文档关键信息提取形成知识图谱:基于NLP算法提取文本内容的关键信息生成信息图谱教程及码源(含pyltp安装使用教程)

文档关键信息提取形成知识图谱:基于NLP算法提取文本内容的关键信息生成信息图谱教程及码源(含pyltp安装使用教程)
1. 项目介绍
目标:输入一篇文档,将文档进行关键信息提取,进行结构化,并最终组织成图谱组织形式,形成对文章语义信息的图谱化展示。
如何用图谱和结构化的方式,即以简洁的方式对输入的文本内容进行最佳的语义表示是个难题。 本项目将对这一问题进行尝试,采用的方法为:输入一篇文档,将文档进行关键信息提取,并进行结构化,并最终组织成图谱组织形式,形成对文章语义信息的图谱化展示。
效果展示
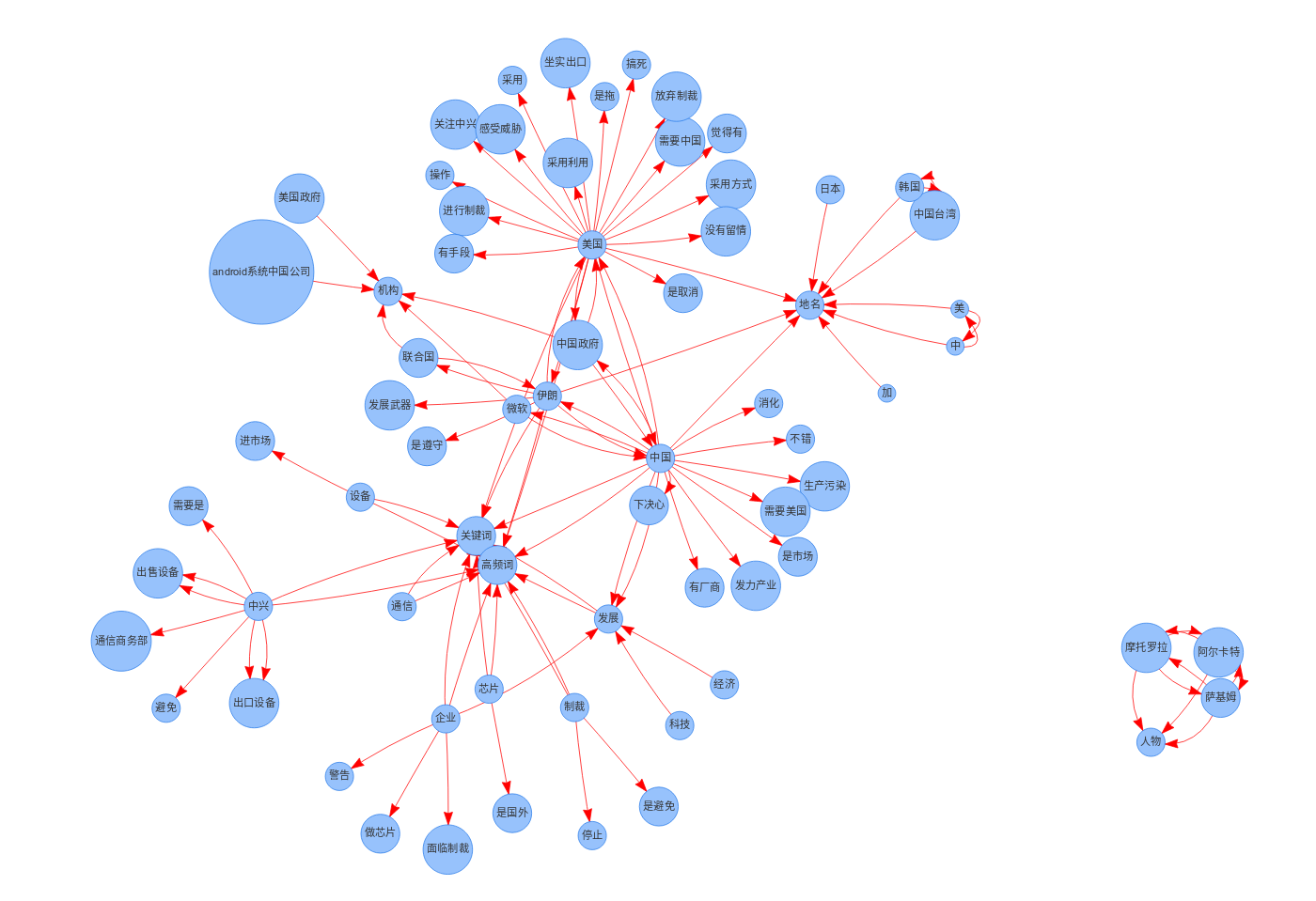
项目链接以及码源见文末:
2.相关依赖安装
2.1 Anaconda安装教程
还是要安装一个Anaconda进行环境隔离,虽然没用到一些深度学习框架,后续改进算法过程是会用的这里提醒一下。
具体教程和避坑文章见:
Anaconda安装超简洁教程,配置环境、创建虚拟环境、添加镜像源
conda创建虚拟环境后文件夹中只有conda-meta文件夹,无法将环境添加到IDE中
2.2 pyltp 安装教程
pyltp 是哈工大自然语言工作组推出的一款基于Python 封装的自然语言处理工具(轮子),提供了分词,词性标注,命名实体识别,依存句法分析,语义角色标注的功能。从应用角度来看,LTP为用户提供了下列组件:
针对单一自然语言处理任务,生成统计机器学习模型的工具
针对单一自然语言处理任务,调用模型进行分析的编程接口
使用流水线方式将各个分析工具结合起来,形成一套统一的中文自然语言处理系统
