神经网络的训练过程、常见的训练算法、如何避免过拟合

神经网络的训练是深度学习中的核心问题之一。神经网络的训练过程是指通过输入训练数据,不断调整神经网络的参数,使其输出结果更加接近于实际值的过程。本文将介绍神经网络的训练过程、常见的训练算法以及如何避免过拟合等问题。
神经网络的训练过程
神经网络的训练过程通常包括以下几个步骤:
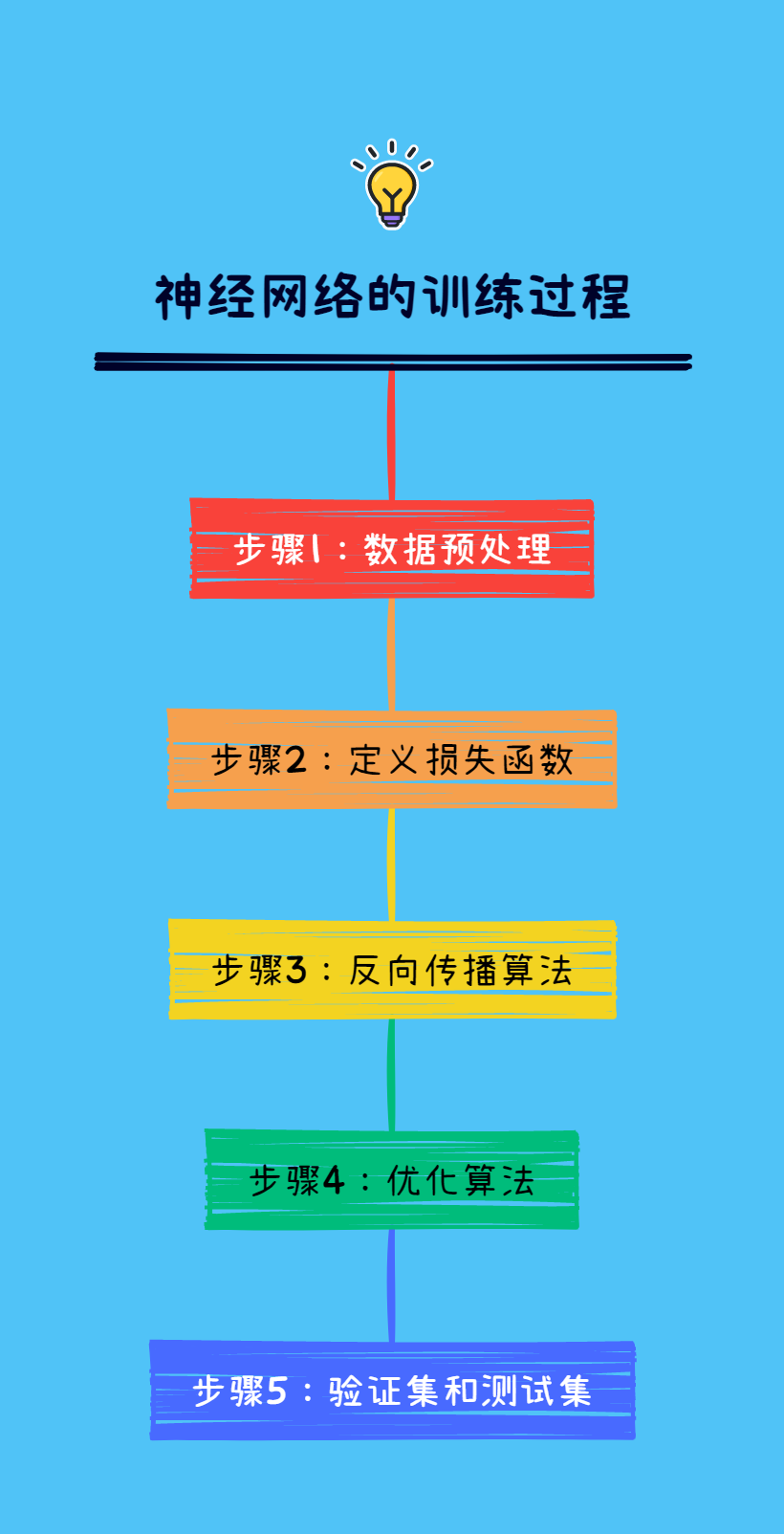
步骤1:数据预处理
在进行神经网络训练之前,需要对训练数据进行预处理。常见的预处理方法包括归一化、标准化等。这些方法可以帮助神经网络更好地学习数据的特征,并提高模型的准确性。
步骤2:定义损失函数
神经网络的训练目标是使预测值和实际值之间的误差最小化。为了实现这个目标,需要定义一个损失函数来衡量预测值和实际值之间的差距。常见的损失函数包括均方误差、交叉熵等。
步骤3:反向传播算法
反向传播算法是神经网络训练的核心算法之一。该算法通过计算损失函数对每个神经元的输出的导数,然后利用链式法则将误差反向传播回网络中的每一层。这样就可以利用误差来更新每个神经元的权重和偏置,从而不断优化神经网络的参数。
步骤4:优化算法
神经网络的优化算法决定了神经网络的训练速度和稳定性。常见的优化算法包括梯度下降法、Adam算法、Adagrad算法等。这些算法的目标是找到合适的学习率,使神经网络的训练过程更加快速和稳定。
步骤5:验证集和测试集
在训练神经网络时,需要将数据集分为训练集、验证集和测试集。训练集用于训练神经网络的参数,验证集用于调整神经网络的超参数,测试集用于评估神经网络的性能。
常见的训练算法
梯度下降法
梯度下降法是最常用的优化算法之一。该算法的基本思想是通过计算损失函数的梯度,不断更新神经网络的参数,早停是一种常见的防止过拟合的方法,它通过在训练过程中定期评估模型在验证集上的性能来判断模型是否过拟合。如果模型在验证集上的性能开始下降,则可以停止训练,从而避免过拟合。
数据增强
数据增强是一种通过对原始数据进行变换来扩充训练集的方法,从而提高模型的泛化能力。常见的数据增强方法包括旋转、缩放、平移、翻转等操作。
总结
神经网络的训练是一个复杂的过程,需要通过选择合适的优化算法、学习率调度、正则化等方法来提高模型的泛化能力,避免过拟合。在实际应用中,需要根据具体的任务和数据特征选择不同的训练策略,以达到最好的效果。

- 点赞
- 收藏
- 关注作者
评论(0)