深度学习基础入门篇10:序列模型-词表示{One-Hot编码、Word Embedding、Word2Vec、词向量的一些有趣应

深度学习基础入门篇[10]:序列模型-词表示{One-Hot编码、Word Embedding、Word2Vec、词向量的一些有趣应用}
在NLP领域,自然语言通常是指以文本的形式存在,但是计算无法对这些文本数据进行计算,通常需要将这些文本数据转换为一系列的数值进行计算。那么具体怎么做的呢?这里就用到词向量的概念。
一般情况下,当我们拿到文本数据的时候,会先对文本进行分词,然后将每个单词映射为相应的词向量,最后基于这些词向量进行计算,达到预设任务的效果,下边我们分如下几节展开介绍词向量相关的知识。
1.One-Hot编码: 一种简单的单词编码方式
在NLP领域,如何将单词数值化呢,One-Hot编码就是一种很简单的方式。假设我们现在有单词数量为 的词表,那可以生成一个长度为 的向量来表示一个单词,在这个向量中该单词对应的位置数值为1,其余单词对应的位置数值全部为0。举例如下:
词典: [queen, king, man, woman, boy, girl ]
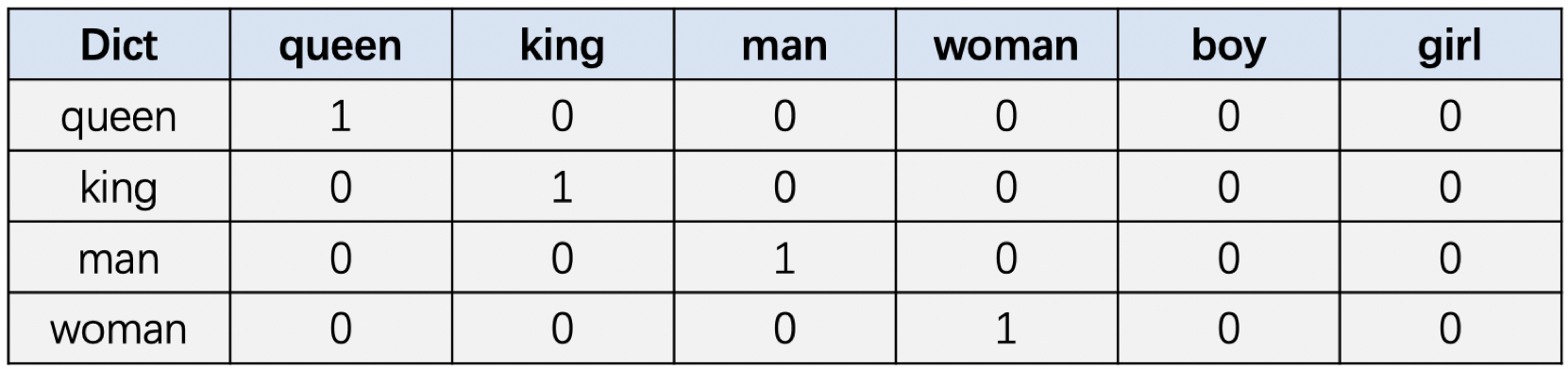
图1 one-hot 编码图
假设当前词典中有以上6个单词,图1展示了其中4个单词的one-hot编码表示。这个表示是不是挺简单的,但是这种表示方式也有一些不太合适的地方。
首先,在实际应用中词表中单词的数量往往比较多,高达几十万,甚至百万。这种情况下使用one-hot编码的方式表示一个单词,向量维度过长,同时向量会极其稀疏。
其次,从图1我们也可以看出向量之间是正交的,向量之间的点积为0,因此无法直接通过向量计算的方式来得出单词之间的关系。直观上我们希望语义相近的单词之间的距离比较近。比如,我们知道,“香蕉”和“橘子”更加相似,而“香蕉”和“句子”就没有那么相似,同时,“香蕉”和“食物”,“水果”的相似程度,可能介于“橘子”和“句子之间”。
2.Word Embedding: 一种分布式单词表示方式
前边我们谈到了one-hot编码的缺陷,这一节我们来聊另一种分布式的表示方式:Word Embedding,看他是怎么解决这些问题的。
假设每个单词都可以用 个特征进行表示,即可以使用这 个特征来刻画每个单词,如图2所示,我们使用图2中的这5个特征来刻画”狗”、”蜈蚣”、”君子兰”和”填空”这几个词。
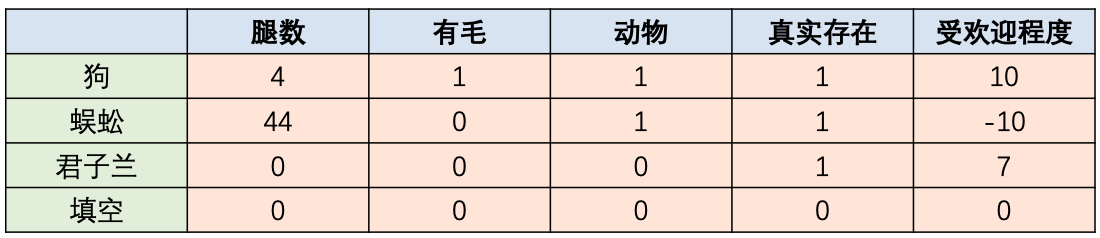
