【2023 · CANN训练营第一季】——Ascend C算子背后的魔法

前言:Ascend C,2023年CANN的一个神奇魔法,得益于Ascend C算子的孪生调试技术,我们可以了解到更多的技术细节,本文试图对隐藏在多核并行,流水计算、dobule buffer背后的CANN Ascend C算子魔法进行摸索和理解,是什么样的技术让用户编写的简单代码可以先实现上述神奇的功能。本文没有请专业人士审查,分析的结果未必正确,只是个人的一种理解,如有错漏,欢迎大家指正!!!
一、硬件基础——向量单元,矩阵单元,数据搬运DMA并行是基础
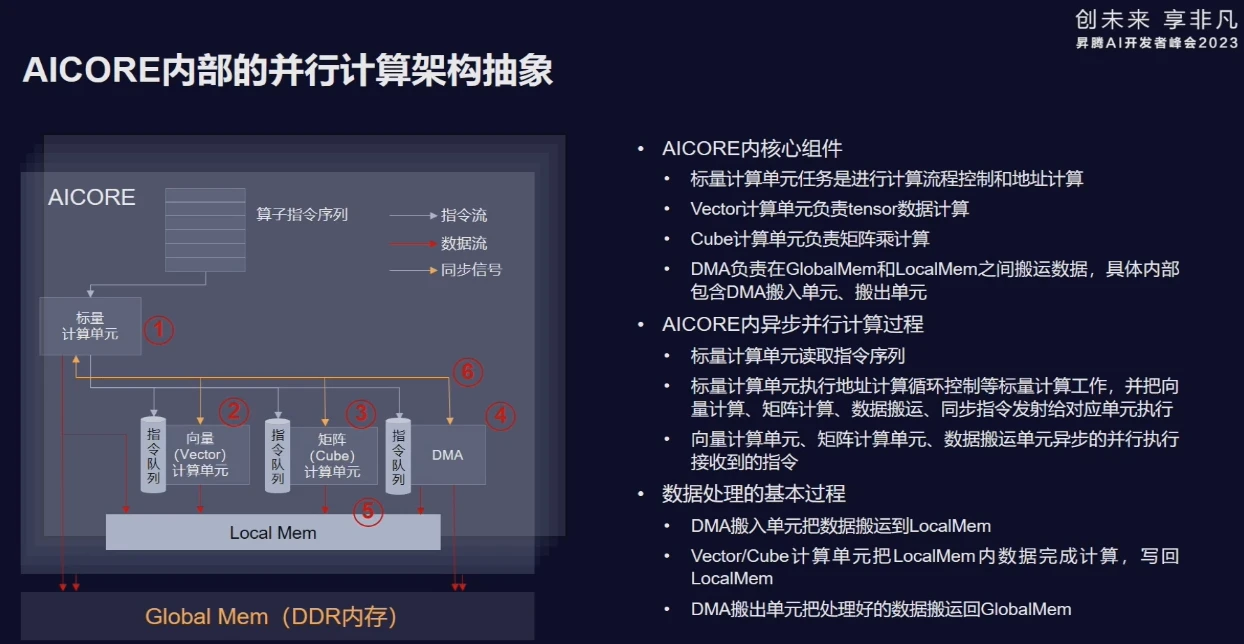
昇腾AI处理器(NPU),可以实现大规模神经网络的计算加速,如下图所示,昇腾AI处理器的计算核心是1个或若干个AI Core,负责执行矩阵、向量、标量计算。Ascend C算子就是运行在AiCore上的。

一)、AICore的架构
