Splunk 查找和字段:Splunk 知识对象

在我之前的博客中,我解释了有助于简化搜索的Splunk 事件、事件类型和标签。在这篇博客中,我将解释以下概念——Splunk 查找、字段和字段提取。
我将讨论为什么查找很重要,以及如何通过匹配唯一键值来关联来自外部源的数据。另一方面,Splunk 字段通过为事件提供特定值来帮助丰富您的数据。我还解释了如何以不同方式提取这些字段。
因此,让我们开始使用 Splunk Lookup。
Splunk 查找
您可能熟悉 Excel 中的查找。Splunk 查找以类似的方式工作。例如,您有一个 product_id 值,该值与其在不同文件(例如 CSV 文件)中的定义相匹配。Lookup 可以帮助您在新字段中映射产品的详细信息。假设您有 product_id=2 并且产品的名称存在于不同的文件中,那么 Splunk 查找将创建一个新字段 - 'product_name',它具有与其关联的 'product_id'。
- 查找表是键和值的映射。
- Splunk Lookup 可帮助您根据与事件数据中的字段匹配的值从外部源添加字段。
- 它在比较不同的事件字段的同时丰富了数据。
- Splunk 查找命令可以接受多个事件字段和目标字段。
- 它可以在搜索时将字段转换为更有意义的信息。
如果您看到下图,这些是不同类型的 Splunk 查找,我将在下面详细解释。
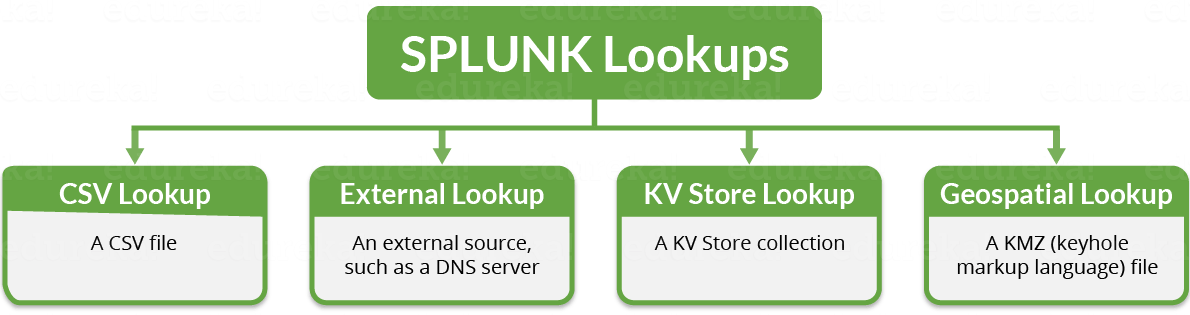
- CSV 查找:顾名思义,CSV 查找从 CSV 文件中提取数据。它使用字段填充事件数据并将其表示在静态数据表中。因此,它也被称为“静态查找”。必须至少有两列表示具有一组值的字段。 它们可以有多个相同值的实例。
- 外部查找:在这种类型的查找中,它会从外部源(例如 DNS 服务器)填充您的事件数据。它可以使用 Python 脚本或二进制可执行文件从外部源获取字段值。因此,它也被称为“脚本查找”。
- KV 存储查找:在这种类型的查找中,它使用从您的应用键值存储(KV 存储)集合中提取的字段填充您的事件数据。此查找将事件中的字段与 KV 存储中的字段进行匹配。
- 地理空间查找: 在这种类型的查找中,数据源是一个 KMZ(压缩锁孔标记语言)文件,用于定义映射区域(例如美国州和美国县)的边界。它匹配 KMZ 文件中的事件,并将字段输出到以 KMZ 编码的事件,例如国家、州或县名。

您可以通过以下方式配置 Splunk 查找:
设置 -> 查找
单击“查找”后,将显示一个新页面,显示“创建和配置查找”。
您可以创建新的查找或编辑现有的查找。
请参阅左侧的屏幕截图以更好地了解如何创建 Splunk 查找。
有 3 种方法可以创建和配置 Splunk 查找:
- 查找表文件
- 查找定义
- 自动查找
让我们深入了解更多细节并了解这些不同的方式:
1. 查找表文件:在查找表文件中,您可以简单地上传一个新文件。当您单击“添加新”视图时,您可以上传 CSV 文件以在您的字段查找中使用。
要创建查找表文件,您需要按照以下步骤操作:
» 转到查找页面
» 打开查找表文件
» 单击新增
» 上传查找文件,浏览要上传的 CSV 文件 (product.csv)。
» 在目标文件名下,命名文件产品。文件
请参阅下面的屏幕截图以获得更好的理解。

