Hash 算法详细介绍与实现 (二)

前言
书接上回,昨天写了第一部分,《Hash 算法详细介绍与实现 (一)》详细介绍了Hash表和Hash算法的相关概念以及算法的基本原理。同时简单介绍几种hash算法的实现:直接取余法和乘法取整法;本文接着详细唠唠Hash算法和Hash表这个数据结构的具体实现以及Hash算法和Hash表常见问题的解决方案,比如解决Hash表的冲突问题等等.相关的理论知识已在上篇文章详细介绍,这里就不再赘述,多的不说少的不唠,直接进入今天的主题:利用Hash算法实现Hash表
Hash表数据结构的实现
hash表是计算机科学中最为重要的数据结构之一,而且运用极广泛,可用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做Hash值.比如我们常用的MD5加密算法,Hash表也是一种快捷的查找技术,在海量数据处理中也有着广泛应用.Hash表的查询速度非常的快,几乎是O(1)的时间复杂度。其实hash就是找到一种数据内容和数据存放地址之间的映射关系。
Hash表结构
我们上面说hash表的时间复杂度是O(1),我们看看他的具体结构:
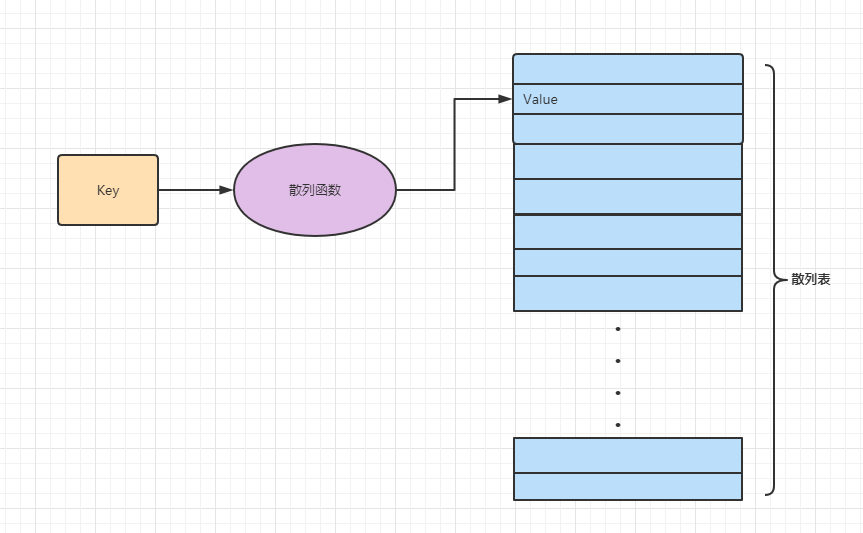
从上图可以看到,构造一个Hash表必须创建一个足够大的数组用于存放数据,另外还需要一个Hash函数把关键字key映射到数组中的某个位置
Hash表的具体实现步骤如下:
创建一个固定大小的数组用于存放数据
设计Hash函数
通过Hash函数把关键字映射到数组的某个位置,并在此位置上进行数据存取

接着我们动手去实现它
利用PHP实现Hash表
这里使用到PHP的面向对象技术
根据上面的流程.首先我们先创建一个HashTable类.里面创建两个成员属性$buckets和size.$buckets是用于存储数据的数组,$size用于记录$buckets数组的大小,也就是数组元素的个数;然后在构造函数中为$buckets数组分配内存,具体代码如下:
<?php
class HashTable{
private $buckets;
private $size=10;
public function __construct(){
$this->buckets = new SplFixedArray($this->size);//初始化
}
}
?>类中的属性使用Private进行修饰,体现面向对象的封装性.在构造函数中为$buckets数组分配了一个大小为10的数组.在这里使用了SPL扩展的SplFixedArray数组,而不是一般的Array(),这是因为SplFixedArray数组更接近于C语言中的数组.而且效率更高.在创建SplFixedArray数组时需要为其提供一个初始化大小.
注:记得开启SPL扩展,或者也可以使用Array进行代替
接着第二步,设计一个Hash函数,这里会用到直接取余法,这里只是为了演示,你还可以选择其他方法,直接上代码:
<?php
function hash($k){
$strlen = strlen($k);
$hashval = 0;
for($i = 0; $i<$strlen; $i++){
$hashval += ord($k{$i});
}
return $hashval % $this->size;//根据公式计算
}有了Hash函数,就可以实现插入和查找方法,插入数据时.先通过Hash函数计算关键字所在Hash表的位置,然后把数据保存到此位置即可.
<?php
public function insertData($k,$v){
$index = $this->hashf($k);
$this->buckets[$index] = $val;
}
?>接着就是查找数据,查找数据的方法是类似的,只不过查找需要返回值,先通过Hash函数环境计算关键字所在的Hash表的位置,返回此位置的数据即可:
<?php
public function findData($k){
$index = $this->hashf($k);
return $this->buckets[$index];
}
?>接下来我们就来验证我们写好的Hash类:
<?php
$hash = new HashTable();
//插入数据
$hash->insertData('name1','张三');
$hash->insertData('name2','李四');
echo '------------HashTable操作-------------';
echo '<br>';
//查找数据
echo $hash->findData('name1');
echo '<br>';
echo '-------------------------';
echo '<br>';
echo $hash->findData('name2');执行结果如下:

可以正常存取看似没什么问题但是我们接下来看看但存入一个类似的key的时候会是什么结果:
<?php
$hash = new HashTable();
//插入数据
$hash->insertData('name1','张三');
$hash->insertData('name12','李四');
echo '------------HashTable操作-------------';
echo '<br>';
//查找数据
echo $hash->findData('name1');
echo '<br>';
echo '-------------------------';
echo '<br>';
echo $hash->findData('name12');
?>这里使用的是一样的代码,只是存入的key不一样,之前的key分别是name1和name2,现在这段代码是name1和name12;我们先来看结果:

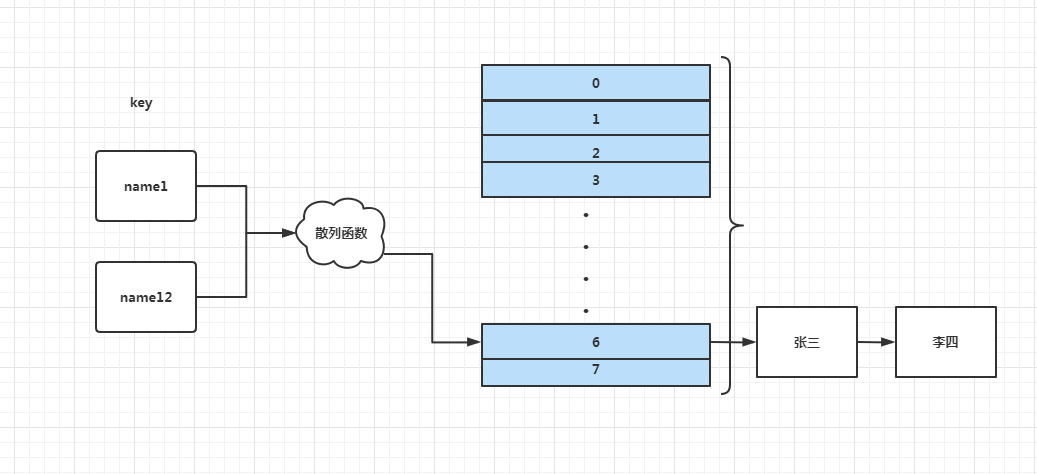
正常来说应该是name1是张三,name12是李四才对,可现在都是name12的值李四,为什么会这样呢?
这就是传说中的Hash表冲突,冲突的原因是:因为不同的关键字通过Hash函数计算出来的Hash值是相同的.我们可以通过打印两者的Hash值看看他们到底是何方妖孽:
echo 'name1Hash值'.$hash->hashf('name12');
echo '<br>';
echo 'name12Hash值'.$hash->hashf('name12');输出结果到都是6
也就是说name1和name12同时存放在Hash表中的第7个位置,所以name1的值被name12覆盖掉;冲突必然的;因为用短位(散列地址空间)表示长位数据(关键码空间),肯定会出现冲突。比如 常见的 MD5 码,一共就128bit,但却要表示无限的数据的散列码,因此必然会出现不同数据具有相同MD5码的情况,只是冲突出现的概率大小不同。但是兵来将挡水来土掩.毕竟方法总比困难多.解决冲突常用的方法有:最常用的就是开放寻址法和链地址法(拉链法),还有更多其它的:比如线性试探、查找链法、多槽位法、独立链法、公共溢出区等等。本文选择实现起来最简单的拉链法来解决冲突问题。
解决冲突的法宝:拉链法的实现
拉链法解决冲突的做法是:将所有相同的Hash值的关键字节点链接在同一个链表中,下面我们看看演示图是:
从上图可以看出,拉链法把相同的Hash值的关键字节点以一个链表的形式连接起来,在查找元素的时候就必须遍历这个链表,比较链表中的每个元素的关键字与查找的关键字是否相等,如果相等就是我们要查找的元素。
因为节点需要保存关键字和数据,同时还要记录具有相同Hash值的节点,所以创建一个HashNode类存储这些信息.HashNode结构如下:
<?php
class HashNode{
public $key;
public $value;
public $nextNode;
//成员属性初始化
public function __construct($key, $value, $nextNode=NULL){
$this->key = $key;
$this->value = $value;
$this->nextNode = $nextNode;
}
}
?>HashNode有三个成员属性.$key,$value,$nextNode,$key是节点的关键字,$value是节点的值,$nextNode是指向具有相同Hash值节点的指针,现在把插入方法修改为下面的形式
<?php
public function insertData($k,$v){
$index = $this->hashf($k);
//创建一个新节点
