python文件操作知多少

前言
对于文件大家应该都不陌生,但是在接触计算机之前,通常将文件定义为内容的载体.如公文书信或者有关政策理论方面的文章.计算机文件也一样,而且在计算机中文件的类型更加丰富多样,用途广泛.有的是用来支撑程序运行的,有的只是单纯用于数据存储,文件使用文件扩展名区分文件类型,比如我们常用图片格式,有.jpg/.png/.gif,记事本保存的文字.txt,办公文档类型.docx/.pptx/.xlsx等.它是存储在计算机存储区的信息集合.
文件是计算机中具有特定标识的存储区,他由操作系统管理,用于计算机操作系统的使用过程中的各项操作的支持,在计算机的系统使用中,文件的操作是贯穿始终的,小到文本存储,大到各种系统软件.而且在软件的开发中对文件的操作几乎是必不可少的,不管是web程序还是桌面程序,就比如对数据的操作,其实也是通过特定的算法和特定的数据格式把数据存入持久化文件中.还有在Python的最热门的自动化办公和数据分析中,对文件的读写操作也是常用操作,还有我们网站中最常用图片上传操作同样涉及到文件操作.
我们开发中对文件的操作非常频繁.而且很多我们待处理的信息都存储于文件中,当处理这些信息时需要通过Python程序来处理,我们该如何操作呢?下面带你领略Python处理文件的风采.
在学习之前,我们先来看看文件处理的基本步骤:
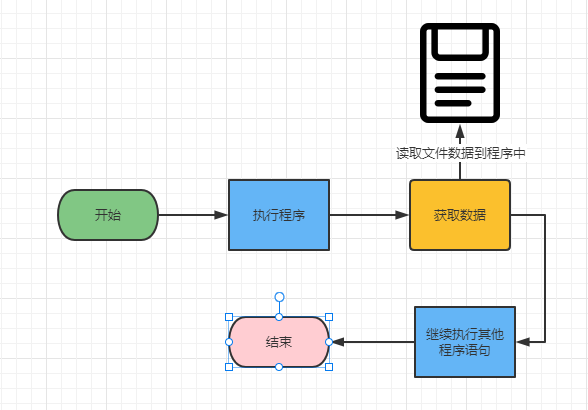
文件的读取
Python程序想要使用计算机存储区的文件时,需要遵守Python文件操作的规定,依顺序读取,如果可以随便处理会让文件变得很不安全.
想要读取文件,先使用Python内置的open()函数通过提供文件路径的方式将文件和程序链接起来,之后便可以通过操作文件对象的方式处理文件.在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法.
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode).
函数基本使用:open(file, mode='r')
完整语法:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)参数说明:
file: 必需,文件路径(相对或者绝对路径)
mode: 可选,文件打开模式(常用值:t,x,b,+,r,rb,rb+,w,w+,wb....)默认为文本模式,如果要以二进制模式打开,加上b
buffering: 设置缓冲
encoding: 一般使用utf8
errors: 报错级别
newline: 区分换行符
closefd: 传入的file参数类型
opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符
既然有fo.open()那当然有fo.close(),close() 方法用于关闭一个已打开的文件。关闭后的文件不能再进行读写操作, 否则会触发 ValueError 错误。 close() 方法允许调用多次。
当 file 对象,被引用到操作另外一个文件时,Python 会自动关闭之前的 file 对象。要养成使用 close() 方法关闭文件是的好习惯
下面通过简单的例子示范文件的操作:
首先先创建一个txt文本文件.随便输入点内容.
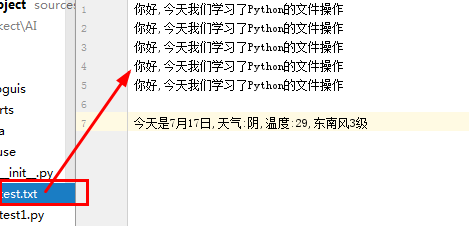
# encoding='utf-8'防止读取中文出现错误,指定字符集为utf8
file = open(r'test.txt',encoding='utf-8') #'r'是防止字符转义的 这里可以使用相对路径或者绝对路径
while True: #Python一般在冒号后面需要注意缩进
line = file.readline() #按行读取
if len(line) == 0: #读完跳出循环停止读取
break
print(line,end="")
file.close()执行结果:

