【编程基础】正则表达式基本使用及在Python中使用正则表达式匹配内容

前言
当接触一个新知识点或者技术时,只要问完哲学中的三大问题,基本就对这个知识点或者技术有大致的了解,这也是我学习一个新技术常用的方法,那到底是哪三大问题呢?
是什么?怎么做,为什么这么做?看似简单其中已经包含很多操作。那我们按照这个做法,先看看正则表达式到底是何方神圣?
正则表达式是什么?
正则表达式,又称规则表达式,(英语:Regular Expression,在代码中常简写为regex、regexp或RE),它是计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式的文本。 许多程序设计语言都支持利用正则表达式进行字符串操作。例如在Perl中内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件普及开的。正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,模式描述在搜索文本时要匹配的一个或多个字符串。
正则表达式的"鼻祖"或许可一直追溯到科学家对人类神经系统工作原理的早期研究。美国新泽西州的Warren McCulloch和出生在美国底特律的Walter Pitts这两位神经生理方面的科学家,研究出了一种用数学方式来描述神经网络的新方法,他们创造性地将神经系统中的神经元描述成了小而简单的自动控制元,从而作出了一项伟大的工作革新。
正则引擎主要可以分为两大类:一种是DFA,一种是NFA。这两种引擎都有了很久的历史(至今二十多年),当中也由这两种引擎产生了很多变体!于是POSIX的出台规避了不必要变体的继续产生。这样一来,主流的正则引擎又分为3类:一、DFA,二、传统型NFA,三、POSIX NFA。
正则表达式的特点
1. 灵活性、逻辑性和功能性非常强;
2. 可以迅速地用极简单的方式达到字符串的复杂控制。
3. 对于刚接触的人来说,比较晦涩难懂。
由于正则表达式主要应用对象是文本,因此它在各种文本编辑器场合都有应用,主要是用于检索和替换,小到我们常用的编辑器编辑器EditPlus,notepad++,sublime,大到办公软件Microsoft Word/Excel、Visual Studio以及IDEA等大型编辑器,都可以使用正则表达式来处理文本内容。
通过上面的描述我们对正则表达式已经有大致的了解,接下来我们看看正则表达式具体有什么作用?
正则表达式的目的
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
1. 给定的字符串是否符合正则表达式的过滤逻辑(称作"匹配")
2. 可以通过正则表达式,从字符串中获取我们想要的特定部分。
概括起来就是检索和匹配
正则表达式符号详解
前面我们了解到正则表达式主要是为了完成对数据的类型匹配,比如:在程序中用户输入一组数组,1234567890qwertyuiopasdfghjkl;现在我们想知道用户输入的数字部分是什么,这时候我们的正则表达式就可以派上用场了,可使用正则表达式返回:['1234567890'],再比如在网页表单上我们要求用户输入身份证号或者手机号,这时候我们同样是使用正则表达式来检查用户输入的身份证号码或者手机号是否正确.
下面我们继续探索正则表达式的匹配规则:
正则表达式的常用符号
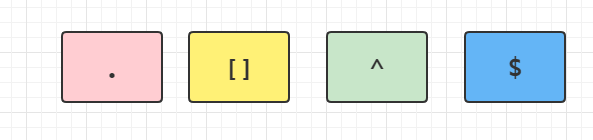
以上这四个字符是所有语言都支持的正则表达式,所以这四个是基础的正则表达式。正则难理解因为里面有一个等价的概念,这个概念大大增加了理解难度,让很多初学者看起来会懵,如果把等价都恢复成原始写法,自己书写正则就超级简单了,就像说话一样去写你的正则了:
?,*,+,\d,\w 都是等价字符
?等价于匹配长度{0,1}
*等价于匹配长度{0,}
+等价于匹配长度{1,}
\d等价于[0-9]
\D等价于[^0-9]
\w等价于[A-Za-z_0-9]
\W等价于[^A-Za-z_0-9]
接着一一来介绍正则表达式常用符号:
. : 匹配任意字符
\:将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\n”匹配\n。“\n”匹配换行符。序列“\”匹配“\”而“(”则匹配“(”。即相当于多种编程语言中都有的“转义字符”的概念。
^:匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。
$:匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。
*:匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于o{0,}
+:匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}
?:匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}
{m,n}:m和n均为非负整数,其中m<=n,最少匹配m次且最多匹配n次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格
\\:转义字符,跟在其后面的字符将失去特殊原字母的含义
[]:字符集,可匹配方括号中任意一个字符
|:或,将两个匹配条件进行逻辑"或"(or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。
...:分组,默认为捕获,即被分组的内容可以被单独取出
{n}:n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o
{n,}:n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”
\number:
\A:匹配字符串开始的位置,忽略多行模式
\z:匹配字符串结束的位置,忽略多行模式
\b:匹配一个单词边界,即匹配位于单词开始或结束位置的空字符串,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”
\B:匹配非单词边界,即不匹配位于单词开始或结束位置的空字符串。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”
\D:匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持
\d:匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持
\s:匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
\S:匹配任何可见字符。等价于[^ \f\n\r\t\v]
\w:匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集
\W:匹配任何非单词字符。等价于“[^A-Za-z0-9_]”
(?:pattern):非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“( )”来组合一个模式的各个部分时很有用。例如“industr(?:y ies)”就是一个比“industry industries”更简略的表达式
x y:匹配x或y。例如,“z food”能匹配“z”或“food”(此处请谨慎)。“[zf]ood”则匹配“zood”或“food”
[xyz]:字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”
[^xyz]:负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”
[a-z]:字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身
[^a-z]:负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符
上面为我们常用的正则表达式符号,因为篇幅原因还有一些没有写的等你继续探索;
正则表达式的简单使用规则(怎么做)
经过上面的介绍,我们对正则表达式已有了初步了解,我们接着进一步正则表达式的使用规则.
在使用正则表达式之前,需要先导入re模块.导入模块之后,需要匹配所需值.比如:可以用\d匹配一个十进制的数字,用\w匹配一个字母或者数字.\d可以匹配2022但无法匹配202q,\d\d\d可以匹配110但无法匹配qqq,\d\w\d可以匹配101但无法匹配q0q.
点"."可以匹配任意字符,字符串"Python."就可以匹配字符串"Python 3.".大括号"{}"可以限制数量,所以可以用\d{3}来匹配3个数字字符,这里不再一一赘述.如果需要更精确地表示范围,可以使用中括号"[]"
在Python中使用正则表达式
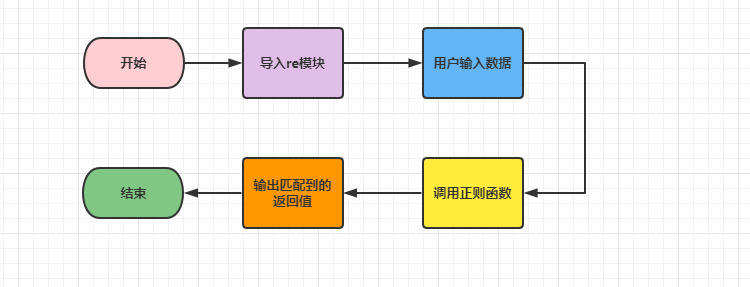
实现流程:
导入re模块
用户输入需要匹配的数据
使用正则函数完成对数字的筛选匹配
输出返回值
代码如下:
import re
useData = str(input('请输入字符串数据:'))
'''
匹配字符串中的数字,+是匹配前面的子表达式一次或多次
'''
digital = re.findall('\d+',useData)
print(digital)执行结果如下:

findall()函数是返回所有匹配到的字符串,返回值的数据类型为列表

- 点赞
- 收藏
- 关注作者
评论(0)