【网络安全】——人工智能安全

目录
本文综合考虑AI技术在模型、数据、承载系统上对安全性的要求,我们用保密性、完整性、鲁棒性、隐私性来定义AI技术的安全模型,并且给出了人工智能安全目前面临的三大威胁:AI模型安全性问题、AI数据与隐私安全性问题,AI系统安全性问题。针对不同的安全威胁,提出了不同防御方法,包括数据投毒攻击、对抗样本攻击、数据隐私威胁。但在实际场景中, AI 系统遇到的威胁往往十分复杂,仅靠单一的防御技术无法有效抵御实际威胁。因此本文总结国内大厂采用的 AI 安全解决方案,然后再从这些方案中提炼出一套涵盖面更广泛的 AI 安全解决方案,主要包括多维对抗和AI SDL。
最后,人工智能应用在实际部署时面临对抗攻击、数据投毒攻击和模型窃取攻击等多种潜在威胁。为了应对实际场景中复杂的威胁以及不断变化的威胁手段, AI 安全研究人员更应从人工智能模型的可解释性等理论角度出发,从根本上解决人工智能模型所面临的安全问题。
一、引言
人工智能技术的崛起依托于三个关键要素:1)深度学习模型在机器学习任务中取得的突破性进展;2)日趋成熟的大数据技术带来的海量数据积累;3)开源学习框架以及计算力提高带来的软硬件基础设施发展。我们在本文中将这三个因素简称为AI模型、AI数据以及AI承载系统。在这三个要素的驱动下,AI技术已经成功应用于生物核身、自动驾驶、图像识别、语音识别等多种场景中,加速了传统行业的智能化变革。随着对这三个因素的探索持续深入,AI技术不仅在多个经典机器学习任务中取得了突破性进展,还广泛应用于真实世界中的各类场景。
为了应对AI技术的安全与隐私泄露威胁,学术界与工业界深入分析攻击原理,并根据不同的攻击原理提出一系列对应的防御技术。这些防御技术覆盖了数据收集、模型训练、模型测试以及系统部署等AI应用的生命周期,充分考虑了每个阶段可能引发的安全与隐私泄露威胁,详细分析了现有攻击方法的原理、攻击实施的过程以及产生的影响,并最终提出对应的防御技术。例如:为了防止攻击者在数据收集阶段污染训练数据并操纵模型训练参数,研究者分析了训练数据毒化对模型产生的影响,随后提出了利用聚类模型激活神经元来区分毒化和干净的数据的防御方法[9];为了防止已经训练好的AI模型被嵌入攻击“后门”,研究者分析了模型中存在“后门”攻击的潜在特征,随后提出了模型剪枝/微调等方法来消除模型中存在的“后门”[10];为了防止攻击者在测试阶段发起的对抗样本攻击,研究者提出使用JPEG压缩、滤波操作、图像模糊处理等方法对输入数据进行预处理,从而降低对抗性扰动带来的影响[11]。此外,为了防止AI模型在训练/测试阶段泄露模型的关键参数,研究者通过对模型结构的适当调整,降低模型过拟合度,从而减少模型泄露的参数信息。尽管上述研究为AI模型提供了有效的防御机制,但会不可避免地降低AI技术在应用中的判断准确率和执行效率。除了从技术层面防范AI安全威胁之外,越来越多的国家和地区推出了数据安全法律法规来保护用户的隐私数据。
综上所述,AI技术所面临的多种安全威胁将会对用户隐私数据造成泄露,并在实际应用场景中对用户的生命与财产带来损失的风险。为了应对AI技术所面临的安全与隐私威胁,本文系统性地总结了学术界与工业界对AI安全与隐私保护技术的相关研究成果。聚焦于AI技术中模型、数据与承载系统的安全问题。我们将首先详细介绍AI模型、数据与承载系统面临的安全威胁,然后逐一介绍针对这些威胁的防御技术,最后提出AI应用的一站式安全解决方案。
二、AI 技术与安全模型
人工智能是一种通过预先设计好的理论模型模拟人类感知、学习和决策过程的技术。完整的AI技术涉及到AI模型、训练模型的数据以及运行模型的计算机系统,AI技术在应用过程中依赖于模型、数据以及承载系统的共同作用。
- AI 模型
- 模型是AI技术的核心,用于实现AI技术的预测、识别等功能,也是 AI 技术不同于其它计算机技术的地方。AI 模型具有数据驱动、自主学习的特点,负责实现机器学习理论和对应算法,能够自动分析输入数据的规律和特征,根据训练反馈自主优化模型参数,最终实现预测输入样本的功能。AI模型通常结合数据挖掘、深度神经网络、数值优化等算法层面的技术来实现其主要功能。以手写数字分类任务为例,AI模型需要判断输入图像是0-9中的哪个数字。为了学习手写数字分类模型,研究者构建训练数据集(例如:MNIST数据集){xi,yi},i=1,2,...,N,其中xi,yi代表某张图像与其对应的数字。模型可以选取卷积神经网络y=fθ(x),其中θ为卷积神经网络的参数。在训练过程中,AI模型使用优化算法不断调整卷积神经网络参数,使模型在训练集上的输出预测结果尽可能接近正确的分类结果。
- AI 数据
- 数据是AI技术的核心驱动力,是AI模型取得出色性能的重要支撑。AI模型需要根据种类多样的训练数据,自动学习数据特征,对模型进行优化调整。海量的高质量数据是AI模型学习数据特征,取得数据内在联系的基本要求和重要保障。尽管AI技术所使用的算法大多在20年前就已经被提出来了,但是直到近些年来,随着互联网的成熟、大规模数据的收集和大数据处理技术的提升才得到了迅猛的发展。大规模数据是AI技术发展的重要支撑,具有以下几个特点:(1)数据体量大,AI模型主要学习知识和经验,而这些知识和经验来源于数据,然而单个数据价值密度较低,大体量的数据有助于模型全面学习隐含的高价值特征和规律;(2)数据多样性强,从各种各样类型的海量数据中,模型可以学习到多样的特征,从而增强模型的鲁棒性与泛化能力。
- AI 承载系统
应用系统是 AI 技术的根基,AI 技术从模型构建到投入使用所需要的全部计算机基础功能都属于这一部分。一般的AI应用部署的流程大致如下:收集应用所需要的大规模数据,使用相关人工智能算法训练模型,将训练完成的模型部署到应用设备上。AI承载系统为AI技术提供重要的运行环境,例如:储存大规模数据需要可靠的数据库技术、训练大型AI模型需要巨大的计算机算力、模型算法的具体实现需要AI软件框架和第三方工具库提供稳定的接口,数据收集与多方信息交互需要成熟稳定的互联网通信技术。目前构建AI应用常使用的主流框架有Tensorflow、PyTorch等,框架高效实现了AI模型运行中所需要的各种操作,例如:卷积、池化以及优化等。这些框架提供了AI技术执行接口供研发人员调用,使其能够通过调用接口快速搭建自定义的AI模型,从而不需要花费太多精力关注底层的实现细节,简化了AI应用的开发难度,使开发人员能够更深入地关注业务逻辑与创新方法。这些优点使得AI技术快速发展,极大地促进了AI应用的落地和普及。
2.1安全技术