图2 单词表示样例
显然,有了这些特征去构建词向量,我们能够根据这些特征比较容易地去划分单词的类别,比如”狗”和”蜈蚣”均是动物,在这个角度上说是一类的,他们之间的距离应该要比”狗”和”君子兰”近。
我们在回到词向量上来,按照同样的想法,可以使用这 个特征来刻画每个单词,并且这 个特征是浮点类型的,这样可以拓宽表示范围。当我们将视角切换到 维空间,那么每个词向量其实就相当于是该 维空间的一个点,相当于是将该单词嵌入到该空间中,这也是Word Embedding的原始意义。
当然我们通常是无法穷举具体的特征类别的,所以在NLP领域一般直接将模型表示为长度为 的向量让模型去训练(只是每个向量维度具体代表什么含义是不好去解释的)。但好消息是通过合适的词向量学习算法,是可以比较好的学习到单词的语义信息的,语义相近的单词之间的距离会比较近,语义不同的单词之间距离会比较远。
图3 词向量示意图
图3展示了关于词向量的一些例子,当我们将词向量训练好之后,我们可以看到France, England, Italy等国家之间比较近,并形成一个小簇;dog, dogs,cat,cats形成一个小簇。簇内的单词距离一般会比较近,不同簇的单词距离会比较远。
3.Word2Vec: 一种词向量的训练方法
前边我们貌似提出了一个对词向量比较好的期望,但是如何去学习这些词向量,达到这种效果呢?这就是本节讨论的话题,本节将通过Word2Vec为大家讲解词向量的训练方法。
简单地讲,Word2Vec是建模了一个单词预测的任务,通过这个任务来学习词向量。假设有这样一句话Pineapples are spiked and yellow,现在假设spiked这个单词被删掉了,现在要预测这个位置原本的单词是什么。
Word2Vec本身就是在建模这个单词预测任务,当这个单词预测任务训练完成之后,那每个单词对应的词向量也就训练好了。下边我们来具体看看吧。
3.1 Word2Vec概述¶
在正式介绍之前,我们先来科普一下Word2Vec,Word2vec是2013年被Mikolov提出来的词向量训练算法,在论文中作者提到了两种word2vec的具体实现方式:连续词袋模型CBOW和Skip-gram,如图4所示。

图4 CBOW和Skip-gram的对比
图4中使用了这句话作为例子:Pineapples are spiked and yellow,在这句话中假设中心词是spiked,这个单词的上下文是其他单词:Pineapples are and yellow。
