线性结构-链表

链表也是一种常用的线性数据结构,与数组不同的是,链表的存储空间并不连续,它是用一组地址任意的存储单元来存放数据的,也就是将存储单元分散在内存的各个地址上。
这些地址分散的存储单元叫做链表的节点,链表就是由一个个链表节点连结而成的。
每个链表都有一个“链表头”,通常是一个指针。对Java而言,它是链表节点对象的引用。用来存放链表中第一个节点的地址。同时,链表中最后一个节点的指针域通常会置空null,用来表示该节点是链表的最后一个节点,没有后继节点。

链表在逻辑上是连续的,但在物理上并不一定连续,链表节点可能分散在内存的各个地址上。
- 每个链表节点都必须包含指针域,用来存放下一个节点的内存地址。数据域则用来存放节点的的数据元素。
- 数据域可以是一个也可以是多个,由具体的需求而定。
- 指针域的类型必须是定义的链表节点类型,或链表节点指针类型。
- 只要获取了链表头,就可以通过指针遍历整个链表。按照指针依次访问,直到访问到最后一个节点(指针域为null)。所以获取链表头非常重要。
链表的定义
定义链表节点
链表是由链表节点构成的,因此在定义链表结构之前,要先定义链表的节点类型。
class Node {
int data;
Node next;
public Node(int data) {
this.data = data; //构造方法,在构造结点对象时将data赋值给this .data成员
}
}在Java中,节点类可以放到链表类文件的最后。
但在C/C++中,必须要先声明后使用,将节点声明在链表前面。定义即可在前也可以在后。
类Node包含两个成员变量:
- data为整型的变量,是该链表节点的数据域,可以用来存放一个整数。
- next为Node类型的引用类型变量,是该链表节点的指针域,用来指定下一个节点。
定义链表
定义完链表节点类Node,接下来我们可以定义链表类。
链表是靠节点间的指针相互关联的。只要获取了链表头就可以通过头指针遍历整个链表。
在链表类中没有必要包含该链表的所有节点,只需要定义一个head成员就足够了。
public class MyLinkedList {
Node head = null;
int length = 0;
//暂未添加链表的操作函数
}
class Node {
int data;
Node next;
public Node(int data) {
this.data = data; //构造方法,在构造结点对象时将data赋值给this .data成员
}
}这个链表类中包含两个成员变量:
- head是Node类型的成员,他是链表中第一个节点的引用,也就是指向第一个节点的指针。
- length是整形变量,用来记录数组中元素的数量。
操作链表的函数可以根据需要而定。
链表的基本操作
链表的基本操作包括向链表中插入节点和从链表中删除节点,另外根据实际需要可以定义获取链表长度、销毁链表等操作。
向链表中插入节点
public boolean insertNode(int data, int index)
这个函数表示在链表的第index个位置上插入一个整形变量data节点。
- 参数
data指链表节点中的元素值而不是节点对象。因为我们定义的链表节点Node中的数据域是int类型,所以参数data也要是int类型。 - 参数index表示要将节点插入链表中的位置,与数组元素的位置相似,我们规定index只能是
[1,length+1]范围内的值。由于链表没有数组中下标访问的操作,所以不需要在意元素位置和下标的关系。
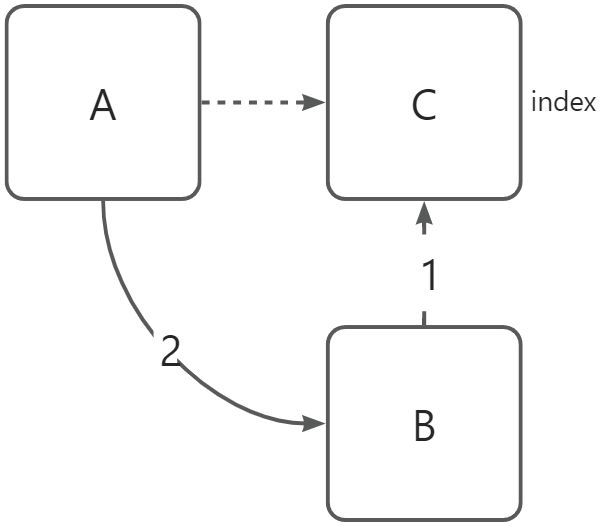
需要注意,index所指的对象是C:
- 创建一个节点对象B,将data值赋值给数据域。
- 将A的指针域赋值给B的指针域,使B指向C。
- 将B的地址赋值给A的指针域,使A指向B。
如果要在链表的第一个位置index=1上插入节点:
- 如果
head==null,则链表是个空链表,此时直接将B的地址赋值给head即可。 - 如果
head!=null,则说明链表中已有节点,此时将head视为A修改修改地址即可。
public boolean insertNode(int data, int index) {
// 向链表的第index位置上插入一个结点,结点数据为data(这里是int类型)
