web安全-信息收集姿势汇总

- Whois 查询
- 信用信息查询
- IP反查站点的站
- 收集相关应用信息
- 微信公众号&微博
- 收集子域名信息
- 权重综合查询
- 全国政府网站基本数据库
- IP反查绑定域名网站
- 资产搜索引擎
- · FOFA语法查询
- 证书透明度公开日志枚举
- · 在线第三方平台查询
- 工具枚举查询
- DNS历史解析
- DNS域传送漏洞
- · DNS记录分类
- DNS域传送漏洞检测
- 查找真实IP
- CDN简介
- 国内外CND
- 判断目标是否存在CDN
- · Ping目标主域
- · 站长工具
- 绕过CDN查找真实IP
- · 国外DNS解析
- · 分站域名&C段查询
- · 分站域名
- · C段查询
- · 网站漏洞
- · 一些测试文件
- · 目标网站APP应用
- · 网络空间引擎搜索








信息收集-补充知识
谷歌hacking语法:
filetype:指定文件类型
inurl:指定url包含内容
site:指定域名
intitle:指定title包含内容
intext:指定内容
inurl:/admin/index #这种很容易找到别人的后台
inurl:/admin.php #这种就很容易找到admin.php的内容
site:edu.cn inurl:.php?id=123 #找SQL注入站点时可以这么找
君子协议
/robots.txt => 防止蜘蛛爬虫的协议
告诉搜索引擎哪些不要爬取,但是因为这是个君子协议,所以搜索引擎可以不遵守
WAF检测
工具:
https://github.com/EnableSecurity/wafw00f wafw00f
APP及其他资产获取
1、APP一键提取反编译【工具:漏了个大洞】
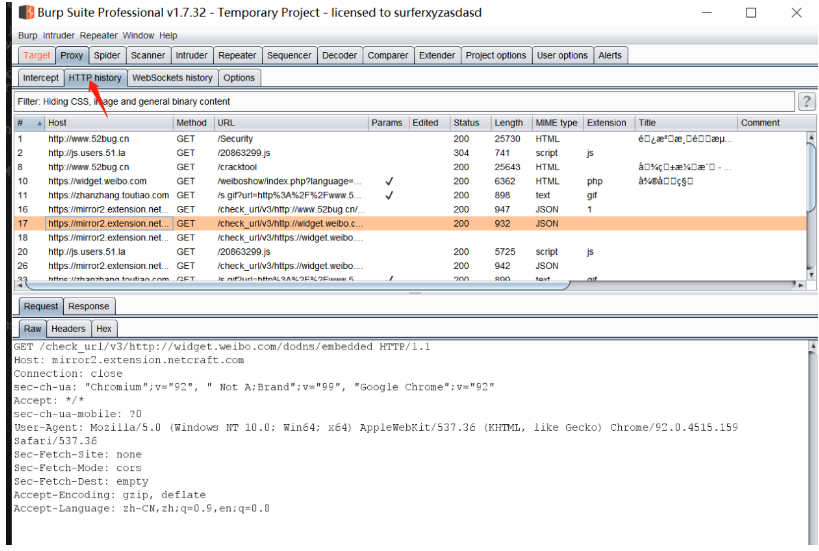
2、APP 抓数据包进行工具配合【模拟器+Burp】
利用Burp历史抓取更多URL
其它方法
同一个域名的不同后缀有可能属于同一个网站(.cn|.com|.net)
知识学习库
https://websec.readthedocs.io/zh/latest/ Web安全学习笔记
Github监控
Github监控最新的EXP发布及其它
# Title: wechat push CVE-2020
# Date: 2020-5-9
# Exploit Author: weixiao9188
# Version: 4.0
# Tested on: Linux,windows
# coding:UTF-8
import requests