连续词袋模型CBOW的建模方式是使用上下文单词来预测spiked这个单词,当然图片上展示的是spikey,相当于是预测错了。Skip-gram正好反过来,它是通过中心词来预测上下文。
一般来说,CBOW比Skip-garm训练快且更加稳定一些,然而,Skip-garm不会刻意地回避生僻词(即出现频率比较低的词),比CBOW能够更好地处理生僻词。在本节呢,我们将以Skip-garm的方式讨论词向量的训练过程。
3.2 Skip-gram训练词向量原理
前边我们说到,Skip-gram是通过中心词来预测上下文。我们还是以Pineapples are spiked and yellow为例进行讲解,如图5所示,中心词是spiked,上下文是Pineapples are and yellow,在Skip-gram中,上下文是我们要预测的词,因此这些词也叫目标词。
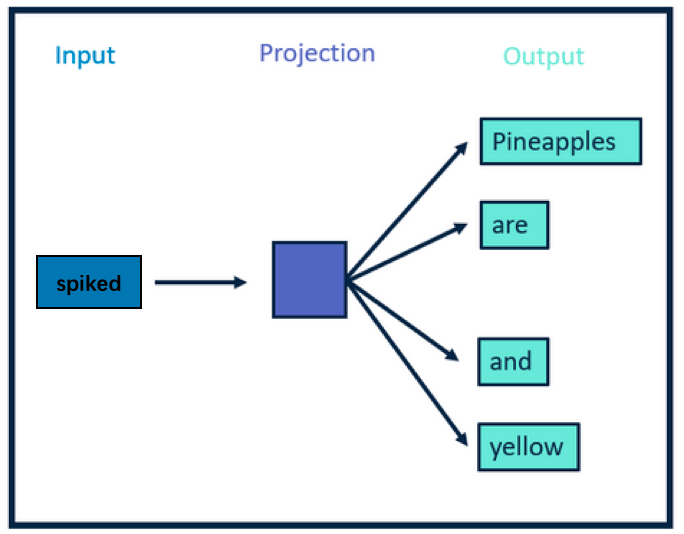
图5 Skip-gram原理图
我们来看看Skip-garm具体是怎么工作的, 首先skip-gram是使用中心词来预测上下文,即利用spiked这个单词来预测 pineapples are and yellow这4个单词,但是训练过程中,这个预测结果很有可能并不是这4个单词,但是没关系,我们会使用这4个单词和预测的单词进行计算损失,通过损失的方式将正确的这4个单词的信息,使用梯度信息反向传播中心词spiked,这样在spiked单词在下次预测的时候,就会更准确一点。
总结一下,在训练过程中通过梯度的方式,将上下文单词的语义传入到了中心词的表示中,即使用了spiked的上下文来训练了spiked的词向量。但是我们来看spiked,和prickly这两个单词,他们的意思都是有刺,多刺的意思,那么真实的文本语料中,他们的上下文大概率也是差不多的,这样通过差不多的上下文去训练这个中心词,那么自然具有相同语义的词的词向量距离会比较近。
3.3 Skip-gram网络结构
前边我们提到,Word2Vec是建模了一个单词预测的任务,通过这个任务来学习词向量。同时呢,Skip-gram是一种以中心词预测上下文的方式进行的,那我们来看看它的网络结构长什么样子,如图6所示。
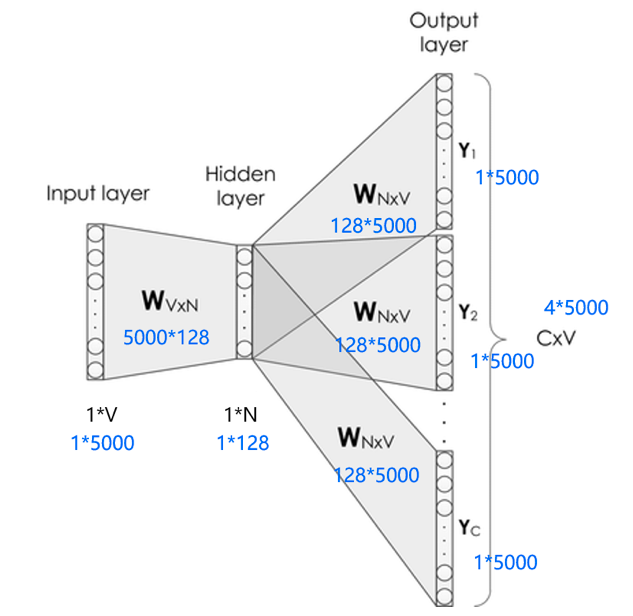
图6 Skip-gram网络结构
Skip-gram的网络结构共包含三层:输入层,隐藏层和输出层。它的处理步骤是这样的:
输入层接收shape为 的one-hot向量 ,其中 代表词表中单词的数量,这个one-hot向量就是上边提到的中心词。
隐藏层包含一个shape为 的参数矩阵 ,其中这个 代表词向量的维度, 就是word embedding 矩阵,即我们要学习的词向量。将输入的one-hot向量 与 相乘,便可得到一个shape为 的向量,即该输入单词对应的词向量 。
输出层包含一个shape为 的参数矩阵 ,将隐藏层输出的 与 相乘,便可以得到shape为 的向量 ,内部的数值分别代表每个候选词的打分,使用softmax函数,对这些打分进行归一化,即得到中心词的预测各个单词的概率。
这是一种比较理想的实现方式,但是这里有两个问题:
这个输入向量是个one-hot编码的方式,只有一个元素为1,其他全是0,是个极其稀疏的向量,假设它第2个位置为1,它和word embedding相乘,便可获得word embedding矩阵的第二行的数据。那么我们知道这个规律,直接通过访存的方式直接获取就可以了,不需要进行矩阵相乘。
在获取了输入单词对应的词向量 后,它是一个 向量。接下来,会使用这个向量和另外一个大的矩阵 进行相乘,最终会获得一个1*V的向量,然后对这个向量进行softmax,可以看到这个向量具有词表的长度,对这么长的向量进行softmax本身也是一个极其消耗资源的事情。
第1个问题解决起来比较简单,我们主要来看第2个问题,那怎么解决呢?直观的想法是我们不要去生成这么多的类别,所以采用了一个负采样的策略,将海量分类转化成了二分类,来缓解这个问题,下我们来看看它具体是怎么做的。
3.4 负采样解决大规模分类问题
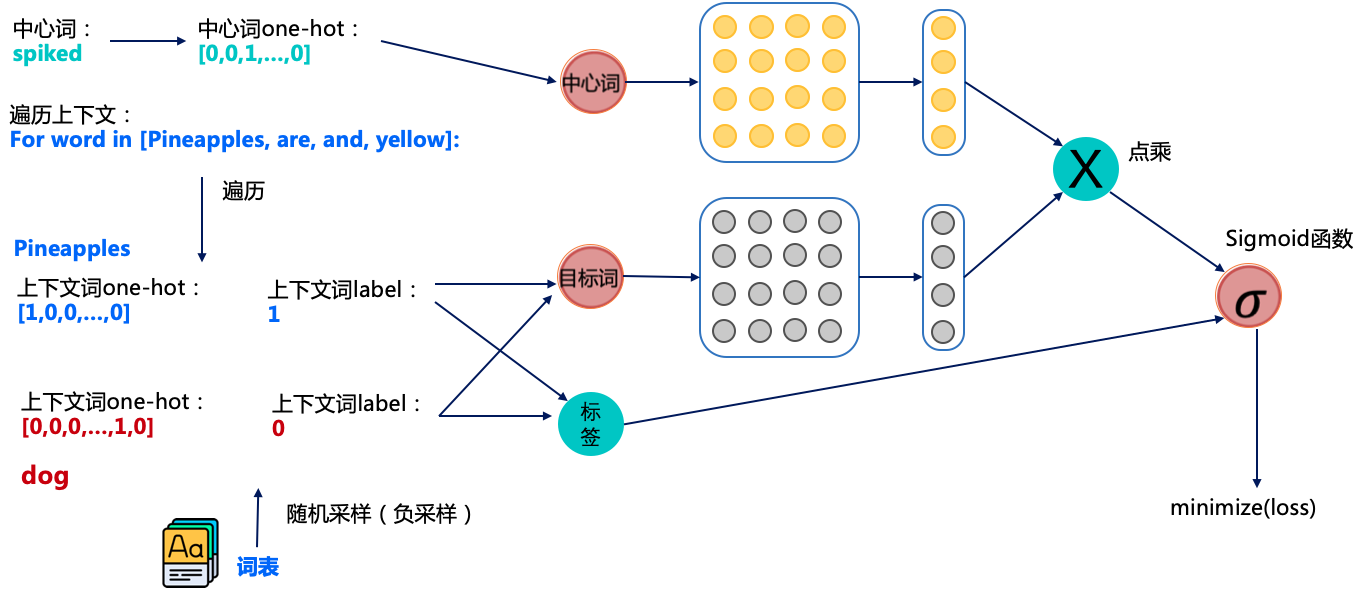
图7 使用负采样策略训练Skip-gram模型
还是以Pineapples are spiked and yellow为例进行讲解,如图7所示,其中中心词是spiked和上下文词是正样本Pineapples are and yellow,这里这个正样本代表该词是中心词的上下文。
以正样本单词Pineapples为例,之前的做法是在使用softmax学习时,需要最大化Pineapples的推理概率,同时最小化其他词表中词的推理概率。之所以计算缓慢,是因为需要对词表中的所有词都计算一遍。然而我们还可以使用另一种方法,就是随机从词表中选择几个代表词,通过最小化这几个代表词的概率,去近似最小化整体的预测概率。
