深度学习进阶篇-国内预训练模型[5]:ERINE、ERNIE 3.0、ERNIE-的设计思路、模型结构、应用场景等详解

深度学习进阶篇-国内预训练模型[5]:ERINE、ERNIE 3.0、ERNIE-的设计思路、模型结构、应用场景等详解
后预训练模型时代
1.ERINE
1.1 ERINE简介
ERINE是百度发布一个预训练模型,它通过引入三种级别的Knowledge Masking帮助模型学习语言知识,在多项任务上超越了BERT。在模型结构方面,它采用了Transformer的Encoder部分作为模型主干进行训练,如 图1 (图片来自网络)所示。
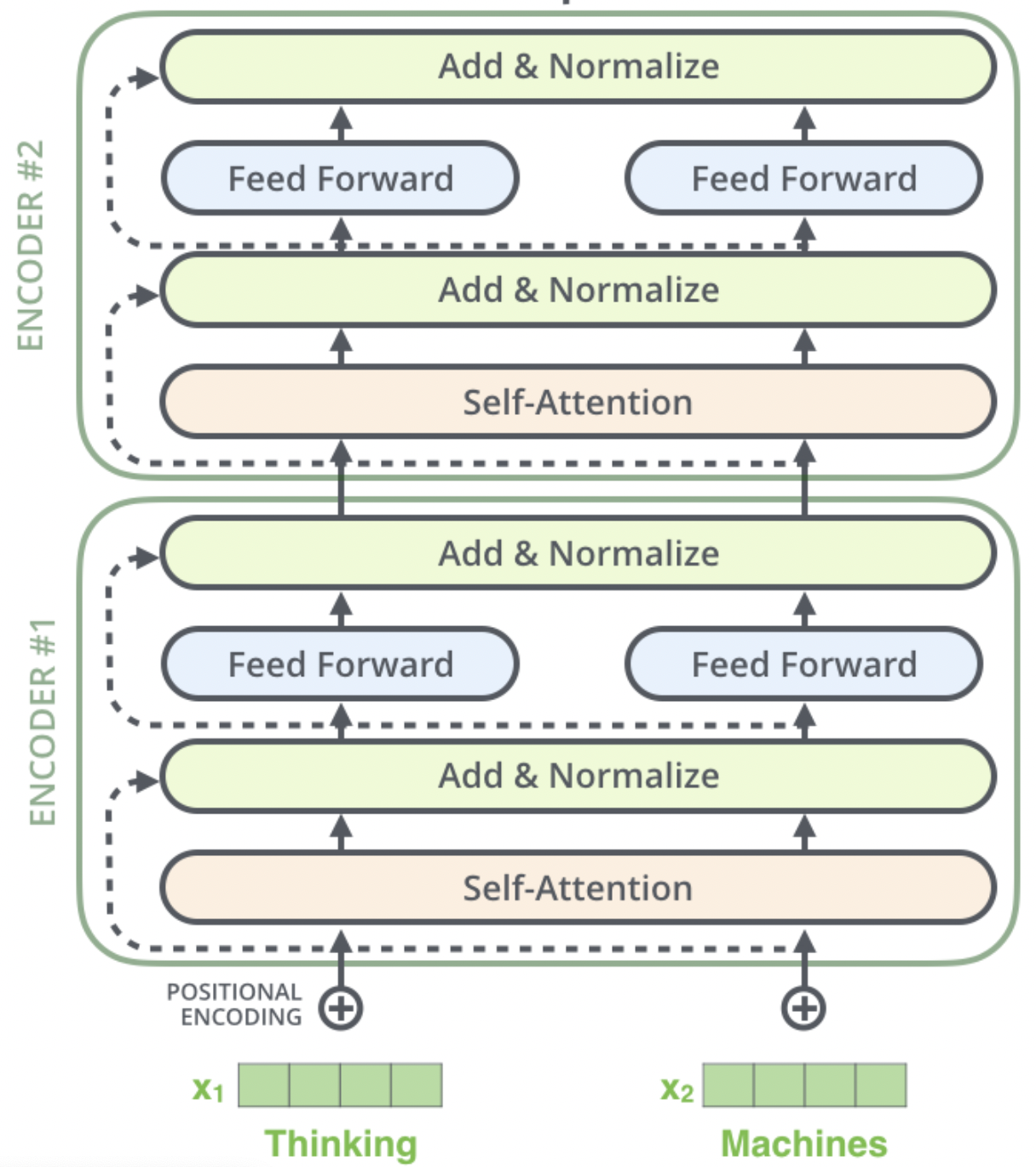
图1 Transformer的Encoder部分
关于ERNIE网络结构(Transformer Encoder)的工作原理,这里不再展开讨论。接下来,我们将聚焦在ERNIE本身的主要改进点进行讨论,即三个层级的Knowledge Masking 策略。这三种策略都是应用在ERNIE预训练过程中的预训练任务,期望通过这三种级别的任务帮助ERNIE学到更多的语言知识。
1.2 Knowledge Masking Task
训练语料中蕴含着大量的语言知识,例如词法,句法,语义信息,如何让模型有效地学习这些复杂的语言知识是一件有挑战的事情。BERT使用了MLM(masked language-model)和NSP(Next Sentence Prediction)两个预训练任务来进行训练,这两个任务可能并不足以让BERT学到那么多复杂的语言知识,特别是后来多个研究人士提到NSP任务是比较简单的任务,它实际的作用不是很大。
说明:
masked language-model(MLM)是指在训练的时候随即从输入预料上mask掉一些单词,然后通过的上下文预测这些单词,该任务非常像我们在中学时期经常做的完形填空。 Next Sentence Prediction(NSP)的任务是判断连个句子是否是具有前后顺承关系的两句话。
考虑到这一点,ERNIE提出了Knowledge Masking的策略,其包含三个级别:ERNIE将Knowledge分成了三个类别:token级别(Basic-Level)、短语级别(Phrase-Level) 和 实体级别(Entity-Level)。通过对这三个级别的对象进行Masking,提高模型对字词、短语的知识理解。
