见微知著,带你认认数据分析的大门,站在门口感受一下预测的魅力

前言
何为预测?
预就是预先、事先,测就是度量、推测。预测通常被理解为对某些事物进行事先推测的过程。其实预测这个概念并不是我们第一次接触到,而是它从古至今都和我们的生活息息相关.而且在计算机技术飞速发展的DT时代,它一直伴随着我们,充斥着生活的方方面面,我们每个人都想更准确地预见未来,来掌握甚至改变事态的发展轨迹.所以用一句简单的话来概括就是:预测是一门研究未来的学问。从古至今都有人不断在研究它,应用它,而且研究的方法和理论也在不断地发展和完善,从古代的占卜术到如今的大数据和人工智能,预测的形式,方法,理论,技术,意义和作用发生了极大的变化.而且在数据科学的加持下,它建立于数据分析的基础上,预测不再是神秘的,而是有据可依,有迹可循,甚至是人人都能使用的一门技能,预测不仅仅是枯燥的建模,干瘪的公式推导,它包含着现象的延伸,就像种子破壳而出,发芽生长一样,具有力量,散发着生命绽放的美。
我们都听过一句谚语:"蚂蚁搬家蛇过道,明日必有大雨到",这是我们古代劳动人民的智慧,是他们根据自己的经验推断出来的.甚至还有夜观天象,占卜之术.我们总说历史总是惊人的相似,在预测中,我们可能会根据经验,因果关系,甚至直觉等等来推断一件事的发生和走势.在历史的场合中,占卜术的出现并不是偶然,面对变幻莫测的大自然,古人心里没底,犹豫,焦虑甚至恐惧,这些不确定性带来了不安全感,从自身以外获得更多信息,从而减少不确定性,他们从身边的现象中探索,比如遇到什么动物,听见什么声音,以及遇见动物的数量,声音的次数乃至事物的颜色,来推断将要发生事情的吉凶祸福,他们认为在事情发生之前,可以通过这些方式得知事情发生的前兆.所以占卜,是先占后卜,即是通过观察身边的事物呈现的状态或者现象对未知的事物进行推测.在殷商时期就已经广泛使用炭火烧烤龟甲,通过裂纹来预测国事,战事,天气,灾难等,看过《封神榜》的童鞋都知道周文王姬昌的占卜之术极其厉害,传说周王姬昌被关在羑里,他为了安稳自己的心灵,也为了把自己的思想学问传给后代,他就依托对阴阳八卦的研究和解释,写出了《周易》这部中国历史上最伟大的书。《周易》根据天地宇宙以及自然变化的规律,告诉人们,处在不同情况下,人们应该采取的态度。

可以看到,占卜的预测方法是缺少科学依据的。预测结果也非常依赖于做出预测的人,不同的人由于经验积累和理解方式的差异,也可能得出完全不同的结果。当然,如果我们对古人的做法不那么消极,则完全可以发挥想象。比如,通过观察身边事物的状态,在愿力特别强的情况下,会不会通过四维时空将未来可能发生的事情在当下的三维世界进行投影呢?因此,这样一联想,古人的做法也可能不是完全瞎扯。虽然我们没有办法去考究古人做法的科学性,但这却为现在的科学预测提供了一些参考,比如,我们要使用跨界的更多维度的数据来做预测,就要善于使用关联的思路,寻找更多的分析维度。好在现在我们的很多信息可以数字化,即便是针对海量数据,也具有成熟的处理办法。
预测的应用
对于个人来说,由于对未知的恐惧,我们都渴望着能知晓未来之事,以寻找从容应对之策。预测这个技能古已有之,古代占卜是预测国事,战事,灾难。由于占卜的不科学和不完全准确,人们一直在努力寻找各自预测的手段。比如东汉时期张衡发明了地动仪,用于监测地震。到了今天依然是我们重要的研究课题,我们虽然无法做到像预测台风一样可以提前几天监测到,但是我们通过大数据和人工智能预警系统,可以提前几十秒,短短的几十秒可以挽救无数的生命和财产。
大家可能都听说过由美国气象学家爱德华·洛伦兹提出的“蝴蝶效应”:指在一个动力系统中,初始条件下微小的变化能带动整个系统的长期的巨大的连锁反应。蝴蝶效应是一种混沌现象,说明了任何事物发展均存在定数与变数,事物在发展过程中其发展轨迹有规律可循,同时也存在不可测的"变数",往往还会适得其反,一个微小的变化能影响事物的发展,证实了事物的发展具有复杂性。
一只南美洲亚马逊河流域热带雨林中的蝴蝶,偶尔扇动几下翅膀,可以在两周以后引起美国得克萨斯州的一场龙卷风。


蝴蝶效应通常用于天气、股票市场等在一定时段难以预测的比较复杂的系统中。如果这个差异越来越大,那这个差距就会形成很大的破坏力。这就是为什么天气或者是股票市场会有崩盘和不可预测的自然灾害。
到了今天的DT时代,我们预测的手段越来越多,越来越科学。完全可做到有理可循,有据可依。我们可以根据预测对象的内外部各种信息、情报以及数据,使用科学的方法和技术,包括判断、推理和模型,对预测对象的趋势发展和变化规律进行预测,从而了解该对象的未来信息,进而评估其发展变化对未来的影响,必要时提出并部署有针对性的方案。
在天气方面,我们通过气象设备收集大量数据,然后通过大数据分析,可以预测小时甚至分钟级别的准确天气预报.于金融方面,我们可以通过大量数据分析可得出股票市场的走势,进而辅助我们做出正确的交易决策,而且银行可利用大数数据分析系统,实现风险控制.相信大家都在电商平台购物的经历,可以看到很多电商平台都有一个推荐模块,比如淘宝的猜你喜欢.这是平台对你的操作记录进行分析而来的,预测你可能需要买什么然后推荐给你.预测涉及的行业和领域极多,并衍生出很多预测专题,小到个人,上至国家大事。除了常见的经济预测、股市预测、气象预测。还有人口预测、上网流量预测、产品销售预测、市场需求预测、流行病预测、价格预测。
预测的定义有很多种,一般认为,预测是从事物发展的历史和现状着手,使用事物的基础信息和统计数据,在严格的理论基础上,对事物的历史发展过程进行深刻的定性分析和严密的定量计算,以了解和认识事物的发展变化规律,进一步对事物未来的发展做出科学推测的过程.
