深度学习进阶篇-国内预训练模型[6]:ERNIE-Doc、THU-ERNIE、K-Encoder融合文本信息和KG知识

深度学习进阶篇-国内预训练模型[6]:ERNIE-Doc、THU-ERNIE、K-Encoder融合文本信息和KG知识;原理和模型结构详解。
1.ERNIE-Doc: A Retrospective Long-Document Modeling Transformer
1.1. ERNIE-Doc简介
经典的Transformer在处理数据时,会将文本数据按照固定长度进行截断,这个看起来比较”武断”的操作会造成上下文碎片化以及无法建模更长的序列依赖关系。基于此项考虑,ERNIE-Doc提出了一种文档层级的预训练语言模型方法:ERNIE-Doc在训练某一个Segment时,允许该segment能够获得整个Doc的信息。
如图1所示,假设一篇完整的文档被分割成3个Segment: ,在编码segment 时,经典的Transformer依赖的只是 本身: , Recurrence Transformer (例如 Transformer-XL)依赖的是 : ,这两种方法均没有使Segment 获得完整的文档信息 。
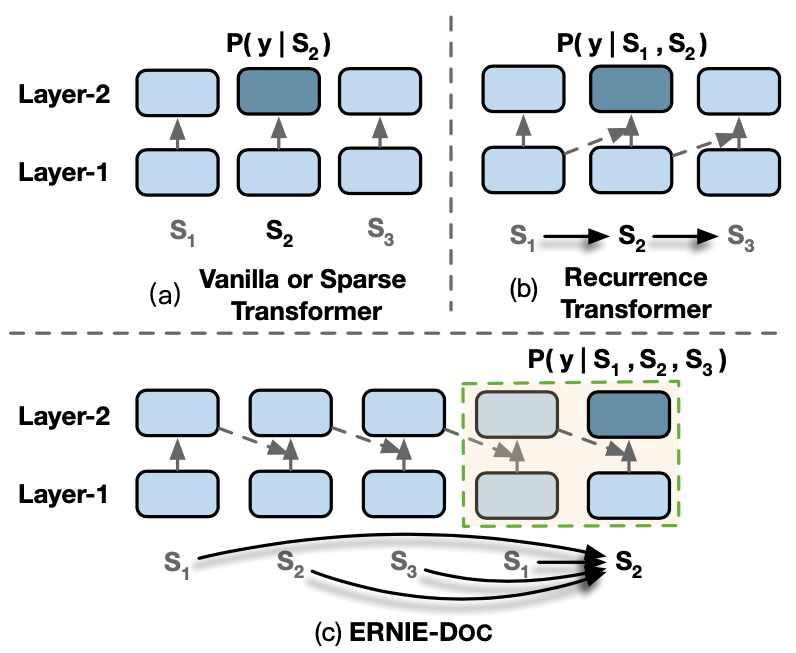
图1 ERNIE-Doc的建模方式图
但是ERNIE-Doc在建模过程中,使得每个Segment均能获得完整的文档信息: ,其中建模长序列的关键点如下:
Retrospective feed mechanism: 将文本两次传入模型获得文本序列的representation,第一次将获得完整的文本序列表示,然后该序列的representation继续参与第二次的编码过程,这样该文本序列在第二次编码过程中,每个token位置便能获得序列完整的双向信息。
Enhanced recurrence mechanism: 使用了一种增强的Segment循环机制进行建模。
Segment-reordering objective: 对一篇文档中的各个segment随机打乱,获得多个乱序文档,然后要求模型预测这些文档中哪个是正常语序的文档。
1.2. 经典/Recurrence Transformer的计算