图2展示了这三个级别的Masking策略和BERT Masking的对比,显然,Basic-Level Masking 同BERT的Masking一样,随机地对某些单词(如 written)进行Masking,在预训练过程中,让模型去预测这些被Mask后的单词;Phrase-Level Masking 是对语句中的短语进行masking,如 a series of;Entity-Level Masking是对语句中的实体词进行Masking,如人名 J. K. Rowling。
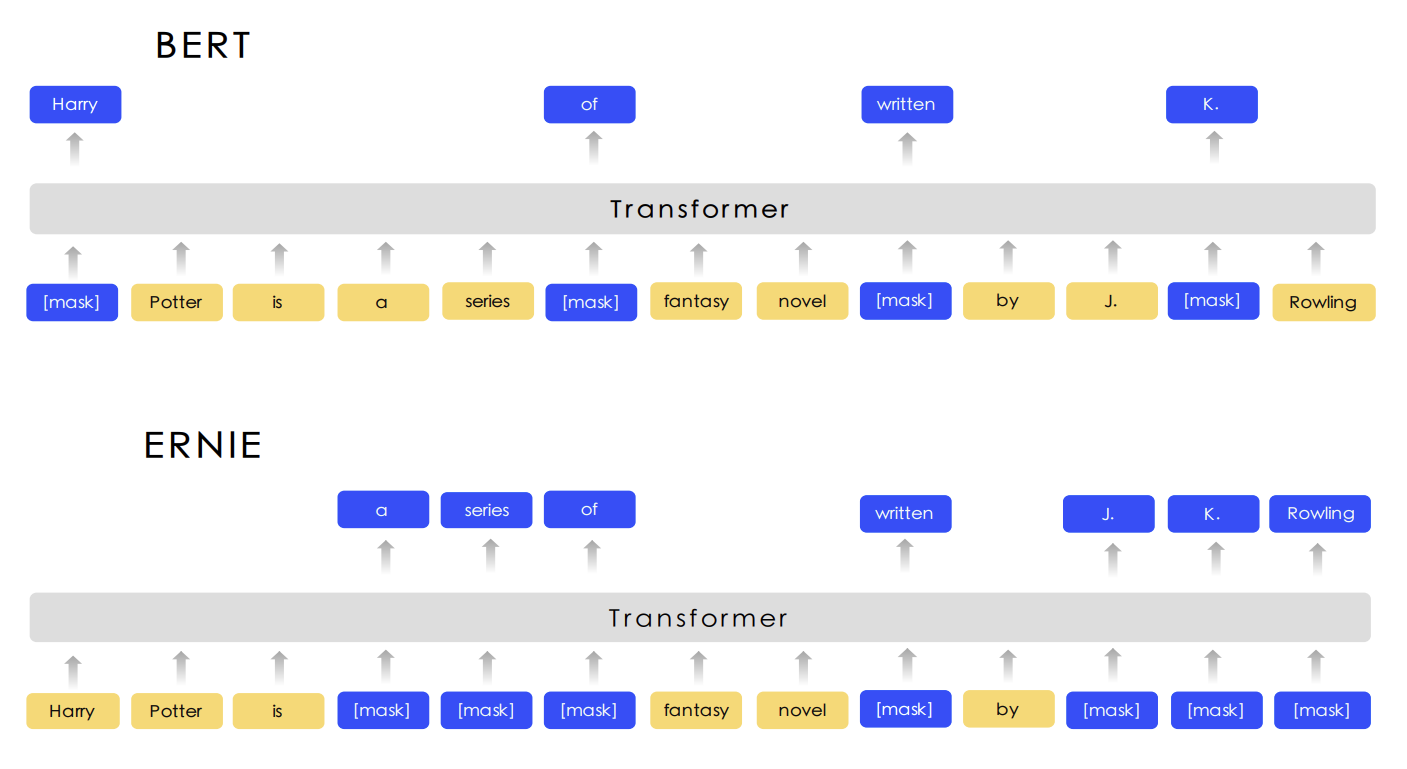
图2 ERNIE和BERT的Masking策略对比
除了上边的Knowledge Masking外,ERNIE还采用多个异源语料帮助模型训练,例如对话数据,新闻数据,百科数据等等。通过这些改进以保证模型在字词、语句和语义方面更深入地学习到语言知识。当ERINE通过这些预训练任务学习之后,就会变成一个更懂语言知识的预训练模型,接下来,就可以应用ERINE在不同的下游任务进行微调,提高下游任务的效果。例如,文本分类任务。
异源语料 :来自不同源头的数据,比如百度贴吧,百度新闻,维基百科等等
2.ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
2.1. ERNIE 3.0的设计思路
自回归模型(Autoregressive Model, AR),通过估计一串文本序列的生成概率分布进行建模。一般而言,AR模型通过要么从前到后计算文本序列概率,要么从后向前计算文本序列概率,但不论哪种方式的建模,都是单向的。即在预测一个单词的时候无法同时看到该单词位置两边的信息。假设给定的文本序列 ,其从左到右的序列生成概率为:
自编码模型(Autoencoding Model, AE), 通过从破坏的输入文本序列中重建原始数据进行建模。例如BERT通过预测【mask】位置的词重建原始序列。它的优点在于在预测单词的时候能够同时捕获该单词位置前后双向的信息;它的缺点是预训练过程中采用了mask单词的策略,然而微调阶段并没有,因此导致了预训练阶段和微调阶段的的GAP,另外在训练过程中,对不同mask单词的预测是相互独立的。假设序列中被mask的词为 ,未被mask的词为 ,则其相应的计算概率为:
一般而言,自回归模型在文本生成任务上表现更好,自编码模型在语言理解任务上表现更好。ERNIE 3.0借鉴此想法,在如下方面进行了改进:
ERNIE 3.0同时结合了将自回归和自编码网络,从而模型在文本生成和语言理解任务表现均很好。
ERNiE 3.0在预训练阶段中引入了知识图谱数据。
2.2. ERNIE 3.0的模型结构
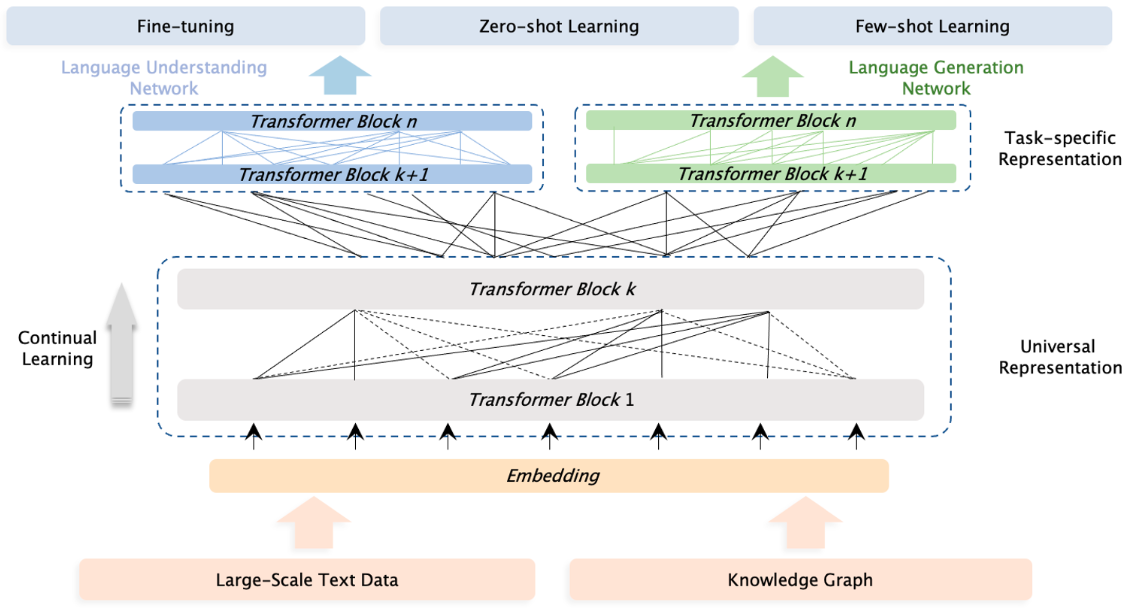
图1 ERNIE 3.0模型结构
2.2.1 ERNIE 3.0的网络结构
延续ERNIE 2.0的语言学习思路,ERNIE 3.0同样期望通过设置多种预任务的方式辅助模型学习语言的各方面知识,比如词法、句法、和语义信息。这些预训练任务包括自然语言生成、自然语言理解和关系抽取等范畴。ERNIE 3.0期望能够在这三种任务模式(task paradigm)中均能获得比较好的效果,因此提出了一个通用的多模式预训练框架,这就是ERNIE 3.0,如图1所示。
ERNIE 3.0认为不同的任务模式依赖的自然语言的底层特征是相同的,比如词法和句法信息,然而不同的任务模式需要的上层具体的特征是不同的。自然语言理解的任务往往倾向于学习语义连贯性,然而自然语义生成任务却期望能够看见更长的上下文信息。
因此,ERNIE 3.0设计了上下两层网络结构:Universal Representation Module 和 Task-specific Representation Module。其中各个模式的任务共享Universal Representation Module,期望其能够捕获一些通用的基础特征; Task-specific Representation Module将去具体适配不同模式的任务(生成和理解),去抽取不同的特征。
前边提到,自回归模型在文本生成任务上表现更好,自编码模型在语言理解任务上表现更好。因此,ERNIE 3.0在上层使用了两个网络,一个用于聚焦自然语言理解,一个用于聚焦自然语言生成任务。这样做主要有两个好处:
不同任务适配更合适的网络,能够提高模型在相应任务上的表现。
在fune-tuning阶段,可以固定Universal Representation Module,只微调Task-specific Representation Module参数,提高训练效率。
2.2.2 Universal Representation Module
此部分使用Transformer-XL作为骨干网络,Transformer-XL允许模型使用记忆循环机制建模更长的文本序列依赖。在实验中,Universal Representation Module设置了比较多的层数和参数,用以加强捕获期望的词法和句法底层语言特征能力。