预测的特点
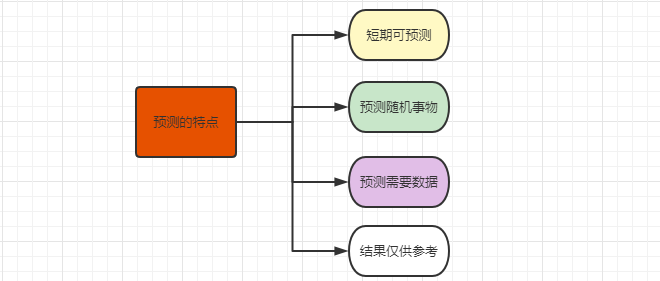
短期可预测
预测是通过事物的过去及现在推测未来,未来的时间可长可短,如果时间太长,由于存在很多不确定因素的干扰,长期预测结果的可信度相对较低,短期预测的结果往往更加可信
预测随机事物
随机事物具有不确定性,这才决定了预测的价值。实现预测要从随机的变化规律中找出相对固定的模式或局部,或整体
预测需要数据
巧妇难为无米之炊,数据就如同做饭的米,实现预测,要通过各种方法收集与预测对象相关的数据,包括历史的,当前的,以及未来的信息,比如天气预报,业务数据等等,然后将这些数据进行整合、清洗和加工
结果仅供参考
由于预测的是随机事物,其发展包含很多不确定性,因此预测结果本来就是不确定的,预测值与实际结果多少存在误差
预测的分类
预测可按不同的维度进行分类:
按范围分类
按时间长短分类
按有无假设条件分类
按预测结果的需求分类
按趋势是否确定分类
按预测依据分类
预测的原则
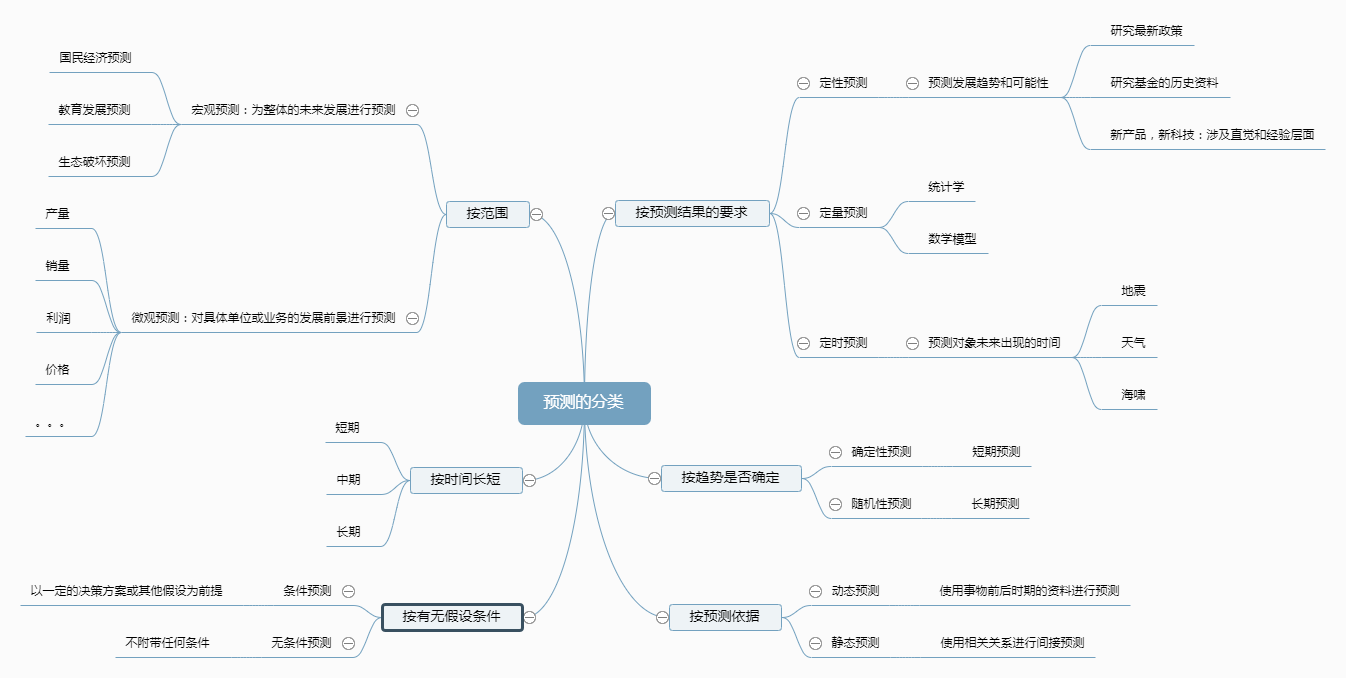
科学的预测是在一定的原则的指导下,按一定的步骤有组织地进行,预测一般应遵循以下8条原则,这8条原则描绘了预测工作的全过程,首先要明确预测的目的,接着采用关联性原则来建立好的分析方法和预测思路,在保持一定连贯性的前提下应用远大近小的原则,建立起预测模型。然后,对预测结果做出概率性预测,对预测偏差较大的动态地反馈回来,并结合模型的实际情况做出调整和修正,使模型更优。当然,提供预测结果必须及时,预测工作的开展也必须控制在一定成本之内。这样,整个预测便建立在坚实的理论基础之上了
目的性原则:进行预测时要关注预测功能的受用者及其对预测结果的要求,只有在充分了解受用者的需求及要求的情况下,正确开展预测,才能避免盲目性
连贯性原则:表示连续的情况或状态.主要包括时间上的连贯性和结构上的连贯性
关联性原则:强调在预测时从相关事物出发去分析影响因素,主要包括中心化关联和类比性关联.以预测对象为中心,去寻找与预测对象相互影响的事物,可能涉及政治,社会,技术,经济等多个方面,这就是中心化关联.类比性关联考虑与预测对象的相似性,从其发展规律中找出有助于预测对象进行预测的因素或信息
近大远小原则:这个好理解,就是离预测时间越近的信息越重要,可信度越高,离预测时间越远的信息就越不重要,近大远小原则,有助于我们在预测时选择样本,选取模型,求解参数和评价预测效果
概率性原则:概率是对随机事件发生的可能性的度量.由于绝大多数预测是针对随机事物的,所以预测得准不准,也会以概率的形式体现出来.需要注意的是,概率只是一种可能性
