【2023 · CANN训练营第一季】——Ascend C算子代码分析—Add算子

前言:Ascend C算子(TIK C++)使用C/C++作为前端开发语言,通过四层接口抽象、并行编程范式、孪生调试等技术,极大提高算子开发效率,助力AI开发者低成本完成算子开发和模型调优部署。学习完理论后,上代码,通过实践理解Ascend C算子的概念,掌握开发流程,以及内核调用符方式的调试方法。
一、算子分析
Add算子的数学公式: ,为简单起见,设定输入张量x, y,z为固定shape(8,2048),数据类型dtype为half类型,数据排布类型format为ND。
,为简单起见,设定输入张量x, y,z为固定shape(8,2048),数据类型dtype为half类型,数据排布类型format为ND。
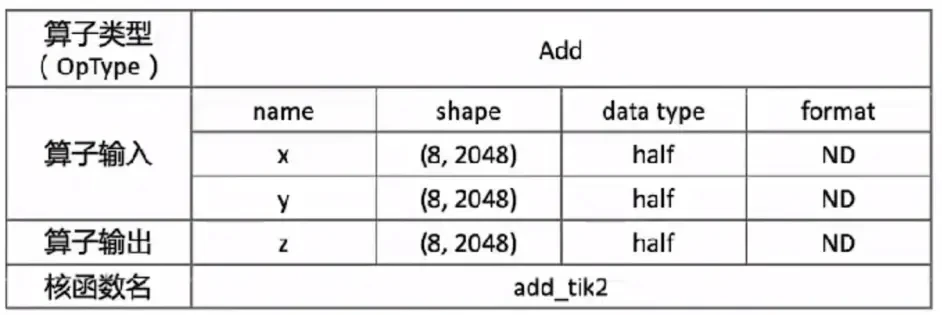
确定如下内容:
1、计算逻辑:输入数据需要先搬入到片上存储,然后使用计算接口(TIK C++ API/矢量计算/双目/ADD,采用2级接口)完成两个加法运算,得到最终结果,再搬出到外部存储。
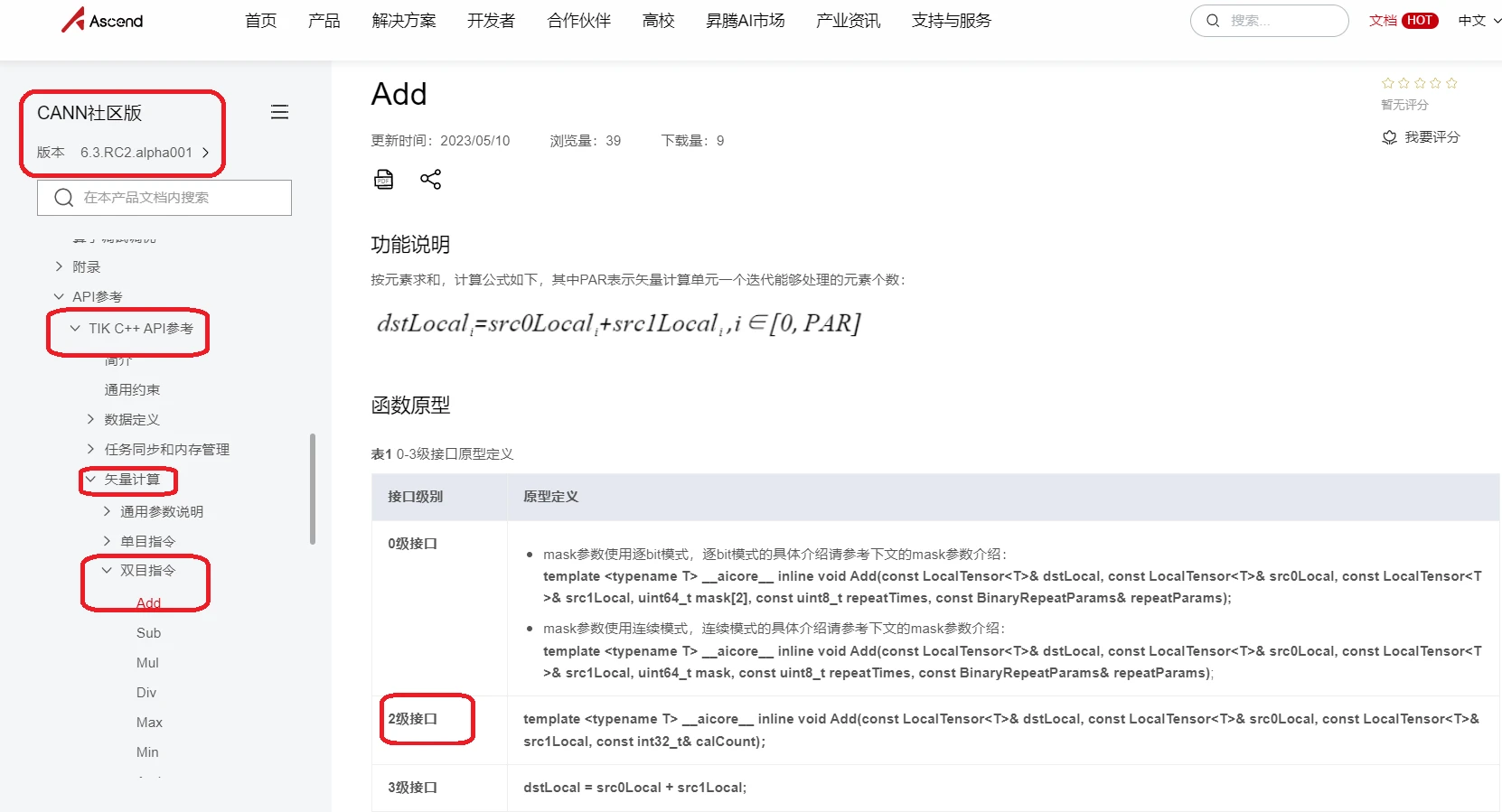
2、输入与输出
输入::固定shape(8,2048),数据排布类型为ND。
输出::与输入相同,固定shape(8,2048),数据排布类型为ND。
3、核函数名称和入参
核函数名称:定义为add_tik2
入参3个,x,y,z:x,y为输入向量在Global Memory上的内存地址,z为计算结果输出到Global Memory上的内存地址。
二、代码分析
代码结构:
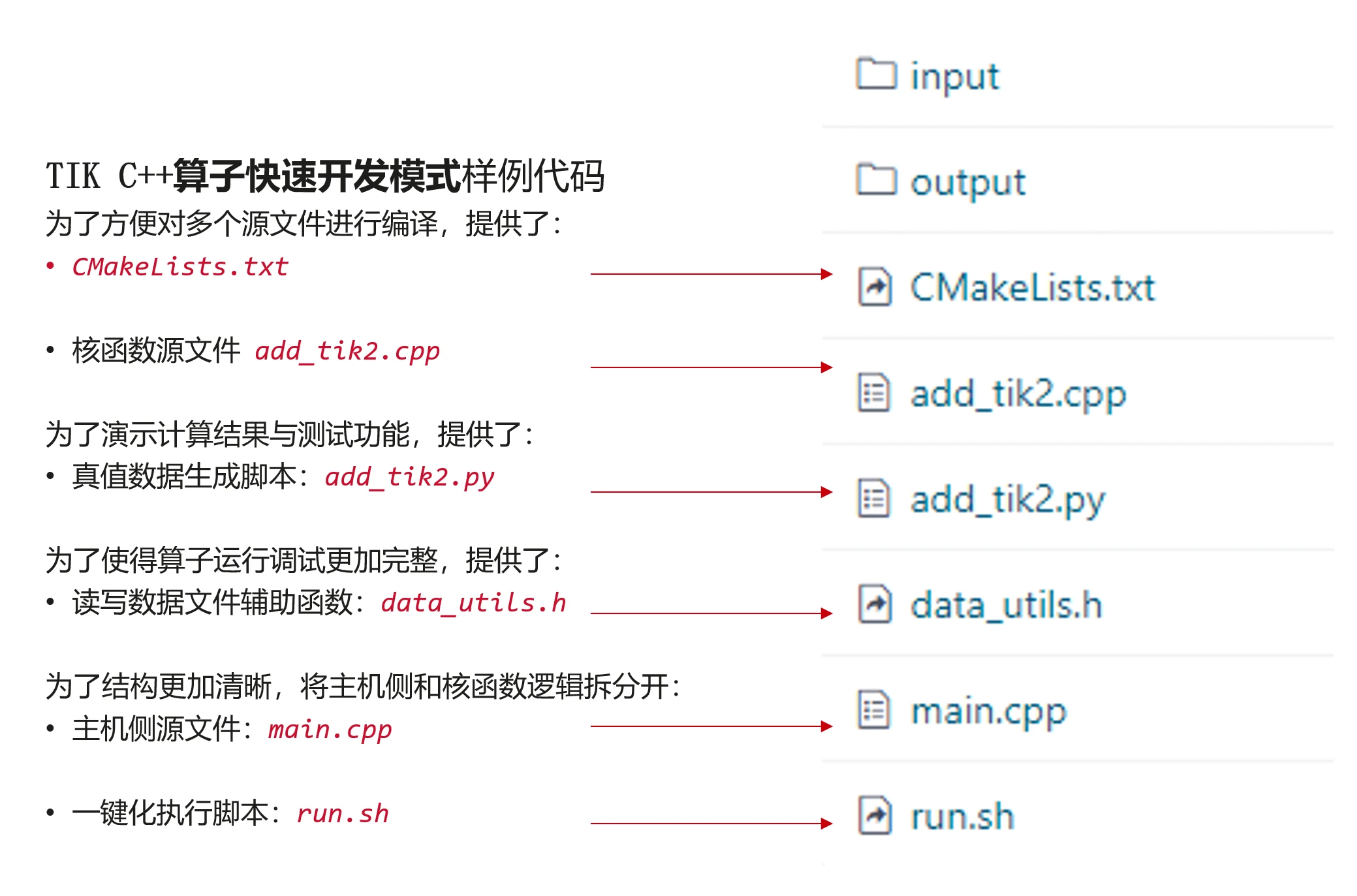
一)算子实现——Add_tik2.cpp
1、核函数定义
extern "C" __global__ __aicore__ void add_tik2(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z)2、核函数实现——算子类的init()和process()
1)在核函数里实例化算子类KernelAdd,并调用init()实现初始化;调用process()实现流水操作
extern "C" __global__ __aicore__ void add_tik2(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z)
{
KernelAdd op;
op.Init(x, y, z);
op.Process();
}2)KernelAdd算子类定义
class KernelAdd {
public:
__aicore__ inline KernelAdd() {}
__aicore__ inline void Init(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z)
{
// get start index for current core, core parallel