if (index < 1 || index > (length + 1)) {
// 这种情况说明插入结点的位置不合法
System.out.println("Insert error position. index = " + index + " length = " + length);
return false;
}
// 要插入结点的位置为1,这时的操作有些特殊
if (index == 1) {
if (head == null) {
head = new Node(data); // 创建第一个结点
} else {
Node node = new Node(data); // 创建一个新结点node
node.next = head; // 将head值赋值给node的next域
head = node; // 再将node赋值给head
}
length++;
return true;
}
// 要插入的结点位置不是1,此时
// 1、将指针p指向要插入位置的前一个结点上
// 2、创建新的结点,并插入到p结点后面
Node p = head; // p指向头结点head,移动到要插入位置的前一个位置
int i = 1;
while (i < index - 1 && p != null) {
p = p.next;
i++;
}
Node node = new Node(data); // 创建该结点
node.next = p.next;
p.next = node;
length++;
return true;
}在每次插入成功之后,成员变量length的值会+1,这样每次需要得到链表长度时直接读取length值就可以了。
也可以通过遍历链表的方法获取链表长度,但是效率较低,时间复杂度为 。
。
链表是一种动态的数据结构,可以随时在其中插入节点或删除节点,所以链表的长度是不断变化的。我们在插入删除的过程中需要随时修改length值,让length始终记录链表当前的长度,那么爱获取链表长度的时候就不需要重新遍历整个链表了,直接返回length值即可。效率会提高很多,时间复杂度为 。
。
其中这一段代码需要格外注意,建议多看几遍。
// 1、将指针p指向要插入位置的前一个结点上
// 2、创建新的结点,并插入到p结点后面
Node p = head; // p指向头结点head,移动到要插入位置的前一个位置
int i = 1;
while (i < index - 1 && p != null) {
p = p.next;
i++;
}
Node node = new Node(data); // 创建该结点
node.next = p.next;
p.next = node;删除节点
public boolean deleteNode(int index)
在实现该函数之前,需要明白什么叫链表中第index个位置上的节点删除:
- 删除链表中
index=3的节点就是将链表中的第3个节点移除,使其前驱节点与后继节点直接连接。 - 删除成功后,链表的长度减1。
显然,index的取值范围为[1,length]。
同样,我们需要注意删除第一个节点时的特殊情况:
- 因为index=1的节点前面没有其他节点,也就没有前驱节点,只需要将
head.next赋值给head即可。这样head就会指向原链表第一个节点的后继节点,也就等价于删除了第一个节点。 - 当head指向null时,链表长度为0。将被第一个if拦下,不会执行到这一步,在此不需要考虑这种情况。
public boolean deleteNode(int index) {
if (index < 1 || index > length) {
// 这种情况说明插入结点的位置不合法
System.out.println("Delete error position.");
return false;
}
// 要删除第一个结点
if (index == 1) {
head = head.next;
length--;
return true;
}
// 将p指向index的前一个节点
Node p = head; // p指向头结点head
int i = 1;
while (i < index - 1 && p != null) {
p = p.next;
i++;
}