这里需要注意的一点是,记忆循环机制只有在自然语言生成任务上会使用。
2.2.3 Task-specific Representation Module
此部分同样使用了Transformer-XL作为骨干网络,Task-specific Representation Module将用于根据不同模式的任务去学习task-specific的高层语义特征。
在ERNIE 3.0的设置中,Universal Representation Module采用了Base版的Transformer-XL,其层数会比Universal Representation Module少。
另外,ERNIE 3.0采用了两种任务模式的Representation Module,一个是NLU-specific Representation Module,另一个是NLG-specific Representation Module,其中前者是一个双向编码网络,后者是个单向编码网络。
2.3. 不同类型的预训练任务
2.3.1 Word-aware Pre-training Task
- Knowledge Masked Language Modeling
Knowledge Masking策略包含三个级别:token级别(Basic-Level)、短语级别(Phrase-Level) 和 实体级别(Entity-Level)。通过对这三个级别的对象进行 Masking,提高模型对字词、短语的知识理解。
图2展示了这三个级别的Masking策略和BERT Masking的对比,显然,Basic-Level Masking 同BERT的Masking一样,随机地对某些单词(如 written)进行Masking,在预训练过程中,让模型去预测这些被Mask后的单词;Phrase-Level Masking 是对语句中的短语进行masking,如 a series of;Entity-Level Masking是对语句中的实体词进行Masking,如人名 J. K. Rowling。
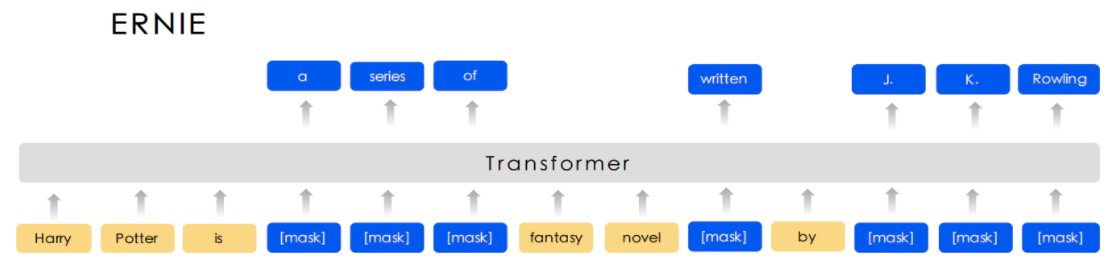
图2 ERNIE和BERT的Masking策略对比
- Document Language Modeling
ERNIE 3.0 选择使用传统的语言模型作为预训练任务,期望减小模型的语言困惑度。同时采用了ERNIE-Doc中提出的记忆循环机制,以建模更长的序列依赖。