如下图所示,单个AICore内,包括:标量计算单元、向量计算单元、矩阵计算单元、本地数据存储单元Local Memory,以及负责数据搬运的DMA单元。
标量计算单元任务是进行计算流程控制和地址计算,向量计算单元负责执行向量运算,矩阵计算单元负责执行矩阵运算;运算单元计算的输入数据,是DMA从Global Mem上搬运到Local Mem上;计算结果也存储在Local Mem上,并由DMA负责将计算结果搬运到Global Mem上。
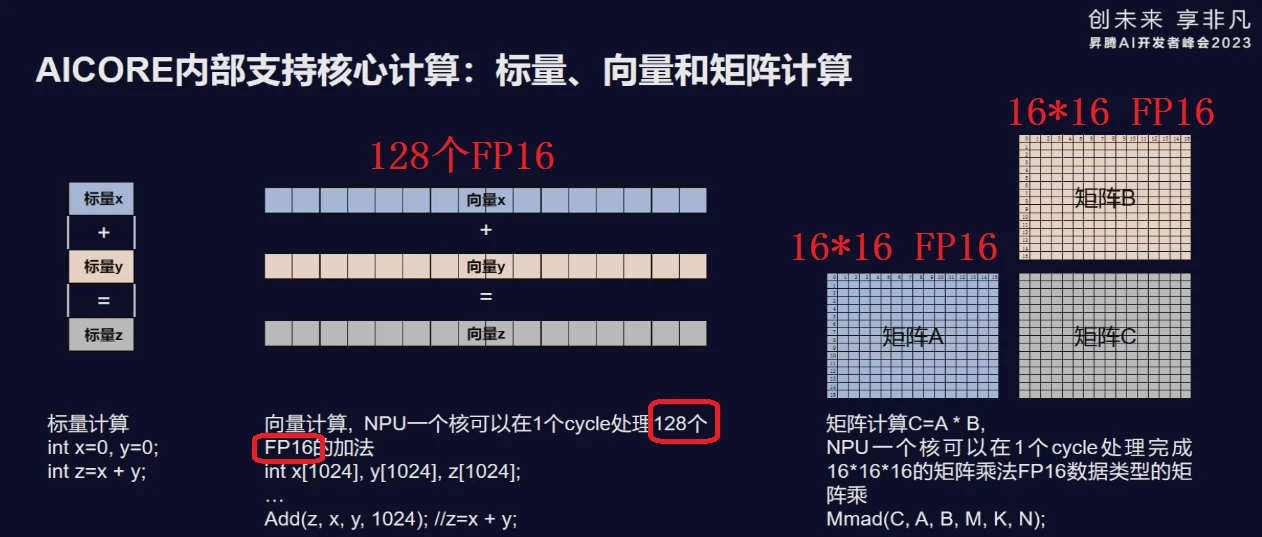
二)AICore计算能力
AICore的三个核心计算单元:
1、标量计算单元:执行标量计算
2、标量计算单元:1cycle可以执行128个FP16的加法;
3、向量计算单元:1cycle可以完成两个16*16 FP16的矩阵乘。
二、技术分析
课上,老师讲述的一个ADD算子的实现。其定义如下:
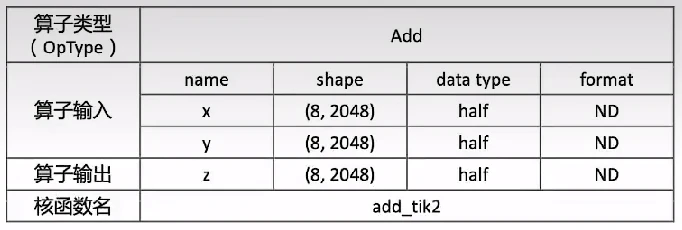