系统可调用的,用于中文语言处理的模型文件
针对单一自然语言处理任务,基于云端的编程接口
安装环境:windows10
2.2.1 pyltp 0.4.0 安装
pip install pyltp
即安装最新版本了
2.2.2 pyltp 0.2.1 安装
这个版本比较坑,直接pip安装不上的,需要用whl本地安装
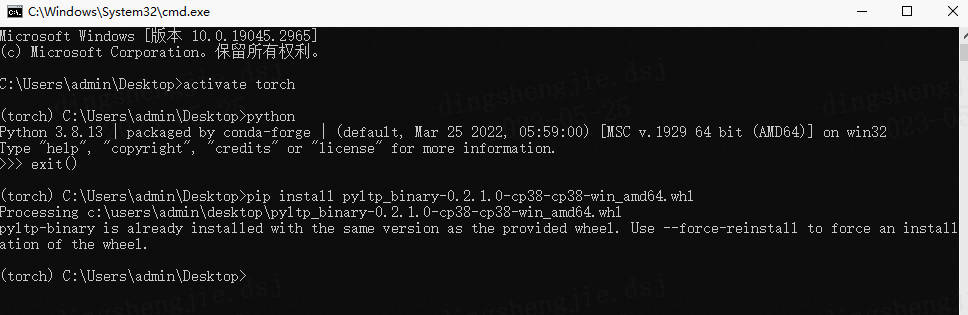
首先进入终端cmd,进入你的虚拟环境,查看python版本
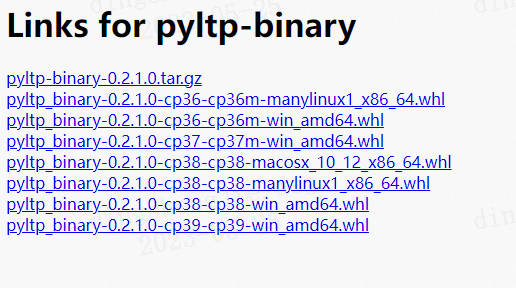
进入官网下载对应版本的pyltp: https://pypi.tuna.tsinghua.edu.cn/simple/pyltp-binary/
- 安装对应版本whl
pip install pyltp_binary-0.2.1.0-cp38-cp38-win_amd64.whl
2.3 LTP模型下载
模型下载官网:http://ltp.ai/download.html
github:https://github.com/HIT-SCIR/ltp
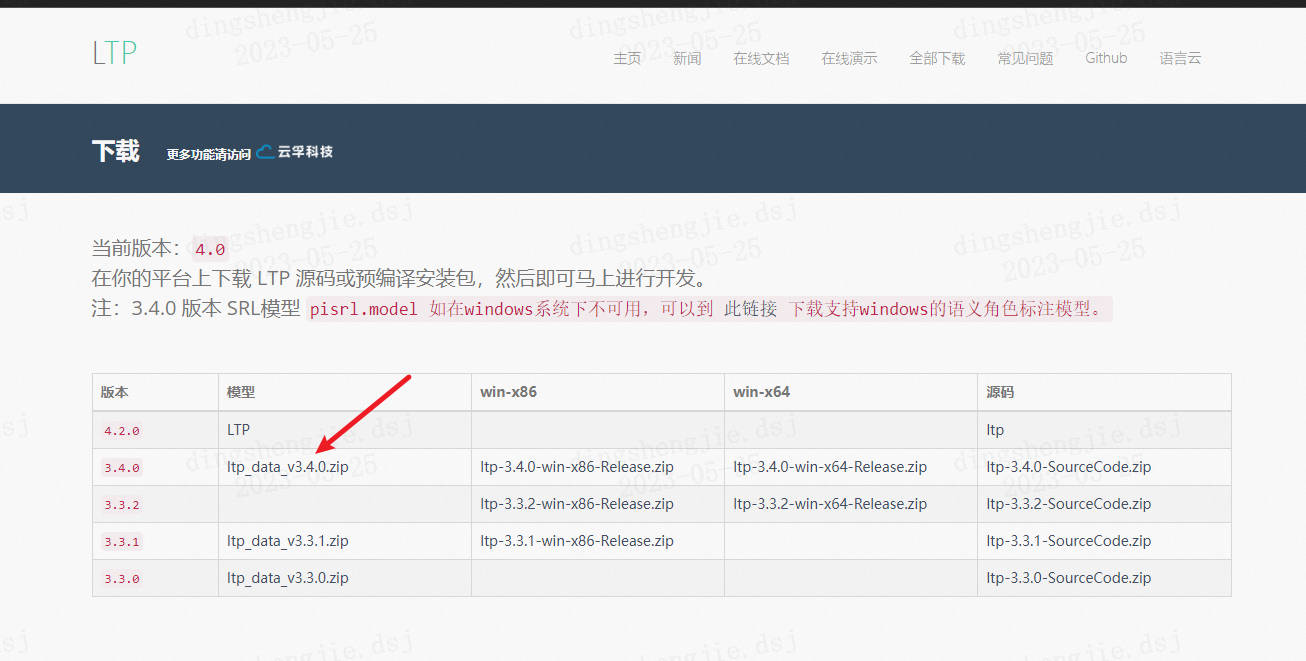
- pyltp 版本:0.2.1
- LTP 版本:3.4.0
下载后,可以解压到任意位置,C盘,D盘、E盘都行,为了方便查找数据,我将模型文件解压到我的pyltp库文件中
(1)新建一个项目文件夹,比如:D:\myLTP;
(2)将模型文件解压,将带版本号的模型文件改名字为ltp_data。文件夹放入项目文件夹;这将是我们以后加载模型的路径。 D:\myLTP\ltp_data.