2.3.2 Structure-aware Pre-training Tasks
- Sentence Reordering Task
将给定的文档依次划分为1-m段,然后打乱这些段,让模型对这些段进行排序,是个k分类问题,这能够帮助模型学习语句之间的关系。
将文档划分为2段,那么排列组合后将有 个可能;将文档划分为3段,那么排列组合后将有 3! 个可能;依次类推,将文档划分为 n 段,那么排列组合后将有 n! 个可能。因此ERNIE将这个任务建模成了一个 k 分类问题,这里 。
- Sentence Distance Task
预测两个句子之间的距离,是个3分类任务。对应的Label依次是0、1和2。其中0代表两个句子在同一篇文章中,并且他们是相邻的;1代表两个句子在同一篇文章中,但他们不是相邻的;2代表两个句子不在同一篇文章中。
2.3.3 Knowledge-aware Pre-training Tasks
为了向预训练模型中引入知识,ERNIE 3.0 尝试在预训练阶段引入了universal knowledge-text prediction(UKTP)任务,如图3所示。
给定一个三元组<head, relation, tail>和一个句子,ERNIE 3.0会mask掉三元组中的实体关系relation,或者句子中的单词word,然后让模型去预测这些内容。当预测实体关系的时候,模型不仅需要考虑三元组中head和tail实体信息,同时也需要根据句子的上下文信息来决定head和tail的关系,从而帮助模型来理解知识。
这个操作基于远程监督的假设:如果一个句子中同时出现head和tail两个实体,则这个句子能够表达这两个实体的关系。
另外,当预测句子中的单词word时,模型不仅需要考虑句子中的上下文信息,同时还可以参考三元组<head, relation, tail>的实体关系。
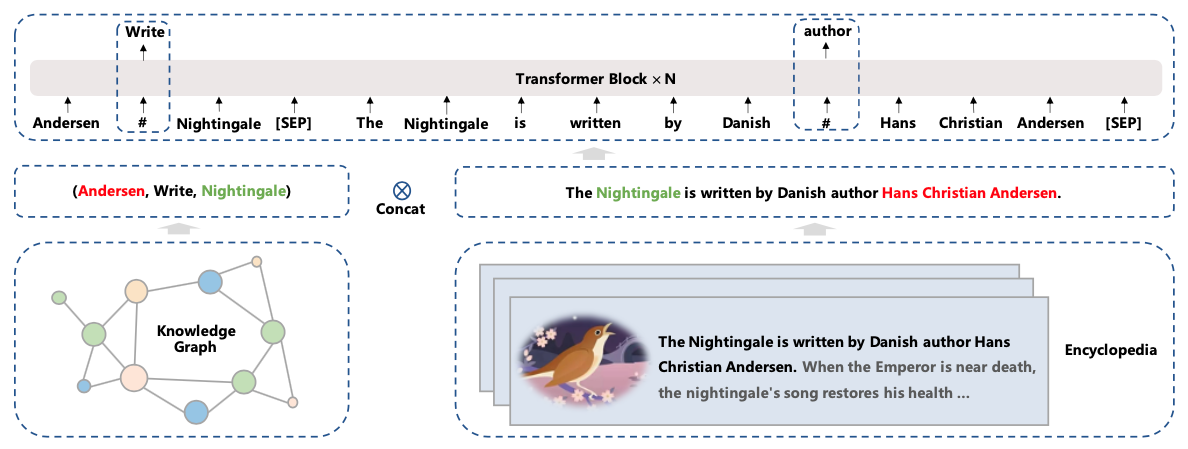
图3 universal knowledge-text prediction
- 相关资料
ERNIE 3.0: LARGE-SCALE KNOWLEDGE ENHANCED PRE-TRAINING FOR LANGUAGE UNDERSTANDING AND GENERATION
ERNIE-DOC: A Retrospective Long-Document Modeling Transformer
