ES中的中文分词技术,很牛逼!

Elasticsearch是一个流行的全文搜索引擎,能够高效地处理大量的复杂查询。在处理中文文本数据时,需要将文本进行分词处理,并对分词结果进行索引和搜索。ES提供了多种中文分词器,能够适应不同场景和需求。本文将详细介绍ES中的中文分词技术。
中文分词的基本概念
中文分词是将连续的中文字串切割成独立的词语序列的过程,是中文自然语言处理中的一项基础任务。中文分词主要有两种方法:基于规则的分词和基于统计的分词。前者依赖于人工编写的规则表达式来实现分词,而后者则利用机器学习算法从大量的语料库中学习到分词规律。
ES中的中文分词器采用的是基于规则的分词方法,对于每个汉字序列都会生成所有可能的分词方案,并通过启发式算法选取最优的方案以保证分词准确性和速度。
ES中的中文分词器
ES中内置了许多中文分词器,每个分词器都有其独特的优点和限制。以下是ES中常用的几种分词器:
IK Analyzer
IK Analyzer是一个开源的中文分词器,由阿里巴巴集团发布。它采用了细粒度切分和歧义处理等技术,能够较好地处理各种中文文本。IK Analyzer支持普通模式、搜索模式和拼音模式三种分词方式,并可以根据需要自定义字典。
Smart Chinese Analyzer
Smart Chinese Analyzer是Lucene自带的一款中文分词器,基于规则的分词方法,能够进行精确的中文分词。Smart Chinese Analyzer支持中文数字、中文量词、时间、日期等特殊词汇的识别和转换。
Jieba Analyzer
Jieba Analyzer是Python中广泛使用的中文分词器,也被应用到ES中。它采用了基于统计的分词方法,能够对复杂的中文文本进行较为准确的分词。Jieba Analyzer支持全模式、精确模式、搜索模式和默认模式,并提供了多种字典和停用词表可供选择。
中文分词的注意事项
虽然ES内置的中文分词器能够较好地处理大部分中文文本,但仍需注意以下问题:
歧义处理
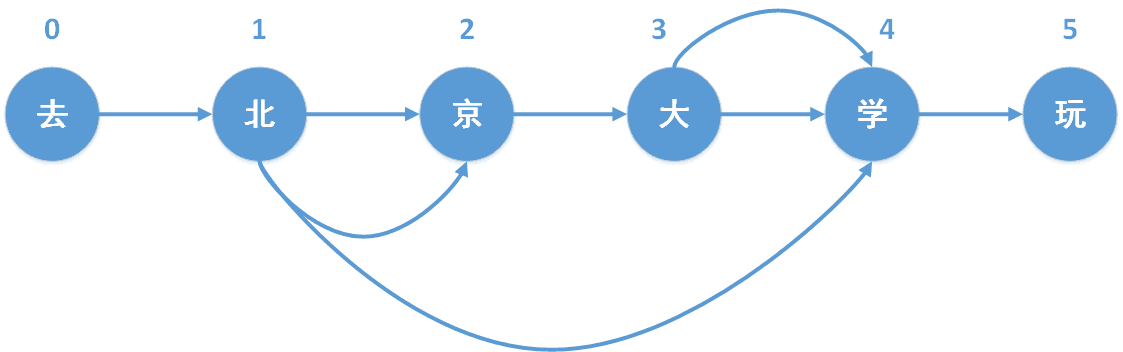
中文分词中存在许多歧义和多义词汇,如“北京大学”,可以切分为“北京”和“大学”,也可以切分为“北京大学”。因此,在进行中文分词时需要对歧义进行处理,以确保分词结果的准确性。
自定义字典
在处理一些特定领域的文本时,分词器可能无法识别某些专业术语或领域特有的词汇。此时,需要手动添加自定义字典来扩展分词器的词汇库,以提高分词效果。
停用词过滤
一些常见的词汇,如“的”、“了”等并不具有实际含义,只是语言连词,不应该作为搜索关键字。这些单词称之为“停用词”,需要在分词器中进行过滤,以提高搜索结果的准确性和效率。
中英文混合
在处理中英文混合的文本时,需要注意区分中英文切分的方式。对于英文文本,可以采用空格或标点符号作为分词标志;而中文则需要使用中文分词器进行处理。
总结
ES中的中文分词器是一项非常重要的技术,它能够有效地帮助我们处理中文文本,并提供全文搜索、高亮显示、聚合分析等功能。在实际应用中,需要根据具体场景和需求选择合适的分词器,并针对特定问题进行优化和调整,以达到更好的效果。
总之,中文分词技术在信息处理和自然语言处理领域有着广泛的应用前景,掌握其原理和方法,将有助于提高数据处理和分析的效率和精度。

- 点赞
- 收藏
- 关注作者
评论(0)