import json
import time
import urllib3
import os
import pandas as pd
time_sleep = 20 # 每隔20秒爬取一次
while(True):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"}
# 判断文件是否存在
datas = []
response1 = None
response2 = None
if os.path.exists("olddata.csv"):
# 如果文件存在则每次爬取10个
df = pd.read_csv("olddata.csv", header=None)
datas = df.where(df.notnull(),None).values.tolist()# 将提取出来的数据中的nan转化为None
requests.packages.urllib3.disable_warnings()
response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE-2021&sort=updated&per_page=10",
headers=headers,verify=False)
response2 = requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&per_page=10",
headers=headers,verify=False)
else:
# 不存在爬取全部
datas = []
requests.packages.urllib3.disable_warnings()
response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE-2021&sort=updated&order=desc",headers=headers,verify=False)
response2 = requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&order=desc",headers=headers,verify=False)
data1 = json.loads(response1.text)
data2 = json.loads(response2.text)
for j in [data1["items"],data2["items"]]:
for i in j:
s = {"name":i['name'],"html":i['html_url'],"description":i['description']}
s1 =[i['name'],i['html_url'],i['description']]
if s1 not in datas:
#print(s1)
#print(datas)
params = {
"text":s["name"],
"desp":" 链接:"+str(s["html"])+"\n简介"+str(s["description"])
}
print("当前推送为"+str(s)+"\n")
print(params)
requests.packages.urllib3.disable_warnings()
requests.get("https://sctapi.ftqq.com/SCT68513T20RxXKZZlL1mtwHtu8UtTyPQ.send",params=params,timeout=10,verify=False)
#time.sleep(1)#以防推送太猛