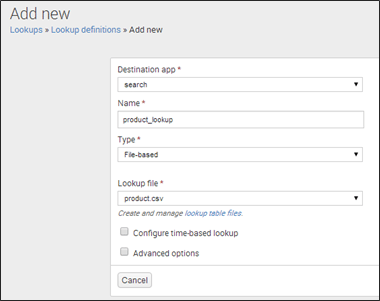
2. 查找定义:查找定义有助于编辑现有查找定义或定义新的基于文件的查找。在定义查找时,您可以重复使用相同的文件,然后使该查找自动运行。
要创建查找定义,您需要执行以下步骤:
» 转到查找页面
» 打开查找定义
» 单击“添加新”
» 将打开一个新框以添加字段定义
» 提供查找的名称
» 设置类型作为“基于文件”
» 选择查找文件的名称 (product.csv)
请参阅下面的屏幕截图以获得更好的理解。
3. 自动查找: 自动查找有助于将新查找配置为自动运行或编辑现有查找。
要创建自动查找,您可以执行以下步骤:
» 转到查找页面» 打开自动查找» 单击新增» 将打开一个新框以添加自动查找» 提供自动查找的名称» 在查找表下, select product_lookup » 选择查找输入和输出字段。
请参阅下面的屏幕截图以获得更好的理解。

创建 Splunk 查找有两个重要的搜索命令 - 输入和输出查找。这些解释如下。
输入查找:Inputlookup 命令从指定的静态查找表中加载搜索结果。它扫描由文件名或表名指定的查找表。如果“append”设置为true,则查找文件中的数据将附加到当前结果集。对于 前充足:阅读product.csv查找文件。
| 输入查找产品.csv
Outputlookup :Outputlookup 命令将搜索结果写入指定的静态查找表。它将结果保存到由文件名或表名指定的查找表中。如果“createinapp”选项设置为 false 或当前没有应用程序,则 Splunk 在系统查找目录中创建文件。例如:写入 product.csv 查找文件。
| 输出查找产品.csv
到现在为止, 您应该已经了解 Splunk 查找是如何创建的。接下来,我将解释 Splunk 字段以及如何提取这些字段以丰富您的数据。
Splunk 字段
假设您有一个公司的大量数据,并且您需要一种简单的方法来访问键=值对中的信息。假设您要识别特定员工的姓名或要查找员工 ID。为此,我们可以声明一个 Splunk 字段,例如 Emp_name 或 Emp_ID,并为其关联一个值。
例如:Emp_name="Jack" 或 Emp_ID='00124'
- 字段是事件数据中的可搜索名称。
- 字段通过向字段提供特定值来过滤事件数据。
- 字段是 Splunk 搜索、报告和数据模型的构建块。
- 一个字段可以有多个值。它可以多次出现,每次都有不同的值。
- 字段名称区分大小写。
现在让我们了解如何提取字段。
Splunk 字段提取:从事件中提取字段的过程是 Splunk 字段提取。默认情况下会提取一些字段,例如:主机、源、源类型和时间戳。我将用一个简单的例子来解释,以正确理解这个过程。

正如您在上面的示例中看到的,它显示了事件数据。在这种情况下,我采用了任何示例事件并将源类型保留为“splunk_web_access”。现在 Splunk Enterprise 将根据 sourcetype 收集的数据提取字段。
在上面的示例中,我选择了正则表达式,它有助于匹配示例事件中突出显示的值。现在,我提取了值“537.36”并将字段名称指定为“test”。这将显示一组值和提取的值。让我们看看这些提取的值是如何显示的。