3.ERNIE-Gram: Pre-training with Explicitly N-Gram Masked language Modeling for Natural Language Understanding
3.1. ERNIE-Gram简介
在经典预训练模型BERT中,主要是通过Masked Language Modeling(MLM)预训练任务学习语言知识。在BERT中MLM会随机Masking一些位置的token,然后让模型去预测这些token。这些Masking的token在中文中便是字,在英文中便是sub-word,这样的预测也许不能让模型获取更加直观的语言知识,所以后续又出现了一些模型,比如ERNIE, SpanBERT等,其从Masking单个字转变成了Masking一系列连续的token,例如Masking实体词,Masking短语等,即从细粒度的Masking转向粗粒度的Masking。
ERNIE-Gram指出一种观点:这种连续的粗粒度Masking策略会忽略信息内部的相互依赖以及不同信息之间的关联。因此,基于这种想法进行改进,提出了一种显式建模n-gram词的方法,即直接去预测一个n-gram词,而不是预测一系列连续的token,从而保证n-gram词的语义完整性。
另外,ERNIE-Gram在预训练阶段借鉴ELECTRA想法,通过引入一个生成器来显式地对不同n-gram词进行建模。具体来讲,其应用生成器模型去采样合理的n-gram词,并用这些词去mask原始的语句,然后让模型去预测这些位置原始的单词。同时还使用了RTD预训练任务,来识别每个token是否是生成的。
3.2. ERNIE和N-Gram的融入方式
上边我们提到了,不同于连续多个token的预测,ERNIE-GRAM采用了一种显式的n-gram方式进行建模,在本节我们将展开讨论ERNIE和显式的n-gram融合建模的方式。ERNIE-Gram主要提出了两种融合方式:Explictly N-gram MLM 和 Comprehensive N-gram Prediction。
在正式介绍之前,我们先回顾一下经典的连续token的建模方式:Contiguously MLM,然后再正式介绍以上ERNIE-Gram提出的两种方式。
3.2.1 Contiguously MLM
给定一串序列 和 n-gram起始边界序列(starting boundaries) ,根据 和 进行如下约定:
:由 转换成的n-gram序列。