xGm.SetGlobalBuffer((__gm__ half*)x + block_idx * BLOCK_LENGTH, BLOCK_LENGTH);
yGm.SetGlobalBuffer((__gm__ half*)y + block_idx * BLOCK_LENGTH, BLOCK_LENGTH);
zGm.SetGlobalBuffer((__gm__ half*)z + block_idx * BLOCK_LENGTH, BLOCK_LENGTH);
// pipe alloc memory to queue, the unit is Bytes
pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half));
}
__aicore__ inline void Process()
{
// loop count need to be doubled, due to double buffer
constexpr int32_t loopCount = TILE_NUM * BUFFER_NUM;
// tiling strategy, pipeline parallel
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
private:
__aicore__ inline void CopyIn(int32_t progress)
{
// alloc tensor from queue memory
LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();
// copy progress_th tile from global tensor to local tensor
DataCopy(xLocal, xGm[progress * TILE_LENGTH], TILE_LENGTH);
DataCopy(yLocal, yGm[progress * TILE_LENGTH], TILE_LENGTH);
// enque input tensors to VECIN queue
inQueueX.EnQue(xLocal);
inQueueY.EnQue(yLocal);
}
__aicore__ inline void Compute(int32_t progress)
{
// deque input tensors from VECIN queue
LocalTensor<half> xLocal = inQueueX.DeQue<half>();
LocalTensor<half> yLocal = inQueueY.DeQue<half>();
LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
// call Add instr for computation
Add(zLocal, xLocal, yLocal, TILE_LENGTH);
// enque the output tensor to VECOUT queue