学术界与工业界的研究工作表明AI技术在应用过程中存在不可估量的安全威胁,这些威胁可能会导致严重的生命和财产损失。投毒攻击[1]毒害AI模型,使得AI模型的决策过程受攻击者控制;对抗样本攻击[3]导致模型在攻击者的恶意扰动下输出攻击者指定的错误预测;模型窃取攻击[8]导致模型的参数信息泄漏。此外,模型逆向工程[6]、成员推断攻击[12]、后门攻击[13]、伪造攻击[14]以及软件框架漏洞[15]等多种安全威胁都会导致严重的后果。这些潜在的威胁使模型违背了AI安全的基本要求。在本小节中,我们立足于AI技术在应用中面临的威胁,借鉴传统信息安全与网络空间安全的标准规范,讨论适用于AI技术的安全模型。
AI技术的崛起不仅依赖于以深度学习为代表的建模技术的突破,更加依赖于大数据技术与AI开源系统的不断成熟。因此,我们在定义AI安全模型的时候,需要系统性地考虑AI模型、AI数据以及AI承载系统这三者对安全性的要求。在AI模型层面,AI安全性要求模型能够按照开发人员的设计准确、高效地执行,同时保留应用功能的完整性,保持模型输出的准确性,以及面对复杂的应用场景和恶意样本的场景中具有较强鲁棒性;在AI数据层面,要求数据不会被未授权的人员窃取和使用,同时在AI技术的生命周期中产生的信息不会泄露个人隐私数据;在AI承载系统层面,要求承载AI技术的各个组成部分能够满足计算机安全的基本要素,包括物理设备、操作系统、软件框架和计算机网络等。综合考虑AI技术在模型、数据、承载系统上对安全性的要求,我们用保密性、完整性、鲁棒性、隐私性定义AI技术的安全模型,如下:
• 保密性 (Confidentiality)要求AI技术生命周期内所涉及的数据与模型信息不会泄露给未授权用户。
• 完整性 (Integrity) 要求 AI 技术在生命周期中,算法模型、数据、基础设施 和产品不被恶意植入、篡改、替换和伪造。
• 鲁棒性 (Robustness) 要求 AI技术在面对多变复杂的实际应用场景的时候具有较强的稳定性,同时能够抵御复杂的环境条件和非正常的恶意干扰。例如:自动驾驶系统在面对复杂路况时不会产生意外行为,在不同光照和清晰度等环境因素下仍可获得稳定结果。
• 隐私性 (Privacy) 要求AI技术在正常构建使用的过程中,能够保护数据主体的数据隐私。与保密性有所区别的是,隐私性是AI模型需要特别考虑的属性,是指在数据原始信息没有发生直接泄露的情况下,AI模型计算产生的信息不会间接暴露用户数据。
2.2 AI 安全问题分类
我们在本小节讨论AI技术在应用过程中存在的安全威胁的分类方法,并且分析了常见的安全威胁具体违背了安全模型的哪些安全性要求。总体来说,我们根据AI技术涉及的三方面:模型、数据、承载系统,将AI安全威胁分为三个大类别,即AI模型安全、AI数据安全与AI承载系统安全。
•AI模型安全问题
AI模型安全是指AI模型面临的所有安全威胁,包括AI模型在训练与运行阶段遭受到来自攻击者的功能破坏威胁,以及由于AI模型自身鲁棒性欠缺所引起的安全威胁。我们进一步将AI模型安全分为三个子类,分别为:1)训练完整性威胁,攻击者通过对训练数据进行修改,对模型注入隐藏的恶意行为。训练完整性威胁破坏了AI模型的完整性,该威胁主要包括传统投毒攻击和后门攻击;2)测试完整性威胁,攻击者通过对输入的测试样本进行恶意修改,从而达到欺骗AI模型的目的,测试完整性威胁主要为对抗样本攻击;3)鲁棒性欠缺威胁,该问题并非来自于恶意攻击,而是来源于AI模型结构复杂、缺乏可解释性,在面对复杂的现实场景时可能会产生不可预计的输出。上述安全隐患如果解决不当,将很难保证AI模型自身行为的安全可靠,阻碍AI技术在实际应用场景中的推广落地。我们将在3.1小节中具体介绍这些安全威胁。
•AI数据安全问题
数据是AI技术的核心驱动力,主要包括模型的参数数据和训练数据。数据安全问题是指AI技术所使用的训练、测试数据和模型参数数据被攻击者窃取。这些数据是模型拥有者花费大量的时间和财力收集得到的,涉及用户隐私信息,因此具有巨大的价值。一旦这些数据泄露,将会侵犯用户的个人隐私,造成巨大的经济利益损失。针对AI技术使用的数据,攻击者可以通过AI模型构建和使用过程中产生的信息在一定程度上窃取AI模型的数据,主要通过两种方式来进行攻击:1)基于模型的输出结果,模型的输出结果隐含着训练/测试数据的相关属性。以脸部表情识别为例,对于每张查询的输入图片,模型会返回一个结果向量,这个结果向量可能包含关于脸部内容的信息,例如微笑、悲伤、惊讶等不同表情的分类概率,而攻击者则可以利用这些返回的结果信息,构建生成模型,进而恢复原始输入数据,窃取用户隐私[16];2)基于模型训练产生的梯度,该问题主要存在于模型的分布式训练中,多个模型训练方之间交换的模型参数的梯度也可被用于窃取训练数据。

图2.1:AI技术面临的安全威胁与挑战、AI安全常用防御技术以及AI应用系统安全解决方案之间的关系
•AI承载系统安全问题
承载AI技术的应用系统主要包括AI技术使用的基础物理设备和软件架构,是AI模型中数据收集存储、执行算法、上线运行等所有功能的基础。应用系统所面临的安全威胁与传统的计算机安全威胁相似,会导致AI技术出现数据泄露、信息篡改、服务拒绝等安全问题。这些问题可以归纳为两个层面:1)软件框架层面,包含主流的AI算法模型的工程框架、实现AI技术相关算法的开源软件包和第三方库、部署AI软件的操作系统,这些软件可能会存在重大的安全漏洞;2)硬件设施层面,包含数据采集设备、GPU服务器、端侧设备等,某些基础设备缺乏安全防护容易被攻击者侵入和操纵,进而可被利用施展恶意行为。
图2.1详细描述了AI技术面临的安全威胁与挑战、AI安全常用防御技术以及AI应用系统安全解决方案之间的关系,例举了AI技术在应用过程中存在的安全威胁和防御技术的种类。在接下来的章节中,我们会全面介绍目前AI技术所面临的安全挑战,以及在现实场景中可能出现的安全隐患。
三、AI技术面临的三大威胁

3.1AI模型安全性问题
3.2.1模型训练完整性威胁
AI模型的决策与判断能力来源于对海量数据的训练和学习过程。因此,数据是模型训练过程中一个非常重要的部分,模型训练数据的全面性、无偏性、纯净性很大程度上影响了模型判断的准确率。一般来说,一个全面的、无偏的、纯净的大规模训练数据可以使模型很好地拟合数据集中的信息,学习到近似于人类甚至超越人类的决策与判断能力。例如:ImageNet数据集使AI模型在图像分类任务中取得的准确率超越了人类感官判断。但是,如果训练数据受到攻击者的恶意篡改,那么模型将学习到错误的预测能力。例如:在分类模型中,攻击者通过篡改训练数据集中特定样本的标签,导致模型测试阶段针对这些样本输出攻击者指定的标签。这类由数据全面性、无偏性、纯净性引起的安全威胁本质上破坏了模型的训练过程,使模型无法学习到完整的决策、判别能力。因此,在本文中,我们也将这类由数据引起的威胁归为破坏模型训练完整性的威胁。破坏模型训练完整性的攻击主要为数据投毒攻击[1],根据投毒的方法与类型,投毒攻击又可以进一步分为目标固定攻击与后门攻击。接下来,我们将简单介绍投毒攻击、目标固定投毒攻击与后门攻击。