反馈原则:指返回到起始位置并产生影响.反馈的作用在于发现问题,对问题进行修正,对系统进行优化等.
及时性原则:预测是与时间紧密关联的一项工作,预测的结果应该快速地用于决策,否则,时机一过,就失去了预测的价值
经济性原则:开展工作需要一定的硬件,人力,时间,财力等资源,所以预测本来就是讲求投资回报率的.经济性原则就是要在保证预测结果精度的前提下,合理地安排、布置,选择合适的建模方法和工具,以最低的费用和最短的时间,获得预期的预测结果。一 定不要过度 追求精确性而无故地耗费成本
预测的完整流程
预测涉及数据处理、建模等内容,本身具有一定的复杂性。 然而,在大数据的推动下,数据基数大、维度多,同时对速度的要求也很高,实现预测的复杂度进一步升级。 因此,为了快速、 有效地开展预测工作,有必要提出一套方法论作为指导,保障预测工作有条不素地进行。
预测是个复杂的过程,需要不同角色的人参与,因此,制定用于指导预测工作开展的流程至关重要。从确定预测主题开始,依次进行收集数据、选择方法、分析规律、建立模型、评估效果,发布模型。
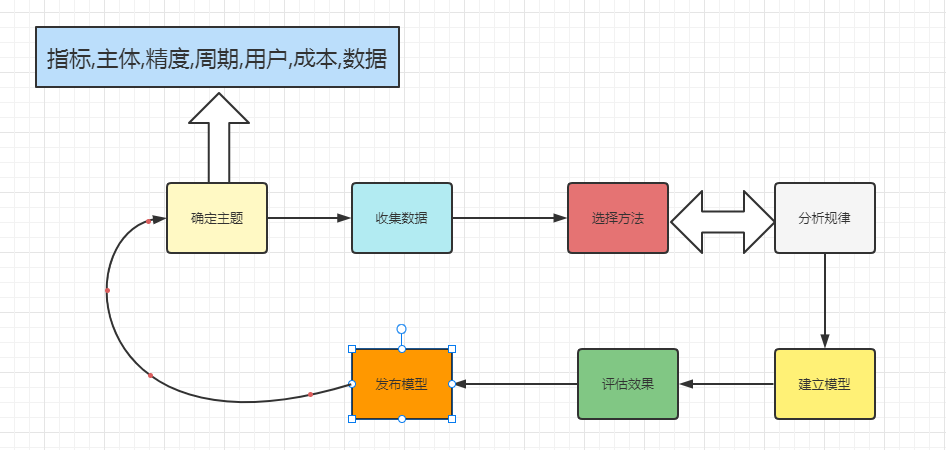
需要注意的是选择方法和分析规律之间是可逆箭头,如果没找到潜在的规律,则还是要回到选择方法环节重新尝试;如果找到了潜在的规律,则说明我们选择了正确的方法并可进入建模环节。在评估效果时,如果没有达到预期,则需要反思主题的合理性,有必要调整主题再进入循环。若评估效果已经达到预期则直接发布模型,注意发布模型与确定主题之间有一条线,表示实现主题的内容,结束循环。整个过程都围绕着数据展开
预测的科学依据——数据分析

数据分析是基于某种行业目的,有导向地进行收集,整理,加工和分析数据的过程.在此过程中,我们可以使用统计分析,数据挖掘等方式或者方法提取有用的信息,并进行概括与总结.如经典的"啤酒与尿布"营销案例:20世纪90年代的美国沃尔玛超市中,"啤酒与尿布"两件商品会经常出现在年轻父亲的购物篮中,超市的管理人员跟进发现,在美国有婴儿的家庭中。一般由母亲在家照料婴儿,年轻的父亲出门购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就出现了啤酒与尿布这样两件看上去毫无关联的商品经常会出现在同一个购物篮的现象