if(isset($this->buckets[$index])){
$newNode = new HashNode($k, $v, $this->buckets[$index]);
}else{
$newNode = new HashNode($k, $v, NULL);
}
$this->buckets[$index] = $newNode;
}修改后的算法流程如下:
使用Hash函数计算关键字的Hash值,通过Hash值定位到Hash表的指定位置
如果此位置已经被其他节点占用,把新节点的$nextNode指向此节点,否则就把新节点的$nextNode设置为NULL
把新节点保存到Hash表的当前位置
经过以上三个步骤相同的Hash值的节点会被连接在同一个链表
查找算法相应要修改为如下代码:
<?php
public function findData($k){
$index = $this->hashf($k);
$current = $this->buckets[$index];
while(isset($current)){
if($current->key == $k){
return $current->value;//查找成功并返回
}
$current = $current->nextNode;
}
//查找失败
return NULL;
}修改之后的查找方法流程如下:
使用Hash函数计算关键字的Hash值,通过Hash值定位到Hash表指定的位置
遍历当前链表,比较链表中的每个节点的关键字与查找关键字是否相等.如果相等,查找成功,直接返回查找到的值
如果整个链表都没有要查找的关键字,则查找失败,返回直接NULL
修改之后的代码我们再来验证一下是否能够解决冲突问题:
<?php
$hash = new HashTable();
//插入数据
$hash->insertData('name1','张三');
$hash->insertData('name12','李四');
echo '------------HashTable操作-------------';
echo '<br>';
//查找数据
echo $hash->findData('name1');
echo '<br>';
echo 'name1Hash值'.$hash->hashf('name12');
echo '<br>';
echo '-------------------------';
echo '<br>';
echo $hash->findData('name12');
echo '<br>';
echo 'name12Hash值'.$hash->hashf('name12');执行结果如下:

从执行结果可以看出,使用拉链法能够正确读取到存入的对应的值,而且不会覆盖原有Hash值相同的key对应的值.愉快地解决了冲突问题,感兴趣的童鞋还可以试试其他办法解决冲突问题
总结
Hash表的优缺点总结
Hash表优点:
无论哈希表中有多少数据,查找、插入、删除(有时包括删除)算法的时间复杂度接近常数级:即O(1)的时间级。实际上,这只需要几条机器指令即可完成
哈希表运算得非常快,在计算机程序中,如果需要在一秒种内查找上千条记录通常使用哈希表(例如拼写检查器)哈希表的速度明显比树快,树的操作通常需要O(N)的时间级。哈希表不仅速度快,编程实现也相对简单
如果不需要有序遍历数据,并且可以提前预测数据量的大小。那么哈希表在速度和易用性方面是其他不可比拟的
Hash表的缺点:它是基于数组的,数组创建后难于扩展,某些哈希表被基本填满时,性能下降得非常严重,所以必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中,这是一个非常费时的过程)

- 点赞
- 收藏
- 关注作者
评论(0)