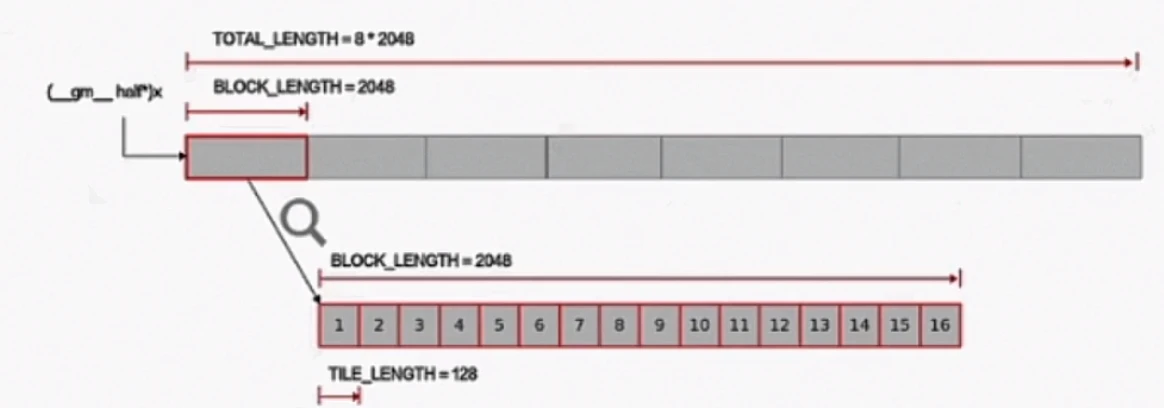
数据整体长度TOTAL_LENGTH为8 * 2048,定义逻辑核熟练USE_CORE_NUM=8(即8个逻辑核),每个核上处理的数据大小BLOCK_LENGTH为2048。
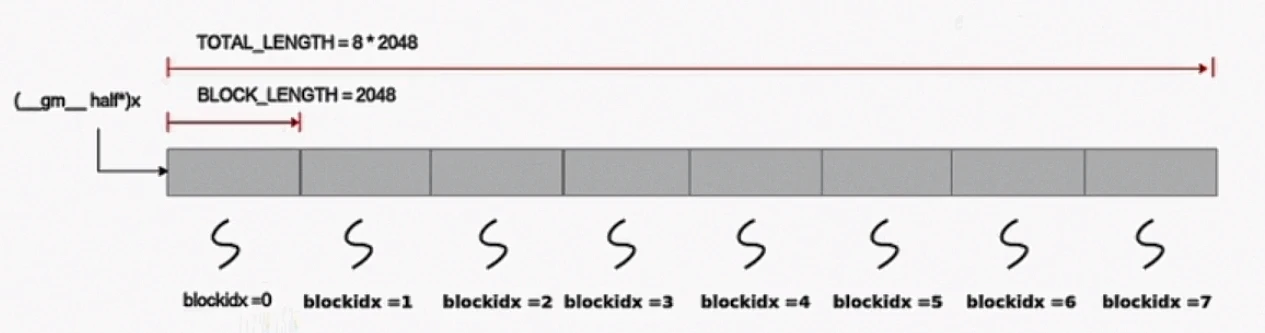
从硬件部分知识,我们知道,单核的向量计算单元一个指令周期能处理128个FP16,所以还需要对单核数据进行切分,切分成16块,每块128个FP16。
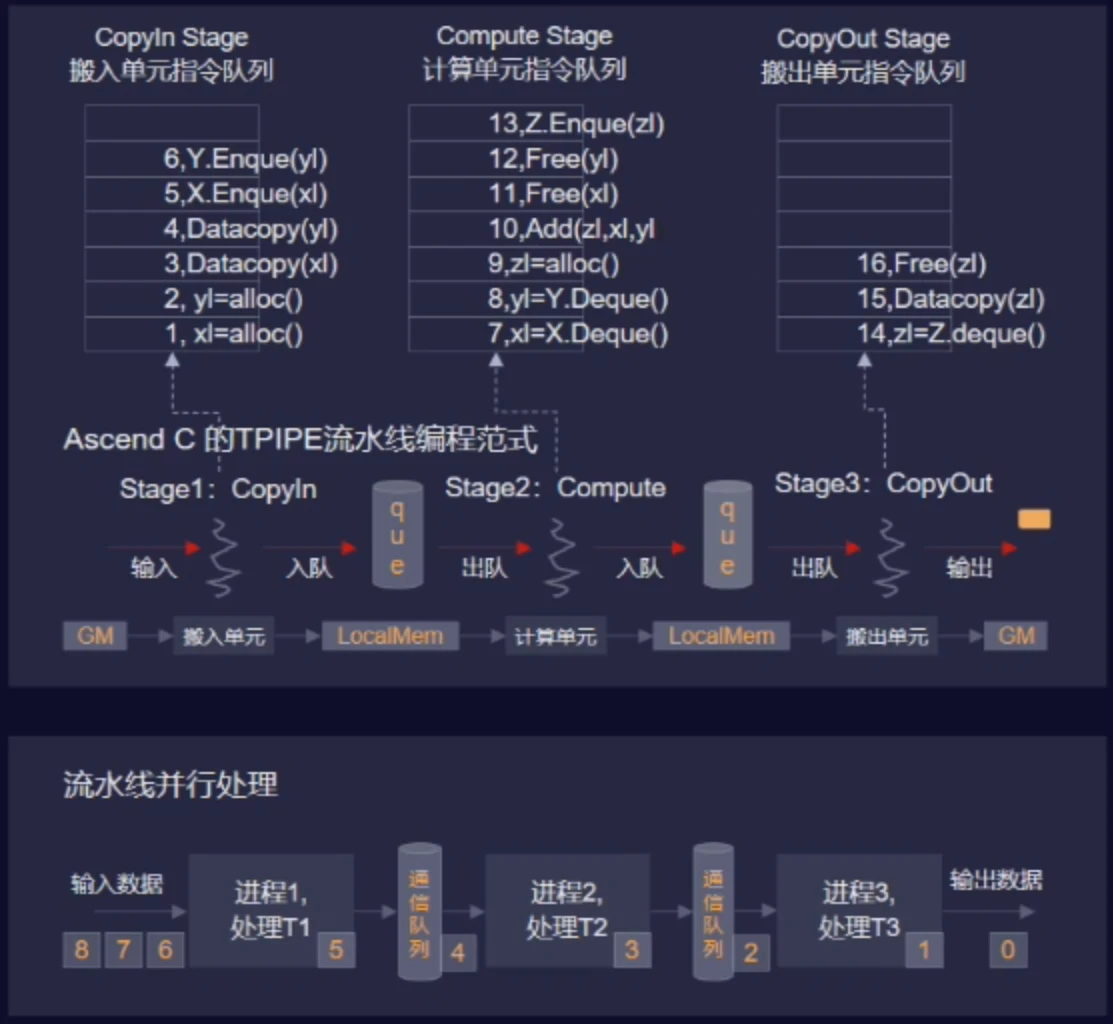
然后通过TPIPE流水线范式,简单的代码就可以让CopyIn、Compute、CopyOut这三个阶段实现流水线工作。
还可以启动double buffer,进行优化,提供流水线的执行效率。
开发者只需要编写简单的代码,就可以的这样高效、并行的能力。背后的黑科技令人神往,下面将结合代码和CPU侧调试获取的信息,做技术分析。
一)、多核并行:
1、开发者需要编写的代码:
在核函数定义里,通过block_idx,计算出输入、输出数据在Global Memory上的偏移地址。
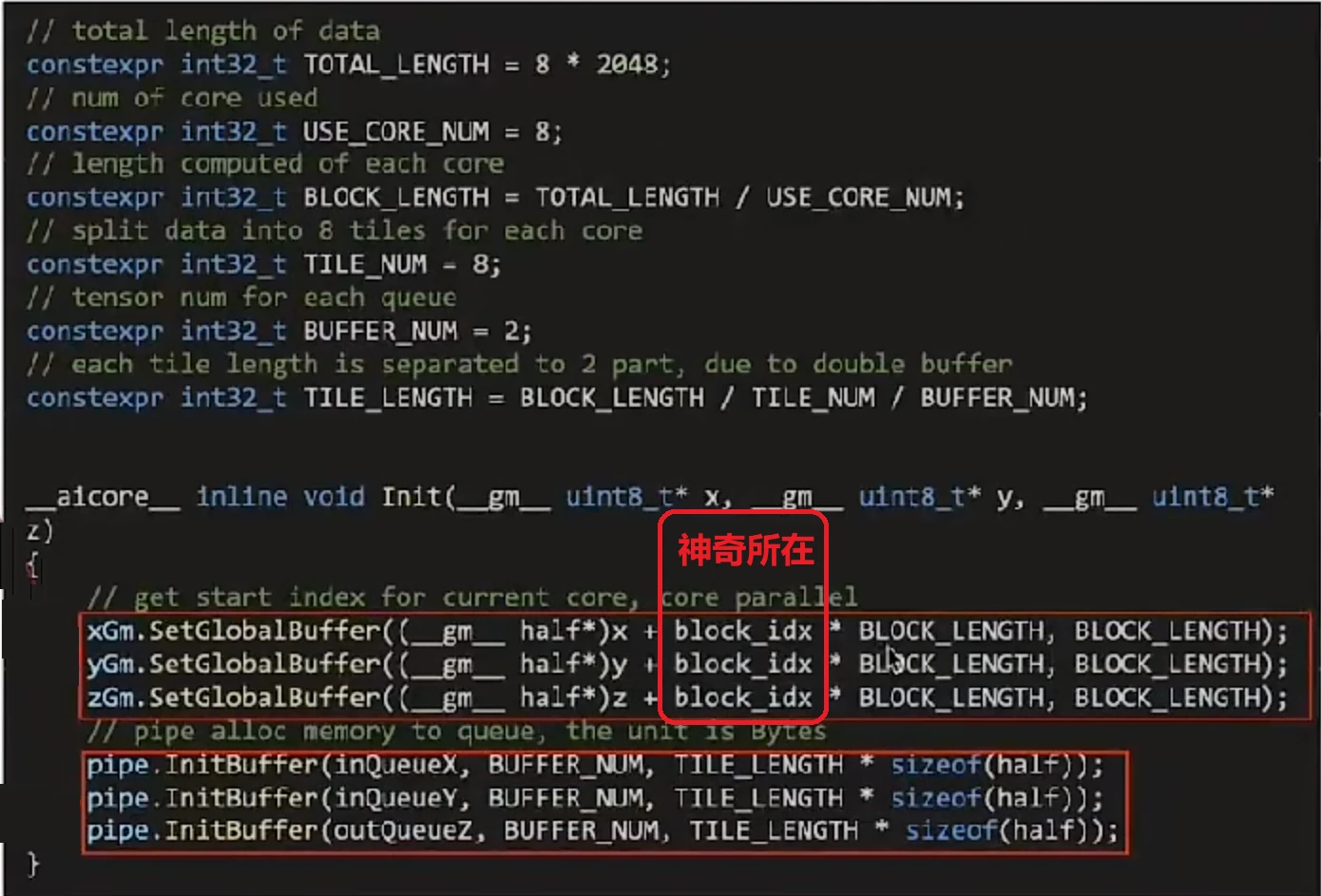
2、背后的黑科技:
2023年昇腾开发者峰会上,CANN首席架构师闫老师说:“芯片内部有多个AI核,AI核是同构的。写一个AI核的计算程序,实际部署时,会启动多个AI核实例,每个实例称之为一个block,所有block运行的程序代码端是完全一样的,入参也是完全一样的。唯一的区别是block_id不同,block_id是个内嵌变量,不是入参。block_id对应逻辑核的数量,按0,1,2...的顺序去排,因此实现了对数据的切分。”
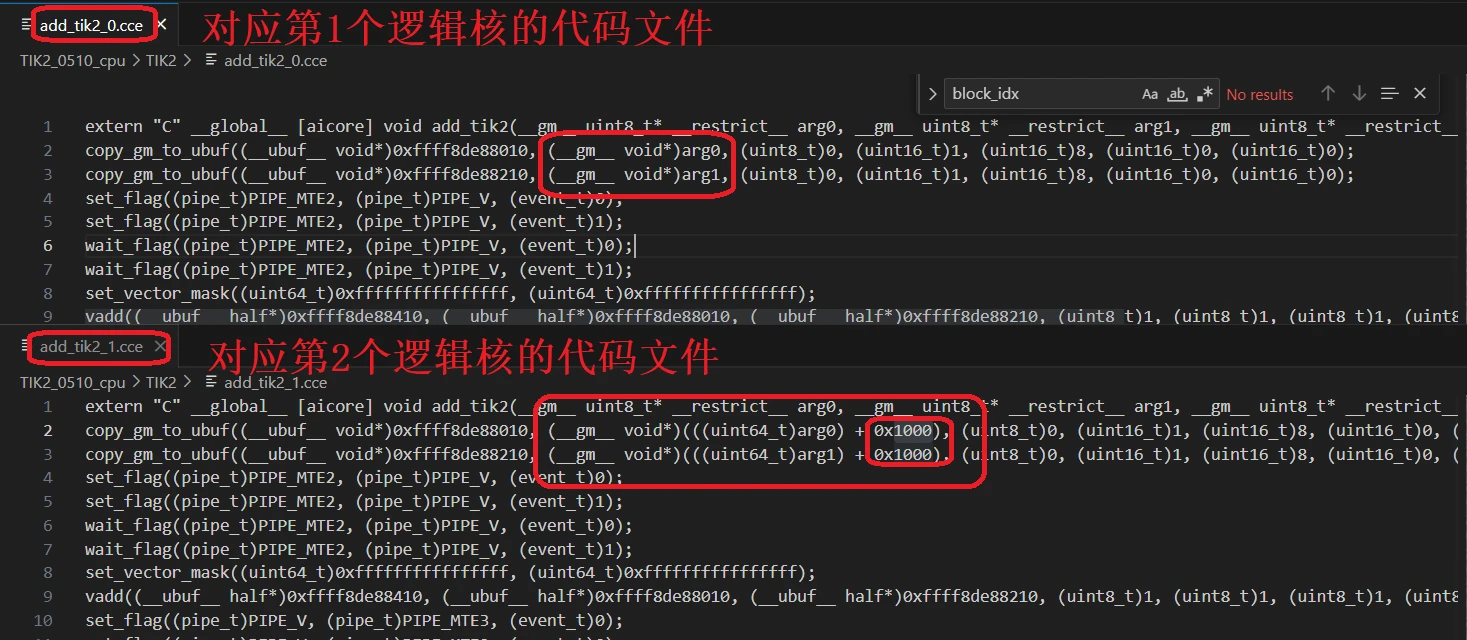
本例在CPU调试模式下,会生成8个CCE文件,代表1个逻辑核的实际指令,我们可以看到2048个fp16,对应4096字节(十六进制0x1000),可以看出相邻2个CCE文件的偏移地址正好是0x1000(4096字节)。