print("推送完成!")
datas.append(s1)
else:
pass
#print("数据已存在!")
pd.DataFrame(datas).to_csv("olddata.csv",header=None,index=None)
time.sleep(time_sleep)
实战案例演示:
群友 WEB 授权测试下的服务测试【https://www.caredaily.com/】
网站表面上看起来存在漏洞的可能性不高,功能都比较简单
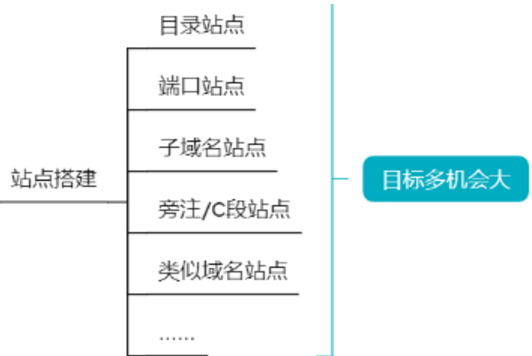
接下来直接从以下5方面开始
我们直接去fofa、shodan、zoomeye进行域名搜索
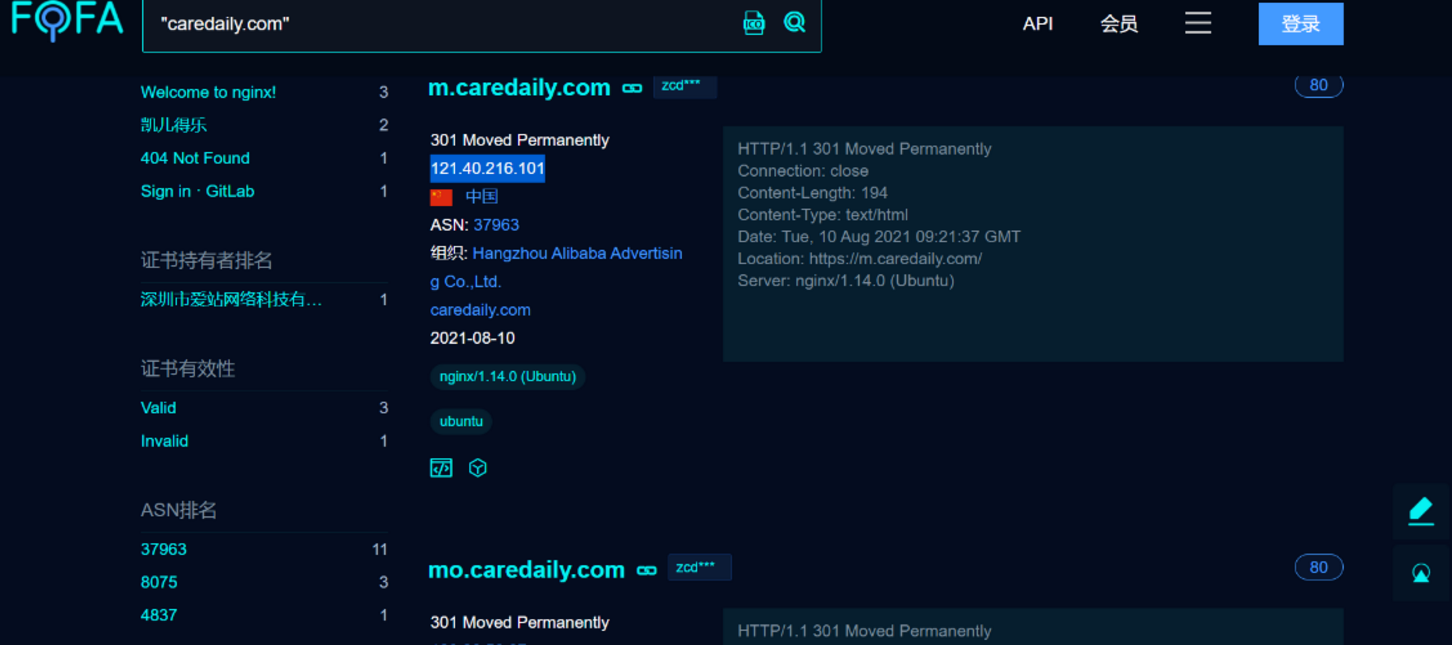
查看特定IP开放的端口服务可以通过
https://fofa.so/hosts/121.40.216.101 -> 替换成想要查询的IP
我们注意到这里8000端口出现了OpenSSH服务,我们就可以去搜对应版本存在的漏洞,去验证

我们又注意到他这27017开了MongoDB,那么就可能存在MongoDB数据库相关的漏洞,我们也可以去进行尝试
