【编程实践】出行无忧,利用Python爬取天气预报

前言
天气预报就是应用大气变化的规律,根据当前及近期的天气形势,对某一地未来一定时期内的天气状况进行预测。它是根据对卫星云图和天气图的分析,结合有关气象资料、地形和季节特点、群众经验等综合研究后作出的。如我国中央气象台的卫星云图,就是我国制造的"风云一号"气象卫星摄取的。利用卫星云图照片进行分析,能提高天气预报的准确率。天气预报就时效的长短通常分为三种:短期天气预报(2~3天)、中期天气预报(4~9天),长期天气预报(10~15天以上)
古人们利用自己的智慧制作简单的观测仪器通过对日、风、云、湿度和降水的观测或者仅凭经验观天象进行天气预测,到如今的各种卫星监测。从古至今人们无不希望对未来天气的有更多的掌握,因为这关乎人们生产生活,生命安全。小到人们的出行大到农作物的收播、疾病的预防以及自然灾害的预防,如果没有掌握天气的预测,只能遵循“靠天吃饭”的自然法则,任由风霜雨雪、冷热不均以及其他自然灾害威胁生产与生活。随着生产力的发展和科学技术的进步,人类活动范围空前扩大,对大自然的影响也越来越大,因而天气预报就成为现代社会不可缺少的重要信息。也随着科学的进步,我们对天气信息数据的获取更加多元化,预测范围更广,预测的种类更加多样,预测时间更精确,更实时。现在我们几乎可以做到对一个地区或城市未来一段时期内的阴晴雨雪、最高最低气温、风向和风力及特殊的灾害性天气的准确预报。就我们国家而言,气象台准确预报寒潮、台风、暴雨等自然灾害出现的位置和强度,就可以直接为工农业生产和群众生活服务。
爬取天气信息使用到的工具
Scrapy框架介绍
Scrapy与Requests很相似,是用纯Python实现一个为了遍历爬取网站数据、分解获取数据而设计的应用程序框架,但Scrapy框架操作相对简单,功能更加完善,用途广泛,可以进行数据的挖掘、数据的监测、自动化测试以及对API数据的提取。可应用于大型的多线程,多进程的爬虫项目
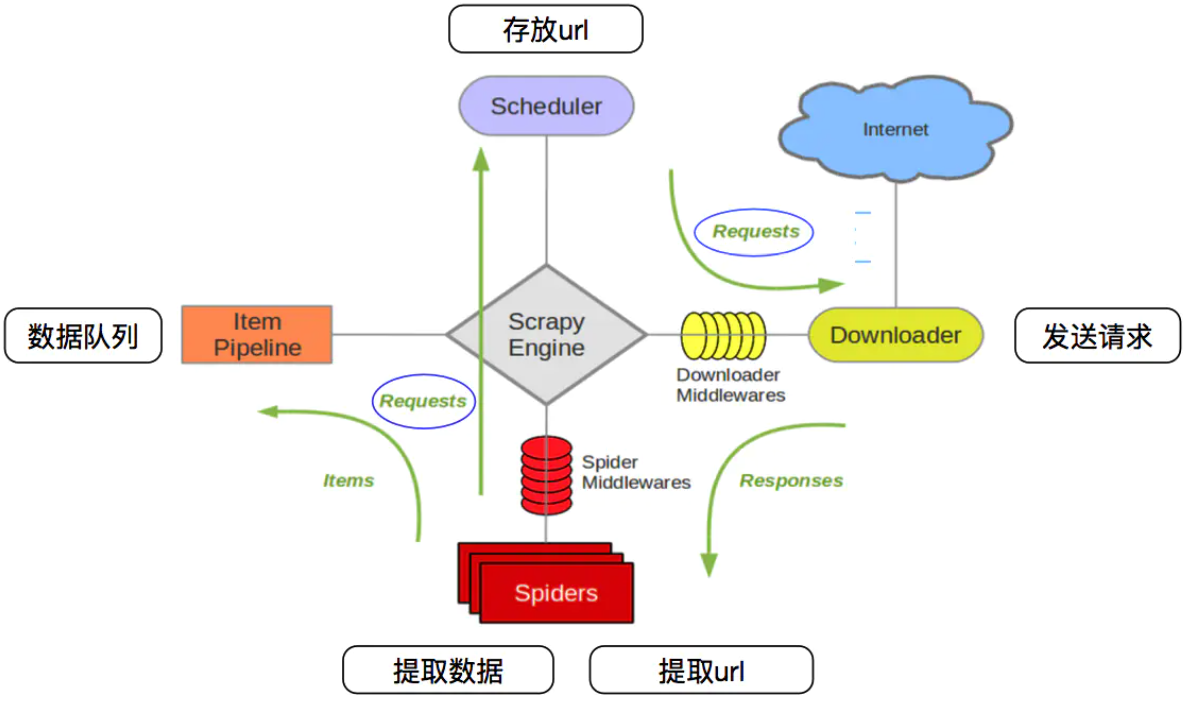
Scrapy的构成
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scarpy的安装
pip install scrapy
或者
pip3 install scrapy如果你使用的是anaconda集成环境还可以使用以下命令进行安装:
conda install scrapy
涉及多个依赖
Scrapy的基本使用流程
使用Scrapy进行数据爬取的流程如下:
创建爬虫项目
明确爬取目标
制作爬虫
保存获取到的数据
项目实操
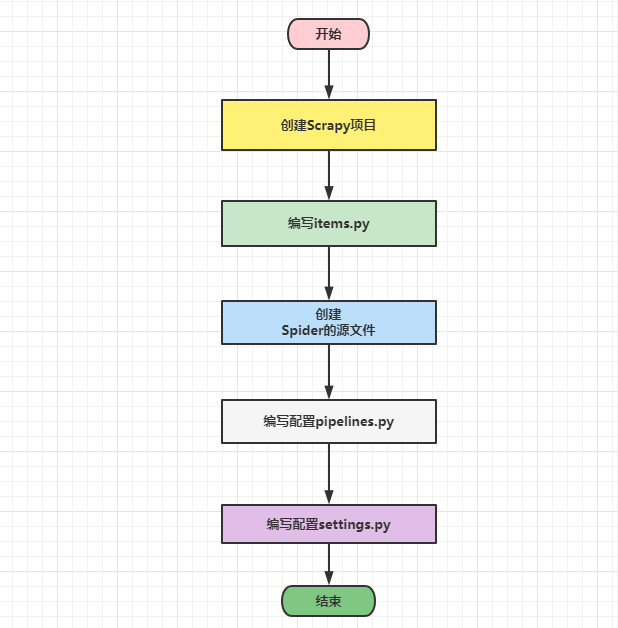
步骤图示
爬取步骤如下:
创建一个Scrapy项目
编写items.py,确定要爬取的目标
创建Spider的源文件
编写配置pipelines.py,这个代码是用来保存爬虫爬取到的数据.最终爬取到的数据一般有多种存储形式:txt,json,csv,excel以及数据库形式.
编写配置settings.py
运行框架进行数据爬取
1.win+r键,输入cmd打开命令行窗口,cd进入本次爬虫项目的文件夹