:从起始边界 中随机选择15%的准备Masking的index,组成
:由 选择出的相应的token集
: 表示将 进行Masking后的序列
图1展示了一个Contiguously MLM的例子,给定的序列为 , 起始边界序列为 , 假设从起始边界序列 的随机选择的索引为 , 则
Contiguously MLM 可通过如下方式进行优化:
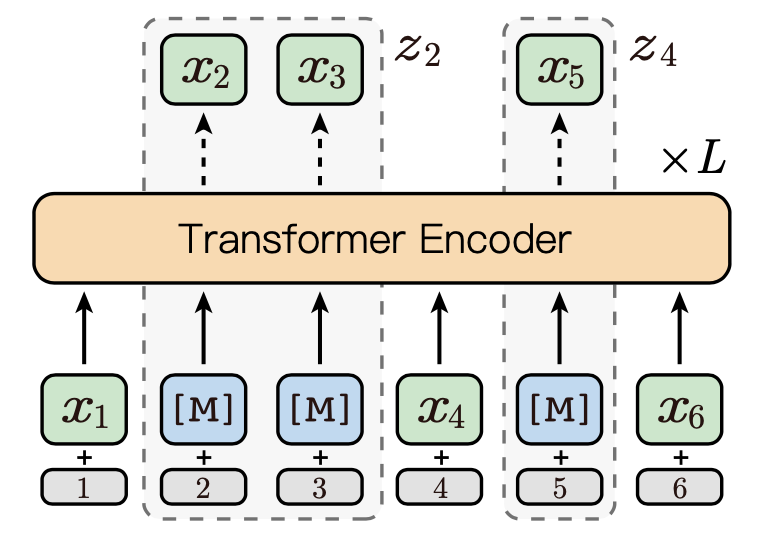
图1 contiguously MLM
在讨论完连续的token Masking策略之后,下面我们将继续讨论ERNIE-Gram中提出的两种显式n-gram的建模方式。
3.2.2 Explicitly N-gram Masked Language Modeling
在连续token预测中, 需要预测多次,每次预测一个token,直到完成这一段连续token的所有预测,才表示完成了一个实体词或者短语。不同于连续token预测, 显式的N-gram预测直接去预测一个n-gram词,即站在一种粗粒度的角度上进行预测。
如图2为所示,假设 为显式的n-gram序列, 为随机选择的Masking token, 则Masking后的完整序列为 。
Explicitly N-gram Masked Language Modeling可通过如下方式进行优化:
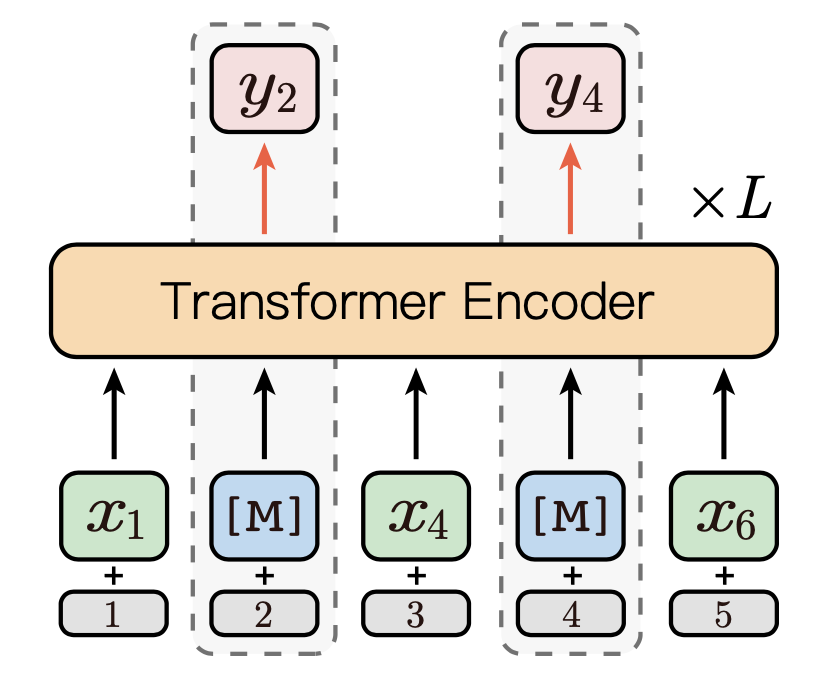
图2 Explicitly N-gram MLM
3.2.3 Comprehensive N-gram Prediction
通过以上讨论可知,Contiguously MLM是从细粒度角度进行预测连续token, Explicitly N-gram MLM是从粗粒度角度进行预测n-gram token, 而本节介绍的Comprehensive N-gram是一种融合细粒度和粗粒度的预测方式,其将更加全面地进行建模。其优化的目标函数为以上两种方式的融合,这里需要注意这两种方式是基于统一的上下文 进行预测:
图3a展示了细粒度和粗粒度预测的详细融合方式,其将细粒度的预测位置直接拼接到了序列的末尾,图中以虚线分割。其中虚线以左是Explictly N-gram的粗粒度预测,虚线以右是Contiguously MLM的细粒度预测。以 位置为例,由于其包含两个token,所以细粒度预测需要预测2次(论文中这两个位置使用了 和 这两个不同的token进行Masking)。
