【算法实践】| 手把手带你实现快速排序算法

前言
我们知道,程序是用来解决问题的,是由多个步骤或过程组成的,这些步骤和过程就是解决问题的算法。
之前在《利用 Python 浅尝算法分析》这篇文章中写过算法分析,接着写了关于经典的冒泡排序算法《利用 Python 手把手带上实现冒泡排序》,算法虽然枯燥,但是当你深入了解就会感受到其中的趣味。在算法的学习中不但可以学会如何思考问题,提高自己的逻辑能力,还能在这些算法中积累解决实际生活问题的方法。算法是无穷无尽的,在编程中他可以是任意一段代码。我们平时在实际开发中涉及到的算法,很多都是衍生于经典算法,或者是多种经典算法的结合,所以学习算法,经典算法是我们绕不过的一道坎、只有跨过去才能这道坎另一边的好风景,方能走得更远,学习经典算法的好处就不多说了。。。直接进入今天的主题--快速排序的实现
快速排序,跟冒泡排序算法一样,顾名思义就是一种排序算法,快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,他将原本的问题分成两个子问题,各个击破,通常称其为分治法(Divide-and-ConquerMethod)。
快速排序由于排序效率在同为O(N*logN)的几种排序方法中效率较高,因此经常被采用,再加上快速排序思想—-分治法也确实实用,这也使得在我们的面试或者工作中经常出现的它的身影,这个算法有些复杂,时间复杂度最好的情况是O(nlogn),最差的情况是O(n^2),而且比较不稳定,占用空间O(logn)
该方法的基本思想是:
1.先从数列中选择一个数作为基准数。
2.分区过程:通过排序,将数据分割成独立的两部分.将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.按此方法,再对左右区间重复第二步,直到各区间只有一个数
整个排序过程可以递归进行,以此达到数据排序的目的
虽然快速排序称为分治法,但分治法无法很好的概括快速排序的全部步骤。所以快速排序又总结为:挖坑填数+分治法,下面我们使用图示展示算法的基本过程
算法过程演示
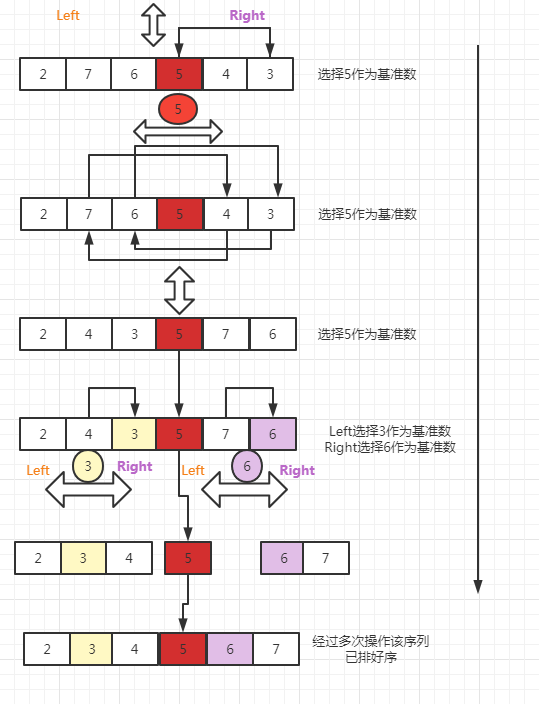
以序列[2,7,6,5,4,3]为例进行排序:
随机选择一个数作为基准数.这里选择5作为基准数.比基准数大的往右移,比基准数小的往左移,直到把5的左边全部是比它小的数,右边全部是比它大的数,第一次完成一个整体排序后,接着对基准数的前后两个半区进行和前面一样的操作,直到整体的排序完成
实现步骤
快速排序步骤:
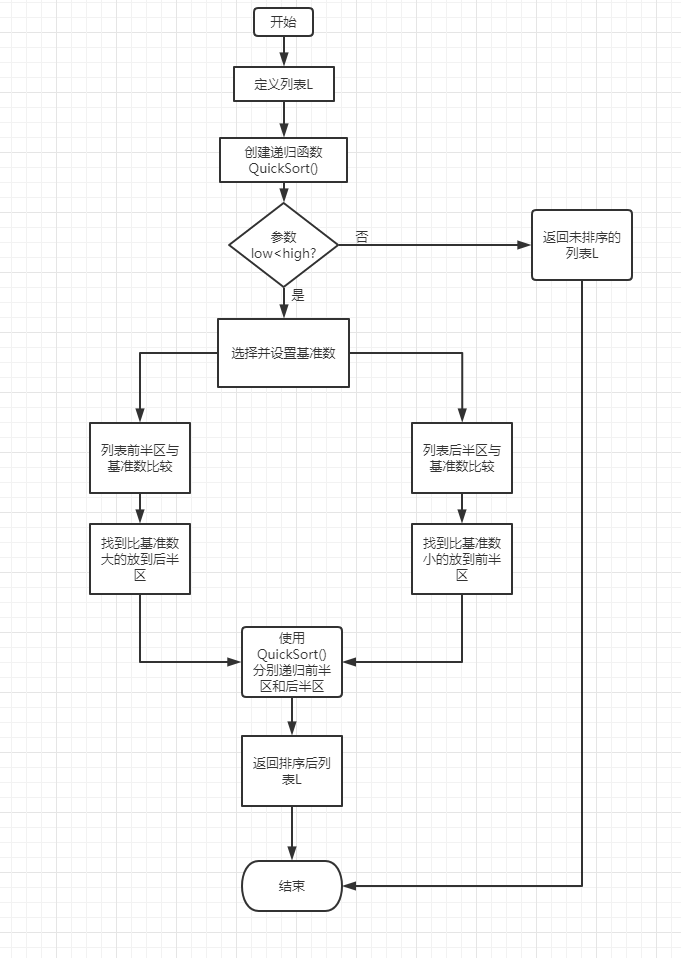
定义一个需要排序的列表
创建递归递归调用的快速排序函数
判断low是否小于high,若low>high,则直接返回原列表
设置基准数pivot
如果列表前半区的数比基准数小或相等,则向后移动一位,直到有比基准数大的数出现,放入后半区.如果列表后半区的数比基准数大或相等.则向前移动一位,直到有比基准数小的数出现,放入前半区内.
递归前后半区,然后返回列表
调用函数输出列表
流程如下:
代码实现
定义快速排序函数QuickSort(),low为列表最左边位置的编号,high为列表最右边的位置编号,如果low>high,直接返回原列表并将列表中第一个数字设置为基准数
def QuickSort(ListData,low,high):
if low < high:
i,j = low,high
#设置基准数
pivot = ListData[i]
while i < j:
#如果列表后边的数,比基准数大或相等,则前移一位直到有比基准数小的数出现
while (i < j) and (ListData[j] >= pivot):
j = j - 1
#如找到,则把第j个元素赋值给第个元素i,此时表中i,j个元素相等
ListData[i] = ListData[j]
#以同样的方式比较前半的子序列
while (i < j) and (ListData[i] <= pivot):
i = i + 1
ListData[j] = ListData[i]
#做完第一轮比较之后,列表被分成了两个子序列,并且i=j,需要将这个数设置回选择的基准数
ListData[i] = pivot
#递归基准数的前后两个子序列
QuickSort(ListData, low, i - 1)
QuickSort(ListData, j + 1, high)
return ListData调用QuickSort()验证排序算法:
ListData = [2,7,6,5,4,3]
print("原列表: ",ListData)
QuickSort(ListData,0,len(ListData)-1)
print("已排序列表: ",ListData)执行结果如下:

总结
快速排序是一种分治法.它将原本的问题分成两个子问题,然后再分别解决这两个子问题.子问题就是子序列完成排序,然后再把它们合并成一个整体.那么对原始序列的排序也就完成了.解决子问题的时候会再次使用快速排序,甚至在这个快速排序里仍要使用快速排序.就像俄罗斯套娃,直到子问题里只剩一个数字,排序才算法完成,这种做法就是传说中的递归
分割子序列时需要选择基准数,如果每次选择的基准数都能使得两个子序列的长度为原来的一半,那么快速排序的运行时间为:O(nlogn),将序列对半分割log2n次之后子序列里便只剩下一个数据,这时子序列的排序也就完成了.也就是说如果把根据基准数分割序列的整个过程一行行地展现.总共有log2n行,每轮(每行)每个数都需要和基准数比较大小,因此每行所需要的运行时间为O(n),所以快速排序的整体的时间复杂度为O(nlogn)
如果运气不好的话,每次都选择到最小值作为基准数,那每次都需要把其他数据移到基准数右边,然后递归执行n轮,运行时间也就成了O(n*2);这就相当于每次都选出最小值并把它移到了最左边,这个操作就和选择排序一样了.还有,如果数据中的每个数字被选为基准数的概率都相等,需要的平均运行时间为O(nlogn)

- 点赞
- 收藏
- 关注作者
评论(0)