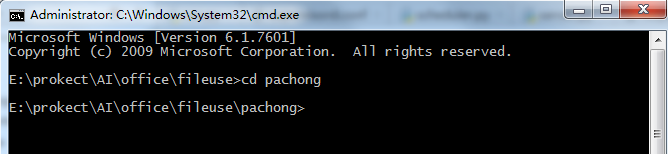
2.通过命令"scrapy startproject 项目名称"创建项目,通过命令:"scrapy genspider 文件名称 域名" 创建爬虫文件,创建完成后会自动生成一些文件
目标网站分析需要提取的数据,在item.py文件中添加字段Item 定义结构化数据字段,用来保存爬取到的数据,类似Python中的dict,但是提供了一些额外的保护以减少错误
具体命令如下:
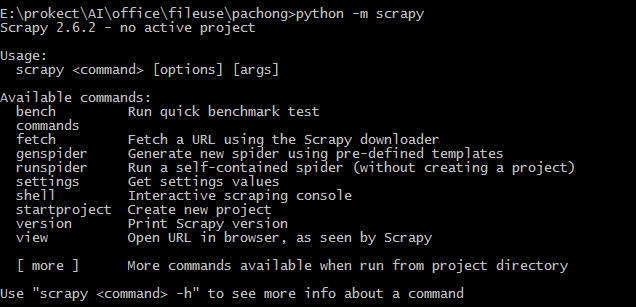
scrapy startproject weather如果遇到以下错误,可通过命令pip install pyopenssl --upgrade安装升级openssl库


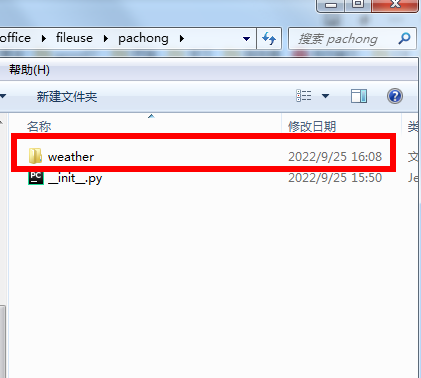
执行创建命令后会生成一个weather的文件夹,里面会生成一些默认的文件,这些文件都是我们项目中要配置的文件
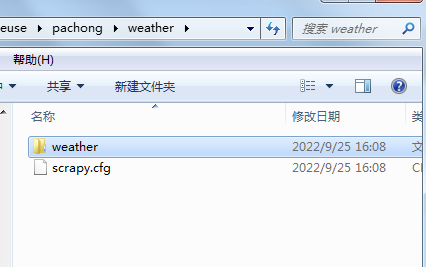
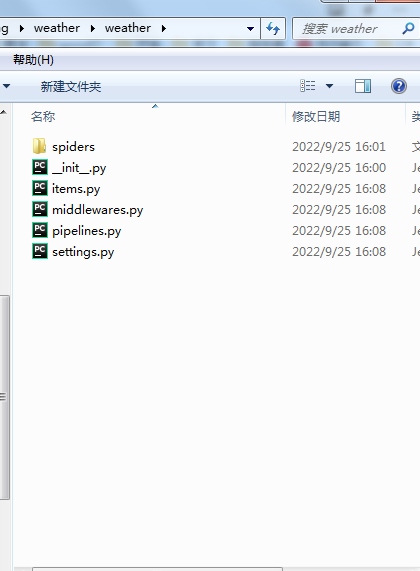
代码实现
编写items.py文件
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class WeatherItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
date = scrapy.Field()
temperature = scrapy.Field()
weather = scrapy.Field()
wind = scrapy.Field()
pass在spider文件夹下创建Spider源文件:GETweather.py这个文件名可以自定义,前后一定要对应上
import scrapy
from weather.items import WeatherItem
class GetweatherSpider(scrapy.Spider):
name = 'GETweather'
#中国天气网
allowed_domains = ['www.weather.com.cn/weather/101280101.shtml']
start_urls = ['http://www.weather.com.cn/weather/101280101.shtml']
def parse(self, response):
# 建立一个列表来保存每天的信息
items = []
# 找到包裹着天气信息的div
day = response.xpath('//ul[@class="t clearfix"]')
# 循环筛选出每天的信息:
for i in list(range(7)):
# 先申请一个weatheritem 的类型来保存数据
item = WeatherItem()
print(item)
item['date'] = day.xpath('./li[' + str(i + 1) + ']/h1//text()').extract()[0]