- 数据投毒攻击
数据投毒攻击指攻击者通过在模型的训练集中加入少量精心构造的毒化数据,使模型在测试阶段无法正常使用或协助攻击者在没有破坏模型准确率的情况下入侵模型。前者破坏模型的可用性,为无目标攻击;后者破坏模型的完整性,为有目标攻击。数据投毒攻击最早由Dalvi等人在文献[1]中提出,他们利用该攻击来逃避垃圾邮件分类器的检测。后来,相关研究人员相继在贝叶斯分类器[40]和支持向量机[41]等机器学习模型中实现了数据投毒攻击。破坏完整性的投毒攻击具有很强的隐蔽性:被投毒的模型对干净数据表现出正常的预测能力,只对攻击者选择的目标数据输出错误结果。这种使AI模型在特定数据上输出指定错误结果的攻击会导致巨大的危害,在某些关键的场景中会造成严重的安全事故。因此,我们在本文中对投毒攻击进行了深入的分析探索,希望这部分内容对读者有所启发。根据攻击者在对毒化模型进行测试时是否修改目标数据,可以将这类攻击分为:目标固定攻击和后门攻击。
目标固定攻击是投毒攻击的一种。在这类攻击中,攻击者在模型的正常训练集Dc=(Xc,Yc)中加入精心构造的毒化数据Dp=(Xp,Yp),使得毒化后的模型将攻击者选定的数据xs分类到目标类别yt,而不影响模型在正常测试集的准确率。构造毒化数据Dp的过程可以看作是一个双层优化的问题。其中,外层优化得到毒化数据Xp∗表示如下:
其中Ladv表示攻击者攻击成功的损失,θ∗表示在Xc∪Xp上训练得到的毒化模型,内层优化得到毒化模型θ∗表示如下:

可以看到目标梯度∇XpLadv同时由内外层损失函数决定。由于AI模型的目标函数是非凸化函数,上述的双层优化问题无法直接求解。
- 后门攻击
- 在这类攻击中,攻击者在模型的正常训练集Dc=(Xc, Yc)中加入精心构造的毒化数据集Dp=(Xp, Yp),使得毒化后的模型将加入攻击者选定的后门触发器(Back door Trigger)的数据分类到攻击者的目标类别yt,而不影响模型的正常性能。以图像分类为例,攻击者在测试阶段在原图片xi上添加一个具体的图案或扰动作为后门触发器∆,具体的过程如下所示:
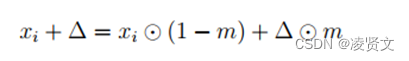
其中, ⊙ 表示元素积, m代表图像掩码。m的大小与xi和∆一致,值为1表示图像像素由对应位置∆的像素取代,而0则表示对应位置的图像像素保持不变。攻击者发动后门攻击的目标可以表示为下式:
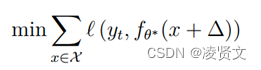
![]()
其中,X表示模型输入空间的所有数据,θ∗表示受害者使用毒化后的数据训练得到的模型参数,训练过程的目标函数如下式所示:

其中,f代表模型结构,θ代表模型参数,ℓ代表损失函数。上式可以看作是多任务学习(Multi-taskLearning)。第一项代表模型在正常任务上的损失函数,这与Dc有关;第二项代表攻击者想要模型额外训练的后门任务上的损失函数,而这取决于Dp。所以后门攻击的关键在于构造合适的Dp,在经过受害者的训练后门任务后,达到目标。
3.2.2模型训练完整性威胁
模型测试阶段是指模型训练完成之后,模型参数被全部固定,模型输入测试样本并输出预测结果的过程。在没有任何干扰的情况下, AI模型的准确率超乎人们的想象,在ImageNet图像分类任务中,识别准确率已经超过了人类。但是,近些年来的研究表明:在模型测试阶段,AI模型容易受到测试样本的欺骗从而输出不可预计的结果,甚至被攻击者操纵。我们将这类威胁AI模型测试阶段正确性的问题定义为测试完整性威胁。对抗攻击与伪造攻击(Adversarial Attack or Evasion Attack) 是破坏模型测试完整性的典型威胁,本章重点关注对抗攻击与伪造攻击。
- 对抗攻击
- 对抗攻击是指利用对抗样本对模型进行欺骗的恶意行为。对抗样本是指在数据集中通过故意添加细微的干扰所形成的恶意输入样本,在不引起人们注意的情况下,可以轻易导致机器学习模型输出错误预测。误判既包括单纯造成模型决策出现错误的无目标攻击,也包括受到攻击者操纵导致定向决策的有目标攻击。对抗攻击最早由Szegedy等人提出,他们在最基本的图像分类任务中,向分类图像的像素中加入微小的扰动,使得分类模型的准确率严重下降,同时对抗样本具有很强的隐蔽性,攻击者做出的修改往往并不会引起人们的察觉。这类威胁来自于AI模型算法本身的缺陷,广泛存在于AI技术应用的各个领域之中,一旦被攻击者利用会造成严重的安全危害。例如:在自动驾驶中,对交通标志的误识别会造成无人汽车做出错误决策引发安全事故。对抗样本的发现严重阻碍着AI技术的广泛应用与发展,尤其是对于安全要求严格的领域。因此,近些年来对抗攻击以及其防御技术吸引了越来越多的目光,成为了研究的一大热点,涌现出大量的学术研究成果。
- 对抗攻击原理与威胁模型
对抗攻击的基本原理就是对正常的样本添加一定的
扰动从而使得模型出现误判。以最基本的图像分类任务为例,攻击者拥有若干数据{xi,yi}Ni=1,其中xi代表数据集中的一个样本也就是一张图像,yi则是其对应的正确类别,N为数据集的样本数量。将用于分类的目标模型表示为f(.),则f(x)表示样本x输入模型得到的分类结果。攻击者应用对抗攻击的方法对正常样本x进行修改得到对应的对抗样本x′,该对抗样本可以造成模型出现误判,同时其与原样本的应该较为接近具有同样的语义信息,一般性定义如下:

其中∥.∥D代表着对抗样本与原样本之间的某种距离度量,为了使修改的样本能够保持语义信息不造成人类的察觉,两者之间的距离应该足够小,同时造成最后模型判断出现错误,分类结果不同于正确类别,而ϵ就是对抗样本与原样本之间设定的最大距离,其取值往往和具体的应用场景有关。
根据攻击意图,对抗攻击可以分为有目标攻击和无目标攻击。以上的一般定义属于无目标攻击,即经过修改的样本只要造成错误使得分类标签与原标签不同即可;有目标攻击是指攻击者根据需要对样本进行修改,使得模型的分类结果变为指定的类别t,定义如下:
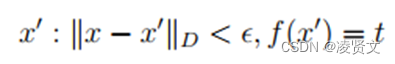
根据攻击者所能获取的信息,对抗攻击可以分为黑盒攻击和白盒攻击。黑盒攻击是指攻击者在不知道目标模型的结构或者参数的情况下进行攻击,但是攻击者可以向模型查询特定的输入并获取预测结果;白盒攻击是指攻击者可以获取目标模型fθ(.)的全部信息,其中θ代表模型的具体参数,用于实施有针对性的攻击算法。一般情况下,由于白盒攻击能够获取更多与模型有关的信息,其攻击性能要明显强于对应的黑盒攻击。以上我们对攻击的主要目标与攻击设置进行了简要的介绍,在不同设置下各种攻击具有不同的特点,主流的攻击技术可以分为基于扰动的对抗攻击和非限制对抗攻击。