在上面的第5行代码中,我们使用到lreadline() 函数,是按行读取文本,文件读取还有一个与之类似的按字符读取read(N),N为一次从文件读取的字符个数,默认读取一个字符到字符串
上面我们使用了while的死循环,通过判断读取的进度结束读取并跳出循环(注:在程序中一定要避免死循环) ,我们还可以使用for循环同样能达到一样的效果:for line in open("文件路径"),按行读取,其实就是通过循环移动文件读取的指针.
再举个例子:计算文件中某个字符的出现次数统计,在平常开发中好像也常用
这里会使用到collections库
collections是Python内建的一个集合模块,提供了许多有用的集合类,实现一些特定的数据类型,可以替代Python中常用的内置数据类型如dict,list,set和tuple。比如不可变类型tuple,我们可以轻松地用它来表示一个二元向量,但这不是本文的重点,感兴趣的童鞋可以自行搜索学习.
素材:我复制的是这篇文章到test.txt

import collections
file = open('test2.txt',encoding='utf-8')
str = file.read().split(' ')
n = collections.Counter(str)
print(n['home'])
s = zip(n.values(), n.keys())
output = open('result.txt','w',encoding='utf-8')
for item in sorted(s, reverse=True):
output.write("{0} {1}\n".format(item[1], item[0]))result.txt统计的部分截图:

直接读入数据然后使用collections.Counter()来统计每个单词的出现次数,返回的是一个字典,然后使用zip把字典压缩成列表变量s
文件的写入
前面说了文件的读操作,自然还有对应的写操作.写文件操作的顺序和读操作的顺序差不多:建立文件链接,写数据,然后关闭文件.
接着我们通过例子来感受一下.
#写数据操作
text = '''As he stood in front of the group of overachievers he said, 'OK, time for a quiz.'
He pulled out a one-gallon,wide-mouth jar and set it on the table in front of him.
He also produced about a dozen fist-sized rocks and carefully placed them,one at a time, into the jar.
When the jar was filled to the top and no more rocks would fit inside, he asked, 'Is this jar full?'
...
'''
file = open("testWrite.txt", "w")
file.write(text)
file.close()testWrite.txt截图

使用了三引号给text指定了带有换行的字符串
上面的写入操作主要是write()函数,写入函数除了这个还有writelines()函数用于向文件中写入一序列的字符串。这一序列字符串可以是由迭代对象产生的,如一个字符串列表。
我们还可以从web上读取数据并保存所需要的数据到文件
#读取web页面信息
from urllib import request
from bs4 import BeautifulSoup
url="http://www.jianshu.com"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
page = request.Request(url,headers=headers)
page_info = request.urlopen(page).read().decode('utf-8')
soup = BeautifulSoup(page_info, 'html.parser')
titles = soup.find_all('a', 'title')
file = open("webinfo.txt","w",encoding='utf-8')
for title in titles:
file.write(title.string + '\n')
file.write("http://www.jianshu.com" + title.get('href') + '\n\n')结果截图:

这个程序requests和BeautifulSoup两个库来获取网络上的信息
如果提示两个不存在,可使用以下命令安装即可:
pip install requests
pip install beautifulsoup4文件的其他操作函数
file.flush():刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入
file.fileno():返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上
file.next():返回文件下一行,但是Python3不支持
与next()函数类似的还有seek()
file.seek():移动文件读取指针到指定位置
file.tell():返回文件当前位置
file.truncate([size]):从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 windows 系统下的换行代表2个字符大小
扩展
上面例子只是对少量数据的处理,但是在日常的开发中往往需要大数据文件进行处理.相对来说Python对大数据文件处理效率不高.所以如果我们遇到大数据文件应该怎么处理呢.我们一般处理方式有:
可以使用分治的思想
将文件切分为多个小段,同时处理多段,处理完后将处理结果合并
使用Python自带的迭代器分行处理文件
这个问题稍微复杂,这里点到为止,以后有机会再单独细说.
对文件的操作就到这里了.篇幅有限,点到为止.还有更多操作文件的方式等你发现!

- 点赞
- 收藏
- 关注作者
评论(0)