下面说明所包含的模型内容:
1. 官方的下载模型文件,ltp_data并解压到任意位置(注意点:模型的路径最好不要有中文,不然模型加载不出),
2. 解压后得到一个大于1G的文件夹,确保此文件夹名称为ltp_data,位置任意,但在Python程序中一定要指明这个路径。
3. LTP提供的模型包括:(在ltp_data文件夹里面)
cws.model 分句模型,单文件
pos.model 词性标注模型,单文件
ner.model 命名实体识别模型,单文件
parser.model 依存句法分析模型,单文件
srl_data/ 语义角色标注模型,多文件(文件夹srl)(注意:按照官网提示注:3.4.0 版本 SRL模型 pisrl.model 如在windows系统下不可用,可以到官网“此链接” 下载支持windows的语义角色标注模型。)
182,672,934 cws.model
260 md5.txt
22,091,814 ner.model
367,819,616 parser.model
196,372,381 pisrl.model
433,443,857 pos.model
6 version
7 个文件 1,202,400,868 字节
2 个目录 108,015,374,336 可用字节
- 文档说明地址:https://github.com/HIT-SCIR/ltp
- Python文档说明地址:https://github.com/HIT-SCIR/pyltp
- http://pyltp.readthedocs.io/zh_CN/latest/api.html#id2
2.4 简要测试
from pyltp import SentenceSplitter
sents = SentenceSplitter.split('元芳你怎么看?我就趴窗口上看呗!') # 分句
print '\n'.join(sents)
结果如下
元芳你怎么看?
我就趴窗口上看呗!
2.5 pyltp中可能遇到问题
问题一:pyltp的初始化报错:segmentor = Segmentor() # 初始化实例TypeError: init(): incompatible constructor argument
LTP_DATA_DIR = './ltp_data_v3.4.0' # ltp模型目录的路径
cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model') # 分词模型路径,模型名称为`cws.model`
segmentor = Segmentor() # 初始化实例
segmentor.load(cws_model_path) # 加载模型
words = segmentor.segment(word) # 分词
words_list = list(words) #words_list列表保存着分词的结果
segmentor.release()
- pyltp的初始化报错
Traceback (most recent call last):
File “test.py”, line 11, in
segmentor = Segmentor() # 初始化实例
TypeError: init(): incompatible constructor arguments. The following argument types are supported:
1. pyltp.Segmentor(model_path: str, lexicon_path: str = None, force_lexicon_path: str = None)
- 解决方法:
解决1: 这是因为pyltp版本的写法不同,这种segmentor = Segmentor() 写法可以安装pyltp==0.2.1
解决2: pyltp==0.4.0的写法:不用segmentor = Segmentor()来进行初始化之后segmentor.load,而是直接加载模型,如以下代码:
from pyltp import Segmentor
LTP_DATA_DIR = './ltp_data_v3.4.0' # ltp模型目录的路径
cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model') # 分词模型