- 基于扰动的对抗攻击
最初的对抗攻击算法主要是基于扰动的对抗攻击,这类攻击在图像分类任务上被广泛研究,也是最主要的攻击类型。这类攻击的主要思想就是在输入样本中加入微小的扰动,从而导致AI模型输出误判。以图像分类任务为例,攻击者可以对输入图像的像素添加轻微扰动,使对抗样本在人类看来是一幅带有噪声的图像。考虑到攻击的隐蔽性,攻击者会对这些扰动的大小进行限制从而避免人类的察觉。已有的研究通常基于扰动的范数大小ℓp度量样本之间距离

其中xi、x′i分别指正常样本和对抗样本在第i处的特征,在图像任务中为对应位置的像素值。目前对抗攻击算法的主要思想是将生成对抗样本的过程看做一个优化问题的求解。接下来我们首先介绍几种白盒对抗攻击算法,之后介绍一些针对防御技术的攻击增强算法,最后给出几种针对黑盒模型的攻击方法。
- 伪造攻击
伪造攻击是向生物识别系统提交伪造信息以通过身份验证的一种攻击方式[32],是一种AI测试完整性威胁。生物验证技术包括指纹核身、面容核身、声纹核身、眼纹核身、掌纹核身等等。以声纹核身为例,攻击者有很多种方法来进行伪造攻击声纹识别系统、声纹支付系统、声纹解锁系统等。例如:攻击者对声纹解锁系统播放一段事先录制或者人工合成的解锁音频通过验证。在这类音频伪造攻击中,攻击者可以通过手机等数码设备直接录制目标人物的解锁音频,也可以通过社交网络检索目标账号获取解锁音频。甚至,攻击者可以从目标人物的多个音频中裁剪合成解锁音频,或者通过深度语音合成技术来合成目标人物的解锁音频。
3.2 AI数据与隐私安全性问题
由于AI技术使用过程中产生的模型梯度更新、输出特征向量以及预测结果与输入数据、模型结构息息相关,因此AI模型产生的计算信息面临着潜在的隐私数据泄露、模型参数泄露风险。
3.2.1 基于模型输出的数据泄露
在AI模型测试阶段,AI模型参数被固定住,测试数据输入模型并输出特征向量、预测结果等信息。例如:在图像分类任务中,模型的输出包含卷积层输出的特征向量、Softmax层输出的预测概率向量等。近些年来研究结果表明,模型的输出结果会隐含一定的数据信息。攻击者可以利用模型输出在一定程度上窃取相关数据,主要可以窃取两类数据信息:1)模型自身的参数数据;2)训练/测试数据。
- 模型窃取
模型窃取攻击(ModelExtractionAttack)是一类隐私数据窃取攻击,攻击者通过向黑盒模型进行查询获取相应结果,窃取黑盒模型的参数或者对应功能。被窃取的模型往往是拥有者花费大量的金钱时间构建而成的,对拥有者来说具有巨大的商业价值。一旦模型的信息遭到泄露,攻击者就能逃避付费或者开辟第三方服务,从而获取商业利益,使模型拥有者的权益受到损害。如果模型遭到窃取,攻击者可以进一步部署白盒对抗攻击来欺骗在线模型,这时模型的泄露会大大增加攻击的成功率,造成严重的安全风险。
目前,大多数AI技术供应商将AI应用部署于云端服务器,通过API来为客户端提供付费查询服务。客户仅能通过定义好的API向模型输入查询样本,并获取模型对样本的预测结果。然而即使攻击者仅能通过API接口输入请求数据,获取输出的预测结果,也能在一定情况下通过查询接口来窃取服务端的模型结构和参数。模型窃取攻击主要可以分为三类:1)Equation-solvingAttack;2)基于Meta-model的模型窃取;3)基于替代模型的模型窃取。
Equation-solving Attack是一类主要针对支持向量机(SVM)等传统的机器学习 方法的模型窃取攻击。攻击者可以先获取模型的算法、结构等相关信息,然后构建公 式方程来根据查询返回结果求解模型参数 [7]。在此基础之上还可以窃取传统算法中 的超参数,例如:损失函数中 loss 项和 regularization 项的权重参数 [73]、KNN 中 的 K 值等。Equation-solving Attack 需要攻击者了解目标算法的类型、结构、训练 数据集等信息,无法应用于复杂的神经网络模型。
基于 Meta-model 模型窃取的主要思想是通过训练一个额外的 Meta Model Φ(·)来预测目标模型的指定属性信息。Meta Model 的输入样本是所预测模型在任务数据 x 上的输出结果 f (x),输出的内容 Φ(f (x)) 则是预测目标模型的相关属性,例如网 络层数、激活函数类型等。因此为了训练 Meta Model,攻击者需要自行收集与目标 模型具有相同功能的多种模型 fi(·),获取它们在相应数据集上的输出,构建 Meta Model 的训练集。然而构建 Meta Model 的训练集需要多样的任务相关模型,对计算资源的要求过高,因此该类攻击并不是非常实用,而作者也仅在 MNIST 数字识别任务上做了实验 [34]。
基于替代模型训练的是目前比较实用的一类模型窃取攻击。攻击者在未知目标 模型结构的情况下向目标模型查询样本,得到目标模型的预测结果,并以这些预测 结果对查询数据进行标注构建训练数据集,在本地训练一个与目标模型任务相同的替代模型,当经过大量训练之后,该模型就具有和目标模型相近的性质。一般来说,攻击者会选取 VGG、ResNet 等具有较强的拟合性的深度学习模型作为替代模型结 构 [35]。基于替代模型的窃取攻击与 Equation-solving Attack 的区别在于,攻击者对 于目标模型的具体结构并不了解,训练替代模型也不是为了获取目标模型的具体参数,而只是利用替代模型去拟合目标模型的功能。为了拟合目标模型的功能,替代 模型需要向目标模型查询大量的样本来构建训练数据集,然而攻击者往往缺少充足 的相关数据,并且异常的大量查询不仅会增加窃取成本,更有可能会被模型拥有者 检测出来。为了解决上述问题,避免过多地向目标模型查询,使训练过程更为高效, 研究者提出对查询的数据集进行数据增强,使得这些数据样本能够更好地捕捉目标 模型的特点[8],例如:利用替代模型生成相应的对抗样本以扩充训练集,研究认为对抗样本往往会位于模型的决策边界上,这使得替代模型能够更好地模拟目标模型的决策行为 [54, 74]。除了进行数据增强,还有研究表明使用与目标模型任务无关的 其它数据构建数据集也可以取得可观的攻击效果,这些工作同时给出了任务相关数 据与无关数据的选取组合策略 [75, 35]。
- 隐私泄露