p.next = p.next.next;
length--;
return true;
}由于Java自带内存回收机制,所以不需要我们手动释放。如果是C/C++,我们需要手动释放该删除节点在堆区开辟的内存空间。
链表的性能分析
改查慢
之前介绍了数组的性能问题,因为数组存储于连续的内存空间,所以支持随机访问,只要给定数组名和下标,就可以在的时间内定位到数组元素。
而链表不支持随机访问,链表的节点是分散存储的,无法通过一个索引在常量时间内定位到链表中的元素,必须从链表头开始顺序遍历链表,所以在链表中定位一个元素的时间复杂度是级别。
增删快
与数组相比,在链表中插入元素和删除元素的效率要高很多,如果已知要插入或删除的节点之前节点的指针,那么插入或删除操作的时间复杂度仅为。
没有内存越界风险
使用数组时需要预先开辟一整块内存空间,存在内存越界的风险,也可能导致内存资源的浪费。
而链表只需要在使用时动态申请节点,不会产生内存越界,内存的使用效率也相对较高。
综上所述,相较于数组,链表的优势在于能够更加灵活地进行插入和删除操作,且内存使用效率更高。因此对于线性表规模难以估计或插入删除操作频繁、随机读取数据的操作较少的场景,更建议使用链表。
不同形态的链表结构
我们将节点中包含一个指针与且指针只能指向该节点的后继节点的链表称作单链表。
除单链表外,还有功能更强大的循环链表和双向链表。
循环链表
循环链表是一种特殊形式的单链表,它的最后一个节点的指针域不为null,而是指向链表的第1个节点。

普通的单链表只能沿着指针方向找到一个节点的后继节点,无法回到其前驱节点。
由于循环链表的最后一个节点的指针域指向了链表的第一个节点,所以只要通过指针后移,就一定能够找到其前驱节点。
双向链表
单链表的节点只有一个指针域,保存其后继节点的指针。
而双向链表的节点保存了两个指针域,一个指针域的指针指向其直接前驱节点,另一个指针域中的指针指向其直接后继节点。

如果需要经常沿两个方向进行节点操作,那么更适合使用双向链表。
双向循环列表
如果把循环链表和双向链表结合起来,就是结构更为复杂的双向循环链表。

双向循环链表结合了循环链表和双向链表的优点,对节点的操作更加方便灵活。
双向循环链表的结构比其他类型的链表更加复杂,所以还要结合具体选择链表结构。
来几道算法题
链表的综合操作
单链表的增删改查
创建一个包含10个节点的单链表保存整型数据1~10,在屏幕上显示链表中的内容。在链表中第1、3、5、20个位置分别插入一个节点,节点的数据均为0,每插入一个节点,就在屏幕上显示链表中的内容。将插入的节点全部删除,再显示链表中的内容,最后将链表销毁。
对于创建链表,可以通过插入节点的操作来实现。
对于显示链表,可以从链表的第1个节点开始顺序向后遍历整个链表,显示访问到的每个节点。
对于销毁链表,我们不需要调用deleteNode(int index)将链表中的节点逐一删除,这是一种冗余操作。对Java而言,如果一个对象失去了引用,则该对象会被Java的垃圾回收机制回收并释放,因此用户没有必要,也无法显式地释放一个对象实例。所以,要销毁一个链表,只需要将链表的头指针head置为null即可。
如果是C/C++,需要循环调用free()或delete()函数显式地释放内存。
public class MyLinkedList {
Node head = null;
int length = 0;
// main方法,它是程序的入口
public static void main(String[] args) {
MyLinkedList list = new MyLinkedList();
// 通过insertNode方法创建一个链表,里面包含1~10,十个整数结点
for (int i = 1; i <= 10; i++) {
list.insertNode(i, i);
}
list.printLinkedList(); // 打印链表中的内容
list.insertNode(0, 1); // 在第1个位置上插入一个包含整数0的结点
list.printLinkedList(); // 打印链表中的内容
list.insertNode(0, 3); // 在第3个位置上插入一个包含整数0的结点
list.printLinkedList(); // 打印链表中的内容