在得此结论后,沃尔玛开始尝试着将啤酒与尿布摆放在相同的区域,让年轻的父亲可以更便捷的找到这两件商品,并为获取更好的商品销售收入,进而推出一次可同时购买"啤酒与尿布",套餐活动.由此可见,数据分析挖掘与概括的潜在信息和事物规律.对于我们日常生活,工作等方面具有一定的指导意义,并且随着互联网的蓬勃发展,越来越多的应用涉及大数据,在这些大数据的背后潜在的又是怎样的数据规律,都需要我们进一步的研究和探索,基于如此的认识,数据分析常用的理论与方法又有哪些?
1.统计分析:统计是进行科学研究的重要方法,通过数字揭示事物在特定时间方面的数量特征,以便对事物进行定量乃至定性分析,从而做出正确的决策,器常见的方法有描述性统计分析、集中趋势分析、相关分析、方差分析、回归分析等
2.数据挖掘:数据挖掘是数据分析的理论核心,各种数据挖掘的算法基于不同的数据类型和数据关联方式,迭代训练关系模型,深入数据内部,挖掘数据潜在价值,其中经典算法有决策树、K-means聚类、SVM分类、Apriori算法等
为了更方便的统计与挖掘数据,许多优秀的统计分析的语言和工具被我们开发与使用,就如Python语言,Python是一种面向对象的解释型计算机程序设计语言,它具有丰富而强大的库,如专用的科学计算扩展numpy,scipy和matplotlib.以及机器学习,数据挖掘模块scikit-learn.TensorFlow等.他们为提供了快速数组处理,数值运算,模型训练以及绘图等功能,为数据分析提供了简洁,方便的调用接口.下面我们将以统计学生成绩为例,具体介绍基于Python语言的数据分析过程
数据的导入与导出
预测建立在大量数据分析的基础上,是科学预测最重要的环节。它使得预测变得有迹可循,有据可依,而数据分析最重要的是数据,数据就相当于驱动动机运行的燃料。
数据分析的第一阶段是获取数据,通常情况下,数据会以文本文件或数据库链接等形式呈现给我们.我们要做的工作是通过一些加载模块完成数据从文件到程序,或从程序到文件的转换操作,这是一项艰巨且重要的工作,但Python将使该工作变得异常简单.只需几行代码,就可轻松导入和导出数据了。一般有以下几种存储文件的导入导出操作:
CSV
Excel
SQL
Excel是我们实际应用中最常用来存储数据的文件格式,而且CSV和Excel用法基本一致,所以接下我们着重实现Excel的导入导出操作:
Exce文件导入
录入学生成绩到excel表格:成绩表.xlsx
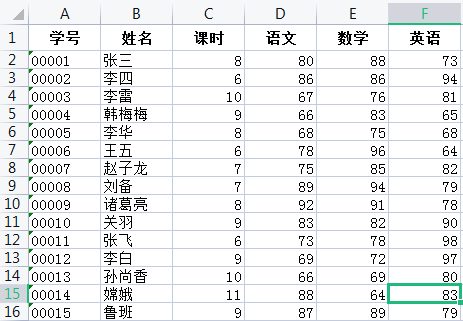
接下来就是见证奇迹的时刻,仅需要几句代码就可以把数据导入到DataFrame中,代码中涉及到pandas库,pandas库是数据分析非常重要的模块.他提供了大量能是我们快捷处理数据的函数和方法.