机器学习模型的预测结果往往包含了模型对于该样本的诸多推理信息。在不同 的学习任务中,这些预测结果往往包含了不同的含义。例如:图像分类任务中,模型 输出的是一个向量,其中每一个向量分量表示测试样本为该种类的概率。最近的研究 结果证明,这些黑盒的输出结果可以用来窃取模型训练数据的信息。例如:Fredrikson 等人提出的模型逆向攻击(Model Inversion Attack)[6] 可以利用黑盒模型输出中的 置信度向量等信息将训练集中的数据恢复出来。他们针对常用的面部识别模型,包括 Softmax 回归,多层感知机和自编码器网络实施模型逆向攻击。他们认为模型输 出的置信度向量包含了输入数据的信息,也可以作为输入数据恢复攻击的衡量标准。 他们将模型逆向攻击问题转变为一个优化问题,优化目标为使得逆向数据的输出向 量与目标输出向量差异尽可能地小,也就是说,假如攻击者获得了属于某一类别的 输出向量,那么他可以利用梯度下降的方法使得逆向的数据经过目标模型的推断后, 仍然能得到同样的输出向量。
成员推断攻击 (Membership-Inference Attack) 是一种更加容易实现的攻击 类型,它是指攻击者将试图推断某个待测样本是否存在于目标模型的训练数据集中,从而获得待测样本的成员关系信息。比如攻击者希望知道某个人的数据是否存在于某个公司的医疗诊断模型的训练数据集中,如果存在,那么我们可以推断出该个体 的隐私信息。我们将目标模型训练集中的数据称为成员数据 (Member Data),而不在训练集中的数据称为非成员数据 (Non-member Data)。同时由于攻击者往往不可能掌握目标模型,因此攻击者只能实施黑盒场景下的成员推断攻击。成员推断攻击是近两年来新兴的一个研究课题,这种攻击可以用于医疗诊断、基因测试等应用场 景,对用户的隐私数据提出了挑战,同时关于这种攻击技术的深入发展及其相关防 御技术的探讨也成为了一个新的研究热点。
3.2.2 基于梯度更新的数据泄露
梯度更新是指模型对参数进行优化时,模型参数会根据计算产生的梯度来进行更新,也就是训练中不断产生的梯度信息。梯度更新的交换往往只出现在分布式模 型训练中,拥有不同私有数据的多方主体每一轮仅使用自己的数据来更新模型,随 后对模型参数的更新进行聚合,分布式地完成统一模型的训练,在这个过程中,中 心服务器和每个参与主体都不会获得其它主体的数据信息。然而即便是在原始数据 获得良好保护的情况下,参与主体的私有数据仍存在泄漏的可能性。
模型梯度更新会导致隐私泄露. 尽管模型在训练的过程中已经使用了很多方法 在防止原始数据泄露,在多方分布式的 AI 模型训练中,个体往往会使用自己的数据 对当前的模型进行训练,并将模型的参数更新传递给其它个体或者中心服务器。在最 近机器学习和信息安全的国际会议上,研究人员提出了一些利用模型参数更新来获 取他人训练数据信息的攻击研究。Melis 等人 [36] 利用训练过程中其它用户更新的模 型参数作为输入特征,训练攻击模型,用于推测其它用户数据集的相关属性;[37, 38] 等人利用对抗生成网络生成恢复其它用户的训练数据,在多方协作训练过程中,利 用公共模型作为判别器,将模型参数更新作为输入数据训练生成器,最终可以获取 受害者特定类别的训练数据。在最近的一项工作中 [39],研究人员并未使用 GAN 等 生成模型,而是基于优化算法对模拟图片的像素进行调整,使得其在公共模型上反 向传播得到的梯度和真实梯度相近,经过多轮的优化模拟图片会慢慢接近真实的训 练数据。
3.3 AI系统安全性问题
AI 系统安全性问题与传统计算机安全领域中的安全问题相似,威胁着 AI 技术 的保密性、完整性和可用性。AI 系统安全问题主要分为两类:1) 硬件设备安全问题, 主要指数据采集存储、信息处理、应用运行相关的计算机硬件设备被攻击者攻击破 解,例如芯片、存储媒介等;2) 系统与软件安全问题,主要指承载 AI 技术的各类计算机软件中存在的漏洞和缺陷,例如:承载技术的操作系统、软件框架和第三方库 等。
3.3.1 硬件设备安全问题
硬件设备安全问题指 AI 技术当中使用的基础物理设备被恶意攻击导致的安全 问题。物理设备是 AI 技术构建的基础,包含了中心计算设备、数据采集设备等基础 设施。攻击者一旦能够直接接触相应的硬件设备,就能够伪造和窃取数据,破坏整 个系统的完整性。例如:劫持数据采集设备,攻击者可以通过 root 等方式取得手机 摄像头的控制权限,当手机应用调用摄像头的时候,攻击者可以直接将虚假的图片 或视频注入相关应用,此时手机应用采集到的并不是真实的画面,使人工智能系统 被欺骗;侧信道攻击,指的是针对加密电子设备在运行过程中的时间消耗、功率消 耗或电磁辐射之类的侧信道信息泄露而对加密设备进行攻击的方法,这种攻击可以 被用来窃取运行在服务器上的 AI 模型信息 [54]。
3.3.2 系统与软件安全问题
系统与软件安全问题是指承载 AI 应用的各类系统软件漏洞导致的安全问题。AI 技术从算法到实现是存在距离的,在算法层面上开发人员更关注如何提升模型本身 性能和鲁棒性。然而强健的算法不代表着 AI 应用安全无虞,在 AI 应用过程中同样 会面临软件层面的安全漏洞威胁,如果忽略了这些漏洞,则可能会导致关键数据篡 改、模型误判、系统崩溃或被劫持控制流等严重后果。
以机器学习框架为例,开发人员可以通过 Tensorflow、PyTorch 等机器学习软 件框架直接构建 AI 模型,并使用相应的接口对模型进行各种操作,无需关心 AI 模 型的实现细节。然而不能忽略的是,机器学习框架掩盖了 AI 技术实现的底层复杂 结构,机器学习框架是建立在众多的基础库和组件之上的,例如 Tensorflow、Caffe、 PyTorch 等框需要依赖 Numpy、libopencv、librosa 等数十个第三方动态库或 Python 模块。这些组件之间存在着复杂的依赖关系。框架中任意一个依赖组件存在的安全 漏洞,都会威胁到整个框架以及其所支撑的应用系统。
研究表明在这些深度学习框架及其依赖库中存在的软件漏洞几乎包含了所有常 见的类型,如堆溢出、释放对象后引用、内存访问越界、整数溢出、除零异常等漏洞, 这些潜在的危害会导致深度学习应用受到拒绝服务、控制流劫持、数据篡改等恶意 攻击的影响 [15]。例如:360 Team SeriOus 团队曾发现由于 Numpy 库中某个模块没 有对输入进行严格检查,特定的输入样本会导致程序对空列表的使用,最后令程序 陷入无限循环,引起拒绝服务的问题。而在使用 Caffe 依赖的 libjasper 视觉库进行 图像识别处理时,某些畸形的图片输入可能会引起内存越界,并导致程序崩溃或者 关键数据(如参数、标签等)篡改等问题 [82]。另外,由于 GPU 设备缺乏安全保护 措施,拷贝数据到显存和 GPU 上的运算均不做越界检查,使用的显存在运行结束后 仍然存在,这都需要用户手动处理,如果程序中缺乏相关处理的措施,则可能存在 内存溢出的风险 [83]。
四、AI 威胁常用防御技术