list.insertNode(0, 5); // 在第5个位置上插入一个包含整数0的结点
list.printLinkedList(); // 打印链表中的内容
list.insertNode(0, 20); // 在第20个位置上插入一个包含整数0的结点
list.printLinkedList(); // 打印链表中的内容
list.deleteNode(1); // 删除第1个位置上的结点
list.deleteNode(2); // 删除第2个位置上的结点
list.deleteNode(3); // 删除第3个位置上的结点
list.printLinkedList(); // 打印链表中的内容
list.destroyLinkedList(); // 销毁链表
}
public boolean insertNode(int data, int index) {
// 向链表的第index位置上插入一个结点,结点数据为data(这里是int类型)
if (index < 1 || index > (length + 1)) {
// 这种情况说明插入结点的位置不合法
System.out.println("Insert error position. index = " + index + " length = " + length);
return false;
}
// 要插入结点的位置为1,这时的操作有些特殊
if (index == 1) {
if (head == null) {
head = new Node(data); // 创建第一个结点
} else {
Node node = new Node(data); // 创建一个新结点node
node.next = head; // 将head值赋值给node的next域
head = node; // 再将node赋值给head
}
length++;
return true;
}
// 要插入的结点位置不是1,此时
// 1、将指针p指向要插入位置的前一个结点上
// 2、创建新的结点,并插入到p结点后面
Node p = head; // p指向头结点head
int i = 1;
while (i < index - 1 && p != null) {
p = p.next;
i++;
}
Node node = new Node(data); // 创建该结点
node.next = p.next;
p.next = node;
length++;
return true;
}
public boolean deleteNode(int index) {
if (index < 1 || index > length) {
// 这种情况说明插入结点的位置不合法
System.out.println("Delete error position.");
return false;
}
// 要删除第一个结点
if (index == 1) {
head = head.next;
length--;
return true;
}
// 将p指向index的前一个节点
Node p = head;
for (int i = 1; i < index - 1; i++) {
p = p.next;
}
p.next = p.next.next;
length--;
return true;
}
public void printLinkedList() {
Node p = head;
while (p != null) {
System.out.print(p.data + " ");
p = p.next;
}
System.out.print("\n-------------------------\n"); // 打印分隔线
}
public void destroyLinkedList() {
head = null; // 头结点指针head置null
length = 0; // 链表长度length设为0
}
}
class Node {
int data;
Node next;
public Node(int data) {
this.data = data; // 构造方法,在构造结点对象时将data赋值给this .data成员
}
}将两个有序链表归并