outQueueZ.EnQue<half>(zLocal);
// free input tensors for reuse
inQueueX.FreeTensor(xLocal);
inQueueY.FreeTensor(yLocal);
}
__aicore__ inline void CopyOut(int32_t progress)
{
// deque output tensor from VECOUT queue
LocalTensor<half> zLocal = outQueueZ.DeQue<half>();
// copy progress_th tile from local tensor to global tensor
DataCopy(zGm[progress * TILE_LENGTH], zLocal, TILE_LENGTH);
// free output tensor for reuse
outQueueZ.FreeTensor(zLocal);
}
private:
TPipe pipe;
// create queues for input, in this case depth is equal to buffer num
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY;
// create queue for output, in this case depth is equal to buffer num
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ;
GlobalTensor<half> xGm, yGm, zGm;
};3)算子类——init()
__aicore__ inline void Init(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z)
{
// get start index for current core, core parallel
xGm.SetGlobalBuffer((__gm__ half*)x + block_idx * BLOCK_LENGTH, BLOCK_LENGTH);
yGm.SetGlobalBuffer((__gm__ half*)y + block_idx * BLOCK_LENGTH, BLOCK_LENGTH);
zGm.SetGlobalBuffer((__gm__ half*)z + block_idx * BLOCK_LENGTH, BLOCK_LENGTH);
// pipe alloc memory to queue, the unit is Bytes
pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half));
}4)算子类——process()
__aicore__ inline void Process()
{
// loop count need to be doubled, due to double buffer