如果你没有安装过pandas.可使用下面命令安装:
pip install pandas
流程如下:

import pandas as pd
file_path = "成绩表.xlsx"
df = pd.read_excel(file_path)
print("表格数据:\n{0}\n".format(df))运行结果:
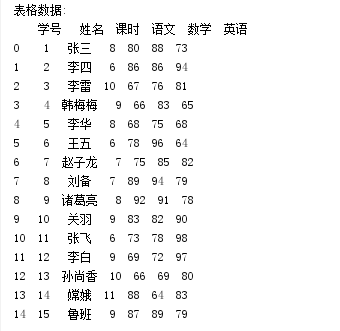
导入csv文件也是类似,只不过csv的导入使用的是read_csv()方法
Exce文件导出
我们在得到统计信息之后,如果需要将该信息以Excel的格式存储到磁盘中.那么我们同样使用pandas模块来操作:
import pandas as pd
subject = ['语文', '数学', '英语','科学']
value = [98, 82.5, 92,99]
mean_list = list(zip(subject, value))
df = pd.DataFrame(data=mean_list, columns=['科目', '成绩'])
writer = pd.ExcelWriter('成绩统计.xlsx', engine='xlsxwriter')
df.to_excel(writer, sheet_name='Sheet1')
writer.save()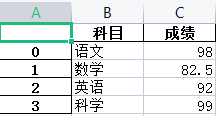
具体流程如下:

导出CSV的流程也是类似的.只不过导出Excel需要调用ExcelWriter,而CSV是生成DataFrame之后,接着就是使用to_csv()方法导出文件到指定路径
导出csv的流程如下:

数据分析
把整理的数据导入之后,接着就是对数据进行分析,通过Python的库函数就可以轻松完成信息的计量统计,数据的管理,数据的关联度分析,仅需一小段代码即可实现:
计算资料描述统计量
计算数据关联度
数据间的线性回归分析
接下来操作我们所用到的数据还是以学生成绩表为主
聚合统计量分析
我们可以通过统计各学科成绩的算术平均值,中位数,极差,标准差等,来了解其分布或者趋势等.具体实现如下:
import pandas as pd
file_path = "成绩表.xlsx"
df = pd.read_excel(file_path, encoding='utf-8')
print("各学科的平均分,中位数,极差,标准差如下:\n")
print("语文成绩的平均分:{0}".format(df['语文'].mean()))
print("语文成绩的中位数:{0}".format(df['语文'].median()))
print("语文成绩的极差:{0}".format(df['语文'].max() - df['语文'].min()))
print("语文成绩的标准差:{0}".format(df['语文'].std()))
print("——————————————————————————\n")
print("数学成绩的平均分:{0}".format(df['数学'].mean()))
print("数学成绩的中位数:{0}".format(df['数学'].median()))
print("英语成绩的极差:{0}".format(df['数学'].max() - df['数学'].min()))
print("数学成绩的标准差:{0}".format(df['数学'].std()))
print("——————————————————————————\n")
print("英语成绩的平均分:{0}".format(df['英语'].mean()))
print("英语成绩的中位数:{0}".format(df['英语'].median()))
print("英语成绩的极差:{0}".format(df['英语'].max() - df['英语'].min()))
print("英语成绩的标准差:{0}".format(df['英语'].std()))
执行结果如下:
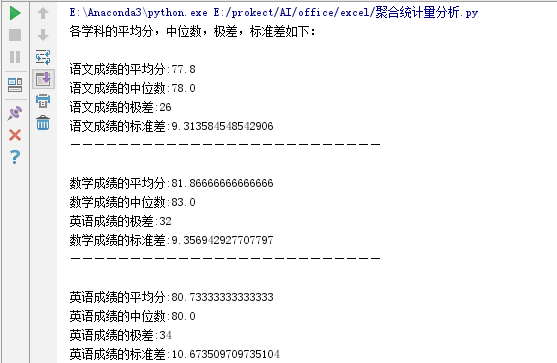
是不是很简单,我们仅仅使用pandas库的函数就可以轻松算出学习各学科成绩的平均分,中位数,极差和标准差,从得出的数据分析可看出学生的数学成绩较为突出.但各科的极差与标准差统计值较大,说明学生各学科的整体水平波动较大.对比各科统计情况来看可能语文成绩表现较为稳定,从统计的数据中可以得出学生各科的成绩都有待进一步巩固
关联度分析
关联度分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度.接下来我们将通过协方差,相关系数与线性回归等方面挖掘数据间的关联关系
1.协方差分析
协方差一般用来衡量两个变量的总体误差,如果两个变量的变化趋势-致,协方差就是正值,说明两个变量正相关。如果两个变量的变化趋势相反,协方差就是负值,说明两个变量负相关。如果两个变量相互独立,那么协方差就是0,说明两个变量不相关。协方差的计算公式如下:
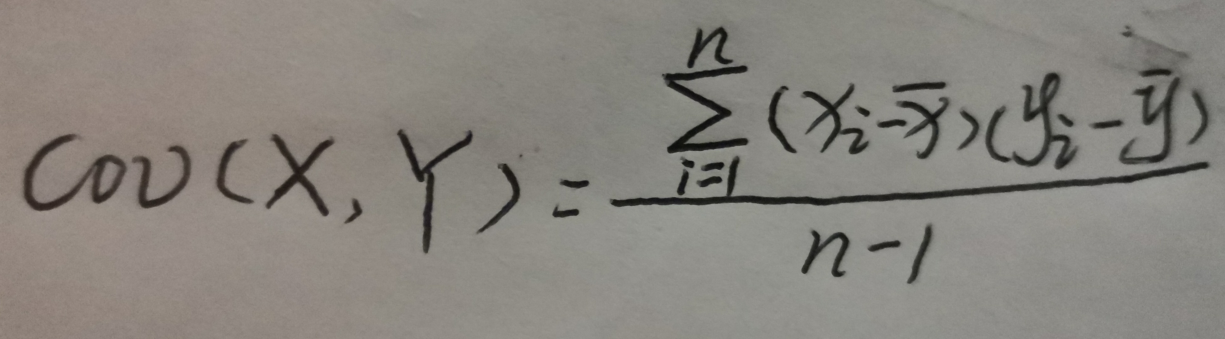
在数据中,除了学生成绩,还可以看到另一个关键信息-- 课时(即学习时长), 现在我们基于协方差来分析学生每天学习用时与本次综合成绩的关联关系.