编写一个函数MyLinkedList MergeLinkedList(MyLinkedList list1,MyLinkedList list2),实现将有序链表list1和list2合并成一个链表。要求合并后的链表依然按值有序,且不开辟额外的内存空间。
本体要求不开辟额外的内存空间,也就是要利用原链表的内存空间,在不创建新节点的前提下实现链表的合并。
一共需要创建四个Node类型的引用变量:
head3:作为结果链表list3的头指针。由于不开辟额外的内存空间,所以需要指向head1和head2节点中的较小者,使用该链表的内存空间。r:指向list3的最后一个节点。使用该变量是为了方便在list3的链表尾插入新的节点。p、q:分别指向list1和list2中待合并的节点。将对比得到的较小值插入到r后面。
由于我们head3初始指向了head1和head2节点中的较小者。只确定了链表的第一个节点,所以此时list3长度为1,r与head3指向的是同一个对象。
在p、q的对比过程中,得到的较小值插入到了r后面。较大值并没有被插入,需要继续拿来对比。
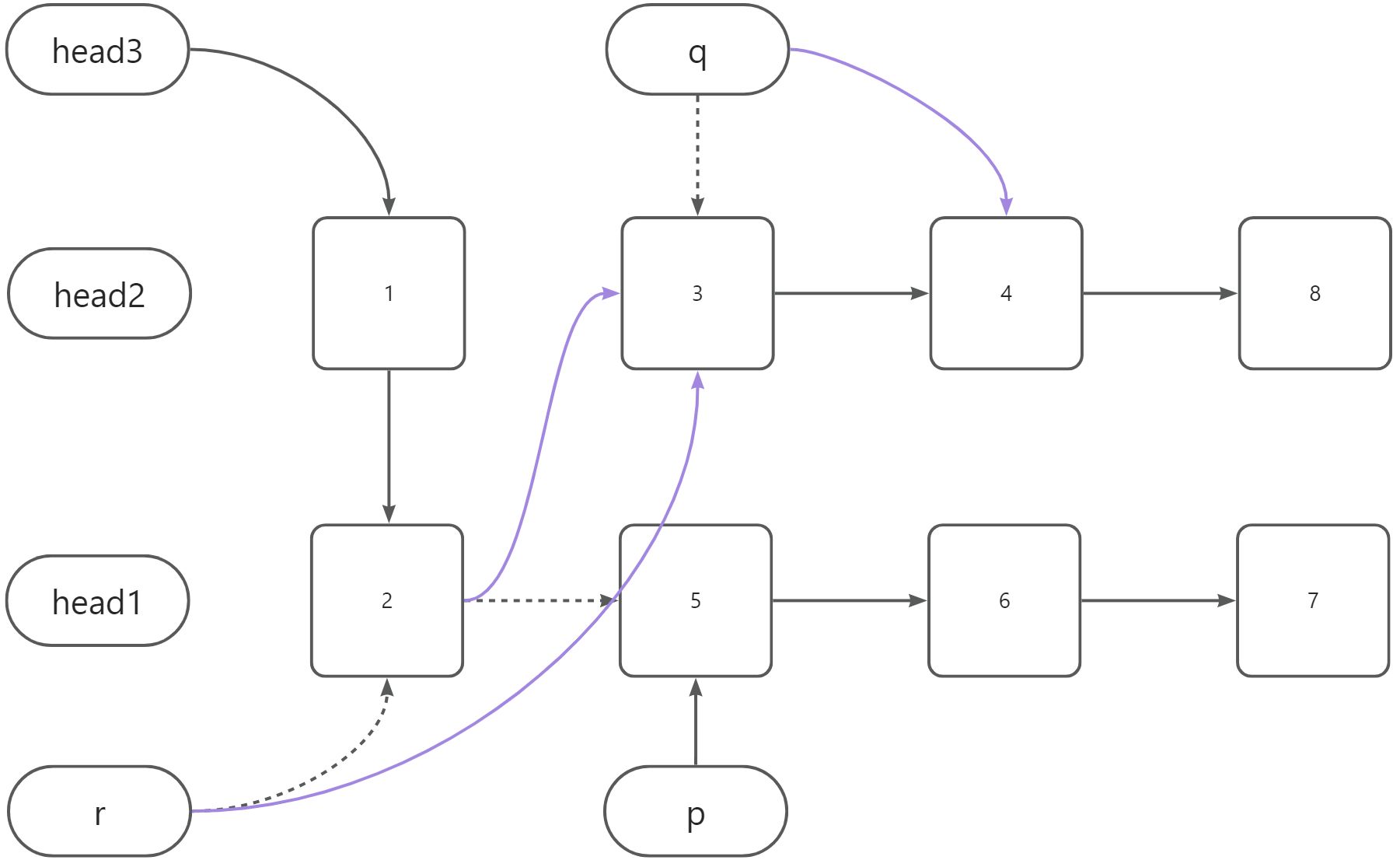
上图中,q小于p,所以:
- 将
q赋值给r.next。使3接入到链表尾部。 - 将
r.next赋值给r。使r指向新的尾节点。 - 将
q.next赋值给q。使q指向原链表的下一个节点。
当p或q等于null时结束循环。此时list1或list2至少有1个链表的节点已经全部合并到list3中。将尚未合并到list3中的链表整体插入到r指向的节点后面实现完整的合并操作。
public class MergeLinkedListTest {
//将以链表list1和链表list2合并,返回链表list3
public static MyLinkedList MergeLinkedList(MyLinkedList list1, MyLinkedList list2) {
Node head3; //定义head3,指向链表list3的头结点
Node p = list1.getHead();//通过getHead()方法获取list1的头结点,并用p指向list1的头结点
Node q = list2.getHead();//通过getHead()方法获取list2的头结点,并用q指向list1的头结点
Node r; //定义r指针
if (p.data <= q.data) {
//如果p结点的数据小于等于q结点数据
head3 = p; //head3指向p结点(list1的头结点)
r = p; //r指向p结点
p = p.next; //p指向下一个结点
} else {
//如果p结点的数据大于q结点数据
head3 = q; //head3指向q结点(list2的头结点)
r = q; //r指向q结点
q = q.next; //q指向下一个结点
}
while (p != null && q != null) {
//进入循环,直到p或q等于null,也就是一个链表遍历结束
if (p.data <= q.data) {
//如果p结点的数据小于等于q结点的数据
//则将p结点插入到r结点后面
r.next = p;
r = r.next;
p = p.next;
} else {
//如果q结点的数据小于p结点的数据
//则将q结点插入到r结点后面
r.next = q;
r = r.next;
q = q.next;
}
}
r.next = (p != null) ? p : q; //将p或q指向的剩余链表连接到r结点后面
MyLinkedList list3 = new MyLinkedList(); //创建list3实例
list3.setHead(head3); //将head3赋值给list3中的head成员
return list3; //返回list3实例引用
}因为MergeLinkedList()函数的参数是MyLinkedList类型对象引用,MyLinkedList对象包含了链表的头节点指针head,所以我们需要获取这个head指针才能对链表进行操作。
整个合并过程中没有开辟额外的内存空间,而是利用原链表的节点资源,通过调整指针实现链表的合并,符合题目要求。

- 点赞
- 收藏
- 关注作者
评论(0)