constexpr int32_t loopCount = TILE_NUM * BUFFER_NUM;
// tiling strategy, pipeline parallel
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
} __aicore__ inline void CopyIn(int32_t progress)
{
// alloc tensor from queue memory
LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();
// copy progress_th tile from global tensor to local tensor
DataCopy(xLocal, xGm[progress * TILE_LENGTH], TILE_LENGTH);
DataCopy(yLocal, yGm[progress * TILE_LENGTH], TILE_LENGTH);
// enque input tensors to VECIN queue
inQueueX.EnQue(xLocal);
inQueueY.EnQue(yLocal);
}
__aicore__ inline void Compute(int32_t progress)
{
// deque input tensors from VECIN queue
LocalTensor<half> xLocal = inQueueX.DeQue<half>();
LocalTensor<half> yLocal = inQueueY.DeQue<half>();
LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
// call Add instr for computation
Add(zLocal, xLocal, yLocal, TILE_LENGTH);
// enque the output tensor to VECOUT queue
outQueueZ.EnQue<half>(zLocal);
// free input tensors for reuse
inQueueX.FreeTensor(xLocal);
inQueueY.FreeTensor(yLocal);
}
__aicore__ inline void CopyOut(int32_t progress)
{
// deque output tensor from VECOUT queue
LocalTensor<half> zLocal = outQueueZ.DeQue<half>();
// copy progress_th tile from local tensor to global tensor
DataCopy(zGm[progress * TILE_LENGTH], zLocal, TILE_LENGTH);
// free output tensor for reuse
outQueueZ.FreeTensor(zLocal);
}