系统性地总结了 AI 模型、AI 数据以及 AI 承载系统面临的威 胁。AI 模型面临的威胁包括:训练阶段的投毒与后门攻击、测试阶段的对抗攻击以 及 AI 模型本身存在的鲁棒性缺失问题;AI 数据面临的威胁包括:利用模型查询结 果的模型逆向攻击、成员推断攻击和模型窃取攻击,以及在训练阶段利用模型参数 更新进行的训练数据窃取攻击;AI 承载系统面临的威胁包括:软件漏洞威胁和硬件 设备安全问题等。
AI 模型训练阶段主要存在的威胁是数据投毒攻击,它可以非常隐蔽地破坏模型 的完整性。近些年来,研究者们提出了多种针对数据投毒攻击的防御方法。由于传统 意义上的有目标的数据投毒攻击可以看作是后门攻击的一种特殊情况,因此后续章 节将主要阐述针对后门攻击的防御方法。根据防御技术的部署场景,这些方法可以 分为两类,分别是面向训练数据的防御和面向模型的防御。面向训练数据的防御部 署在模型训练数据集上,适用于训练数据的来源不被信任的场景;面向模型的防御 主要应用于检测预训练模型是否被毒化,若被毒化则尝试修复模型中被毒化的部分, 这适用于模型中可能已经存在投毒攻击的场景。
AI 模型在预测阶段主要存在的威胁为对抗样本攻击。近些年来,研究者们提出 了多种对抗样本防御技术,这些技术被称为对抗防御 (Adversarial Defense)。对抗防 御可以分为启发式防御和可证明式防御两类。启发式防御算法对一些特定的对抗攻 击具有良好的防御性能,但其防御性能没有理论性的保障,意味着启发式防御技术 在未来很有可能被击破。可证明式防御通过理论证明,计算出特定对抗攻击下模型 的最低准确度,即在理论上保证模型面对攻击时性能的下界。但目前的可证明式防 御方法很难在大规模数据集上应用,我们将其作为模型安全性测试的一部分放在之 后的章节阐述。本节主要阐述部分具有代表性的启发式防御技术,根据防御算法的 作用目标不同分为三类:分别是对抗训练、输入预处理以及特异性防御算法。对抗训 练通过将对抗样本纳入训练阶段来提高深度学习网络主动防御对抗样本的能力;输 入预处理技术通过对输入数据进行恰当的预处理,消除输入数据中可能的对抗性扰 动,从而达到净化输入数据的功能;其他特异性防御算法通过修改现有的网络结构 或算法来达到防御对抗攻击的目的。
除了训练与预测阶段存在的威胁,AI 模型还存在鲁棒性缺乏风险。鲁棒性缺乏 是指模型在面对多变的真实场景时泛化能力有限,导致模型产生不可预测的误判行 为。为了增强 AI 模型的鲁棒性,提高模型的泛化能力,增强现实场景下模型应对多 变环境因素时模型的稳定性,研究人员提出了数据增强和可解释性增强技术:数据 增强技术的目标是加强数据的收集力度并增强训练数据中环境因素的多样性,使模 型能够尽可能多地学习到各种真实场景下的样本特征,进而增强模型对多变环境的 适应性;可解释性增强技术的目标是解释模型是如何进行决策的以及为何模型能够 拥有较好的性能。若能较好地解答上述问题,将有助于在 AI 模型构建过程中依据可 解释性的指导,有针对性地对模型进行调整,从而增强其泛化能力。
表 4.1: 防御方法概括
威胁类型 |
防御种类 |
防御方法 |
针对具体攻击 |
频谱分析法 |
标签翻转攻击 |
||
面向训练数据的防御 |
激活值聚类法 |
标签翻转攻击 |
|
强扰动输入 |
常规后门攻击 |
||
数据投毒威胁 |
网络裁剪法 |
常规后门攻击 |
|
面向模型防御 |
后门逆向法 模式连通法 |
基于图案触发器的攻击 常规后门攻击 |
|
ULP |
常规后门攻击 |
||
FGSM 对抗训练 |
FGSM 对抗攻击 |
||
PGD 对抗训练 |
常规对抗攻击 |
||
对抗训练 |
集成对抗训练 |
黑盒对抗攻击 |
|
Logits 对抗训练 |
常规对抗攻击 |
||
对抗样本威胁 |
生成对抗训练 |
常规对抗攻击 |
|
输入预处理防御 |
输入变换法 输入清理法 |
灰盒、黑盒攻击 灰盒、黑盒攻击 |
|
防御性蒸馏法 |
FGSM 对抗攻击 |
||
特异性防御算法 |
特征剪枝法 |
黑盒攻击与常规攻击 |
|
随机算法 |
黑盒攻击与常规攻击 |
||
模型结构防御 |
模型泛化法 目标优化法 |
模型窃取、成员推断攻击 成员推断攻击 |
|
截断混淆法 |
模型窃取、成员推断攻击 |
||
数据隐私威胁 |
信息混淆防御 |
噪声混淆法 |
成员推断攻击 |
查询控制防御 |
样本特征检测法 用户行为检测法 |
模型窃取、成员推断攻击 成员推断攻击 |
五、AI 应用系统一站式安全解决方案
AI 技术已经是许多业务系统的核心驱动力,如苹果 Siri、微软小冰都依赖智能 语音识别模型,谷歌照片利用图像识别技术快速识别图像中的人、动物、风景和地 点。然而正如《人工智能安全》[149] 一书中提到,新技术必然会带来新的安全问题, 一方面是其自身的脆弱性会导致新技术系统不稳定或者不安全的情况,这是新技术 的内在安全问题,一方面是新技术会给其他领域带来新的问题,导致其他领域不安 全,这是新技术的衍生安全问题。近年来学术界和工业界针对 AI 应用系统的攻击案例此起彼伏,例如腾讯攻破了特斯拉的自动驾驶系统、百度攻破了公有云上的图像 识别系统、Facebook 和 Google 掀起了反 DeepFake 浪潮。
本文第 3 章介绍了 AI 系统是可能面临的包括对抗样本攻击、投毒攻击和供 应链攻击等各类威胁,同时本文第 4 章也给出了面向各类 AI 威胁的防御技术。但在实际场景中,AI系统遇到的威胁往往十分复杂,仅靠单一的防御技术无法有效抵御实际威胁。因此在本章节,我们先回顾国内外大厂采用的AI安全解决方案,然后再从这些方案中提炼出一套涵盖面更广泛的AI安全解决方案。
5.1 行业介绍
•百度. 百度是国内最早研究 AI模型安全性问题的公司之一。当前百度建立了一套可衡量深度神经网络在物理世界中鲁棒性的标准化框架。事实上,物理世界中使用的模型往往与人们的衣食住行相关(如无人自动驾驶、医疗自动诊断等),这些模型一旦出现问题,后果将非常严重。因此,该框架首先基于现实世界的正常扰动定义了可能出现威胁的五大安全属性,分别是光照、空间变换、模糊、噪声和天气变化;然后,针对不同的模型任务场景,制定不同的评估标准,如非定向分类错误、目标类别错误分类到评估者设定的类别等标准;最后,对于不同安全属性扰动带来的威胁,该框架采用了图像领域中广为接受的最小扰动的Lp范数来量化威胁严重性以及模型鲁棒性。