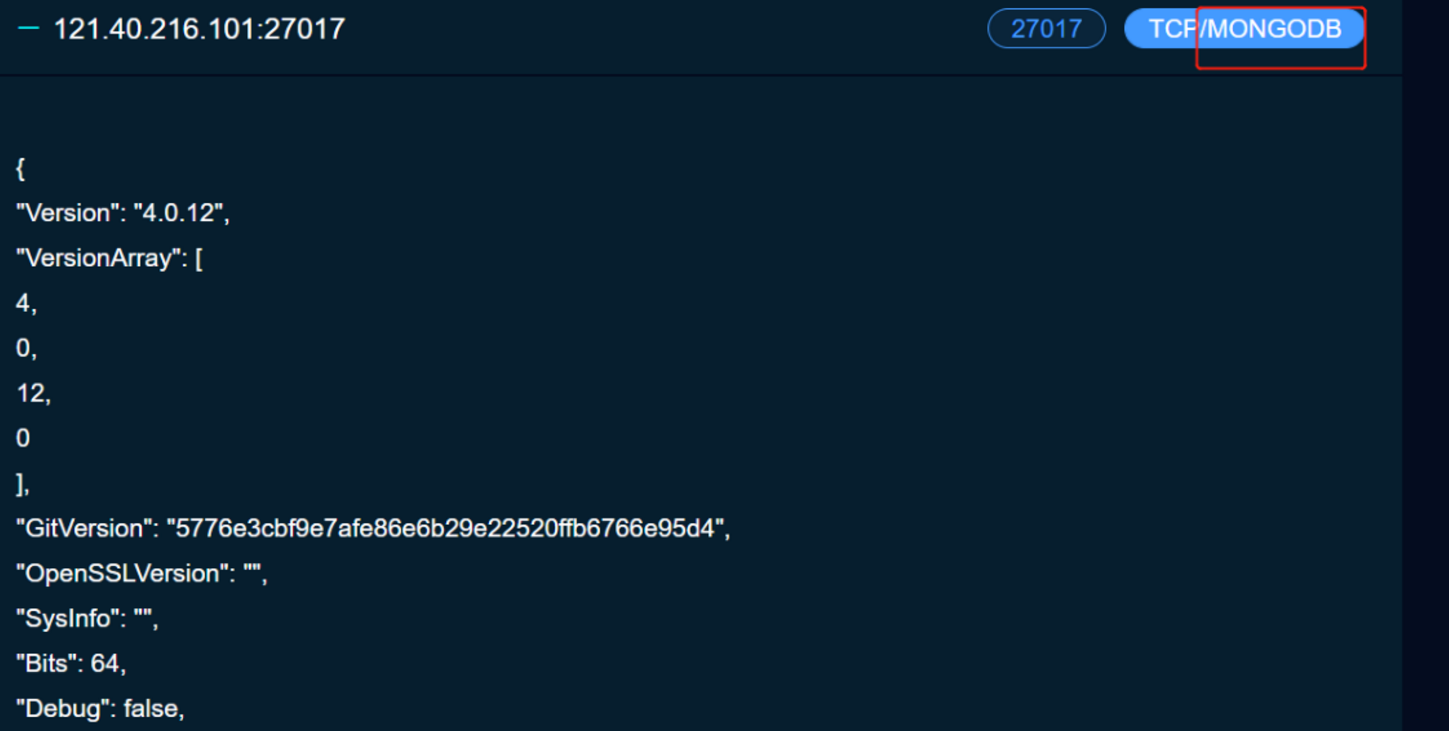
这个地方又可以成为一个攻击点
其他端口也类似,端口代表着服务,有服务就代表可能存在相应的服务的漏洞
我们就可以先记录下来,然后最后统一对各个点进行攻击。
我们还可以搜索它的目录站点、子域名站点、旁注/C段站点进一步扩大我们的攻击面【利用工具:7kbScan御剑扫描、Layer子域名挖掘机、同IP站点查询】
最后讲一下类似域名怎么找?
利用接口查,第一步就是查备案信息【需要VIP】
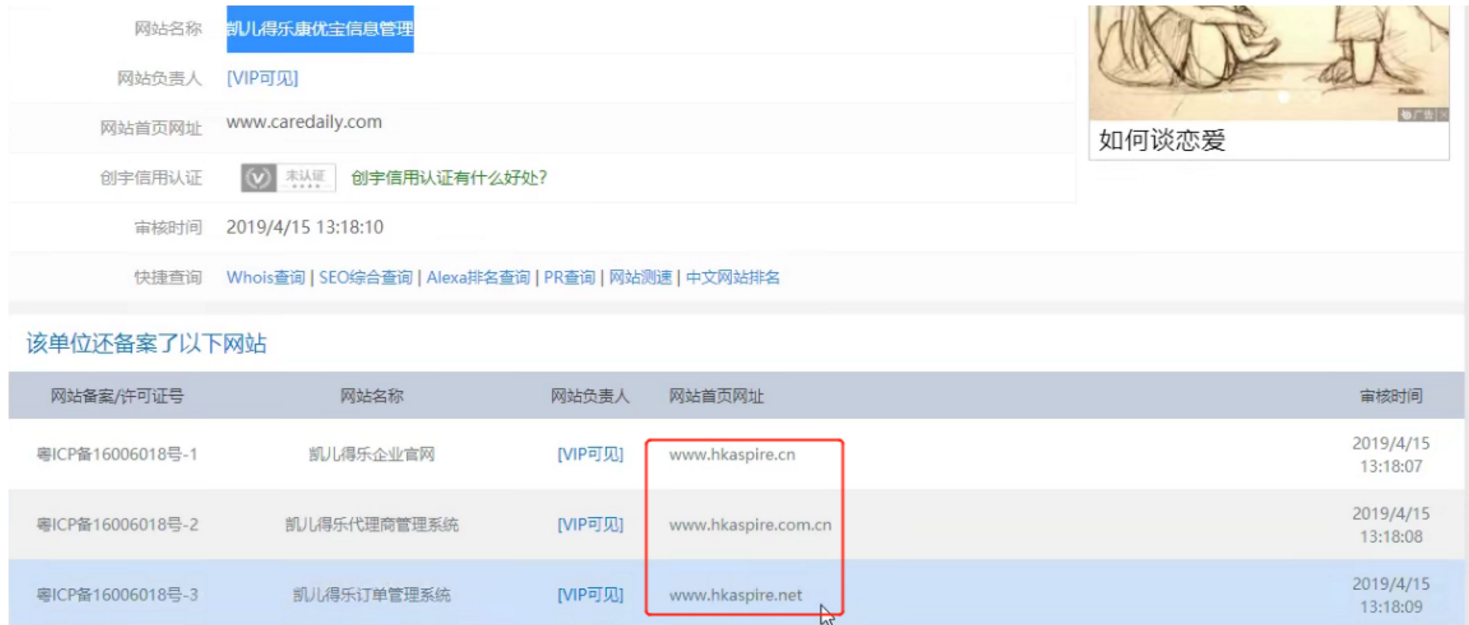
然后我们就新获得了几个域名
http://hkaspire.net/ 和 https://hkaspire.cn/
在 http://hkaspire.net/ 这个网站我们发现这里可以点击,点击之后跳转到一个新的页面 http://hkaspire.net:8080/login
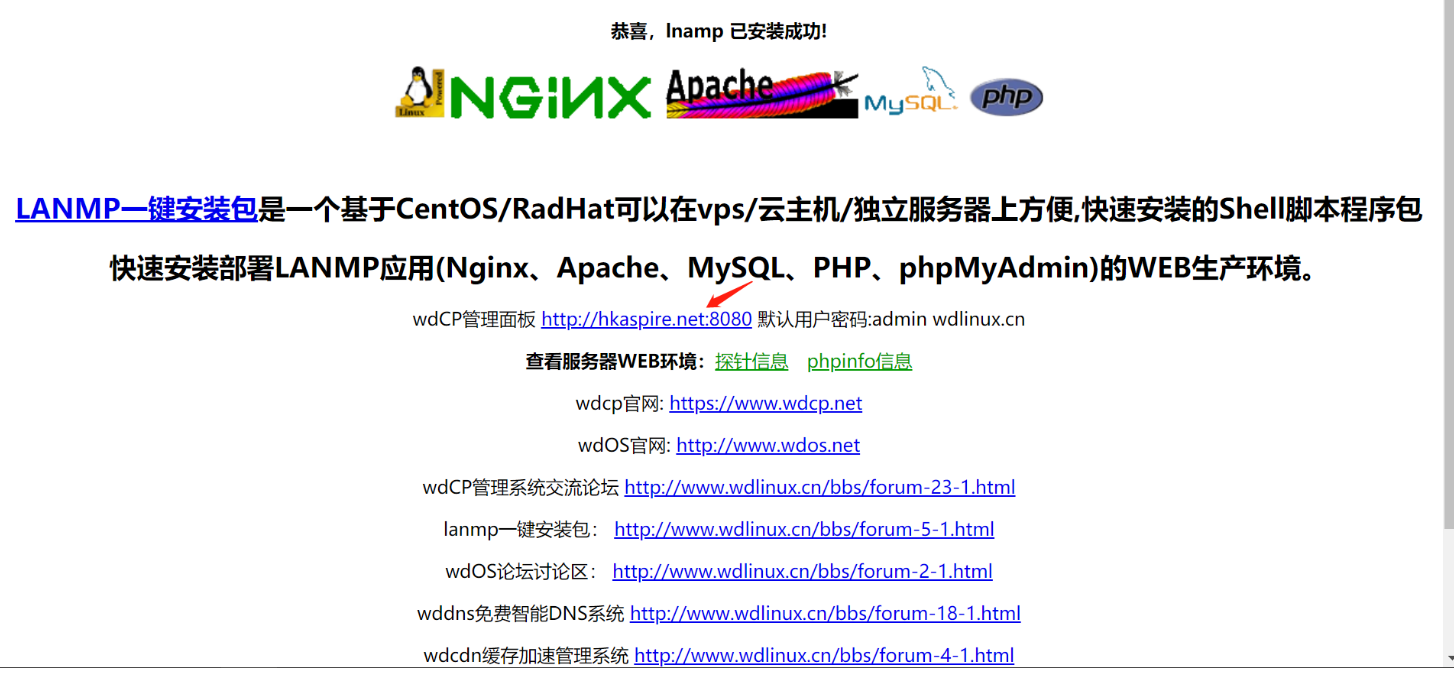
这其实也是可以成为一个攻击面的
他这里其实还暴露了很多,类似于探针信息,phpinfo信息
针对这个WDCP登陆系统,我们也可以直接在网上搜漏洞,进行漏洞测试