在正式介绍正式ERNIE-DOC之前,我们先来回顾一下经典和Recurrence Transformer模型的计算。假设当前存在一个长文档 被划分为这样几个Segment: ,其中每个Segment包含 个token: 。另外约定 为Transformer第 层第 个Segment的编码向量。对于第 个Segment ,Transformer第 层对其相应的编码计算方式为:
如上述讨论,这两种方式均不能使得每个Segment获得Doc的完整信息。
1.3. Retrospective feed mechanism
ERNIE-Doc借鉴了人类阅读的行为习惯,在人类阅读时会分为两个阶段:首先会快速略读一下文档内容,然后回过头来仔细阅读。ERNIE-Doc基于此设计了Retrospective feed mechanism,该机制同样包含两个阶段:Skimming phase 和 Retrospective phase。
具体来讲,一篇文档会传入模型两次,第一次被称为Skimming phase,在该阶段将会获得改文档的完整序列表示。第二次被称为 Retrospective phase,在该阶段将会融入Skimming phase获得的完整文档表示,开始进一步的编码计算,从而保证在第二次计算每个Segment编码时能够获得完整的文档信息。Retrospective phase的计算方式如下:
其中以上公式各个参数解释如下:
:一篇文档的Segment数量; :Transformer模型层的数量; :每个Segment中的最大token数量。
:一篇文档在所有层中输出的编码向量。
: 一篇文档在第 层产生的编码向量。
:第 个Segment在第 层产生的编码向量。
从以上公式可以看到,在retrospective 阶段,当计算每个Segment时,会引入完整文档的表示 ,这样就保证了编码时,每个token能够获得完整文档的信息。
1.4. Enhanced Recurrence Mechanism
ERNIE-Doc通过使用Retrospective feed mechanism和Enhanced Recurrence Mechanism两种方式,增大了计算每个segment时的有效上下文长度。但是第3节引入的公式计算复杂度是很高,因此 Enhanced Recurrence Mechanism期望前一个Segment便能获得完整的文档信息,然后直接融入前一个Segment便能使得当前Segment计算融入完整的文档信息。
如图2所示,ERNIE-Doc通过将前一个Segment的同层编码表示,引入了当前Segment的计算中,这个做法同时也有利于上层信息反补下层的编码表示,具体公式为:
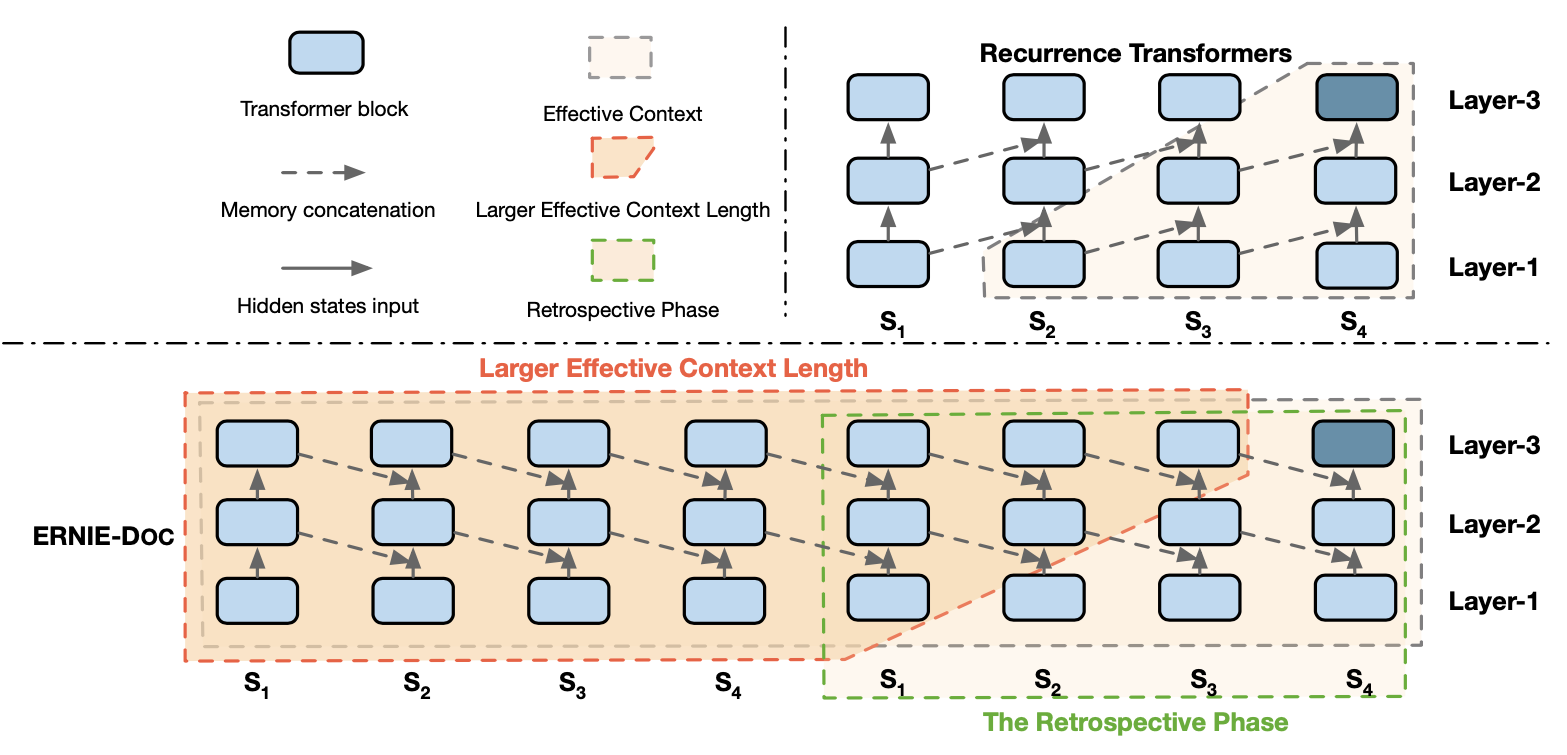
图2 ERNIE的Segment连接方式
1.5. Segment-Reordering Objective
在预训练阶段,ERNIE-Doc使用了两个预训练任务:MLM和Segment-Reordering Objective。我们先来讨论Segment-Reordering Objective,其旨在帮助模型显式地建模Segment之间的关系,其会将一篇长文档进行划分为若干部分,然后将这些部分进行随机打乱,最后让模型进行预测原始的语序,这是一个 分类问题: ,其中 是最大的划分数量。
如图3所示,假设存在一篇文档 被划分为3部分: ,ERNIE-Doc通过打乱这些部分得到 ,然后在最后一个Segment 的位置进行预测原始的文档顺序 。
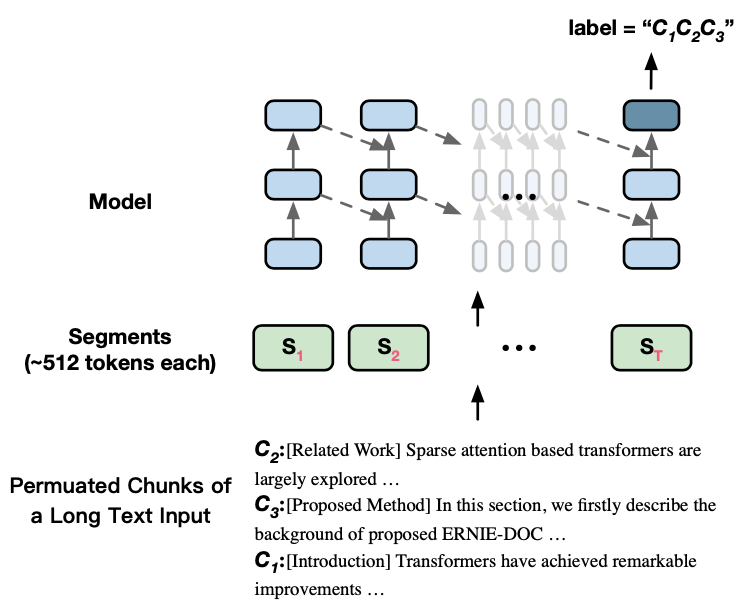
图3 预训练任务Segment-Reordering Objective
另外,在获得 后,ERNIE-Doc会对 进行划分Segment: ,并且会对这些Segment中的某些Token 进行Mask,从而构造MLM任务,要求模型根据破坏的Segment 恢复成原始的 。结合MLM和Segment-Reordering Objective总的预训练目标为:
其中, 表示Segment-Reordering Objective仅仅在最后一个Semgnet 位置被执行,以优化模型。
- 相关资料
2.ERNIE:Enhanced Language Representation with Informative Entities
2.1. THU-ERNIE简介
当前的预训练模型(比如BERT、GPT等)往往在大规模的语料上进行预训练,学习丰富的语言知识,然后在下游的特定任务上进行微调。但这些模型基本都没有使用知识图谱(KG)这种结构化的知识,而KG本身能提供大量准确的知识信息,通过向预训练语言模型中引入这些外部知识可以帮助模型理解语言知识。基于这样的考虑,作者提出了一种融合知识图谱的语言模型ERNIE,由于该模型是由清华大学提供的,为区别百度的ERNIE,故本文后续将此模型标记为THU-ERNIE。
这个想法很好,但将知识图谱的知识引入到语言模型存在两个挑战:
Structured Knowledge Encoding:如何为预训练模型提取和编码知识图谱的信息?
