搞懂了数据包的传输和为什么页面第二次打开快【玩转浏览器原理】

前情提要
我经常和浏览器打交道,但是对它的了解又不够深,总觉得自己有点渣。
学习浏览器工作原理的Flag久已,可追溯到刚工作那会(一晃三十年过去了)。
今年不知是打通了任督二脉还是怎样,很多立下的豪言壮志竟然要一一实现了。(Flag一一被叶一一实现)。
|

从输入URL到页面展示的完整流程
想要了解数据包和页面渲染的相关内容,我们先来看一个基础又常见的知识点,浏览器从输入URL到页面展示都发生了什么。
一张流程图
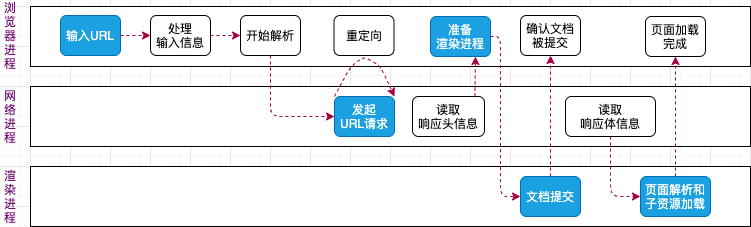
——蓝色:核心节点
图片果然能帮助梳理比较长的流程。
浏览器进程的概念,我上篇文章有解释过,浏览器的多进程架构包含多种进程,不同进程负责处理不同的任务。
从上图中可以看出,当浏览器输入URL之后,具体发生了什么以及各个进程之间是怎么配合的。
提炼时刻
1、浏览器输入URL之后,浏览器进程会将URL请求发送到网络进程进行解析;
2、网络进程先从缓存中查找该资源,查不到会进入网络请求流程;(如果查到了直接返回资源给浏览器进程)
3、请求前,先要进行 DNS 解析,用来获得请求域名的服务器 IP 地址;(如果请求协议是 HTTPS,还需要建立 TLS 连接)
4、得到IP地址之后,用IP地址和服务器建立TCP 连接。建立成功之后,浏览器会构建请求信息,然后向服务器发送请求信息。
5、服务器接收到请求信息后,会根据请求信息生成响应数据(包括响应行、响应头和响应体等信息),并发给网络进程。等网络进程接收了响应头信息之后,开始解析响应头信息。
6、浏览器进程接收到网络进程的响应头数据之后,便向渲染进程发送“提交文档”的消息;(前篇文章提到过,当页面打开时,浏览器会默认准备一个渲染进程)
7、渲染进程接收到“提交文档”的消息后,会和网络进程建立传输数据的“管道”;等文档数据传输完成之后,渲染进程会返回“确认提交”的消息给浏览器进程;
8、一旦文档被提交,渲染进程便开始解析页面和加载子资源。