例如,先指定一个中心词(spiked)和一个目标词正样本(Pineapples),再随机在词表中采样几个目标词负样本(如”dog,house”等)。
有了这些正负样本,我们的skip-gram模型就变成了一个二分类任务。对于目标词正样本,我们需要最大化它的预测概率;对于目标词负样本,我们需要最小化它的预测概率。通过这种方式,我们就可以完成计算加速。这个做法就是负采样。
我们再回到图7看一看整体的训练流程是怎么样的。图7中相当于有两个词向量矩阵:黄色的和灰色的,他们的shape都是一样的。整体的流程大概是这样的。
获取中心词spiked的正负样本(正负样本是目标词),这里一般会设定个固定的窗口,比如中心词前后3个词算是中心词的上下文(即正样本);
获取对应词的词向量,其中中心词从黄色的向量矩阵中获取词向量,目标词从灰色的向量矩阵中获取词向量。
将中心词和目标词的词向量进行点积并经过sigmoid函数,我们知道sigmoid是可以用于2分类的函数,通过这种方式来预测中心词和目标词是否具有上下文关系。
将预测的结果和标签使用交叉熵计算损失值,并计算梯度进行反向迭代,优化参数。
经过这个训练的方式,我们就可以训练出我们想要的词向量,但图7中包含两个词向量矩阵(黄色的和灰色的),一般是将中心词对应的词向量矩阵(黄色的)作为正式训练出的词向量。看到这里我想你已经明白Skip-gram大致是如何训练词向量了。
4. 关于词向量的一些有趣应用
前边几节我们提到,对词向量的期望是具有相同语义的词之间的距离比较近,不同语义的词之间的距离比较远。那么在词向量训练完成之后,我们可以基于这个期望去实验一些有趣的应用,也相当于是验证词向量学习的好坏。
4.1 相似度计算
我们可以去挖掘某个单词的同义词,即将一个单词的词向量和其他所有单词词向量进行距离计算,距离最小的那些词就是和该单词语义相近的,例如:
nice: good, great, wonderful
dog: dogs, puppy
4.2词聚类
根据各个单词的词向量,可以执行词聚类的算法,这样可以挖掘出一批语义相近的单词,例如:
Beijing, Washington, Paris, Berlin
slow, slowser, slowest
4.3 词关系推理
这是比较有趣的一个应用,通过词语义上的一些关系来进行推理一些词,例如下面几个例子。
King - Man + Woman = Queen
China - Beijing + Washington = America

- 点赞
- 收藏
- 关注作者
评论(0)