame("login_frame")
driver.find_element(By.ID, "switcher_plogin").click()
# 账号输入框输入已知qq账号
driver.find_element(By.ID,"u").send_keys(user)
# 密码框输入已知密码
driver.find_element(By.ID,"p").send_keys(pw)
# 自动点击登陆按钮
driver.find_element(By.ID,"login_button").click()
# 让webdriver操纵当前页
driver.switch_to.default_content()
# 跳到说说的url, friend你可以任意改成你想访问的空间
driver.get("http://user.qzone.qq.com/" + "好友的qq号码"+ "/311")循环爬取所有说说记录,并将记录存入txt文件中
next_num = 0 # 初始“下一页”的id
while True:
# 下拉滚动条,使浏览器加载出动态加载的内容,
# 我这里是从1开始到6结束 分5 次加载完每页数据
for i in range(1,6):
height = 20000*i#每次滑动20000像素
strWord = "window.scrollBy(0,"+str(height)+")"
driver.execute_script(strWord)
time.sleep(4)
# 很多时候网页由多个<frame>或<iframe>组成,webdriver默认定位的是最外层的frame,
# 所以这里需要选中一下说说所在的frame,否则找不到下面需要的网页元素
driver.switch_to.frame("app_canvas_frame")
selector = etree.HTML(driver.page_source)
divs = selector.xpath('//*[@id="msgList"]/li/div[3]')
#这里使用 a 表示内容可以连续不清空写入
with open('qq.txt','a',encoding='utf-8') as f:
for div in divs:
qq_name = div.xpath('./div[2]/a/text()')
qq_content = div.xpath('./div[2]/pre/text()')
qq_time = div.xpath('./div[4]/div[1]/span/a/text()')
qq_name = qq_name[0] if len(qq_name)>0 else ''
qq_content = qq_content[0] if len(qq_content)>0 else ''
qq_time = qq_time[0] if len(qq_time)>0 else ''
print(qq_name,qq_time,qq_content)
f.write(qq_content+"\n")
# 当已经到了尾页,下一页这个按钮就没有id了,可以结束了
if driver.page_source.find('pager_next_' + str(next_num)) == -1:
break
# 找到下一页的按钮,因为下一页的按钮是动态变化的,这里需要动态记录一下
driver.find_element(By.ID,'pager_next_' + str(next_num)).click()
# 下一页的id
next_num += 1
# 因为在下一个循环里首先还要把页面下拉,所以要跳到外层的frame上
driver.switch_to.parent_frame()
注:设置间隔时间是为了让浏览器能够将页面信息完整加载
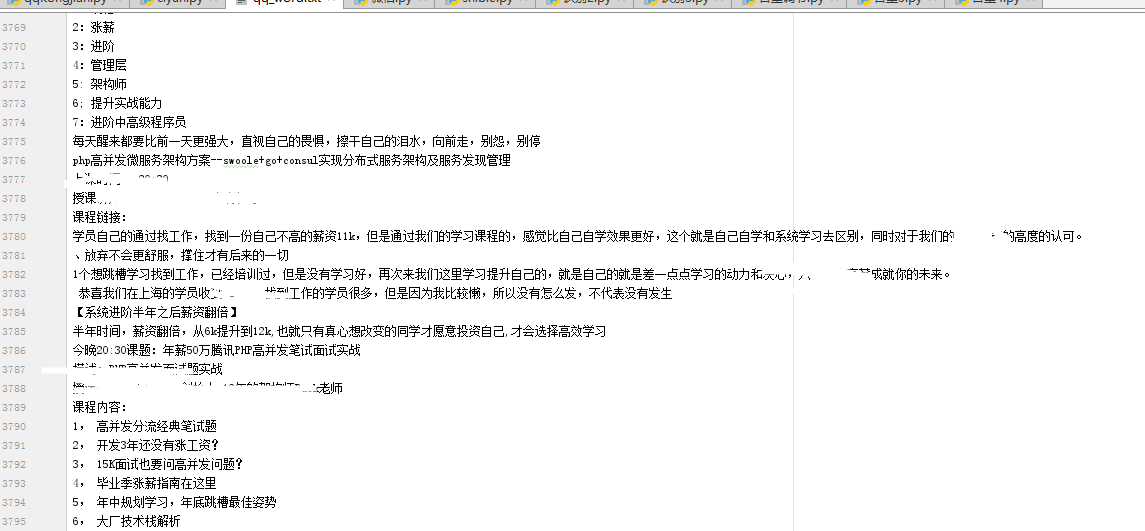
这是获取到的某机构老师的的说说数据
导入相关模块,定义词云函数,设置相关参数,将数据生成词云,并将词云可视化
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
#生成词云
def create_word_cloud(filename):
text= open("qq.txt".format(filename),encoding='utf-8').read()
# 结巴分词
wordlist = jieba.cut(text, cut_all=True)
wl = " ".join(wordlist)
# 设置词云
wc = WordCloud(
# 设置背景颜色
background_color="white",
# 设置最大显示的词云数
max_words=2000,
# 这种字体都在电脑字体中,一般路径
font_path='C:\Windows\Fonts\simfang.ttf',
height= 1200,
width= 1600,
# 设置字体最大值
max_font_size=100,
# 设置有多少种随机生成状态,即有多少种配色方案
random_state=30,
)
myword = wc.generate(wl) # 生成词云
# 展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()
wc.to_file('py_book.png') # 把词云保存下
if __name__ == '__main__':
create_word_cloud('word_py')open("qq.txt".format(filename),encoding='utf-8').read()一定要设置设置编码,否则导致txt读取和保存错误

生成词云最后效果如下图:


- 点赞
- 收藏
- 关注作者
评论(0)