segmentor = Segmentor(cws_model_path)
words = segmentor.segment("元芳你怎么看")
print("|".join(words))
segmentor.release()
问题二:使用方法一安装出现VC++错误,
原因:你的电脑确实VC++编译环境,需要安装特定的VC++支持数据包。
解决方法:安装支持环境,下载下面的exe文件,安装VC++编译环境。
2.6 LTP基本组件使用(可以跳过)
2.6.1分词
import os
from pyltp import Segmentor
LTP_DATA_DIR='D:\LTP\ltp_data_v3.4.0'
cws_model_path=os.path.join(LTP_DATA_DIR,'cws.model')
segmentor=Segmentor()
segmentor.load(cws_model_path)
words=segmentor.segment('熊高雄你吃饭了吗')
print(type(words))
print('\t'.join(words))
segmentor.release()
#结果展示:
熊高雄 你 吃饭 了 吗
2.6.2 使用自定义字典
import os
from pyltp import Segmentor
#ltp模型目录的路径
LTP_DATA_DIR='D:\LTP\ltp_data_v3.4.0'
# 分词模型路径,模型名称为`cws.model`
cws_model_path=os.path.join(LTP_DATA_DIR,'cws.model')
segmentor=Segmentor() #初始化实例
#加载模型 第二个参数是您的外部词典文件路径
segmentor.load_with_lexicon(cws_model_path,'lexicon')
words=segmentor.segment('亚硝酸盐是一种化学物质')
print('\t'.join(words))
segmentor.release()
#代码运行结果:
亚硝酸盐 是 一 种 化学 物质
2.6.3 词性标注
词性标注的目标是用一个单独的标签标记每一个词,该标签表示了用法和其句法作用,比如名词、动词、形容词等。
在自然语言分析中,机器需要模拟理解语言。为了实现这一点,它必须在一定程度上能够了解自然语言的规则。它首先需要理解的是词,特别是每一个词的性质。它是一个名词还是一个形容词?如果它是一个动词的屈折形式,那么它的不定形式是什么,以及该屈折形式使用了什么对应的时态、人称和数?这个任务被称为词性标注(Part-of-Speech (PoS) tagging)
词性标注的正确与否将会直接影响到后续的句法分析、语义分析,是中文信息处理的基础性课题之一。常用的词性标注模型有 N 元模型、隐马尔科夫模型、最大熵模型、基于决策树的模型等。其中,隐马尔科夫模型是应用较广泛且效果较好的模型之一。
import os
from pyltp import Postagger
#ltp模型目录的路径
LTP_DATA_DIR='D:\LTP\ltp_data_v3.4.0'
# 词性标注模型路径,模型名称'pos.model'
pos_model_path=os.path.join(LTP_DATA_DIR,'pos.model')
postagger=Postagger() #初始化实例
#加载模型
postagger.load(pos_model_path)
words=['元芳','你','怎么','看'] #分词结果
postags=postagger.postag(words); #词性标注
print('\t'.join(postags))
postagger.release() #释放模型
nh r r v
2.6.4 命名实体识别
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。简单的讲,就是识别自然文本中的实体指称的边界和类别。
常见方法:
早期的命名实体识别方法基本都是基于规则的。之后由于基于大规模的语料库的统计方法在自然语言处理各个方面取得不错的效果之后,一大批机器学习的方法也出现在命名实体类识别任务。宗成庆老师在统计自然语言处理一书粗略的将这些基于机器学习的命名实体识别方法划分为以下几类:
有监督的学习方法:这一类方法需要利用大规模的已标注语料对模型进行参数训练。目前常用的模型或方法包括隐马尔可夫模型、语言模型、最大熵模型、支持向量机、决策树和条件随机场等。值得一提的是,基于条件随机场的方法是命名实体识别中最成功的方法。
半监督的学习方法:这一类方法利用标注的小数据集(种子数据)自举学习。
无监督的学习方法:这一类方法利用词汇资源(如 WordNet)等进行上下文聚类。
混合方法:几种模型相结合或利用统计方法和人工总结的知识库。
值得一提的是,由于深度学习在自然语言的广泛应用,基于深度学习的命名实体识别方法也展现出不错的效果,此类方法基本还是把命名实体识别当做序列标注任务来做,比较经典的方法是 LSTM+CRF、BiLSTM+CRF。
LTP 采用 BIESO 标注体系。B 表示实体开始词,I表示实体中间词,E表示实体结束词,S表示单独成实体,O表示不构成命名实体。
LTP 提供的命名实体类型为:人名(Nh)、地名(Ns)、机构名(Ni)。
B、I、E、S位置标签和实体类型标签之间用一个横线 - 相连;O标签后没有类型标签。
import os
from pyltp import NamedEntityRecognizer
#ltp模型目录的路径
LTP_DATA_DIR='D:\LTP\ltp_data_v3.4.0'
# 命名实体识别模型路径,模型名称'ner.model'
ner_model_path=os.path.join(LTP_DATA_DIR,'ner.model')
recognizer=NamedEntityRecognizer() #初始化实例
#加载模型
recognizer.load(ner_model_path)
words=['元芳','你','怎么','看'] #分词结果
postags=['nh','r','r','v'] #词性标注结果
netags=recognizer.recognize(words,postags) #命名实体识别
print('\t'.join(netags))
recognizer.release() #释放模型
S-Nh O O O
2.6.5 依存句法分析
import os
from pyltp import Parser
#ltp模型目录的路径
LTP_DATA_DIR='D:\LTP\ltp_data_v3.4.0'
# 依存句法分析模型路径,模型名称'parser.model'
par_model_path=os.path.join(LTP_DATA_DIR,'parser.model')
parser=Parser() #初始化实例
#加载模型
parser.load(par_model_path)
words=['元芳','你','怎么','看'] #分词结果
postags=['nh','r','r','v'] #词性标注结果
arcs=parser.parse(words,postags) #句法分析
print("\t".join("%d:%s" % (arc.head,arc.relation)for arc in arcs))
parser.release() #释放模型
4:SBV 4:SBV 4:ADV 0:HED
2.6.6 语义角色标注
语义角色标注(Semantic Role Labeling,简称 SRL)是一种浅层的语义分析。
给定一个句子, SRL 的任务是找出句子中谓词的相应语义角色成分,包括核心语义角色(如施事者、受事者等) 和附属语义角色(如地点、时间、方式、原因等)。根据谓词类别的不同,又可以将现有的 SRL 分为动词性谓词 SRL 和名词性谓词 SRL。
import os
from pyltp import SementicRoleLabeller
from pyltp import Parser
#ltp模型目录的路径
LTP_DATA_DIR='D:\LTP\ltp_data_v3.4.0'
#依存句法分析模型路径,模型名称'parser.model'
par_model_path=os.path.join(LTP_DATA_DIR,'parser.model')