import numpy as np
import pandas as pd
file_path = "成绩表.xlsx"
df = pd.read_excel(file_path, encoding='utf-8')
print("表格数据如下:\n{0}".format(df))
report = list(df.iloc[:, 3:].sum(axis=1))
hour_report = list(df["课时"])
hour_report.extend(report)
data = np.array(hour_report).reshape(15, 2, order="F")
df_hour_report = pd.DataFrame(data, columns=['时长', '总分'])
print("\n")
print("时长与成绩总分统计情况:\n{0}".format(df_hour_report))
print("\n")
print("时长与成绩协方差统计情况:\n{0}".format(df_hour_report.cov()))运行结果:
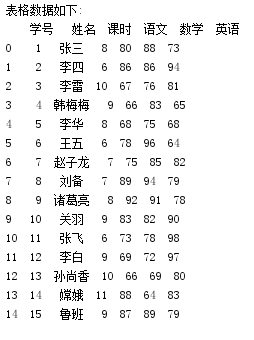


代码中调用了cov方法计算了学习时长于综合成绩的协方差cov(时长,总分)=-13.3,说明有效学习时长与综合成绩负相关,即学生每天的学习用时并非都是有效时长,或者说明学生学习是不够认真,不够重视.只是应付任务.导致利用很对时间却依然没有提高成绩
2.相关关系分析
协方差可以通过数字衡量变量间的相关性,却无法针对相关的密切程度进行度量,如学生每日有效的学习用时与综合成绩的相关程度,当我们面对多个变量时,无法通过协方差来说明哪两组数据的]相关性最高。要衡量和对比相关性的密切程度,就需要使用下一个方法一相关系数。相关系数是反应变量之间关系密切程度的统计量,相关系数的取值区间在-1~1之间。1表示两个变量完全线性相关, -1表示两 个变量完全负相关,0表示两个变量不相关。 数据越趋近于0表示相关关系越弱,计算公式如下:
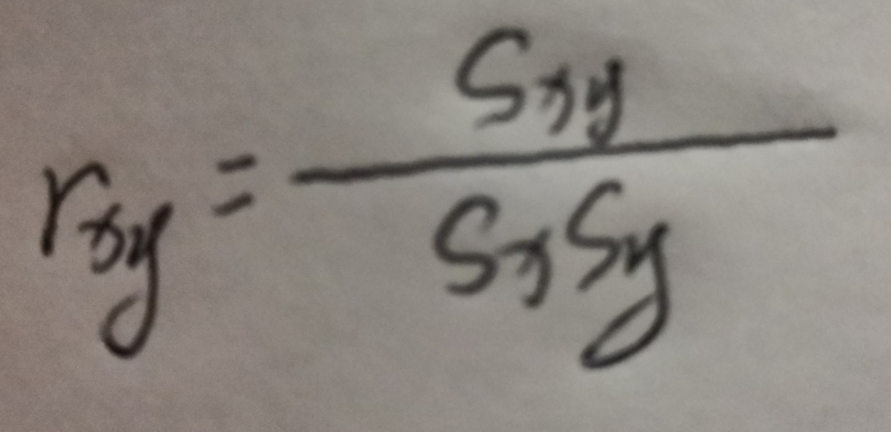
其中,r.表示样本相关系数,S表示样本协方差,S, 表示x的样本标准差,S, 表示y的样本标准差。接下来我们将相关系数代入学生成绩的例子
学习时长与综合成绩的相关系数:
import math
import numpy as np
import pandas as pd
file_path = "成绩表.xlsx"
df = pd.read_excel(file_path, encoding='utf-8')
report = list(df.iloc[:, 3:].sum(axis=1))
hour_report = list(df["课时"])
hour_report.extend(report)
data = np.array(hour_report).reshape(15, 2, order="F")
df_hour_report = pd.DataFrame(data, columns=['时长', '综合成绩'])
print("学习时长与综合成绩的协方差:\n{0}\n".format(df_hour_report.cov()))
matrix_cov = df_hour_report.cov()
coefficent_cor = round(
matrix_cov["时长"]["综合成绩"] / math.sqrt(matrix_cov["时长"]["时长"]) /
math.sqrt(matrix_cov["综合成绩"]["综合成绩"]), 2)
print("学习时长与综合成绩的相关系数 :{0}".format(coefficent_cor))执行结果:

我们基于协方差的计算流程,在得到时长与成绩的协方差后,将相关变量代入公式,最后得出有效学习时长与综合成绩的相关系数crrelation_cofficent =-0.47,从数值的层面可以说明,学生每天有效的学习时长与综合成绩负相关,对于这些学生来说是两者的没有关联性
