【算法实践】分块查找知多少?手把手带你实现分块查找

前言
什么是分块查找?
分块查找又称索引顺序查找,是折半查找和顺序查找的一种改进方法,由于只要求索引表是有序的,对块内节点没有排序要求,因此特别适合于节点动态变化的情况。它吸取了顺序查找和折半查找各自的优点,既有动态结构,又适于快速查找。折半查找其实也算是分块查找的特殊用法,分块查找的速度虽然不如折半查找算法,但比顺序查找算法快得多,同时又不需要对全部节点进行排序。当节点很多且块数很大时,对索引表可以采用折半查找,这样能够进一步提高查找的速度。
当增加或减少节以及节点的关键码改变时,只需将该节点调整到所在的块即可。在空间复杂性上,分块查找的主要代价是增加了一个辅助数组。
需要注意的是,当节点变化很频繁时,可能会导致块与块之间的节点数相差很大,没写快具有很多节点,而另一些块则可能只有很少节点,这将会导致查找效率的下降。
分块查找的基本思想:分块查找要求将n个数据元素划分为m块(m小于等于n)。每一块的数据不必有序,但块与块之间必须有序,也就是说第一块中任意一个元素都必须小于第二块中任意一个元素,而第二块中任意一个元素又都必须小于第三块中任意一个元素,
分块查找的核心是构建索引表,索引表包括两个字段,即关键码,(存放对应子表中的最大关键字)和指针字段(存放指向对应子表的指针),索引表按关键码字段有序排序。通过最大关键字与起始地址确定其具体位置。
图解分块查找
分块查找设计
查找图示
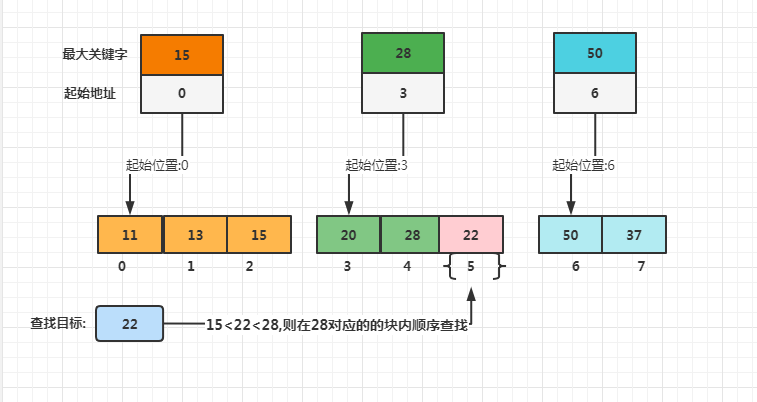
查找过程
分块查找的过程分为两步:
第一步是在索引表中确定待查记录所在的块,可以顺序查找或折半查找索引表
第二步是在块内顺序查找
代码实现
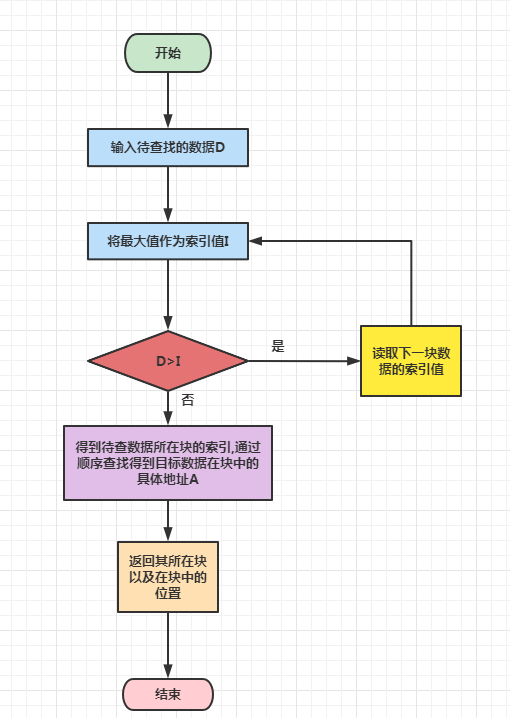
根据上图可得出基本步骤如下:
输入待查的目标数据
把最大值作为索引值
判断待查数据是否大于索引值,如果大于索引值,那么比较下一块数据的索引值,否则得到当前当前待查找数据所在块的索引
通过顺序查找得到待查找数据在块中的位置
返回目标数据的位置
代码如下:
定义相关参数
Length = 8 #输入元素的个数
targets = 0
pos = -1
tabNum = 3 #分块
tabPos = -1
print("请输入列表,以空格键隔开数字:",end=' ')
list=[int(s) for s in input().split()]
goal = int(input('请输入待查元素:')) #用户输入查找值
print('需要在列表中在找到:', goal)排序后建立索引,根据索引建立子列表,并显示构造的子列表:
list_index = [] #使用二维列表表示多个子序列
for i in range(tabNum): # 在列表中添加m个列表
list_index.append([])
for i in range(1, tabNum):
list_index[i].append(list[i - 1])
for i in range(1, tabNum - 1): # 将添加元素的子列表中的元素降序排列
for j in range(1, tabNum - i):
if list_index[j] < list_index[j + 1]:
list_index[j], list_index[j + 1] = list_index[j + 1], list_index[j]
for i in range(tabNum - 1, Length):
for j in range(1, tabNum):
if list[i] > list_index[j][0]:
list_index[j - 1].append(list[i])
break
else:
list_index[tabNum - 1].append(list[i])
if len(list_index[0]) > 1:
for i in range(len(list_index[0]) - 1, 0, -1):
if list_index[0][i] > list_index[0][i - 1]:
list_index[0][i], list_index[0][i - 1] = list_index[0][i - 1], list_index[0][i]
print("子列表结构:",list_index) # 输出子列表将给定的目标元素与各个子列表进行比较,确定目标元素所在位置,标记并返回,若找到则输出目标元素所在位置,否则输出:"没找到" 。下面就是见证奇迹的时刻:
for i in range(tabNum - 1, -1, -1): #确定给定元素位置
if len(list_index[i]) != 0 and goal < list_index[i][0]:
for j in range(len(list_index[i])):
if list_index[i][j] == goal:
tabPos = i + 1
pos = j + 1
targets = 1
if targets:
print("在第", tabPos,"个子列表中第",pos,"的位置")
else:
print("没找到")执行结果如下:

总结
分块查找的平均查找长度由两部分组成,一个是对索引表进行查找的平均查找长度,一个是对块内节点进行查找的平均查找长度,总的平均查找长度为E(n)=+。线性表中共有n个节点,分成大小相等的b块,每块有s=n/b个节点。假定读索引表也采用顺序查找,只考虑查找成功的情况,并假定对每个节点的查找概率是相等的,则对每块的查找概率是1/b,对快内每个节点的查找概率是1/s。
分块查找在现实生活中也很常用。比如:公司有不同的部门,每个员工都有属于自己的工号;且每个部门的员工档案是放在不同的文件夹中,当你要找一个员工的档案时,最快的方法是确定他所在的部门,然后在对应的部门档案文件夹中逐一查找对应的员工档案。再比如:在一个小区有很多单元,每栋楼都有很多住户,如果你是快递员,要送货上门,精准投递的通常最好做法就是确定客户住在几单元,楼层,房号多少,在这里单元可作为分块划分的依据,楼层也可作为分块划分的依据,可根据具体情况设定。现实生活中,一般以单元号划分块基本就能精准送达

- 点赞
- 收藏
- 关注作者
评论(0)