item['temperature'] = day.xpath('./li[' + str(i + 1) + ']/p[@class="tem"]/i/text()').extract()[0]
item['weather'] = day.xpath('./li[' + str(i + 1) + ']/p[@class="wea"]/text()').extract()[0]
item['wind'] = day.xpath('./li[' + str(i + 1) + ']/p[@class="win"]/em/span/@title').extract()[0] + \
day.xpath('./li[' + str(i + 1) + ']/p[@class="win"]/i/text()').extract()[0]
items.append(item)
return items编写pipelines.py
import os
class WeatherPipeline:
def process_item(self, item, spider):
print(item)
# print(item)
# 获取当前工作目录
base_dir = os.getcwd()
# 文件存在data目录下的weather.txt文件内,data目录和txt文件需要自己事先建立好
filename = base_dir + '/gzweather.txt'
# 从内存以追加的方式打开文件,并写入对应的数据
with open(filename, 'a', encoding='utf-8') as f:
f.write('广州 ' + item['date'] + ' 的天气:\n')
f.write(item['temperature'] + '\n')
f.write(item['weather'] + '\n')
f.write(item['wind'] + '\n\n')
return item设置settings.py文件:去掉注释
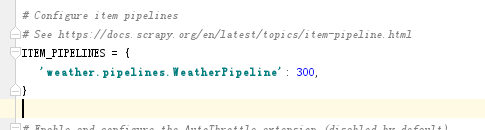
具体代码如下:
BOT_NAME = 'weather'
SPIDER_MODULES = ['weather.spiders']
NEWSPIDER_MODULE = 'weather.spiders'
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
'weather.pipelines.WeatherPipeline': 300,
}执行爬虫程序:
from scrapy import cmdline
cmdline.execute(['scrapy','crawl','CQtianqi'])执行结果如下:

总结
Scrapy和其他的爬虫库的不同处就在于Scrapy是一个爬虫框架,可以根据实际需求修改内容,实现所有功能的爬虫,不用重复造轮子,Scrapy底层是异步框架Twisted.吞吐量高,可以实现多线程的爬虫并更高效完成数据爬取工作

- 点赞
- 收藏
- 关注作者
评论(0)