9、经过一系列的资源加载和解析,最终页面内容就能呈现到浏览器上了。(具体怎么渲染,下篇单独讲讲)
一个数据包的"旅行"
上面输入URL获得页面的流程中,提到数据资源,这些数据资源是怎么被送达到浏览器呢?这将是一场神奇的旅程。
互联网中的数据是通过数据包进行传输的,传输包括两个关键步骤,数据包被送达主机和主机将数据包转给应用。(如果传输的数据很大,那么该数据就会被拆成多个小数据包)
UDP
UDP(User Datagram Protocol),用户数据报协议。主要作用是通过端口号将数据包分发给正确的应用。
以下是一个简化的UDP传输模型:
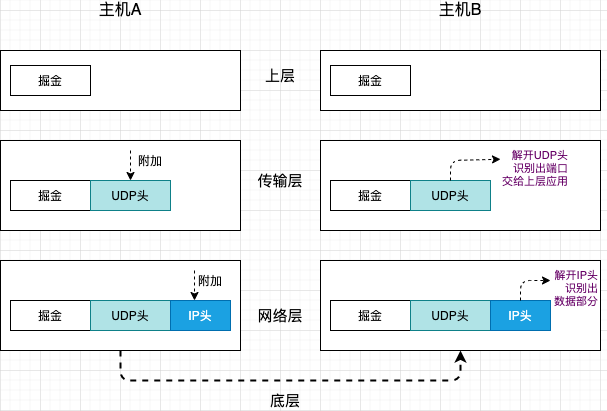
借助模型图,也就帮助梳理出一个数据包从主机A传输到主机B的流程:
1、主机A的上层将“掘金”的数据包交给传输层;
2、传输层会在数据包前面附加上UDP头,组成新的数据包,并交给网络层;
3、网络层接收之后,数据包前附加IP头,组成新的数据包,并交给底层;
4、将数据包传输到主机B的网络层,主机B会解开IP头信息,并将解开的数据部分交给传输层;
5、在传输层,数据包中的UDP头会被解开,并根据解开的数据中的端口号,把数据部分交给上层的应用程序;
6、最终,一个“掘金”的数据包就传送到了主机 B 上层应用程序里。
旅行结束,知识点get。
等等,这里有一行提示:
使用UDP发送数据,可能有各种因素导致数据包出错。 UDP可以校验数据是否正确,但对错误的数据包,不提供重发机制,只是丢弃当前的包,并且UDP在发送之后无法知道是否能达到目的地。
有点不靠谱,网络发展这么快,应该有靠谱的传输方式,于是TCP出现了。
TCP
TCP(Transmission Control Protocol)传输控制协议,是一种面向连接的、可靠的、基于字节流的传输层通信协议。
TCP单个数据包的传输流程和UDP流程差不多,但是,TCP头的信息可以保证数据传输的完整性。
保证数据传输的可靠性是有前提的,那就是牺牲了传输速度,因为TCP经典的“三次握手”和“数据包校验机制”,把传输过程中的数据包的数量提升了一倍。
划重点时刻