3.线性回归分析
在相关关系分析中我们在得出,在这批学生中时长与成绩具有较弱关联的结论,现在尝试着使用回归分析描述出其对应的关联关系,回归分析是确定两组或两组以上变量间关系的统计方法。回归分析按照变量的数量分为一元回归和多元回归。我们的数据中只包含学习时长和综合成绩两个变量,因此使用一元回归,接下来将通过调用scikit-learn模块完成两者线性模型的学习
import pandas as pd
from sklearn.linear_model import LinearRegression
file_path = "成绩表.xlsx"
df = pd.read_excel(file_path, encoding='utf-8')
hour = df["课时"].values.reshape(15, 1)
report = df.iloc[:, 3:].sum(axis=1).values.reshape(15, 1)
linear_reg = LinearRegression()
linear_reg.fit(hour, report)
print("学习时长与综合成绩的线性回归方程:\n" +
"y={0}x+{1}".format(linear_reg.coef_[0][0], linear_reg.intercept_[0]))执行结果:

在本例中,综合成绩和学习时长是负相关的,也就是说综合成绩并没有随着学习时长的变化有所提升
我们在导入数据到程序后,首先抽取出学生学习时长与各科成绩数据,将学习时长设置为自变量x,并统计出综合成绩后,将其设置为因变量y,之后分别将变量作为实参传入线性回归模型Linear-Regression的fit 方法中,最终得到时长与成绩的线性回归方程
数据可视化
我们上面的分析统计工作得出了一定的结论,但仅限于文字层面的上的描述,所以如果需要更深入分析,我们还可以使用直观的图表形式支撑我们得出的结论,比如我们可以使用柱状图来展示排名情况,使用箱线图直观显示数据的分散情况,让我们更直观地了解数据的中位数,异常值,分布区间等形状信息.下面我们来实现这两种图表的展示:
排名柱状图
import pandas as pd
import matplotlib.pyplot as plt
file_path = "成绩表.xlsx"
df_raw = pd.read_excel(file_path, encoding='utf-8')
df_report = pd.DataFrame(df_raw.iloc[:, 3:].sum(axis=1), columns=["综合成绩"])
df_aggr = pd.concat((df_raw, df_report), axis=1)
df_aggr_sort = df_aggr.sort_values(by=['综合成绩'], ascending=False)
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
width = 0.5
fig, ax = plt.subplots()
ax.bar(df_aggr_sort["姓名"], df_aggr_sort["语文"], width=width, label="语文")
ax.bar(df_aggr_sort["姓名"], df_aggr_sort["数学"],
bottom=df_aggr_sort["语文"], width=width, label="数学")
ax.bar(df_aggr_sort["姓名"], df_aggr_sort["英语"],
bottom=df_aggr_sort["语文"] + df_aggr_sort["数学"],
width=width, label="英语")
ax.set_xlabel("姓名")
ax.set_ylabel("综合成绩")