二)、单核流水线:
1、开发者需要编写的代码:
仅一个循环,加3行代码实现了流水线。
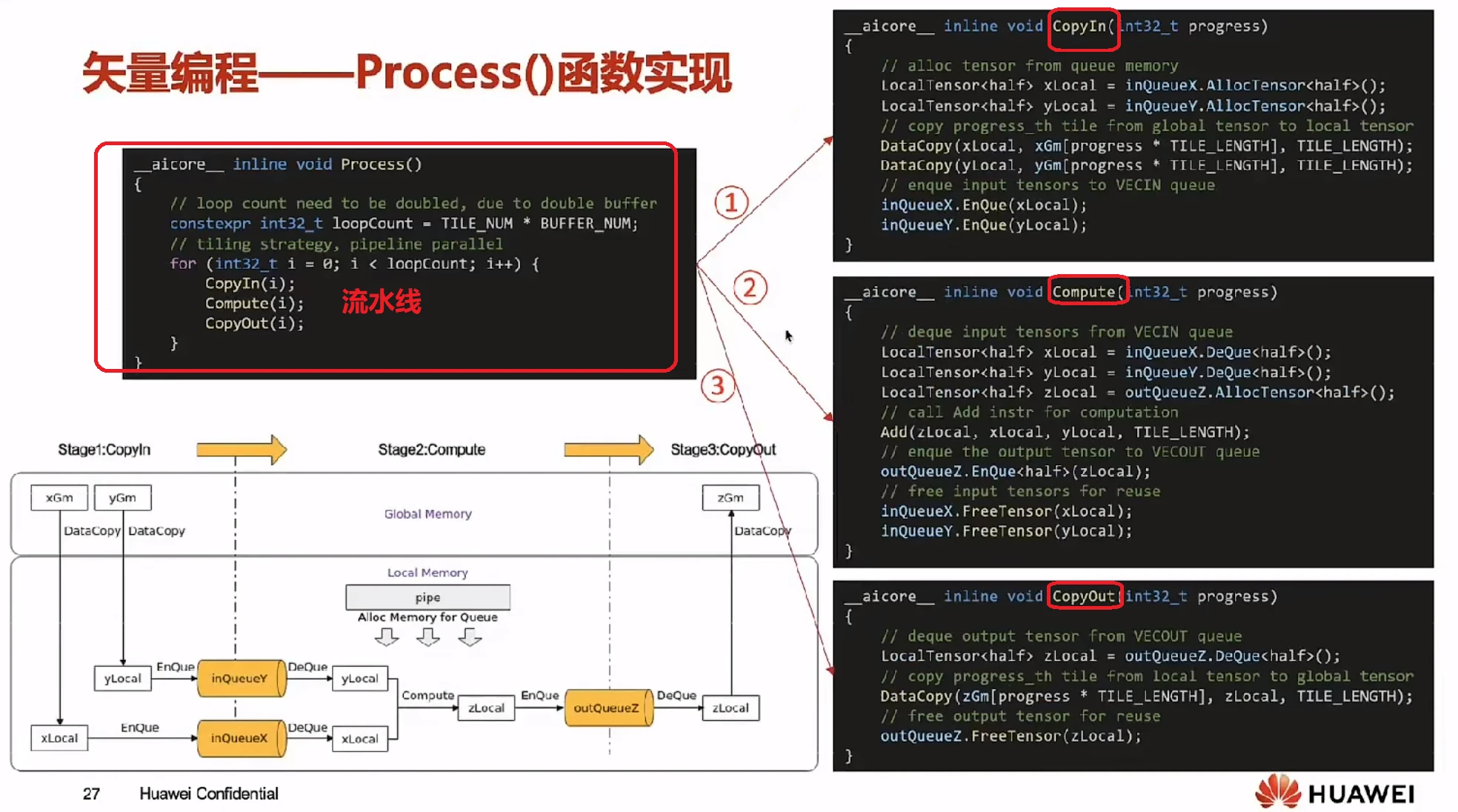
2、背后的魔法:
昇腾AI处理器使用set_flag/wait_flag两条指令组成的指令对,保证队列内部以及队列之间按照逻辑关系执行。set_flag/wait_flag为两条指令,在set_flag/wait_flag的指令中,可以指定一对指令队列的关系,表示两个队列之间完成一组“锁”机制,其作用方式为:
set_flag:当前序指令的所有读写操作都完成之后,当前指令开始执行,并将硬件中的对应标志位设置为1。
wait_flag:当执行到该指令时,如果发现对应标志位为0,该队列的后续指令将一直被阻塞;如果发现对应标志位为1,则将对应标志位设置为0,同时后续指令开始执行。
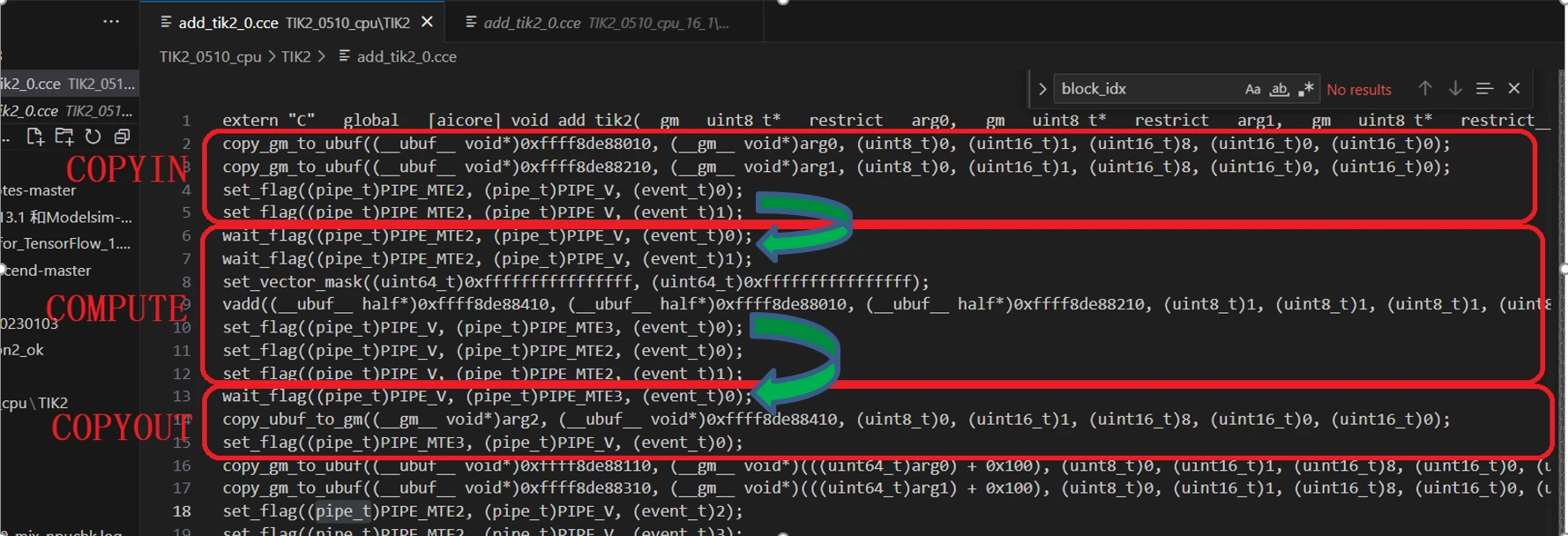