# 语义角色标注模型路径,模型名称'pisrl_win.model'
srl_model_path=os.path.join(LTP_DATA_DIR,'pisrl_win.model')
#初始化实例
parser=Parser()
labeller=SementicRoleLabeller()
#加载模型
parser.load(par_model_path)
labeller.load(srl_model_path)
words=['元芳','你','怎么','看']
postags=['nh','r','r','v']
#句法分析
arcs=parser.parse(words,postags)
#arcs使用依存句法的结果
roles=labeller.label(words,postags,arcs)
#打印结果
for role in roles:
print(role.index," ".join(["%s:(%d,%d)" % (arg.name,arg.range.start,arg.range.end)for arg in role.arguments]))
labeller.release() #释放模
[dynet] random seed: 2834750376
[dynet] allocating memory: 2000MB
[dynet] memory allocation done.
3 A0:(1,1) ADV:(2,2)
3.文档关键信息提取形成知识图谱
代码情况:模型文件、主函数、前端可视化代码
部分代码展示:
from sentence_parser import *
import re
from collections import Counter
from GraphShow import *
from keywords_textrank import *
'''事件挖掘'''
class CrimeMining:
def __init__(self):
self.textranker = TextRank()
self.parser = LtpParser()
self.ners = ['nh', 'ni', 'ns']
self.ner_dict = {
'nh':'人物',
'ni':'机构',
'ns':'地名'
}
self.graph_shower = GraphShow()
'''移除括号内的信息,去除噪声'''
def remove_noisy(self, content):
p1 = re.compile(r'([^)]*)')
p2 = re.compile(r'\([^\)]*\)')
return p2.sub('', p1.sub('', content))
'''收集命名实体'''
def collect_ners(self, words, postags):
ners = []
for index, pos in enumerate(postags):
if pos in self.ners:
ners.append(words[index] + '/' + pos)
return ners
'''对文章进行分句处理'''
def seg_content(self, content):
return [sentence for sentence in re.split(r'[??!!。;;::\n\r]', content) if sentence]
'''对句子进行分词,词性标注处理'''
def process_sent(self, sent):
words, postags = self.parser.basic_process(sent)
return words, postags
'''构建实体之间的共现关系'''
def collect_coexist(self, ner_sents, ners):
co_list = []
for sent in ner_sents:
words = [i[0] + '/' + i[1] for i in zip(sent[0], sent[1])]
co_ners = set(ners).intersection(set(words))
co_info = self.combination(list(co_ners))