二)算子验证
1、算子调用——main.c
1)CPU方式——通过ICPU_RUN_KF宏调用
#ifdef __CCE_KT_TEST__
uint8_t* x = (uint8_t*)tik2::GmAlloc(inputByteSize);
uint8_t* y = (uint8_t*)tik2::GmAlloc(inputByteSize);
uint8_t* z = (uint8_t*)tik2::GmAlloc(outputByteSize);
ReadFile("./input/input_x.bin", inputByteSize, x, inputByteSize);
// PrintData(x, 16, printDataType::HALF);
ReadFile("./input/input_y.bin", inputByteSize, y, inputByteSize);
// PrintData(y, 16, printDataType::HALF);
ICPU_RUN_KF(add_tik2, blockDim, x, y, z); // use this macro for cpu debug
// PrintData(z, 16, printDataType::HALF);
WriteFile("./output/output_z.bin", z, outputByteSize);
tik2::GmFree((void *)x);
tik2::GmFree((void *)y);
tik2::GmFree((void *)z);2)NPU方式——内核调用符方式
使用NPU方式,需要按照AscendCL的编程流程调用。
#ifdef __CCE_KT_TEST__
//cpu 方式
#else
aclInit(nullptr);
aclrtContext context;
aclError error;
int32_t deviceId = 0;
aclrtCreateContext(&context, deviceId);
aclrtStream stream = nullptr;
aclrtCreateStream(&stream);
uint8_t *xHost, *yHost, *zHost;
uint8_t *xDevice, *yDevice, *zDevice;
aclrtMallocHost((void**)(&xHost), inputByteSize);
aclrtMallocHost((void**)(&yHost), inputByteSize);
aclrtMallocHost((void**)(&zHost), outputByteSize);
aclrtMalloc((void**)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc((void**)&yDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc((void**)&zDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST);
ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize);
// PrintData(xHost, 16, printDataType::HALF);
ReadFile("./input/input_y.bin", inputByteSize, yHost, inputByteSize);
// PrintData(yHost, 16, printDataType::HALF);
aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE);
aclrtMemcpy(yDevice, inputByteSize, yHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE);
add_tik2_do(blockDim, nullptr, stream, xDevice, yDevice, zDevice); // call kernel in this function
aclrtSynchronizeStream(stream);
aclrtMemcpy(zHost, outputByteSize, zDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST);
// PrintData(zHost, 16, printDataType::HALF);
WriteFile("./output/output_z.bin", zHost, outputByteSize);
aclrtFree(xDevice);
aclrtFree(yDevice);
aclrtFree(zDevice);
aclrtFreeHost(xHost);
aclrtFreeHost(yHost);
aclrtFreeHost(zHost);
aclrtDestroyStream(stream);
aclrtResetDevice(deviceId);
aclFinalize();
#endif实质上,使用的是内核调用符方式:<<<>>>
#ifndef __CCE_KT_TEST__
// call of kernel function
void add_tik2_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z)
{
add_tik2<<<blockDim, l2ctrl, stream>>>(x, y, z);
}
#endif2、算子验证
通过numpy生成输入x,y的值,并计算出x+y的值作为精度比对基准,上述三个数据落盘存储,然后调用写好的add算子在CPU模式和npu模式下分别以落盘的x,y作为输入,计算出结果z,并于numpy的计算结果进行对比,验证。采用计算md5方式比较add算子和numpy对相同输入的计算结果,两者md5相同,则两个文件完全相同。
1)生成基准数据——add_tik2.py
用numpy的随机生成输入:input_x和input_y,并计算出input_x+input_y的值golden作为比对基准数据,并落盘存储。