COPYIN单元和COMPUTE单元,通过set_flag/和wait_flag指令对,如上图的绿色箭头,确保COPYIN单元数据拷贝完成后,再由COMPUTE单元执行运算。
COPYOUT单元和COMPUTE单元,通过set_flag/和wait_flag指令对,如上图的绿色箭头,确保COMPUTE单元运算完成后,再由COPYOUT单元搬运计算结果。
这个机制,实现了流水线操作,前序操作完成后,自动执行有关联的后续操作。
不同分块数据(i)之间也是通过set_flag/和wait_flag指令对,实现流水操作的。如下图所示,右侧为不使用double buffer的情况,我们看到在做完第i次ADD后,通过set_flag操作,可以触发第i+1次的COPYIN操作。完成第i次ADD操作后,第i次的输入数已经不再需要了,可以执行第i+1次的COPYIN操作,把数据拷贝入Local Memory。下图,左侧部分是有double bu
ffer的情况,基本原理类似,double buffer背后的技术实现,在下一章节描述。

三)、Double Buffer
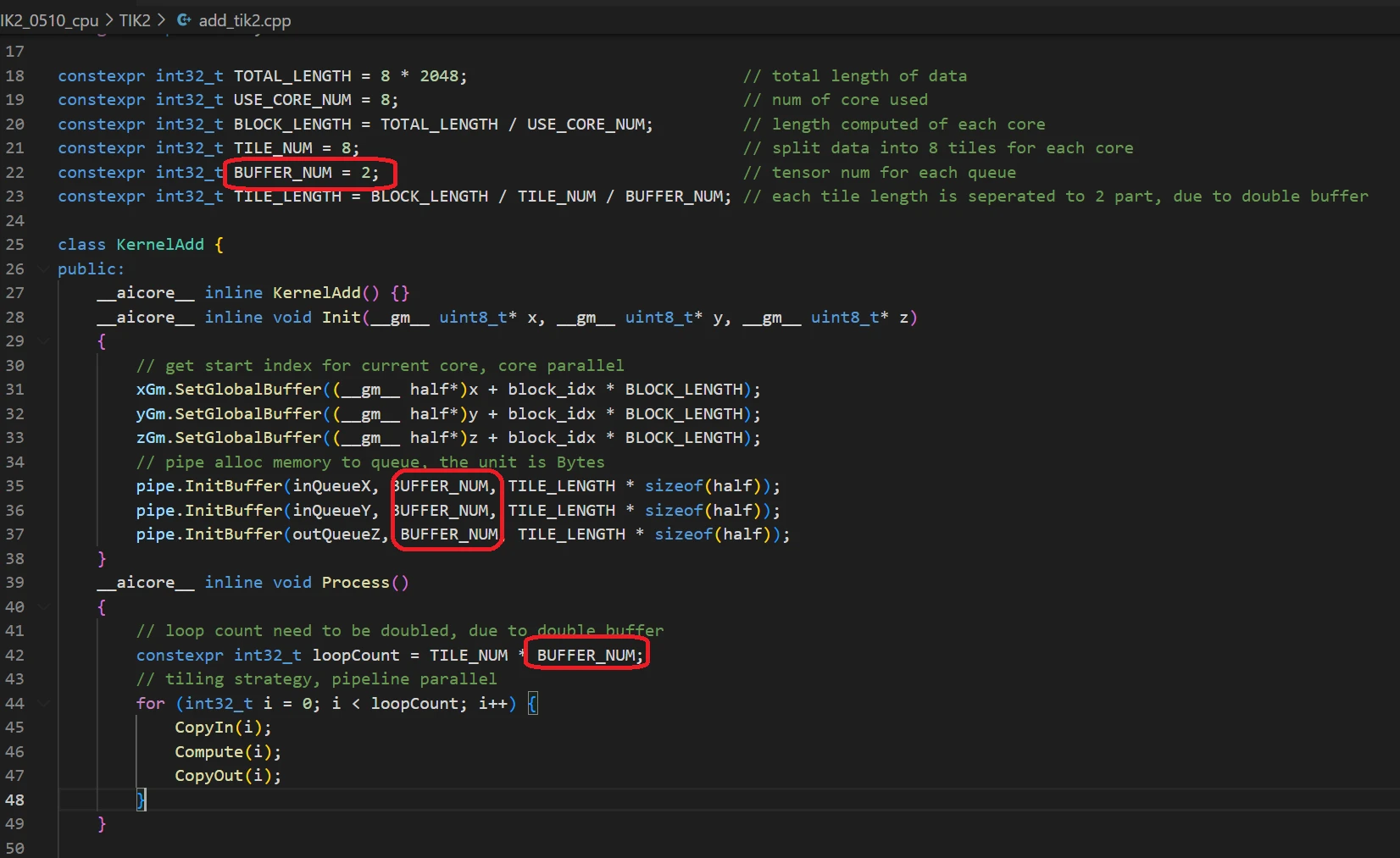
1、开发者需要编写的代码:
开启dobule buffer,只需要引入BUFFER_NUM变量,并修改2处代码即可,见下图。
2、背后的魔法:
“话越少,事越大”,double buffer这个概念困惑了我很久,直到在2023年昇腾开发者峰会上看到下面的两张截图。这两张图很好的讲述了double buffer的作用,先上图,后面再分析。
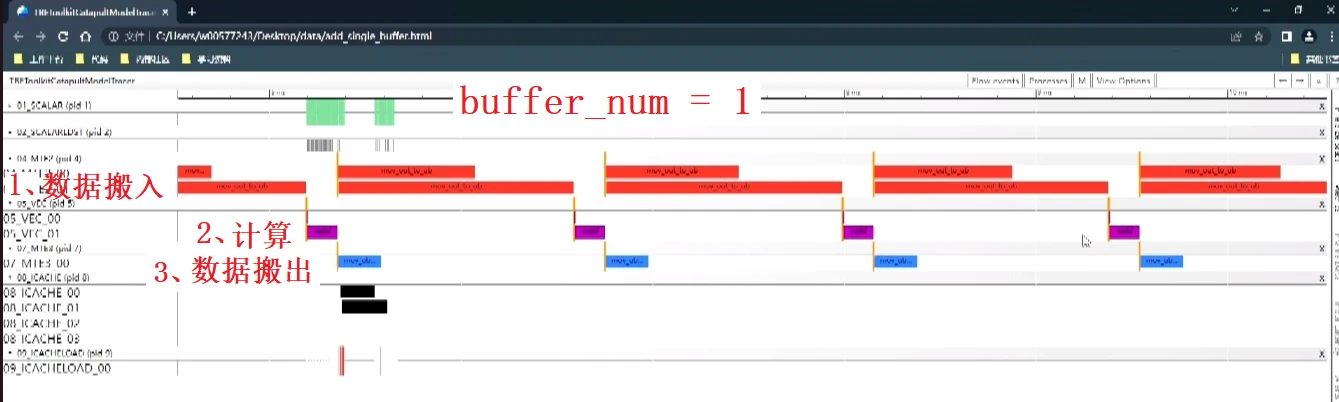 截图于2023年昇腾AI开发者峰会算子演示
截图于2023年昇腾AI开发者峰会算子演示
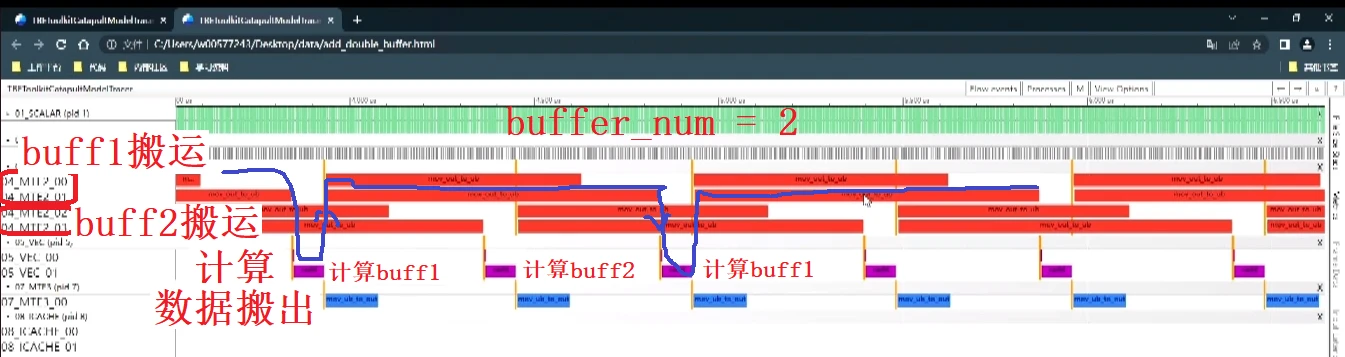
截图于2023年昇腾AI开发者峰会算子演示
我们知道,数据先要从global memory搬运到local memory里(buff1或buff2)里,然后计算单元会对数据进行计算,计算结果存到local memory,然后再把结果搬出到global memory里。我们需要注意到,当计算单元完成计算后,输入数据buff的数据已经没有用了,此时搬运单元会将下一个数据搬入buff,这是流水线的原理,不是double buffer的魔法。这个数据搬入,然后计算的过程,我在第2副图的用蓝色的线进行表示。
从上面的分析我们知道,搬运单元需要等待计算完成后,才能搬入下一组数据。而Double Buffer要优化的是数据搬入单元在等待当前数据计算完成的时间。做法就是在开辟一个存储单元buffer2,当运算单元计算当前buffer1数据时,往buffer2里搬运数据,等计算单元完成buffer1数据计算时,等buffer2数据搬运完成后,开始计算buffer2的数据,此时由于buffer1的数据已经完成计算,所以搬运单元又可以立即往buffer1中搬运新的数据。

- 点赞
- 收藏
- 关注作者
评论(0)