co_list += co_info
if not co_list:
return []
return {i[0]:i[1] for i in Counter(co_list).most_common()}
3.1 调用方式
from text_grapher import *
content = 'xxxxxx请自己输入'
handler = CrimeMining()
handler.main(content8)
结果保存在graph.html文件当中。
3.2案例展示
1) 中兴事件
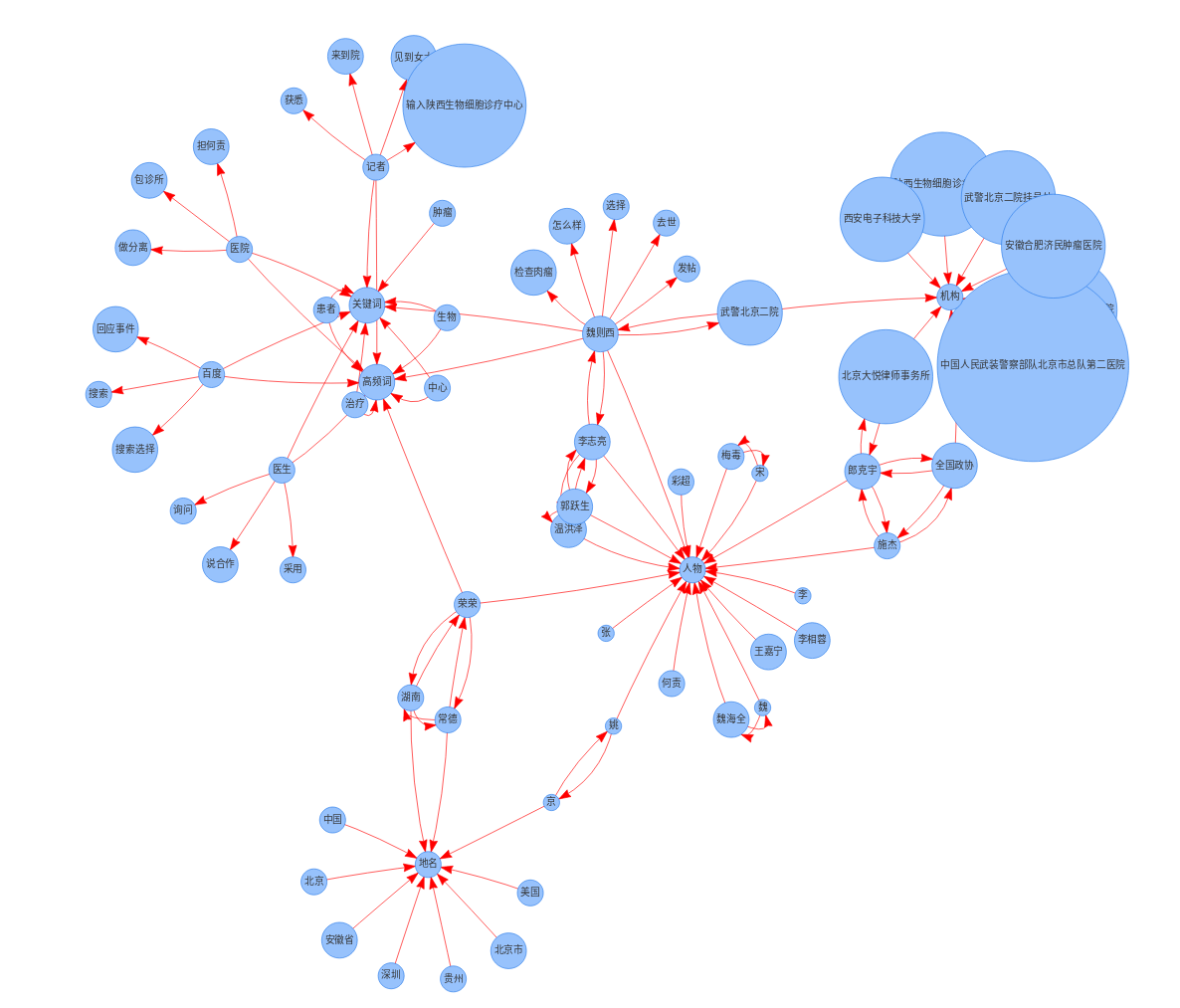
- 魏则西事件
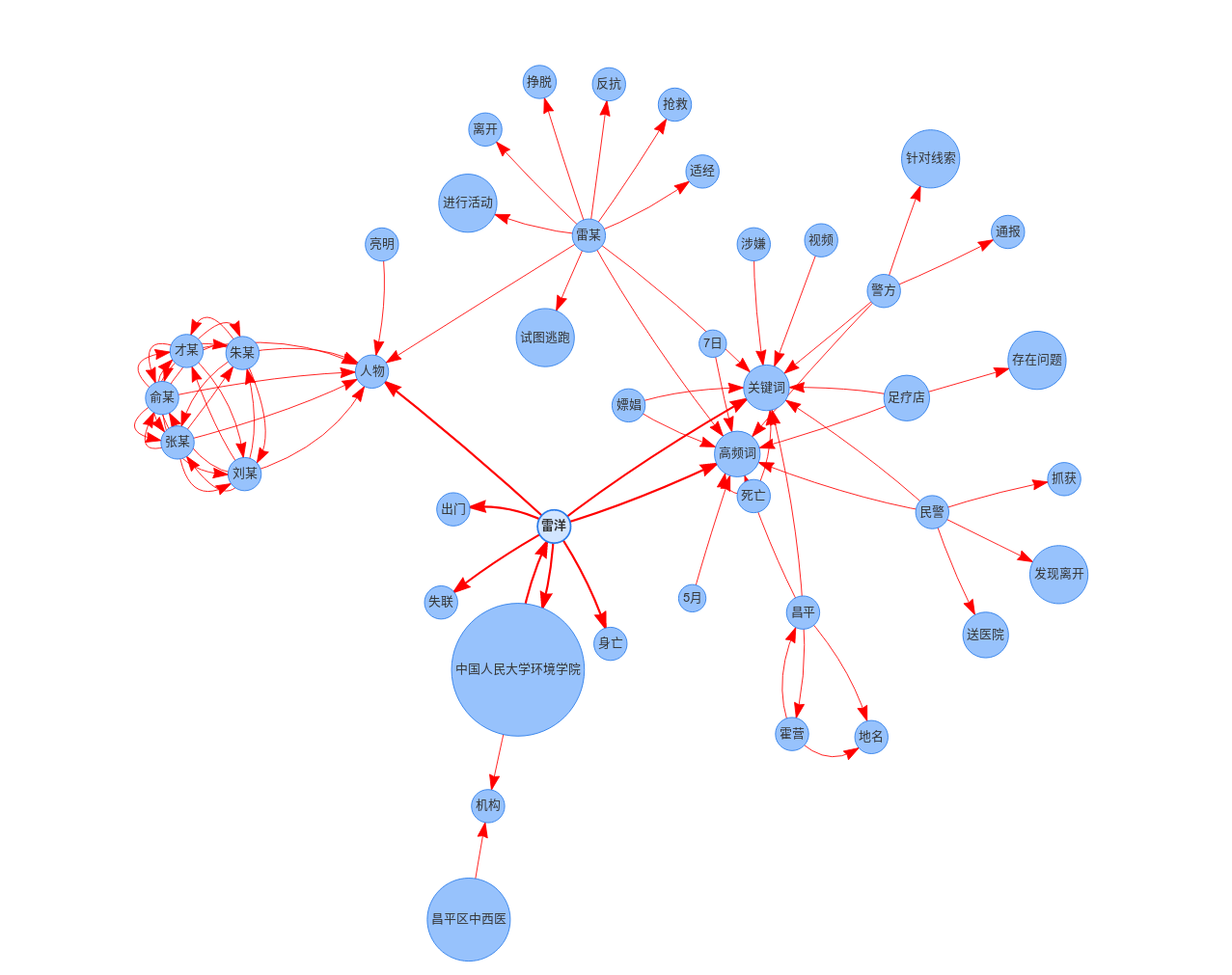
- 雷洋事件
- 同学事件
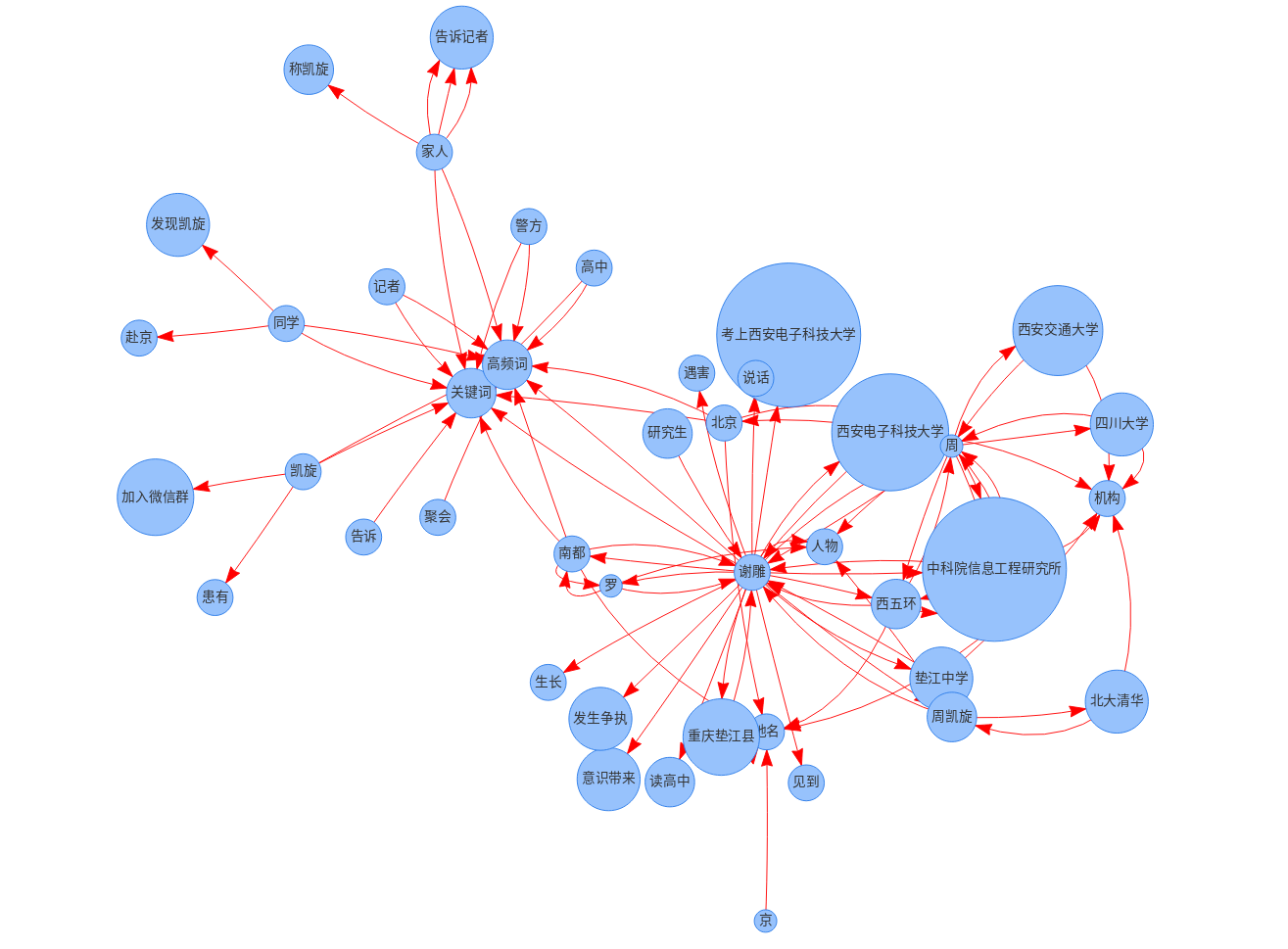
(原标题:中科院研究生遇害案:凶手系同乡学霸,老师同学已为死者发起捐款)
6月14日下午6点多,中科院信息工程研究所硕士研究生谢雕在饭馆招待自重庆远道而来的高中同学周凯旋时,被周凯旋用匕首杀害。随后,周凯旋被北京警方抓获。
周凯旋被抓后,他的家人向被警方递交了精神鉴定材料,称周凯旋患有精神性疾病。
谢雕的家人罗发明告诉南都记者,谢雕被害后,他的研究生老师和同学发起了捐款。并说,谢雕的遗体已经进行尸检,等尸检结果出来后,家人将会把火化后的骨灰带回老家安葬,之后,他们将等待北京检察机关的公诉。
高中同学千里赴京去杀人
今年25岁的谢雕生长于重庆垫江县的一个小山村,谢雕和周凯旋同在垫江中学读高中,两人学习成绩名列前茅,周凯旋经常考年级第一,两人都是垫江中学的优秀毕业生,谢雕考上了西安电子科技大学,周凯旋考取了四川大学。
微信图片_20180627174901_副本.jpg案发现场的行凶者周凯旋(受访者提供)。
学习优秀的周凯旋认为自己应该能考上北大清华等名校,于是在入读四川大学两三个月后,选择了退学复读。经过半年多的苦读,周凯旋以优异成绩考取了西安交通大学,来到了谢雕所在的城市,且是硕博连读。
但周凯旋因大学本科期间因沉迷游戏,考试不及格,最终失掉了硕博连读的机会,本科毕业后就回到重庆寻找就业机会。谢雕自西安电子科技大学毕业后,在2016年考取了中国科学院大学的硕士研究生,所读专业隶属于中科院信息工程研究所。
谢雕的家人告诉南都记者,6月14日下午6点,谢雕在西五环外的中科院信息工程研究所门口见到了久未见面的高中同学周凯旋。把他带到旁边的饭馆吃饭,两人还合影发到了高中同学微信群。这时,谢雕还没意识到周凯旋即将对他带来致命伤害。
南都记者在谢雕遇害现场视频中看到,在谢雕点菜时,周凯旋用匕首刺向他胸部,谢雕中刀站起后退时,周凯旋用匕首又刺向他颈部,谢雕倒地后,周凯旋又从背部向他连刺几刀。之后,又持刀割断了谢雕的颈部动脉。这时,有食客拿起椅子砸向正在行凶的周凯旋。刺死谢雕后,周凯旋举起双手挥舞,随后扬长而去。后来,周凯旋被北京警方抓获。
同学聚会时自己觉得受伤害起杀心
罗发明告诉南都记者,作为被害人家属,他们向北京警方了解到,凶案原因来自两年前的一场同学聚会,谢雕的一些话对周凯旋带来很大心理压力,让他不能释怀。
两年前的一次高中同学聚会中,大家聊的话题很多,也聊到了周凯旋喜欢打游戏的事情,谢雕说了一些激励周凯旋的话,让他不要再打游戏,要振作起来。在参与聚会的同学们看来,这些话是常理之中的,但在周凯旋看来,对他带来很大伤害,两年来给他带来很大心理压力。
参与那次聚会的同学后来回忆,在一起玩“狼人杀”游戏时,谢雕、周凯旋发生了争执,但不愉快的瞬间很快就过去了,大家也都没当回事。
那次聚会之后的春节,不少同学发现被周凯旋拉黑,中断了联系。直至一年之后,周凯旋才加入了高中同学微信群。
谢雕的家人说,周凯旋在网上购买了杀人凶器匕首,收货地址填写了北京,他在北京拿到网购的匕首后,才暗藏在身前来面见谢雕。
师生捐款助他家人渡难关
周凯旋被北京警方抓获后,他的家人向警方称周凯旋患有精神病,并提供了一些证明材料,希望得到从轻处置。
谢雕遇害后,他的学校为失去这么优秀的学生感到惋惜。谢雕的老师说,“谢雕家境并不富裕,本科尚有2.5万助学贷款未偿还,前不久还向同学借款1万,父亲也患有鼻咽癌。”
谢雕的老师和同学发起了捐款,希望能帮助谢雕的家人暂时渡过难关。
谢雕的家人告诉南都记者,他们向谢雕的学校提出要求,希望案件能尽快解决。