现在,根据 Splunk 提取字段的时间,有两种类型的字段提取:
- 索引时间字段提取(在默认字段的情况下)
- 搜索时间字段提取(在搜索字段的情况下)
让我们更详细地了解它:
| 索引时间字段提取 | 搜索时间字段提取 |
| 1.索引时间字段提取发生在Splunk索引数据的索引时间。 | 1.搜索时间字段提取发生在我们搜索数据的搜索时间。 |
| 2. 您可以在索引之前定义自定义源类型和主机,以便它可以用它们标记事件。 | 2. 您不能更改主机或源类型分配。 |
| 3. Splunk 为每个事件(如主机、源和源类型)提取一组默认字段。它还包括静态或动态主机分配、结构化数据字段提取、自定义索引时间字段提取、事件时间戳等。 | 3. Splunk 可以根据其搜索设置提取默认字段以外的其他字段。它包括事件类型匹配、搜索时字段提取、从查找中添加字段、事件分割、字段别名、标记等。 |
接下来,Splunk 有 3 种方式来实现字段提取。
- 使用字段提取器实用程序
- 在 Splunk Web 中使用字段提取页面
- 直接在 .conf 文件中使用字段提取
下面详细解释这三个:
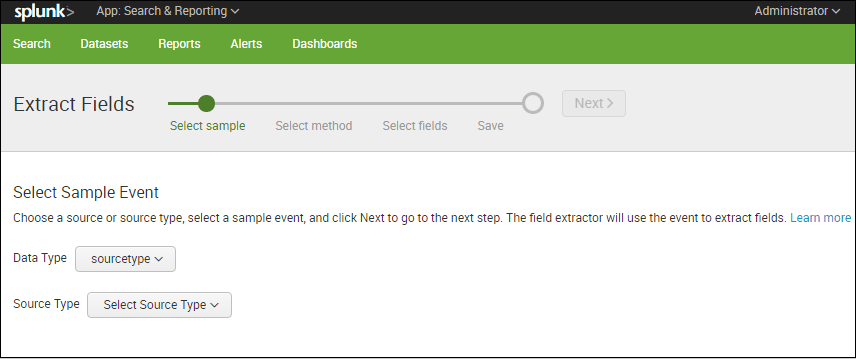
1. 使用字段提取器实用程序:您可以使用字段提取器实用程序创建新字段此外,它还用于在您的 Splunk 实例中动态创建自定义字段。
- 字段提取器使您能够通过选择示例事件并突出显示要从该事件中提取的字段来定义字段提取。
- 它提供了两种提取字段的方法——正则表达式和分隔符。正则表达式方法最适用于非结构化事件数据,而分隔符是为结构化事件数据设计的。
- 如果您不熟悉正则表达式语法和用法,字段提取器实用程序会很有用,因为它会生成字段提取正则表达式并允许您测试它们。
请参阅下面的屏幕截图以获得更好的理解。
2. 在 Splunk Web 中使用字段提取页面:我们可以使用“字段提取页面”来管理搜索时的字段提取。字段提取页面使我们能够:
- 查看整个搜索时间提取集。
- 创建新的搜索时间字段提取。
- 更新字段提取的权限。
- 删除字段提取
让我们看看如何在 Splunk Web 中访问字段提取页面:转到设置 -> 字段 -> 字段提取
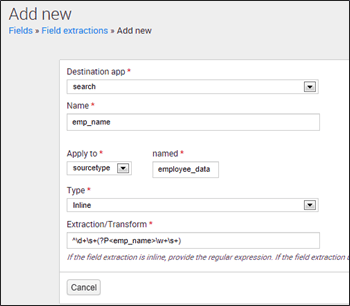
在上面的截图中,我解释了如何从employee_data sourcetype 中提取employee name 字段。您可以使用以下正则表达式来提取 emp_name 字段:^d+s+(?P<emp_name>w+s+)此外,如果您不知道如何创建正则表达式,可以从字段提取器实用程序生成此正则表达式。
3.直接在.conf文件中使用字段提取:您也可以通过直接编辑props.conf和transforms.conf文件来提取字段。您可以在:$SPLUNK_HOME/etc/system/local/中找到它们
注意:不要编辑$SPLUNK_HOME/etc/system/default/ 中的文件,因为它包括系统设置、身份验证和授权信息、索引映射和各种其他重要设置。
所以,这都是关于 Splunk 知识对象的。我希望这些博客能帮助您了解不同的知识对象及其在为您的业务带来运营效率方面所扮演的角色。查看下一个教程博客,它解释了每个 Splunk 管理员必须掌握的三个概念——许可、数据老化和配置文件。

- 点赞
- 收藏
- 关注作者
评论(0)