一分钟学会计数排序——C语言实现

【摘要】 计数排序是一种非比较排序。它的主要思想是建立一个临时数组 CountArr ,用来统计序列中每个元素出现的次数,例如若序列元素 n 一共出现了 m 次,则使 CountArr [n] = m;统计完毕后。根据统计的结果,将序列按顺序插入到原数组中即完成排序。计数排序时间复杂度为O(N+range),空间复杂度为 O(range)。计数排序看着貌似比快排还要厉害,但是它的局限性较高。计数排序适合范围

![]()
文章目录
计数排序是一种非比较排序。它的主要思想是建立一个临时数组 CountArr ,用来统计序列中每个元素出现的次数,例如若序列元素 n 一共出现了 m 次,则使 CountArr [n] = m;统计完毕后。根据统计的结果,将序列按顺序插入到原数组中即完成排序。
一、过程详解
我相信单凭一句概念是理解不了的,接下来通过示例详细讲解;
这是待排序的数组;

![]()
这是统计数组用来统计原数组中每个元素出现的次数;

![]()
接下来进行统计;
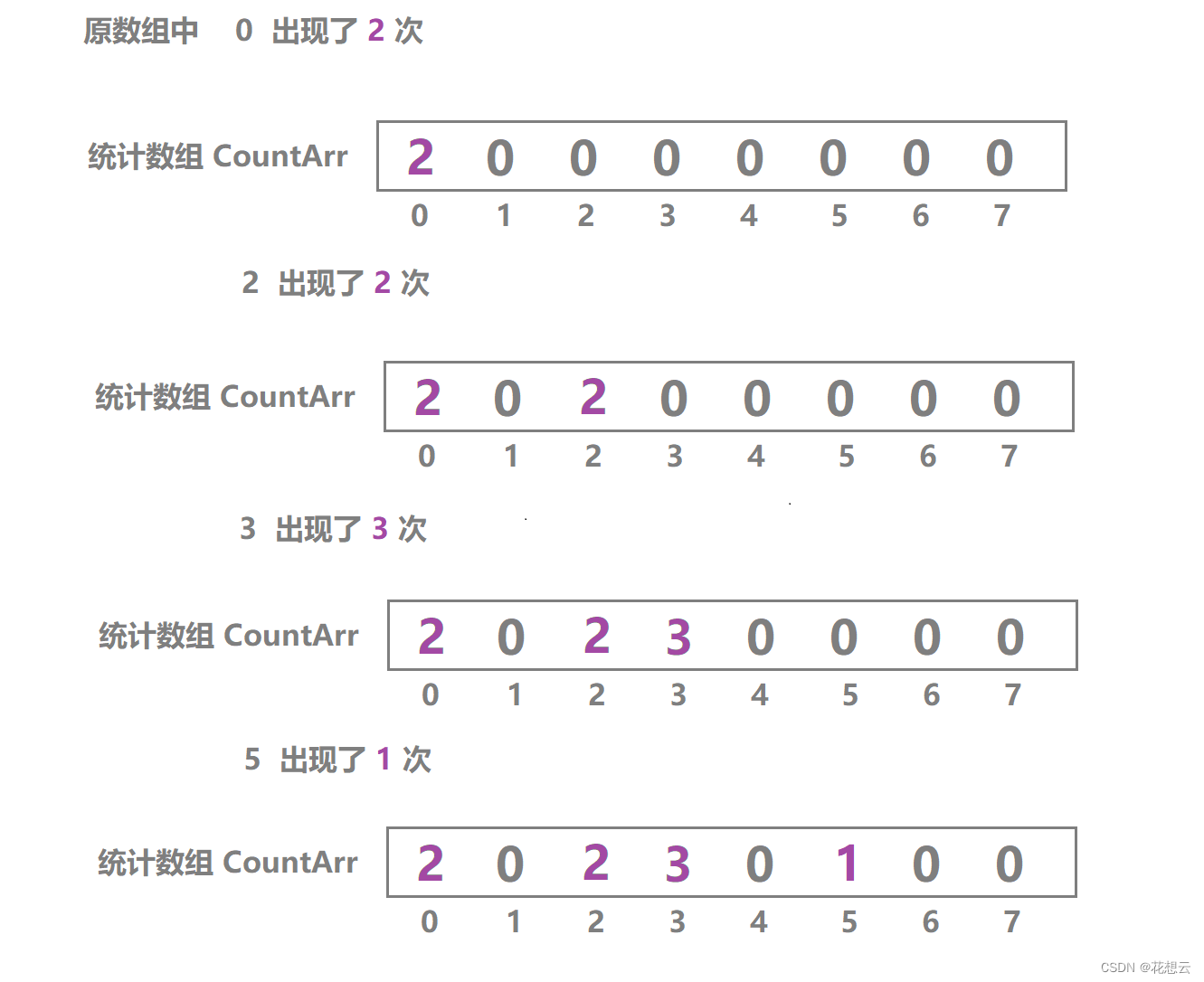
![]() 根据统计结果在原数组中填入数据;
根据统计结果在原数组中填入数据;
以上就是整个统计排序过程了。
二、代码实现
了解了过程后,代码的实现很简单。
以上代码虽然能够完成排序的任务,但是它是有缺陷的。
假设我们要排序的序列为1,6,6,6,6,9,9,3,3,5,7,8,2,3,0,0,0 ,那么效果非常棒。因为它的时间复杂度为 O(N+max),空间复杂度为 O(max+1)。
我们发现空间复杂度是与序列中的最大值 max 有关的,因为首先需要创建大小为 max+1 的统计数组。
如果我们要排序的序列为 1001,1002,1003,1003,1001,1005,1001,按照上述代码的逻辑,应该创建一个大小为 1005 +1 的统计数组。
这里就有一个很明显的弊端,序列只有 7 个元素,却要用大小 1005+1 的统计数组来统计,意味着统计数组的前 1000 位都要被浪费掉了。
那么统计数组合理的大小应为多大呢?答案是 1005 - 1001 + 1,即序列最大元素 - 最小元素 + 1。
三、代码改进
试着改进一下之前的计数排序代码。
void CountSort(int* a, int n)
{
int max = a[0];
int min = a[0];
for (int i = 0; i < n; i++)
{
if (max < a[i])
max = a[i];
if (min > a[i])
min = a[i];
}
int range = max - min + 1;
int* CountArr = (int*)calloc(range,sizeof(int) );
if (CountArr == NULL)
{
perror("calloc fail");
exit(-1);
}
//1.统计次数
for (int i = 0; i < n; i++)
{
CountArr[a[i] - min]++;
}
//2.排序
int k = 0;
for (int j = 0; j < range; j++)
{
while (CountArr[j]--)
{
a[k++] = j + min;
}
}
free(CountArr);
}改进后的统计排序,时间复杂度为O(N+range),空间复杂度为 O(range)。计数排序看着貌似比快排还要厉害,但是它的局限性较高。计数排序适合范围集中的数据,并且只适合整型数据。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)