• 腾讯. 腾讯公司针对AI落地过程中面临的各类安全问题进行了细致的划分,具体分为AI软硬件安全、AI算法安全、模型安全、AI数据安全和数据隐私等部分。软硬件安全主要是考虑到部署AI模型的软件和硬件层面可能存在的安全漏洞,如内存溢出、摄像头劫持等问题;AI算法安全主要考虑深度学习存在对抗样本的问题,容易出现错误的预测结果;模型本身的安全则涉及到模型窃取,这一问题目前实现方式比较多,常见的方法是直接物理接触下载模型并逆向获取模型参数,以及通过多次查询来拟合“影子”模型实现等价窃取;此外,模型的训练数据也会被污染,开源的预训练模型可能被恶意埋入后门,这些问题都被划分为AI模型的数据安全问题;当然,模型训练使用的数据集也会涉及用户的隐私,因此攻击者可能也会通过查询获取用户隐私。为了缓解这些问题,腾讯安全团队借助AI能力,针对性地构建了多种攻击检测技术。
• 华为. 华为公司同样对AI安全问题展开了深入的研究,其将AI系统面临的挑战分为5个部分,包括软硬件的安全、数据完整性、模型保密性、模型鲁棒性和数据隐私。其中,软硬件的安全涉及应用、模型、平台、芯片和编码中可能存在的漏洞或后门;数据完整性主要涉及各类数据投毒攻击;模型保密性则主要涉及到模型的窃取问题;模型鲁棒性考虑训练模型时的样本往往覆盖性不足,使得模型鲁棒性不强,同时模型面对恶意对抗样本攻击时,无法给出正确的判断结果等问题;数据隐私考虑在用户提供训练数据的场景下,攻击者能够通过反复查询训练好的模型获得用户的隐私信息。
为了应对这些挑战,华为主要考虑三个层次的防御手段:攻防安全、模型安全和架构安全。其中,攻防安全考虑针对已知的攻击手段,设计针对性的防御机制来保护AI系统,经典的防御技术包括对抗训练、知识蒸馏、对抗样本检测、训练数据过滤、集成模型、模型剪枝等。而针对模型本身存在的安全问题,考虑包括模型可检测性、可验证性和可解释性等技术,以提升模型应对未知攻击的能力。在业务中实际使用AI模型,需要结合业务自身特点,分析判断AI模型架构安全,综合利用隔离、检测、熔断和冗余等安全机制设计AI安全架构与部署方案,增强业务产品、业务流程与业务功能的健壮性。
• RealAI. RealAI是一家专注于从根本上增强AI的可靠性、可信性以及安全性的创业公司。该公司通过黑盒和白盒方式,对目标模型进行对抗样本攻击,并通过检测器和去噪器等方式构建模型的AI防火墙;此外,它们也考虑了模型窃取和后门检测等问题。
5.2 多维对抗与AI SDL
AI系统的防御与攻击者的攻击是一个不断演变的攻防对抗过程,攻击者会不断更新攻击手法来突破AI系统的防御。例如以黑产为代表的攻击者,会不断探测AI系统的漏洞,开发新的攻击工具,降低攻击成本来突破AI系统,获得高额的经济收益。
在实际场景中,我们需要从多个视角切入来应对与攻击者之间日益焦灼的对抗战役。一个非常有效的战略就是知己知彼,知彼就是从防御的视角切入,时时刻刻跟踪对手的动向,部署策略模型对各类攻击行为进行监测,对于这类技术我们称之为多维对抗技术,知己就是从评测的视角切入,实时检测AI系统中的漏洞并进行修补,降低攻击面、风险面,对于这类技术我们称之为AI模型安全开发生命周(AISDL),这也是借鉴应用安全领域的SDL理念。
- 多维对抗
- 多维对抗的核心理念就是把攻防链路进行切面(深度数据化),再充分融合机器智能和专家智能,结合威胁情报,化被动防御为主动攻防,在对手还在尝试阶段就能够发现异常行为,再通过置信度排序和团伙挖掘等进行审理定性、处置,是一个系统化的防御体系。
- AI模型安全开发生命周期(AI SDL)
AI SDL是从安全角度指导AI模型开发过程的管理模式。AI SDL是一个安全保证的过程,它在AI模型开发的所有阶段都引入了安全和隐私的原则。具体来说,AI模型的生命周期包括模型设计、数据与预训练模型准备、模型开发与训练、模型验证与测试、模型部署与上线、模型性能监控、模型下线这七个流程。AI SDL通过安全指导这7个模型开发流程,保障模型在其全生命周期中的安全性。
六、总结与展望
人工智能技术已广泛应用于生物核身、自动驾驶、语音识别、自然语言处理和博弈等多种场景。人工智能技术在加速传统行业的智能化变革的同时,其安全性问题也越来越被人们关注。聚焦于人工智能安全问题,本文从AI模型、AI数据和AI承载系统三个角度系统地总结了人工智能技术所面临的威胁,介绍了面对这些威胁的防御手段,并面向工业界给出了安全的人工智能应用一站式解决方案。
人工智能应用在实际部署时面临对抗攻击、数据投毒攻击和模型窃取攻击等多种潜在威胁。在实际应用场景中,多种AI攻击同时存在,我们很难用单一的防御技术来应对现实场景中复杂的威胁。此外,在人工智能的攻防对抗过程中防御是更困难的一方,攻击者可以不断更新攻击技术来突破目前最有效的防御系统,然而新的防御系统却需要考虑现存的所有攻击技术。为了应对实际场景中复杂的威胁以及不断变化的威胁手段,AI安全研究人员更应从人工智能模型的可解释性等理论角度出发,从根本上解决人工智能模型所面临的安全问题。一方面,研究人员在模型的训练阶段可以通过选取或设计本身具有可解释性的模型,为模型增强泛化能力和鲁棒性;另一方面,研究人员要尝试解释模型的工作原理,即在不改变模型本身的情况下探索模型是如何根据输入样本进行决策的。
参考文献
[1] Nilesh N. Dalvi, Pedro M. Domingos, Mausam, Sumit K. Sanghai, and Deepak Verma. Adversarial classification. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, Washington, USA, August 22-25, 2004, pages 99–108, 2004.
[2] Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Iden- tifying vulnerabilities in the machine learning model supply chain. CoRR, abs/1708.06733, 2017.
[3] Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Er- han, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199, 2013.
[4] Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. Robust physical-world attacks on deep learning visual classification. In 2018 IEEE Con- ference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, pages 1625–1634. IEEE Computer Society, 2018.