import numpy as np
def gen_golden_data_simple():
input_x = np.random.uniform(-100, 100, [8, 2048]).astype(np.float16)
input_y = np.random.uniform(-100, 100, [8, 2048]).astype(np.float16)
golden = (input_x + input_y).astype(np.float16)
input_x.tofile("./input/input_x.bin")
input_y.tofile("./input/input_y.bin")
golden.tofile("./output/golden.bin")
if __name__ == "__main__":
gen_golden_data_simple()
2)数据比对
直接比较算子计算结果和基准数据的md5,两者相同,则数据完全相同。在run.sh的末尾处。
# 验证计算结果
echo "md5sum: ";md5sum output/*.bin三、运行调试
本次训练营没有提供开发环境,提供了一个沙箱,沙箱已经安装好了开发环境。首先把代码搞沙箱里面。老师为了简化操作,提前将cpu和npu模式下的编译和运行,封装到脚本run.sh中。使用脚本命令分别执行CPU或NPU模式下的调试。
一)CPU模式下运行、调试
1、编译、运行:
bash run.sh add_tik2 ascend910 aicore cpu编译及运行结果:
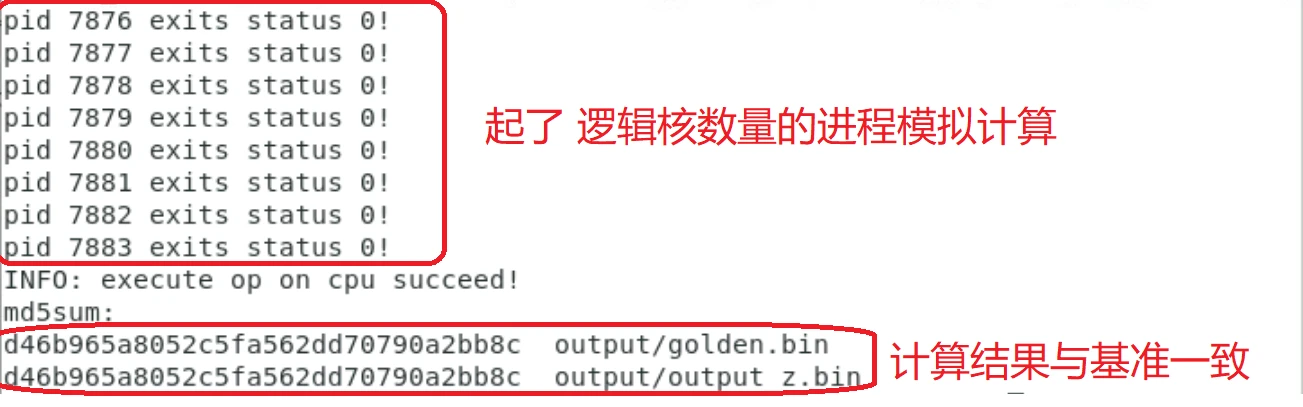
2、gdb调试:
使用gdb单步调试算子计算精度,也可以在代码中直接编写printf(...)来观察数值的输出。由于cpu调测已转为多进程调试,每个核都是一个独立的子进程,故gdb需要转换成子进程调试的方式。
在gdb启动后,首先设置跟踪子进程,之后再打断点,就会停留在子进程中,设置的命令为:
set follow-fork-mode child这样,停留在遇到断点的第一个子进程中。其余不再赘述。
二)NPU模式下运行、调试
1、运行:
bash run.sh add_tik2 ascend910 aicore npu编译及运行结果:
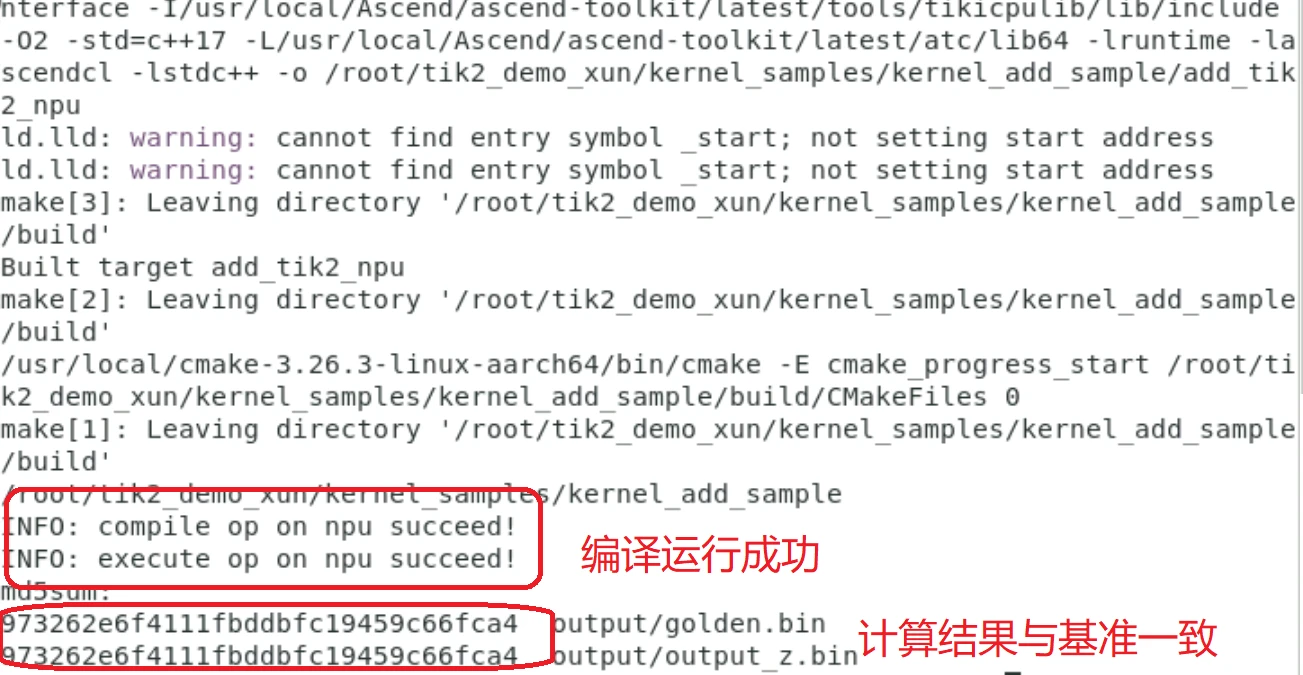
2、调试:
在真实芯片上获取profiling数据,进行性能精细调优。
msprof --application="./add_tik2_npu" --output="./out" --ai-core=on --aic-metrics="PipeUtilization" 执行过程如下:
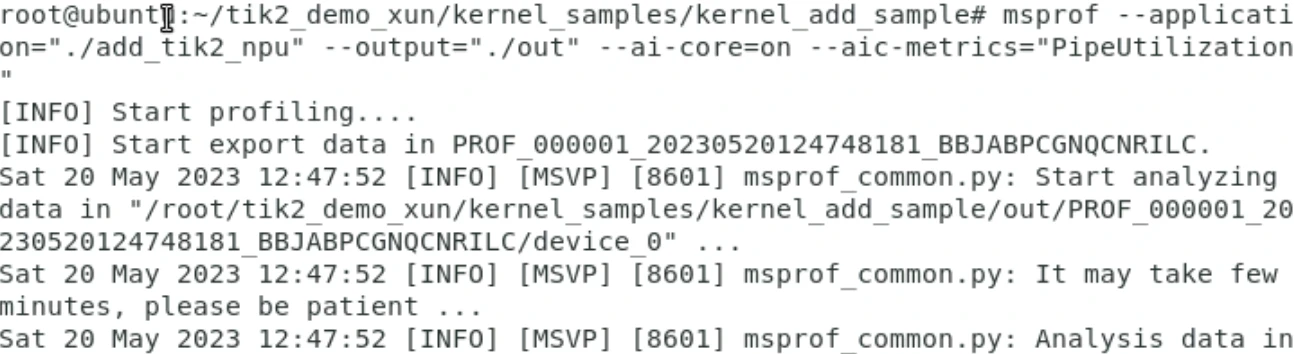

执行后,对Profiling数据进行解析与导出,存放在工程的下述目录下。
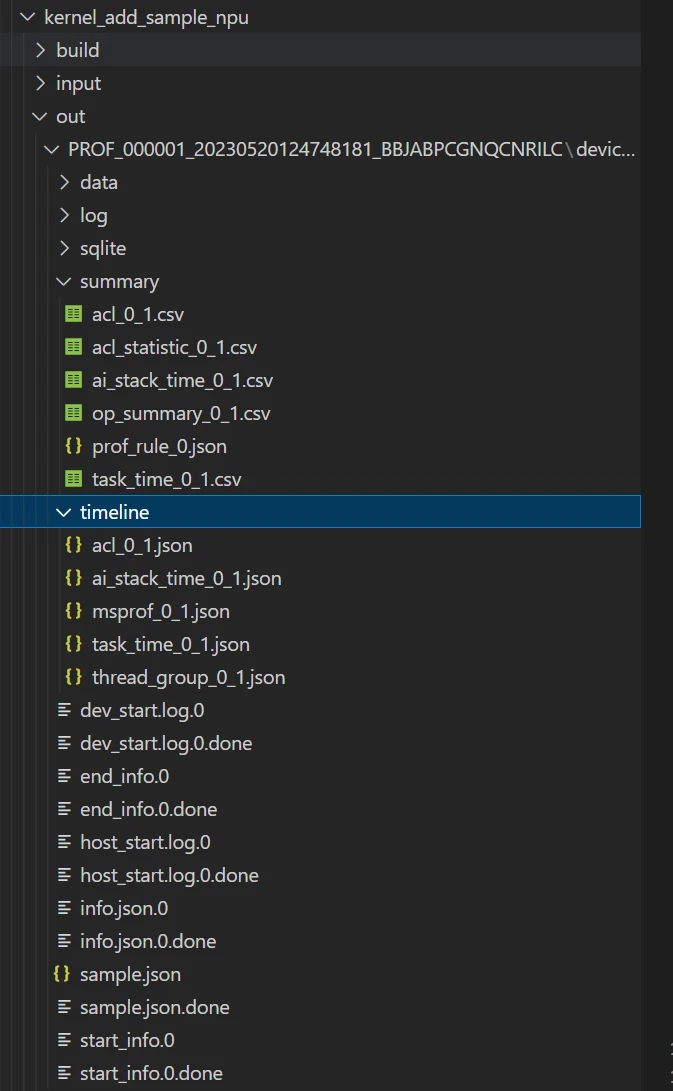

- 点赞
- 收藏
- 关注作者
评论(0)