Heterogeneous Information Fusion:语言模型和知识图谱对单词的表示(representation)是完全不同的两个向量空间,这种情况下如何将两者进行融合?
对于第一个问题,THU-ERNIE使用TAGME提取文本中的实体,并将这些实体链指到KG中的对应实体对象,然后找出这些实体对象对应的embedding,这些embedding是由一些知识表示方法,例如TransE训练得到的。
对于第二个问题,THU-ERNIE在BERT模型的基础上进行改进,除了MLM、NSP任务外,重新添加了一个和KG相关的预训练目标:Mask掉token和entity (实体) 的对齐关系,并要求模型从图谱的实体中选择合适的entity完成这个对齐。
2.2. THU-ERNIE的模型结构
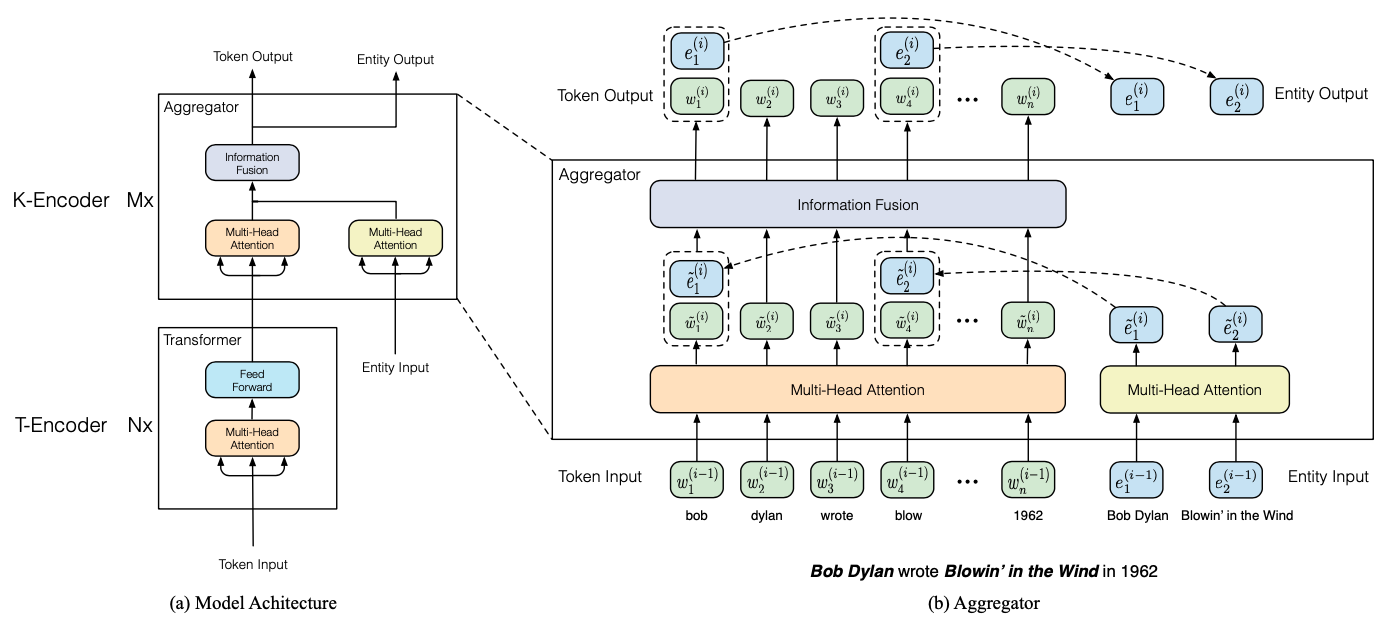
图1 THU-ERNIE的模型架构
THU-ERNIE在预训练阶段就开始了与KG的融合,如图1a所示,THU-ERNIE是由两种类型的Encoder堆叠而成:T-Encoder和K-Encoder。其中T-Encoder在下边堆叠了 层,K-Encoder在上边堆叠了 层,所以整个模型共有 层,T-Encoder的输出和相应的KG实体知识作为K-Encoder的输入。
从功能上来讲,T-Encoder负责从输入序列中捕获词法和句法信息;K-Encoder负责将KG知识和从T-Encoder中提取的文本信息进行融合,其中KG知识在这里主要是实体,这些实体是通过TransE模型训练出来的。
THU-ERNIE中的T-Encoder的结构和BERT结构是一致的,K-Encoder则做了一些改变,K-Encoder对T-Encoder的输出序列和实体输入序列分别进行Multi-Head Self-Attention操作,之后将两者通过Fusion层进行融合。
2.3. K-Encoder融合文本信息和KG知识
本节将详细探讨K-Encoder的内部结构以及K-Encoder是如何融合预训练文本信息和KG知识的。图1b展示了K-Encoder的内部细节信息。