UDP和TCP各自有优缺点,两者的应用场景可以采用扬长避短的方式。
协议 |
应用场景 |
UDP |
关注速度、不严格要求数据完整性的场景,如在线视频、互动游戏等。 |
TCP |
需要可靠传输、流量控制的场景,比如电子邮件、文件传输、浏览器访问页面等。 |
为什么页面第二次打开快了很多
上面输入URL获得页面的流程中,提到了网络进程先从缓存中查找资源,换个角度看这段文字,也就是说浏览器会缓存资源。
一组趣味问答
问:那么什么时候会进行缓存呢?
答:第一次打开页面的时候。
问:都有哪些数据会被缓存呢?
答:DNS缓存和页面资源缓存这两块数据。
问:所以第二次打开快是因为第一次缓存耗时了吗?
答:是的。
问:DNS缓存和页面资源缓存,哪个耗时更长?
答:页面资源缓存。
浏览器资源缓存
讲浏览器资源缓存,就必须先上李兵老师课程里下面这张图了。
缓存查找流程示意图
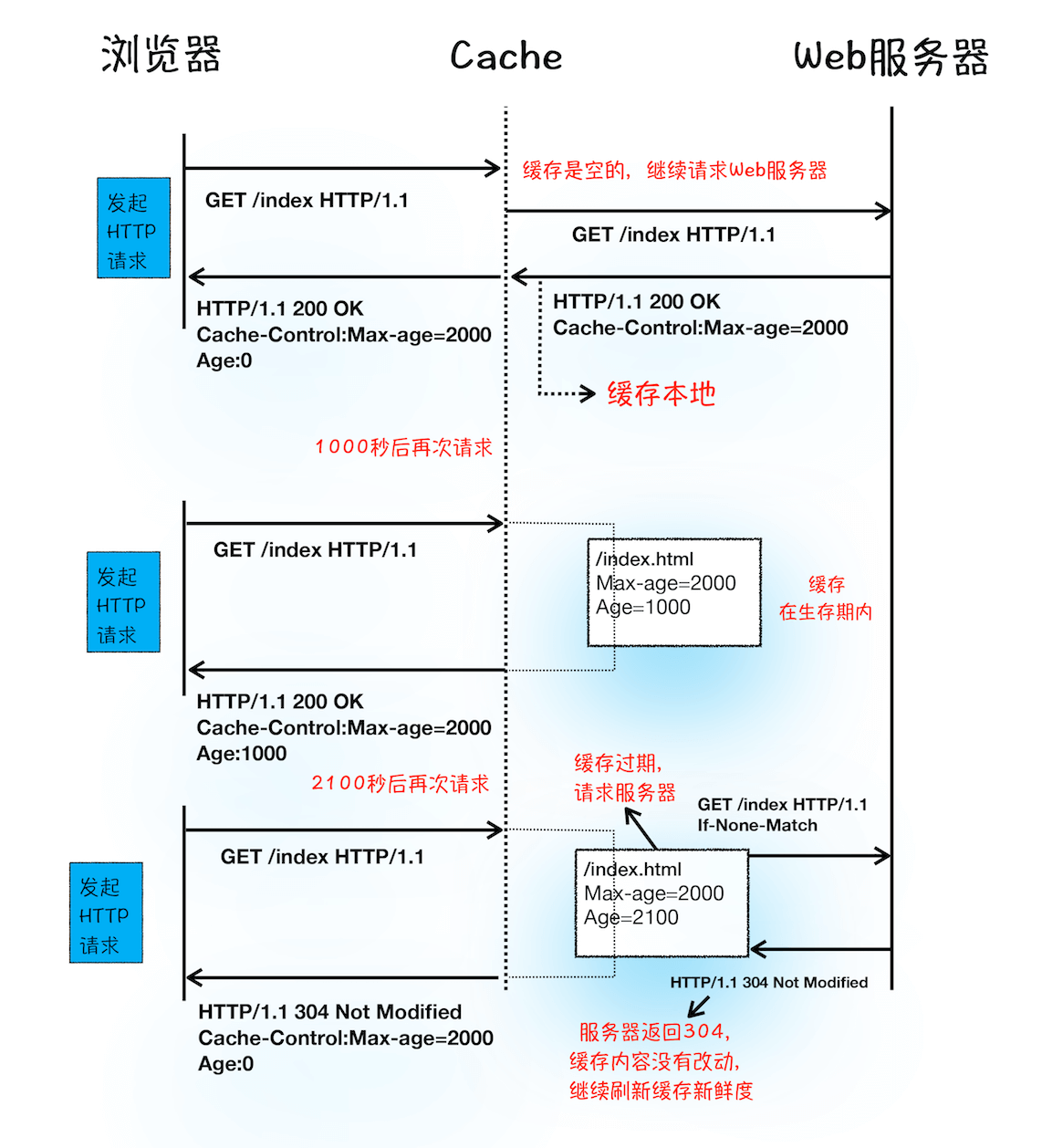
流程梳理
1、第一次请求时,浏览器会从返回响应头中,通过Cache-Control字段来判断是否缓存该资源。通常,还会为这个资源设置一个缓存过期时长,缓存时长是通过Cache-Control中的Max-age参数来设置的,比如上图中设置的缓存过期时间是 2000s。
2、如果设置了缓存过期时长,会出现未过期和已过期两种情况:
- 该缓存资源未过期的情况下,如果再次请求该资源,会直接返回缓存中的资源给浏览器。
- 该缓存资源已过期的情况下,浏览器会继续发起网络请求,并且在 HTTP 请求头中带上 If-None-Match。
3、服务器收到请求头后,会根据 If-None-Match的值来判断请求的资源是否有更新。
- 如果没有更新,就返回304状态码。表示缓存可以继续使用,资源不会重复发送。
- 如果资源有更新,服务器就直接返回最新资源给浏览器。
未完待续
文章写完之后,掌握了三部分知识点:
- 从输入URL到页面展示的完整流程
- 数据包如何进行传输
- 为什么页面第二次打开快了很多

- 点赞
- 收藏
- 关注作者
评论(0)