此时,整个文本序列为: , 为了在Self-Attention时不造成信息的混乱,ERNIE-Gram约定:
虚线以左的 Explicitly N-gram MLM 粗粒度预测,即在预测 和 时,只能看见虚线以左的token。
虚线以后的Contiguously MLM细粒度预测,即在预测 和 时,只能看见自己以及虚线以左的token。
图3b展示了其计算时的Attention矩阵,其中红色点表示相互能够看见,在Self-Attention计算时,相互的信息需要融入。
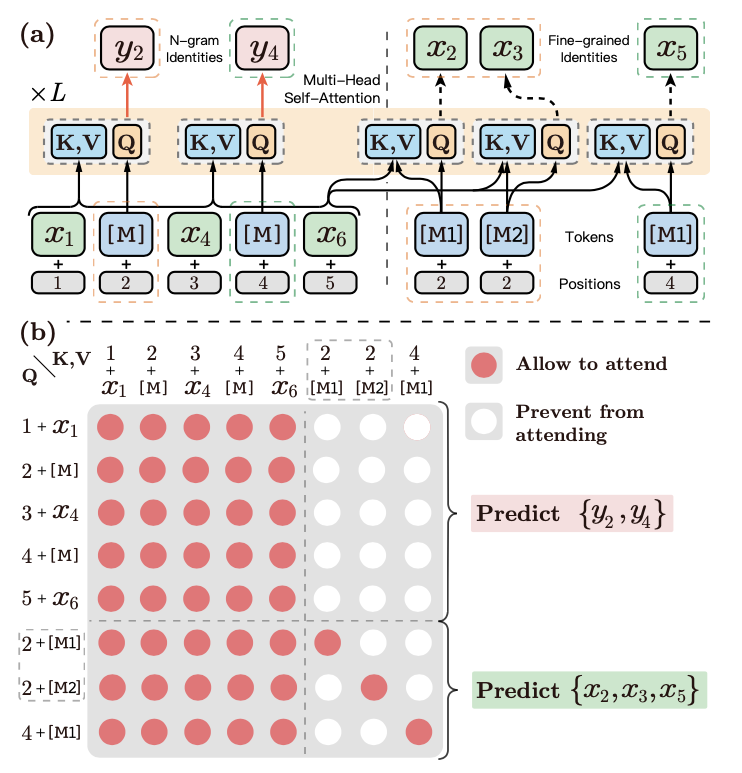
图3 Comprehensive N-gram Prediction
3.3. 使用生成器显式建模N-gram Relation
为了更加显式地建模不同n-gram之间的关系,在预训练阶段,ERNIE-Gram借鉴了Electra的思路,使用一个生成器去生成一个位置的n-gram词,并且用这个n-gram词去mask该位置的n-gram token。
如图4所示,Transformer Encoder 便是生成器,图4b展示了使用生成的n-gram token去mask原始句子token的一个样例,ERNIE-Gram根据数据Masking位置的词分布采样了public official和completely去替换了原始语句词,即
原始语句:the prime minister proposed nothing less than a overhaul of the tax system.
Masking语句:the public official proposed completely a overhaul of the tax system.
然后将Masking语句传入Transformer Encoder 中进行训练。
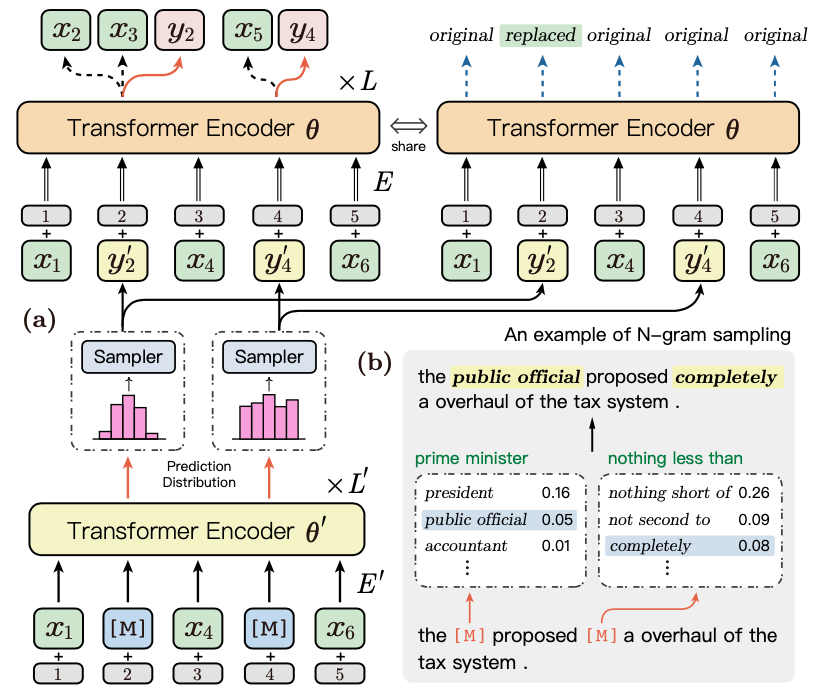
图4 Enhanced N-gram Relation Modeling
假设 表示生成的n-gram项, 表示用生成n-gram项Masking后的序列,则联合的预训练目标函数为:
另外,ERNIE-Gram融入了the replaced token detection (RTD)任务,用于识别这些token是否是被生成器替换的token。假设 为真实目标n-gram词替换后的序列,则RTD的目标函数为:

- 点赞
- 收藏
- 关注作者
评论(0)