罗发明对南都记者说,谢雕的遗体已经进行尸检,尸检后十天至十五天出来结果,等拿到尸检报告后,他们会尽快火化谢雕的遗体,把他的骨灰带回重庆老家安葬。
对于这一案件,谢雕的家人告诉南都记者,他们将等待北京的检察机关提起公诉。
- 其他事件
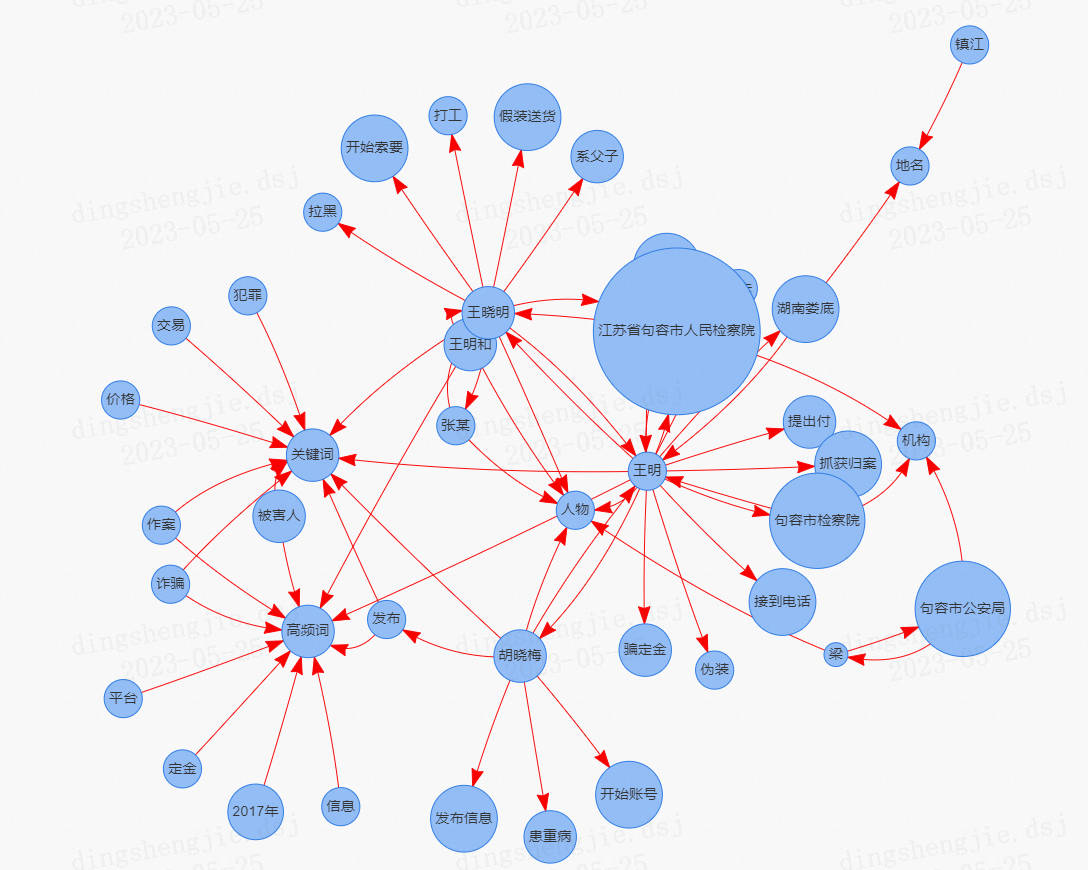
正义网镇江9月5日电(通讯员喻瑶 杜希)通过网络二手平台发布虚假信息,利用低廉的价格吸引购买者,诱骗买家先付定金、再付全款,先后诈骗作案11起,涉案金额28200元。2017年7月27日,江苏省句容市人民检察院依法对王明、王晓明两人以涉嫌诈骗罪批准逮捕。
妻子患病缺钱治,心思一动起歪念
王明和王晓明系父子关系。 2016年2月,王明的妻子胡晓梅患上重病,前期到医院治疗已经花费了十几万元医疗费用,后期治疗更是个“无底洞”,因为家庭生活困难,夫妻二人就动起了诈骗赚钱的歪念。
2016年底,王明在湖南娄底路边买了11张外地的手机卡用于联络,又购买了9张通过别人名字的办理的银行卡用于收款,准备好作案工具后,妻子胡晓梅就开始在58同城这些二手交易平台上注册账号,发布各种便宜的虚假二手信息,一切准备就绪,他们静待“猎物”上钩。
先后作案11起 先骗定金再骗全款
因为胡晓梅在平台上发布的二手信息价格很低,货品质量看起来也不错,所以很快就有“顾客”上门,2017年1月11日,王明接到一个句容宝华人的电话,有意购买他在网络平台上发布的一辆价值3200元的二手车,为了迅速达成交易,王明伪装成卖车老板和买家开始谈价格,价格谈拢后,王明提出要先付定金,再送货上门的要求。当日,王明顺利骗到了100元定金。
第二天,王明按照初次双方谈好的送货地址,让自己的儿子王晓明假装成送货人,向被害人打电话,谎称把交易的货物运到了句容市某地,声称自己开的车是“黑车”,直接进行现金交易不太安全,让被害人张某把剩下的购车款打过来,先付钱再拿车,被害人张某立即通过某银行ATM机向王晓明支付了剩余的3100元。王晓明又开始索要其他费用,这时被害人张某已经觉察到了不对劲,不肯再付钱,王晓明就把号码拉黑,不再联系。
轻松到手的钱财,进一步引发了父子两人的贪欲。很快,王明的儿子王晓明就不再打工,而是加入父母,全家一起做专职诈骗的“买卖”。随着诈骗次数的增加,他们的诈骗手法也从单纯的收取定金和购车款发展出索要上牌费、安全保证金等多种形式。
一家人分工协作,王明负责伪装老板和取钱,王晓明假装送货,胡晓梅发布信息。2017年初至今,王明一家人共诈骗作案11起,涉案金额28200元。
受害人报警,父子两人终落法网
2017年4月3日,句容市公安局接到了被害人梁某某等人的报警电话,经过公安机关介入侦查,犯罪嫌疑人王明、王晓明于2017年6月6日被抓获归案。2017年7月21日,在句容市检察院检察官在依法对犯罪嫌疑人王明等人讯问过程中,王明在得知自己和儿子因触犯法律而将面临牢狱之灾时,后悔不已。
“近年来,检察机关在依法查办的多起诈骗案中发现,不法分子利用可乘之机,以多种方式实施不同的诈骗,作案手段多样化,让广大市民深受其害。检察机关将依法履行职能,对此类诈骗犯罪坚决打击,实现从快从速逮捕和审查起诉,同时检察官提醒广大市民,遇到不法侵害要及时报警。”承办检察官说。
#项目链接以及码源见文末:
4.总结
- 项目优点:
将文档进行关键信息提取,进行结构化,并最终组织成图谱组织形式,形成对文章语义信息的图谱化展示。在后续抽取任务上有借鉴意义
- 项目不足之处:
- 如何用图谱和结构化的方式,即以简洁的方式对输入的文本内容进行最佳的语义表示是个难题。
- 本项目采用了高频词,关键词,命名实体识别,主谓宾短语识别等抽取方式,并尝试将三类信息进行图谱组织表示,后续有待优化不然会导致抽取信息混乱且无效
- 该项目:命名实体识别以及关键信息抽取受限于NLP的性能,在算法和方式上还存在多处不足。(采用了pyltp库自带的算法具有滞后性)
- 处理方式项目也是按照小段落方式抽取,同时在关系定义上模糊,目前看了主要是依赖实体定义链接,有改进空间。
参考链接:pyltp安装教程及简单使用:https://www.likecs.com/show-308274257.html
pyltp的安装和使用:https://www.e-learn.cn/topic/3461951

- 点赞
- 收藏
- 关注作者
评论(0)