我们可以看到,其对文本序列 (token Input) 和KG知识(Entity Input)分别进行Multi-Head Self-Attention(MH-ATT)操作,假设在第 层中,token Input对应的embedding是 ,Entity Input对应的embedding是 ,则Multi-Head Self-Attention操作的公式可以表示为:
然后Entity序列的输出将被对齐到token序列的第一个token上,例如实体”bob dylan”将被对齐到第一个单词”bob”上。接下里将这些MH-ATT的输入到Fusion层,在这里将进行文本信息和KG知识的信息融合。因为有些token没有对应的entity,有些token有对应的entity,所以这里需要分两种情况讨论。
对于那些有对应entity的token,信息融合的过程是这样的:
对于那些没有对应entity的token,信息融合的过程是这样的:
其中这里的 是个非线性的激活函数,通常可以使用GELU函数。最后一层的输出将被视作融合文本信息和KG知识的最终向量。
2.4. THU-ERNIE的预训练任务
在预训练阶段,THU-ERNIE的预训练任务包含3个任务:MLM、NSP和dEA。dEA将随机地Mask掉一些token-entity对,然后要求模型在这些对齐的token上去预测相应的实体分布,其有助于将实体注入到THU-ERNIE模型的语言表示中。
由于KG中实体的数量往往过于庞大,对于要进行这个任务的token来讲,THU-ERNIE将会给定小范围的实体,让该token在这个范围内去计算要输出的实体分布,而不是全部的KG实体。
给定token序列 和对应的实体序 ,对于要对齐的token 来讲,相应的对齐公式为:
类似与BERT对token的Mask策略,THU-ERNIE在Mask token-entity对齐的时候也采用的一定的策略,如下:
以5%的概率去随机地替换实体,让模型去预测正确的entity。
以15%的概率直接Mask掉token-entity,让模型去预测相应的entity。
以80%的概率保持token-entity的对齐不变,以让模型学到KG知识,提升语言理解能力。
最终,THU-ERNIE的总的预训练损失是由MLM、NSP和dEA三者的加和。
- 参考资料

- 点赞
- 收藏
- 关注作者
评论(0)