[5] Tencent Keen Security Lab. Experimental security research of tesla autopi- lot, 2019. https://keenlab.tencent.com/en/2019/03/29/Tencent-Keen-S ecurity-Lab-Experimental-Security-Research-of-Tesla-Autopilot/.
[6] Matt Fredrikson, Somesh Jha, and Thomas Ristenpart. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, October 12-16, 2015, pages 1322–1333. ACM, 2015.
[7] Florian Tramèr, Fan Zhang, Ari Juels, Michael K. Reiter, and Thomas Risten- part. Stealing machine learning models via prediction apis. In 25th USENIXSecurity Symposium, USENIX Security 16, Austin, TX, USA, August 10-12, 2016, pages 601–618. USENIX Association, 2016.
[8] Nicolas Papernot, Patrick D. McDaniel, Ian J. Goodfellow, Somesh Jha,
Z. Berkay Celik, and Ananthram Swami. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, AsiaCCS 2017, Abu Dhabi, United Arab Emirates, April 2-6, 2017, pages 506–519. ACM, 2017.
[9] Bryant Chen, Wilka Carvalho, Nathalie Baracaldo, Heiko Ludwig, Benjamin Edwards, Taesung Lee, Ian Molloy, and Biplav Srivastava. Detecting backdoor attacks on deep neural networks by activation clustering. In Workshop on Arti- ficial Intelligence Safety 2019 co-located with the Thirty-Third AAAI Conference on Artificial Intelligence 2019 (AAAI-19), Honolulu, Hawaii, January 27, 2019, volume 2301 of CEUR Workshop Proceedings. CEUR-WS.org, 2019.
[10] Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. Fine-pruning: Defend- ing against backdooring attacks on deep neural networks. In Research in Attacks, Intrusions, and Defenses - 21st International Symposium, RAID 2018, Herak- lion, Crete, Greece, September 10-12, 2018, Proceedings, volume 11050 of Lecture Notes in Computer Science, pages 273–294. Springer, 2018.
[11] Cihang Xie, Jianyu Wang, Zhishuai Zhang, Zhou Ren, and Alan L. Yuille. Mit- igating adversarial effects through randomization. In 6th International Confer- ence on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018.
[12] Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Member- ship inference attacks against machine learning models. In 2017 IEEE Sympo- sium on Security and Privacy, SP 2017, San Jose, CA, USA, May 22-26, 2017, pages 3–18. IEEE Computer Society, 2017.
[13] Yuanshun Yao, Huiying Li, Haitao Zheng, and Ben Y. Zhao. Latent backdoor attacks on deep neural networks. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, CCS 2019, London, UK, November 11-15, 2019, pages 2041–2055, 2019.
[14] Mahmood Sharif, Sruti Bhagavatula, Lujo Bauer, and Michael K. Reiter. Acces- sorize to a crime: Real and stealthy attacks on state-of-the-art face recognition.In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Com- munications Security, Vienna, Austria, October 24-28, 2016, pages 1528–1540.
ACM, 2016.
[15] Qixue Xiao, Kang Li, Deyue Zhang, and Weilin Xu. Security risks in deep learning implementations. In 2018 IEEE Security and Privacy Workshops, SP Workshops 2018, San Francisco, CA, USA, May 24, 2018, pages 123–128. IEEE
Computer Society, 2018.
[16] Ziqi Yang, Jiyi Zhang, Ee-Chien Chang, and Zhenkai Liang. Neural network in- version in adversarial setting via background knowledge alignment. In Lorenzo Cavallaro, Johannes Kinder, XiaoFeng Wang, and Jonathan Katz, editors, Pro- ceedings of the 2019 ACM SIGSAC Conference on Computer and Communica- tions Security, CCS 2019, London, UK, November 11-15, 2019, pages 225–240.
ACM, 2019.
[17] Luis Muñoz-González, Battista Biggio, Ambra Demontis, Andrea Paudice, Vasin Wongrassamee, Emil C. Lupu, and Fabio Roli. Towards poisoning of deep learn- ing algorithms with back-gradient optimization. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, AISec@CCS 2017, Dallas, TX, USA, November 3, 2017, pages 27–38, 2017.
[18] Ali Shafahi, W. Ronny Huang, Mahyar Najibi, Octavian Suciu, Christoph Studer, Tudor Dumitras, and Tom Goldstein. Poison frogs! targeted clean- label poisoning attacks on neural networks. In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, 3-8 December 2018, Montréal, Canada, pages
6106–6116, 2018.
[19] Chen Zhu, W. Ronny Huang, Hengduo Li, Gavin Taylor, Christoph Studer, and Tom Goldstein. Transferable clean-label poisoning attacks on deep neural nets. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, pages 7614–7623, 2019.
[20] Yingqi Liu, Shiqing Ma, Yousra Aafer, Wen-Chuan Lee, Juan Zhai, Weihang Wang, and Xiangyu Zhang. Trojaning attack on neural networks. In 25th Annual Network and Distributed System Security Symposium, NDSS 2018, San Diego, California, USA, February 18-21,2018.
[21] Aniruddha Saha, Akshayvarun Subramanya, and Hamed Pirsiavash. Hidden trigger backdoor attacks. arXiv preprint arXiv:1910.00033, 2019.
[22] Shihao Zhao, Xingjun Ma, Xiang Zheng, James Bailey, Jingjing Chen, and Yu- Gang Jiang. Clean-label backdoor attacks on video recognition models. CoRR, abs/2003.03030, 2020.
[23] Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
[24] Alexey Kurakin, Ian J. Goodfellow, and Samy Bengio. Adversarial examples in the physical world. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Workshop Track Proceedings. OpenReview.net, 2017.
[25] Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In 2017 IEEE Symposium on Security and Privacy (SP), pages 39–57. IEEE, 2017.
[26] Tianhang Zheng, Changyou Chen, and Kui Ren. Distributionally adversarial attack. In Proceedings of the AAAI Conference on Artificial Intelligence, vol- ume 33, pages 2253–2260, 2019.
[27] Nicolas Papernot, Patrick D. McDaniel, Somesh Jha, Matt Fredrikson, Z. Berkay Celik, and Ananthram Swami. The limitations of deep learning in adversarial settings. In IEEE European Symposium on Security and Privacy, EuroS&P 2016, Saarbrücken, Germany, March 21-24, 2016, pages 372–387. IEEE, 2016.
[28] Pin-Yu Chen, Yash Sharma, Huan Zhang, Jinfeng Yi, and Cho-Jui Hsieh. EAD: elastic-net attacks to deep neural networks via adversarial examples. In Sheila A. McIlraith and Kilian Q. Weinberger, editors, Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2-7, 2018, pages 10–17. AAAI Press, 2018.
[29] Yang Song, Rui Shu, Nate Kushman, and Stefano Ermon. Constructing unre- stricted adversarial examples with generative models. In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, 3-8 December 2018, Montréal, Canada,
pages 8322–8333, 2018.
[30] Tom B. Brown, Dandelion Mané, Aurko Roy, Martín Abadi, and Justin Gilmer.Adversarial patch. CoRR, abs/1712.09665, 2017.

- 点赞
- 收藏
- 关注作者
评论(0)