针对这个 https://hkaspire.cn/ 网站,这也是个系统,我们也可以进行漏洞测试

与此同时,这个域名https://hkaspire.cn/也涉及到新的IP地址,我们也可以针对这个IP地址进行测试【进行fofa的搜索】
所以能做的事情是很多的
这样还没完,我们可以拿这种网站的标题去百度|谷歌搜索
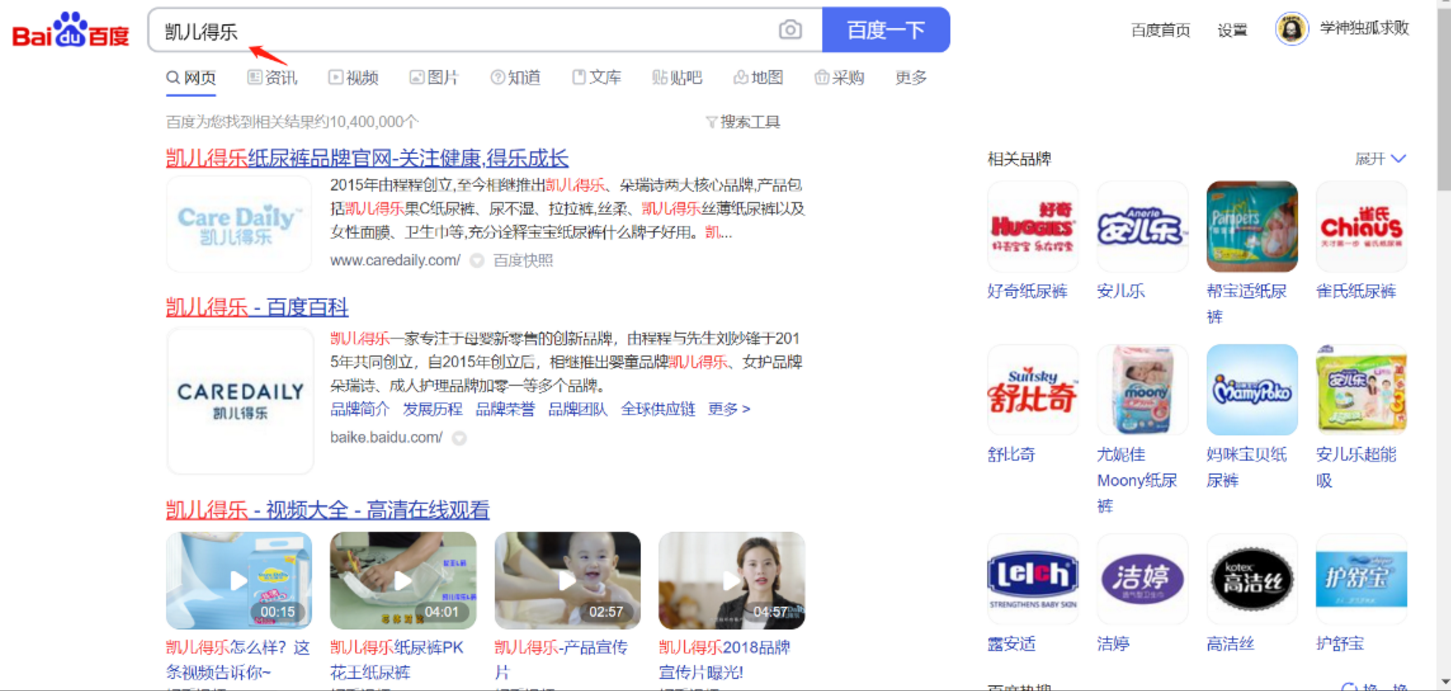
像是域名差不多的都可以进行测试
我们还可以去搜索域名的关键字【尽量用Google去搜索】
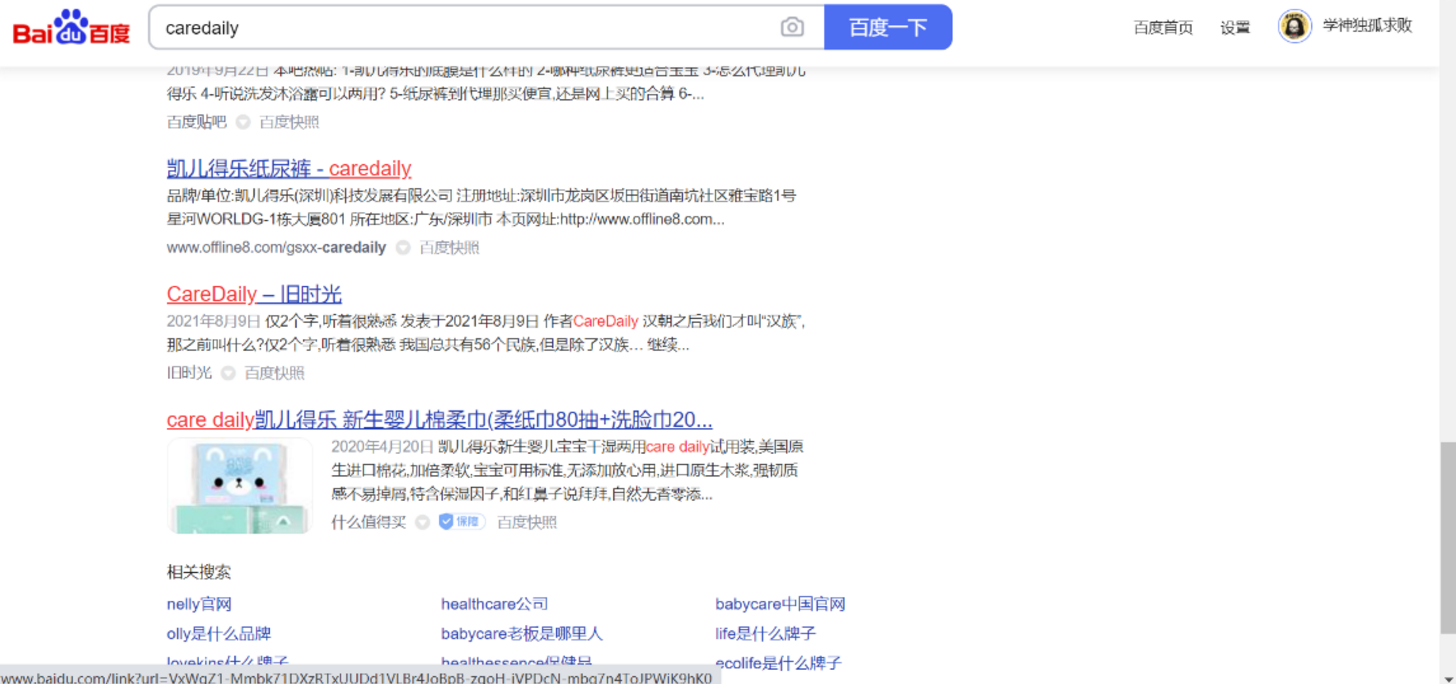
这个是我们通过谷歌搜到的 http://caredaily.xyz/

我们查看其robots.txt可以查到其一些路径
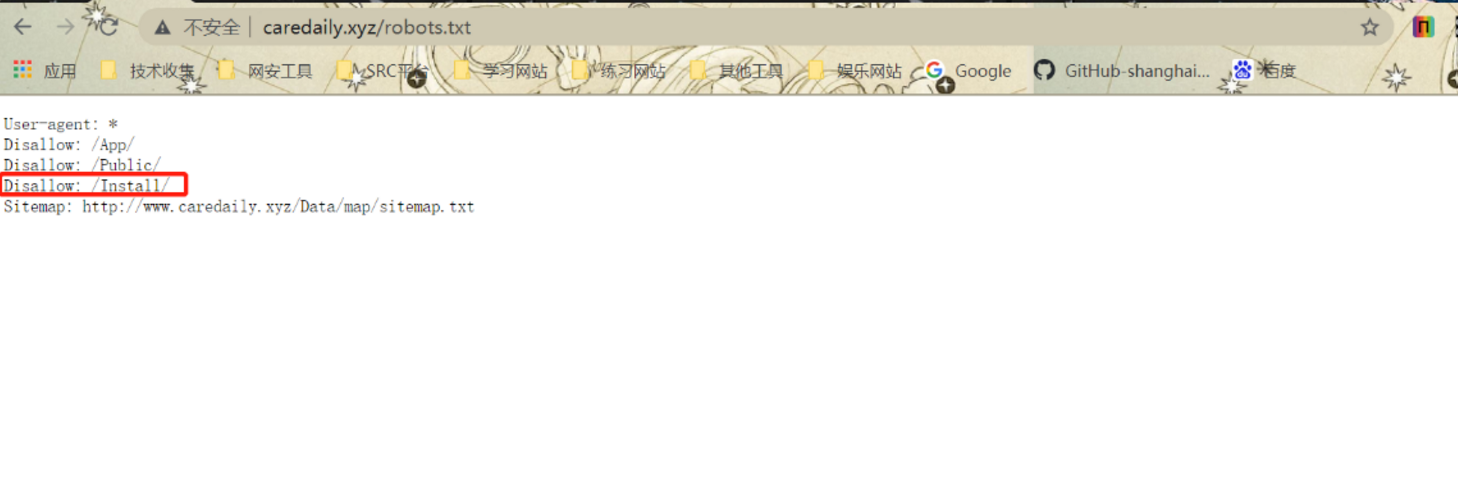
我们进这个Install看看
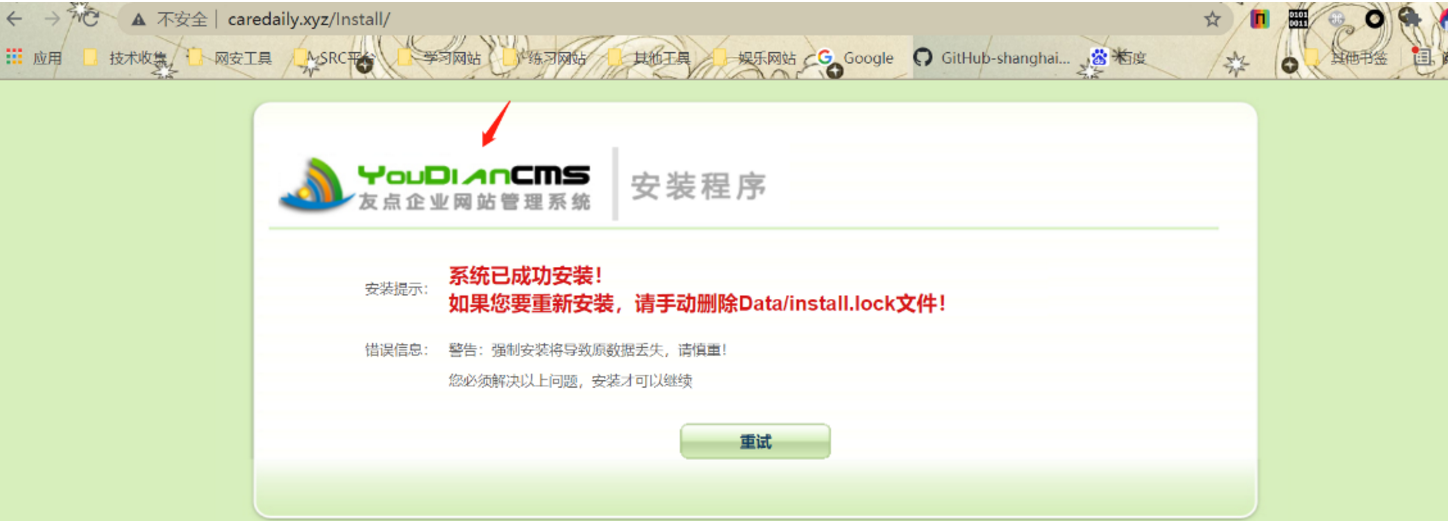
然后我们就又可以去百度搜索youdiancms漏洞
这搜到的信息已经足够多了,而且我们每个得到的域名对应的每个IP,每个端口都要扫,我们会拿到相当多信息,足够我们进行渗透测试

- 点赞
- 收藏
- 关注作者
评论(0)