ax.legend()
plt.show()执行结果:
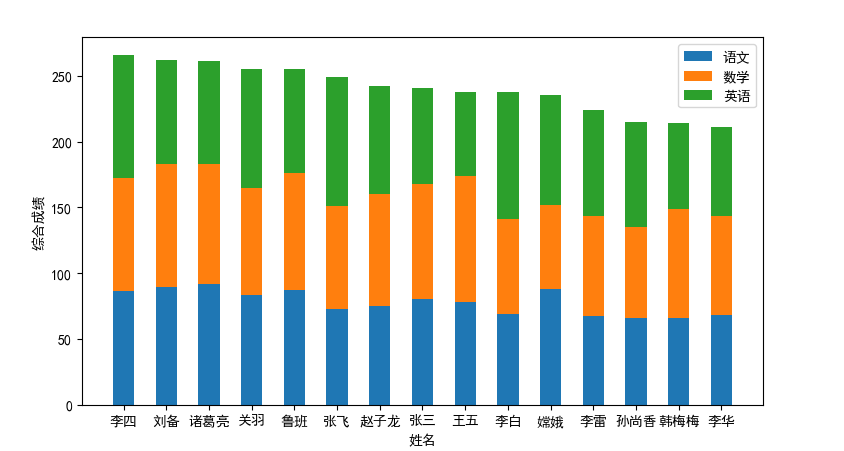
这里画图用到了matplotlib模块,如果还不会使用这个模块的童鞋可参考《Python 绘制精美可视化数据分析图表 (一)-Matplotlib》
成绩分布箱线图
import pandas as pd
import matplotlib.pyplot as plt
file_path = "成绩表.xlsx"
df_raw = pd.read_excel(file_path, encoding='utf-8')
df_report = pd.DataFrame(df_raw.iloc[:, 3:].sum(axis=1), columns=["综合成绩"])
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
fig, ax = plt.subplots()
plt.boxplot(df_report["综合成绩"])
ax.set_xticklabels(["综合成绩"])
ax.set_ylabel("总分")
plt.title("成绩分布箱线图")
plt.show()
执行结果:
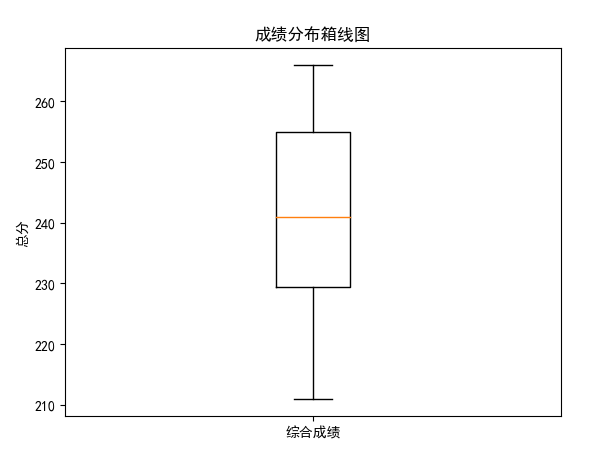
先统计完学生的综合成绩,然后调用绘图函数boxplot将综合成绩数据作为实参传入,并通过matplotlib.pyplot的show方法显示成绩分布箱线图。
其中,箱线图中引入了统计学的四分位数的概念,所谓四分位数,就是把组中所有数据由小到大排列并分成四等份,处于三个分割点位置的数字就是四分位数:
第一四分位数(Q1),又称为“下四分位数”,等于该样本中所有数值由小到大排列后第25%的数字,如上图中的矩形的底边边框
第二四分位数(Q2),又称为“中位数”,等于该样本中所有数值由小到大排列后第50%的数字,如上图中的矩形中的黄色的内嵌线段
第三四分位数(Q3),又称为“上四分位数”,等于该样本中所有数值由小到大排列后第75%的数字,如上图中的矩形的顶边边框
还有更多的图形图表展示形式,比如客观展示整体情况的直方图;还有清晰反映与比较各区间成绩的比重的饼图等等.这里不再赘述.感兴趣的童鞋,你们可以尝试去实现并绘制这些图像
当然只是数据分析的冰山一角.本文只是抛转引玉,数据分析涉及到的内容以及算法极多,有待我们继续学习和探索~
总结
总体来说,预测就是从已知推测未知.然后做出警示或者是改变,古代的占卜,地动仪,观天象等,都是对经验的总结和思考的结果,从贝叶斯概率性分析就是从先验知识推测后验知识, 现代天气预报,地震预测,台风预测,甚至目前疫情的预测,企业对市场走向预测,金融市场股票走势的预测。预测事态走向,小到各个平台预测用户购买意向,比如推荐系统,猜你喜欢等等这些都是数据分析后结果,大到社会治安可以通过数据分析和预测,预防诈骗,盗窃等,将一切违法扼杀于萌芽之初,或通过对交通数据的分析,减少交通事故的发生。预测都是通过收集数据、分析数据、借助统计学和概率论的手段,根据以往的历史资料、数据和已掌握的经验、知识,通过科学方法,定性或定量地对未来发展趋势或可能发生的事做出预计和推测;而且我们还可以通过预测,规避风险的发生,挽回或者降低我们的损失,比如银行的风控系统,就是很好的应用.甚至国家安全,战争的研究,军旗推演,同样是一种对未来的预测。但预测的结果并非百分百与实际相符,而是大概率可能发生而已,事态会随着环境的改变而改变,毕竟环境复杂,瞬息万变,不确定性因素诸多,甚至可能牵一而动全身,所以我们需要掌握更多数据,方能做出更加准确的预测。
正所谓有因必有果,虽然古代没有计算机,没有大数据.但是对事物规律的分析,然后归纳总结等等.这一套流程.是中国老祖先早已有之的智慧。我们都知道“以史为鉴,可以知兴替”,这应该也算属于预测的范畴,总结历史经验,在对历史的深入思考中汲取智慧、开创未来


- 点赞
- 收藏
- 关注作者
评论(0)